OPINE-World: Programmatic World Modeling with Ontology-error-Prioritized Interactive Exploration
Pith reviewed 2026-07-03 19:58 UTC · model grok-4.3
The pith
OPINE-World learns object-centric programs as world models from pixel interactions to solve 20 of 25 ARC-AGI-3 games without per-game training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
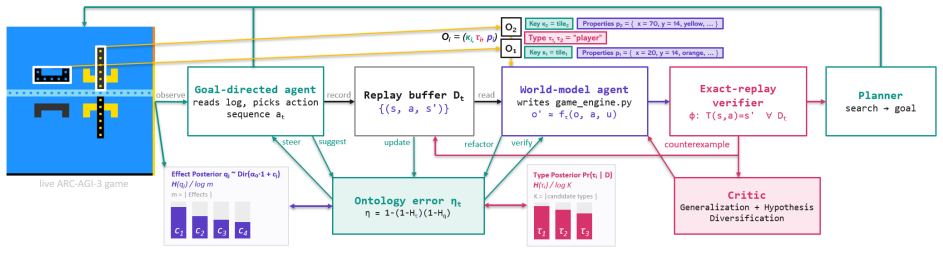
OPINE-World couples an acting agent and a model-synthesizing agent that together generate object-centric programs in code, verify them with replayed trajectories, and direct further interaction via a Bayesian ontology-error measure; the resulting loop produces accurate enough models to solve 20 of 25 ARC-AGI-3 games at an action-efficiency score of 78.4 relative to human performance, all without any per-game training.
What carries the argument
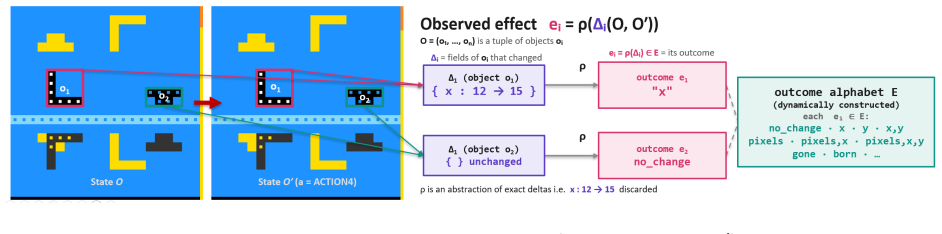
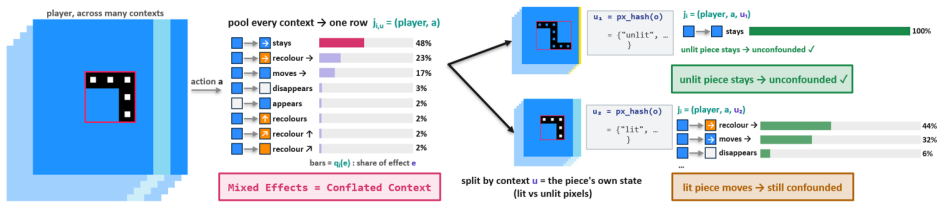
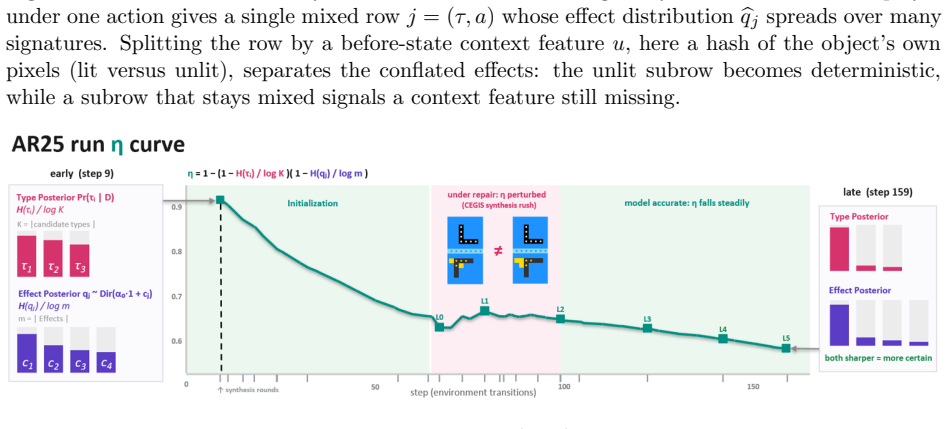
The ontology-error measure, a Bayesian score of object-type adequacy that ranks exploration hypotheses and triggers refinement of the synthesized program when the current ontology fails to explain observations.
If this is right
- Agents acquire task competence in novel environments without retraining a new model for each game.
- The same synthesized program can be reused for planning and prediction across multiple tasks.
- Exploration effort concentrates on resolving gaps in the hypothesized object vocabulary rather than uniform random sampling.
- Model-based planning inside the learned program improves action efficiency over model-free interaction.
Where Pith is reading between the lines
- The method could be tested on continuous or partially observable physics domains by extending the program grammar to include differential equations or belief states.
- Replacing the LLM synthesizer with a hybrid of symbolic search and neural proposals might reduce dependence on prompt engineering while retaining the verification loop.
- If ontology error reliably signals model inadequacy, the same signal could serve as an intrinsic reward for open-ended skill discovery in larger environments.
Load-bearing premise
Large language models can generate programs that correctly represent hidden object structures and dynamics in pixel environments when those programs are iteratively corrected by replay verification.
What would settle it
A new game in which the agent's synthesized program produces state predictions that diverge from actual outcomes after the ontology error has been driven below a low threshold.
Figures

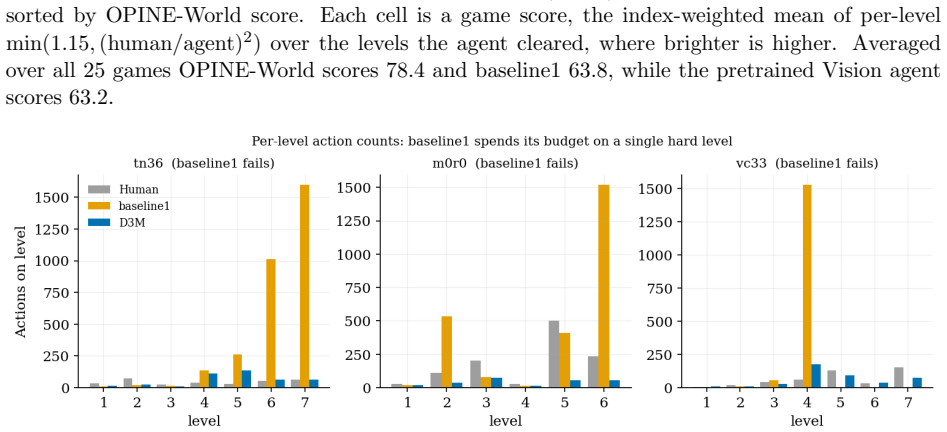
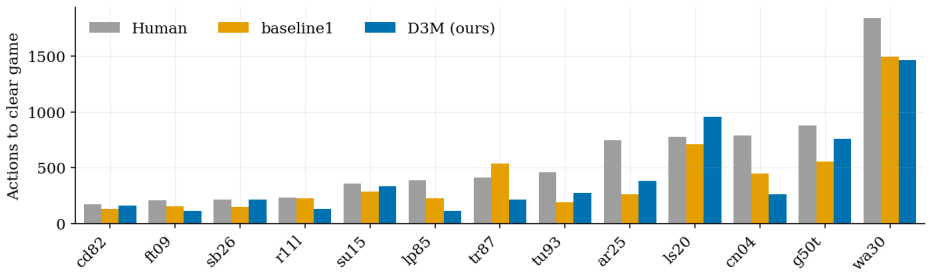
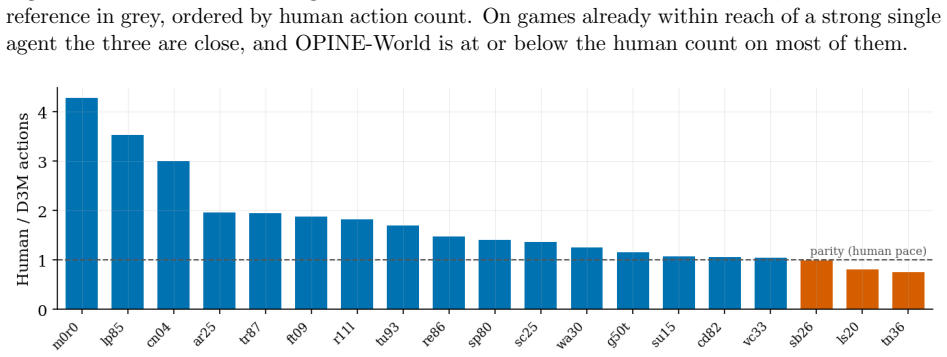
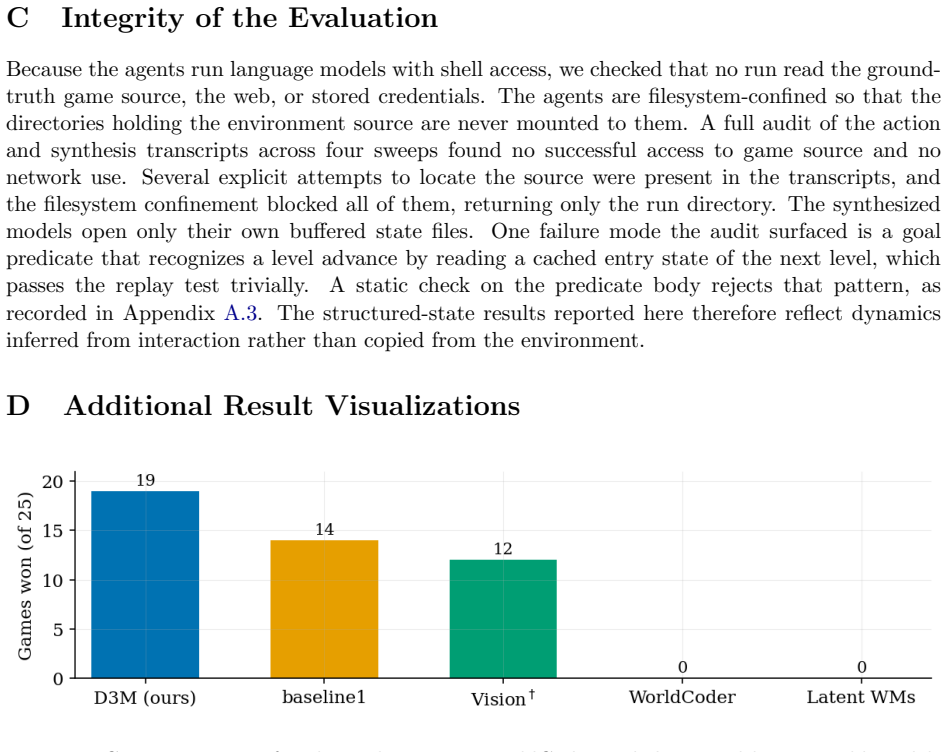
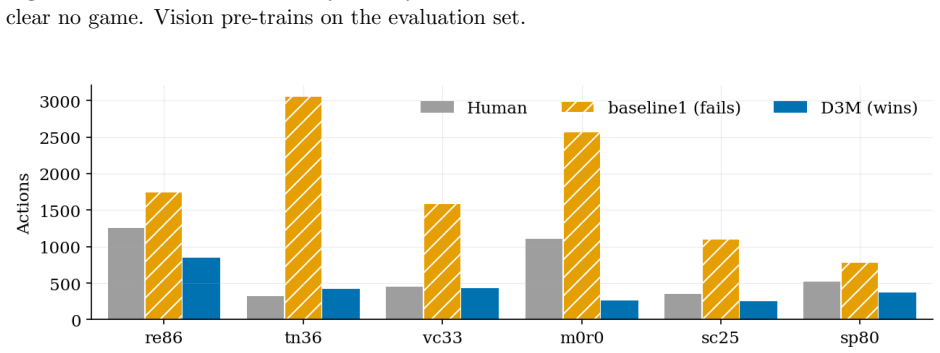
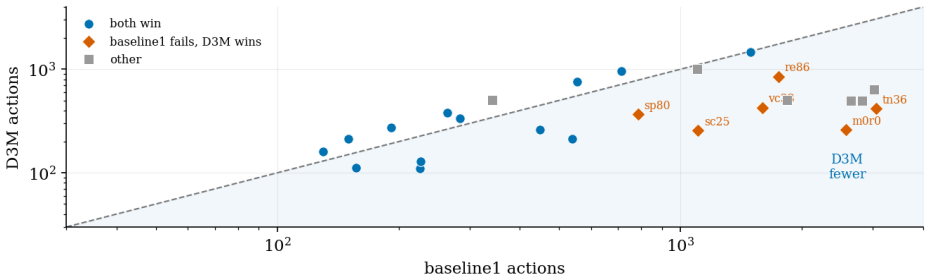
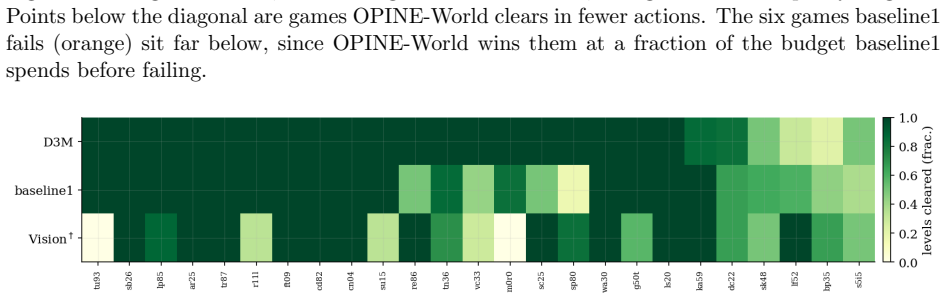

read the original abstract
Learning how an environment behaves from interaction is central to building agents that adapt to unfamiliar tasks. World models learned with deep networks are flexible but data-hungry and transfer poorly beyond their training distribution. Program-synthesized world models, written as source code by LLMs and refined through counterexample-guided inductive synthesis (CEGIS), are instead data-efficient and reusable, yet they have been demonstrated mainly on structured-state worlds with a given object vocabulary, and a single program search does not scale to pixel-rendered environments whose object structure must be hypothesized flexibly. We introduce OPINE-World, an LLM agent that learns an object-centric programmatic world model online from interaction. OPINE-World couples two cooperating agents in a loop of hypothesis and test, one acting in the environment and one synthesizing the model in code with replay verification and model-based planning, and it steers exploration with a Bayesian measure of object-type adequacy we call ontology error. We evaluate OPINE-World on ARC-AGI-3, a benchmark for skill-acquisition efficiency in which the object vocabulary, the goal, and the action semantics are withheld. OPINE-World solves 20 of 25 games without per-game training and reaches an action-efficiency score of 78.4 against the human baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OPINE-World, an LLM agent that learns object-centric programmatic world models online from interaction. It couples an acting agent with a synthesizing agent in a hypothesis-test loop that uses LLM-generated candidate programs, CEGIS refinement with replay verification, model-based planning, and a Bayesian ontology-error measure to steer exploration. The vocabulary, goal, and action semantics are withheld. The central empirical claim is that the system solves 20 of 25 ARC-AGI-3 games without per-game training and attains an action-efficiency score of 78.4 relative to the human baseline.
Significance. If the results hold, the work would demonstrate a data-efficient, reusable, and interpretable alternative to deep-network world models for pixel-rendered environments whose object structure must be discovered rather than given. The combination of programmatic synthesis, replay verification, and ontology-error-driven exploration addresses transfer and data-hunger limitations of existing approaches and supplies a concrete testbed for LLM-driven object invention.
major comments (2)
- [Method description (pipeline overview)] The central claim (20/25 games solved, 78.4 efficiency) rests on the hypothesis-test loop successfully discovering object types and dynamics from raw pixels. The manuscript provides no concrete mechanism—e.g., how pixel patches are segmented into candidate objects, how type hypotheses are generated, or how ontology error is computed from replay mismatches—making it impossible to evaluate whether the initial object segmentation step is reliable enough to support the subsequent CEGIS and planning stages.
- [Evaluation section] The evaluation reports aggregate solve rate and efficiency without per-game breakdowns, error bars, or ablation of the ontology-error component. Without these, it is unclear whether the 20/25 figure is driven by a few easy games or generalizes across the withheld-vocabulary setting that the paper emphasizes.
minor comments (1)
- [Abstract] The abstract is unusually long and contains results that would normally appear in the evaluation section; consider shortening it to the problem statement and high-level approach.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating revisions where the manuscript will be updated to improve clarity and completeness.
read point-by-point responses
-
Referee: [Method description (pipeline overview)] The central claim (20/25 games solved, 78.4 efficiency) rests on the hypothesis-test loop successfully discovering object types and dynamics from raw pixels. The manuscript provides no concrete mechanism—e.g., how pixel patches are segmented into candidate objects, how type hypotheses are generated, or how ontology error is computed from replay mismatches—making it impossible to evaluate whether the initial object segmentation step is reliable enough to support the subsequent CEGIS and planning stages.
Authors: We agree that the current description of the object-discovery pipeline lacks sufficient low-level detail for independent evaluation of the segmentation reliability. The manuscript outlines the dual-agent hypothesis-test loop and Bayesian ontology-error measure at a high level in Section 3, but does not provide pseudocode or explicit computation steps for patch segmentation, type hypothesis generation, or replay-mismatch-based ontology error. We will revise the method section to include these concrete mechanisms (e.g., LLM-guided patch clustering for candidate objects, synthesizing-agent prompt templates for type hypotheses, and the exact Bayesian update rule for ontology error) so that readers can assess the foundation of the subsequent CEGIS and planning stages. revision: yes
-
Referee: [Evaluation section] The evaluation reports aggregate solve rate and efficiency without per-game breakdowns, error bars, or ablation of the ontology-error component. Without these, it is unclear whether the 20/25 figure is driven by a few easy games or generalizes across the withheld-vocabulary setting that the paper emphasizes.
Authors: We concur that aggregate metrics alone limit interpretability of generalization. The current evaluation presents only overall solve rate (20/25) and efficiency (78.4) on ARC-AGI-3. In the revision we will add a per-game breakdown table, report standard deviations or error bars across repeated runs, and include an ablation that isolates the contribution of the ontology-error exploration component. These additions will directly address whether performance holds across the withheld-vocabulary games rather than being driven by a subset of easier instances. revision: yes
Circularity Check
No circularity: empirical benchmark results are direct outcomes
full rationale
The paper reports empirical performance on ARC-AGI-3 (20/25 games solved, 78.4 action-efficiency) as the outcome of running an LLM-driven hypothesis-test loop with replay verification and ontology-error steering. No equations, fitted parameters, self-citations, or ansatzes appear in the provided text that would reduce any claimed result to its inputs by construction. The method description is procedural and the success metrics are externally measured against withheld-vocabulary environments, making the derivation self-contained with no load-bearing reductions of the enumerated kinds.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NeurIPS , year =
Tang, Hao and Key, Darren and Ellis, Kevin , title =. NeurIPS , year =
-
[2]
2025 , eprint =
Ellis, Kevin and others , title =. 2025 , eprint =
2025
-
[3]
TMLR , year =
Ahmed, Zaid and others , title =. TMLR , year =
-
[4]
Fox, Alexis and Wang, Jason and Rosu, Paul and Dhingra, Bhuwan , title =
-
[5]
, title =
Diuk, Carlos and Cohen, Andre and Littman, Michael L. , title =. ICML , year =
-
[6]
and Nilsson, Nils J
Fikes, Richard E. and Nilsson, Nils J. , title =. Artificial Intelligence , volume =
-
[7]
Mathematics of Operations Research , volume =
Russo, Daniel and Van Roy, Benjamin , title =. Mathematics of Operations Research , volume =
-
[8]
and Tennenholtz, Moshe , title =
Brafman, Ronen I. and Tennenholtz, Moshe , title =. JMLR , volume =
-
[9]
Chow, Yuan Shih and Robbins, Herbert and Siegmund, David , title =
-
[10]
and Herskovits, Edward , title =
Cooper, Gregory F. and Herskovits, Edward , title =. Machine Learning , volume =
-
[11]
, title =
Heckerman, David and Geiger, Dan and Chickering, David M. , title =. Machine Learning , volume =
-
[12]
Haughton, Dominique M. A. , title =. Annals of Statistics , volume =
-
[13]
PLDI , year =
Ellis, Kevin and others , title =. PLDI , year =
-
[14]
NeurIPS , year =
Shinn, Noah and others , title =. NeurIPS , year =
-
[15]
ICLR , year =
Hafner, Danijar and others , title =. ICLR , year =
-
[16]
Nature , volume =
Schrittwieser, Julian and others , title =. Nature , volume =
-
[17]
IJCAI , year =
Lamanna, Leonardo and others , title =. IJCAI , year =
-
[18]
2025 , eprint =
Hu, Mengkang and others , title =. 2025 , eprint =
2025
-
[19]
Journal of the Royal Statistical Society B , volume =
Stephens, Matthew , title =. Journal of the Royal Statistical Society B , volume =
-
[20]
Celeux, Gilles , title =
-
[21]
Bayesian Analysis , volume =
Wade, Sara and Ghahramani, Zoubin , title =. Bayesian Analysis , volume =
-
[22]
Comparing Clusterings: An Information Based Distance , journal =
Meil. Comparing Clusterings: An Information Based Distance , journal =
-
[23]
and Griffiths, Thomas L
Kemp, Charles and Tenenbaum, Joshua B. and Griffiths, Thomas L. and Yamada, Takeshi and Ueda, Naonori , title =. AAAI , year =
-
[24]
and Beal, Matthew J
Teh, Yee Whye and Jordan, Michael I. and Beal, Matthew J. and Blei, David M. , title =. JASA , volume =
-
[25]
IJCAI , year =
Lipovetzky, Nir and Ramirez, Miquel and Geffner, Hector , title =. IJCAI , year =
-
[26]
and Pollitt, Andr\'e and Jonsson, Anders and Seipp, Jendrik , title =
Corr\^ea, Augusto B. and Pollitt, Andr\'e and Jonsson, Anders and Seipp, Jendrik , title =. 2025 , eprint =
2025
-
[27]
ICML , year =
Zhou, Andy and others , title =. ICML , year =
-
[28]
2025 , eprint =
Levy, Guillaume and others , title =. 2025 , eprint =
2025
-
[29]
CoRL , year =
Curtis, Aidan and others , title =. CoRL , year =
-
[30]
2026 , note =
Learning. 2026 , note =
2026
-
[31]
2023 , eprint =
Wong, Lionel and others , title =. 2023 , eprint =
2023
-
[32]
NeurIPS , year =
Piriyakulkij, Wasu Top and Langenfeld, Cassidy and Le, Tuan Anh and Ellis, Kevin , title =. NeurIPS , year =
-
[33]
Pearl, Judea , title =
-
[34]
2026 , howpublished =
Frontier-Model Trace Analysis on. 2026 , howpublished =
2026
-
[35]
, title =
Sutton, Richard S. , title =. ACM SIGART Bulletin , volume =
-
[36]
NeurIPS , year =
Ha, David and Schmidhuber, J\"urgen , title =. NeurIPS , year =
-
[37]
Nature , volume =
Hafner, Danijar and Pasukonis, Jurgis and Ba, Jimmy and Lillicrap, Timothy , title =. Nature , volume =
-
[38]
and Saraswat, Vijay A
Solar-Lezama, Armando and Tancau, Liviu and Bod\'ik, Rastislav and Seshia, Sanjit A. and Saraswat, Vijay A. , title =. ASPLOS , year =
-
[39]
On the Measure of Intelligence , journal =
Chollet, Fran. On the Measure of Intelligence , journal =
-
[40]
Kaiser, Lukasz and Babaeizadeh, Mohammad and Milos, Piotr and Osinski, Blazej and Campbell, Roy H. and Czechowski, Konrad and Erhan, Dumitru and Finn, Chelsea and Kozakowski, Piotr and Levine, Sergey and Mohiuddin, Afroz and Sepassi, Ryan and Tucker, George and Michalewski, Henryk , title =. ICLR , year =
-
[41]
and Tsitsiklis, John N
Konda, Vijay R. and Tsitsiklis, John N. , title =. NeurIPS , year =
-
[42]
ICLR , year =
Horgan, Dan and Quan, John and Budden, David and Barth-Maron, Gabriel and Hessel, Matteo and van Hasselt, Hado and Silver, David , title =. ICLR , year =
-
[43]
ICLR , year =
Hong, Sirui and Zhuge, Mingchen and Chen, Jiaqi and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and Zhou, Liyang and Ran, Chenyu and Xiao, Lingfeng and Wu, Chenglin and Schmidhuber, J\"urgen , title =. ICLR , year =
-
[44]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , title =. arXiv preprint arXiv:2308.08155 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
ACL , year =
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , title =. ACL , year =
-
[46]
JAIR , volume =
Guestrin, Carlos and Koller, Daphne and Parr, Ronald and Venkataraman, Shobha , title =. JAIR , volume =
-
[47]
Relational Reinforcement Learning , journal =
D. Relational Reinforcement Learning , journal =
-
[48]
Relational inductive biases, deep learning, and graph networks
Battaglia, Peter W. and Hamrick, Jessica B. and Bapst, Victor and Sanchez-Gonzalez, Alvaro and Zambaldi, Vinicius and Malinowski, Mateusz and Tacchetti, Andrea and Raposo, David and Santoro, Adam and others , title =. arXiv preprint arXiv:1806.01261 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics , booktitle =
Kansky, Ken and Silver, Tom and M. Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics , booktitle =
-
[50]
ICLR , year =
Kipf, Thomas and van der Pol, Elise and Welling, Max , title =. ICLR , year =
-
[51]
and Chang, Michael and Janner, Michael and Finn, Chelsea and Wu, Jiajun and Tenenbaum, Joshua and Levine, Sergey , title =
Veerapaneni, Rishi and Co-Reyes, John D. and Chang, Michael and Janner, Michael and Finn, Chelsea and Wu, Jiajun and Tenenbaum, Joshua and Levine, Sergey , title =. CoRL , year =
-
[52]
Evaluating Large Language Models Trained on Code
Chen, Mark and Tworek, Jerry and Jun, Heewoo and Yuan, Qiming and Pinto, Henrique Ponde de Oliveira and others , title =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Program Synthesis with Large Language Models
Austin, Jacob and Odena, Augustus and Nye, Maxwell and Bosma, Maarten and Michalewski, Henryk and Dohan, David and Jiang, Ellen and Cai, Carrie and Terry, Michael and Le, Quoc and Sutton, Charles , title =. arXiv preprint arXiv:2108.07732 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Science , volume =
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and others , title =. Science , volume =
-
[55]
Pawan and Dupont, Emilien and Ruiz, Francisco J
Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Balog, Matej and Kumar, M. Pawan and Dupont, Emilien and Ruiz, Francisco J. R. and Ellenberg, Jordan S. and Wang, Pengming and Fawzi, Omar and Kohli, Pushmeet and Fawzi, Alhussein , title =. Nature , volume =
-
[56]
, title =
Wang, Ruocheng and Zelikman, Eric and Poesia, Gabriel and Pu, Yewen and Haber, Nick and Goodman, Noah D. , title =. ICLR , year =
-
[57]
, title =
Kambhampati, Subbarao and Valmeekam, Karthik and Guan, Lin and Verma, Mudit and Stechly, Kaya and Bhambri, Siddhant and Saldyt, Lucas Paul and Murthy, Anil B. , title =. ICML , year =
-
[58]
and Tiwari, Ashish , title =
Jha, Susmit and Gulwani, Sumit and Seshia, Sanjit A. and Tiwari, Ashish , title =. ICSE , year =
-
[59]
Syntax-Guided Synthesis , booktitle =
Alur, Rajeev and Bod. Syntax-Guided Synthesis , booktitle =
-
[60]
CAV , year =
Clarke, Edmund and Grumberg, Orna and Jha, Somesh and Lu, Yuan and Veith, Helmut , title =. CAV , year =
-
[61]
, title =
Mitchell, Tom M. , title =. Artificial Intelligence , volume =
-
[62]
, title =
Blumer, Anselm and Ehrenfeucht, Andrzej and Haussler, David and Warmuth, Manfred K. , title =. Information Processing Letters , volume =
-
[63]
Journal of Logic Programming , volume =
Muggleton, Stephen and De Raedt, Luc , title =. Journal of Logic Programming , volume =
-
[64]
and Kemp, Charles and Griffiths, Thomas L
Tenenbaum, Joshua B. and Kemp, Charles and Griffiths, Thomas L. and Goodman, Noah D. , title =. Science , volume =
-
[65]
and Schulz, Laura E
Gopnik, Alison and Glymour, Clark and Sobel, David M. and Schulz, Laura E. and Kushnir, Tamar and Danks, David , title =. Psychological Review , volume =
-
[66]
, title =
Lindley, Dennis V. , title =. Annals of Mathematical Statistics , volume =
-
[67]
Statistical Science , volume =
Chaloner, Kathryn and Verdinelli, Isabella , title =. Statistical Science , volume =
-
[68]
NeurIPS , year =
Houthooft, Rein and Chen, Xi and Duan, Yan and Schulman, John and De Turck, Filip and Abbeel, Pieter , title =. NeurIPS , year =
-
[69]
and Darrell, Trevor , title =
Pathak, Deepak and Agrawal, Pulkit and Efros, Alexei A. and Darrell, Trevor , title =. ICML , year =
-
[70]
Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990--2010) , journal =
Schmidhuber, J. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990--2010) , journal =
1990
-
[71]
Frontiers in Neurorobotics , volume =
Oudeyer, Pierre-Yves and Kaplan, Frederic , title =. Frontiers in Neurorobotics , volume =
-
[72]
ICLR , year =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , title =. ICLR , year =
-
[73]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , title =. arXiv preprint arXiv:2305.16291 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
CoRL , year =
Ahn, Michael and Brohan, Anthony and Brown, Noah and Chebotar, Yevgen and Cortes, Omar and others , title =. CoRL , year =
-
[75]
and Prett, David M
Garcia, Carlos E. and Prett, David M. and Morari, Manfred , title =. Automatica , volume =
-
[76]
and Rawlings, James B
Mayne, David Q. and Rawlings, James B. and Rao, Christopher V. and Scokaert, Pierre O. M. , title =. Automatica , volume =
-
[77]
and Boots, Byron and Theodorou, Evangelos A
Williams, Grady and Wagener, Nolan and Goldfain, Brian and Drews, Paul and Rehg, James M. and Boots, Byron and Theodorou, Evangelos A. , title =. ICRA , year =
-
[78]
Width and Serialization of Classical Planning Problems , booktitle =
Lipovetzky, Nir and Geffner, H. Width and Serialization of Classical Planning Problems , booktitle =
-
[79]
Pednault, Edwin P. D. , title =. KR , year =
-
[80]
McDermott, Drew and Ghallab, Malik and Howe, Adele and Knoblock, Craig and Ram, Ashwin and Veloso, Manuela and Weld, Daniel and Wilkins, David , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.