SPLIT: Cross-Lingual Empathy and Cultural Grounding in English and Ukrainian LLM Responses
Pith reviewed 2026-07-03 14:39 UTC · model grok-4.3
The pith
Two of three tested LLMs produce weaker empathetic and culturally grounded responses in Ukrainian than in English on crisis prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
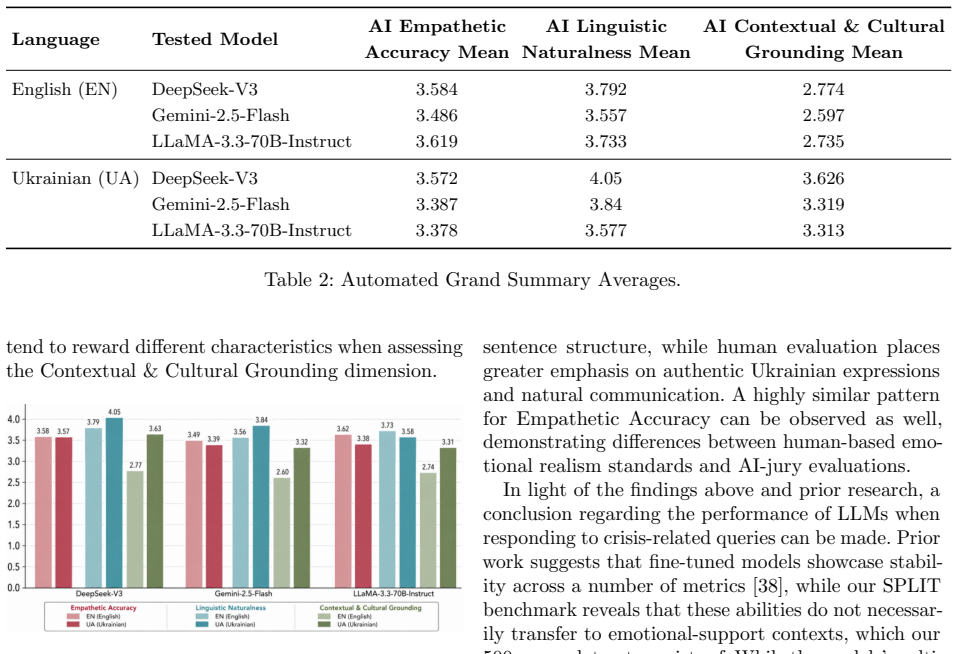
We introduce SPLIT, a 500-prompt benchmark designed to evaluate LLM consistency in generating emotionally grounded responses across five categories: Stress, Panic, Loneliness, Internal Displacement, and Tension. We evaluate three technically diverse LLMs across three dimensions: Empathetic Accuracy, Linguistic Naturalness, and Contextual & Cultural Grounding. Our findings reveal that Gemini-2.5-Flash and LLaMA-3.3-70B-Instruct degrade when transitioning to Ukrainian, while DeepSeek-V3 remains comparatively stable within our benchmark. We additionally find that human and AI evaluators agree weakly on empathy and naturalness but diverge on cultural grounding. We further argue that producing Uk
What carries the argument
The SPLIT benchmark: 500 prompts in five crisis categories scored on Empathetic Accuracy, Linguistic Naturalness, and Contextual & Cultural Grounding in both English and Ukrainian.
If this is right
- Model selection for multilingual emotional support should favor architectures that preserve performance across languages rather than those that degrade.
- Evaluation of crisis-related LLM output must include explicit cultural-grounding metrics beyond language fluency.
- LLM-as-a-jury methods are unreliable for cultural aspects and should be supplemented by human raters from the target culture.
- Future training or fine-tuning of LLMs for low-to-mid-resource languages should target emotional-support contexts separately from general text generation.
Where Pith is reading between the lines
- Deployment of current LLMs for crisis support in Ukrainian-speaking regions carries a risk of culturally mismatched advice that English-only testing would miss.
- The same degradation pattern may appear in other mid-resource languages; repeating the SPLIT design for Polish or Romanian would test this.
- The observed human-AI rater divergence implies that purely automated leaderboards will systematically under-detect cultural failures in emotional support tasks.
Load-bearing premise
The 500 prompts and the three scoring dimensions validly measure cross-lingual empathy and cultural grounding for the chosen crisis categories.
What would settle it
A replication using a fresh set of 500 prompts drawn from the same categories but with Ukrainian cultural experts as primary raters that finds no performance drop for Gemini or LLaMA.
Figures





read the original abstract
Large Language Models are increasingly deployed in emotional-support contexts and crisis-related situations. Nevertheless, their cross-lingual abilities in these circumstances remain underexplored. Existing benchmarks emphasize multilingual performance but rarely examine crisis-related empathy and cultural grounding in low-to-mid-resource languages. We introduce SPLIT, a 500-prompt benchmark designed to evaluate LLM consistency in generating emotionally grounded responses across five categories: Stress, Panic, Loneliness, Internal Displacement, and Tension. We evaluate three technically diverse LLMs across three dimensions: Empathetic Accuracy, Linguistic Naturalness, and Contextual & Cultural Grounding. The framework aims to assess and compare the quality of LLM responses in both English and Ukrainian languages, as well as to explore the reliability of the LLM-as-a-jury paradigm. Our findings reveal that Gemini-2.5-Flash and LLaMA-3.3-70B-Instruct degrade when transitioning to Ukrainian, while DeepSeek-V3 remains comparatively stable within our benchmark. We additionally find that human and AI evaluators agree weakly on empathy and naturalness but diverge on cultural grounding. We further argue that producing Ukrainian text is not equivalent to producing Ukrainian emotional support. Our findings may assist in the future development of more culturally tailored benchmark designs, as well as encourage a stronger emphasis on human-centered evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPLIT, a 500-prompt benchmark spanning five crisis categories (Stress, Panic, Loneliness, Internal Displacement, Tension) to evaluate three LLMs (Gemini-2.5-Flash, LLaMA-3.3-70B-Instruct, DeepSeek-V3) on Empathetic Accuracy, Linguistic Naturalness, and Contextual & Cultural Grounding in both English and Ukrainian. It reports degradation for the first two models when switching to Ukrainian, relative stability for DeepSeek-V3, and weak human-AI evaluator agreement on empathy/naturalness with divergence on cultural grounding, while arguing that Ukrainian text generation does not equate to culturally appropriate emotional support.
Significance. If the benchmark and evaluation framework validly isolate the targeted constructs, the work would usefully highlight gaps in cross-lingual empathy for crisis-related support in mid-resource languages and question the reliability of LLM-as-judge paradigms. The explicit comparison of human and automated evaluation is a constructive element that could guide more robust multilingual benchmark design.
major comments (3)
- [Abstract / Methods] Abstract and Methods (SPLIT benchmark design): The paper states the five crisis categories and three scoring dimensions but supplies no information on prompt authorship (native-speaker cultural adaptation versus translation), rubric operationalization, or any reliability metric such as inter-annotator agreement; this directly undermines the load-bearing claim that the observed language-gap and evaluator-divergence results reflect model behavior rather than benchmark artifacts.
- [Evaluation framework / Results] Evaluation framework and Results sections: No details are provided on the scoring rubrics for Contextual & Cultural Grounding, the statistical tests supporting degradation claims, or the correlation metrics and sample sizes used to establish 'weak agreement' between human and AI evaluators; without these, the central findings cannot be verified.
- [Methods] § on Ukrainian prompt construction: The absence of explicit criteria tying the cultural-grounding rubric to Ukrainian-specific norms (e.g., internal displacement or tension contexts) leaves open the possibility that the reported stability of DeepSeek-V3 and divergence on cultural grounding are artifacts of literal translation rather than genuine cross-lingual capability.
minor comments (2)
- [Abstract] The abstract is information-dense; separating the benchmark description, model results, and evaluator-agreement findings into distinct sentences would improve readability.
- [Methods] Consider adding a table summarizing the three dimensions with example rubric items to clarify the evaluation criteria for readers.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important areas where additional methodological transparency will strengthen the manuscript. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (SPLIT benchmark design): The paper states the five crisis categories and three scoring dimensions but supplies no information on prompt authorship (native-speaker cultural adaptation versus translation), rubric operationalization, or any reliability metric such as inter-annotator agreement; this directly undermines the load-bearing claim that the observed language-gap and evaluator-divergence results reflect model behavior rather than benchmark artifacts.
Authors: We agree that explicit details on benchmark construction are essential. Prompts were developed through collaboration with native Ukrainian speakers who created culturally adapted scenarios rather than performing literal translations from English. Rubrics were operationalized drawing on established empathy and cultural psychology literature, with dimension-specific criteria. We will add a dedicated Methods subsection describing the full prompt authorship process, rubric operationalization, and explicitly note that inter-annotator agreement was not computed (single primary annotator with spot checks); this limitation and its implications will be discussed. These additions will directly address the concern about potential benchmark artifacts. revision: yes
-
Referee: [Evaluation framework / Results] Evaluation framework and Results sections: No details are provided on the scoring rubrics for Contextual & Cultural Grounding, the statistical tests supporting degradation claims, or the correlation metrics and sample sizes used to establish 'weak agreement' between human and AI evaluators; without these, the central findings cannot be verified.
Authors: We acknowledge the omission of these specifics. The full scoring rubric for Contextual & Cultural Grounding (including example anchors for Ukrainian cultural elements) will be added to an appendix. Degradation claims were supported by paired statistical comparisons (to be named explicitly, e.g., Wilcoxon signed-rank tests with effect sizes). Human-AI agreement used Cohen's kappa and Pearson correlation on the full set of 500 prompts evaluated by three human raters and the LLM judge; exact sample sizes and coefficients will be reported. These details will be inserted into the Evaluation framework and Results sections. revision: yes
-
Referee: [Methods] § on Ukrainian prompt construction: The absence of explicit criteria tying the cultural-grounding rubric to Ukrainian-specific norms (e.g., internal displacement or tension contexts) leaves open the possibility that the reported stability of DeepSeek-V3 and divergence on cultural grounding are artifacts of literal translation rather than genuine cross-lingual capability.
Authors: We will revise the Ukrainian prompt construction subsection to explicitly map each element of the cultural-grounding rubric to Ukrainian-specific norms. This includes references to post-2022 internal displacement experiences, culturally normative expressions of tension and emotional restraint, and community support structures, drawn from consultations with Ukrainian cultural experts. The revision will clarify that prompts and rubrics were designed for cultural appropriateness rather than surface-level translation, thereby strengthening the interpretation of model differences. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation is self-contained
full rationale
The paper introduces the SPLIT benchmark (500 prompts across five crisis categories) and reports LLM performance on three human-defined scoring dimensions for English vs. Ukrainian responses. No equations, fitted parameters, or derivations are present. The central claims (model degradation patterns and human-AI evaluator agreement) are direct empirical measurements on the newly constructed dataset; they do not reduce to prior outputs, self-citations, or ansatzes by construction. The benchmark design itself is presented as an input rather than a derived result, and no load-bearing step relies on self-referential uniqueness theorems or renamed known patterns. This is a standard empirical model-comparison study whose validity rests on external human evaluation rather than internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five categories and 500 prompts adequately represent real-world crisis-related empathy and cultural grounding needs in English and Ukrainian.
Reference graph
Works this paper leans on
-
[1]
Empathic grounding: Explorations using multimodal interaction and large language models with conversational agents
Mehdi Arjmand, Farnaz Nouraei, Ian Steenstra, and Timothy Bickmore. Empathic grounding: Explorations using multimodal interaction and large language models with conversational agents. InProceedings of the 24th ACM International Conference on Intelligent Virtual Agents, IVA ’24, New York, NY, USA, 2024. Association for Computing Machinery
2024
-
[2]
Multi- lingual routing in mixture-of-experts, 2026
Lucas Bandarkar, Chenyuan Yang, Mohsen Fayyaz, Junlin Hu, and Nanyun Peng. Multi- lingual routing in mixture-of-experts, 2026
2026
-
[3]
Llms instead of human judges? a large scale empirical study across 20 nlp evalu- ation tasks, 2025
Anna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, et al. Llms instead of human judges? a large scale empirical study across 20 nlp evalu- ation tasks, 2025
2025
-
[4]
Judgesense: A benchmark for prompt sensitivity in llm-as-a-judge systems, 2026
Rohith Reddy Bellibatlu, Edward Raff, and Wen- bin Zhang. Judgesense: A benchmark for prompt sensitivity in llm-as-a-judge systems, 2026
2026
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Bal- can, and H. Lin, editors,Advances in Neural In- formation Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020
1901
-
[6]
Yu, Qiang Yang, and Xing Xie
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models, 2023
2023
-
[7]
Benchmarking llm-as-a-judge for long-form output evaluation, 2026
Junjie Chen, Yuxi Dong, Haitao Li Graves, Wei- hang Su, Yujia Zhou, Min Zhang, Yiqun Liu, and Qinyao Ai. Benchmarking llm-as-a-judge for long-form output evaluation, 2026
2026
-
[8]
Reduc- ing tokenization premiums for low-resource lan- guages, 2026
Geoffrey Churchill and Steven Skiena. Reduc- ing tokenization premiums for low-resource lan- guages, 2026
2026
-
[9]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
1960
-
[10]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities, 2025
Gheorghe Comanici, Eric Bieber, Mike Schaeker- mann, Ice Pasupat, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities, 2025
2025
-
[11]
Deepseek-v3 technical report, 2025
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, et al. Deepseek-v3 technical report, 2025
2025
-
[12]
Results of WMT23 metrics shared task: Metrics might be guilty but references are not innocent
Markus Freitag, Nitika Mathur, Chi-kiu Lo, et al. Results of WMT23 metrics shared task: Metrics might be guilty but references are not innocent. In Philipp Koehn, Barry Haddow, Tom Kocmi, and Christof Monz, editors,Proceedings of the Eighth Conference on Machine Translation, pages 578–628, Singapore, December 2023. Association for Computational Linguistics
2023
-
[13]
How reliable is multilin- gual llm-as-a-judge?, 2025
Xiyan Fu and Wei Liu. How reliable is multilin- gual llm-as-a-judge?, 2025
2025
-
[14]
The llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. The llama 3 herd of models, 2024. 16
2024
-
[15]
Judge’s verdict: A comprehensive analysis of llm judge capability through human agreement, 2025
Steve Han, Gilberto Titericz Junior, Tom Balough, and Wenfei Zhou. Judge’s verdict: A comprehensive analysis of llm judge capability through human agreement, 2025
2025
-
[16]
Mubench: Assessment of multilingual capabilities of large language models across 61 languages, 2025
Wenhan Han, Yifan Zhang, Zhixun Chen, Binbin Liu, Haobin Lin, Bingni Zhang, Taifeng Wang, Mykola Pechenizkiy, Meng Fang, and Yin Zheng. Mubench: Assessment of multilingual capabilities of large language models across 61 languages, 2025
2025
-
[17]
Xcomps: A mul- tilingual benchmark of conceptual minimal pairs, 2025
Linyang He, Ercong Nie, Sukru Samet Dindar, Arsalan Firoozi, Adrian Florea, Van Nguyen, Corentin Puffay, Riki Shimizu, Haotian Ye, Jonathan Brennan, Helmut Schmid, Hinrich Sch¨ utze, and Nima Mesgarani. Xcomps: A mul- tilingual benchmark of conceptual minimal pairs, 2025
2025
-
[18]
Op- timizing ai language models: A study of chatgpt-4 vs chatgpt-4o.ODU Digital Commons: Electrical & Computer Engineering Faculty Publications,
MD Fayaz Bin Hossen, Muhammad Enayetur Rahman, Muhammad Rezaur Rahman, et al. Op- timizing ai language models: A study of chatgpt-4 vs chatgpt-4o.ODU Digital Commons: Electrical & Computer Engineering Faculty Publications,
-
[19]
Accessed: June 15, 2026
Preprint. Accessed: June 15, 2026
2026
-
[20]
Evaluating the effectiveness of large language models in automated news article sum- marization, 2025
Lionel Richy Panlap Houamegni and Fatih Gedikli. Evaluating the effectiveness of large language models in automated news article sum- marization, 2025
2025
-
[21]
An empirical study of llm-as-a-judge for llm evaluation: Fine-tuned judge model is not a general substitute for gpt-4, 2025
Hui Huang, Xingyuan Bu, Hongli Zhou, Yingqi Qu, Jing Liu, Muyun Yang, Bing Xu, and Tiejun Zhao. An empirical study of llm-as-a-judge for llm evaluation: Fine-tuned judge model is not a general substitute for gpt-4, 2025
2025
-
[22]
Olympicarena medal ranks: Who is the most intelligent ai so far?, 2024
Zhen Huang, Zengzhi Wang, Shijie Xia, and Pengfei Liu. Olympicarena medal ranks: Who is the most intelligent ai so far?, 2024
2024
-
[23]
Eugene Jang, Kimin Lee, Jin-Woo Chung, Ke- untae Park, and Seungwon Shin. Improbable bigrams expose vulnerabilities of incomplete to- kens in byte-level tokenizers.arXiv preprint arXiv:2410.23684, 2024
-
[24]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chap- lot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L´ elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth´ ee Lacroix, and William El Sayed. Mistral 7b, 2023
2023
-
[25]
The state and fate of linguistic diversity and inclusion in the nlp world, 2021
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. The state and fate of linguistic diversity and inclusion in the nlp world, 2021
2021
-
[26]
Practicing with language models cultivates human empathic communication, 2026
Aakriti Kumar, Nalin Poungpeth, Diyi Yang, Bruce Lambert, and Matthew Groh. Practicing with language models cultivates human empathic communication, 2026
2026
-
[27]
From generation to judgment: Opportunities and challenges of llm-as-a-judge, 2025
Dawei Li, Bohan Jiang, Liangjie Huang, Alimo- hammad Beigi, Chengshuai Zhao, Zhen Tan, Am- rita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of llm-as-a-judge, 2025
2025
-
[28]
Preference leakage: A contamination problem in llm-as-a-judge, 2026
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. Preference leakage: A contamination problem in llm-as-a-judge, 2026
2026
-
[30]
Holistic evaluation of language models, 2023
Percy Liang, Rishi Bommasani, Tony Lee, et al. Holistic evaluation of language models, 2023
2023
-
[31]
Zheng Wei Lim, Alham Fikri Aji, and Trevor Cohn. Understanding cross-lingual inconsis- tency in large language models.arXiv preprint arXiv:2505.13141, 2025
-
[32]
Are multilingual llms culturally-diverse reasoners? an investigation into multicultural proverbs and sayings, 2024
Chen Cecilia Liu, Fajri Koto, Timothy Bald- win, and Iryna Gurevych. Are multilingual llms culturally-diverse reasoners? an investigation into multicultural proverbs and sayings, 2024. 17
2024
-
[33]
Paths not taken: Understand- ing and mending the multilingual factual recall pipeline, 2025
Meng Lu, Ruochen Zhang, Carsten Eickhoff, and Ellie Pavlick. Paths not taken: Understand- ing and mending the multilingual factual recall pipeline, 2025
2025
-
[34]
Emo- tional intelligence in large language models is fragmented across perception, cognition, and in- teraction, 2026
Minghao Lv, Lu Chen, Enchang Zhang, Anji Zhou, Xiaoran Xue, Hanyi Zhang, Fenghua Tang, Zhuo Rachel Han, and Mengyue Wu. Emo- tional intelligence in large language models is fragmented across perception, cognition, and in- teraction, 2026
2026
-
[35]
Indicparam: Bench- mark to evaluate llms on low-resource indic lan- guages, 2026
Ayush Maheshwari, Kaushal Sharma, Vivek Pa- tel, and Aditya Maheshwari. Indicparam: Bench- mark to evaluate llms on low-resource indic lan- guages, 2026
2026
-
[36]
Kar- naze, and Mai ElSherief
Ananya Malik, Nazanin Sabri, Melissa M. Kar- naze, and Mai ElSherief. Are LLMs empa- thetic to all? investigating the influence of multi-demographic personas on a model’s em- pathy. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 24938...
2025
-
[37]
Bridging minds and machines: Toward an integration of ai and cognitive science, 2025
Rui Mao, Qian Liu, Xiao Li, Erik Cambria, and Amir Hussain. Bridging minds and machines: Toward an integration of ai and cognitive science, 2025
2025
-
[38]
Masoud, Ziquan Liu, Martin Ferianc, Philip Treleaven, and Miguel Rodrigues
Reem I. Masoud, Ziquan Liu, Martin Ferianc, Philip Treleaven, and Miguel Rodrigues. Cul- tural alignment in large language models: An explanatory analysis based on hofstede’s cultural dimensions, 2024
2024
-
[39]
Poli Nemkova, Amrit Adhikari, Matthew Pearson, Vamsi Krishna Sadu, and Mark V. Albert. Cross- lingual stability and bias in instruction-tuned language models for humanitarian nlp, 2025
2025
-
[40]
Gpt-4 technical report, 2024
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, et al. Gpt-4 technical report, 2024
2024
-
[41]
Goucher, et al
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, et al. Gpt-4o system card, 2024
2024
-
[42]
The tokenizer tax across 25 european languages: Domain invariance, cross- lingual few-shot effects, and the ukrainian penalty, 2026
Volodymyr Ovcharov. The tokenizer tax across 25 european languages: Domain invariance, cross- lingual few-shot effects, and the ukrainian penalty, 2026
2026
-
[43]
Samuel J. Paech. Eq-bench: An emotional in- telligence benchmark for large language models, 2024
2024
-
[44]
Natural language processing applications for low-resource languages.Natural Language Processing, 31(2):183–197, 2025
Partha Pakray, Alexander Gelbukh, and Sivaji Bandyopadhyay. Natural language processing applications for low-resource languages.Natural Language Processing, 31(2):183–197, 2025
2025
-
[45]
Too polite to be human: Evaluating LLM empa- thy in Korean conversations via a DCT-based framework
Seoyoon Park, Jaehee Kim, and Hansaem Kim. Too polite to be human: Evaluating LLM empa- thy in Korean conversations via a DCT-based framework. In James Hale, Brian Deuksin Kwon, and Ritam Dutt, editors,Proceedings of the Third Workshop on Social Influence in Conversations (SICon 2025), pages 76–89, Vienna, Austria, jul
2025
-
[46]
Association for Computational Linguistics
-
[47]
Jos´ e Pombal, Ricardo Rei, and Andr´ e F. T. Mar- tins. Self-preference bias in rubric-based evalu- ation of large language models.arXiv preprint arXiv:2604.06996, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Multilingual != multicultural: Evaluating gaps between multilingual capabilities and cul- tural alignment in llms, 2025
Jonathan Rystrøm, Hannah Rose Kirk, and Scott Hale. Multilingual != multicultural: Evaluating gaps between multilingual capabilities and cul- tural alignment in llms, 2025
2025
-
[49]
Lund, Nishith Reddy Mannuru, Muhammad Arbab Arshad, Kadhim Hayawi, Ravi Varma Kumar Bevara, Aashrith Mannuru, and Laiba Batool
Sakib Shahriar, Brady D. Lund, Nishith Reddy Mannuru, Muhammad Arbab Arshad, Kadhim Hayawi, Ravi Varma Kumar Bevara, Aashrith Mannuru, and Laiba Batool. Putting gpt-4o to the sword: A comprehensive evaluation of lan- guage, vision, speech, and multimodal proficiency. Applied Sciences, 14(17), 2024
2024
-
[50]
Lin, Adam S
Ashish Sharma, Inna W. Lin, Adam S. Miner, David C. Atkins, and Tim Althoff. Towards fa- cilitating empathic conversations in online men- tal health support: A reinforcement learning ap- proach, 2021
2021
-
[51]
Julius Sim and Chris C. Wright. The kappa statistic in reliability studies: Use, interpretation, 18 and sample size requirements.Physical Therapy, 85(3):257–268, 2005
2005
-
[52]
Judging the judges: A systematic evaluation of bias mitigation strate- gies in llm-as-a-judge pipelines, 2026
Sadman Kabir Soumik. Judging the judges: A systematic evaluation of bias mitigation strate- gies in llm-as-a-judge pipelines, 2026
2026
-
[53]
Beyond the imitation game: Quantify- ing and extrapolating the capabilities of language models, 2023
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, et al. Beyond the imitation game: Quantify- ing and extrapolating the capabilities of language models, 2023
2023
-
[54]
Empowering smaller models: Tuning llama and gemma with chain-of-thought for ukrainian exam tasks, 2025
Mykyta Syromiatnikov, Victoria Ruvinskaya, and Nataliia Komleva. Empowering smaller models: Tuning llama and gemma with chain-of-thought for ukrainian exam tasks, 2025
2025
-
[55]
Syromiatnikov and Victoria M
Mykyta V. Syromiatnikov and Victoria M. Ruvin- skaya. Ua-code-bench: A competitive program- ming benchmark for evaluating large language models code generation in ukrainian.Informatics Culture Technology, 2:308–314, nov 2025
2025
-
[56]
Comparative analysis of automatic literature review using mistral large language model and human reviewers, 2024
Hsiao-Ching Tsai, Yueh-Fen Huang, and Chih- Wei Kuo. Comparative analysis of automatic literature review using mistral large language model and human reviewers, 2024. Research Square Preprint
2024
-
[57]
Atten- tion is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Atten- tion is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Ad- vances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[58]
All languages matter: Evalu- ating lmms on culturally diverse 100 languages, 2025
Ashmal Vayani, Dinura Dissanayake, Hasindri Watawana, et al. All languages matter: Evalu- ating lmms on culturally diverse 100 languages, 2025
2025
-
[59]
Vygotsky.Mind in Society: The Develop- ment of Higher Psychological Processes
Lev S. Vygotsky.Mind in Society: The Develop- ment of Higher Psychological Processes. Harvard University Press, Cambridge, MA, 1978
1978
-
[60]
Auxiliary-loss-free load balancing strategy for mixture-of-experts, 2024
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts, 2024
2024
-
[61]
Hearti- ficial intelligence: Exploring empathy in language models, 2025
Victoria Williams and Benjamin Rosman. Hearti- ficial intelligence: Exploring empathy in language models, 2025
2025
-
[62]
Evaluating knowledge- based cross-lingual inconsistency in large lan- guage models, 2024
Xiaolin Xing, Zhiwei He, Haoyu Xu, Xing Wang, Rui Wang, and Yu Hong. Evaluating knowledge- based cross-lingual inconsistency in large lan- guage models, 2024
2024
-
[63]
Multi-dimensional evaluation of empathetic dialog responses, 2024
Zhichao Xu and Jiepu Jiang. Multi-dimensional evaluation of empathetic dialog responses, 2024
2024
-
[64]
Llama beyond en- glish: An empirical study on language capability transfer, 2024
Jun Zhao, Zhihao Zhang, Luhui Gao, Qi Zhang, Tao Gui, and Xuanjing Huang. Llama beyond en- glish: An empirical study on language capability transfer, 2024
2024
-
[65]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Sto- ica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023
2023
-
[66]
Un- derstanding and enhancing the planning capabil- ity of language models via multi-token prediction, 2025
Qimin Zhong, Hao Liao, Siwei Wang, Mingyang Zhou, Xiaoqun Wu, Rui Mao, and Wei Chen. Un- derstanding and enhancing the planning capabil- ity of language models via multi-token prediction, 2025. 19
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.