Decentralized Stochastic Subgradient-type Methods with Communication Compression for Nonsmooth Nonconvex Optimization
Pith reviewed 2026-07-03 08:45 UTC · model grok-4.3
The pith
Relating iterates to differential inclusion trajectories establishes global convergence of compressed decentralized subgradient methods for nonsmooth nonconvex problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By relating the consensus-error iterates and the averaged iterates to the trajectories of continuous-time differential inclusions, global convergence is established for all methods encompassed by the framework when the objective functions are nonsmooth and lack Clarke regularity.
What carries the argument
Relating consensus-error iterates and averaged iterates to trajectories of continuous-time differential inclusions
If this is right
- Global convergence holds for every method inside the framework under the stated nonsmooth nonconvex conditions.
- Both unbiased compression and contractive compression with error compensation are covered by the same convergence argument.
- New methods built inside the framework, such as sign-based regularization variants and gradient-tracking momentum variants, inherit the global convergence guarantee.
- Numerical experiments confirm practical viability and expose the communication-accuracy trade-off for the newly constructed methods.
Where Pith is reading between the lines
- The differential-inclusion technique may extend to deriving convergence rates or stability margins not addressed in the paper.
- Similar continuous-time embeddings could analyze other distributed algorithms that combine compression with nonsmooth objectives.
- In large-scale settings the framework suggests that communication budgets can be reduced while preserving global convergence for irregular loss landscapes.
Load-bearing premise
The discrete algorithm dynamics are accurately captured by the continuous-time differential inclusions for establishing global convergence.
What would settle it
A concrete instance of a nonsmooth nonconvex objective and a valid compression operator where an encompassed method diverges despite the differential inclusion trajectory predicting convergence.
Figures
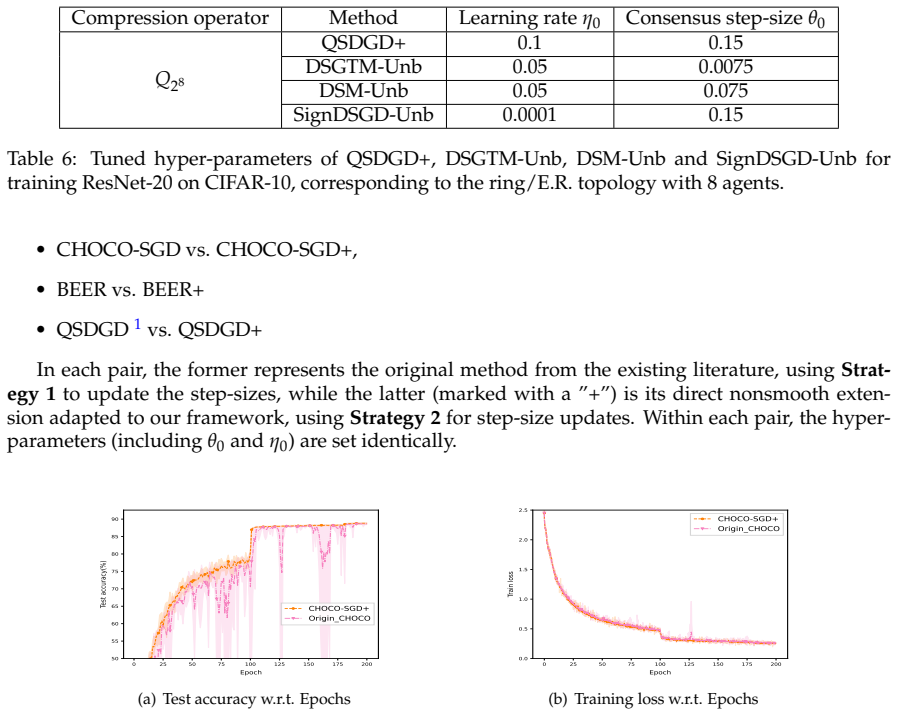
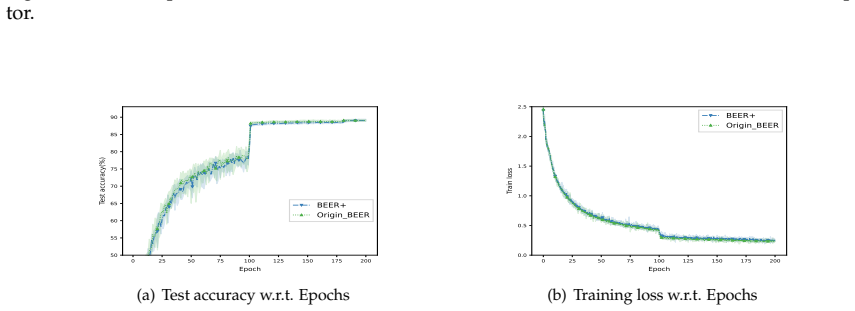
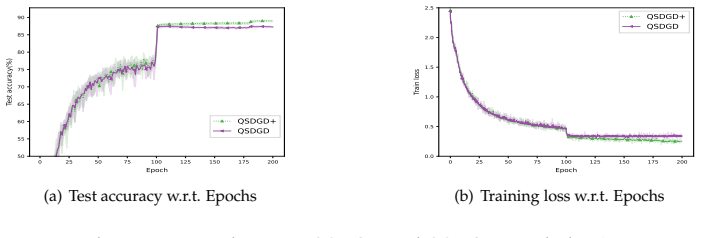
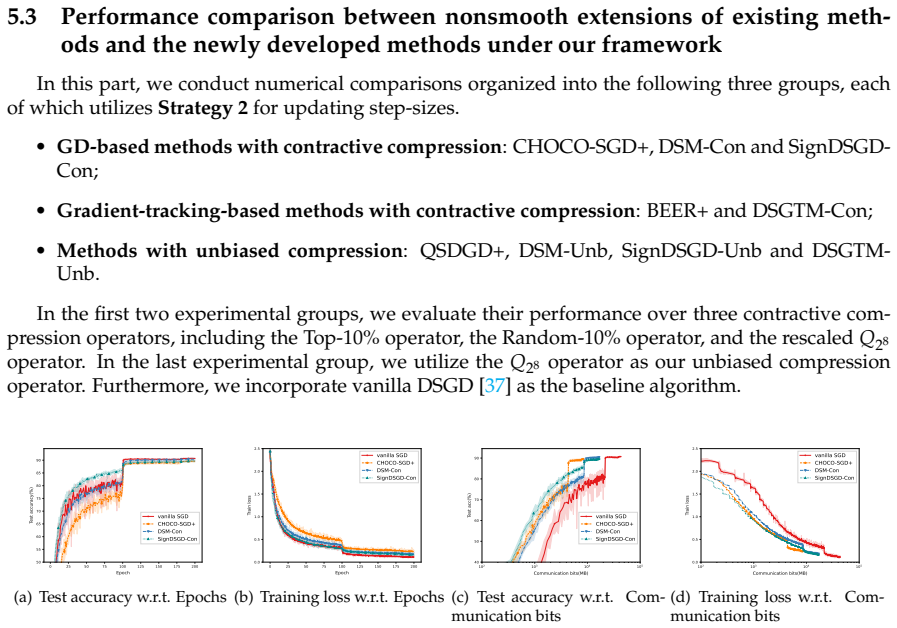
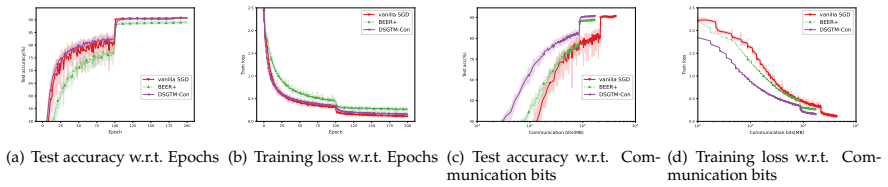
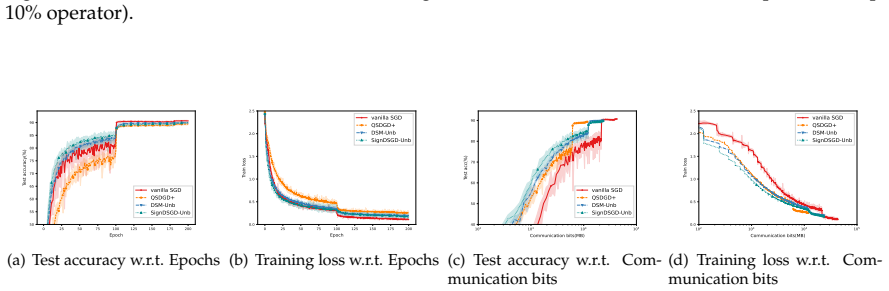
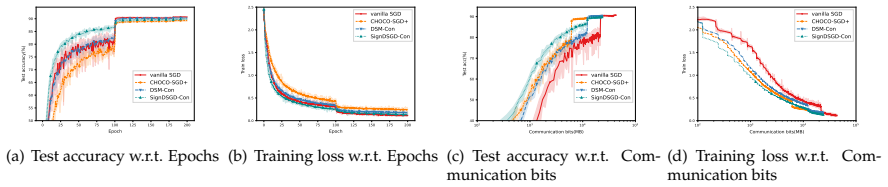
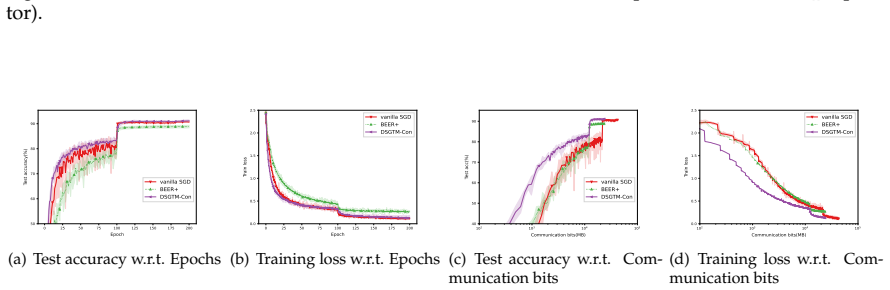
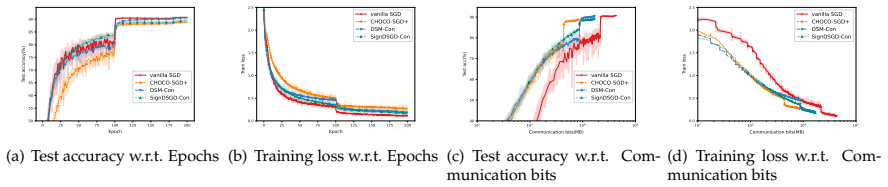
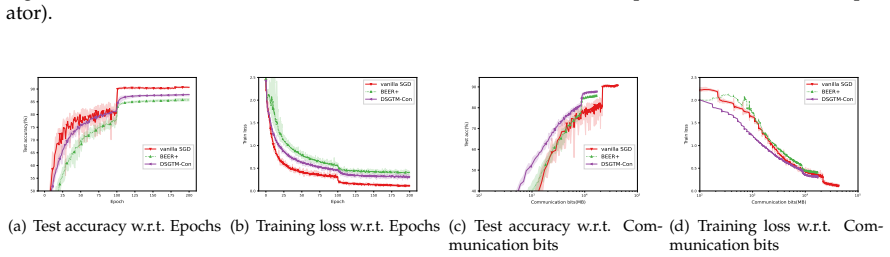
read the original abstract
In this paper, we consider the nonsmooth nonconvex decentralized optimization problem, where inter-agent communication is compressed. We propose a general framework that unifies various decentralized stochastic subgradient-type methods with unbiased compression and contractive compression with error compensation. By relating the consensus-error iterates and the averaged iterates to the trajectories of continuous-time differential inclusions, we establish global convergence for all methods encompassed by our framework when the objective functions are nonsmooth and lack Clarke regularity. Based on our framework, we further develop several compression-based methods, including decentralized stochastic subgradient methods utilizing sign-based regularization and gradient-tracking momentum. Preliminary numerical experiments empirically support our theoretical results and highlight the communication-accuracy trade-off of the newly developed methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a general framework unifying various decentralized stochastic subgradient-type methods that incorporate communication compression (covering both unbiased operators and contractive operators with error compensation) for nonsmooth nonconvex decentralized optimization problems. It claims to establish global convergence of all methods in the framework by relating the consensus-error iterates and the averaged iterates to trajectories of continuous-time differential inclusions, without requiring Clarke regularity of the objective functions. Based on the framework, new methods are developed (including sign-based regularization and gradient-tracking momentum variants), and preliminary numerical experiments are presented to support the theory and illustrate communication-accuracy trade-offs.
Significance. If the convergence result holds with the claimed generality, the work would be a meaningful contribution to decentralized optimization by extending convergence guarantees to nonsmooth nonconvex settings without Clarke regularity while accommodating practical compression schemes. The unification of compression types and the differential-inclusion technique for handling nonsmoothness are technical strengths; the new method variants and empirical illustrations of the trade-off add applied value for distributed learning scenarios.
major comments (1)
- [Abstract and convergence analysis] Abstract and convergence analysis section: the central claim that relating consensus-error and averaged iterates to DI trajectories yields global convergence for nonsmooth objectives lacking Clarke regularity is load-bearing. The discrete dynamics include stochastic subgradient noise plus compression-induced errors; it is unclear how the approximation error between the discrete stochastic compressed iterates and the DI trajectories is controlled uniformly as the step-size tends to zero, given that the DI may admit multiple solutions or lack a uniform Lyapunov decrease without regularity. Explicit error bounds or lemmas establishing this limit (independent of the nonsmoothness) are needed to secure the result.
minor comments (2)
- [Abstract] Abstract: the statement that 'preliminary numerical experiments empirically support our theoretical results' would be strengthened by including at least one quantitative performance metric or setup detail rather than remaining purely qualitative.
- [Framework section] Notation and assumptions: the precise definitions of the unbiased and contractive-with-error-compensation properties for the compression operators should be stated with equation numbers in the framework section for immediate reference when reading the convergence argument.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comment on the convergence analysis. We address the concern below and will revise the manuscript to provide the requested explicit bounds.
read point-by-point responses
-
Referee: [Abstract and convergence analysis] Abstract and convergence analysis section: the central claim that relating consensus-error and averaged iterates to DI trajectories yields global convergence for nonsmooth objectives lacking Clarke regularity is load-bearing. The discrete dynamics include stochastic subgradient noise plus compression-induced errors; it is unclear how the approximation error between the discrete stochastic compressed iterates and the DI trajectories is controlled uniformly as the step-size tends to zero, given that the DI may admit multiple solutions or lack a uniform Lyapunov decrease without regularity. Explicit error bounds or lemmas establishing this limit (independent of the nonsmoothness) are needed to secure the result.
Authors: We appreciate this observation on the load-bearing step of the analysis. The manuscript adapts standard stochastic approximation arguments to show that the consensus-error and averaged iterates track DI trajectories in the limit, with the compression operators (unbiased or contractive with error compensation) and stochastic subgradient noise incorporated via bounded variance assumptions. However, we agree that the uniform control of the approximation error as the step-size tends to zero—particularly when the DI may have multiple solutions and without a uniform Lyapunov function—would benefit from an explicit lemma independent of Clarke regularity. In the revision we will insert a new lemma (in the convergence analysis section or appendix) deriving such bounds using only the Lipschitz continuity of the compression maps, bounded subgradient norms, and standard martingale convergence tools; this will make the passage to the limit fully rigorous without additional regularity. revision: yes
Circularity Check
No significant circularity; convergence via standard DI techniques is self-contained
full rationale
The abstract and description indicate the central step relates discrete consensus-error and averaged iterates to continuous-time differential inclusion trajectories to obtain global convergence for nonsmooth nonconvex problems. This is a standard external technique (not a self-definition, fitted prediction, or self-citation reduction). No quotes or equations in the provided material exhibit any of the enumerated circular patterns; the framework unifies existing methods and develops new ones without the result being forced by its own inputs. The analysis is therefore self-contained against external DI theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Compression operators are either unbiased or contractive with error compensation.
- domain assumption Differential inclusions accurately model the discrete consensus and averaged iterates for convergence analysis.
Reference graph
Works this paper leans on
-
[1]
Qsgd: Communication-efficient sgd via gradient quantization and encoding.Advances in neural in- formation processing systems, 30, 2017
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan Vojnovic. Qsgd: Communication-efficient sgd via gradient quantization and encoding.Advances in neural in- formation processing systems, 30, 2017
2017
-
[2]
The convergence of sparsified gradient methods.Advances in Neural Information Pro- cessing Systems, 31, 2018
Dan Alistarh, Torsten Hoefler, Mikael Johansson, Nikola Konstantinov, Sarit Khirirat, and C´edric Renggli. The convergence of sparsified gradient methods.Advances in Neural Information Pro- cessing Systems, 31, 2018
2018
-
[3]
Dynamics of stochastic approximation algorithms
Michel Bena ¨ım. Dynamics of stochastic approximation algorithms. InSeminaire de Probabilites XXXIII, pages 1–68. Springer, 2006
2006
-
[4]
Stochastic approximations and differential inclusions.SIAM Journal on Control and Optimization, 44(1):328–348, 2005
Michel Bena ¨ım, Josef Hofbauer, and Sylvain Sorin. Stochastic approximations and differential inclusions.SIAM Journal on Control and Optimization, 44(1):328–348, 2005
2005
-
[5]
Signsgd: Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. Signsgd: Compressed optimisation for non-convex problems. InInternational Conference on Ma- chine Learning, pages 560–569. PMLR, 2018
2018
-
[6]
signSGD with Majority Vote is Communication Efficient And Fault Tolerant
Jeremy Bernstein, Jiawei Zhao, Kamyar Azizzadenesheli, and Anima Anandkumar. signsgd with majority vote is communication efficient and fault tolerant.arXiv preprint arXiv:1810.05291, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
On biased com- pression for distributed learning.Journal of Machine Learning Research, 24(276):1–50, 2023
Aleksandr Beznosikov, Samuel Horv ´ath, Peter Richt ´arik, and Mher Safaryan. On biased com- pression for distributed learning.Journal of Machine Learning Research, 24(276):1–50, 2023
2023
-
[8]
Subgradient-based neural networks for nonsmooth nonconvex optimization problems.IEEE Transactions on Neural Networks, 20(6):1024–1038, 2009
Wei Bian and Xiaoping Xue. Subgradient-based neural networks for nonsmooth nonconvex optimization problems.IEEE Transactions on Neural Networks, 20(6):1024–1038, 2009
2009
-
[9]
Clarke subgradients of strati- fiable functions.SIAM Journal on Optimization, 18(2):556–572, 2007
J ´erˆome Bolte, Aris Daniilidis, Adrian Lewis, and Masahiro Shiota. Clarke subgradients of strati- fiable functions.SIAM Journal on Optimization, 18(2):556–572, 2007
2007
-
[10]
A mathematical model for automatic differentiation in machine learning.Advances in Neural Information Processing Systems, 33:10809–10819, 2020
J ´erˆome Bolte and Edouard Pauwels. A mathematical model for automatic differentiation in machine learning.Advances in Neural Information Processing Systems, 33:10809–10819, 2020
2020
-
[11]
Conservative set valued fields, automatic differentiation, stochastic gradient methods and deep learning.Mathematical Programming, 188(1):19–51, 2021
J ´erˆome Bolte and Edouard Pauwels. Conservative set valued fields, automatic differentiation, stochastic gradient methods and deep learning.Mathematical Programming, 188(1):19–51, 2021
2021
-
[12]
Federated learning and privacy: Building privacy-preserving systems for machine learning and data science on decentralized data.Queue, 19(5):87–114, 2021
Kallista Bonawitz, Peter Kairouz, Brendan McMahan, and Daniel Ramage. Federated learning and privacy: Building privacy-preserving systems for machine learning and data science on decentralized data.Queue, 19(5):87–114, 2021
2021
-
[13]
Springer, 2009
Vivek S Borkar.Stochastic approximation: a dynamical systems viewpoint, volume 48. Springer, 2009
2009
-
[14]
Springer, 2008
Vivek S Borkar and Vivek S Borkar.Stochastic approximation: a dynamical systems viewpoint, vol- ume 9. Springer, 2008
2008
-
[15]
An inertial newton algo- rithm for deep learning.The Journal of Machine Learning Research, 22(1):5977–6007, 2021
Camille Castera, J ´erˆome Bolte, C ´edric F´evotte, and Edouard Pauwels. An inertial newton algo- rithm for deep learning.The Journal of Machine Learning Research, 22(1):5977–6007, 2021
2021
-
[16]
A decentralized framework for server- less edge computing in the internet of things.IEEE Transactions on Network and Service Manage- ment, 18(2):2166–2180, 2020
Claudio Cicconetti, Marco Conti, and Andrea Passarella. A decentralized framework for server- less edge computing in the internet of things.IEEE Transactions on Network and Service Manage- ment, 18(2):2166–2180, 2020. 27
2020
-
[17]
Springer Science & Business Media, 2008
Francis H Clarke, Yuri S Ledyaev, Ronald J Stern, and Peter R Wolenski.Nonsmooth analysis and control theory, volume 178. Springer Science & Business Media, 2008
2008
-
[18]
SIAM, 1990
Frank H Clarke.Optimization and nonsmooth analysis, volume 5. SIAM, 1990
1990
-
[19]
Stochastic subgradient method converges on tame functions.Foundations of Computational Mathematics, 20(1):119–154, 2020
Damek Davis, Dmitriy Drusvyatskiy, Sham Kakade, and Jason D Lee. Stochastic subgradient method converges on tame functions.Foundations of Computational Mathematics, 20(1):119–154, 2020
2020
-
[20]
Edge intelligence: The confluence of edge computing and artificial intelligence.IEEE Internet of Things Journal, 7(8):7457–7469, 2020
Shuiguang Deng, Hailiang Zhao, Weijia Fang, Jianwei Yin, Schahram Dustdar, and Albert Y Zomaya. Edge intelligence: The confluence of edge computing and artificial intelligence.IEEE Internet of Things Journal, 7(8):7457–7469, 2020
2020
-
[21]
Convergence rates of distributed gra- dient methods under random quantization: A stochastic approximation approach.IEEE Trans- actions on Automatic Control, 66(10):4469–4484, 2020
Thinh T Doan, Siva Theja Maguluri, and Justin Romberg. Convergence rates of distributed gra- dient methods under random quantization: A stochastic approximation approach.IEEE Trans- actions on Automatic Control, 66(10):4469–4484, 2020
2020
-
[22]
Stochastic methods for composite and weakly convex optimiza- tion problems.SIAM Journal on Optimization, 28(4):3229–3259, 2018
John C Duchi and Feng Ruan. Stochastic methods for composite and weakly convex optimiza- tion problems.SIAM Journal on Optimization, 28(4):3229–3259, 2018
2018
-
[23]
Ilyas Fatkhullin, Igor Sokolov, Eduard Gorbunov, Zhize Li, and Peter Richt ´arik. Ef21 with bells & whistles: Practical algorithmic extensions of modern error feedback.arXiv preprint arXiv:2110.03294, 2021
-
[24]
Consensus multi-agent reinforcement learning for volt-var control in power distribution networks.IEEE Transactions on Smart Grid, 12(4):3594– 3604, 2021
Yuanqi Gao, Wei Wang, and Nanpeng Yu. Consensus multi-agent reinforcement learning for volt-var control in power distribution networks.IEEE Transactions on Smart Grid, 12(4):3594– 3604, 2021
2021
-
[25]
Natural compression for distributed deep learning
Samuel Horv ´oth, Chen-Yu Ho, Ludovit Horvath, Atal Narayan Sahu, Marco Canini, and Peter Richt´arik. Natural compression for distributed deep learning. InMathematical and Scientific Machine Learning, pages 129–141. PMLR, 2022
2022
-
[26]
Lower bounds and nearly optimal algorithms in distributed learning with communication compression.Advances in Neural Infor- mation Processing Systems, 35:18955–18969, 2022
Xinmeng Huang, Yiming Chen, Wotao Yin, and Kun Yuan. Lower bounds and nearly optimal algorithms in distributed learning with communication compression.Advances in Neural Infor- mation Processing Systems, 35:18955–18969, 2022
2022
-
[27]
S-near-dgd: A flexible distributed stochastic gradient method for inexact communication.IEEE Transactions on Automatic Control, 68(2):1281–1287, 2022
Charikleia Iakovidou and Ermin Wei. S-near-dgd: A flexible distributed stochastic gradient method for inexact communication.IEEE Transactions on Automatic Control, 68(2):1281–1287, 2022
2022
- [28]
-
[29]
Lyapunov stability of the subgradient method with constant step size.Mathematical Programming, 202(1):387–396, 2023
C ´edric Josz and Lexiao Lai. Lyapunov stability of the subgradient method with constant step size.Mathematical Programming, 202(1):387–396, 2023
2023
-
[30]
Privacy-preserving decentralized learning framework for healthcare system.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 17(2s):1–24, 2021
Harsh Kasyap and Somanath Tripathy. Privacy-preserving decentralized learning framework for healthcare system.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 17(2s):1–24, 2021
2021
-
[31]
Anastasia Koloskova, Tao Lin, Sebastian U Stich, and Martin Jaggi. Decentralized deep learning with arbitrary communication compression.arXiv preprint arXiv:1907.09356, 2019
-
[32]
Decentralized stochastic optimization and gossip algorithms with compressed communication
Anastasia Koloskova, Sebastian Stich, and Martin Jaggi. Decentralized stochastic optimization and gossip algorithms with compressed communication. InInternational Conference on Machine Learning, pages 3478–3487. PMLR, 2019
2019
-
[33]
Nonsmooth nonconvex stochastic heavy ball.Journal of Optimization Theory and Applica- tions, 201(2):699–719, 2024
Tam Le. Nonsmooth nonconvex stochastic heavy ball.Journal of Optimization Theory and Applica- tions, 201(2):699–719, 2024. 28
2024
-
[34]
Xin Liu Lei Wang. A variance-reduced stochastic gradient tracking algorithm for decentralized optimization with orthogonality constraints.Journal of Industrial and Management Optimization, 19(10):7753–7776, 2023
2023
-
[35]
Distributed subgradient method for multi- agent optimization with quantized communication.Mathematical Methods in the Applied Sciences, 40(4):1201–1213, 2017
Jueyou Li, Guo Chen, Zhiyou Wu, and Xing He. Distributed subgradient method for multi- agent optimization with quantized communication.Mathematical Methods in the Applied Sciences, 40(4):1201–1213, 2017
2017
-
[36]
Decentralized composite optimiza- tion with compression.arXiv preprint arXiv:2108.04448, 2021
Yao Li, Xiaorui Liu, Jiliang Tang, Ming Yan, and Kun Yuan. Decentralized composite optimiza- tion with compression.arXiv preprint arXiv:2108.04448, 2021
-
[37]
Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent.Advances in neural information processing systems, 30, 2017
2017
-
[38]
A compressed gradient tracking method for decentralized optimization with linear convergence.IEEE Transactions on Automatic Control, 67(10):5622–5629, 2022
Yiwei Liao, Zhuorui Li, Kun Huang, and Shi Pu. A compressed gradient tracking method for decentralized optimization with linear convergence.IEEE Transactions on Automatic Control, 67(10):5622–5629, 2022
2022
-
[39]
Yiwei Liao, Zhuorui Li, Shi Pu, and Tsung-Hui Chang. A robust compressed push-pull method for decentralized nonconvex optimization.arXiv preprint arXiv:2408.01727, 2024
-
[40]
Slota, Naigang Wang, Jie Chen, and Yangyang Xu
Wei Liu, Anweshit Panda, Ujwal Pandey, Christopher Brissette, Yikang Shen, George M. Slota, Naigang Wang, Jie Chen, and Yangyang Xu. Compressed decentralized momentum stochastic gradient methods for nonconvex optimization, 2025
2025
-
[41]
Learning- driven decentralized machine learning in resource-constrained wireless edge computing
Zeyu Meng, Hongli Xu, Min Chen, Yang Xu, Yangming Zhao, and Chunming Qiao. Learning- driven decentralized machine learning in resource-constrained wireless edge computing. In IEEE INFOCOM 2021-IEEE Conference on Computer Communications, pages 1–10. IEEE, 2021
2021
-
[42]
Critical random graphs: diameter and mixing time
Asaf Nachmias and Yuval Peres. Critical random graphs: diameter and mixing time. 2008
2008
-
[43]
Differential error feedback for communication-efficient decentralized learning.IEEE Transactions on Signal Processing, 2025
Roula Nassif, Stefan Vlaski, Marco Carpentiero, Vincenzo Matta, and Ali H Sayed. Differential error feedback for communication-efficient decentralized learning.IEEE Transactions on Signal Processing, 2025
2025
-
[44]
Network topology and communication- computation tradeoffs in decentralized optimization.Proceedings of the IEEE, 106(5):953–976, 2018
Angelia Nedi ´c, Alex Olshevsky, and Michael G Rabbat. Network topology and communication- computation tradeoffs in decentralized optimization.Proceedings of the IEEE, 106(5):953–976, 2018
2018
-
[45]
A method of solving a convex programming problem with con- vergence rate o\bigl(kˆ2\bigr)
Yurii Evgen’evich Nesterov. A method of solving a convex programming problem with con- vergence rate o\bigl(kˆ2\bigr). InDoklady Akademii Nauk, volume 269, pages 543–547. Russian Academy of Sciences, 1983
1983
-
[46]
Incremental without replacement sampling in nonconvex optimization.Jour- nal of Optimization Theory and Applications, 190(1):274–299, 2021
Edouard Pauwels. Incremental without replacement sampling in nonconvex optimization.Jour- nal of Optimization Theory and Applications, 190(1):274–299, 2021
2021
-
[47]
The perron-frobenius theorem: some of its applications.IEEE Signal Processing Magazine, 22(2):62–75, 2005
S Unnikrishna Pillai, Torsten Suel, and Seunghun Cha. The perron-frobenius theorem: some of its applications.IEEE Signal Processing Magazine, 22(2):62–75, 2005
2005
-
[48]
Some methods of speeding up the convergence of iteration methods.Ussr computational mathematics and mathematical physics, 4(5):1–17, 1964
Boris T Polyak. Some methods of speeding up the convergence of iteration methods.Ussr computational mathematics and mathematical physics, 4(5):1–17, 1964
1964
-
[49]
Noise reduction by swarming in social foraging.IEEE Transactions on Automatic Control, 61(12):4007–4013, 2016
Shi Pu, Alfredo Garcia, and Zongli Lin. Noise reduction by swarming in social foraging.IEEE Transactions on Automatic Control, 61(12):4007–4013, 2016
2016
-
[50]
Error compensated distributed sgd can be acceler- ated.Advances in Neural Information Processing Systems, 34:30401–30413, 2021
Xun Qian, Peter Richt ´arik, and Tong Zhang. Error compensated distributed sgd can be acceler- ated.Advances in Neural Information Processing Systems, 34:30401–30413, 2021. 29
2021
-
[51]
An ex- act quantized decentralized gradient descent algorithm.IEEE Transactions on Signal Processing, 67(19):4934–4947, 2019
Amirhossein Reisizadeh, Aryan Mokhtari, Hamed Hassani, and Ramtin Pedarsani. An ex- act quantized decentralized gradient descent algorithm.IEEE Transactions on Signal Processing, 67(19):4934–4947, 2019
2019
-
[52]
Ef21: A new, simpler, theoretically better, and practically faster error feedback.Advances in Neural Information Processing Systems, 34:4384–4396, 2021
Peter Richt ´arik, Igor Sokolov, and Ilyas Fatkhullin. Ef21: A new, simpler, theoretically better, and practically faster error feedback.Advances in Neural Information Processing Systems, 34:4384–4396, 2021
2021
-
[53]
Robbins and D
H. Robbins and D. Siegmund. A convergence theorem for non negative almost supermartin- gales and some applications**research supported by nih grant 5-r01-gm-16895-03 and onr grant n00014-67-a-0108-0018. In Jagdish S. Rustagi, editor,Optimizing Methods in Statistics, pages 233–
-
[54]
Academic Press, 1971
1971
-
[55]
Suhail M Shah and Raghu Bollapragada. A stochastic gradient tracking algorithm for decentral- ized optimization with inexact communication.arXiv preprint arXiv:2307.14942, 2023
-
[56]
Extra: An exact first-order algorithm for decen- tralized consensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
Wei Shi, Qing Ling, Gang Wu, and Wotao Yin. Extra: An exact first-order algorithm for decen- tralized consensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
2015
-
[57]
Squarm-sgd: Communication- efficient momentum sgd for decentralized optimization.IEEE Journal on Selected Areas in Infor- mation Theory, 2(3):954–969, 2021
Navjot Singh, Deepesh Data, Jemin George, and Suhas Diggavi. Squarm-sgd: Communication- efficient momentum sgd for decentralized optimization.IEEE Journal on Selected Areas in Infor- mation Theory, 2(3):954–969, 2021
2021
-
[58]
Sparq-sgd: Event-triggered and compressed communication in decentralized optimization.IEEE Transactions on Automatic Control, 68(2):721–736, 2022
Navjot Singh, Deepesh Data, Jemin George, and Suhas Diggavi. Sparq-sgd: Event-triggered and compressed communication in decentralized optimization.IEEE Transactions on Automatic Control, 68(2):721–736, 2022
2022
-
[59]
Sparsified sgd with memory
Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified sgd with memory. Advances in neural information processing systems, 31, 2018
2018
-
[60]
Distributed anonymous mobile robots: Formation of geometric patterns.SIAM Journal on Computing, 28(4):1347–1363, 1999
Ichiro Suzuki and Masafumi Yamashita. Distributed anonymous mobile robots: Formation of geometric patterns.SIAM Journal on Computing, 28(4):1347–1363, 1999
1999
-
[61]
Communication compression for decentralized training.Advances in Neural Information Processing Systems, 31, 2018
Hanlin Tang, Shaoduo Gan, Ce Zhang, Tong Zhang, and Ji Liu. Communication compression for decentralized training.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[62]
Learning structured sparsity in deep neural networks.Advances in neural information processing systems, 29, 2016
Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Learning structured sparsity in deep neural networks.Advances in neural information processing systems, 29, 2016
2016
-
[63]
Terngrad: Ternary gradients to reduce communication in distributed deep learning.Advances in neural information processing systems, 30, 2017
Wei Wen, Cong Xu, Feng Yan, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Terngrad: Ternary gradients to reduce communication in distributed deep learning.Advances in neural information processing systems, 30, 2017
2017
-
[64]
Fast linear iterations for distributed averaging.Systems & Control Letters, 53(1):65–78, 2004
Lin Xiao and Stephen Boyd. Fast linear iterations for distributed averaging.Systems & Control Letters, 53(1):65–78, 2004
2004
-
[65]
Distributed average consensus with time-varying metropolis weights.Automatica, 1, 2006
Lin Xiao, Stephen Boyd, and Sanjay Lall. Distributed average consensus with time-varying metropolis weights.Automatica, 1, 2006
2006
-
[66]
Nachuan Xiao, Xiaoyin Hu, Xin Liu, and Kim-Chuan Toh. Adam-family methods for nonsmooth optimization with convergence guarantees.arXiv preprint arXiv:2305.03938, 2023
-
[67]
Nachuan Xiao, Xiaoyin Hu, and Kim-Chuan Toh. Convergence guarantees for stochastic sub- gradient methods in nonsmooth nonconvex optimization.arXiv preprint arXiv:2307.10053, 2023
-
[68]
Compressed decentralized proximal stochastic gradient method for nonconvex composite problems with het- erogeneous data
Yonggui Yan, Jie Chen, Pin-Yu Chen, Xiaodong Cui, Songtao Lu, and Yangyang Xu. Compressed decentralized proximal stochastic gradient method for nonconvex composite problems with het- erogeneous data. InInternational Conference on Machine Learning, pages 39035–39061. PMLR, 2023
2023
-
[69]
Chung-Yiu Yau and Hoi-To Wai. Docom: Compressed decentralized optimization with near- optimal sample complexity.arXiv preprint arXiv:2202.00255, 2022. 30
-
[70]
Zipml: Training linear models with end-to-end low precision, and a little bit of deep learning
Hantian Zhang, Jerry Li, Kaan Kara, Dan Alistarh, Ji Liu, and Ce Zhang. Zipml: Training linear models with end-to-end low precision, and a little bit of deep learning. InInternational Conference on Machine Learning, pages 4035–4043. PMLR, 2017
2017
-
[71]
Multi-agent reinforcement learning: A selec- tive overview of theories and algorithms.Handbook of reinforcement learning and control, pages 321–384, 2021
Kaiqing Zhang, Zhuoran Yang, and Tamer Bas ¸ar. Multi-agent reinforcement learning: A selec- tive overview of theories and algorithms.Handbook of reinforcement learning and control, pages 321–384, 2021
2021
-
[72]
Siyuan Zhang, Nachuan Xiao, and Xin Liu. Decentralized stochastic subgradient methods for nonsmooth nonconvex optimization.arXiv preprint arXiv:2403.11565, 2024
-
[73]
Beer: Fasto(1/t)rate for decentralized nonconvex optimization with communication compression.Advances in Neural Information Processing Systems, 35:31653–31667, 2022
Haoyu Zhao, Boyue Li, Zhize Li, Peter Richt ´arik, and Yuejie Chi. Beer: Fasto(1/t)rate for decentralized nonconvex optimization with communication compression.Advances in Neural Information Processing Systems, 35:31653–31667, 2022
2022
-
[74]
Communication-efficient distributed blockwise momentum sgd with error-feedback.Advances in Neural Information Processing Systems, 32, 2019
Shuai Zheng, Ziyue Huang, and James Kwok. Communication-efficient distributed blockwise momentum sgd with error-feedback.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[75]
Zehan Zhu, Heng Zhao, Yan Huang, Joey Tianyi Zhou, Shouling Ji, and Jinming Xu. Dp-csgp: Differentially private stochastic gradient push with compressed communication.arXiv preprint arXiv:2512.13583, 2025
-
[76]
Ensembles semi-analytiques
Stanisław Łojasiewicz. Ensembles semi-analytiques. 1965. Appendix 6.1 Proof of Lemma 3.8 Proof.A straightforward calculation shows that, for anyN∈N ∗, aγk + k ∑ i=N k ∏ j=i (1−aγ j)aγi−1 + k ∏ j=N−1 (1−aγ j) =aγ k + k ∑ i=N+1 k ∏ j=i (1−aγ j)aγi−1 + k ∏ j=N (1−aγ j)aγ N−1 + k ∏ j=N (1−aγ j)(1−aγ N−1 ) =aγ k + k ∑ i=N+1 k ∏ j=i (1−aγ j)aγi−1 + k ∏ j=N (1−a...
1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.