Recognition: 2 theorem links
· Lean TheoremCaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
Pith reviewed 2026-05-13 05:56 UTC · model grok-4.3
The pith
CaC shows that a hierarchical temporal-then-spatial scan lets vision-language models detect subtle video anomalies more reliably for use as rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
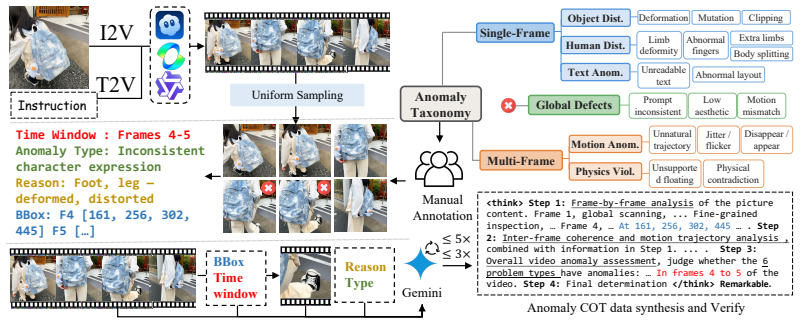
CaC is a coarse-to-fine anomaly reward model based on vision-language models. During inference it first runs a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding inside the selected interval, and finally reaches judgments through structured spatiotemporal chain-of-thought reasoning. The model is trained on a newly built large-scale generated-video anomaly dataset using a three-stage pipeline: single- and multi-frame supervised fine-tuning for anchoring, followed by group relative policy optimization that adds temporal and spatial IoU rewards to supervise the intermediate localization steps.
What carries the argument
Hierarchical spatiotemporal concentrating: the three-step inference process of global temporal anchoring, localized spatial grounding, and chain-of-thought reasoning, trained with added IoU rewards in reinforcement learning.
If this is right
- Accuracy on fine-grained anomaly benchmarks rises when the model concentrates hierarchically rather than scoring globally.
- Using CaC as a reward signal during generation reduces the rate of anomalies in the resulting videos.
- Overall visual quality of generated videos improves when the reward model supplies more localized feedback.
- The added temporal and spatial IoU rewards in training produce more grounded intermediate localization outputs.
- The progressive three-stage training allows the model to acquire both basic anchoring and advanced reasoning capabilities.
Where Pith is reading between the lines
- The same staged temporal-then-spatial pattern could be tested on other sequential media such as audio tracks or multi-view 3D sequences.
- If the localization rewards generalize, they might serve as a template for training interpretable reasoning in other vision-language tasks beyond anomaly detection.
- Extending the dataset construction pipeline to include longer videos or real captured footage would test whether the gains remain when the domain shifts.
- The approach opens a route to reward models that output not only a score but also explicit time and space attributions that human reviewers can inspect.
Load-bearing premise
The newly constructed generated-video anomaly dataset is representative of the distributions that appear in real deployment of video generation systems.
What would settle it
Apply the trained CaC model to videos produced by a different generator or containing anomaly types absent from the training set, then measure whether the reported accuracy gains and anomaly reduction still appear.
Figures



read the original abstract
In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CaC, a coarse-to-fine anomaly reward model for videos based on vision-language models. It first performs global temporal scanning to identify anomalous windows, then fine-grained spatial grounding, followed by structured spatiotemporal Chain-of-Thought reasoning. To support this, the authors construct a large-scale generated-video anomaly dataset with per-frame bounding-box annotations, temporal windows, and attribution labels. Training proceeds in three stages: single- and multi-frame supervised fine-tuning for anchoring, followed by two-turn Group Relative Policy Optimization (GRPO) augmented with Temporal and Spatial IoU rewards. The central claims are a 25.7% accuracy improvement on fine-grained anomaly benchmarks and an 11.7% reduction in generated-video anomalies (with improved overall quality) when CaC is used as a reward signal.
Significance. If the performance claims are substantiated with rigorous controls, the work would advance video reward modeling by introducing interpretable hierarchical spatiotemporal reasoning and IoU-supervised localization. The construction of the annotated dataset and the GRPO augmentation with localization rewards constitute concrete contributions that could be adopted in video generation alignment pipelines. The approach is technically coherent and addresses a genuine gap in fine-grained anomaly handling, though its broader impact hinges on demonstrated generalizability beyond the custom dataset.
major comments (3)
- [§5] §5 (Experiments): The headline claims of 25.7% accuracy improvement and 11.7% anomaly reduction are stated without reported baselines, statistical significance tests, ablation studies isolating the IoU rewards or the hierarchical stages, or explicit data splits. This absence prevents verification that the gains arise from the proposed concentrating mechanism rather than dataset-specific fitting.
- [§3] §3 (Dataset Construction): The newly constructed generated-video anomaly dataset with per-frame boxes, temporal windows, and attribution labels is load-bearing for all training and evaluation. No cross-distribution hold-out, external benchmark comparison, or analysis of distributional shift (e.g., artifact patterns, motion profiles) is described, leaving the representativeness assumption untested.
- [§4.2] §4.2 (GRPO Training): The Temporal and Spatial IoU rewards are introduced to supervise intermediate localization, yet no sensitivity analysis on their coefficients, comparison to standard accuracy-only GRPO, or quantitative ablation of the two-turn structure is provided. These omissions directly affect the claim that the rewards produce more grounded reasoning.
minor comments (2)
- The abstract and method description refer to 'structured spatiotemporal Chain-of-Thought reasoning' without an explicit example or template of the reasoning format in the main text or supplementary material.
- Figure captions and axis labels in the experimental results would benefit from explicit indication of which curves correspond to the full CaC model versus ablated variants.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful review of our manuscript. We are pleased that the referee recognizes the potential of our hierarchical spatiotemporal concentrating approach and the contributions of the new dataset and GRPO training strategy. We address each of the major comments below and commit to substantial revisions to address the concerns raised.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The headline claims of 25.7% accuracy improvement and 11.7% anomaly reduction are stated without reported baselines, statistical significance tests, ablation studies isolating the IoU rewards or the hierarchical stages, or explicit data splits. This absence prevents verification that the gains arise from the proposed concentrating mechanism rather than dataset-specific fitting.
Authors: We fully agree that the experimental section requires more rigorous validation to support the headline claims. In the revised manuscript, we will expand §5 to include a comprehensive set of baselines from prior video anomaly detection methods and reward models. Statistical significance will be assessed using appropriate tests such as Student's t-test or Wilcoxon signed-rank test over multiple random seeds. We will add ablation studies that systematically isolate the impact of the Temporal and Spatial IoU rewards as well as each component of the hierarchical pipeline (global temporal scanning, fine-grained spatial grounding, and structured CoT). Explicit details on data splits, including the proportions for training, validation, and testing, along with any stratification by anomaly type, will be provided. These changes will allow readers to verify that the reported improvements are due to the proposed CaC mechanism. revision: yes
-
Referee: [§3] §3 (Dataset Construction): The newly constructed generated-video anomaly dataset with per-frame boxes, temporal windows, and attribution labels is load-bearing for all training and evaluation. No cross-distribution hold-out, external benchmark comparison, or analysis of distributional shift (e.g., artifact patterns, motion profiles) is described, leaving the representativeness assumption untested.
Authors: We recognize that demonstrating the dataset's robustness is essential. In the revision, we will introduce a cross-distribution hold-out evaluation by reserving subsets generated from unseen video generation models or with distinct anomaly characteristics. Where feasible, we will perform comparisons on adapted external benchmarks to assess transferability. Furthermore, we will add a dedicated analysis subsection quantifying distributional shifts, including metrics on artifact patterns (e.g., frequency of specific visual artifacts) and motion profiles (e.g., optical flow statistics). This will provide evidence supporting the dataset's representativeness for generated video anomalies. revision: yes
-
Referee: [§4.2] §4.2 (GRPO Training): The Temporal and Spatial IoU rewards are introduced to supervise intermediate localization, yet no sensitivity analysis on their coefficients, comparison to standard accuracy-only GRPO, or quantitative ablation of the two-turn structure is provided. These omissions directly affect the claim that the rewards produce more grounded reasoning.
Authors: We agree that these analyses are necessary to substantiate the effectiveness of our reward design. The revised paper will include a sensitivity study on the weighting coefficients for the Temporal IoU and Spatial IoU rewards, reporting performance across a range of values. We will also present direct comparisons between our IoU-augmented GRPO and a baseline using only accuracy rewards. Additionally, we will quantify the benefit of the two-turn structure through an ablation study comparing one-turn and two-turn variants. These results will be incorporated into §4.2 to more convincingly demonstrate that the IoU rewards lead to improved localization and grounded reasoning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs a new dataset with per-frame annotations and attribution labels, then applies a three-stage training process (SFT followed by GRPO augmented with explicitly defined Temporal and Spatial IoU rewards). The reported 25.7% accuracy gain and 11.7% anomaly reduction are measured outcomes on fine-grained benchmarks and generated videos, not quantities that reduce by the paper's own equations to parameters fitted on the target test distribution. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation; the spatiotemporal concentrating mechanism and reward design remain independent of the final evaluation metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- Temporal and Spatial IoU reward coefficients
axioms (1)
- domain assumption Vision-language models possess sufficient spatiotemporal grounding capacity that can be elicited via progressive fine-tuning and RL
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process... Rtemp(yi) = |Fpred ∩ Fgt| / |Fpred ∪ Fgt| ... Rspa(yi) = mean IoU(bpred_m, bgt_m)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-turn GRPO... first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ghazal Alinezhad Noghre, Armin Danesh Pazho, and Hamed Tabkhi. A survey on video anomaly detection via deep learning: Human, vehicle, and environment.arXiv preprint arXiv:2508.14203, 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025
-
[4]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[5]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024
work page 2024
-
[6]
Yuanhao Cai, Kunpeng Li, Menglin Jia, Jialiang Wang, Junzhe Sun, Feng Liang, Weifeng Chen, Felix Juefei-Xu, Chu Wang, Ali Thabet, et al. Phygdpo: Physics-aware groupwise direct preference optimization for physically consistent text-to-video generation.arXiv preprint arXiv:2512.24551, 2025
-
[7]
CropVLM: Learning to Zoom for Fine-Grained Vision-Language Perception
Miguel Carvalho, Helder Dias, and Bruno Martins. Cropvlm: Learning to zoom for fine-grained vision-language perception, 2026. URLhttps://arxiv.org/abs/2511.19820
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2503.23461 (2025)
Nikai Du, Zhennan Chen, Shan Gao, Zhizhou Chen, Xi Chen, Zhengkai Jiang, Jian Yang, and Ying Tai. Textcrafter: Accurately rendering multiple texts in complex visual scenes.arXiv preprint arXiv:2503.23461, 2025
-
[11]
Gemini-3-pro.https://deepmind.google/models/gemini/pro/, 2025
Google. Gemini-3-pro.https://deepmind.google/models/gemini/pro/, 2025
work page 2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page Pith review arXiv 2026
-
[15]
Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2105–2123, 2024. 10
work page 2024
-
[16]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan
Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, et al. Videoscore2: Think before you score in generative video evaluation.arXiv preprint arXiv:2509.22799, 2025
-
[17]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tade- vosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2568–2577, 2025
work page 2025
-
[18]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Dongfu Jiang, Max Ku, Tianle Li, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu Chen. Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024
work page 2024
-
[21]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
work page 2023
-
[22]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Subjective-aligned dataset and metric for text-to-video quality assessment
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, and Ning Liu. Subjective-aligned dataset and metric for text-to-video quality assessment. InProceedings of the 32nd ACM International Conference on Multimedia, pages 7793–7802, 2024
work page 2024
-
[24]
Yifei Li, Wenzhao Zheng, Yanran Zhang, Runze Sun, Yu Zheng, Lei Chen, Jie Zhou, and Jiwen Lu. Skyra: Ai-generated video detection via grounded artifact reasoning.arXiv preprint arXiv:2512.15693, 2025
-
[25]
Youfang Lin, Jinji Fu, Haomin Wen, Jiyuan Wang, Zhenjie Wei, Yuting Qiang, Xiaowei Mao, Lixia Wu, Haoyuan Hu, Yuxuan Liang, et al. Drl4aoi: A drl framework for semantic-aware aoi segmentation in location-based services.arXiv preprint arXiv:2412.05437, 2024
-
[26]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Dynamic typography: Bringing text to life via video diffusion prior
Zichen Liu, Yihao Meng, Hao Ouyang, Yue Yu, Bolin Zhao, Daniel Cohen-Or, and Huamin Qu. Dynamic typography: Bringing text to life via video diffusion prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14787–14797, 2025
work page 2025
-
[29]
Ovi: Twin backbone cross-modal fusion for audio-video generation
Chetwin Low, Weimin Wang, and Calder Katyal. Ovi: Twin backbone cross-modal fusion for audio-video generation.arXiv preprint arXiv:2510.01284, 2025
-
[30]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025. 11
work page 2025
-
[31]
Yi Peng, Peiyu Wang, Xiaokun Wang, Yichen Wei, Jiangbo Pei, Weijie Qiu, Ai Jian, Yunzhuo Hao, Jiachun Pan, Tianyidan Xie, et al. Skywork r1v: Pioneering multimodal reasoning with chain-of-thought.arXiv preprint arXiv:2504.05599, 2025
-
[32]
Pejaver V Rao and Lawrence L Kupper. Ties in paired-comparison experiments: A general- ization of the bradley-terry model.Journal of the American Statistical Association, 62(317): 194–204, 1967
work page 1967
-
[33]
Weiming Ren, Huan Yang, Ge Zhang, Cong Wei, Xinrun Du, Wenhao Huang, and Wenhu Chen. Consisti2v: Enhancing visual consistency for image-to-video generation.arXiv preprint arXiv:2402.04324, 2024
-
[34]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Yuxiang Shen, Hailong Huang, Zhenkun Gao, Xueheng Li, Man Zhou, Chengjun Xie, Haoxuan Che, Xuanhua He, and Jie Zhang. Svfeye: A semantic-visual fusion framework with multi-scale visual context for multimodal reasoning, 2026. URL https://arxiv.org/abs/2603.00171
-
[37]
Hao Tan, Jun Lan, Senyuan Shi, Zichang Tan, Zijian Yu, Huijia Zhu, Weiqiang Wang, Jun Wan, and Zhen Lei. Videoveritas: Ai-generated video detection via perception pretext reinforcement learning.arXiv preprint arXiv:2602.08828, 2026
-
[38]
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Xiansheng Chen, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-rft: Reinforcement fine-tuning for visual reasoning of vision language models.arXiv preprint arXiv:2503.20752, 2025
-
[39]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
-
[41]
Bridging Time and Space: Decoupled Spatio-Temporal Alignment for Video Grounding
Xuezhen Tu, Jingyu Wu, Fangyu Kang, Qingpeng Nong, Kaijin Zhang, Chaoyue Niu, and Fan Wu. Bridging time and space: Decoupled spatio-temporal alignment for video grounding, 2026. URLhttps://arxiv.org/abs/2604.08014
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Jiankang Wang, Zhihan Zhang, Zhihang Liu, Yang Li, Jiannan Ge, Hongtao Xie, and Yongdong Zhang. Spacevllm: Endowing multimodal large language model with spatio-temporal video grounding capability, 2025. URLhttps://arxiv.org/abs/2503.13983
-
[44]
TAGRPO: Boosting GRPO on image-to- video generation with direct trajectory alignment, 2026
Jin Wang, Jianxiang Lu, Guangzheng Xu, Comi Chen, Haoyu Yang, Linqing Wang, Peng Chen, Mingtao Chen, Zhichao Hu, Longhuang Wu, et al. Tagrpo: Boosting grpo on image-to-video generation with direct trajectory alignment.arXiv preprint arXiv:2601.05729, 2026. 12
-
[45]
Digging into contrastive learning for robust depth estimation with diffusion models
Jiyuan Wang, Chunyu Lin, Lang Nie, Kang Liao, Shuwei Shao, and Yao Zhao. Digging into contrastive learning for robust depth estimation with diffusion models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 4129–4137. ACM, 2024
work page 2024
-
[46]
Jiyuan Wang, Chunyu Lin, Cheng Guan, Lang Nie, Jing He, Haodong Li, Kang Liao, and Yao Zhao. Jasmine: Harnessing diffusion prior for self-supervised depth estimation.arXiv preprint arXiv:2503.15905, 2025
-
[47]
From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
JiYuan Wang, Chunyu Lin, Lei Sun, Rongying Liu, Lang Nie, Mingxing Li, Kang Liao, Xiangxiang Chu, and Yao Zhao. From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
-
[48]
Jiyuan Wang, Chunyu Lin, Lei Sun, Zhi Cao, Yuyang Yin, Lang Nie, Zhenlong Yuan, Xi- angxiang Chu, Yunchao Wei, Kang Liao, et al. Geometry-guided reinforcement learning for multi-view consistent 3d scene editing.arXiv preprint arXiv:2603.03143, 2026
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Qunzhong Wang, Jie Liu, Jiajun Liang, Yilei Jiang, Yuanxing Zhang, Jinyuan Chen, Yaozhi Zheng, Xintao Wang, Pengfei Wan, Xiangyu Yue, et al. Vr-thinker: Boosting video reward models through thinking-with-image reasoning.arXiv preprint arXiv:2510.10518, 2025
-
[51]
Lift: Leveraging human feedback for text-to-video model alignment,
Yibin Wang, Zhiyu Tan, Junyan Wang, Xiaomeng Yang, Cheng Jin, and Hao Li. Lift: Leveraging human feedback for text-to-video model alignment.arXiv preprint arXiv:2412.04814, 2024
-
[52]
Yibin Wang, Zhimin Li, Yuhang Zang, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Unified multimodal chain-of-thought reward model through reinforcement fine-tuning.arXiv preprint arXiv:2505.03318, 2025
-
[53]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Yuan Wang, Borui Liao, Huijuan Huang, Jinda Lu, Ouxiang Li, Kuien Liu, Meng Wang, and Xiang Wang. Thinking with frames: Generative video distortion evaluation via frame reward model.arXiv preprint arXiv:2601.04033, 2026
-
[55]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. InProceedings of the IEEE/CVF international conference on computer vision, pages 7623–7633, 2023
work page 2023
-
[56]
RewardDance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, et al. Rewarddance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
-
[57]
Shang Wu, Chenwei Xu, Zhuofan Xia, Weijian Li, Lie Lu, Pranav Maneriker, Fan Du, Manling Li, and Han Liu. Phyprompt: Rl-based prompt refinement for physically plausible text-to-video generation.arXiv preprint arXiv:2603.03505, 2026
-
[58]
Tianhe Wu, Jian Zou, Jie Liang, Lei Zhang, and Kede Ma. Visualquality-r1: Reasoning-induced image quality assessment via reinforcement learning to rank.arXiv preprint arXiv:2505.14460, 2025
-
[59]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[60]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation.arXiv preprint arXiv:2412.21059, 2024. 13
-
[61]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Reason: Reinforced causal search with information bottleneck for video understanding, 2025
Yuan Zhou, Litao Hua, Shilong Jin, Wentao Huang, and Haoran Duan. Reason: Reinforced causal search with information bottleneck for video understanding, 2025. URL https:// arxiv.org/abs/2511.12530
-
[63]
Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Zhenheng Yang, and Yang You. Focus: Efficient keyframe selection for long video understanding, 2025. URL https: //arxiv.org/abs/2510.27280. 14 Appendix In this appendix, we provide additional implementation details, experimental results, analyses, and discussions for a comprehensive evaluation and ...
-
[64]
Human analysis(if there is no visible person, you must explicitly write “no visible person”), and the analysis must explicitly state whether an anomaly exists. Clothing: precisely describe the clothing type, color, clarity of patterns or textures, and all accessories. Posture: describe the overall pose and specifically describe the positions of the limbs....
-
[65]
Object identification: list all visible objects
Object analysis, and the analysis must explicitly state whether an anomaly exists. Object identification: list all visible objects. Object attributes: describe the shape, color, and texture clarity of each object, and evaluate whether its size proportion is reasonable. Spatial relationship: state the positions between objects and people, and between objec...
-
[66]
Environment analysis, and the analysis must explicitly state whether an anomaly exists. Scene: clearly specify the background type. Lighting: judge the direction of the main light source, and describe the position, length, and softness or hardness of shadows. Environment details: check whether the background contains blur, repeated textures, geometric dis...
-
[67]
The error type is exactly the same: the error category used and described by the AI model must be completely consistent with the human annotation
-
[68]
The erroneous object is essentially the same: the erroneous object identified by the AI model must refer to the same entity as the human annotation. the erroneous object identified by the AI model must refer to the same entity or the same region as the human annotation
-
[69]
The error phenomenon is essentially the same: the error phenomenon described by the AI model must be identical in underlying nature to the phenomenon in the human annotation
-
[70]
The time range matches strictly: the time range identified by the AI model must match the time range in the human annotation under the following criteria: the start-frame deviation must be no more than 2 frames; the end-frame deviation must be no more than 2 frames; the overall overlap of the time range must be at least 85%. the time range identified by t...
-
[71]
There is an exact one-to-one correspondence: each analysis item produced by the AI model must form an exact one-to-one match with each human-annotated error description. Please output only “consistent” or “inconsistent,” and do not add any other explanation. Figure S6:Prompt for Consistency Verification.Colors follow Fig. S4. 27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.