Hawk: Harnessing Hardware-Aware Knowledge for High-Performance NPU Kernel Generation
Pith reviewed 2026-07-03 14:58 UTC · model grok-4.3
The pith
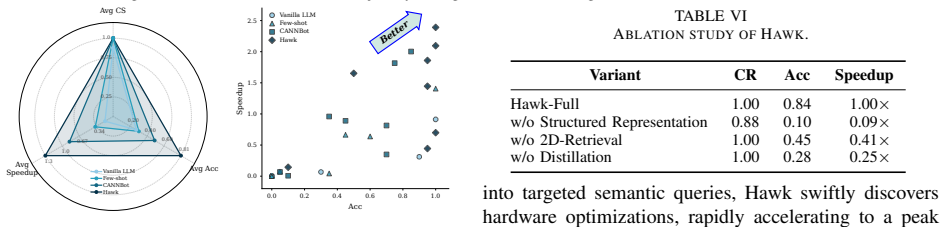
Hawk raises NPU kernel generation accuracy from 49.4 percent to 80 percent by distilling hardware constraints from execution results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
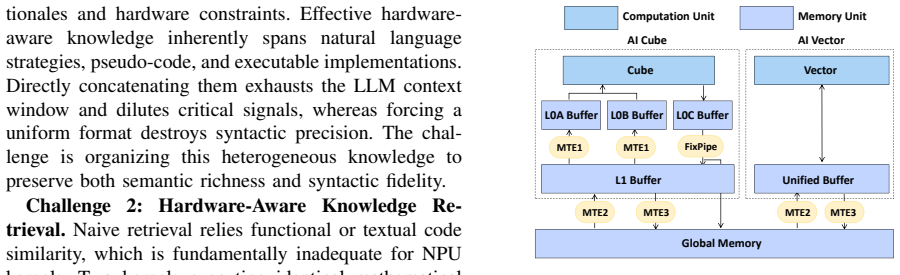
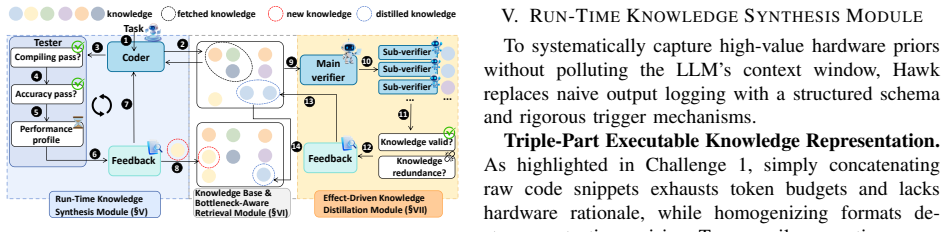
Hawk is a training-free framework that harnesses hardware-aware knowledge through three core modules: the Run-Time Knowledge Synthesis Module, which couples error context with executable semantics via Triple-Part Executable Knowledge Representation; the Bottleneck-Aware Knowledge Retrieval Module, which projects queries into orthogonal syntactic and hardware-aligned semantic spaces using a 2D-Retrieval paradigm; and the Effect-Driven Knowledge Distillation Module, which performs LLM-driven semantic arbitration to prune errors and consolidate redundancies based on empirical execution feedback. On real-world NPU workloads this raises generation accuracy from 49.4 percent to 80.0 percent and de
What carries the argument
Hawk's three-module pipeline: Run-Time Knowledge Synthesis with Triple-Part Executable Knowledge Representation, Bottleneck-Aware Knowledge Retrieval via 2D-Retrieval, and Effect-Driven Knowledge Distillation driven by execution feedback.
If this is right
- Kernel developers obtain correct and performant NPU code without hand-written hardware priors.
- Generated kernels run up to 2.2 times faster on actual NPU hardware than prior automated methods.
- The system continuously improves its knowledge base from runtime observations rather than static training data.
- Accuracy gains hold across multiple real-world NPU workloads without additional model fine-tuning.
Where Pith is reading between the lines
- Similar feedback-driven distillation could be applied to kernel generation for other accelerators such as GPUs or custom ASICs.
- The approach offers a path to make LLMs more reliable for any low-level programming task where runtime constraints are hard to encode statically.
- Integrating the three modules into existing code-generation pipelines might reduce the expert time needed to port models to new hardware targets.
Load-bearing premise
Execution feedback can guide the LLM to prune errors and consolidate knowledge without the model introducing fresh inaccuracies during semantic arbitration.
What would settle it
On a held-out set of NPU workloads the generated kernels achieve accuracy below 60 percent or no measurable speedup relative to the baselines used in the paper.
Figures





read the original abstract
Developing high-performance kernels for Neural Processing Units (NPUs) is a critical industry bottleneck, requiring developers to manually navigate implicit hardware constraints and strict memory hierarchies. While large language models offer immense automation potential, they fail catastrophically on NPUs due to a fundamental lack of hardware-specific priors. Naively transplanting code snippets from similar NPU kernels may pass the compiler, but it consistently triggers runtime crashes and performance degradation by blindly violating underlying hardware constraints. To overcome this, we introduce Hawk, a training-free framework that harnesses hardware-aware knowledge through three core modules: (1) Run-Time Knowledge Synthesis Module, which employs a Triple-Part Executable Knowledge Representation to inherently couple the error context with executable semantics; (2) Bottleneck-Aware Knowledge Retrieval Module, which implements a 2D-Retrieval paradigm to project queries into orthogonal syntactic and hardware-aligned semantic spaces; and (3) Effect-Driven Knowledge Distillation Module, which leverages LLM-driven semantic arbitration to continuously distill the knowledge by pruning errors and consolidating redundancies based on the empirical execution feedback. Extensive evaluations on real-world NPU workloads demonstrate that Hawk elevates generation accuracy from 49.4% to 80.0%, while achieving up to a 2.2x execution speedup over state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hawk, a training-free framework for LLM-based generation of high-performance NPU kernels. It comprises three modules: (1) Run-Time Knowledge Synthesis using Triple-Part Executable Knowledge Representation to couple error context with executable semantics; (2) Bottleneck-Aware Knowledge Retrieval via 2D-Retrieval projecting queries into syntactic and hardware-aligned semantic spaces; and (3) Effect-Driven Knowledge Distillation employing LLM semantic arbitration on execution feedback to prune errors and consolidate knowledge. The central empirical claim is that Hawk raises kernel generation accuracy from 49.4% to 80.0% and delivers up to 2.2× execution speedup over SOTA baselines on real-world NPU workloads.
Significance. If the reported accuracy and speedup gains are reproducible and the arbitration step functions without systematic bias, the work would represent a meaningful advance in training-free, hardware-aware code generation for specialized accelerators. The explicit coupling of execution feedback with knowledge distillation and the 2D retrieval design are technically distinctive. However, the absence of detailed experimental protocols, baseline characterizations, and validation of the LLM arbitration mechanism limits the immediate assessability of these contributions.
major comments (2)
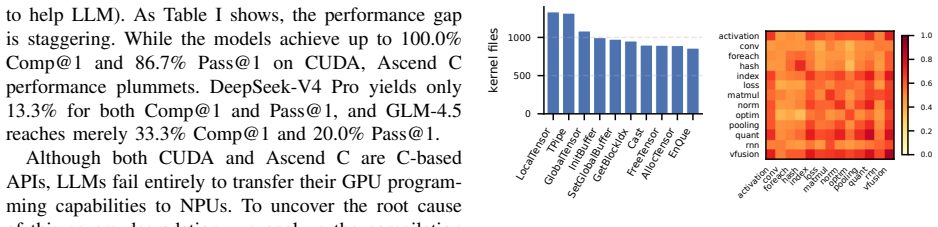
- [Abstract and §3] Abstract and §3 (Effect-Driven Knowledge Distillation Module): The headline accuracy improvement (49.4% → 80.0%) and 2.2× speedup are attributed to LLM-driven semantic arbitration that prunes hardware violations using execution feedback. No mechanism is described to detect or correct LLM misinterpretations of NPU-specific constraints (memory hierarchy, implicit scheduling) when feedback is noisy; because the framework is training-free, any such errors propagate directly to the final metrics. This is load-bearing for the central claim.
- [Abstract and experimental evaluation section] Abstract and experimental evaluation section: The manuscript states concrete numerical gains (49.4% → 80.0% accuracy, 2.2× speedup) but supplies no baseline descriptions, workload/dataset details, number of trials, or error bars. Without these, it is impossible to determine whether the data support the attribution to the three modules rather than implementation artifacts or cherry-picked cases.
minor comments (1)
- [§2 and §3] Notation for the Triple-Part Executable Knowledge Representation and 2D-Retrieval paradigm is introduced without an accompanying diagram or pseudocode example, making the data flow between modules difficult to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that enhance the clarity and completeness of the work without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Effect-Driven Knowledge Distillation Module): The headline accuracy improvement (49.4% → 80.0%) and 2.2× speedup are attributed to LLM-driven semantic arbitration that prunes hardware violations using execution feedback. No mechanism is described to detect or correct LLM misinterpretations of NPU-specific constraints (memory hierarchy, implicit scheduling) when feedback is noisy; because the framework is training-free, any such errors propagate directly to the final metrics. This is load-bearing for the central claim.
Authors: We acknowledge that §3 does not explicitly describe a dedicated mechanism for detecting or correcting potential LLM misinterpretations of NPU constraints (such as memory hierarchy or implicit scheduling) when execution feedback is noisy. The current design relies on the Triple-Part Executable Knowledge Representation to couple error context directly with executable semantics, and on iterative effect-driven distillation using empirical feedback to prune errors. However, to strengthen the presentation, we will revise §3 to include an explicit discussion of how semantic arbitration is anchored in execution outcomes and to report empirical checks on arbitration consistency across feedback iterations. This addresses the load-bearing nature of the claim. revision: yes
-
Referee: [Abstract and experimental evaluation section] Abstract and experimental evaluation section: The manuscript states concrete numerical gains (49.4% → 80.0% accuracy, 2.2× speedup) but supplies no baseline descriptions, workload/dataset details, number of trials, or error bars. Without these, it is impossible to determine whether the data support the attribution to the three modules rather than implementation artifacts or cherry-picked cases.
Authors: We agree that the experimental evaluation section provides high-level results but omits the requested protocol details. In the revised manuscript we will add a dedicated subsection specifying the SOTA baselines and their configurations, the exact real-world NPU workloads and datasets, the number of independent trials, and error bars (or standard deviations) for all reported metrics. This will enable readers to evaluate the robustness of the gains and their attribution to Hawk's modules. revision: yes
Circularity Check
No circularity: empirical results from training-free modules
full rationale
The paper presents Hawk as a training-free three-module framework and reports accuracy (49.4% to 80.0%) and speedup (2.2x) as direct empirical outcomes of evaluations on real-world NPU workloads. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description that would reduce the claimed results to the inputs by construction. The Effect-Driven Knowledge Distillation Module is described as using LLM arbitration on execution feedback, but this is presented as an operational step whose reliability is evaluated externally rather than defined into the metrics. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can produce correct NPU kernels when supplied with appropriate hardware-aware executable knowledge
invented entities (3)
-
Run-Time Knowledge Synthesis Module
no independent evidence
-
Bottleneck-Aware Knowledge Retrieval Module
no independent evidence
-
Effect-Driven Knowledge Distillation Module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Xu, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, C. Linget al., “Deepseek-v4: Towards highly efficient million-token context intelligence,”arXiv preprint arXiv:2606.19348, 2026
-
[2]
Q. Team, “Qwen3. 5-omni technical report,”arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
GLM-5: from Vibe Coding to Agentic Engineering
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xieet al., “Glm-5: from vibe coding to agentic engineering,”arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
AscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units
X. Cao, J. Zhai, P. Li, Z. Hu, C. Yan, B. Mu, G. Fang, B. She, J. Li, Y . Suet al., “Ascendkernelgen: A systematic study of llm-based kernel generation for neural processing units,”arXiv preprint arXiv:2601.07160, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Y . Zheng, Z. Li, S. Zhang, H. Wang, J. Sheng, J. Wang, J. Yan, W. Zhang, Y . Wen, B. Tanget al., “Towards cold- start drafting and continual refining: A value-driven memory approach with application to npu kernel synthesis,”arXiv preprint arXiv:2603.10846, 2026
-
[7]
As- cendcraft: Automatic ascend npu kernel generation via dsl-guided transcompilation,
Z. Wen, S. Shao, Z. Li, Y . Ge, T. Xu, Y . Lin, and T. Zhang, “As- cendcraft: Automatic ascend npu kernel generation via dsl-guided transcompilation,”arXiv preprint arXiv:2601.22760, 2026
-
[8]
Akg: automatic kernel generation for neural processing units using polyhedral transformations,
J. Zhao, B. Li, W. Nie, Z. Geng, R. Zhang, X. Gao, B. Cheng, C. Wu, Y . Cheng, Z. Liet al., “Akg: automatic kernel generation for neural processing units using polyhedral transformations,” inProceedings of the 42nd ACM SIGPLAN International Con- ference on Programming Language Design and Implementation, 2021, pp. 1233–1248
2021
-
[9]
To- wards better answers: Automated stack overflow post updating,
Y . Mai, Z. Gao, H. Wang, T. Bi, X. Hu, X. Xia, and J. Sun, “To- wards better answers: Automated stack overflow post updating,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 591–603
2025
-
[10]
Morest: Model-based restful api testing with execution feedback,
Y . Liu, Y . Li, G. Deng, Y . Liu, R. Wan, R. Wu, D. Ji, S. Xu, and M. Bao, “Morest: Model-based restful api testing with execution feedback,” inProceedings of the 44th International Conference on Software Engineering, 2022, pp. 1406–1417
2022
-
[11]
Kernelllm: Making kernel development more accessible,
Z. V . Fisches, S. Paliskara, S. Guo, A. Zhang, J. Spisak, C. Cummins, H. Leather, G. Synnaeve, J. Isaacson, A. Markosyan, and M. Saroufim, “Kernelllm: Making kernel development more accessible,” 6 2025. [Online]. Available: https://huggingface.co/facebook/KernelLLM
2025
-
[12]
Reinforcement tuning open source llms for kernel generation
A. Garg, J. Heo, and M. Mou, “Reinforcement tuning open source llms for kernel generation.” [Online]. Available: https://api.semanticscholar.org/CorpusID:281103975
-
[13]
Tritonrl: Training llms to think and code triton without cheating,
J. Woo, S. Zhu, A. Nie, Z. Jia, Y . Wang, and Y . Park, “Tritonrl: Training llms to think and code triton without cheating,”arXiv preprint arXiv:2510.17891, 2025
-
[14]
React: Ir-level patch presence test for binary,
Q. Zhan, X. Hu, X. Xia, and S. Li, “React: Ir-level patch presence test for binary,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 381–392
2024
-
[15]
Type- alias analysis: Enabling llvm ir with accurate types,
J. Zhou, Z. Pan, W. Shen, X. Wang, K. Lu, and Z. Qian, “Type- alias analysis: Enabling llvm ir with accurate types,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 2203–2226, 2025
2025
-
[16]
Robust vul- nerability detection across compilations: Llvm-ir vs. assembly with transformer model,
R. Shir, P. Surve, Y . Elovici, and A. Shabtai, “Robust vul- nerability detection across compilations: Llvm-ir vs. assembly with transformer model,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 618–639, 2025
2025
-
[17]
The incredible shrinking context... in a decompiler near you,
S. Lagouvardos, Y . Bollanos, N. Grech, and Y . Smaragdakis, “The incredible shrinking context... in a decompiler near you,” Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 1350–1373, 2025
2025
-
[18]
Few-shot natural language to first-order logic translation via code generation,
J. Liu, “Few-shot natural language to first-order logic translation via code generation,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 10 939–10 960
2025
-
[19]
Why in-context learning models are good few-shot learners?
S. Wu, Y . Wang, and Q. Yao, “Why in-context learning models are good few-shot learners?” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[20]
A theory of emergent in-context learning as implicit structure induction
M. Hahn and N. Goyal, “A theory of emergent in-context learning as implicit structure induction,”arXiv preprint arXiv:2303.07971, 2023
-
[21]
On edge- fog-cloud collaboration and reaping its benefits: a heterogeneous multi-tier edge computing architecture,
N. Fernando, S. Shrestha, S. W. Loke, and K. Lee, “On edge- fog-cloud collaboration and reaping its benefits: a heterogeneous multi-tier edge computing architecture,”Future Internet, vol. 17, no. 1, p. 22, 2025
2025
-
[22]
Heterogeneous multi-computing-units based lt coded computation in wireless networks,
B. Fang and X. Qiao, “Heterogeneous multi-computing-units based lt coded computation in wireless networks,” in2026 IEEE Wireless Communications and Networking Conference (WCNC). IEEE, 2026, pp. 1–6
2026
-
[23]
Skybyte: architecting an efficient memory-semantic cxl-based ssd with os and hardware co-design,
H. Zhang, Y . Xue, Y . E. Zhou, S. Li, and J. Huang, “Skybyte: architecting an efficient memory-semantic cxl-based ssd with os and hardware co-design,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 577–593
2025
-
[24]
Faster and stronger: Unleashing data processing potential through hardware heterogeneity,
C. Wang, Y . Luo, W. Du, K. Wang, N. Gu, and J. Yu, “Faster and stronger: Unleashing data processing potential through hardware heterogeneity,”IEEE Internet of Things Journal, vol. 12, no. 10, pp. 14 559–14 576, 2025
2025
-
[25]
Cuda agent: Large-scale agentic rl for high-performance cuda kernel generation,
W. Dai, H. Wu, Q. Yu, H.-a. Gao, J. Li, C. Jiang, W. Lou, Y . Song, H. Yu, J. Chenet al., “Cuda agent: Large-scale agentic rl for high-performance cuda kernel generation,”arXiv preprint arXiv:2602.24286, 2026
-
[26]
Kevin: Multi-turn rl for generating cuda kernels,
C. Baronio, P. Marsella, B. Pan, S. Guo, and S. Alberti, “Kevin: Multi-turn rl for generating cuda kernels,”arXiv preprint arXiv:2507.11948, 2025
-
[27]
Cuda-l1: Improving cuda optimization via contrastive reinforcement learning,
X. Li, X. Sun, A. Wang, J. Li, and C. Shum, “Cuda-l1: Improving cuda optimization via contrastive reinforcement learning,”arXiv preprint arXiv:2507.14111, 2025
-
[28]
K. S. Dong, S. Modi, D. Nikiforov, S. Damani, E. Lin, S. K. S. Hari, and C. Kozyrakis, “Kernelblaster: Continual cross-task cuda optimization via memory-augmented in-context reinforcement learning,”arXiv preprint arXiv:2602.14293, 2026
-
[29]
Stark: Strategic team of agents for refining kernels,
J. Dong, Y . Yang, T. Liu, Y . Wang, F. Qi, V . Tarokh, K. Ran- gadurai, and S. Yang, “Stark: Strategic team of agents for refining kernels,”arXiv preprint arXiv:2510.16996, 2025
-
[30]
Cud- aforge: An agent framework with hardware feedback for cuda kernel optimization,
Z. Zhang, R. Wang, S. Li, Y . Luo, M. Hong, and C. Ding, “Cud- aforge: An agent framework with hardware feedback for cuda kernel optimization,”arXiv preprint arXiv:2511.01884, 2025
-
[31]
Avo: agentic variation operators for au- tonomous evolutionary search,
T. Chen, Z. Ye, B. Xu, Z. Ye, T. Liu, A. Hassani, T. Chen, A. Kerr, H. Wu, Y . Xuet al., “Avo: agentic variation operators for au- tonomous evolutionary search,”arXiv preprint arXiv:2603.24517, 2026
-
[32]
Multik- ernelbench: A multi-platform benchmark for kernel generation,
Z. Wen, Y . Zhang, Z. Li, Z. Liu, L. Xie, and T. Zhang, “Multik- ernelbench: A multi-platform benchmark for kernel generation,” arXiv e-prints, pp. arXiv–2507, 2025
2025
-
[33]
(2026) ops-nn
Huawei. (2026) ops-nn. [Online]. Available: https://gitcode.com/cann/ops-nn
2026
-
[34]
(2026) Cannbot
——. (2026) Cannbot. [Online]. Available: https://gitcode.com/cann/cannbot-skills
2026
-
[35]
Injecting the bm25 score as text improves bert-based re-rankers,
A. Askari, A. Abolghasemi, G. Pasi, W. Kraaij, and S. Verberne, “Injecting the bm25 score as text improves bert-based re-rankers,” inEuropean Conference on Information Retrieval. Springer, 2023, pp. 66–83
2023
-
[36]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Linet al., “Qwen3 embedding: Advancing text embedding and reranking through foundation models,”arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V . Cormack, C. L. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 2009, pp. 758–759
2009
-
[38]
Rag-fusion: a new take on retrieval-augmented generation.arXiv preprint arXiv:2402.03367, 2024
Z. Rackauckas, “Rag-fusion: a new take on retrieval-augmented generation,”arXiv preprint arXiv:2402.03367, 2024
-
[39]
Mmmorrf: Multimodal multilingual modularized reciprocal rank fusion,
S. Samuel, D. DeGenaro, J. Guallar-Blasco, K. Sanders, S. Eis- ape, A. Reddy, A. Martin, A. Yates, E. Yang, C. Carpenteret al., “Mmmorrf: Multimodal multilingual modularized reciprocal rank fusion,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Re- trieval, 2025, pp. 4004–4009
2025
-
[40]
Does few-shot learning help llm performance in code synthesis?
D. Xu, T. Xie, B. Xia, H. Li, Y . Bai, Y . Sun, and W. Wang, “Does few-shot learning help llm performance in code synthesis?”arXiv preprint arXiv:2412.02906, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.