Subliminal Clocks: Latent Time Modelling in Diffusion Language Models
Pith reviewed 2026-07-03 13:45 UTC · model grok-4.3
The pith
Diffusion language models encode a latent representation of denoising progress inside their residual streams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
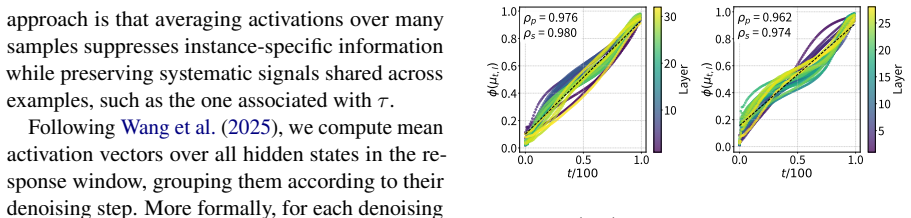
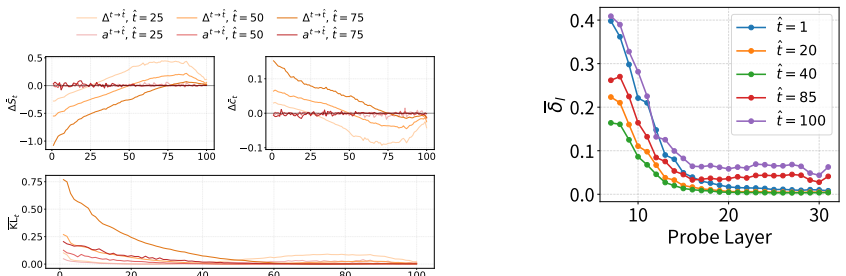
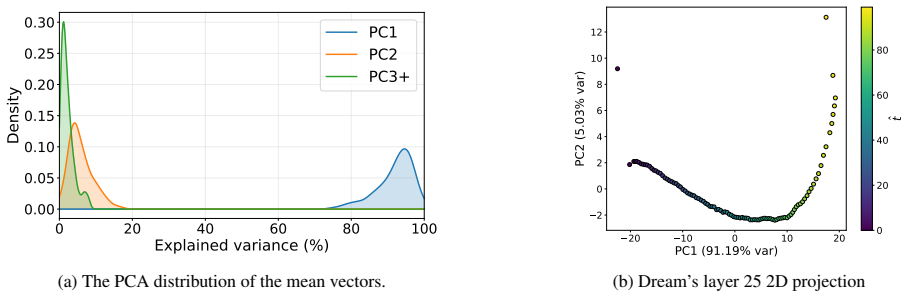
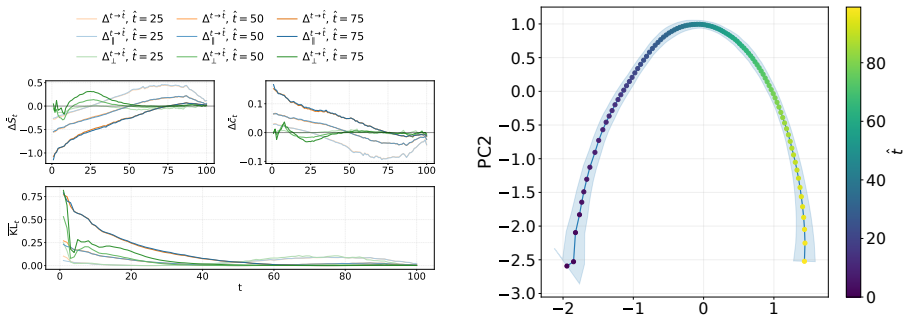
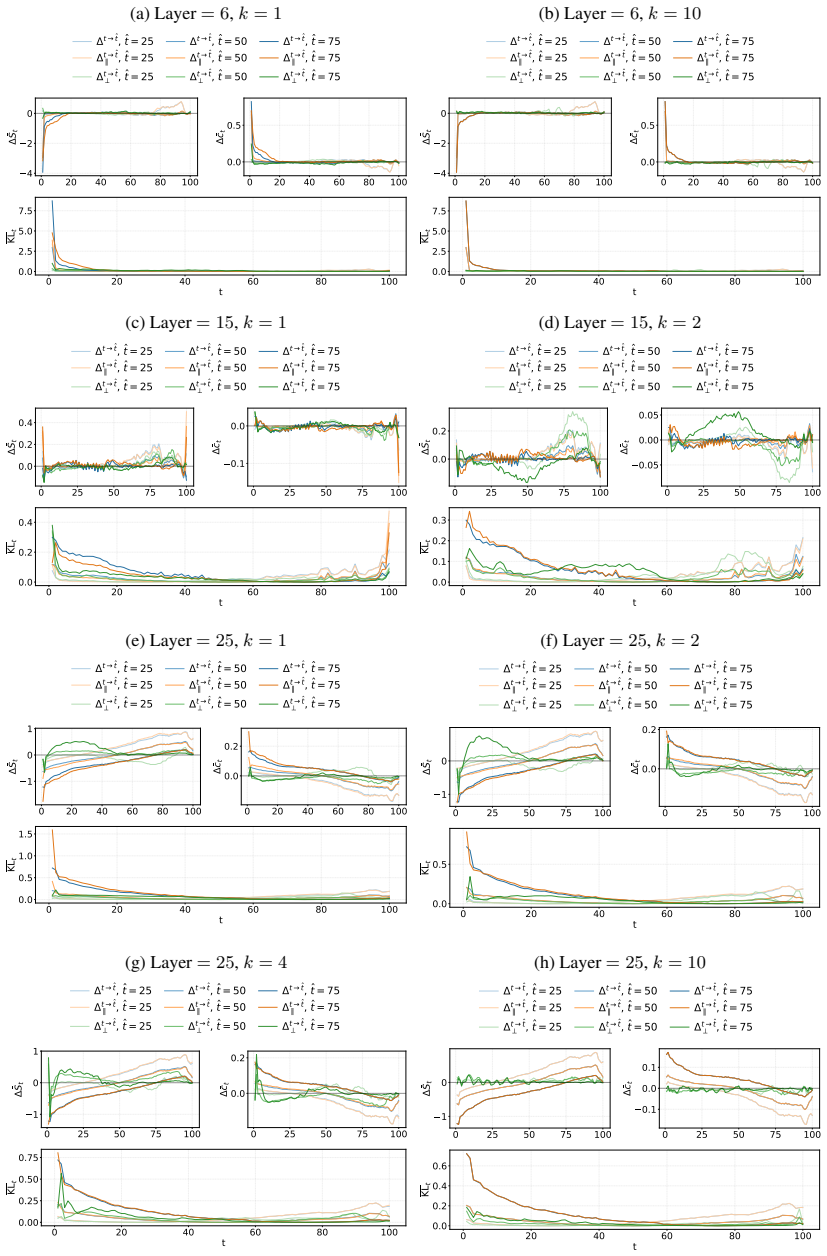
DLMs encode a latent representation related to the diffusion timestep within their residual streams. This signal can be reliably extracted using probes across layers, indicating that denoising progress is decodable from internal activations. Steering the model along a low-dimensional subspace associated with the inferred timestep systematically modulates its notion of denoising progress, leading to predictable changes in model confidence and entropy. The representation exhibits structured and interpretable properties in activation space.
What carries the argument
Linear probes that extract a timestep-related direction from residual-stream activations, together with the low-dimensional subspace used to steer that direction.
If this is right
- Denoising progress is decodable from internal activations across layers.
- Steering along the timestep subspace produces systematic, predictable shifts in model confidence and entropy.
- The representation shows structured geometry in activation space that can be interpreted.
- The model maintains an implicit notion of time that influences its generation behavior.
Where Pith is reading between the lines
- The latent signal could be used to control generation length or quality without changing the training procedure.
- Similar internal clocks may appear in other diffusion or iterative generative models.
- Interventions on this subspace might offer a new way to debug or regularize sampling trajectories.
Load-bearing premise
The direction found by the probes corresponds to a causal encoding of denoising progress rather than a byproduct of other generation statistics.
What would settle it
Steering along the identified subspace produces no consistent shift in next-token entropy or confidence, or the probe fails to predict the true timestep on new samples from the same model.
Figures


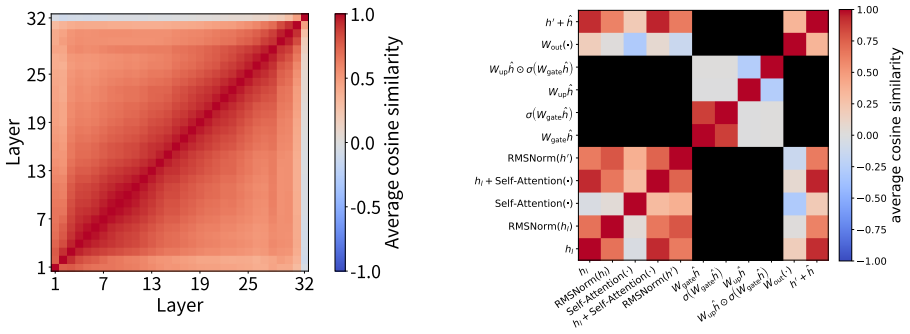
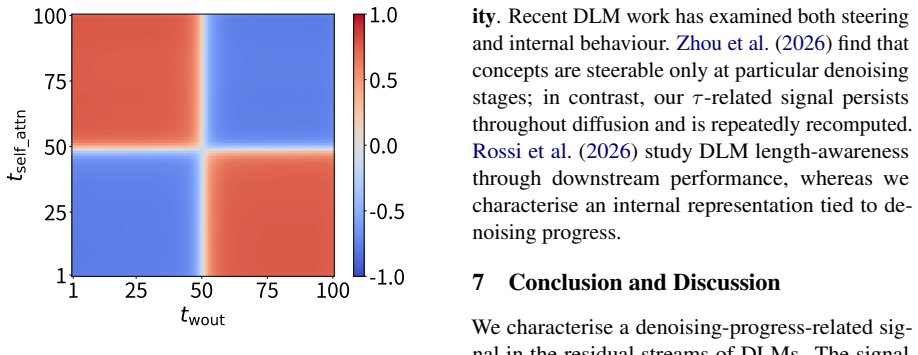
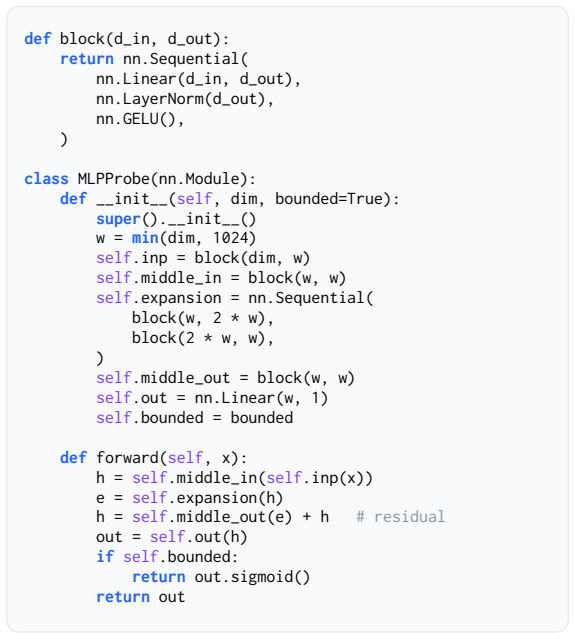

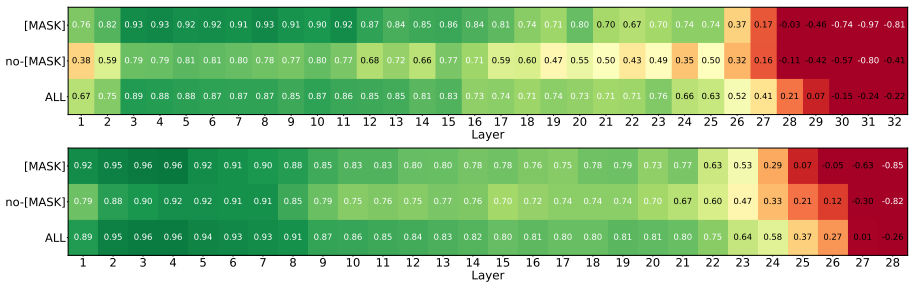
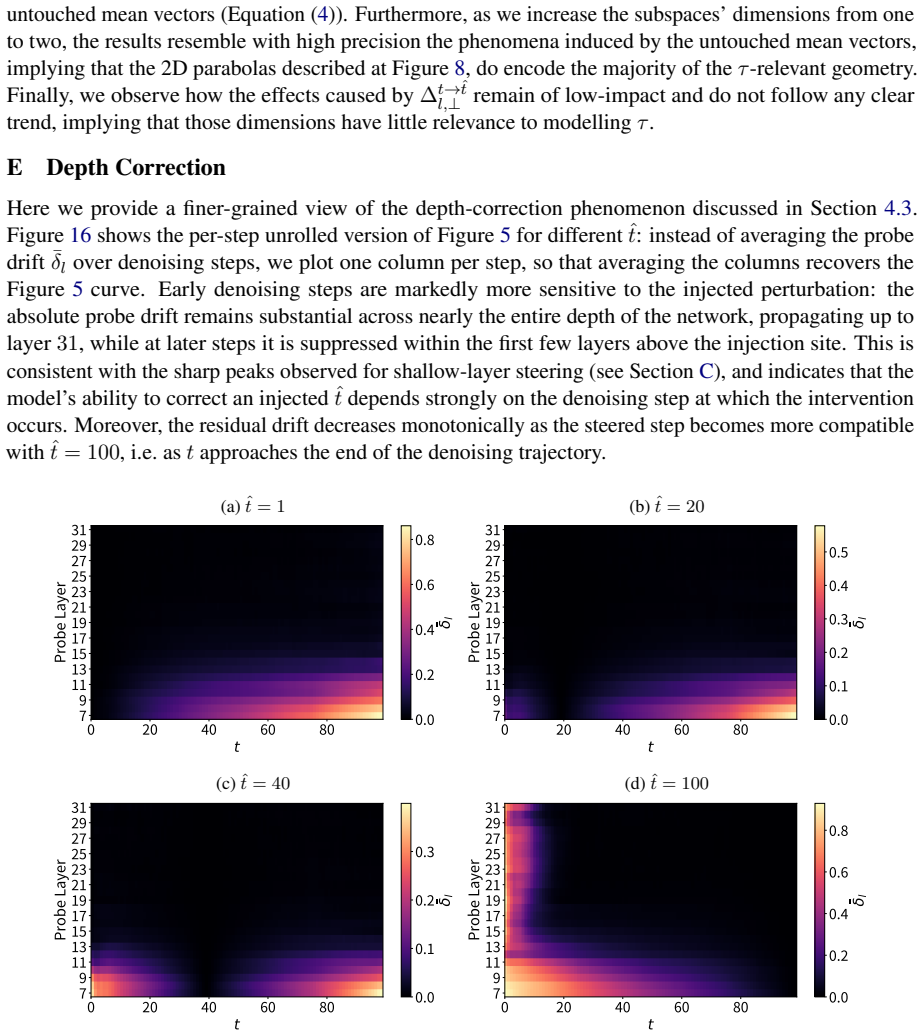
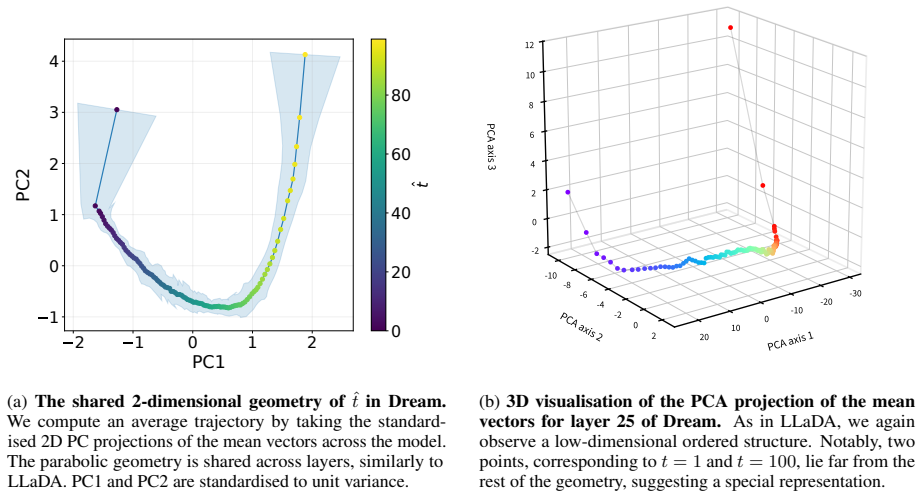
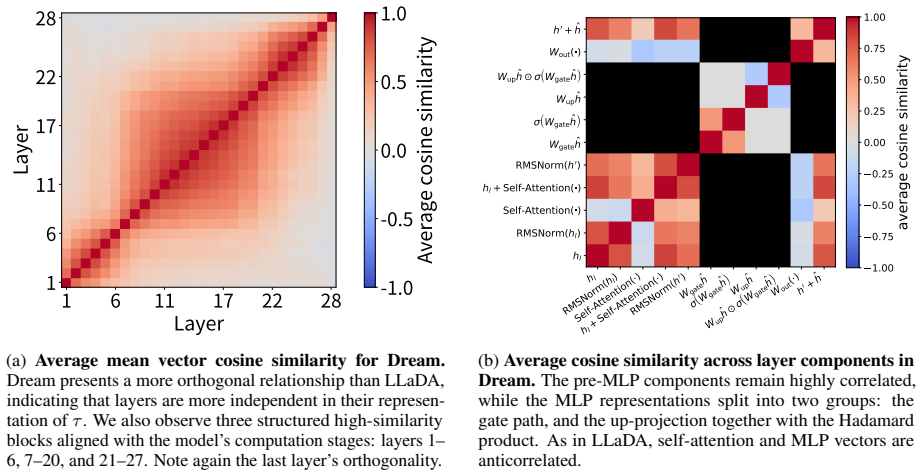
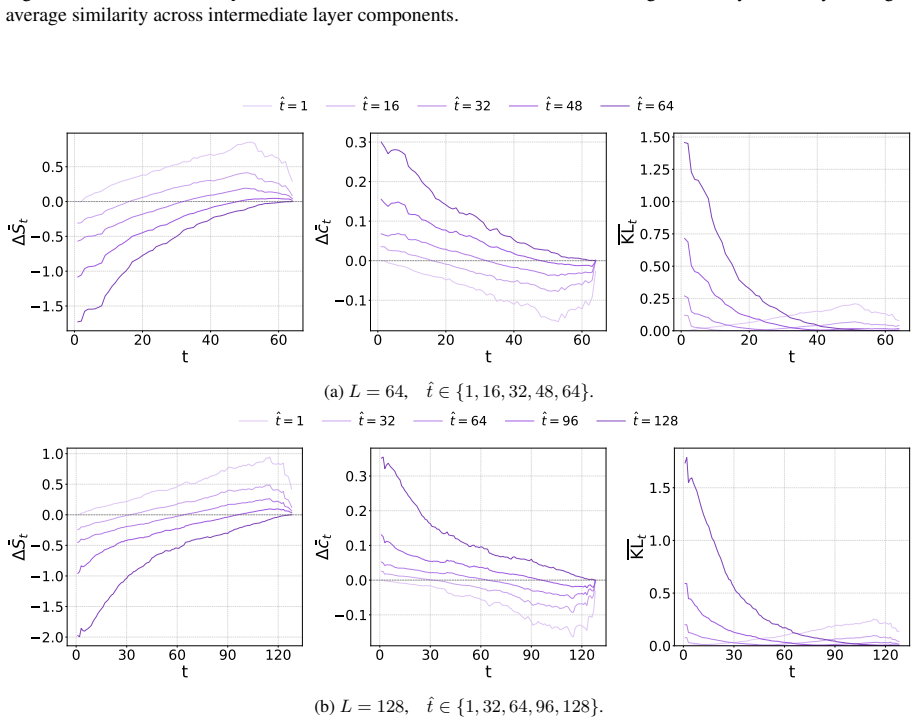
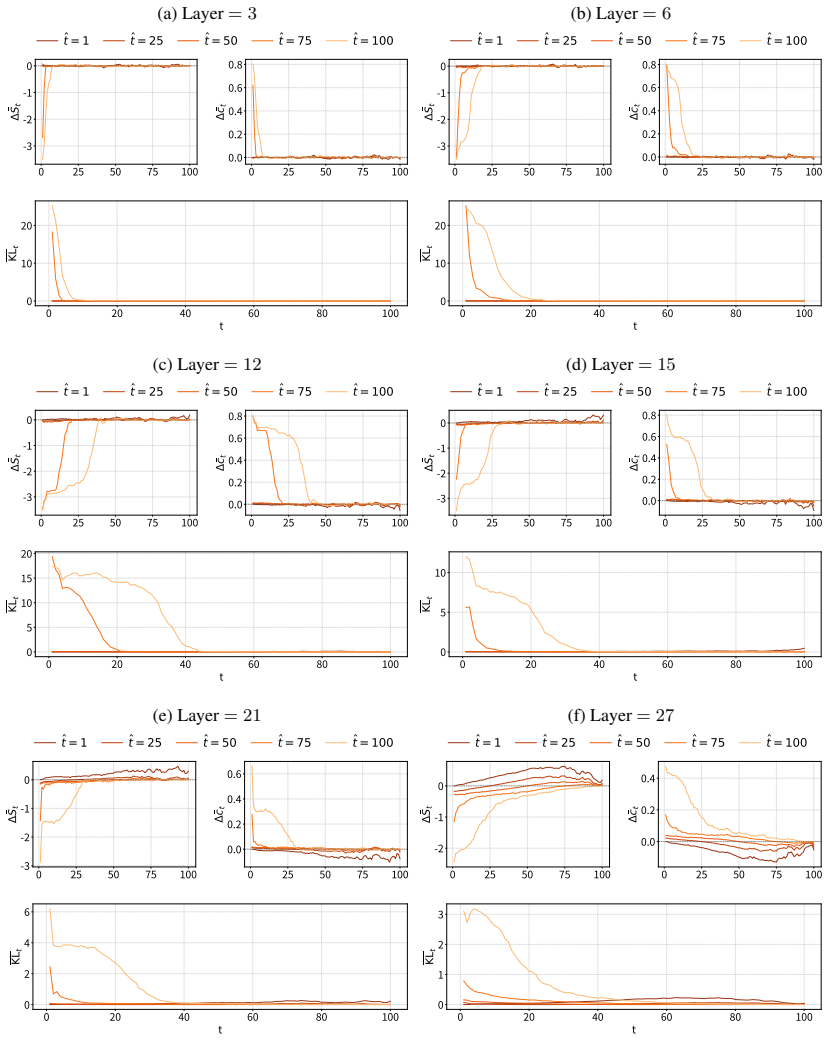
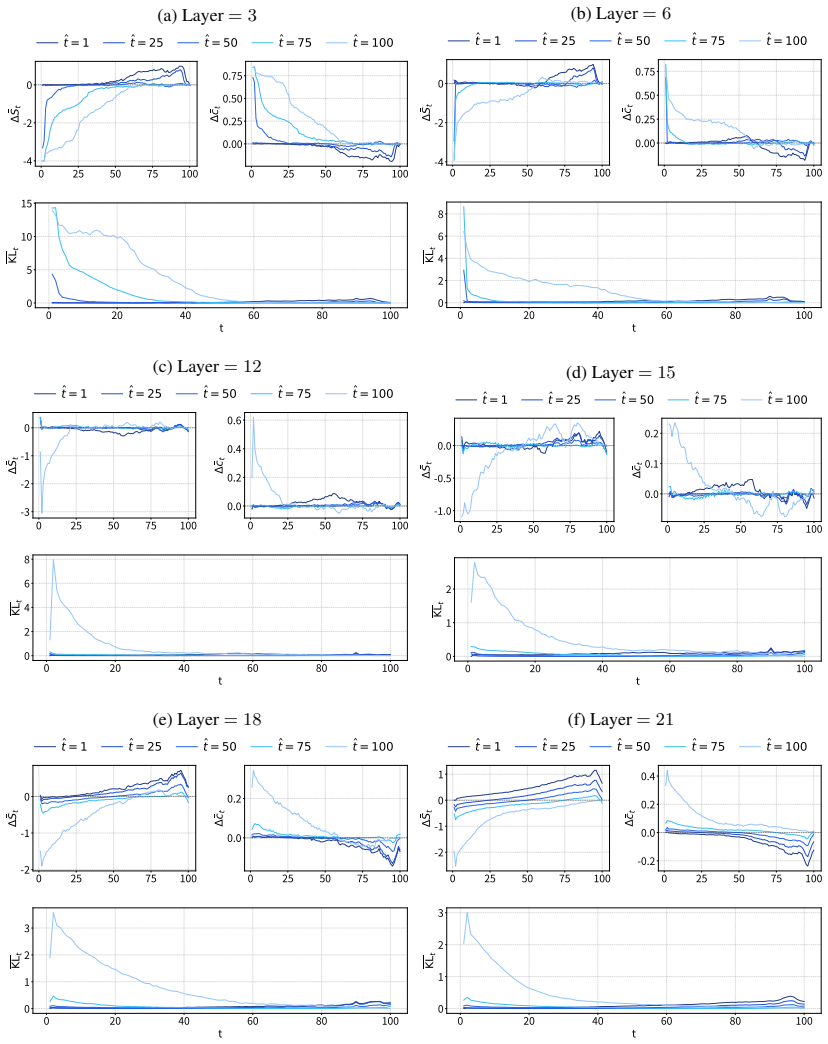
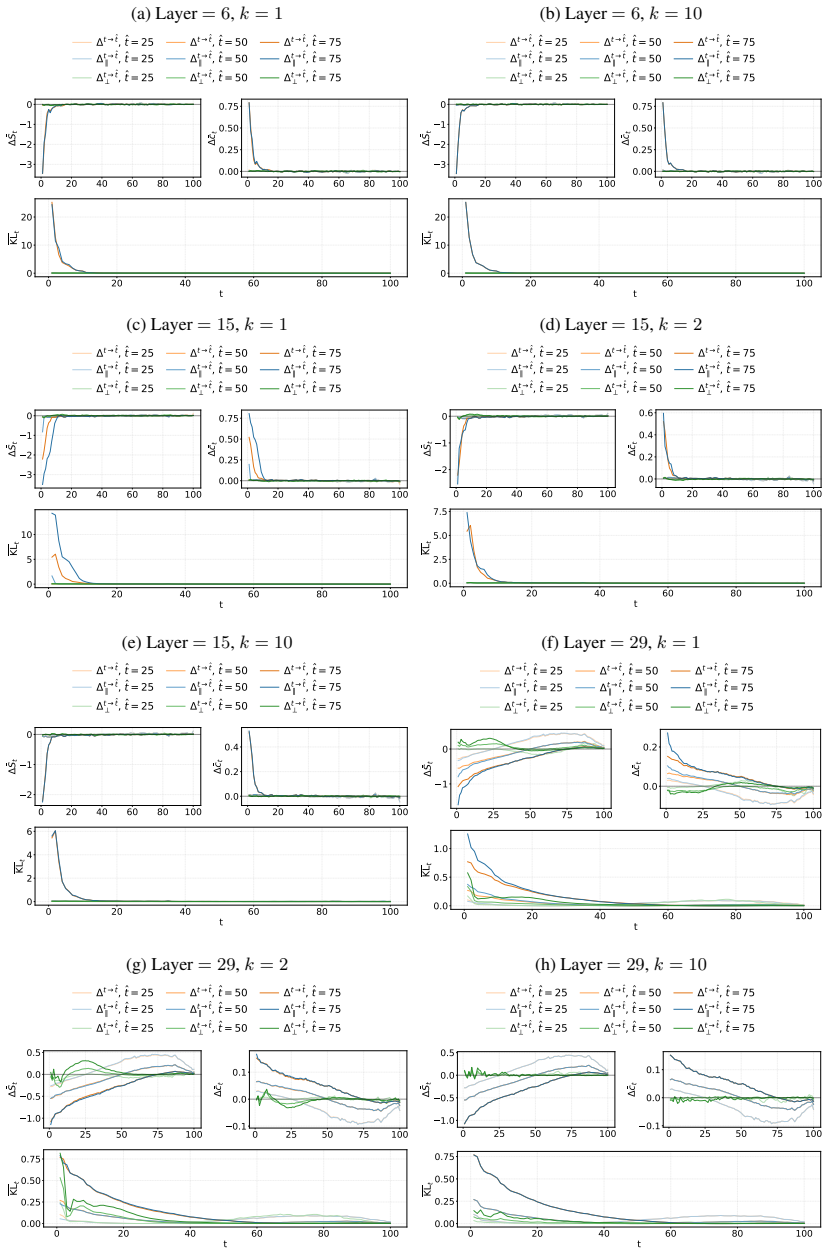
read the original abstract
Diffusion Language Models (DLMs) have recently emerged as a promising alternative to autoregressive models. Unlike standard diffusion-based approaches, DLMs are not explicitly conditioned on a timestep, raising a natural question: do these models internally represent denoising progress, and how is such information used downstream? In this work, we show that DLMs do in fact encode a latent representation related to the diffusion timestep within their residual streams. We find that this signal can be reliably extracted using probes across layers, indicating that denoising progress is decodable from internal activations. We further demonstrate that steering the model along a low-dimensional subspace associated with the inferred timestep allows us to systematically modulate its notion of denoising progress, leading to predictable changes in model confidence and entropy. Finally, we analyse the geometry of the identified representation, showing that it exhibits structured and interpretable properties in activation space, and shedding light on how such a signal is processed by these models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion language models (DLMs) internally encode a latent representation of the diffusion timestep within their residual streams despite lacking explicit timestep conditioning. This signal is reliably extractable via probes across layers. Steering along the associated low-dimensional subspace modulates the model's notion of denoising progress, producing predictable shifts in confidence and entropy. The work also examines the geometry of the representation, reporting structured and interpretable properties in activation space.
Significance. If the central empirical claims hold after addressing causality concerns, the results would advance interpretability research on diffusion language models by showing they develop implicit time representations. This could distinguish DLMs from autoregressive models and suggest new mechanisms for controlling generation dynamics. The combination of probing, steering, and geometric analysis follows established interpretability methods but applies them to a timely model class.
major comments (2)
- [steering experiments] The steering experiments (described in the abstract) report changes in confidence and entropy after intervening along the probed direction, but these downstream metrics can be altered by many other activation-space directions (e.g., those correlated with token entropy, position, or output length). The manuscript provides no evidence of an intervention that isolates the inferred timestep while holding other generation properties fixed, nor a direct measurement that the effective noise schedule changes. This assumption is load-bearing for the claim that the subspace is a causal encoding of denoising progress that the model functionally uses.
- [methods and experiments] No details are supplied on probe training procedures, steering implementation, datasets, statistical controls, or quantitative results (e.g., probe accuracies, steering magnitudes, or baseline comparisons). Without these, the central empirical claims that the signal is 'reliably extracted' and produces 'predictable changes' cannot be assessed for robustness or reproducibility.
minor comments (2)
- The abstract summarizes geometric findings only at a high level ('structured and interpretable properties'); a brief quantitative description or reference to a specific figure would improve clarity.
- Notation for the 'low-dimensional subspace' and 'inferred timestep' should be defined more precisely when first introduced to avoid ambiguity with related concepts such as noise level or generation step.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the manuscript requires additional methodological details and stronger controls in the steering experiments to support the causal claims. We outline our responses below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: [steering experiments] The steering experiments (described in the abstract) report changes in confidence and entropy after intervening along the probed direction, but these downstream metrics can be altered by many other activation-space directions (e.g., those correlated with token entropy, position, or output length). The manuscript provides no evidence of an intervention that isolates the inferred timestep while holding other generation properties fixed, nor a direct measurement that the effective noise schedule changes. This assumption is load-bearing for the claim that the subspace is a causal encoding of denoising progress that the model functionally uses.
Authors: We acknowledge that the existing steering results do not include explicit controls to isolate the timestep direction from correlated factors such as token entropy or position, nor do they provide a direct measurement of changes to the effective noise schedule. The direction used for steering was obtained from probes trained specifically to recover the timestep, and the resulting shifts in confidence and entropy are consistent with altered denoising progress. In the revision we will add controlled experiments that hold other generation properties fixed and report any feasible measurements of the noise schedule to strengthen the causal interpretation. revision: yes
-
Referee: [methods and experiments] No details are supplied on probe training procedures, steering implementation, datasets, statistical controls, or quantitative results (e.g., probe accuracies, steering magnitudes, or baseline comparisons). Without these, the central empirical claims that the signal is 'reliably extracted' and produces 'predictable changes' cannot be assessed for robustness or reproducibility.
Authors: We agree that the current manuscript lacks the necessary methodological details. The revised version will include complete descriptions of probe training procedures, steering implementation, datasets, statistical controls, probe accuracies, steering magnitudes, and baseline comparisons to enable reproducibility and evaluation of the claims. revision: yes
Circularity Check
No circularity: empirical probing and steering results are self-contained.
full rationale
The paper's claims rest on experimental extraction of signals from model activations via probes and subsequent steering interventions. No equations, fitted parameters, or self-citations are presented that reduce any reported 'prediction' or 'result' to the inputs by construction. The derivation chain consists of observable measurements (decodability across layers, changes in confidence/entropy under steering) that do not loop back to definitions or prior author work as load-bearing premises. This is the standard non-circular outcome for an empirical interpretability study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Your absorbing discrete diffusion secretly models the conditional distributions of clean data , author=. arXiv preprint arXiv:2406.03736 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2023 , eprint=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
2023
-
[3]
Transformer Circuits Thread , year=
Gurnee, Wes and Ameisen, Emmanuel and Kauvar, Isaac and Tarng ,Julius and Pearce, Adam and Olah, Chris and Batson, Joshua , title=. Transformer Circuits Thread , year=
-
[4]
2026 , eprint=
DLM-Scope: Mechanistic Interpretability of Diffusion Language Models via Sparse Autoencoders , author=. 2026 , eprint=
2026
-
[5]
2026 , eprint=
The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs , author=. 2026 , eprint=
2026
-
[6]
2025 , eprint=
Masks Can Be Distracting: On Context Comprehension in Diffusion Language Models , author=. 2025 , eprint=
2025
-
[7]
2025 , eprint=
Geometry of Decision Making in Language Models , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint=
Hypothesis-Driven Feature Manifold Analysis in LLMs via Supervised Multi-Dimensional Scaling , author=. 2026 , eprint=
2026
-
[9]
2025 , eprint=
Transformers represent belief state geometry in their residual stream , author=. 2025 , eprint=
2025
-
[10]
arXiv preprint arXiv:2505.18235 , year=
The origins of representation manifolds in large language models , author=. arXiv preprint arXiv:2505.18235 , year=
-
[11]
Symmetry in language statistics shapes the geometry of model representations
Symmetry in language statistics shapes the geometry of model representations , author=. arXiv preprint arXiv:2602.15029 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
International Conference on Learning Representations , volume=
Not all language model features are one-dimensionally linear , author=. International Conference on Learning Representations , volume=
-
[13]
2026 , eprint=
Large Language Models Encode Semantics and Alignment in Linearly Separable Representations , author=. 2026 , eprint=
2026
-
[14]
2026 , eprint=
Do Sparse Autoencoders Capture Concept Manifolds? , author=. 2026 , eprint=
2026
-
[15]
arXiv preprint arXiv:2510.18871 , year=
How Do LLMs Use Their Depth? , author=. arXiv preprint arXiv:2510.18871 , year=
-
[16]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[17]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
What does BERT learn about the structure of language? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[18]
arXiv preprint arXiv:2508.09138 , year=
Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models , author=. arXiv preprint arXiv:2508.09138 , year=
-
[19]
arXiv preprint arXiv:2510.15731 , year=
Attention Sinks in Diffusion Language Models , author=. arXiv preprint arXiv:2510.15731 , year=
-
[20]
Mechanism Shift During Post-training from Autoregressive to Masked Diffusion Language Models
Mechanism Shift During Post-training from Autoregressive to Masked Diffusion Language Models , author=. arXiv preprint arXiv:2601.14758 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Discovering Latent Knowledge in Language Models Without Supervision
Discovering latent knowledge in language models without supervision , author=. arXiv preprint arXiv:2212.03827 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2312.01037 , year=
Eliciting latent knowledge from quirky language models , author=. arXiv preprint arXiv:2312.01037 , year=
-
[24]
Steering Llama 2 via Contrastive Activation Addition
Panickssery, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Julian and Turner, Alexander , title =. arXiv preprint arXiv:2312.06681 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2410.12299 , year =
Wang, Weixuan and Yang, Jingyuan and Peng, Wei , title =. arXiv preprint arXiv:2410.12299 , year =
-
[26]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =
-
[27]
2024 , eprint =
The. 2024 , eprint =
2024
-
[28]
2025 , howpublished =
Introducing. 2025 , howpublished =
2025
-
[29]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal =
-
[30]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
2025 , howpublished =
System Card:. 2025 , howpublished =
2025
-
[32]
2024 , howpublished =
Learning to Reason with Large Language Models , author =. 2024 , howpublished =
2024
-
[33]
2019 , eprint=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
2019
-
[34]
2023 , eprint=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. 2023 , eprint=
2023
-
[35]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Dream 7B: Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[37]
Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Llada 1.5: Variance-reduced preference optimization for large language diffusion models , author=. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
Du, Zhenbang and Xia, Kejing and Zhong, Xinrui and Fu, Yonggan and Oswald, Nicolai and Ji, Binfei and Khailany, Brucek and Molchanov, Pavlo and Lin, Yingyan , journal=
-
[39]
arXiv preprint arXiv:2603.21342 , year=
Generalized Discrete Diffusion from Snapshots , author=. arXiv preprint arXiv:2603.21342 , year=
-
[40]
2024 , eprint=
Simple and Effective Masked Diffusion Language Models , author=. 2024 , eprint=
2024
-
[41]
2025 , eprint=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. 2025 , eprint=
2025
-
[42]
2025 , eprint=
Generalized Interpolating Discrete Diffusion , author=. 2025 , eprint=
2025
-
[43]
2025 , eprint=
The Diffusion Duality , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling , author=. 2025 , eprint=
2025
-
[45]
arXiv preprint arXiv:2510.06303 , year=
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation , author=. arXiv preprint arXiv:2510.06303 , year=
-
[46]
International Conference on Learning Representations , volume=
Block diffusion: Interpolating between autoregressive and diffusion language models , author=. International Conference on Learning Representations , volume=
-
[47]
Steering Without Breaking: Mechanistically Informed Interventions for Discrete Diffusion Language Models , author=. arXiv preprint arXiv:2605.10971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
arXiv preprint arXiv:2603.06123 , year=
Diffusion Language Models Are Natively Length-Aware , author=. arXiv preprint arXiv:2603.06123 , year=
-
[49]
Introspective Diffusion Language Models
Introspective Diffusion Language Models , author=. arXiv preprint arXiv:2604.11035 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Understanding and Accelerating the Training of Masked Diffusion Language Models
Understanding and Accelerating the Training of Masked Diffusion Language Models , author=. arXiv preprint arXiv:2605.13026 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
2025 , eprint=
Fast-dLLM v2: Efficient Block-Diffusion LLM , author=. 2025 , eprint=
2025
-
[52]
arXiv preprint arXiv:2508.13021 , year=
Pc-sampler: Position-aware calibration of decoding bias in masked diffusion models , author=. arXiv preprint arXiv:2508.13021 , year=
-
[53]
2024 , eprint=
Better & Faster Large Language Models via Multi-token Prediction , author=. 2024 , eprint=
2024
-
[54]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[56]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[57]
2021 , eprint=
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies , author=. 2021 , eprint=
2021
-
[58]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Advances in neural information processing systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in neural information processing systems , volume=
-
[60]
arXiv preprint arXiv:2211.04236 , year=
Self-conditioned embedding diffusion for text generation , author=. arXiv preprint arXiv:2211.04236 , year=
-
[61]
The Eleventh International Conference on Learning Representations , year=
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[62]
Continuous diffusion for categorical data
Continuous diffusion for categorical data , author=. arXiv preprint arXiv:2211.15089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.