eXact-Prior Variational Autoencoder (X-VAE): Learning Data-Adaptive Gaussian Mixture Priors for Latent Distributions
Pith reviewed 2026-07-03 21:40 UTC · model grok-4.3
The pith
X-VAE replaces the standard normal prior with a Gaussian prior whose mean and variance come from latent codes of a pretrained autoencoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
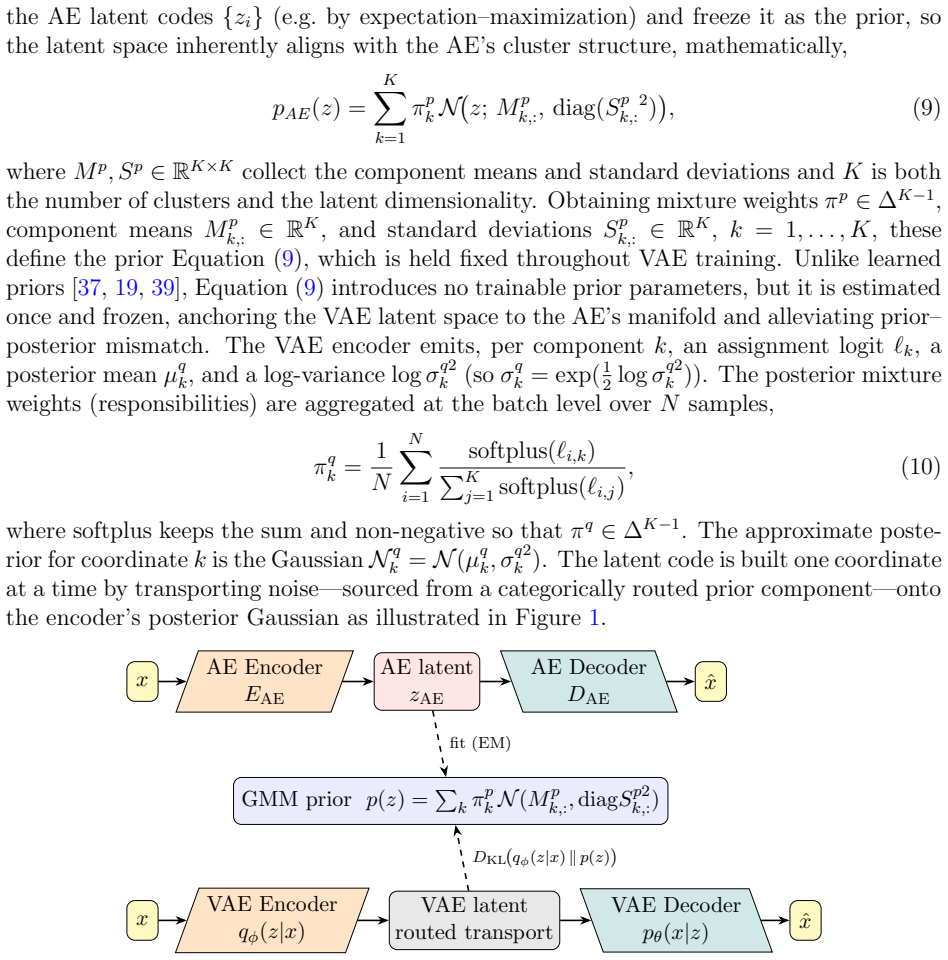
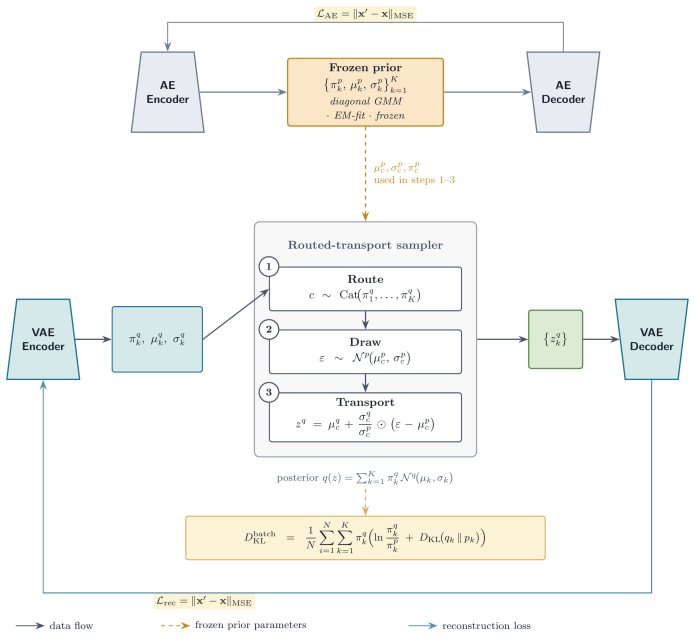
The central claim is that the empirical mean and standard deviation of latent codes from a separately pretrained autoencoder can be used to parameterize a Gaussian prior for a VAE, that the corresponding KL divergence term can be written in closed form, and that the resulting model produces latent representations that align more closely with the empirical data distribution while preserving reconstruction quality and allowing explicit variance control via a scaling factor.
What carries the argument
The data-adaptive Gaussian prior whose mean and standard deviation are set to the sample statistics of latent codes from a pretrained autoencoder.
If this is right
- X-VAE produces latent representations whose statistics more closely match the empirical distribution of the training data.
- Generated samples remain realistic while the latent scaling factor gives direct control over diversity versus fidelity.
- The method is presented as suitable for engineering design tasks that require both constraint satisfaction and exploration.
- The KL divergence objective for the new prior is derived without introducing additional fitting artifacts.
Where Pith is reading between the lines
- The two-stage training (AE then VAE) adds a preprocessing step whose cost might be offset if the same AE is reused across multiple VAE runs.
- Replacing only the first two moments leaves higher-order structure of the latent distribution unmodeled, so the approach may still underperform on data with strong multimodality.
- The scaling factor at generation time could be made learnable rather than fixed, turning it into an additional degree of freedom during inference.
Load-bearing premise
The empirical mean and standard deviation computed from the latent codes of a separately pretrained autoencoder form a suitable and stable prior for the subsequent VAE training.
What would settle it
Train both a standard VAE and an X-VAE on the same benchmark datasets and check whether the X-VAE version shows lower reconstruction error or visibly better sample fidelity; if it does not, or if the KL term causes training divergence, the central claim fails.
Figures


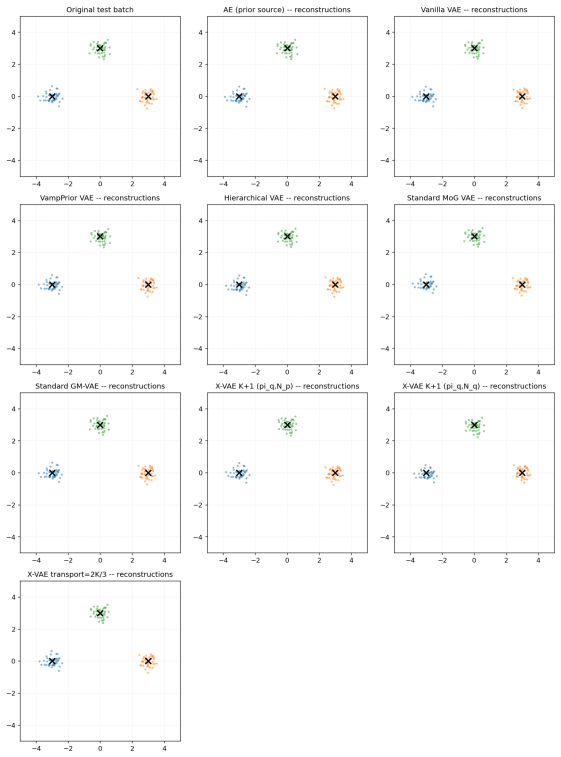
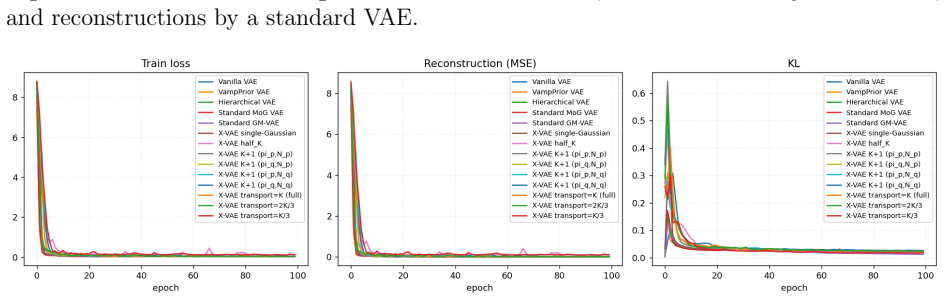


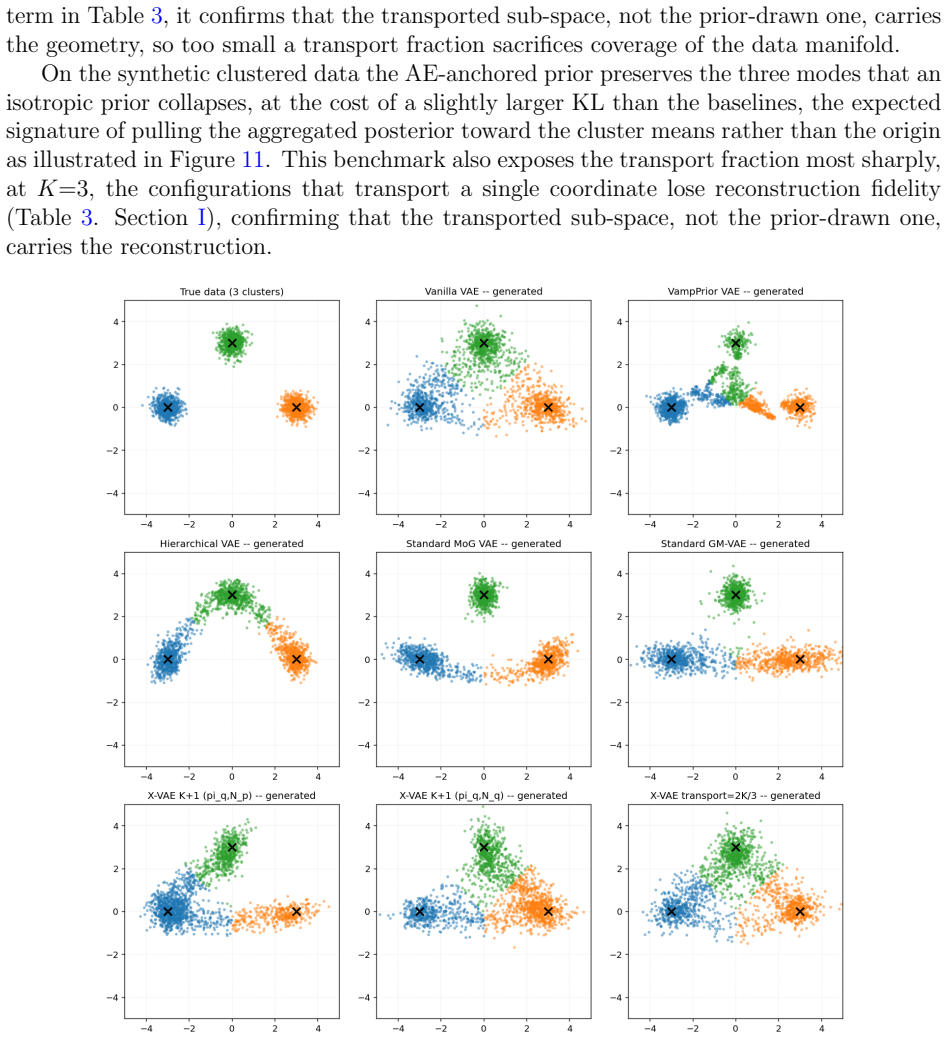


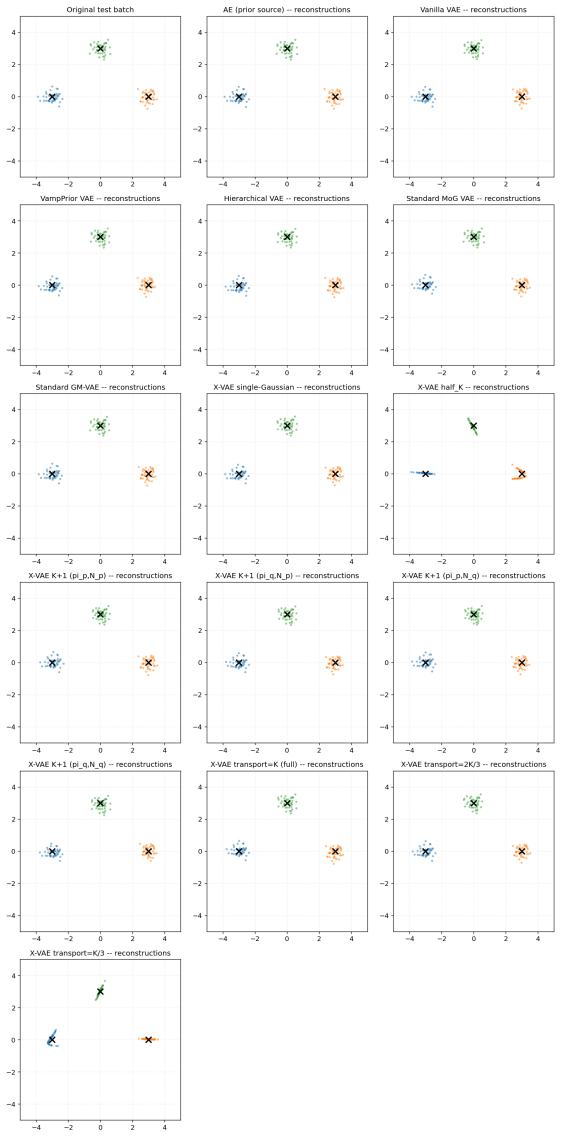


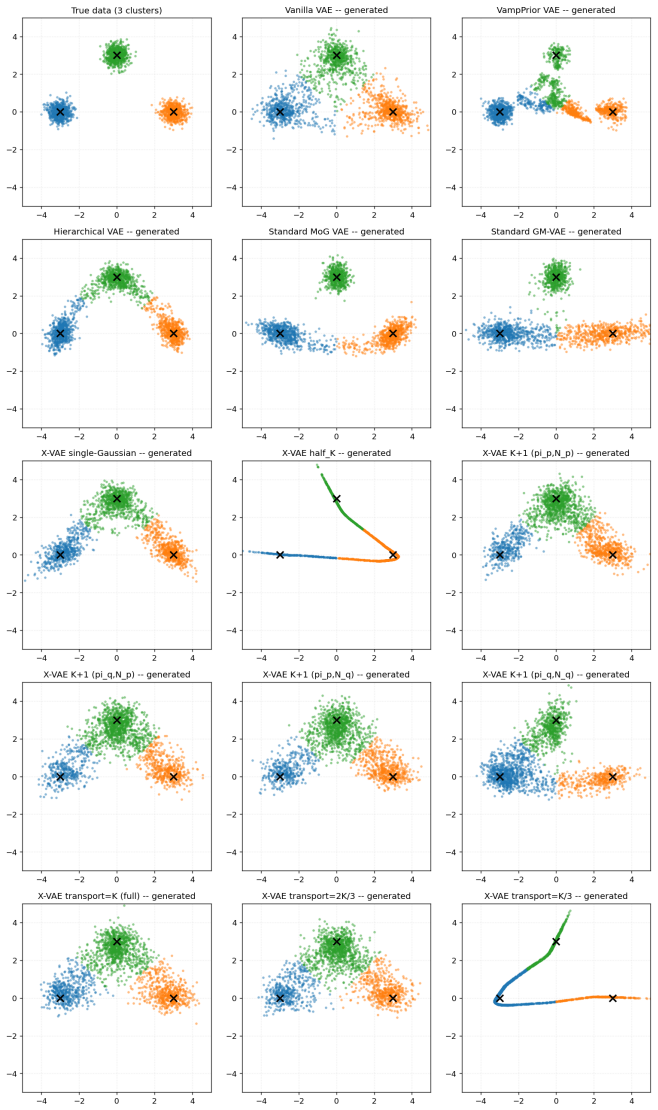
read the original abstract
Variational Autoencoders (VAEs) commonly assume a standard isotropic Gaussian prior over the latent space, an assumption that often fails to capture the true distribution of latent representations for complex datasets. This mismatch can limit reconstruction accuracy, reduce sample quality, and constrain the expressive power of the learned latent space. We propose the eXact-Prior Variational Autoencoder (X-VAE), a framework that replaces the conventional standard normal prior with a Gaussian prior derived from the latent representations of a pretrained autoencoder (AE). Specifically, the empirical mean and standard deviation of the AE latent codes are used to parameterize a data-adaptive prior that more closely reflects the underlying structure of the training data. During generation, X-VAE introduces a latent scaling factor that enables explicit control over the variance of the sampled latent vectors, providing a simple mechanism for balancing sample diversity and fidelity. This flexibility makes the proposed approach particularly well suited for applications such as industrial and engineering design, where generated solutions must satisfy strict structural or functional constraints while still permitting meaningful design exploration. We present the mathematical formulation of well-suited X-VAE, derive the corresponding KL divergence objective for the proposed prior, and evaluate the method on standard benchmark datasets. Experimental results demonstrate that X-VAE preserves reconstruction quality while producing latent representations that better align with the empirical data distribution, leading to improved controllability and more realistic generated samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the eXact-Prior Variational Autoencoder (X-VAE), which replaces the standard normal prior in VAEs with a data-adaptive Gaussian prior whose mean and standard deviation are computed from the latent codes of a separately pretrained deterministic autoencoder. The abstract states that the corresponding KL divergence is derived, a latent scaling factor is added for controllable generation, and experiments on benchmark datasets show preserved reconstruction quality with better alignment to the empirical latent distribution.
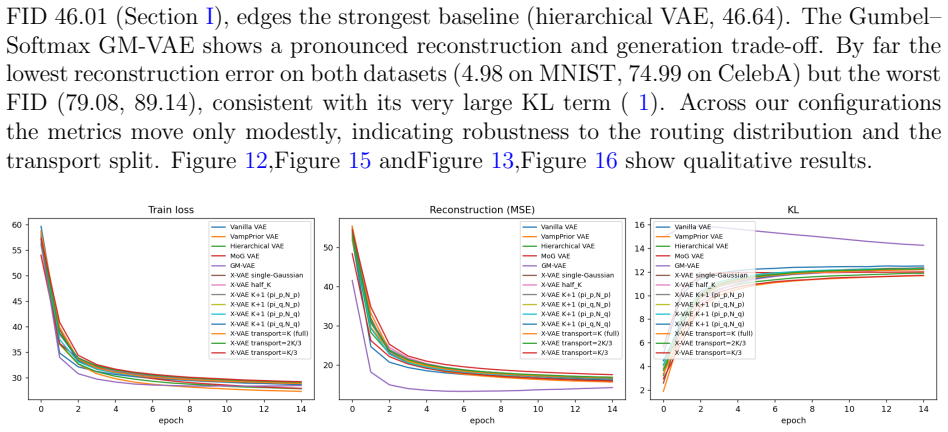
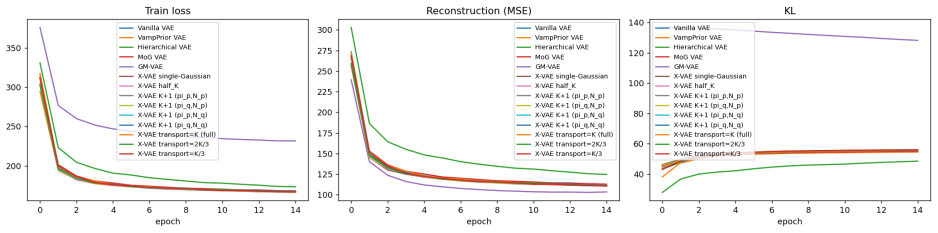
Significance. If the claimed KL derivation is correct and the prior alignment holds without introducing fitting artifacts, the approach offers a lightweight way to adapt the prior to data structure, which could benefit applications requiring constrained yet explorable generation such as engineering design. However, the absence of any equations, quantitative results, or ablation studies in the provided abstract limits assessment of whether the central claim is supported.
major comments (3)
- [Title and Abstract] Title vs. Abstract: The title claims 'Gaussian Mixture Priors' but the method description uses a single Gaussian N(μ_AE, σ_AE) parameterized by empirical statistics from the AE; this mismatch is load-bearing for the stated contribution and must be corrected.
- [Abstract] Abstract: The central claim requires a derivation of the KL term for the data-adaptive prior, yet no equations are shown; without the explicit form it is impossible to verify whether the closed-form KL between the variational posterior and N(μ_AE, σ_AE) is correctly obtained or whether the AE-derived statistics introduce misalignment with the VAE marginal.
- [Abstract] Abstract (method description): The prior parameters are extracted from a separately pretrained deterministic AE on the same data; the manuscript must demonstrate (via analysis or experiment) that this fixed target aligns with the distribution induced by the VAE encoder, as the skeptic concern about under-regularization or artifacts is not addressed.
minor comments (1)
- [Abstract] Abstract contains the awkward phrase 'mathematical formulation of well-suited X-VAE'; rephrase for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments on our submission. We address each major comment below and indicate the planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Title and Abstract] Title vs. Abstract: The title claims 'Gaussian Mixture Priors' but the method description uses a single Gaussian N(μ_AE, σ_AE) parameterized by empirical statistics from the AE; this mismatch is load-bearing for the stated contribution and must be corrected.
Authors: We agree with this observation. The title incorrectly refers to Gaussian Mixture Priors, whereas the method implements a single Gaussian prior using empirical mean and standard deviation from the pretrained AE. This is an oversight in the title. We will revise the title to remove 'Mixture' and accurately describe the single Gaussian prior. revision: yes
-
Referee: [Abstract] Abstract: The central claim requires a derivation of the KL term for the data-adaptive prior, yet no equations are shown; without the explicit form it is impossible to verify whether the closed-form KL between the variational posterior and N(μ_AE, σ_AE) is correctly obtained or whether the AE-derived statistics introduce misalignment with the VAE marginal.
Authors: The manuscript derives the KL divergence in the main text using the standard closed-form expression for the KL between two univariate Gaussians (extended to multivariate diagonal case). The abstract is a high-level summary and conventionally omits equations. We will ensure the derivation is clearly presented and will consider adding a short statement in the abstract if space permits. The AE statistics are computed on the same dataset, and the VAE is trained to match this prior, minimizing the risk of misalignment. revision: partial
-
Referee: [Abstract] Abstract (method description): The prior parameters are extracted from a separately pretrained deterministic AE on the same data; the manuscript must demonstrate (via analysis or experiment) that this fixed target aligns with the distribution induced by the VAE encoder, as the skeptic concern about under-regularization or artifacts is not addressed.
Authors: This is a valid concern. While the experiments show preserved reconstruction quality and better alignment to the empirical latent distribution, we do not provide a direct quantitative comparison between the AE latent distribution and the VAE encoder outputs post-training. We will add an ablation study or analysis in the revised manuscript to address potential under-regularization or artifacts. revision: yes
Circularity Check
No significant circularity; derivation is self-contained modeling choice
full rationale
The paper defines a data-adaptive Gaussian prior by computing empirical mean and std from latent codes of a separately pretrained AE on the same data, then uses the standard closed-form KL between two Gaussians in the VAE objective. This is an explicit modeling decision, not a derivation that reduces to its inputs by construction. No equations equate a 'prediction' to a fitted parameter, no self-citation chains support load-bearing claims, and no uniqueness theorems or ansatzes are smuggled in. The approach is evaluated on external benchmarks and remains independent of the target result.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent scaling factor
axioms (1)
- domain assumption Empirical mean and standard deviation of latent codes from a pretrained autoencoder provide a suitable Gaussian prior for VAE training
Reference graph
Works this paper leans on
-
[1]
Alexander A Alemi et al. “Fixing a broken ELBO”. In:International Conference on Machine Learning(2018).url:https://arxiv.org/abs/1711.00464
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Latent Space Oddity: on the Curvature of Deep Generative Models
Georgios Arvanitidis, Lars Kai Hansen, and Soren Hauberg. “Latent Space Oddity: on the Curvature of Deep Generative Models”. In:International Conference on Learning Representations (ICLR). 2018.url:https://arxiv.org/abs/1710.11379
-
[3]
dpVAEs: Fixing Sample Generation for Regularized VAEs
Riddhish Bhalodia and Ahmed Elgammal. “dpVAEs: Fixing Sample Generation for Regularized VAEs”. In:Proceedings of the Asian Conference on Computer Vision (ACCV). Nov. 2020.url:https://arxiv.org/abs/1911.10506
-
[4]
Diagnosing and Enhancing VAE Models
Bin Dai and David Wipf. “Diagnosing and Enhancing VAE Models”. In:International Conference on Learning Representations. 2019.url:https://arxiv.org/abs/1903. 05789
2019
-
[5]
Nat Dilokthanakul et al.Deep Unsupervised Clustering with Gaussian Mixture Varia- tional Autoencoders. 2017. arXiv:1611.02648 [cs.LG].url:https://arxiv.org/ abs/1611.02648
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Emilien Dupont.Learning Disentangled Joint Continuous and Discrete Representa- tions. 2018. arXiv:1804.00104 [stat.ML].url:https://arxiv.org/abs/1804. 00104
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
From Variational to Deterministic Autoencoders
Partha Ghosh et al. “From Variational to Deterministic Autoencoders”. In:Interna- tional Conference on Learning Representations (ICLR). 2020
2020
-
[8]
MIT Press, 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016
2016
-
[9]
Junxian He et al.Lagging Inference Networks and Posterior Collapse in Variational Autoencoders. 2019. arXiv:1901.05534 [cs.LG].url:https://arxiv.org/abs/ 1901.05534
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
Approximating the Kullback Leibler divergence be- tween Gaussian mixture models
John Hershey and Peder Olsen. “Approximating the Kullback Leibler divergence be- tween Gaussian mixture models”. In:2007 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). Vol. 4. IEEE. 2007, pp. IV–905
2007
-
[11]
Martin Heusel et al.GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. 2018. arXiv:1706.08500 [cs.LG].url:https://arxiv. org/abs/1706.08500
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
beta-VAE: Learning basic visual concepts with a constrained variational framework
Irina Higgins et al. “beta-VAE: Learning basic visual concepts with a constrained variational framework”. In: (2017)
2017
-
[13]
Reducing the Dimensionality of Data with Neural Networks
Geoffrey E. Hinton and Ruslan R. Salakhutdinov. “Reducing the Dimensionality of Data with Neural Networks”. In:Science313.5786 (2006), pp. 504–507
2006
-
[14]
ELBO Surgery: Yet Another Way to Carve Up the Variational Evidence Lower Bound
Matthew D. Hoffman and Matthew J. Johnson. “ELBO Surgery: Yet Another Way to Carve Up the Variational Evidence Lower Bound”. In:Advances in Neural Informa- tion Processing Systems Workshops. NeurIPS Workshop on Advances in Approximate Bayesian Inference. 2016. 20
2016
-
[15]
Springer Texts in Statistics
Gareth James et al.An Introduction to Statistical Learning: with Applications in R. Springer Texts in Statistics. Springer, 2013.isbn: 978-1-4614-7137-0.url:https : //www.statlearning.com/
2013
-
[16]
Eric Jang, Shixiang Gu, and Ben Poole.Categorical Reparameterization with Gumbel- Softmax. 2017. arXiv:1611.01144 [stat.ML].url:https://arxiv.org/abs/1611. 01144
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Diederik P Kingma and Max Welling.Auto-Encoding Variational Bayes. 2022. arXiv: 1312.6114 [stat.ML].url:https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Kingma and Jimmy Ba.Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba.Adam: A Method for Stochastic Optimization
-
[19]
arXiv:1412.6980 [cs.LG].url:https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Improving Variational Inference with Inverse Autoregressive Flow
Diederik P. Kingma et al.Improving Variational Inference with Inverse Autoregressive Flow. 2017. arXiv:1606.04934 [cs.LG].url:https://arxiv.org/abs/1606.04934
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
AutoVAE: Mismatched Variational Autoencoder with Irregular Posterior-Prior Pairing
Toshiaki Koike-Akino and Ye Wang. “AutoVAE: Mismatched Variational Autoencoder with Irregular Posterior-Prior Pairing”. In:2022 IEEE International Symposium on Information Theory (ISIT). IEEE. 2022, pp. 1885–1890.doi:10.1109/ISIT50566. 2022.9834769
-
[22]
Autoencoding beyond pixels using a learned similarity metric
Anders Boesen Lindbo Larsen et al. “Autoencoding beyond pixels using a learned similarity metric”. In:International conference on machine learning. PMLR. 2016, pp. 1558–1566.url:https://arxiv.org/abs/1512.09300
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
Backpropagation Applied to Handwritten Zip Code Recognition
Y. LeCun et al. “Backpropagation Applied to Handwritten Zip Code Recognition”. In: Neural Computation1.4 (1989), pp. 541–551.doi:10.1162/neco.1989.1.4.541
-
[24]
Machine learning in aerody- namic shape optimization
Jichao Li, Xiaosong Du, and Joaquim R.R.A. Martins. “Machine learning in aerody- namic shape optimization”. In:Progress in Aerospace Sciences134 (2022), p. 100849. issn: 0376-0421.doi:https://doi.org/10.1016/j.paerosci.2022.100849.url: https://www.sciencedirect.com/science/article/pii/S0376042122000410
-
[25]
Shuyu Lin et al.Balancing Reconstruction Quality and Regularisation in ELBO for VAEs. 2019. arXiv:1909 . 03765 [cs.LG].url:https : / / arxiv . org / abs / 1909 . 03765
2019
-
[26]
Deep Learning Face Attributes in the Wild
Ziwei Liu et al. “Deep Learning Face Attributes in the Wild”. In:Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2015, pp. 3730–3738. url:https://arxiv.org/abs/1411.7766
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
Understanding posterior collapse in generative latent variable models
James Lucas et al. “Understanding posterior collapse in generative latent variable models”. In:Workshop on Deep Generative Models at ICLR(2019)
2019
-
[28]
Alireza Makhzani et al.Adversarial Autoencoders. 2016. arXiv:1511.05644 [cs.LG]. url:https://arxiv.org/abs/1511.05644
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Sampling via Measure Transport: An Introduction
Youssef Marzouk et al. “Sampling via Measure Transport: An Introduction”. In:Hand- book of Uncertainty Quantification. Springer International Publishing, 2016, pp. 1– 41.isbn: 9783319112596.doi:10 . 1007 / 978 - 3 - 319 - 11259 - 6 _ 23 - 1.url:http : //dx.doi.org/10.1007/978-3-319-11259-6_23-1. 21
-
[30]
Generating Diverse High-Fidelity Images with VQ-VAE-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. “Generating diverse high-fidelity images with vq-vae-2”. In:Advances in neural information processing systems. 2019, pp. 14866–14876.url:https://arxiv.org/abs/1906.00446
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Danilo Jimenez Rezende and Shakir Mohamed.Variational Inference with Normalizing Flows. 2016. arXiv:1505.05770 [stat.ML].url:https://arxiv.org/abs/1505. 05770
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra.Stochastic Backpropa- gation and Approximate Inference in Deep Generative Models. 2014. arXiv:1401.4082 [stat.ML].url:https://arxiv.org/abs/1401.4082
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
Mihaela Ro¸ sca, Balaji Lakshminarayanan, and Shakir Mohamed.Distribution Match- ing in Variational Inference. 2019. arXiv:1802 . 06847 [stat.ML].url:https : / / arxiv.org/abs/1802.06847
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[34]
Learning represen- tations by back-propagating errors
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. “Learning represen- tations by back-propagating errors”. In:Nature323.6088 (1986), pp. 533–536
1986
-
[35]
Tim Salimans et al.Improved Techniques for Training GANs. 2016. arXiv:1606.03498 [cs.LG].url:https://arxiv.org/abs/1606.03498
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[36]
Casper Kaae Sønderby et al.Ladder Variational Autoencoders. 2016. arXiv:1602 . 02282 [stat.ML].url:https://arxiv.org/abs/1602.02282
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[37]
Christian Szegedy et al.Rethinking the Inception Architecture for Computer Vision
-
[38]
arXiv:1512.00567 [cs.CV].url:https://arxiv.org/abs/1512.00567
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Jakub M. Tomczak and Max Welling.VAE with a VampPrior. 2018. arXiv:1705.07120 [cs.LG].url:https://arxiv.org/abs/1705.07120
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Aerodynamics-guided machine learning for design optimization of electric vehicles
Jonathan Tran et al. “Aerodynamics-guided machine learning for design optimization of electric vehicles”. In:Communications Engineering3 (Nov. 2024).doi:10.1038/ s44172-024-00322-0
2024
-
[41]
Arash Vahdat and Jan Kautz.NVAE: A Deep Hierarchical Variational Autoencoder
- [42]
-
[43]
Stacked Denoising Autoencoders: Learning Useful Representa- tions in a Deep Network with a Local Denoising Criterion
Pascal Vincent et al. “Stacked Denoising Autoencoders: Learning Useful Representa- tions in a Deep Network with a Local Denoising Criterion”. In:Journal of Machine Learning Research11.11 (2010), pp. 3371–3408.url:http://jmlr.org
2010
- [44]
-
[45]
− 1 2 dX j=1 (zj −µ j)2 σ2 j # .(36) Hence: q(z) = 1 (2π)d/2Qd j=1 σq,j exp
Bin Yu and Karl Kumbier.Veridical Data Science: The Practice of Responsible Data Analysis and Decision Making. Cambridge, MA: MIT Press, 2020. 22 A Derivation of the Gaussian Mixture-KL Objective We prove the sampled upper bound Equation (18). We first establish the general mixture bound and then specialize to the dimension-wise Gaussian case. Lemma 1(Mix...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.