A Multi-Branch Hierarchy-Aware Framework for Heterogeneous Audio Classification
Pith reviewed 2026-07-03 06:06 UTC · model grok-4.3
The pith
A CLAP-based multi-branch system with hierarchy-aware heads and KNN post-processing reaches 80.84% hierarchical F1 on heterogeneous audio classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By expanding the training set with a filtered subset of BSD35k, processing multiple acoustic features through separate branches, and refining outputs with hierarchy-aware classifiers plus KNN post-processing, the framework produces hierarchical F1 scores of 80.84% for the strongest single model and up to 81.25% for complementary ensembles on the BSD10k-v1.2 set.
What carries the argument
Multi-branch hierarchy-aware framework built on CLAP representations, with feature-specific branches, hierarchy-aware classifiers, and KNN-based post-processing.
If this is right
- The log-STFT branch delivers the strongest single-model performance among the acoustic features tested.
- Ensemble combinations of models with different acoustic features and classification heads improve over any individual system.
- KNN post-processing enforces taxonomy consistency and raises hierarchical F1 scores for all reported configurations.
- The three combined strategies together produce the observed gains under the fixed DCASE evaluation protocol.
Where Pith is reading between the lines
- The same branch-and-post-process pattern could be applied to other audio taxonomies or to hierarchical tasks outside audio if the label structure is comparable.
- Performance gains may partly come from the added data volume rather than the architectural choices alone.
- The method could be tested on datasets with noisier or less complete taxonomies to check whether the hierarchy-aware component remains effective.
Load-bearing premise
The filtered subset of BSD35k can be added to training without introducing distribution shift or label noise that would invalidate the reported gains on the evaluation set.
What would settle it
Retraining the identical models on the original training data only and measuring whether the Hier. F1 scores on BSD10k-v1.2 drop below the reported values or fall within the range expected from random variation.
Figures
read the original abstract
This technical report describes our system for Task 1 of the DCASE 2026 Challenge, which aims to classify heterogeneous audio recordings according to the Broad Sound Taxonomy (BST). The task requires both accurate second-level prediction and consistency with the top-level taxonomy. Our system is built on CLAP-based audio-text representations and is improved along three strategies: expanding the training set with a filtered subset of BSD35k, enhancing acoustic modeling with feature-specific branches, and refining predictions using hierarchy-aware classifiers and KNN-based post-processing. Among the acoustic features considered, the log-STFT branch provides the strongest single-model performance. With KNN-based post-processing, our best single system achieves a hierarchical F1 score (Hier. F1) of 80.84% on the BSD10k-v1.2 set under the same evaluation protocol as the baseline. We further construct ensemble systems by combining models with complementary acoustic features and classification heads, achieving Hier. F1 scores of 81.25% and 81.18%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a technical report on a system for DCASE 2026 Challenge Task 1, classifying heterogeneous audio according to the Broad Sound Taxonomy. It builds on CLAP audio-text representations and improves performance via three strategies: expanding the training set with a filtered subset of BSD35k, using multi-branch acoustic modeling with feature-specific branches (e.g., log-STFT), and applying hierarchy-aware classifiers with KNN-based post-processing. The central empirical claims are hierarchical F1 scores of 80.84% for the best single system and 81.25%/81.18% for two ensembles on the BSD10k-v1.2 evaluation set.
Significance. If the reported gains can be attributed to the multi-branch and hierarchy-aware components rather than data expansion choices, the work provides a competitive empirical baseline for hierarchical audio classification in a challenge setting and illustrates practical benefits of combining complementary acoustic features with post-processing.
major comments (2)
- [Abstract] Abstract: The performance claims (Hier. F1 of 80.84% single-system and 81.25%/81.18% ensemble) depend on expanding training data with a 'filtered subset of BSD35k,' yet the manuscript provides no description of filtering criteria, subset size, overlap verification against BSD10k-v1.2, or diagnostics for distribution shift/label noise. This is load-bearing for attributing gains to the proposed framework rather than the added data.
- [Experiments] Experiments (implied by reported scores): No ablation studies isolate the independent contributions of data expansion, multi-branch modeling, hierarchy-aware heads, and KNN post-processing; performance numbers are given without error bars, multiple runs, or statistical tests. This leaves open whether the three strategies produce the claimed gains independently of data selection.
minor comments (1)
- [Abstract] The abstract and methods would benefit from explicit reference to the exact baseline system and evaluation protocol used for comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our DCASE 2026 technical report. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (Hier. F1 of 80.84% single-system and 81.25%/81.18% ensemble) depend on expanding training data with a 'filtered subset of BSD35k,' yet the manuscript provides no description of filtering criteria, subset size, overlap verification against BSD10k-v1.2, or diagnostics for distribution shift/label noise. This is load-bearing for attributing gains to the proposed framework rather than the added data.
Authors: We agree that the filtering process requires explicit documentation to support attribution of gains to the framework components. The revised manuscript will include a dedicated subsection detailing the filtering criteria applied to BSD35k (label consistency verification and removal of noisy or ambiguous samples), the size of the retained subset, methods used to confirm zero overlap with BSD10k-v1.2 (metadata cross-checks and audio fingerprinting), and basic diagnostics for distribution shift and label noise. These additions will clarify the role of data expansion relative to the multi-branch and hierarchy-aware elements. revision: yes
-
Referee: [Experiments] Experiments (implied by reported scores): No ablation studies isolate the independent contributions of data expansion, multi-branch modeling, hierarchy-aware heads, and KNN post-processing; performance numbers are given without error bars, multiple runs, or statistical tests. This leaves open whether the three strategies produce the claimed gains independently of data selection.
Authors: We acknowledge the absence of component-wise ablations in the current report. The revised version will incorporate incremental ablation results demonstrating the contribution of each strategy (data expansion, multi-branch acoustic modeling, hierarchy-aware heads, and KNN post-processing) when added sequentially to the base CLAP model. On the request for error bars, multiple runs, and statistical tests: the challenge timeline and fixed evaluation protocol limited us to single-run reporting under the official setup; we will add a limitations paragraph noting this constraint while highlighting the consistent performance trends observed across complementary single systems and ensembles as corroborating evidence. revision: partial
Circularity Check
Empirical system description with no derivation chain present
full rationale
The paper is a DCASE 2026 technical report describing an audio classification pipeline (CLAP embeddings, multi-branch acoustic features, hierarchy-aware heads, KNN post-processing) and reporting direct empirical Hier. F1 scores on BSD10k-v1.2 after adding a filtered BSD35k subset. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the text. All performance numbers are obtained by running the described system on the challenge evaluation set; they do not reduce to any input by algebraic construction or redefinition. The data-expansion step is an experimental choice whose validity can be checked externally and does not create circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In DCASE 2026 Task 1, audio samples are annotated according to the Broad Sound Taxonomy (BST), where 23 second-level categories are grouped into 5 top-level classes [6]
INTRODUCTION Heterogeneous audio classification aims to recognize sound events and acoustic scenes from real-world recordings with diverse con- tent, recording conditions, and metadata quality. In DCASE 2026 Task 1, audio samples are annotated according to the Broad Sound Taxonomy (BST), where 23 second-level categories are grouped into 5 top-level classe...
2026
-
[2]
A Multi-Branch Hierarchy-Aware Framework for Heterogeneous Audio Classification
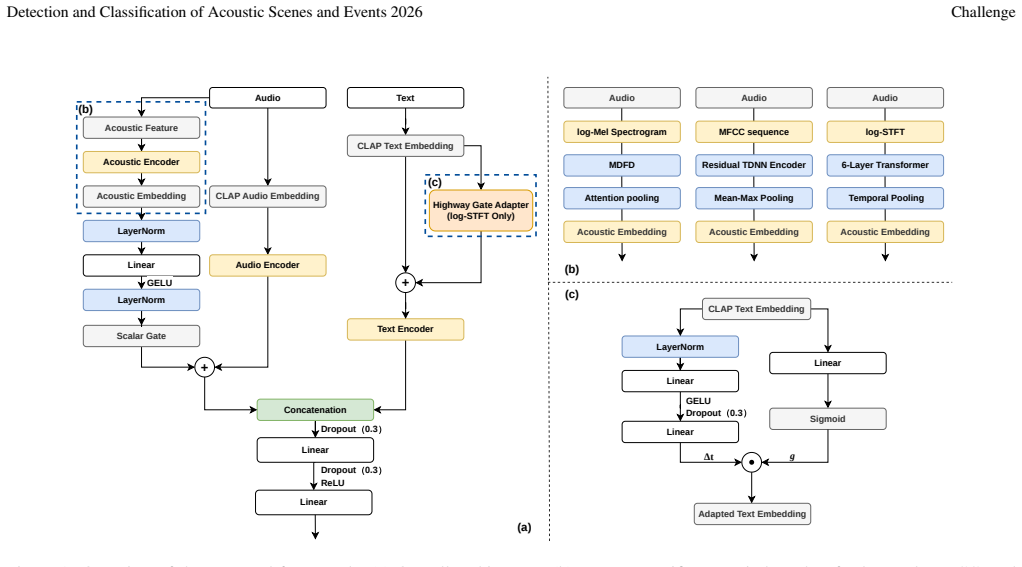
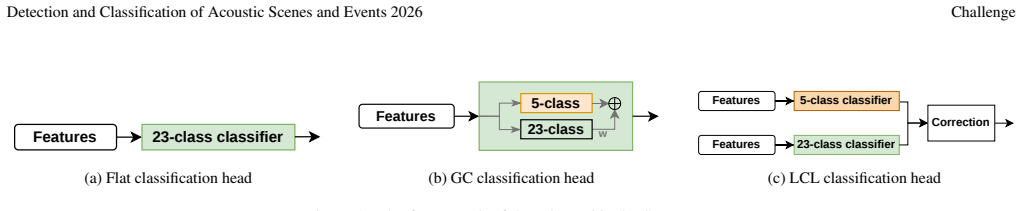
MODEL ARCHITECTURE AND TRAINING STRATEGY 2.1. Feature-Specific Acoustic Branch Framework As illustrated in Fig. 1(a), we extend the original CLAP-based ar- chitecture by introducing two enhancement modules: a feature- specific acoustic branch (b) on the audio side and a Highway Gate Adapter (c) on the text side. The acoustic branches are designed to compl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
+ BSD-Grand + KD-log-STFT
EXPERIMENTS 3.1. Data Preprossing and Training Details All audio files were first resampled to 16 kHz and converted into fixed-duration 5-second clips. Audio clips shorter than 5 seconds were padded to the target length. Based on the processed wave- form, we extracted three types of acoustic features: MFCC, log-Mel spectrogram, and log-STFT. More specific...
2026
-
[4]
CONCLUSION This technical report describes our system for DCASE 2026 Task
2026
-
[5]
Among single models, the log-STFT branch with post-processing achieves the best performance (80.84% Hier
We improve the CLAP-based baseline through BSD-Grand dataset expansion, multi-branch acoustic feature extraction (log- Mel, MFCC, log-STFT), hierarchy-aware classification heads, and KNN-based post-processing with knowledge distillation. Among single models, the log-STFT branch with post-processing achieves the best performance (80.84% Hier. F1). Our best...
-
[6]
DCASE 2025 challenge,
“DCASE 2025 challenge,” https://dcase.community/ challenge2025/, 2025
2025
-
[7]
IEEE conference publication center,
“IEEE conference publication center,” https://www.ieee.org/ portal/pages/pubs/confpubcenter/register.html, 2025. [3]PDF Specification for IEEE Xplore, https://www2. securecms.com/ICASSP2015/papers/PaperFormat/ Author-PDF-Guide-V32.pdf, IEEE
2025
-
[8]
Hierarchical clas- sification for acoustic scenes using deep learning,
B. Ding, T. Zhang, G. Liu, and C. Wang, “Hierarchical clas- sification for acoustic scenes using deep learning,”Applied Acoustics, vol. 212, p. 109594, 2023. Detection and Classification of Acoustic Scenes and Events 2026 Challenge
2023
-
[10]
A general- purpose sound taxonomy for the classification of heteroge- neous sound collections,
P. Anastasopoulou, X. Serra, and F. Font, “A general- purpose sound taxonomy for the classification of heteroge- neous sound collections,” https://www.researchsquare.com/ article/rs-7206795/v1, 2025, in press
2025
-
[11]
Hetero- geneous sound classification with the Broad Sound Taxonomy and dataset,
P. Anastasopoulou, J. Torrey, X. Serra, and F. Font, “Hetero- geneous sound classification with the Broad Sound Taxonomy and dataset,” inProceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), 2024
2024
-
[12]
Hi- erarchical and multimodal learning for heterogeneous sound classification,
P. Anastasopoulou, F. A. Dal R ´ı, X. Serra, and F. Font, “Hi- erarchical and multimodal learning for heterogeneous sound classification,” inProceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), 2025
2025
-
[13]
BSD35K-CS: Broad Sound Dataset 35K – Crowd Sourced,
P. Anastasopoulou and F. Font Corbera, “BSD35K-CS: Broad Sound Dataset 35K – Crowd Sourced,” Mar. 2026. [Online]. Available: https://doi.org/10.5281/zenodo.19187100
-
[14]
Functional annotation of genes using hierarchical text categorization,
S. Kiritchenko, S. Matwin, A. F. Famili,et al., “Functional annotation of genes using hierarchical text categorization,” in Proceedings of the ACL Workshop on Linking Biological Lit- erature, Ontologies and Databases: Mining Biological Se- mantics, 2005, pp. 76–83
2005
-
[15]
Large-scale contrastive language-audio pretrain- ing with feature fusion and keyword-to-caption augmenta- tion,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretrain- ing with feature fusion and keyword-to-caption augmenta- tion,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[16]
Nearest neighbor knowledge distillation for neural machine translation,
Z. Yang, R. Sun, and X. Wan, “Nearest neighbor knowledge distillation for neural machine translation,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2022, pp. 5546–5556
2022
-
[17]
SpecAugment: A simple data augmen- tation method for automatic speech recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “SpecAugment: A simple data augmen- tation method for automatic speech recognition,” inProceed- ings of Interspeech, 2019, pp. 2613–2617
2019
-
[18]
Data augmen- tation using random image cropping and patching for deep CNNs,
R. Takahashi, T. Matsubara, and K. Uehara, “Data augmen- tation using random image cropping and patching for deep CNNs,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 9, pp. 2917–2931, 2019
2019
-
[19]
KNN- enhanced deep learning against noisy labels,
S. Kong, Y . Li, J. Wang, A. Rezaei, and H. Zhou, “KNN- enhanced deep learning against noisy labels,”arXiv preprint arXiv:2012.04224, 2020
-
[20]
Teacher-student architecture for knowledge distillation: A survey,
C. Hu, X. Li, D. Liu, H. Wu, X. Chen, J. Wang, and X. Liu, “Teacher-student architecture for knowledge distillation: A survey,”arXiv preprint arXiv:2308.04268, 2023
-
[21]
Deep neural net- work ensembles using class-vs-class weighting,
R. Fabricius, O. ˇSuch, and P. Tarabek, “Deep neural net- work ensembles using class-vs-class weighting,”IEEE Ac- cess, vol. 11, pp. 77 703–77 715, 2023
2023
-
[22]
R. K. Srivastava, K. Greff, and J. Schmidhuber, “Highway net- works,”arXiv preprint arXiv:1505.00387, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
Learning Identity Mappings with Residual Gates
P. H. P. Savarese, L. O. Mazza, and D. R. Figueiredo, “Learn- ing identity mappings with residual gates,”arXiv preprint arXiv:1611.01260, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.