Log_bQuant: Quantizing Language Models in Logarithmic Space
Pith reviewed 2026-07-02 12:34 UTC · model grok-4.3
The pith
Logarithmic quantization with an adjustable base outperforms asymmetric linear quantization for 4-bit language model weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Log_b Quant maps each weight through a logarithm whose base can be tuned per tensor, then rounds the result to a small set of discrete levels that are later exponentiated back to the original scale. When applied at 4 bits this representation preserves accuracy better than asymmetric linear quantization performed at the same tensor granularity.
What carries the argument
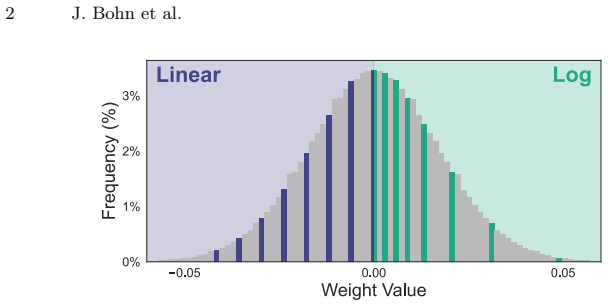
Adjustable-base logarithmic quantization, which discretizes log_b(|w|) into a fixed number of bins before restoring sign and magnitude.
If this is right
- Higher downstream task accuracy at 4-bit precision than tensor-wise asymmetric linear quantization.
- Substantial reduction in model memory footprint.
- Moderate improvement in inference speed on consumer GPUs.
- Practical deployment of larger models on hardware without high-bandwidth memory or specialized accelerators.
Where Pith is reading between the lines
- The per-tensor choice of base may be the main source of the reported gain; fixing the base across a model would likely reduce the advantage.
- The same log-space discretization could be tested on convolutional or recurrent networks whose weight statistics differ from transformers.
- Making the base itself a learned parameter rather than a hyper-parameter search result would remove a manual tuning step.
Load-bearing premise
Common weight distributions in the tested language models are better matched by an adjustable logarithmic scale than by asymmetric linear quantization applied at tensor level.
What would settle it
A controlled comparison on a model whose weights follow a distribution for which the linear method already achieves equal or higher benchmark scores at 4 bits.
Figures
read the original abstract
Quantization has become an invaluable tool to reduce memory requirements and inference speed of modern language models, in particular to make them available for consumer setups and edge devices. While previous work has primarily focused on uniform quantization codebooks, such approaches are prone to suboptimal representations due to low-frequency high-magnitude weights. We introduce Log$_\text{b}$Quant, a novel logarithmic quantization approach with adjustable bases, to adapt to common parameter distributions. We show that our method exhibits superior performance at 4-bit precision on several performance benchmarks compared to asymmetric linear quantization at tensor-wise granularity, while achieving moderate speedup and high memory savings, making it suitable for private use on consumer-grade GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Log_bQuant, a logarithmic quantization scheme for language-model weights that employs an adjustable base b to better match observed parameter distributions. The central empirical claim is that this approach yields higher benchmark performance than tensor-wise asymmetric linear quantization at 4-bit precision while delivering moderate inference speedup and substantial memory reduction.
Significance. If the reported gains are reproducible, the work is significant for practical LLM deployment on consumer hardware. The adjustable-base construction directly targets the known mismatch between uniform linear codebooks and the heavy-tailed weight distributions typical in transformers. The paper supplies a falsifiable, head-to-head comparison on standard benchmarks, which constitutes direct evidence for the motivating assumption.
minor comments (3)
- Abstract: the claim of 'superior performance on several performance benchmarks' would be strengthened by naming the specific models, datasets, and metrics (e.g., perplexity on WikiText-2, zero-shot accuracy on LAMBADA) rather than leaving them implicit.
- Notation: the definition of the adjustable base b and its optimization procedure should be stated explicitly in the main text (not only in an appendix) so that readers can reproduce the mapping without ambiguity.
- Figures/Tables: ensure that all reported speedups and memory savings include the precise hardware platform, batch size, and sequence length used for measurement.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive assessment of our work on Log_bQuant. The recommendation for minor revision is noted. No specific major comments were provided in the report, so we address the overall feedback below.
Circularity Check
No significant circularity
full rationale
The paper introduces Log_bQuant as an empirical quantization technique with adjustable bases and validates it via direct benchmark comparisons against asymmetric linear quantization. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing steps appear in the abstract or described construction. The central claim rests on experimental outcomes that are independently falsifiable against external benchmarks rather than reducing to self-definition or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
free parameters (1)
- adjustable base b
Reference graph
Works this paper leans on
-
[1]
Ansel, J., Yang, E., He, H., Gimelshein, N., Jain, A., Voznesensky, M., Bao, B., Bell, P., Berard, D., Burovski, E., Chauhan, G., Chourdia, A., Constable, W., Des- maison, A., DeVito, Z., Ellison, E., Feng, W., Gong, J., Gschwind, M., Hirsh, B., Huang, S., Kalambarkar, K., Kirsch, L., Lazos, M., Lezcano, M., Liang, Y., Liang, J., Lu, Y., Luk, C.K., Maher,...
-
[2]
Berger, C.: Linear and logarithmic quantization approaches for efficient inference with deep neural networks. Tech. rep., Technical University Munich, Chair of Data Processing, Munich, Germany (2022) 10 J. Bohn et al
2022
-
[3]
Bisk, Y., Zellers, R., Bras, R.L., Gao, J., Choi, Y.: Piqa: Reasoning about physical commonsense in natural language (2019), https://arxiv.org/abs/1911.11641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
In: Findings of the Association for Computational Linguistics: NAACL
Bohn, J., Mrozinski, F., Groh, G.: Adaptive parameter compression for language models. In: Findings of the Association for Computational Linguistics: NAACL
-
[5]
7269–7286 (2025)
pp. 7269–7286 (2025)
2025
- [6]
-
[7]
IEEE Security & Privacy 2023
Brüggemann, A., Hundt, R., Schneider, T., Suresh, A., Yalame, H.: FLUTE: Fast and secure lookup table evaluations (full version), https://eprint.iacr.org/2023/499, publication info: Published elsewhere. IEEE Security & Privacy 2023
2023
-
[8]
In: Proceedings of the 10th International Conference on Advances in Information Technology (IAIT)
Cai, J., Takemoto, M., Nakajo, H.: A deep look into logarithmic quantization of model parameters in neural networks. In: Proceedings of the 10th International Conference on Advances in Information Technology (IAIT). pp. 1–8. ACM (2018)
2018
-
[9]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10558–10578 (2024)
Cheng, H., Zhang, M., Shi, J.Q.: A survey on deep neural network pruning: Taxon- omy, comparison, analysis, and recommendations. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10558–10578 (2024)
2024
-
[10]
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., Tafjord, O.: Think you have solved question answering? try arc, the ai2 reasoning challenge (2018), https://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Dettmers, T., Lewis, M., Belkada, Y., Zettlemoyer, L.: LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (2022), https://arxiv.org/abs/2208.07339
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Frantar, E., Ashkboos, S., Hoefler, T., Alistarh, D.: Gptq: Accurate post-training quantization for generative pre-trained transformers (2023), https://arxiv.org/abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
doi:10.5281/zenodo.12608602 , url =
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Gold- ing, L., Hsu, J., Le Noac’h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang,J.,Reynolds,L.,Schoelkopf,H.,Skowron,A.,Sutawika,L.,Tang,E.,Thite, A.,Wang,B.,Wang,K.,Zou,A.:Thelanguagemodelevaluationharness(072024). https://doi.org/10.5281/zenodo.12608602, https...
-
[14]
In: 2025 Design, Automation & Test in Europe Conference (DATE)
Geng, X., Liu, S., Wang, H., Han, J., Jiang, H.: Lookup table refactoring: To- wards efficient logarithmic number system addition for large language models. In: 2025 Design, Automation & Test in Europe Conference (DATE). pp. 1–7 (2025). https://doi.org/10.23919/DATE64628.2025.10993215
-
[15]
https://doi.org/10.48550/arXiv.2103.13630, http://arxiv.org/abs/2103.13630
Gholami, A., Kim, S., Dong, Z., Yao, Z., Mahoney, M.W., Keutzer, K.: A survey of quantization methods for efficient neural network inference. https://doi.org/10.48550/arXiv.2103.13630, http://arxiv.org/abs/2103.13630
-
[16]
Gholami, A., Yao, Z., Kim, S., Hooper, C., Mahoney, M.W., Keutzer, K.: AI and memory wall. IEEE Micro44(3), 33–39 (2024). https://doi.org/10.1109/MM.2024.3373763
-
[17]
https://doi.org/10.48550/arXiv.1908.05033, http://arxiv.org/abs/1908.05033
Gong, R., Liu, X., Jiang, S., Li, T., Hu, P., Lin, J., Yu, F., Yan, J.: Differ- entiable soft quantization: Bridging full-precision and low-bit neural networks. https://doi.org/10.48550/arXiv.1908.05033, http://arxiv.org/abs/1908.05033
-
[18]
Grattafiori, A., et al.: The Llama 3 Herd of Models (2024), https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
In: Advances in Neural Information Processing Systems
Han, S., Pool, J., Tran, J., Dally, W.J.: Learning both weights and connections for efficient neural networks. In: Advances in Neural Information Processing Systems. vol. 28 (2015) LogbQuant: Quantizing Language Models in Logarithmic Space 11
2015
-
[20]
In: Advances in Neural Information Processing Systems
Hassibi, B., Stork, D.G.: Second order derivatives for network pruning: Optimal Brain Surgeon. In: Advances in Neural Information Processing Systems. vol. 5, pp. 164–171. Morgan Kaufmann (1992)
1992
-
[21]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding (2021), https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Hsu,Y.C.,Hua,T.,Chang,S.,Lou,Q.,Shen,Y.,Jin,H.:Languagemodelcompres- sionwithweightedlow-rankfactorization.In:InternationalConferenceonLearning Representations (2022)
2022
-
[23]
Advances in neural infor- mation processing systems2(1989)
LeCun, Y., Denker, J., Solla, S.: Optimal brain damage. Advances in neural infor- mation processing systems2(1989)
1989
-
[24]
In: International Conference on Machine Learning
Li, Y., Yin, R., Lee, D., Xiao, S., Panda, P.: GPTAQ: Efficient finetuning-free quantization for asymmetric calibration. In: International Conference on Machine Learning. pp. 36690–36706. PMLR (2025)
2025
-
[25]
In: In- ternational Conference on Learning Representations
Lin, C.H., Gao, S., Smith, J., Patel, A., Tuli, S., Shen, Y., Jin, H., Hsu, Y.C.: MoDeGPT: Modular decomposition for large language model compression. In: In- ternational Conference on Learning Representations. vol. 2025, pp. 101355–101390 (2025)
2025
-
[26]
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.M., Wang, W.C., Xiao, G., Dang, X., Gan, C., Han, S.: Awq: Activation-aware weight quantization for llm compression and acceleration (2024), https://arxiv.org/abs/2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Advances in Neural Information Processing Systems37, 107112–107137 (2024)
Ling, G., Wang, Z., Yan, Y., Liu, Q.: SlimGPT: Layer-wise structured pruning for large language models. Advances in Neural Information Processing Systems37, 107112–107137 (2024)
2024
-
[28]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Liu, Y., Wen, J., Wang, Y., Ye, S., Zhang, L.L., Cao, T., Li, C., Yang, M.: VPTQ: Extreme low-bit vector post-training quantization for large language models. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 8181–8196 (2024)
2024
-
[29]
Advances in neural information processing systems36, 21702–21720 (2023)
Ma, X., Fang, G., Wang, X.: Llm-pruner: On the structural pruning of large lan- guage models. Advances in neural information processing systems36, 21702–21720 (2023)
2023
-
[30]
Computational Linguistics19(2), 313–330 (1993)
Marcus, M.P., Santorini, B., Marcinkiewicz, M.A.: Building a large annotated corpus of english: The penn treebank. Computational Linguistics19(2), 313–330 (1993)
1993
-
[31]
Merity, S., Xiong, C., Bradbury, J., Socher, R.: Pointer sentinel mixture models (2016), https://arxiv.org/abs/1609.07843
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Micikevicius, P., Stosic, D., Burgess, N., Cornea, M., Dubey, P., Grisenthwaite, R., Ha, S., Heinecke, A., Judd, P., Kamalu, J., et al.: FP8 formats for deep learning. arXiv preprint arXiv:2209.05433 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Convolutional Neural Networks using Logarithmic Data Representation
Miyashita, D., Lee, E.H., Murmann, B.: Convolutional neural networks using log- arithmic data representation. arXiv preprint arXiv:1603.01025 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
In: Proceedings of the IEEE/CVF international conference on computer vision
Nagel, M., Baalen, M.v., Blankevoort, T., Welling, M.: Data-free quantization through weight equalization and bias correction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1325–1334 (2019)
2019
-
[35]
https://doi.org/10.48550/arXiv.2505.13496, http://arxiv.org/abs/2505.13496
Pospieszny, P., Mormul, W., Szyndler, K., Kumar, S.: ADALog: Adaptive unsu- pervised anomaly detection in logs with self-attention masked language model. https://doi.org/10.48550/arXiv.2505.13496, http://arxiv.org/abs/2505.13496
-
[36]
https://doi.org/10.48550/arXiv.2203.05025, http://arxiv.org/abs/2203.05025 12 J
Przewlocka-Rus, D., Sarwar, S.S., Sumbul, H.E., Li, Y., Salvo, B.D.: Power- of-two quantization for low bitwidth and hardware compliant neural networks. https://doi.org/10.48550/arXiv.2203.05025, http://arxiv.org/abs/2203.05025 12 J. Bohn et al
-
[37]
Journal of Machine Learning Research21, 140:1–140:67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research21, 140:1–140:67 (2020)
2020
-
[38]
GLU Variants Improve Transformer
Shazeer, N.: GLU variants improve transformer. arXiv preprint arXiv:2002.05202 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[39]
In: International Conference on Learning Representations
Sun, M., Liu, Z., Bair, A., Kolter, Z.: A simple and effective pruning approach for large language models. In: International Conference on Learning Representations. vol. 2024, pp. 4942–4964 (2024)
2024
-
[40]
In: Proceedings of the International Conference on Computer- Aided Design
Vogel, S., Liang, M., Guntoro, A., Stechele, W., Ascheid, G.: Efficient hard- ware acceleration of CNNs using logarithmic data representation with arbi- trary log-base. In: Proceedings of the International Conference on Computer- Aided Design. pp. 1–8. ACM (2018). https://doi.org/10.1145/3240765.3240803, https://dl.acm.org/doi/10.1145/3240765.3240803
-
[41]
text" denotes the sentences to be embedded. PromptEOL Qwen Summarize the sentence:
Weber, M., Fu, D., Anthony, Q., Oren, Y., Adams, S., Alexandrov, A., Lyu, X., Nguyen, H., Yao, X., Adams, V., Athiwaratkun, B., Chala- mala, R., Chen, K., Ryabinin, M., Dao, T., Liang, P., Ré, C., Rish, I., Zhang, C.: RedPajama: an open dataset for training large language models. https://doi.org/10.48550/arXiv.2411.12372, http://arxiv.org/abs/2411.12372
-
[42]
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cis- tac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Le Scao, T., Gugger, S., Drame, M., Lhoest, Q., Rush, A.: Transformers: State-of-the-art natu- ral language processing. In: Liu, Q., Schlangen, D. (eds.) Proc...
- [43]
-
[44]
Yang,A.,etal.:Qwen3TechnicalReport(2025),https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Understanding straight-through estimator in training ac- tivation quantized neural nets
Yin, P., Lyu, J., Zhang, S., Osher, S., Qi, Y., Xin, J.: Understanding straight- through estimator in training activation quantized neural nets. arXiv preprint arXiv:1903.05662 (2019)
-
[46]
Zandieh, A., Daliri, M., Hadian, M., Mirrokni, V.: TurboQuant: Online vector quantization with near-optimal distortion rate. arXiv preprint arXiv:2504.19874 (2025) A Additional Tables LogbQuant: Quantizing Language Models in Logarithmic Space 13 T able 5.Accuracy (↑) on MMLU and normalized accuracy (↑) on ARC-C and PIQA, respectively. Reported values are ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.