AnyGroundBench: A Specialized-Domain Benchmark for Video Grounding in Vision-Language Models
Pith reviewed 2026-07-03 15:44 UTC · model grok-4.3
The pith
Current vision-language models fail at spatio-temporal video grounding in specialized domains even with in-context learning examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AnyGroundBench shows that state-of-the-art vision-language models cannot reliably perform spatio-temporal video grounding when faced with specialized domains; both zero-shot generalization and in-context learning produce failures that expose weaknesses in reasoning about rare visual concepts and intricate temporal dynamics.
What carries the argument
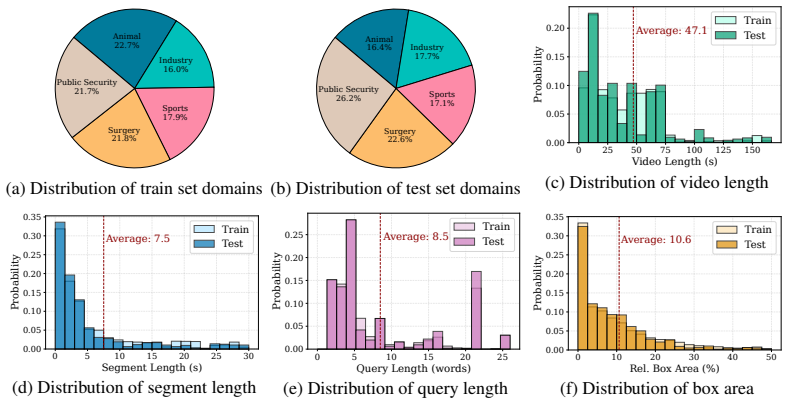
AnyGroundBench supplies paired training and test subsets across animal, industry, sports, surgery, and public security domains, each with dense expert spatio-temporal annotations on newly captured videos, to isolate domain adaptation performance.
If this is right
- Evaluation of video grounding must incorporate dedicated domain-adaptation protocols rather than rely solely on general zero-shot benchmarks.
- Models require new mechanisms to handle rare visual concepts and complex motion sequences that do not appear in everyday pre-training data.
- Research progress in this area can now be tracked systematically by measuring gains on the provided training and test splits.
- Practical deployment in specialized fields will need explicit adaptation strategies beyond current in-context learning approaches.
Where Pith is reading between the lines
- Real-world systems using these models may need retrieval or fine-tuning pipelines tailored to narrow domains rather than depending on general capabilities.
- The benchmark design could be extended to test adaptation under stricter computational limits or with fewer training examples.
- Similar domain-shift problems are likely to appear in other multimodal tasks such as action recognition or video question answering.
Load-bearing premise
The five chosen domains and the new expert-annotated videos capture the real distribution shifts and spatio-temporal difficulties that specialized applications actually present.
What would settle it
A model that reaches high accuracy on the AnyGroundBench test sets under the zero-shot or in-context learning protocols described would directly contradict the reported failure.
Figures



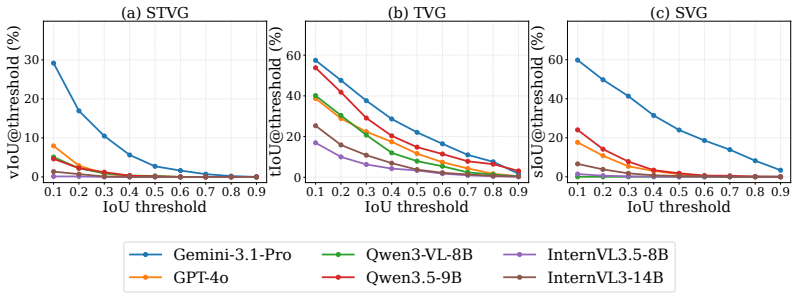
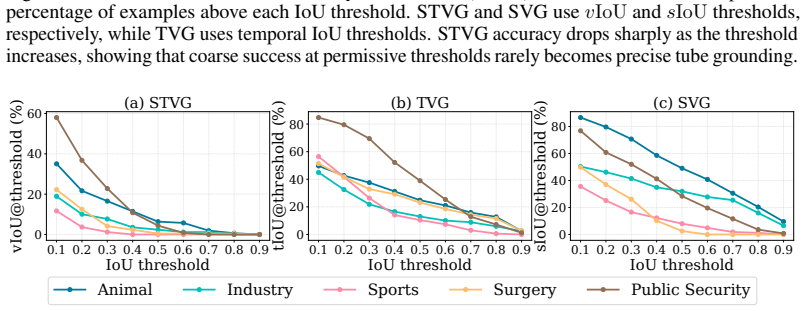
read the original abstract
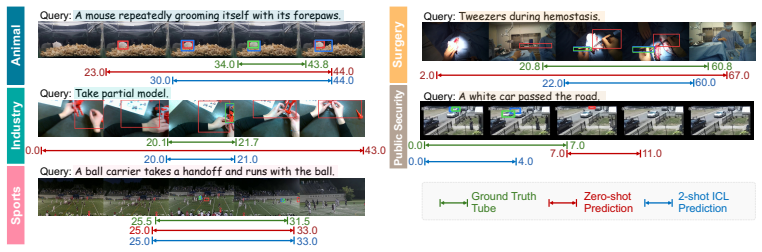
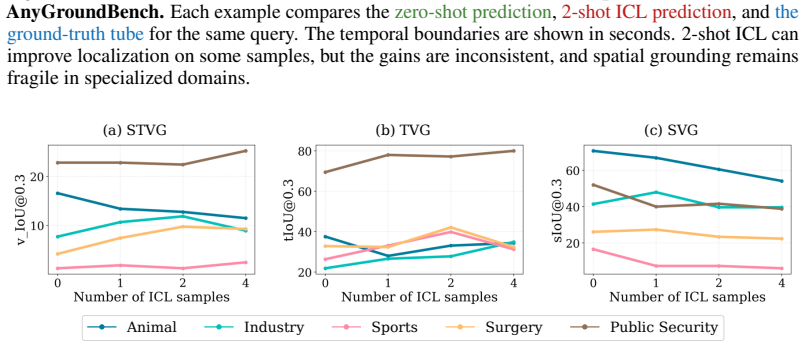
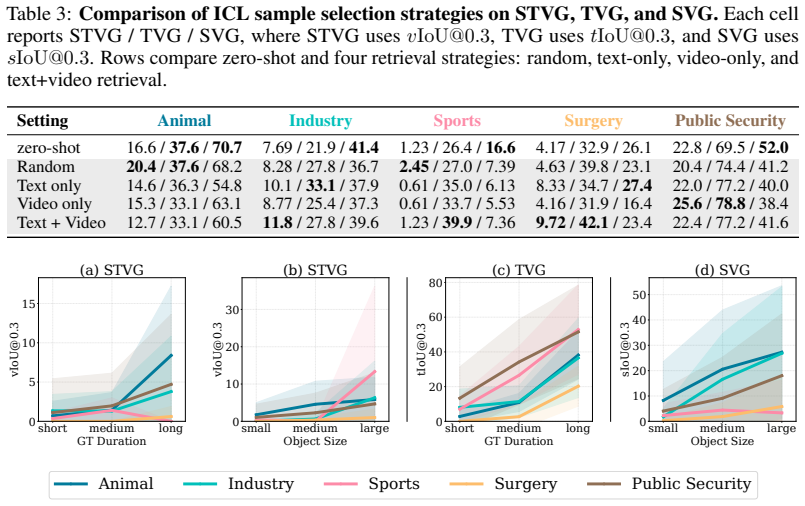
Vision-Language Models (VLMs) have demonstrated immense promise in Spatio-Temporal Video Grounding (STVG). However, current evaluation protocols are largely confined to zero-shot assessments on general, daily-life benchmarks. This creates a critical disconnect from real-world applications in specialized fields, where models inevitably encounter rare visual concepts and complex spatio-temporal dynamics. Since exhaustive pre-training across infinite data distributions is infeasible, the ability to adapt to novel domains is essential. To bridge this gap, we introduce AnyGroundBench, a domain-adaptation benchmark designed to shift the STVG evaluation paradigm from static zero-shot testing to rigorous domain adaptation. Targeting five specialized domains (animal, industry, sports, surgery, and public security), AnyGroundBench pairs newly captured videos such as expert-annotated mouse behaviors with established datasets, unifying them through dense, high-fidelity spatio-temporal annotations. Crucially, the benchmark provides dedicated training subsets to systematically measure domain adaptability. We extensively evaluate 15 state-of-the-art VLMs, assessing their zero-shot generalization and In-Context Learning (ICL) capabilities under practical computational constraints. Ultimately, our findings reveal that current models fail in both zero-shot and ICL-based adaptation when confronted with specialized domains, exposing critical flaws in spatio-temporal reasoning that future research must address.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AnyGroundBench, a domain-adaptation benchmark for spatio-temporal video grounding (STVG) targeting five specialized domains (animal, industry, sports, surgery, public security). It combines newly captured videos (including expert-annotated mouse behaviors) with existing datasets under dense spatio-temporal annotations, supplies dedicated training subsets, and evaluates 15 VLMs on zero-shot generalization and in-context learning (ICL) under computational constraints. The central finding is that current models fail in both regimes, exposing critical flaws in spatio-temporal reasoning.
Significance. If the benchmark's annotations and domain shifts are verifiably representative, the work would usefully redirect STVG evaluation from general-domain zero-shot testing toward measurable adaptation, providing a concrete testbed and falsifiable failure modes for future VLM research.
major comments (2)
- [Abstract / Benchmark Construction] Abstract and benchmark-construction section: no inter-annotator agreement statistics or quantitative distribution-shift metrics (e.g., feature-space divergence or label-distribution distances between general and specialized domains) are reported. These quantities are load-bearing for the claim that observed failures reflect model limitations rather than benchmark artifacts.
- [Evaluation Protocol] Evaluation section: the abstract (and apparently the reported experiments) omits exact ICL prompting templates, data-split definitions, and any statistical tests on the reported performance drops. Without these, the assertion that models 'fail' in domain adaptation cannot be independently verified.
minor comments (1)
- [Data Release] Clarify whether the 'newly captured videos' are released with the benchmark and under what license.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on AnyGroundBench. The comments highlight important aspects of benchmark validation and reproducibility that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / Benchmark Construction] Abstract and benchmark-construction section: no inter-annotator agreement statistics or quantitative distribution-shift metrics (e.g., feature-space divergence or label-distribution distances between general and specialized domains) are reported. These quantities are load-bearing for the claim that observed failures reflect model limitations rather than benchmark artifacts.
Authors: We agree that inter-annotator agreement (IAA) statistics and quantitative distribution-shift metrics are important to confirm that performance drops arise from model limitations in specialized domains rather than annotation variability or weak domain shifts. The revised manuscript will report IAA for the newly captured and expert-annotated videos (e.g., mouse behaviors) and will include distribution-shift metrics such as feature-space divergence computed via pre-trained vision embeddings together with label-distribution distances (e.g., Jensen-Shannon divergence on action and spatial categories) between the general-domain source data and the five specialized domains. revision: yes
-
Referee: [Evaluation Protocol] Evaluation section: the abstract (and apparently the reported experiments) omits exact ICL prompting templates, data-split definitions, and any statistical tests on the reported performance drops. Without these, the assertion that models 'fail' in domain adaptation cannot be independently verified.
Authors: We concur that exact ICL prompting templates, precise data-split definitions, and statistical tests are required for independent verification of the failure claims. The revised version will supply the complete ICL prompt templates employed, explicit definitions of all data splits (including how the dedicated training subsets per domain are constructed and used), and statistical significance tests (paired t-tests or Wilcoxon signed-rank tests with reported p-values) on the observed performance drops between general and specialized domains for both zero-shot and ICL regimes. revision: yes
Circularity Check
No circularity: empirical benchmark and evaluations only
full rationale
The paper introduces AnyGroundBench, a new video dataset across five domains with expert annotations, then reports zero-shot and ICL evaluations of 15 VLMs. No equations, fitted parameters, predictions, or derivations appear in the text. All claims rest on direct empirical measurements against external model outputs and the new annotations; nothing reduces by construction to self-defined inputs or self-citation chains. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 Technical Report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
VideoMolmo: Spatio-Temporal Grounding Meets Pointing.arXiv preprint arXiv:2506.05336, 2025
Ghazi Shazan Ahmad, Ahmed Heakl, Hanan Gani, Abdelrahman Shaker, Zhiqiang Shen, Fahad Shahbaz Khan, and Salman Khan. VideoMolmo: Spatio-Temporal Grounding Meets Pointing.arXiv preprint arXiv:2506.05336, 2025
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Language Models are Few-Shot Learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language Models are Few-Shot Learners . InNeurIPS, 2020
2020
-
[5]
Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Max Ehrlich, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, and Guilin Liu. Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models. In NeurIPS, 2026
2026
-
[6]
Weakly-Supervised Spatio- Temporally Grounding Natural Sentence in Video
Zhenfang Chen, Lin Ma, Wenhan Luo, and Kwan-Yee Kenneth Wong. Weakly-Supervised Spatio- Temporally Grounding Natural Sentence in Video. InACL, 2019
2019
-
[7]
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning.arXiv preprint arXiv:2503.11495, 2025
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
MeViS: A Large-scale Benchmark for Video Segmentation with Motion Expressions
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, and Chen Change Loy. MeViS: A Large-scale Benchmark for Video Segmentation with Motion Expressions. InICCV, 2023
2023
-
[10]
Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
Yuhao Dong, Shulin Tian, Shuai Liu, Shuangrui Ding, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang, and Ziwei Liu. Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition. arXiv preprint arXiv:2602.08439, 2026
-
[11]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. InC...
2025
-
[12]
Surgical Tool Detection in Open Surgery Videos
Ryo Fujii, Ryo Hachiuma, Hiroki Kajita, and Hideo Saito. Surgical Tool Detection in Open Surgery Videos. Applied Sciences, 2022
2022
-
[13]
EgoSurgery-Phase: A Dataset of Surgical Phase Recognition from Egocentric Open Surgery Videos
Ryo Fujii, Masashi Hatano, Hideo Saito, and Hiroki Kajita. EgoSurgery-Phase: A Dataset of Surgical Phase Recognition from Egocentric Open Surgery Videos. InMICCAI, 2024
2024
-
[14]
Ryo Fujii, Hideo Saito, and Ryo Hachiuma. VIOLA: Towards Video In-Context Learning with Minimal Annotations.arXiv preprint arXiv:2601.15549, 2026
-
[15]
Ryo Fujii, Hideo Saito, and Hiroki Kajita. EgoSurgery-Tool: A Dataset of Surgical Tool and Hand Detection from Egocentric Open Surgery Videos.arXiv preprint arXiv:2406.03095, 2024
-
[16]
OmniGround: A Comprehensive Spatio-Temporal Grounding Benchmark for Real-World Complex Scenarios
Hong Gao, Jingyu Wu, Xiangkai Xu, Kangni Xie, Yunchen Zhang, Bin Zhong, Xurui Gao, and Min-Ling Zhang. OmniGround: A Comprehensive Spatio-Temporal Grounding Benchmark for Real-World Complex Scenarios. InCVPR, 2026. 10
2026
-
[17]
Gemini 3 Flash Model Card
Google DeepMind. Gemini 3 Flash Model Card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf, 2025
2025
-
[18]
Emrullah Ildiz, Xuechen Zhang, Mahdi Soltanolkotabi, Marco Mondelli, and Samet Oymak
Halil Alperen Gozeten, M. Emrullah Ildiz, Xuechen Zhang, Mahdi Soltanolkotabi, Marco Mondelli, and Samet Oymak. Test-Time Training Provably Improves Transformers as In-context Learners. InICML, 2025
2025
-
[19]
Ross, Carl V ondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, and Jitendra Malik
Chunhui Gu, Chen Sun, David A. Ross, Carl V ondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, and Jitendra Malik. A V A: A Video Dataset of Spatio-Temporally Localized Atomic Visual Actions. InCVPR, 2018
2018
-
[20]
Context-Guided Spatio-Temporal Video Grounding
Xin Gu, Heng Fan, Yan Huang, Tiejian Luo, and Libo Zhang. Context-Guided Spatio-Temporal Video Grounding. InCVPR, 2024
2024
-
[21]
Xin Gu, Haoji Zhang, Qihang Fan, Jingxuan Niu, Zhipeng Zhang, Libo Zhang, Guang Chen, Fan Chen, Longyin Wen, and Sijie Zhu. Thinking With Bounding Boxes: Enhancing Spatio-Temporal Video Grounding via Reinforcement Fine-Tuning.arXiv preprint arXiv:2511.21375, 2025
-
[22]
Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
Miran Heo, Min-Hung Chen, De-An Huang, Sifei Liu, Subhashree Radhakrishnan, Seon Joo Kim, Yu-Chiang Frank Wang, and Ryo Hachiuma. Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks. InCVPR, 2025
2025
-
[23]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. InICLR, 2022
2022
-
[24]
VTimeLLM: Empower LLM to Grasp Video Moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. VTimeLLM: Empower LLM to Grasp Video Moments. InCVPR, 2024
2024
-
[25]
Visual Prompt Tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual Prompt Tuning. InECCV, 2022
2022
-
[26]
Embracing Consistency: A One-Stage Approach for Spatio-Temporal Video Grounding
Yang Jin, yongzhi li, Zehuan Yuan, and Yadong MU. Embracing Consistency: A One-Stage Approach for Spatio-Temporal Video Grounding. InNeurIPS, 2022
2022
-
[27]
Neurobiology of Rodent Self-Grooming and Its Value for Translational Neuroscience.Nature Reviews Neuroscience, 2016
Allan V Kalueff, Adam Michael Stewart, Cai Song, Kent C Berridge, Ann M Graybiel, and John C Fentress. Neurobiology of Rodent Self-Grooming and Its Value for Translational Neuroscience.Nature Reviews Neuroscience, 2016
2016
-
[28]
Language-Free Training for Zero-Shot Video Grounding
Dahye Kim, Jungin Park, Jiyoung Lee, Seongheon Park, and Kwanghoon Sohn. Language-Free Training for Zero-Shot Video Grounding. InWACV, 2023
2023
-
[29]
VideoICL: Confidence- based Iterative In-context Learning for Out-of-Distribution Video Understanding
Kangsan Kim, Geon Park, Youngwan Lee, Woongyeong Yeo, and Sung Ju Hwang. VideoICL: Confidence- based Iterative In-context Learning for Out-of-Distribution Video Understanding. InCVPR, 2025
2025
-
[30]
RefEgo: Referring Expression Comprehension Dataset from First-Person Perception of Ego4D
Shuhei Kurita, Naoki Katsura, and Eri Onami. RefEgo: Referring Expression Comprehension Dataset from First-Person Perception of Ego4D. InICCV, 2023
2023
-
[31]
Kento Kuwataka and Taiji Suzuki. Test-Time Training Enhances In-Context Learning of Nonlinear Functions.arXiv preprint 2509.25741, 2026
-
[32]
VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
Chenglin Li, Qianglong Chen, Feng Han, Yikun Wang, Xingxi Yin, Yan Gong, Ruilin Li, Yin Zhang, and Jiaqi Wang. VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning.arXiv preprint 2601.15724, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
LLaV A-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xiaoming Wei, and Si Liu. LLaV A-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding. In CVPR, 2025
2025
-
[34]
MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
Yixuan Li, Lei Chen, Runyu He, Zhenzhi Wang, Gangshan Wu, and Limin Wang. MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions. InICCV, 2021
2021
-
[35]
GroundingGPT: Language Enhanced Multi-modal Grounding Model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, YiQing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Vu Tu, Zhida Huang, and Tao Wang. GroundingGPT: Language Enhanced Multi-modal Grounding Model. InACL, 2024
2024
-
[36]
Fine-grained Spatiotemporal Grounding on Egocentric Videos
Shuo Liang, Yiwu Zhong, Zi-Yuan Hu, Yeyao Tao, and Liwei Wang. Fine-grained Spatiotemporal Grounding on Egocentric Videos. InICCV, 2025
2025
-
[37]
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA: Weight-Decomposed Low-Rank Adaptation. InICML, 2024. 11
2024
-
[38]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. InECCV, 2024
2024
-
[39]
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, and Zhuochen Wang. Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence.arXiv preprint arXiv:2510.20579, 2025
-
[40]
Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding
Xun Long Ng, Kian Eng Ong, Qichen Zheng, Yun Ni, Si Yong Yeo, and Jun Liu. Animal Kingdom: A Large and Diverse Dataset for Animal Behavior Understanding. InCVPR, 2022
2022
-
[41]
Lavanchy, and Nicolas Padoy
Chinedu Innocent Nwoye, Kareem Elgohary, Anvita Srinivas, Fauzan Zaid, Joël L. Lavanchy, and Nicolas Padoy. CholecTrack20: A Multi-Perspective Tracking Dataset for Surgical Tools. InCVPR, 2025
2025
-
[42]
Enrich and Detect: Video Temporal Grounding with Multimodal LLMs
Pramanick, Shraman and Mavroudi, Effrosyni and Song, Yale and Chellappa, Rama and Torresani, Lorenzo and Afouras, Triantafyllos. Enrich and Detect: Video Temporal Grounding with Multimodal LLMs. In ICCV, 2025
2025
-
[43]
Qwen3.5: Towards Native Multimodal Agents, February 2026
Qwen Team. Qwen3.5: Towards Native Multimodal Agents, February 2026
2026
-
[44]
MECCANO: A Multimodal Egocentric Dataset for Humans Behavior Understanding in the Industrial-like Domain .CVIM, 2023
Francesco Ragusa, Antonino Furnari, and Giovanni Maria Farinella. MECCANO: A Multimodal Egocentric Dataset for Humans Behavior Understanding in the Industrial-like Domain .CVIM, 2023
2023
-
[45]
ENIGMA-51: Towards a Fine-Grained Understanding of Human Behavior in Industrial Scenarios
Francesco Ragusa, Rosario Leonardi, Michele Mazzamuto, Claudia Bonanno, Rosario Scavo, Antonino Furnari, and Giovanni Maria Farinella. ENIGMA-51: Towards a Fine-Grained Understanding of Human Behavior in Industrial Scenarios. InWACV, 2024
2024
-
[46]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollar, and Christoph Feichtenhofer. SAM 2: Segment Anything in Images and Videos. InICLR, 2025
2025
-
[47]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InEMNLP-IJCNLP, 2019
2019
-
[48]
TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding. InCVPR, 2024
2024
-
[49]
Learning To Retrieve Prompts for In-Context Learning
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learning To Retrieve Prompts for In-Context Learning. InNAACL, 2022
2022
-
[50]
The Mouse Action Recognition System (MARS) software pipeline for automated analysis of social behaviors in mice.eLife, 2021
Cristina Segalin, Jalani Williams, Tomomi Karigo, May Hui, Moriel Zelikowsky, Jennifer J Sun, Pietro Perona, David J Anderson, and Ann Kennedy. The Mouse Action Recognition System (MARS) software pipeline for automated analysis of social behaviors in mice.eLife, 2021
2021
-
[51]
URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
Seonguk Seo, Joon-Young Lee, and Bohyung Han. URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark. InECCV, 2020
2020
-
[52]
Annotating Objects and Relations in User-Generated Videos
Xindi Shang, Donglin Di, Junbin Xiao, Yu Cao, Xun Yang, and Tat-Seng Chua. Annotating Objects and Relations in User-Generated Videos. InICMR, 2019
2019
-
[53]
Xiaoqian Shen, Min-Hung Chen, Yu-Chiang Frank Wang, Mohamed Elhoseiny, and Ryo Hachiuma. Zoom-Zero: Reinforced Coarse-to-Fine Video Understanding via Temporal Zoom-in.arXiv preprint arXiv:2512.14273, 2025
-
[54]
VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding
Jiapeng Shi, Junke Wang, Zuyao You, Bo He, and Zuxuan Wu. VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding. InICML, 2026
2026
-
[55]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. OpenAI GPT-5 System Card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
STVGBert: A Visual-Linguistic Transformer Based Framework for Spatio-Temporal Video Grounding
Rui Su, Qian Yu, and Dong Xu. STVGBert: A Visual-Linguistic Transformer Based Framework for Spatio-Temporal Video Grounding. InICCV, 2021
2021
-
[57]
Real-World Anomaly Detection in Surveillance Videos
Waqas Sultani, Chen Chen, and Mubarak Shah. Real-World Anomaly Detection in Surveillance Videos. In CVPR, 2018
2018
-
[58]
Human-Centric Spatio-Temporal Video Grounding With Visual Transformers.TCSVT, 2022
Zongheng Tang, Yue Liao, Si Liu, Guanbin Li, Xiaojie Jin, Hongxu Jiang, Qian Yu, and Dong Xu. Human-Centric Spatio-Temporal Video Grounding With Visual Transformers.TCSVT, 2022. 12
2022
-
[59]
Vidi Team, Chia-Wen Kuo, Chuang Huang, Dawei Du, Fan Chen, Fanding Lei, Feng Gao, Guang Chen, Haoji Zhang, Haojun Zhao, Jin Liu, Jingjing Zhuge, Lili Fang, Lingxi Zhang, Longyin Wen, Lu Guo, Lu Xu, Lusha Li, Qihang Fan, Rachel Deng, Shaobo Fang, Shu Zhang, Sijie Zhu, Stuart Siew, Weiyan Tao, Wen Zhong, Xiaohui Shen, Xin Gu, Ye Yuan, Yicheng He, Yiming Cui...
-
[60]
SpaceVLLM: Endowing Multimodal Large Language Model with Spatio-Temporal Video Grounding Capability
Jiankang Wang, Zhihan Zhang, Zhihang Liu, Yang Li, Jiannan Ge, Hongtao Xie, and Yongdong Zhang. SpaceVLLM: Endowing Multimodal Large Language Model with Spatio-Temporal Video Grounding Capability. InAAAI, 2026
2026
-
[61]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. InternVideo2: Scaling Foundation Models for Multimodal Video Understanding. InECCV, 2024
2024
-
[63]
VideoGrounding-DINO: Towards Open-V ocabulary Spatio-Temporal Video Grounding
Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. VideoGrounding-DINO: Towards Open-V ocabulary Spatio-Temporal Video Grounding. InCVPR, 2024
2024
-
[64]
Can I Trust Your Answer? Visually Grounded Video Question Answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can I Trust Your Answer? Visually Grounded Video Question Answering. InCVPR, 2024
2024
-
[65]
An Explanation of In-context Learning as Implicit Bayesian Inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An Explanation of In-context Learning as Implicit Bayesian Inference. InICLR, 2022
2022
-
[66]
ToG-Bench: Task-Oriented Spatio-Temporal Grounding in Egocentric Videos
Qi’ao Xu, Tianwen Qian, Yuqian Fu, Kailing Li, Yang Jiao, Jiacheng Zhang, Xiaoling Wang, and Liang He. ToG-Bench: Task-Oriented Spatio-Temporal Grounding in Egocentric Videos.arXiv preprint arXiv:2512.03666, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Personal Visual Context Learning in Large Multimodal Models
Zihui Xue, Ami Baid, Sangho Kim, Mi Luo, and Kristen Grauman. Personal Visual Context Learning in Large Multimodal Models.arXiv preprint arXiv:2605.10936, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Spatio-Temporal Person Retrieval via Natural Language Queries
Masataka Yamaguchi, Kuniaki Saito, Yoshitaka Ushiku, and Tatsuya Harada. Spatio-Temporal Person Retrieval via Natural Language Queries. InICCV, 2017
2017
-
[69]
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. VideoChat-R1.5: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception.arXiv preprint arXiv:2509.21100, 2025
-
[70]
TubeDETR: Spatio- Temporal Video Grounding with Transformers
Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. TubeDETR: Spatio- Temporal Video Grounding with Transformers. InCVPR, 2022
2022
-
[71]
Zaiquan Yang, Yuhao LIU, Gerhard Petrus Hancke, and Rynson W. H. Lau. Unleashing the Potential of Multimodal LLMs for Zero-Shot Spatio-Temporal Video Grounding. InNeurIPS, 2025
2025
-
[72]
OmniSTVG: Toward Spatio-Temporal Omni-Object Video Grounding
Jiali Yao, Xin Gu, Xinran Deng, Mengrui Dai, Bing Fan, Zhipeng Zhang, Yan Huang, Heng Fan, and Libo Zhang. OmniSTVG: Toward Spatio-Temporal Omni-Object Video Grounding. InICLR, 2026
2026
-
[73]
Crandall
Yu Yao, Xizi Wang, Mingze Xu, Zelin Pu, Yuchen Wang, Ella Atkins, and David J. Crandall. DoTA: Unsupervised Detection of Traffic Anomaly in Driving Videos.TPAMI, 2023
2023
-
[74]
Eliciting In-Context Learning in Vision-Language Models for Videos Through Curated Data Distributional Properties
Keunwoo Peter Yu, Zheyuan Zhang, Fengyuan Hu, Shane Storks, and Joyce Chai. Eliciting In-Context Learning in Vision-Language Models for Videos Through Curated Data Distributional Properties. In EMNLP, 2024
2024
-
[75]
Towards Surveillance Video-and-Language Understanding: New Dataset, Baselines, and Challenges
Tongtong Yuan, Xuange Zhang, Kun Liu, Bo Liu, Chen Chen, Jian Jin, and Zhenzhen Jiao. Towards Surveillance Video-and-Language Understanding: New Dataset, Baselines, and Challenges. InCVPR, 2024
2024
-
[76]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving. InNeurIPS, 2025
2025
-
[77]
STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning
Xiaowen Zhang, Zhi Gao, Licheng Jiao, Lingling Li, and Qing Li. STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning. InICLR, 2026. 13
2026
-
[78]
Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences
Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences. InCVPR, 2020
2020
-
[79]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: Benchmarking Multi-task Long Video Understanding. InCVPR, 2025
2025
-
[80]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models.arXiv preprint arXiv:2504.10479, 2025. 14 Appendix A Implementation and Inference Details A.1 Inference Configuration Model-Specific Param...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.