CausalMix: Data Mixture as Causal Inference for Language Model Training
Pith reviewed 2026-07-02 15:42 UTC · model grok-4.3
The pith
Treating data mixtures as causal treatments lets small proxy runs predict optimal mixes for larger models and data pools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
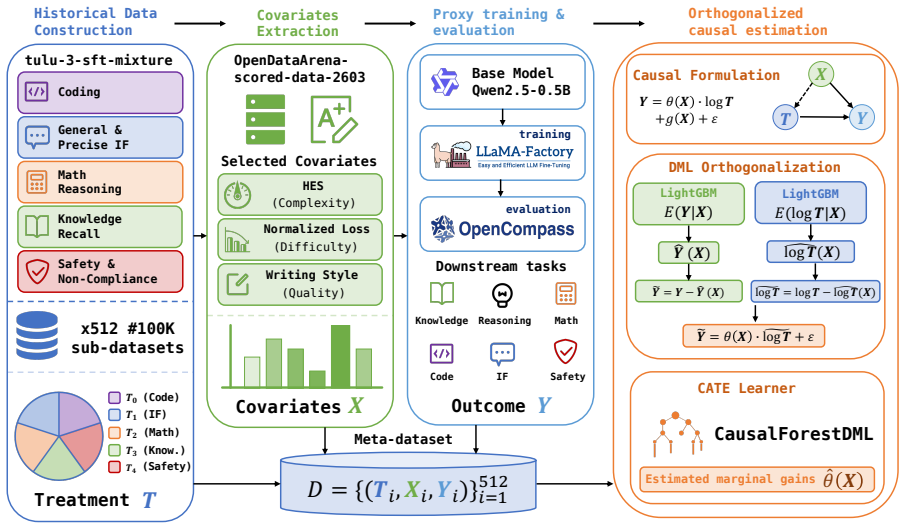
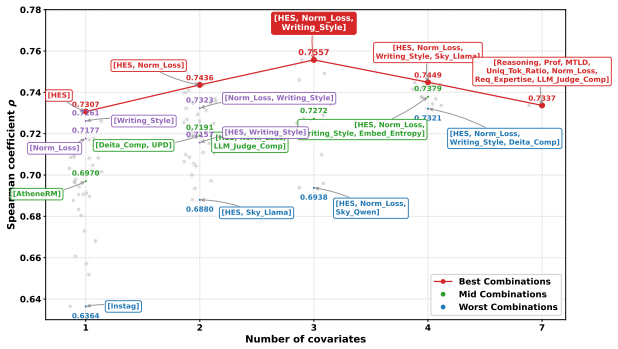
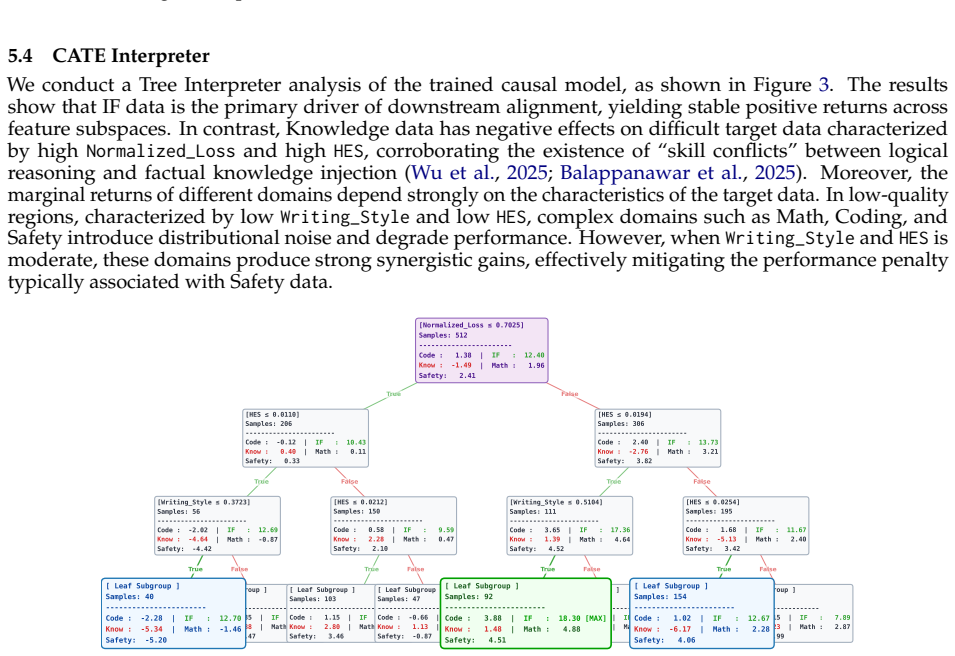
By fitting a causal model on 512 runs of a 0.5B-scale proxy to estimate the Conditional Average Treatment Effect with data-pool statistical features as covariates and domain mixture as treatment, the method extrapolates an optimal mixture for an 800K data pool, applies it to train a 7B model, and generalizes the framework to long chain-of-thought data on a 4B model, producing consistent gains over baselines such as RegMix across downstream tasks while supplying visual analysis of the learned mixing strategy through a CATE Interpreter.
What carries the argument
Causal model estimating Conditional Average Treatment Effect (CATE) with data-pool statistical features as covariates and domain mixture as the treatment.
If this is right
- Optimal mixtures can be inferred dynamically for new data states without retraining the optimizer from scratch.
- The same causal framework applies to both standard pretraining and long chain-of-thought data regimes.
- Visual inspection of the CATE Interpreter reveals how the learned mixing strategy depends on data covariates.
- Confounding biases in mixture optimization are isolated by the causal modeling step.
Where Pith is reading between the lines
- The method could reduce total compute spent on mixture search when data pools are updated frequently.
- Similar causal framing might apply to other training choices such as learning-rate schedules or architecture variants.
- Validation on a wider range of model families would test whether the proxy-to-target transfer remains reliable.
Load-bearing premise
Effects estimated from 0.5B-scale proxy runs transfer without material bias to 7B-scale training on larger data pools and to chain-of-thought data on 4B models.
What would settle it
Training the 7B model with the extrapolated mixture and observing no improvement over RegMix on the reported downstream tasks would falsify the transfer claim.
Figures
read the original abstract
In Large Language Model (LLM) training, data mixing plays a pivotal role in determining model performance. Recent methods optimize mixture weights via proxy models, but they rely on the assumption of static data distributions. As a result, when the underlying data pool shifts, these methods require costly retraining from scratch. This limitation restricts their ability to scale seamlessly from small settings to larger data pools and model sizes. In this paper, we propose CausalMix to address this limitation by casting data mixture optimization as a causal inference problem. We formulate the statistical features of the data pool as covariates and the domain mixture as the treatment. After fitting a causal model on 512 runs of Qwen2.5-0.5B to estimate the Conditional Average Treatment Effect (CATE), we extrapolate the optimal mixture for an 800K data pool and apply it to train a 7B model. Furthermore, we successfully generalize the framework to long chain-of-thought data on Qwen3-4B-Base. By leveraging causal modeling to isolate confounding biases, CausalMix dynamically infers state-dependent optimal data mixtures. Extensive experiments show that the mixture guided by CausalMix consistently improves performance across multiple downstream tasks, outperforming RegMix and other baselines. In addition, we use the CATE Interpreter to provide visual analysis of the learned mixing strategy. Overall, CausalMix offers a causal and interpretable framework for optimizing LLM data mixtures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that framing LLM data mixture optimization as causal inference—treating data-pool statistical features as covariates and domain mixture weights as treatment—allows fitting a causal model on 512 runs of Qwen2.5-0.5B to estimate CATE, extrapolating an optimal mixture for an 800K data pool, and applying it to train a 7B model (plus a separate generalization to long CoT data on Qwen3-4B-Base). The resulting mixtures are reported to outperform RegMix and other baselines on downstream tasks while providing interpretability via a CATE Interpreter.
Significance. If the CATE estimates prove transferable and the identification assumptions hold, the approach could reduce the need for repeated proxy retraining when data pools change and supply a more principled way to handle confounding in mixture optimization. The use of 512 controlled runs and the attempt to generalize across scales and data types (standard pretraining to CoT) are positive elements that, if validated, would strengthen the contribution.
major comments (3)
- [Abstract] Abstract and the description of the experimental pipeline: the central claim that the fitted CATE from 0.5B runs can be extrapolated to select mixtures for 7B training rests on the unstated assumption that treatment effects are invariant to model scale. No covariate or moderator for model capacity (or any proxy such as parameter count or compute) appears in the causal graph, so scale-mixture interactions remain unmodeled; this directly undermines the extrapolation step that produces the 7B result.
- [Abstract] Abstract: the manuscript states that a causal model was fitted to estimate CATE but supplies no information on model specification (e.g., which estimator or functional form), identification assumptions (e.g., ignorability, positivity), validation of CATE estimates, error bars, or sensitivity analyses. Without these details the claim that CausalMix “isolates confounding biases” cannot be evaluated.
- [Abstract] The 4B CoT generalization: the same 0.5B-derived CATE is applied to a different data regime (long chain-of-thought) and model size (4B). The absence of scale or data-type moderators in the causal model makes this transfer an additional untested assumption that is load-bearing for the broader claim of dynamic, state-dependent mixture inference.
minor comments (2)
- [Abstract] The abstract refers to “512 runs of Qwen2.5-0.5B” and an “800K data pool” without clarifying whether the 512 runs used the same or a smaller data pool; this detail is needed to assess the proxy-to-target gap.
- Notation for the causal model (covariates, treatment, outcome) should be introduced with explicit symbols and linked to the CATE formula in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating revisions where appropriate to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the experimental pipeline: the central claim that the fitted CATE from 0.5B runs can be extrapolated to select mixtures for 7B training rests on the unstated assumption that treatment effects are invariant to model scale. No covariate or moderator for model capacity (or any proxy such as parameter count or compute) appears in the causal graph, so scale-mixture interactions remain unmodeled; this directly undermines the extrapolation step that produces the 7B result.
Authors: We acknowledge that the causal graph does not include model scale (or any proxy) as a covariate or moderator, and the extrapolation from 0.5B CATE estimates to 7B training therefore rests on an implicit assumption of transferability. The manuscript presents this as an empirical finding supported by the 7B results, but we agree the assumption should be stated explicitly. In the revision we will add a dedicated paragraph in the methods and discussion sections stating the scale-invariance assumption, its motivation from the observed transfer, and its status as a limitation. We will also note that incorporating scale as a moderator is a natural extension for future work. revision: partial
-
Referee: [Abstract] Abstract: the manuscript states that a causal model was fitted to estimate CATE but supplies no information on model specification (e.g., which estimator or functional form), identification assumptions (e.g., ignorability, positivity), validation of CATE estimates, error bars, or sensitivity analyses. Without these details the claim that CausalMix “isolates confounding biases” cannot be evaluated.
Authors: We agree that the abstract (and, to a lesser extent, the main text) lacks sufficient detail on the causal estimator, identification assumptions, validation, uncertainty quantification, and sensitivity checks. The full methods section describes the estimator and assumptions at a high level, but we will expand both the abstract and the main text to specify the exact estimator and functional form, list the maintained identification assumptions with justification, report validation metrics and error bars on the CATE estimates, and include sensitivity analyses. These additions will be made in the revised manuscript. revision: yes
-
Referee: [Abstract] The 4B CoT generalization: the same 0.5B-derived CATE is applied to a different data regime (long chain-of-thought) and model size (4B). The absence of scale or data-type moderators in the causal model makes this transfer an additional untested assumption that is load-bearing for the broader claim of dynamic, state-dependent mixture inference.
Authors: We recognize that applying the 0.5B-derived CATE to the 4B long-CoT setting likewise assumes transferability across both scale and data regime without explicit moderators. The manuscript presents the 4B result as a successful generalization, but the underlying assumption is not discussed. In the revision we will add explicit discussion of this transfer assumption in the generalization section, describe how the framework was adapted for the CoT data pool, and list the lack of data-type moderators as a limitation with suggested directions for future modeling. revision: partial
Circularity Check
No significant circularity; derivation relies on external empirical validation
full rationale
The paper fits a causal model on 512 runs of a 0.5B proxy model to estimate CATE, then applies the resulting mixture selection to train a separate 7B model on an 800K pool (and a 4B model on CoT data). The central claim of performance improvement is evaluated through actual large-model training and downstream metrics, not derived tautologically from the small-model fit. No equations reduce the large-scale result to the proxy fit by construction, no self-citations are load-bearing in the provided text, and the method does not rename known results or smuggle ansatzes. The transfer assumption is an empirical hypothesis subject to falsification, not a definitional loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- Causal model parameters for CATE estimation
axioms (1)
- domain assumption Causal effects estimated at 0.5B scale remain valid at 7B scale and across data-pool shifts
Reference graph
Works this paper leans on
-
[1]
Biometrika , volume=
Quasi-oracle estimation of heterogeneous treatment effects , author=. Biometrika , volume=. 2021 , publisher=
2021
-
[2]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
The statistical analysis of compositional data , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1982 , publisher=
1982
-
[3]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
Qwen Team , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
-
[4]
2025 , eprint=
AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale , author=. 2025 , eprint=
2025
-
[5]
Li, Peng and He, Yeye and Yashar, Dror and Cui, Weiwei and Ge, Song and Zhang, Haidong and Rifinski Fainman, Danielle and Zhang, Dongmei and Chaudhuri, Surajit , title =. Proc. ACM Manag. Data , month = may, articleno =. 2024 , issue_date =. doi:10.1145/3654979 , abstract =
-
[6]
WildGuard: Open One-stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of
Seungju Han and Kavel Rao and Allyson Ettinger and Liwei Jiang and Bill Yuchen Lin and Nathan Lambert and Yejin Choi and Nouha Dziri , booktitle=. WildGuard: Open One-stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of. 2024 , url=
2024
-
[7]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
WildTeaming at Scale: From In-the-Wild Jailbreaks to (Adversarially) Safer Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[8]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The Art of Saying No: Contextual Noncompliance in Language Models , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[9]
The Twelfth International Conference on Learning Representations , year=
WizardCoder: Empowering Code Large Language Models with Evol-Instruct , author=. The Twelfth International Conference on Learning Representations , year=
-
[10]
Hugging Face repository , howpublished =
Edward Beeching and Shengyi Costa Huang and Albert Jiang and Jia Li and Benjamin Lipkin and Zihan Qina and Kashif Rasul and Ziju Shen and Roman Soletskyi and Lewis Tunstall , title =. Hugging Face repository , howpublished =. 2024 , publisher =
2024
-
[11]
OpenMathInstruct-2: Accelerating
Shubham Toshniwal and Wei Du and Ivan Moshkov and Branislav Kisacanin and Alexan Ayrapetyan and Igor Gitman , booktitle=. OpenMathInstruct-2: Accelerating. 2025 , url=
2025
-
[12]
S ci RIFF : A Resource to Enhance Language Model Instruction-Following over Scientific Literature
Wadden, David and Shi, Kejian and Morrison, Jacob and Li, Alan and Naik, Aakanksha and Singh, Shruti and Barzilay, Nitzan and Lo, Kyle and Hope, Tom and Soldaini, Luca and Shen, Shannon Zejiang and Downey, Doug and Hajishirzi, Hannaneh and Cohan, Arman. S ci RIFF : A Resource to Enhance Language Model Instruction-Following over Scientific Literature. Proc...
-
[13]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[14]
W ild V is: Open Source Visualizer for Million-Scale Chat Logs in the Wild
Deng, Yuntian and Zhao, Wenting and Hessel, Jack and Ren, Xiang and Cardie, Claire and Choi, Yejin. W ild V is: Open Source Visualizer for Million-Scale Chat Logs in the Wild. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2024. doi:10.18653/v1/2024.emnlp-demo.50
-
[15]
WildChat: 1M Chat
Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng , booktitle=. WildChat: 1M Chat. 2024 , url=
2024
-
[16]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
OpenAssistant Conversations - Democratizing Large Language Model Alignment , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[17]
Rush and Thomas Wolf , title =
Nazneen Rajani and Lewis Tunstall and Edward Beeching and Nathan Lambert and Alexander M. Rush and Thomas Wolf , title =. Hugging Face repository , howpublished =. 2023 , publisher =
2023
-
[18]
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Singh, Shivalika and Vargus, Freddie and D. Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.620
-
[19]
2026 , url=
ModalMix: Optimizing Multimodal Data Mixtures with Compute-Dependent Regression , author=. 2026 , url=
2026
-
[20]
2025 , eprint=
TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training , author=. 2025 , eprint=
2025
-
[21]
NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , year=
Train-before-Test Harmonizes Language Model Rankings , author=. NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , year=
2025
-
[22]
The Fourteenth International Conference on Learning Representations , year=
Superficial Safety Alignment Hypothesis , author=. The Fourteenth International Conference on Learning Representations , year=
-
[23]
Unveiling Downstream Performance Scaling of
Chengyin Xu and Kaiyuan Chen and Xiao Li and Ke Shen and Chenggang Li , booktitle=. Unveiling Downstream Performance Scaling of. 2026 , url=
2026
-
[24]
A Strategic Coordination Framework of Small LM s Matches Large LM s in Data Synthesis
Gao, Xin and Pei, Qizhi and Tang, Zinan and Li, Yu and Lin, Honglin and Wu, Jiang and Wu, Lijun and He, Conghui. A Strategic Coordination Framework of Small LM s Matches Large LM s in Data Synthesis. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.566
-
[25]
Tang, Zinan and Gao, Xin and Pei, Qizhi and Pan, Zhuoshi and Cai, Mengzhang and Wu, Jiang and He, Conghui and Wu, Lijun. Middo: Model-Informed Dynamic Data Optimization for Enhanced LLM Fine-Tuning via Closed-Loop Learning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.350
-
[26]
Position: The Most Expensive Part of an
Nikhil Kandpal and Colin Raffel , booktitle=. Position: The Most Expensive Part of an. 2025 , url=
2025
-
[27]
Journal of Artificial Intelligence Research , volume=
A survey on data selection for llm instruction tuning , author=. Journal of Artificial Intelligence Research , volume=
-
[28]
can llms logically reason through counterfactuals? , author=
If pigs could fly... can llms logically reason through counterfactuals? , author=. arXiv preprint arXiv:2505.22318 , year=
-
[29]
arXiv preprint arXiv:2506.02126 , year=
Knowledge or reasoning? a close look at how llms think across domains , author=. arXiv preprint arXiv:2506.02126 , year=
-
[30]
Econometrica: journal of the Econometric Society , pages=
Root-N-consistent semiparametric regression , author=. Econometrica: journal of the Econometric Society , pages=. 1988 , publisher=
1988
-
[31]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Not All Correct Answers Are Equal: Why Your Distillation Source Matters , author=. 2025 , eprint=
2025
-
[33]
Proceedings of the 42nd International Conference on Machine Learning , articleno =
Li, Yuan and Liu, Zhengzhong and Xing, Eric , title =. Proceedings of the 42nd International Conference on Machine Learning , articleno =. 2025 , publisher =
2025
-
[34]
2023 , eprint=
Efficient Online Data Mixing For Language Model Pre-Training , author=. 2023 , eprint=
2023
-
[35]
and Ma, Tengyu and Yu, Adams Wei , title =
Xie, Sang Michael and Pham, Hieu and Dong, Xuanyi and Du, Nan and Liu, Hanxiao and Lu, Yifeng and Liang, Percy and Le, Quoc V. and Ma, Tengyu and Yu, Adams Wei , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[36]
International Conference on Machine Learning , pages=
Orthogonal random forest for causal inference , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[37]
Journal of the American Statistical Association , volume=
Estimation and inference of heterogeneous treatment effects using random forests , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
2018
-
[38]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[39]
Keith Battocchi and Eleanor Dillon and Maggie Hei and Greg Lewis and Paul Oka and Miruna Oprescu and Vasilis Syrgkanis , title=
-
[40]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[41]
Hartvigsen, Thomas and Gabriel, Saadia and Palangi, Hamid and Sap, Maarten and Ray, Dipankar and Kamar, Ece. T oxi G en: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.234
-
[42]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Generalizing Verifiable Instruction Following , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[43]
Instruction-Following Evaluation for Large Language Models
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[45]
Is Your Code Generated by Chat
Jiawei Liu and Chunqiu Steven Xia and Yuyao Wang and LINGMING ZHANG , booktitle=. Is Your Code Generated by Chat. 2023 , url=
2023
-
[46]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[47]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[48]
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong. O lympiad B ench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. Proceedings of the ...
-
[49]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[50]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[51]
Zhong, Wanjun and Cui, Ruixiang and Guo, Yiduo and Liang, Yaobo and Lu, Shuai and Wang, Yanlin and Saied, Amin and Chen, Weizhu and Duan, Nan. AGIE val: A Human-Centric Benchmark for Evaluating Foundation Models. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.149
-
[52]
Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt. DROP : A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[53]
Transactions on Machine Learning Research , issn=
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[54]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[55]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[56]
Second Conference on Language Modeling , year=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. Second Conference on Language Modeling , year=
-
[57]
Unified Data Selection for
Xiaoyuan Li and Yubo Ma and Chengpeng Li and Keqin Bao and Yiyao Yu and Wenjie Wang and Fuli Feng and Dayiheng Liu , year=. Unified Data Selection for
-
[58]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Wettig, Alexander and Gupta, Aatmik and Malik, Saumya and Chen, Danqi , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[59]
arXiv preprint arXiv:2503.00808 , year=
Predictive data selection: The data that predicts is the data that teaches , author=. arXiv preprint arXiv:2503.00808 , year=
-
[60]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[61]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[62]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[63]
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
2025 , url =
OpenDataArena , title =. 2025 , url =
2025
-
[65]
arXiv preprint arXiv:2512.14051 , year=
OpenDataArena: A Fair and Open Arena for Benchmarking Post-Training Dataset Value , author=. arXiv preprint arXiv:2512.14051 , year=
-
[66]
2025 , note =
OpenDataArena , title =. 2025 , note =
2025
-
[67]
Advances in Neural Information Processing Systems , editor=
Revisiting Neural Scaling Laws in Language and Vision , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[68]
The Thirteenth International Conference on Learning Representations , year=
Scaling Laws for Downstream Task Performance in Machine Translation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[69]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Are Emergent Abilities of Large Language Models a Mirage? , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[70]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[71]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
The Thirteenth International Conference on Learning Representations , year=
RegMix: Data Mixture as Regression for Language Model Pre-training , author=. The Thirteenth International Conference on Learning Representations , year=
-
[73]
Journal of the American statistical Association , volume=
Causal inference using potential outcomes: Design, modeling, decisions , author=. Journal of the American statistical Association , volume=. 2005 , publisher=
2005
-
[74]
2015 , publisher=
Causal inference in statistics, social, and biomedical sciences , author=. 2015 , publisher=
2015
-
[75]
International Conference on Machine Learning , pages=
DOGE: Domain Reweighting with Generalization Estimation , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[76]
The Thirteenth International Conference on Learning Representations , year=
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance , author=. The Thirteenth International Conference on Learning Representations , year=
-
[77]
The Thirteenth International Conference on Learning Representations , year=
Aioli: A Unified Optimization Framework for Language Model Data Mixing , author=. The Thirteenth International Conference on Learning Representations , year=
-
[78]
SMART : Submodular Data Mixture Strategy for Instruction Tuning
Renduchintala, H S V N S Kowndinya and Bhatia, Sumit and Ramakrishnan, Ganesh. SMART : Submodular Data Mixture Strategy for Instruction Tuning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.766
-
[79]
Forty-second International Conference on Machine Learning , year=
Data Mixing Optimization for Supervised Fine-Tuning of Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[80]
2026 , url=
Chenlin Ming and Chendi Qu and Qizhi Pei and Zhuoshi Pan and Yu Li and Xiaoming Duan and Lijun Wu and Conghui He , booktitle=. 2026 , url=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.