DetailAnywhere: Fashion Detail Generation via Cross-Modal Feature Alignment Distillation
Pith reviewed 2026-07-03 15:54 UTC · model grok-4.3
The pith
DetailAnywhere generates photorealistic fashion details from focus markers on garment images via cross-modal distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
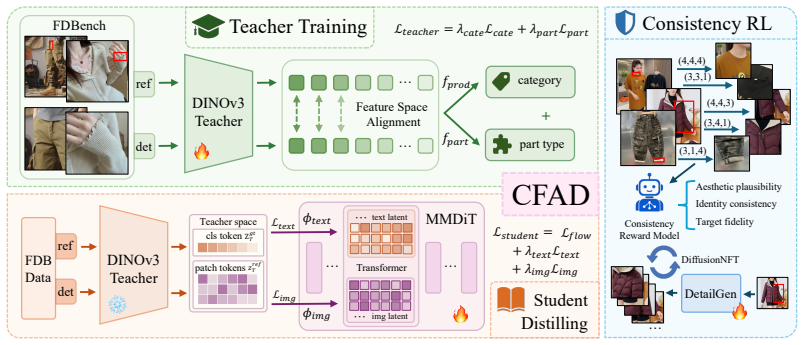
Cross-Modal Feature Alignment Distillation aligns both branches of a Multimodal Diffusion Transformer in a shared semantic space using a fine-tuned DINOv3 teacher, enabling the model to bridge the correspondence between a focus marker and the corresponding photorealistic close-up while preserving garment identity without any precise prompt.
What carries the argument
Cross-Modal Feature Alignment Distillation (CFAD), which performs dual-branch distillation from a DINOv3 teacher into a Multimodal Diffusion Transformer.
If this is right
- E-commerce platforms can let users request and receive close-up views of specific garment features directly from product photos.
- Generated details remain consistent with the reference image's identity even without text descriptions of the detail.
- The consistency reward model provides a way to optimize diffusion outputs for paired image quality along multiple axes.
- Non-template detail synthesis becomes feasible for apparel visualization tasks.
Where Pith is reading between the lines
- The same alignment strategy might apply to detail generation in other domains such as product design or interior visualization.
- FDBench could serve as a testbed for studying focus-conditioned generation beyond fashion.
- The dual-branch distillation might combine with other teacher models to handle additional conditioning signals.
Load-bearing premise
A fine-tuned DINOv3 teacher can align both branches of a Multimodal Diffusion Transformer in a shared semantic space to bridge the correspondence between a focus marker and a photorealistic close-up while preserving garment identity without precise prompts.
What would settle it
An experiment in which DetailAnywhere fails to outperform state-of-the-art open-source methods on FDBench quantitative metrics or in human evaluations would show the distillation approach does not solve the semantic gap.
Figures



read the original abstract
Diffusion-based generative AI has achieved remarkable success in e-commerce applications such as virtual try-on, poster generation, and product background synthesis. However, when making online purchasing decisions for apparel, consumers also desire the freedom to examine specific detail regions of interest, such as collars, cuffs, and fabric textures, yet existing methods have not explicitly studied this setting. We therefore formalize a new, non-template task: Fashion Detail Generation with focus conditioning, and release FDBench, the first benchmark comprising 40K+ human-verified reference-detail pairs across 41 different categories. This task poses a unique semantic gap challenge: the model must bridge the correspondence between a focus marker on a product reference image and a photorealistic close-up view of the indicated region, while faithfully preserving the garment's identity, without any precise prompt. To bridge this gap, we propose Cross-modal Feature Alignment Distillation (CFAD), which leverages a fine-tuned DINOv3 teacher to align both branches of a Multimodal Diffusion Transformer in a shared semantic space via dual-branch distillation. To further improve consistency between generated details and reference images, we introduce a consistency reward model that jointly scores image pairs along three quality axes and optimizes generation via reinforcement learning. Experiments show that our model DetailAnywhere significantly outperforms all state-of-the-art opensource methods across all metrics and human evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a new task called Fashion Detail Generation with focus conditioning for e-commerce apparel, releases the FDBench benchmark with 40K+ human-verified reference-detail pairs across 41 categories, proposes Cross-modal Feature Alignment Distillation (CFAD) that uses a fine-tuned DINOv3 teacher to align both branches of a Multimodal Diffusion Transformer in a shared semantic space, introduces a consistency reward model scoring image pairs on three axes and optimized via reinforcement learning, and claims that the resulting DetailAnywhere model significantly outperforms all state-of-the-art open-source methods across all metrics and human evaluations.
Significance. If the outperformance claims hold under rigorous validation, the work would be significant for advancing controllable generative models in fashion e-commerce by addressing an unstudied detail-region task without requiring precise prompts, while providing the first dedicated benchmark; the distillation and RL consistency components represent a targeted technical approach to the semantic gap problem.
minor comments (1)
- The abstract states outperformance 'across all metrics' but does not name the specific metrics, baselines, or quantitative values, which hinders immediate assessment of the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for their review and for acknowledging the task formalization, FDBench benchmark, and the proposed CFAD distillation plus RL consistency components. We note that the report lists no specific major comments, only an overall summary and a conditional significance assessment. We address the recommendation of 'uncertain' by confirming that all experimental claims in the manuscript are supported by the provided metrics, human evaluations, and open-source baselines as described.
Circularity Check
No significant circularity detected
full rationale
The provided information consists solely of the abstract, which describes the task, benchmark, and proposed method at a high level without any equations, derivations, or specific mathematical steps. No load-bearing claims reduce to self-definitions or fitted inputs by construction, as no such details are available for inspection. The central claim of outperformance is presented as an experimental result rather than a derived prediction from inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[2]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[3]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorber, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[4]
Viton-hd: High-resolution virtual try-on via misalignment-aware normalization
Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[5]
Tryondiffusion: A tale of two unets
Luyang Zhu, Dawei Yang, Tyler Zhu, Fitsum Reda, William Chan, Chitwan Saharia, Mohammad Norouzi, and Ira Kemelmacher-Shlizerman. Tryondiffusion: A tale of two unets. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[6]
Improving diffusion models for authentic virtual try-on in the wild
Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, and Jinwoo Shin. Improving diffusion models for authentic virtual try-on in the wild. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[7]
Postermaker: Towards high-quality product poster generation with accurate text rendering
Yifan Gao, Zihang Lin, Chuanbin Liu, Min Zhou, Tiezheng Ge, Bo Zheng, and Hongtao Xie. Postermaker: Towards high-quality product poster generation with accurate text rendering. arXiv preprint arXiv:2504.06632, 2025
-
[8]
Sixiang Chen, Jianyu Lai, Jialin Gao, Hengyu Shi, Zhongying Liu, Tian Ye, Junfeng Luo, Xiaoming Wei, and Lei Zhu. Posteromni: Generalized artistic poster creation via task distillation and unified reward feedback.arXiv preprint arXiv:2602.12127, 2026
-
[9]
Multimodal garment designer: Human-centric latent diffusion models for fashion image editing
Alberto Baldrati, Davide Morelli, Giuseppe Cartella, Marcella Cornia, Marco Bertini, and Rita Cucchiara. Multimodal garment designer: Human-centric latent diffusion models for fashion image editing. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[10]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow im- age editing instructions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[11]
Enhancing virtual try-on with synthetic pairs and error-aware noise scheduling
Nannan Li, Kevin J Shih, and Bryan A Plummer. Enhancing virtual try-on with synthetic pairs and error-aware noise scheduling. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21238–21247, 2025
2025
-
[12]
Deepfashion: Powering robust clothes recognition and retrieval with rich annotations
Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[13]
E-comiq-zh: A human-aligned dataset and bench- mark for fine-grained evaluation of e-commerce posters with chain-of-thought
Meiqi Sun, Mingyu Li, and Junxiong Zhu. E-comiq-zh: A human-aligned dataset and bench- mark for fine-grained evaluation of e-commerce posters with chain-of-thought. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[14]
Qwen Team. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
FLUX.2: Frontier visual intelligence
Black Forest Labs. FLUX.2: Frontier visual intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[16]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Multimodal representation alignment for image generation: Text-image interleaved control is easier than you think
Liang Chen, Shuai Bai, Wenhao Chai, Weichu Xie, Haozhe Zhao, Leon Vinci, Junyang Lin, and Baobao Chang. Multimodal representation alignment for image generation: Text-image interleaved control is easier than you think. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6146–6156, 2025
2025
-
[18]
Jaa-Yeon Lee, Byunghee Cha, Jeongsol Kim, and Jong Chul Ye. Aligning text to image in diffusion models is easier than you think.arXiv preprint arXiv:2503.08250, 2025
-
[19]
Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42(4):1–10, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42(4):1–10, 2023
2023
-
[20]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research (TMLR), 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[22]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InIEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[23]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning Workshop, 2015
2015
-
[24]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Diffusion models beat gans on image synthesis.Advances in Neural Information Processing Systems (NeurIPS), 2021
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis.Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[26]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[28]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[29]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.International Conference on Learning Representations (ICLR), 2023
2023
-
[30]
Edit in 2D, Verify in 3D: Reinforcement Learning for Multi-view Consistent Scene Editing
Jiyuan Wang, Chunyu Lin, Lei Sun, Zhi Cao, Yuyang Yin, Lang Nie, Zhenlong Yuan, Xi- angxiang Chu, Yunchao Wei, Kang Liao, et al. Geometry-guided reinforcement learning for multi-view consistent 3d scene editing.arXiv preprint arXiv:2603.03143, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Learning to generate stylized handwritten text via a unified representation of style, content, and noise
Honglie Wang, Yan-Ming Zhang, Wangzi Yao, Fei Yin, and Cheng-Lin Liu. Learning to generate stylized handwritten text via a unified representation of style, content, and noise. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[32]
Template-guided cascaded diffusion for stylized handwritten chinese text-line generation
Honglie Wang, Minsi Ren, Yan-Ming Zhang, Fei Yin, and Cheng-Lin Liu. Template-guided cascaded diffusion for stylized handwritten chinese text-line generation. InInternational Conference on Document Analysis and Recognition, pages 149–166. Springer, 2025
2025
-
[33]
Sculpting features from noise: Reward-guided hierarchical diffusion for task-optimal feature transformation.Advances in Neural Information Processing Systems, 38:23452–23474, 2026
Nanxu Gong, Zijun Li, Sixun Dong, Haoyue Bai, Wangyang Ying, Xinyuan Wang, and Yanjie Fu. Sculpting features from noise: Reward-guided hierarchical diffusion for task-optimal feature transformation.Advances in Neural Information Processing Systems, 38:23452–23474, 2026. 12
2026
-
[34]
From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
JiYuan Wang, Chunyu Lin, Lei Sun, Rongying Liu, Lang Nie, Mingxing Li, Kang Liao, Xiangxiang Chu, and Yao Zhao. From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
-
[35]
Symmcompletion: High-fidelity and high-consistency point cloud completion with symmetry guidance
Hongyu Yan, Zijun Li, Kunming Luo, Li Lu, and Ping Tan. Symmcompletion: High-fidelity and high-consistency point cloud completion with symmetry guidance. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9094–9102, 2025
2025
-
[36]
Diffpc: Diffusion-based high perceptual fidelity image compression with semantic refinement
Yichong Xia, Yimin Zhou, Jinpeng Wang, Baoyi An, Haoqian Wang, Yaowei Wang, and Bin Chen. Diffpc: Diffusion-based high perceptual fidelity image compression with semantic refinement. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[37]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[38]
Sdedit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations (ICLR), 2022
2022
-
[39]
Zijun Li, Hongyu Yan, Shijie Li, Kunming Luo, Li Lu, Xulei Yang, and Weisi Lin. Diffpcn: Latent diffusion model based on multi-view depth images for point cloud completion.arXiv preprint arXiv:2509.23723, 2025
-
[40]
Jiyuan Wang, Chunyu Lin, Cheng Guan, Lang Nie, Jing He, Haodong Li, Kang Liao, and Yao Zhao. Jasmine: Harnessing diffusion prior for self-supervised depth estimation.arXiv preprint arXiv:2503.15905, 2025
-
[41]
Hongyu Yan, Kunming Luo, Weiyu Li, Yixun Liang, Shengming Li, Jingwei Huang, Chunchao Guo, and Ping Tan. Posemaster: Generating 3d characters in arbitrary poses from a single image.arXiv preprint arXiv:2506.21076, 2025
-
[42]
Digging into con- trastive learning for robust depth estimation with diffusion models
Jiyuan Wang, Chunyu Lin, Lang Nie, Kang Liao, Shuwei Shao, and Yao Zhao. Digging into con- trastive learning for robust depth estimation with diffusion models. InProceedings of the 32nd ACM International Conference on Multimedia, MM ’24, page 4129–4137. ACM, October 2024. doi: 10.1145/3664647.3681168. URLhttp://dx.doi.org/10.1145/3664647.3681168
-
[43]
Jiyuan Wang, Chunyu Lin, Lang Nie, Shujun Huang, Yao Zhao, Xing Pan, and Rui Ai. Weath- erdepth: Curriculum contrastive learning for self-supervised depth estimation under adverse weather conditions. In2024 IEEE International Conference on Robotics and Automation (ICRA), page 4976–4982. IEEE, May 2024. doi: 10.1109/icra57147.2024.10611100. URL http://dx.d...
-
[44]
Denoising diffusion autoencoders are unified self-supervised learners
Weilai Xiang, Hongyu Yang, Di Huang, and Yunhong Wang. Denoising diffusion autoencoders are unified self-supervised learners. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[45]
Emer- gent correspondence from image diffusion
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emer- gent correspondence from image diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[46]
Cross modal distillation for supervision transfer
Saurabh Gupta, Judy Hoffman, and Jitendra Malik. Cross modal distillation for supervision transfer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[47]
Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on
Jeongho Kim, Gyojung Gu, Minho Park, Sunghyun Park, and Jaegul Choo. Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[48]
Catvton: Concatenation is all you need for virtual try-on with diffusion models
Zheng Chong, Xiao Dong, Haoxiang Li, Shiyue Zhang, Wenqing Zhang, Xujie Zhang, Hanqing Zhao, Dongmei Jiang, and Xiaodan Liang. Catvton: Concatenation is all you need for virtual try-on with diffusion models. InInternational Conference on Learning Representations (ICLR), 2025. 13
2025
-
[49]
Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on
Davide Morelli, Alberto Baldrati, Giuseppe Cartella, Marcella Cornia, Marco Bertini, and Rita Cucchiara. Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on. InACM Multimedia, 2023
2023
-
[50]
Texture- preserving diffusion models for high-fidelity virtual try-on
Xu Yang, Changxing Ding, Zhibin Hong, Junhao Huang, Jin Tao, and Xiangmin Xu. Texture- preserving diffusion models for high-fidelity virtual try-on. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[51]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[52]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[53]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[55]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editre- ward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[57]
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, and Zheng Liu. Editscore: Unlocking online RL for image editing via high-fidelity reward modeling.arXiv preprint arXiv:2509.23909, 2025
-
[58]
Deepfm: A factorization-machine based neural network for ctr prediction
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: A factorization-machine based neural network for ctr prediction. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2017
2017
-
[59]
Autopp: Towards automated product poster generation and optimization, 2025
Jiahao Fan, Yuxin Qin, Wei Feng, Yanyin Chen, Yaoyu Li, Ao Ma, Yixiu Li, Li Zhuang, Haoyi Bian, Zheng Zhang, Jingjing Lv, Junjie Shen, and Ching Law. Autopp: Towards automated product poster generation and optimization, 2025. URL https://arxiv.org/abs/2512. 21921
2025
-
[60]
Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought.Advances in Neural Information Processing Systems, 38:63841– 63869, 2025
Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, and Shikun Zhang. Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought.Advances in Neural Information Processing Systems, 38:63841– 63869, 2025
2025
-
[61]
Arc: Robots adaptive risk-aware robust control via distributional reinforcement learning
Junlong Wu, Yi Cheng, Hang Liu, and Houde Liu. Arc: Robots adaptive risk-aware robust control via distributional reinforcement learning. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10656–10663. IEEE, 2025
2025
-
[62]
CaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
Jiyuan Wang, Huan Ouyang, Jiuzhou Lin, Chunyu Lin, Dewen Fan, Boheng Zhang, Haonan Fan, Fei Zuo, Jia Sun, Huaiqing Wang, et al. Cac: Advancing video reward models via hierarchical spatiotemporal concentrating.arXiv preprint arXiv:2605.11723, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
High quality underwater image compression with adaptive color correction
Yimin Zhou, Yichong Xia, Sicheng Pan, Bin Chen, Yaowei Li, Jiawei Li, Mingyao Hong, Zhi Wang, and Yaowei Wang. High quality underwater image compression with adaptive color correction. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8587–8591. IEEE, 2026. 14
2026
-
[64]
EVE: Verifiable Self-Evolution of MLLMs via Executable Visual Transformations
Yongrui Heng, Chaoya Jiang, Han Yang, Shikun Zhang, and Wei Ye. Eve: Verifiable self- evolution of mllms via executable visual transformations.arXiv preprint arXiv:2604.18320, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
FLUX.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.https://github.com/black-forest-labs/flux, 2024
2024
-
[66]
Jeeyung Kim, Erfan Esmaeili, and Qiang Qiu. Text embedding is not all you need: Attention control for text-to-image semantic alignment with text self-attention maps.arXiv preprint arXiv:2411.15236, 2024
-
[67]
Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18262–18272, 2025
2025
-
[68]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
HPSv3: Towards wide-spectrum human preference score.arXiv preprint arXiv:2508.03789, 2025
Yuhang Ma et al. HPSv3: Towards wide-spectrum human preference score.arXiv preprint arXiv:2508.03789, 2025
-
[71]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[73]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, et al. Qwen3- vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer. In NeurIPS, 2025
2025
-
[76]
FireRed-Image-Edit-1.0 technical report.arXiv preprint arXiv:2602.13344, 2026
Super Intelligence Team. FireRed-Image-Edit-1.0 technical report.arXiv preprint arXiv:2602.13344, 2026
-
[77]
JoyAI-Image: Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
Lin Song, Wenbo Li, Guoqing Ma, Wei Tang, Bo Wang, Yuan Zhang, Yijun Yang, Yicheng Xiao, Jianhui Liu, et al. Awaking spatial intelligence in unified multimodal understanding and generation.arXiv preprint arXiv:2605.04128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
GPT-Image-1: Image generation in the OpenAI API
OpenAI. GPT-Image-1: Image generation in the OpenAI API. https://openai.com/index/ image-generation-api/, 2025
2025
-
[79]
Nano Banana 2 (Gemini 3.1 Flash Image Preview)
Google DeepMind. Nano Banana 2 (Gemini 3.1 Flash Image Preview). https: //ai.google.dev/gemini-api/docs/image-generation, 2026. Model ID: gemini-3.1-flash-image-preview; accessed 2026-05-07
2026
-
[80]
Seedream 5.0 Lite
ByteDance Seed. Seedream 5.0 Lite. https://seed.bytedance.com/en/seedream5_0_ lite, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.