Measuring the Gap Between Human and LLM Research Ideas
Pith reviewed 2026-07-02 12:20 UTC · model grok-4.3
The pith
LLM-generated research ideas cluster around bridge-like opportunities and synthesis methods while human ideas spread more broadly across framing and contribution styles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
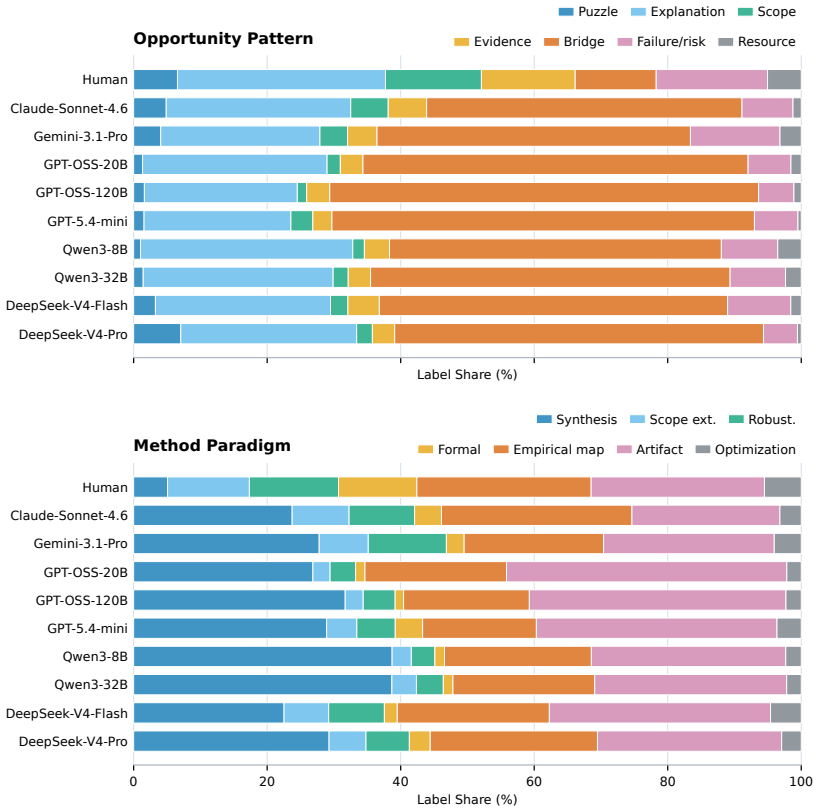
By reverse-engineering a small set of prior works for each human paper and prompting LLMs to generate a new idea from the titles and summaries, then classifying all ideas with the two-axis research-taste taxonomy, the study finds that LLM ideas are disproportionately concentrated around bridge-like opportunities and synthesis methods, whereas the human paper reference distribution spreads more broadly across ways of framing gaps and constructing contributions.
What carries the argument
The two-axis research-taste taxonomy that classifies each idea by its opportunity pattern and research paradigm.
If this is right
- LLMs can produce a range of reasonable research ideas from the same inputs used for human papers.
- The range of ideas produced by LLMs remains narrower than the spread observed in human research.
- The concentration pattern appears consistently across different LLMs.
- LLM ideas are systematically shifted relative to human research taste in the dimensions measured by the taxonomy.
Where Pith is reading between the lines
- If the observed concentration arises from patterns in training data, then additional fine-tuning on diverse human idea examples could broaden LLM outputs.
- The framework supplies a concrete way to test whether changes in prompting or model scale reduce the measured gap.
- Human researchers who incorporate LLM suggestions may still need to supply the broader framing approaches that the models under-produce.
Load-bearing premise
The small set of reverse-engineered prior works accurately represents the actual inspirational sources for each human paper's core idea, and the taxonomy captures stable differences in research taste.
What would settle it
Re-running the same reverse-engineering and taxonomy process on a new, larger collection of human papers yields no measurable distributional difference between the human reference ideas and the LLM-generated ideas.
Figures






read the original abstract
LLMs are increasingly used to brainstorm research ideas, but existing evaluations mostly judge individual ideas by novelty, feasibility, or expert preference. We instead ask: how far are current LLM-generated ideas from human researchers? To characterize this gap, we build a large-scale evaluation framework for ideation from high-quality human research papers. For each paper, we reverse-engineer a small set of closely related prior works that likely inspired its core idea. LLMs are then prompted to generate a new idea from the set of paper titles and summaries. We introduce a two-axis research-taste taxonomy to profile each idea by its opportunity pattern and research paradigm, and use it to quantify the divergence between human and LLM ideas. Across idea sets generated by different LLMs, we observe a consistent distributional gap: LLM ideas are disproportionately concentrated around bridge-like opportunities and synthesis methods, whereas the human paper reference distribution spreads more broadly across ways of framing gaps and constructing contributions. This result suggests that strong LLMs can produce a range of reasonable ideas, but that range remains narrower than, and systematically shifted relative to, human research taste.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework to quantify the gap between human and LLM research ideas: for each high-quality human paper, a small set of closely related prior works is reverse-engineered; LLMs are prompted to generate new ideas from those priors; and both human and LLM ideas are profiled using a newly defined two-axis taxonomy (opportunity pattern and research paradigm). The central empirical result is a consistent distributional gap across multiple LLMs: LLM ideas concentrate on bridge-like opportunities and synthesis methods, while the human reference distribution is broader across gap-framing and contribution styles.
Significance. If the taxonomy faithfully captures stable differences in research taste independent of the specific papers and the reverse-engineered priors are representative, the work supplies a quantitative, reproducible characterization of how current LLM ideation remains narrower and systematically shifted relative to human research practices. The consistency of the gap across LLMs is a strength that could inform targeted improvements in LLM research assistants.
major comments (2)
- [§3] §3 (two-axis taxonomy): the taxonomy is introduced by the authors without reported inter-annotator agreement, external validation, or sensitivity analysis to category boundary choices. Because the distributional-gap claim is obtained by binning ideas into these author-defined categories, the absence of validation metrics means the observed concentration of LLM ideas could be produced by the delineation of the axes rather than by a genuine difference in idea generation.
- [§2.2] §2.2 (reverse-engineering of prior works): the human reference distribution and the LLM prompts both rest on a small set of reverse-engineered priors whose selection rules and fidelity to actual inspirational sources are not validated or subjected to sensitivity checks. Any systematic bias in this reconstruction would affect both sides of the comparison and undermine the gap measurement.
minor comments (1)
- [Results] Results section: the abstract states a 'consistent distributional gap' across LLMs but does not report the exact number of papers, LLMs, or statistical tests used to establish consistency; these details should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the taxonomy and reverse-engineering procedure. We address each point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (two-axis taxonomy): the taxonomy is introduced by the authors without reported inter-annotator agreement, external validation, or sensitivity analysis to category boundary choices. Because the distributional-gap claim is obtained by binning ideas into these author-defined categories, the absence of validation metrics means the observed concentration of LLM ideas could be produced by the delineation of the axes rather than by a genuine difference in idea generation.
Authors: We agree that the absence of reported inter-annotator agreement and sensitivity analysis is a limitation. The taxonomy was developed through iterative author discussion to capture stable dimensions of opportunity framing and contribution style. In the revision we will add (i) inter-annotator agreement statistics on a held-out sample of ideas and (ii) a sensitivity analysis that perturbs category boundaries and re-computes the distributional gap. These additions will directly test whether the observed LLM concentration is robust to reasonable boundary choices. revision: yes
-
Referee: [§2.2] §2.2 (reverse-engineering of prior works): the human reference distribution and the LLM prompts both rest on a small set of reverse-engineered priors whose selection rules and fidelity to actual inspirational sources are not validated or subjected to sensitivity checks. Any systematic bias in this reconstruction would affect both sides of the comparison and undermine the gap measurement.
Authors: The priors were selected by close reading to recover works that directly precede and motivate the core contribution of each human paper. We acknowledge that formal validation and sensitivity checks were not reported. Because the identical prior sets are supplied to both the human reference distribution and the LLM prompts, any reconstruction bias would need to interact differently with LLM versus human ideation to explain the gap; the consistency of the gap across multiple LLMs makes such an interaction less plausible. Nevertheless, the revision will include a sensitivity experiment that substitutes alternative prior sets for a subset of papers and verifies persistence of the distributional difference. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs a human reference distribution by reverse-engineering priors from existing papers and generates LLM ideas from those same inputs, then classifies both sets using a newly introduced two-axis taxonomy to observe distributional differences. This process does not reduce any central claim to its inputs by construction: the taxonomy is applied uniformly as a measurement tool rather than being defined in terms of the observed gap, no fitted parameters are renamed as predictions, and no self-citation chain or uniqueness theorem is invoked to force the result. The derivation remains self-contained, relying on external human papers as an independent benchmark.
Axiom & Free-Parameter Ledger
free parameters (2)
- Size of prior-work set per paper
- Taxonomy category definitions
axioms (2)
- domain assumption Reverse-engineered prior works accurately represent the inspirational sources for each human paper's core idea.
- domain assumption The two-axis taxonomy captures meaningful and stable differences in research taste.
invented entities (1)
-
Two-axis research-taste taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Learning Representations, volume 2025, pages 94003--94092, 2025 a . URL https://proceedings.iclr.cc/paper_files/paper/2025/file/ea...
2025
-
[2]
ResearchAgent : Iterative research idea generation over scientific literature with large language models
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. ResearchAgent : Iterative research idea generation over scientific literature with large language models. In Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 6709--6738, 2025
2025
-
[3]
The ideation-execution gap: Execution outcomes of llm-generated versus human research ideas
Chenglei Si, Tatsunori Hashimoto, and Diyi Yang. The ideation-execution gap: Execution outcomes of llm-generated versus human research ideas. arXiv preprint arXiv:2506.20803, 2025 b
-
[4]
Autonomous chemical research with large language models
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models. Nature, 624 0 (7992): 0 570--578, 2023
2023
-
[5]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https://arxiv.org/abs/2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
A comprehensive survey of scientific large language models and their applications in scientific discovery
Yu Zhang, Xiusi Chen, Bowen Jin, Sheng Wang, Shuiwang Ji, Wei Wang, and Jiawei Han. A comprehensive survey of scientific large language models and their applications in scientific discovery. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8783--8817, 2024
2024
-
[7]
Yilun Zhao, Weiyuan Chen, Zhijian Xu, Manasi Patwardhan, Chengye Wang, Yixin Liu, Lovekesh Vig, and Arman Cohan. A b G en: Evaluating large language models in ablation study design and evaluation for scientific research. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the A...
-
[8]
H yp ER : Literature-grounded hypothesis generation and distillation with provenance
Rosni Vasu, Chandrayee Basu, Bhavana Dalvi Mishra, Cristina Sarasua, Peter Clark, and Abraham Bernstein. H yp ER : Literature-grounded hypothesis generation and distillation with provenance. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Languag...
-
[9]
Sciarena: An open evaluation platform for non-verifiable scientific literature-grounded tasks
Yilun Zhao, Kaiyan Zhang, Tiansheng Hu, Sihong Wu, Ronan Le Bras, Yixin Liu, Xiangru Tang, Joseph Chee Chang, Jesse Dodge, Jonathan Bragg, Chen Zhao, Hannaneh Hajishirzi, Doug Downey, and Arman Cohan. Sciarena: An open evaluation platform for non-verifiable scientific literature-grounded tasks. In The Thirty-ninth Annual Conference on Neural Information P...
2026
-
[10]
R bt A ct: Rebuttal as supervision for actionable review feedback generation
Sihong Wu, Yiling Ma, Yilun Zhao, Tiansheng Hu, Owen Jiang, Manasi Patwardhan, and Arman Cohan. R bt A ct: Rebuttal as supervision for actionable review feedback generation. In Maria Liakata, Viviane P. Moreira, Jiajun Zhang, and David Jurgens, editors, Findings of the A ssociation for C omputational L inguistics: ACL 2026 , pages 33965--33992, San Diego,...
2026
-
[11]
IRIS : Interactive research ideation system for accelerating scientific discovery
Aniketh Garikaparthi, Manasi Patwardhan, Lovekesh Vig, and Arman Cohan. IRIS : Interactive research ideation system for accelerating scientific discovery. In Proceedings of ACL -- System Demonstrations, pages 592--603, July 2025
2025
-
[12]
Ai can learn scientific taste, 2026
Jingqi Tong, Mingzhe Li, Hangcheng Li, Yongzhuo Yang, Yurong Mou, Weijie Ma, Zhiheng Xi, Hongji Chen, Xiaoran Liu, Qinyuan Cheng, Ming Zhang, Qiguang Chen, Weifeng Ge, Qipeng Guo, Tianlei Ying, Tianxiang Sun, Yining Zheng, Xinchi Chen, Jun Zhao, Ning Ding, Xuanjing Huang, Yugang Jiang, and Xipeng Qiu. Ai can learn scientific taste, 2026. URL https://arxiv...
-
[13]
Prompting diverse ideas: Increasing ai idea variance
Lennart Meincke, Ethan R Mollick, and Christian Terwiesch. Prompting diverse ideas: Increasing ai idea variance. arXiv preprint arXiv:2402.01727, 2024
-
[14]
A comprehensive analysis of large language model outputs: Similarity, diversity, and bias
Brandon Smith, Mohamed Reda Bouadjenek, Tahsin Alamgir Kheya, Phillip Dawson, and Sunil Aryal. A comprehensive analysis of large language model outputs: Similarity, diversity, and bias. arXiv preprint arXiv:2505.09056, 2025
-
[15]
The homogenizing effect of large language models on human expression and thought
Zhivar Sourati, Alireza S Ziabari, and Morteza Dehghani. The homogenizing effect of large language models on human expression and thought. Trends in Cognitive Sciences, 2026
2026
-
[16]
SciMON : Scientific inspiration machines optimized for novelty
Qingyun Wang, Doug Downey, Heng Ji, and Tom Hope. SciMON : Scientific inspiration machines optimized for novelty. In Annual Meeting of the Association for Computational Linguistics, pages 279--299, 2024
2024
-
[17]
Spark : A system for scientifically creative idea generation
Aishik Sanyal, Samuel Schapiro, Sumuk Shashidhar, Royce Moon, Lav R Varshney, and Dilek Hakkani-Tur. Spark : A system for scientifically creative idea generation. In International Conference on Computational Creativity, 2025
2025
- [18]
-
[19]
Xiang Hu, Hongyu Fu, Jinge Wang, Yifeng Wang, Zhikun Li, Renjun Xu, Yu Lu, Yaochu Jin, Lili Pan, and Zhenzhong Lan. Nova: An iterative planning and search approach to enhance novelty and diversity of LLM generated ideas. arXiv preprint arXiv:2410.14255, 2024
-
[20]
Kevin Pu, K. J. Kevin Feng, Tovi Grossman, Tom Hope, Bhavana Dalvi Mishra, Matt Latzke, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue. IdeaSynth : Iterative research idea development through evolving and composing idea facets with literature-grounded feedback. In CHI Conference on Human Factors in Computing Systems, pages 1--31, 2025
2025
-
[21]
Tianyang Gu, Jingjin Wang, Zhihao Zhang, and Haohong Li. LLMs can realize combinatorial creativity: Generating creative ideas via LLMs for scientific research. arXiv preprint arXiv:2412.14141, 2024
-
[22]
Many heads are better than one: Improved scientific idea generation by a LLM -based multi-agent system
Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, Philip Torr, Bowen Zhou, and Nanqing Dong. Many heads are better than one: Improved scientific idea generation by a LLM -based multi-agent system. In Annual Meeting of the Association for Computational Linguistics, pages 28201--28240, 2025
2025
-
[23]
Kai Ruan, Xuan Wang, Jixiang Hong, Peng Wang, Yang Liu, and Hao Sun. Evaluating llms' divergent thinking capabilities for scientific idea generation with minimal context, 2026. URL https://arxiv.org/abs/2412.17596
-
[24]
IdeaBench : Benchmarking large language models for research idea generation
Sikun Guo, Amir Hassan Shariatmadari, Guangzhi Xiong, Albert Huang, Myles Kim, Corey M Williams, Stefan Bekiranov, and Aidong Zhang. IdeaBench : Benchmarking large language models for research idea generation. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5888--5899, 2025 a
2025
-
[25]
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Yujie Liu, Zonglin Yang, Tong Xie, Jinjie Ni, Ben Gao, Yuqiang Li, Shixiang Tang, Wanli Ouyang, Erik Cambria, and Dongzhan Zhou. Researchbench: Benchmarking llms in scientific discovery via inspiration-based task decomposition, 2026. URL https://arxiv.org/abs/2503.21248
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
GLTR : Statistical detection and visualization of generated text
Sebastian Gehrmann, Hendrik Strobelt, and Alexander Rush. GLTR : Statistical detection and visualization of generated text. In Marta R. Costa-juss \`a and Enrique Alfonseca, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 111--116, Florence, Italy, July 2019. Association for Co...
-
[27]
Automatic detection of generated text is easiest when humans are fooled
Daphne Ippolito, Daniel Duckworth, Chris Callison-Burch, and Douglas Eck. Automatic detection of generated text is easiest when humans are fooled. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 1808--1822, 2020
2020
-
[28]
D etect GPT : Zero-shot machine-generated text detection using probability curvature
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. D etect GPT : Zero-shot machine-generated text detection using probability curvature. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learni...
2023
-
[29]
Mauve: Measuring the gap between neural text and human text using divergence frontiers
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. Mauve: Measuring the gap between neural text and human text using divergence frontiers. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, page...
2021
-
[30]
Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv preprint arXiv:2301.07597, 2023
-
[31]
Using large language models to simulate multiple humans and replicate human subject studies
Gati V Aher, Rosa I Arriaga, and Adam Tauman Kalai. Using large language models to simulate multiple humans and replicate human subject studies. In International conference on machine learning, pages 337--371. PMLR, 2023
2023
-
[32]
Whose opinions do language models reflect? In International conference on machine learning, pages 29971--30004
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. Whose opinions do language models reflect? In International conference on machine learning, pages 29971--30004. PMLR, 2023
2023
-
[33]
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, Desmond Elliott, Raquel Fern \'a ndez, Albert Gatt, Esam Ghaleb, Mario Giulianelli, Michael Hanna, Alexander Koller, Andre Martins, Philipp Mondorf, Vera Neplenbroek, Sandro Pezzelle, Barbara Plank, David Schlangen, Alessandro Suglia, Aditya K Surikuchi, Ece Takmaz, and Alberto Testoni. LLM s instea...
-
[34]
Mind the blind spots: A focus-level evaluation framework for LLM reviews
Hyungyu Shin, Jingyu Tang, Yoonjoo Lee, Nayoung Kim, Hyunseung Lim, Ji Yong Cho, Hwajung Hong, Moontae Lee, and Juho Kim. Mind the blind spots: A focus-level evaluation framework for LLM reviews. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural La...
-
[35]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36: 0 46595--46623, 2023
2023
-
[36]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 2511--2522, 2023
2023
-
[37]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jay Shin, yejin cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, S Shin, Ryan, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors, International Conference on Learning Representations, vo...
-
[38]
A coefficient of agreement for nominal scales
Jacob Cohen. A coefficient of agreement for nominal scales. Educational and psychological measurement, 20 0 (1): 0 37--46, 1960
1960
-
[39]
Introducing Claude Sonnet 4.6 , Feb 2026
Anthropic. Introducing Claude Sonnet 4.6 , Feb 2026. URL https://www.anthropic.com/news/claude-sonnet-4-6
2026
-
[40]
Gemini 3.1 Pro: A smarter model for your most complex tasks , Feb 2026
Google. Gemini 3.1 Pro: A smarter model for your most complex tasks , Feb 2026. URL https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/
2026
-
[41]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025. URL https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Introducing GPT‑5.4 , Mar 2026
OpenAI. Introducing GPT‑5.4 , Mar 2026. URL https://openai.com/index/introducing-gpt-5-4/
2026
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[45]
Divergence measures based on the shannon entropy
Jianhua Lin. Divergence measures based on the shannon entropy. IEEE Transactions on Information theory, 37 0 (1): 0 145--151, 1991
1991
-
[46]
Mehdi S. M. Sajjadi, Olivier Bachem, Mario Lucic, Olivier Bousquet, and Sylvain Gelly. Assessing generative models via precision and recall. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neur...
2018
-
[47]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35: 0 22199--22213, 2022
2022
-
[48]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 0 24824--24837, 2022
2022
-
[49]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Web-scale k-means clustering
David Sculley. Web-scale k-means clustering. In Proceedings of the 19th international conference on World wide web, pages 1177--1178, 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.