Regularized Variational and Spectral Log-Density-Ratio Estimation in the Gaussian Location Model
Pith reviewed 2026-07-03 17:43 UTC · model grok-4.3
The pith
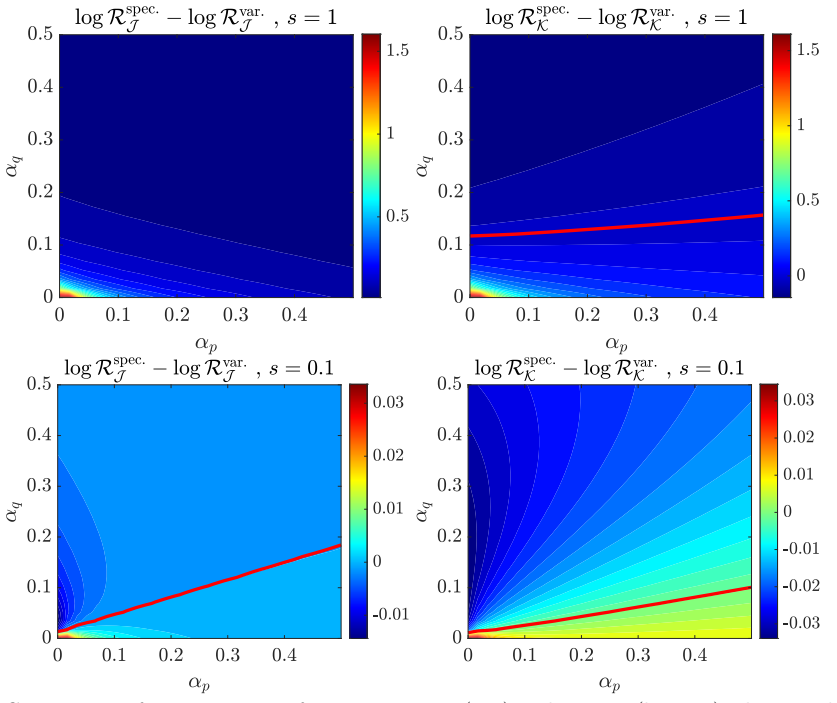
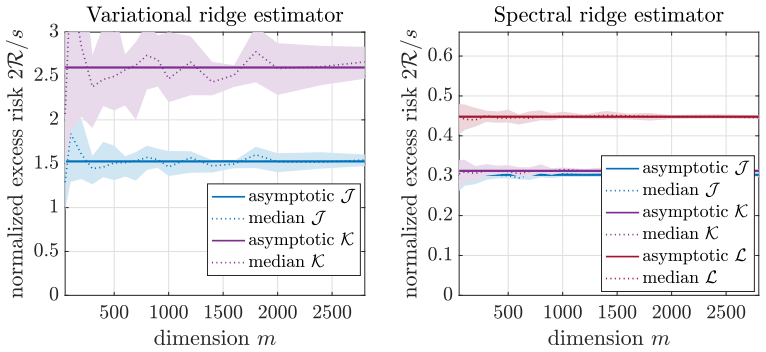
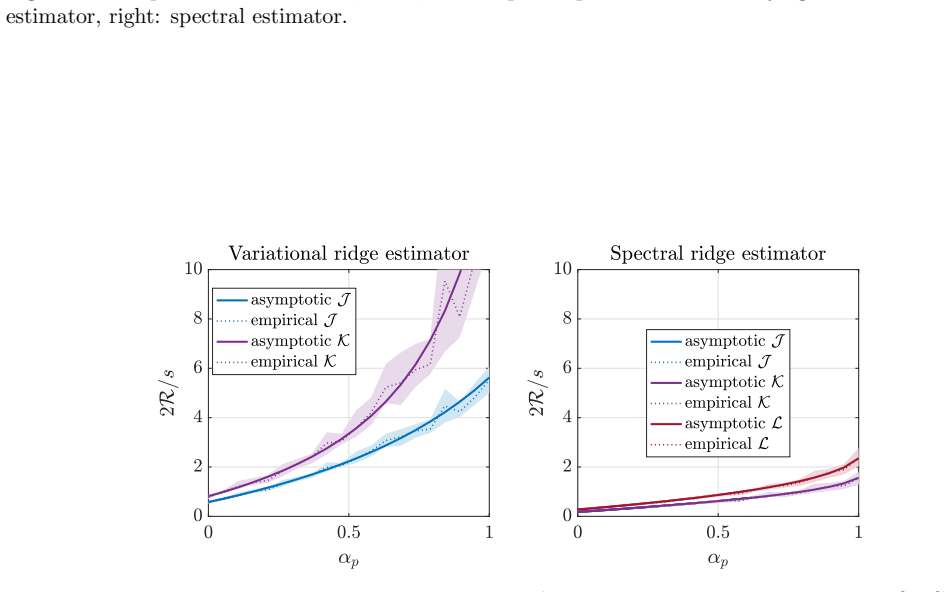
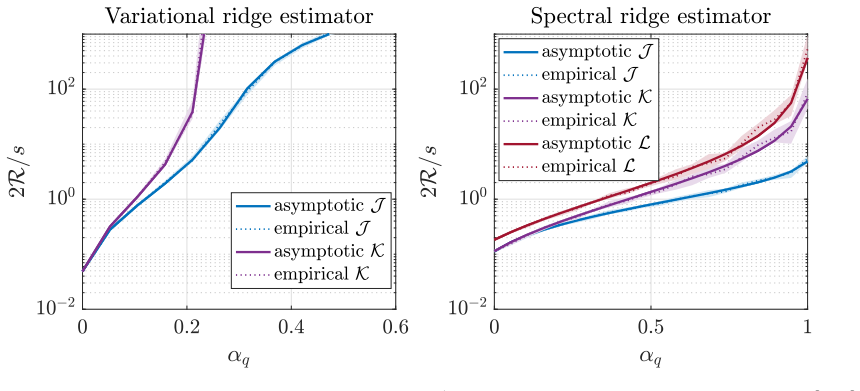
In the Gaussian location model, ridge-regularized variational log-density-ratio estimation has lower asymptotic risk than the spectral alternative when observations greatly exceed dimension, but the spectral estimator is preferable with few
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
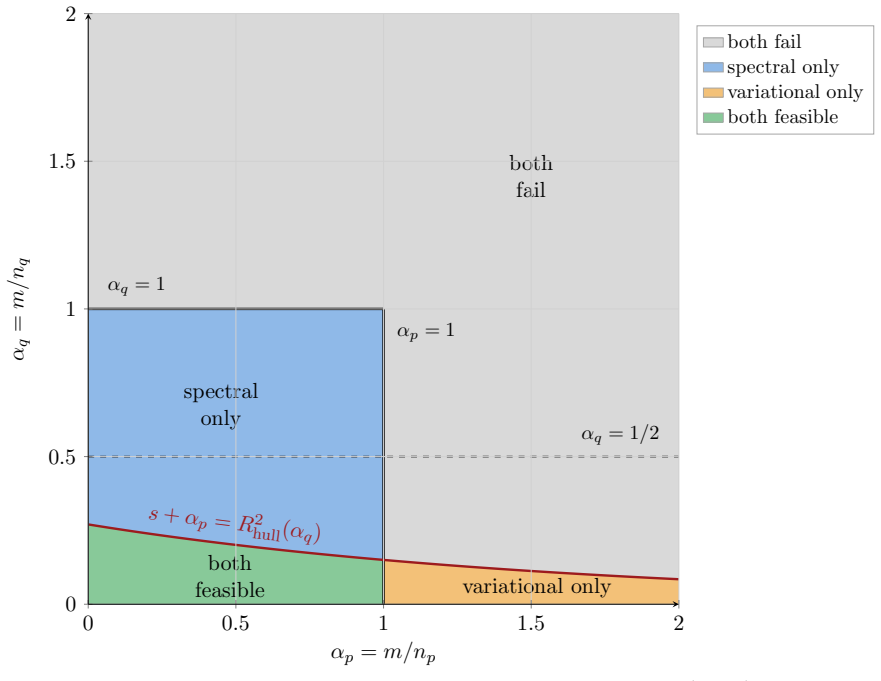
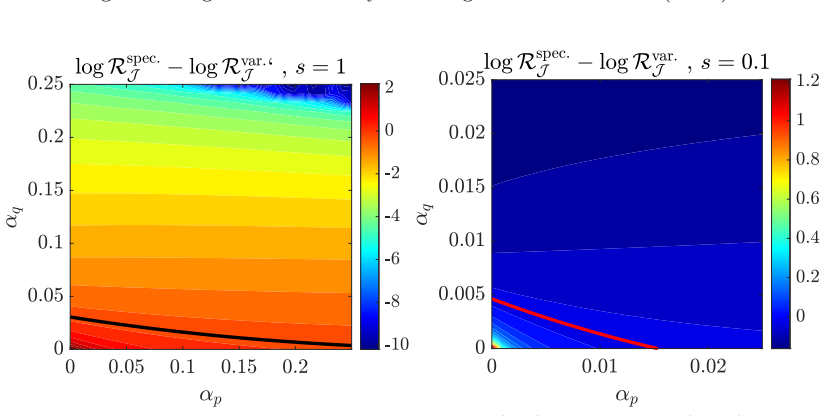
Under the analyzed high-dimensional regimes with fixed observation-to-dimension ratios, the well-specified variational estimator attains smaller population risk than the spectral estimator when the number of observations is large, while the spectral estimator is favored with fewer observations due to its covariance-based construction having lower variance; the limits are characterized via CGMT for the variational case and resolvent equivalents for the spectral case.
What carries the argument
High-dimensional deterministic asymptotic equivalents for the population risks of the two ridge-regularized estimators, obtained respectively from the convex-Gaussian-min-max theorem and from resolvents of weighted sums of two independent Gaussian sample covariances.
If this is right
- For density-ratio tasks in high dimensions, the variational estimator should be selected when sample size is large relative to dimension.
- The spectral estimator should be preferred in the small-sample regime to exploit its lower variance.
- A nuclear-norm penalty can be added to either estimator to induce feature learning, though its analysis remains partial.
Where Pith is reading between the lines
- The risk comparison may extend to other well-specified parametric families beyond the Gaussian location model.
- The derived asymptotic formulas could be used to optimize the regularization parameter as a function of the aspect ratio without cross-validation.
- Similar variational-versus-spectral trade-offs may appear in other ratio estimation problems such as importance sampling or mutual-information estimation.
Load-bearing premise
The observations are drawn exactly from the Gaussian location model with identical covariance matrices for the two distributions.
What would settle it
A finite-sample simulation in the Gaussian location model that measures empirical risks for both estimators across a sweep of observation-to-dimension ratios and checks whether the risk ordering reverses at the ratio predicted by the asymptotic formulas.
Figures
read the original abstract
We study ridge-regularized log-density-ratio estimation in the Gaussian location model with a common covariance matrix. By affine invariance, the model is written as q $\sim$ N(0, I), p $\sim$ N($\Delta$, I), with linear features, where $\Delta$ is a mean vector. The variational estimator is the empirical Kullback-Leibler (KL) log-normalized fit with a squared L2-penalty on its nonconstant coefficient, and the spectral estimator recently introduced in [1] replaces a single variational problem by a continuum of ridge-regularized least-squares problems. We derive high-dimensional deterministic asymptotic equivalents when the numbers of observations and dimension tend to infinity with fixed ratios. The regularized variational limit is characterized by a scalar entropy minimization problem derived from the convex-Gaussian-min-max theorem (CGMT), while the regularized spectral limit follows from deterministic equivalents for resolvents of weighted sums of two independent Gaussian sample covariance matrices. We use these formulas to compare population risks, with experiments focused on fixed-signal aspect-ratio sweeps and optimized regularization. Our conclusion is that with many observations, under the criteria and asymptotic regimes analyzed here, the well-specified variational estimator has the smaller risk, while with fewer observations, the spectral estimator is favored because its covariance-based construction has lower variance. We also study how a nuclear penalty can be used and partially analyzed to perform feature learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives high-dimensional asymptotic equivalents for the population risks of ridge-regularized variational and spectral log-density-ratio estimators in the Gaussian location model (q ~ N(0,I), p ~ N(Δ,I) with common covariance). The variational limit is characterized via the convex-Gaussian-min-max theorem (CGMT) as a scalar entropy minimization problem, while the spectral limit follows from deterministic equivalents for resolvents of weighted sums of two independent Gaussian sample covariance matrices. These formulas are used to compare risks, with the conclusion that the well-specified variational estimator has smaller risk with many observations while the spectral estimator is favored with fewer observations due to lower variance from its covariance-based construction. Experiments focus on fixed-signal aspect-ratio sweeps with optimized regularization, and a nuclear penalty is partially analyzed for feature learning.
Significance. If the derivations hold, the work provides precise asymptotic risk characterizations that enable direct comparison of the two estimators in the high-dimensional regime with fixed observation-to-dimension ratios. The explicit use of CGMT for the variational case and resolvent deterministic equivalents for the spectral case is a strength, as these are standard tools that yield exact limits under the stated model. The scoping of the conclusion to the analyzed criteria, regimes, and Gaussian location model is clearly stated upfront.
minor comments (2)
- [Abstract] Abstract: the phrase 'optimized regularization' is used for the risk comparisons but the manuscript does not specify whether the regularization strength is chosen by oracle knowledge of the population risk or by a data-driven procedure; this affects how the comparison should be interpreted in practice.
- [Model setup paragraph] The high-dimensional limit is taken with fixed ratios of observations to dimension, but the notation for the limiting ratios (e.g., n_p/d, n_q/d) is not introduced until later sections; adding it to the model-setup paragraph would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment of the derivations and scoping, and recommendation of minor revision. No major comments appear in the provided report.
Circularity Check
No significant circularity identified
full rationale
The paper derives high-dimensional asymptotic equivalents for the variational estimator via the external convex-Gaussian-min-max theorem (CGMT) and for the spectral estimator via resolvent deterministic equivalents of weighted sample covariances. These are standard external mathematical tools. The subsequent population-risk comparison occurs inside the stated Gaussian location model and fixed-ratio asymptotic regime, but does not reduce any claim to a fitted parameter, self-definition, or self-citation chain by construction. Model assumptions are declared explicitly at the outset; no load-bearing step collapses to the paper's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- ridge regularization strength
axioms (2)
- domain assumption Data exactly follows the two-Gaussian location model with identical covariance matrices
- domain assumption High-dimensional limit with n, d → ∞ at fixed aspect ratios
Reference graph
Works this paper leans on
-
[1]
A Spectral Framework for Closed-Form Relative Density Estimation
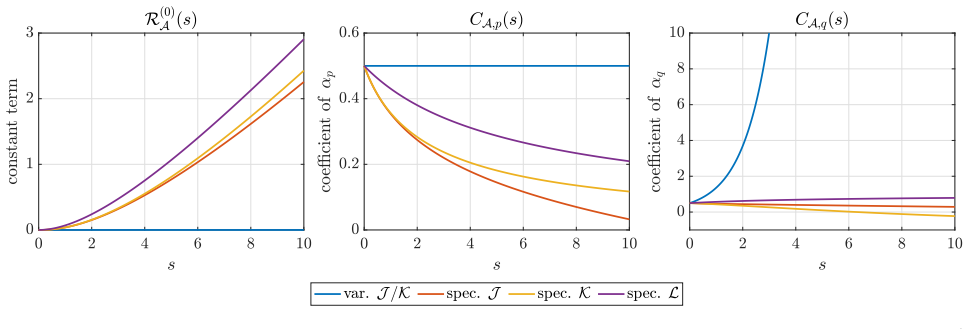
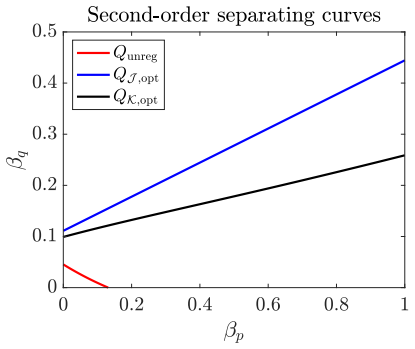
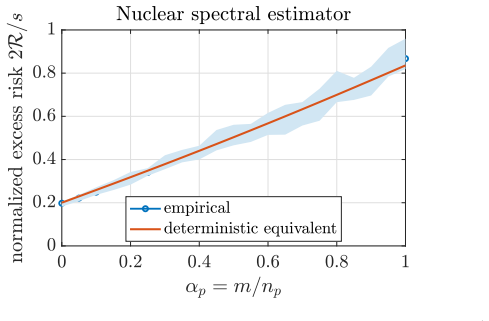
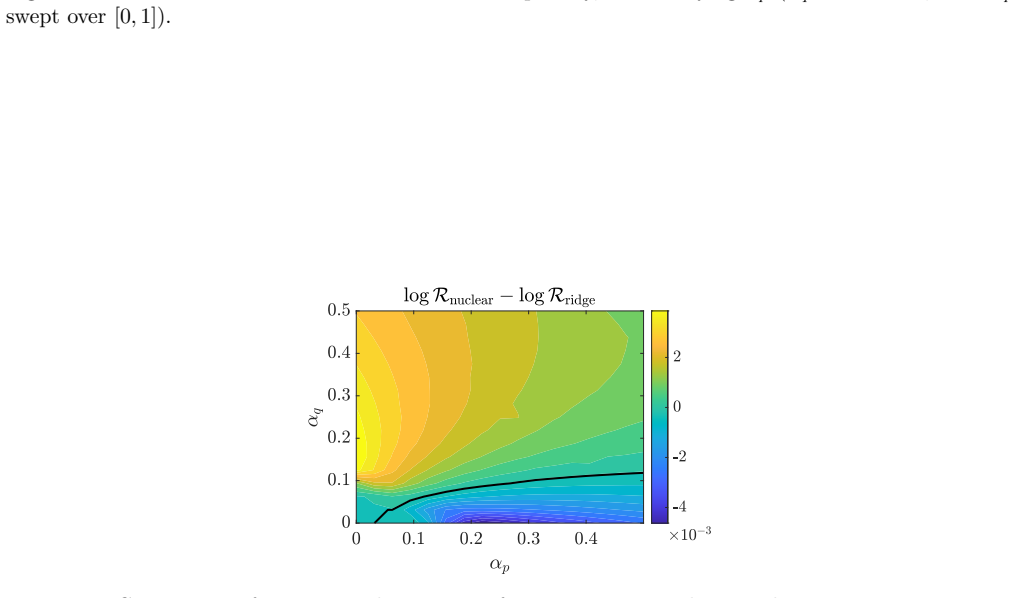
Francis Bach. A spectral framework for closed-form rela tive density estimation, 2026. arXiv:2605.10668. (cited on pages 1, 2, 3, 5, 6, 7, 26, 28, and 29) 59 Figure 9: Performance of the estimator with nuclear penalty , when varying α p (α q = 0. 1 fixed, with α p swept over [0, 1]). Figure 10: Comparison of two spectral estimators for a given s = 1 when r...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Direct importance estimation for covariate shif t adaptation
Masashi Sugiyama, Taiji Suzuki, Shinichi Nakajima, His ashi Kashima, Paul von B¨ unau, and Motoaki Kawanabe. Direct importance estimation for covariate shif t adaptation. Annals of the Institute of Statistical Mathematics , 60(4):699–746, 2008. (cited on pages 1 and 3)
2008
-
[3]
A least-squares approach to direct im- portance estimation
Takafumi Kanamori, Shohei Hido, and Masashi Sugiyama. A least-squares approach to direct im- portance estimation. Journal of Machine Learning Research , 10:1391–1445, 2009. (cited on pages 1 and 3)
2009
-
[4]
Density Ratio Estimation in Machine Learning
Masashi Sugiyama, Taiji Suzuki, and Takafumi Kanamori. Density Ratio Estimation in Machine Learning. Cambridge University Press, 2012. (cited on pages 1 and 3)
2012
-
[5]
Wainwright, and Michael I
XuanLong Nguyen, Martin J. Wainwright, and Michael I. Jo rdan. Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory , 56(11):5847–5861, 2010. (cited on pages 1, 3, 4, 7, and 29)
2010
-
[6]
Donsker and S
Monroe D. Donsker and S. R. Srinivasa Varadhan. Asymptot ic evaluation of certain Markov process expectations for large time, I. Communications on Pure and Applied Mathematics , 28(1):1–47, 1975. (cited on pages 1, 3, 7, and 29)
1975
-
[7]
Inferences for case-control and semiparametr ic two-sample density ratio models
Jing Qin. Inferences for case-control and semiparametr ic two-sample density ratio models. Biometrika, 85(3):619–630, 1998. (cited on page 1)
1998
-
[8]
Cand` es and Pragya Sur
Emmanuel J. Cand` es and Pragya Sur. The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression. The Annals of Statistics , 48(1):27–42, 2020. (cited on pages 1 and 3)
2020
-
[9]
Fi nite-sample performance of the maximum likelihood estimator in logistic regression, 2024
Hugo Chardon, Matthieu Lerasle, and Jaouad Mourtada. Fi nite-sample performance of the maximum likelihood estimator in logistic regression, 2024. arXiv: 2411.02137. (cited on pages 1 and 3)
-
[10]
Hoerl and Robert W
Arthur E. Hoerl and Robert W. Kennard. Ridge regression : Biased estimation for nonorthogonal problems. Technometrics, 12(1):55–67, 1970. (cited on page 1)
1970
-
[11]
Smola, Arthur Gretton, Kar sten M
Jiayuan Huang, Alexander J. Smola, Arthur Gretton, Kar sten M. Borgwardt, and Bernhard Sch¨ olkopf. Correcting sample selection bias by unlabeled data. In Advances in Neural Information Processing Systems, 2007. (cited on page 3)
2007
-
[12]
Linking losses for density ratio and class-probability estimation
Aditya Krishna Menon and Cheng Soon Ong. Linking losses for density ratio and class-probability estimation. In International Conference on Machine Learning , 2016. (cited on page 3)
2016
-
[13]
Cand` es
Pragya Sur and Emmanuel J. Cand` es. A modern maximum-li kelihood theory for high-dimensional logistic regression. Proceedings of the National Academy of Sciences , 116(29):14516–14525, 2019. (cited on page 3)
2019
-
[14]
The i mpact of regularization on high-dimensional logistic regression
Fariborz Salehi, Ehsan Abbasi, and Babak Hassibi. The i mpact of regularization on high-dimensional logistic regression. In Advances in Neural Information Processing Systems , 2019. (cited on pages 3, 13, and 28)
2019
-
[15]
Silverstein
Zhidong Bai and Jack W. Silverstein. Spectral Analysis of Large Dimensional Random Matrices . Springer, 2nd edition, 2010. (cited on pages 3, 14, 28, and 29) 61
2010
-
[16]
Dete rministic equivalents for certain functionals of large random matrices
Walid Hachem, Philippe Loubaton, and Jamal Najim. Dete rministic equivalents for certain functionals of large random matrices. The Annals of Applied Probability , 17(3):875–930, 2007. (cited on pages 3 and 28)
2007
-
[17]
High-dimensional asy mptotics of prediction: Ridge regression and classification
Edgar Dobriban and Stefan Wager. High-dimensional asy mptotics of prediction: Ridge regression and classification. The Annals of Statistics , 46(1):247–279, 2018. (cited on page 3)
2018
-
[18]
The interpolation p hase transition in neural networks: Memo- rization and generalization under lazy training
Andrea Montanari and Yiqiao Zhong. The interpolation p hase transition in neural networks: Memo- rization and generalization under lazy training. The Annals of Statistics , 50(5):2816–2847, 2022. (cited on pages 3, 14, and 28)
2022
-
[19]
High-dimensional analysis of double des cent for linear regression with random projec- tions
Francis Bach. High-dimensional analysis of double des cent for linear regression with random projec- tions. SIAM Journal on Mathematics of Data Science , 6(1):26–50, 2024. (cited on pages 3, 14, 15, 16, 28, 42, and 43)
2024
-
[20]
Peter McCullagh and John A. Nelder. Generalized Linear Models . Chapman & Hall, 1989. (cited on page 4)
1989
-
[21]
Convex Optimization
Stephen Boyd and Lieven Vandenberghe. Convex Optimization . Cambridge University Press, 2004. (cited on page 4)
2004
-
[22]
Jorge Nocedal and Stephen J. Wright. Numerical Optimization. Springer, 2nd edition, 2006. (cited on pages 4 and 13)
2006
-
[23]
Minimization of ϕ -divergences on sets of signed measures
Michel Broniatowski and Amor Keziou. Minimization of ϕ -divergences on sets of signed measures. Studia Scientiarum Mathematicarum Hungarica , 43(4):403–442, 2006. (cited on page 5)
2006
-
[24]
Orthogonal Polynomials: Computation and Approximation
Walter Gautschi. Orthogonal Polynomials: Computation and Approximation . Oxford University Press,
-
[25]
(cited on pages 6 and 13)
-
[26]
Existence of direct density ratio estimators, 2025
Erika Banzato, Mathias Drton, Kian Saraf-Poor, and Hon gjian Shi. Existence of direct density ratio estimators, 2025. arXiv:2502.12738. (cited on page 9)
-
[27]
The implicit bias of gradient descent on separable data
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gu nasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data. Journal of Machine Learning Research , 19(70):1–57, 2018. (cited on page 9)
2018
-
[28]
Lee, Daniel Soudry, and Nath an Srebro
Suriya Gunasekar, Jason D. Lee, Daniel Soudry, and Nath an Srebro. Implicit bias of gradient descent on linear convolutional networks. In Advances in Neural Information Processing Systems , 2018. (cited on page 9)
2018
-
[29]
van der Vaart
Aad W. van der Vaart. Asymptotic Statistics . Cambridge University Press, 1998. (cited on pages 10, 19, and 20)
1998
-
[30]
High-Dimensional Probability: An Introduction with Applic ations in Data Science
Roman Vershynin. High-Dimensional Probability: An Introduction with Applic ations in Data Science . Cambridge University Press, 2018. (cited on page 10)
2018
-
[31]
The Gaussian min-max theorem in the Presence of Convexity
Christos Thrampoulidis, Samet Oymak, and Babak Hassib i. The Gaussian min-max theorem in the presence of convexity, 2014. arXiv:1408.4837. (cited on pages 12 and 37) 62
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Regularized linear regression: A precise analysis of the estimation error
Christos Thrampoulidis, Samet Oymak, and Babak Hassib i. Regularized linear regression: A precise analysis of the estimation error. In Conference on Learning Theory , 2015. (cited on page 12)
2015
-
[33]
Corless, Gaston H
Robert M. Corless, Gaston H. Gonnet, David E. G. Hare, Da vid J. Jeffrey, and Donald E. Knuth. On the Lambert W function. Advances in Computational Mathematics , 5:329–359, 1996. (cited on page 13)
1996
-
[34]
Trace Ideals and Their Applications
Barry Simon. Trace Ideals and Their Applications . American Mathematical Society, 2005. (cited on page 18)
2005
-
[35]
Richard P. Brent. Algorithms for Minimization Without Derivatives . Prentice Hall, 1973. (cited on page 26)
1973
-
[36]
Convex multi-task feature learning
Andreas Argyriou, Theodoros Evgeniou, and Massimilia no Pontil. Convex multi-task feature learning. Machine Learning, 73(3):243–272, 2008. (cited on pages 28, 45, and 47)
2008
-
[37]
Sinan G¨ unt¨ urk
Ingrid Daubechies, Ronald DeVore, Massimo Fornasier, and C. Sinan G¨ unt¨ urk. Iteratively reweighted least squares minimization for sparse recovery. Communications on Pure and Applied Mathematics , 63(1):1–38, 2010. (cited on page 29)
2010
-
[38]
Optimization with sparsity-inducing penalties
Francis Bach, Rodolphe Jenatton, Julien Mairal, and Gu illaume Obozinski. Optimization with sparsity-inducing penalties. Foundations and Trends in Machine Learning , 4(1):1–106, 2012. (cited on page 29)
2012
-
[39]
Ajanki, L´ aszl´ o Erd˝ os, and Torben H
Oskari H. Ajanki, L´ aszl´ o Erd˝ os, and Torben H. Kr¨ uger. Stability of the matrix Dyson equation and random matrices with correlations. Probability Theory and Related Fields , 173(1–2):293–373, 2019. (cited on pages 29, 49, 51, and 53)
2019
-
[40]
Mutual information neural esti mation
Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajes hwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. Mutual information neural esti mation. In International Conference on Machine Learning, 2018. (cited on page 29)
2018
-
[41]
Alemi, and George Tucker
Ben Poole, Sherjil Ozair, Aaron van den Oord, Alexander A. Alemi, and George Tucker. On variational bounds of mutual information. In International Conference on Machine Learning, 2019. (cited on page 29)
2019
-
[42]
Random features for larg e-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for larg e-scale kernel machines. In Advances in Neural Information Processing Systems , 2007. (cited on page 29)
2007
-
[43]
Christopher K. I. Williams and Matthias Seeger. Using t he Nystr¨ om method to speed up kernel machines. In Advances in Neural Information Processing Systems , 2001. (cited on page 29)
2001
-
[44]
A rando m matrix approach to neural networks
Cosme Louart, Zhenyu Liao, and Romain Couillet. A rando m matrix approach to neural networks. The Annals of Applied Probability , 28(2):1190–1248, 2018. (cited on page 29)
2018
-
[45]
The generalization erro r of random features regression: Precise asymptotics and the double descent curve
Song Mei and Andrea Montanari. The generalization erro r of random features regression: Precise asymptotics and the double descent curve. Communications on Pure and Applied Mathematics , 75(4):667–766, 2022. (cited on page 29)
2022
-
[46]
Hong Hu and Yue M. Lu. Universality laws for high-dimens ional learning with random features. IEEE Transactions on Information Theory , 69(3):1932–1964, 2023. (cited on page 29) 63
1932
-
[47]
Gener- alisation error in learning with random features and the hid den manifold model
Federica Gerace, Bruno Loureiro, Florent Krzakala, Ma rc M´ ezard, and Lenka Zdeborov´ a. Gener- alisation error in learning with random features and the hid den manifold model. In International Conference on Machine Learning , 2020. (cited on page 29)
2020
-
[48]
Learning curves of generic features mapsfor realistic datasets with a teacher-student model
Bruno Loureiro, C´ edric Gerbelot, Hugo Cui, Sebastian Goldt, Florent Krzakala, Marc M´ ezard, and Lenka Zdeborov´ a. Learning curves of generic features mapsfor realistic datasets with a teacher-student model. In Advances in Neural Information Processing Systems , 2021. (cited on page 29)
2021
-
[49]
Fluctuations, bias, variance & ensemble of learners: Exact asymptotics fo r convex losses in high-dimension
Bruno Loureiro, Cedric Gerbelot, Maria Refinetti, Gabr iele Sicuro, and Florent Krzakala. Fluctuations, bias, variance & ensemble of learners: Exact asymptotics fo r convex losses in high-dimension. In International Conference on Machine Learning , 2022. (cited on page 29)
2022
-
[50]
Johnstone
Iain M. Johnstone. On the distribution of the largest ei genvalue in principal components analysis. The Annals of Statistics , 29(2):295–327, 2001. (cited on page 29)
2001
-
[51]
Ph ase transition of the largest eigenvalue for nonnull complex sample covariance matrices
Jinho Baik, G´ erard Ben Arous, and Sandrine P´ ech´ e. Ph ase transition of the largest eigenvalue for nonnull complex sample covariance matrices. The Annals of Probability , 33(5):1643–1697, 2005. (cited on page 29)
2005
-
[52]
Precise error analysis of regularized M- estimators in high dimensions
Christos Thrampoulidis, Ehsan Abbasi, and Babak Hassi bi. Precise error analysis of regularized M- estimators in high dimensions. IEEE Transactions on Information Theory , 64(8):5592–5628, 2018. (cited on page 39)
2018
-
[53]
On the numerical evaluation of Fred holm determinants
Folkmar Bornemann. On the numerical evaluation of Fred holm determinants. Mathematics of Com- putation, 79(270):871–915, 2010. (cited on page 44)
2010
-
[54]
Perturbation Theory for Linear Operators
Tosio Kato. Perturbation Theory for Linear Operators . Springer, 1995. (cited on page 46)
1995
-
[55]
Isotropic local laws for sample covariance and generalized Wigner matrices
Alex Bloemendal, L´ aszl´ o Erd˝ os, Antti Knowles, Horng-Tzer Yau, and Jun Yin. Isotropic local laws for sample covariance and generalized Wigner matrices. Electronic Journal of Probability , 19(33):1–53,
-
[56]
(cited on pages 49 and 53)
-
[57]
Charles M. Stein. Estimation of the mean of a multivaria te normal distribution. The Annals of Statistics, 9(6):1135–1151, 1981. (cited on page 49)
1981
-
[58]
Khorunzhy, Boris A
Alexei M. Khorunzhy, Boris A. Khoruzhenko, and Leonid A . Pastur. Asymptotic properties of large random matrices with independent entries. Journal of Mathematical Physics , 37(10):5033–5060, 1996. (cited on page 49)
1996
-
[59]
Ajanki, L´ aszl´ o Erd˝ os, and Torben H
Oskari H. Ajanki, L´ aszl´ o Erd˝ os, and Torben H. Kr¨ uger. Quadratic Vector Equations on Complex Upper Half-Plane . Memoirs of the American Mathematical Society. American Ma thematical Society,
-
[60]
(cited on pages 51 and 53)
-
[61]
Kr¨ uger
Johannes Alt, L´ aszl´ o Erd˝ os, and Torben H. Kr¨ uger. The Dyson equation with linear self-energy: Spectral bands, edges and cusps. Documenta Mathematica , 25:1421–1539, 2020. (cited on pages 51 and 53)
2020
-
[62]
Fixed point equations and nonlinear eig envalue problems in ordered Banach spaces
Herbert Amann. Fixed point equations and nonlinear eig envalue problems in ordered Banach spaces. SIAM Review , 18(4):620–709, 1976. (cited on page 59)
1976
-
[63]
Positive Definite Matrices
Rajendra Bhatia. Positive Definite Matrices . Princeton University Press, 2007. (cited on page 59) 64
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.