Automated grading of Linux/bash examinations using large language models: a four-level cognitive taxonomy approach
Pith reviewed 2026-07-03 13:13 UTC · model grok-4.3
The pith
Gemini 3.0 Pro with rubric-guided prompts matches expert grading on Linux and bash answers, but agreement falls as cognitive complexity rises.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
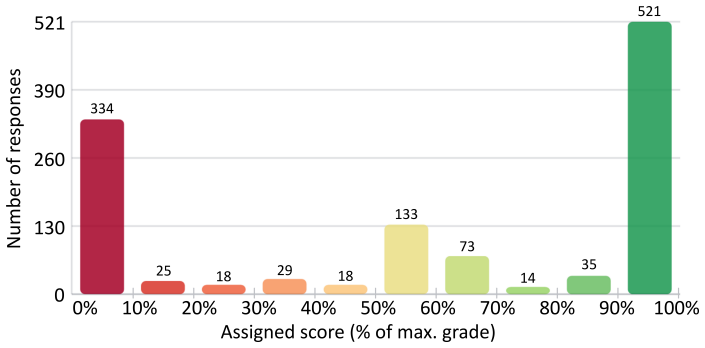
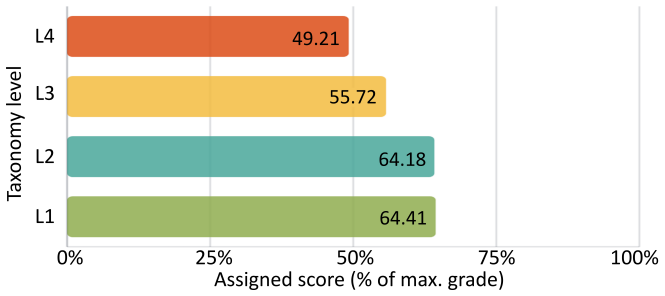
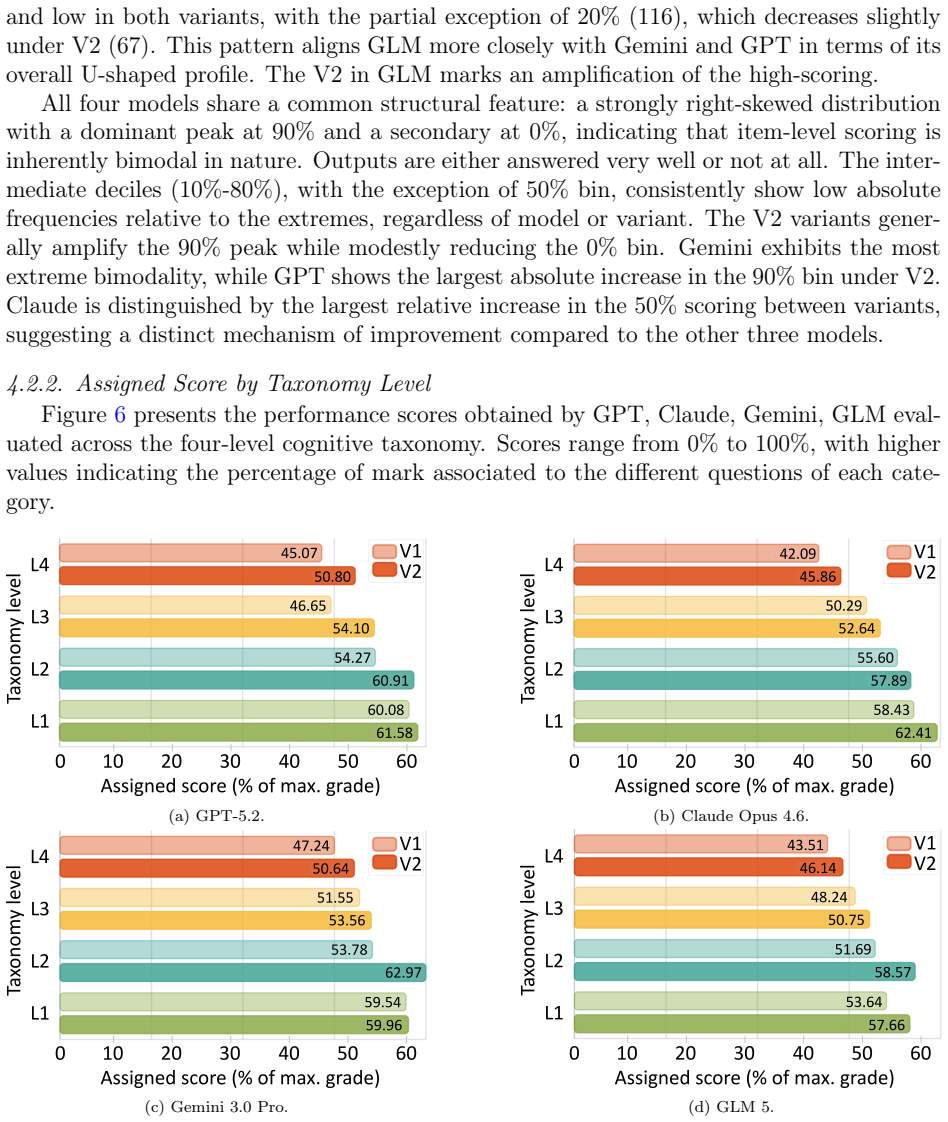
Gemini 3.0 Pro with rubric-guided prompting reached the highest agreement with three human graders, ICC(3,1) = 0.888, MAE = 0.10, and near-zero bias. Agreement declined consistently with taxonomy level, with the largest gaps at L3 and L4. Across all four models, rubric quality produced larger gains than provider differences, and structured prompts improved results uniformly. Question complexity therefore serves as a reliable predictor of LLM grading difficulty and supplies a basis for deciding which items are suitable for AI assistance.
What carries the argument
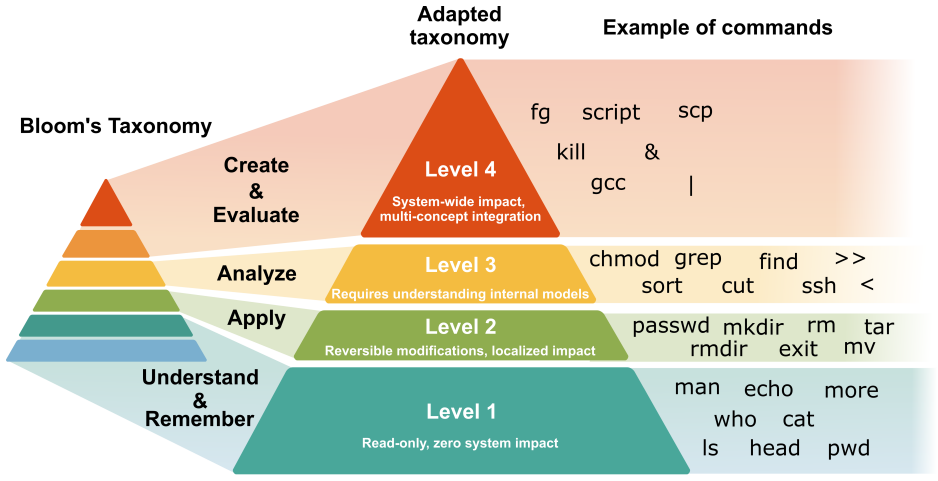
A four-level cognitive taxonomy that orders questions by increasing cognitive complexity and operational impact, from L1 information retrieval through L4 advanced system management.
If this is right
- Rubric-enhanced prompts raise agreement more reliably than switching between frontier models.
- L3 and L4 questions show the largest gaps and therefore require human review even when lower levels can use AI.
- The taxonomy supplies a concrete rule for routing items to AI or human graders.
- The reported prompt templates and evaluation protocol transfer directly to other command-line or scripting assessments.
- Question complexity measured by the taxonomy predicts LLM grading error across providers.
Where Pith is reading between the lines
- Instructors could pre-screen new exam questions with the taxonomy and automatically route higher levels to humans.
- The same taxonomy might help design training data that improves model performance specifically on L3 and L4 items.
- If the pattern holds, departments facing enrollment growth could scale grading capacity without uniform loss of quality.
- The approach offers a template for testing AI graders in any domain where partial credit and multiple correct answers are common.
Load-bearing premise
The four-level taxonomy correctly identifies the features of questions that determine how difficult they are for LLMs to grade.
What would settle it
A replication on the same responses in which a model or prompt achieves high agreement on L4 items, or in which agreement no longer declines with taxonomy level, would undermine the claim that complexity predicts grading difficulty.
Figures
read the original abstract
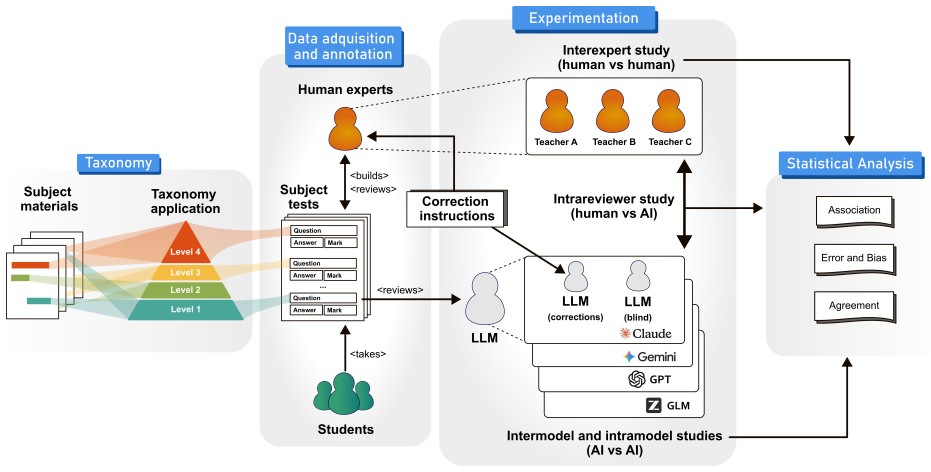
Scalable and reliable grading of command-line examinations remains a challenge in computing education, where rising enrolments make manual marking difficult and rule-based autograders cannot handle partial credit, equivalent solutions, or syntactic variation. This paper evaluates whether four frontier Large Language Models (GPT, Claude Opus, Gemini, and GLM) can approximate expert judgment when grading short Linux/bash command responses. The study adopts a four-level cognitive taxonomy that combines cognitive complexity and operational impact, ranging from information retrieval (L1) and basic file manipulation (L2) to structural operations (L3) and advanced system management (L4). The models were tested with two prompt variants, a minimal baseline and a rubric-enhanced version, on 1200 real responses from second-year Computer Engineering students independently graded by three expert instructors. Gemini~3.0 Pro with rubric-guided prompting achieved the highest human-AI agreement (ICC(3,1) = 0.888, MAE = 0.10, Bland-Altman bias = -0.014). Agreement declined consistently as taxonomy level increased, with the largest discrepancies at higher levels. Across all models, rubric quality had a larger effect than provider choice, with structured prompts consistently improving agreement. These results show that question complexity is a reliable predictor of the difficulty LLMs face in grading accurately, and they establish a principled, taxonomy-based framework for determining which questions are suitable for AI-assisted grading and which require human review, while also providing a transferable evaluation protocol and prompt templates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates four frontier LLMs (GPT, Claude Opus, Gemini, GLM) on grading 1200 real Linux/bash student responses independently marked by three expert instructors. It introduces a four-level cognitive taxonomy (L1 information retrieval to L4 advanced system management) combining cognitive complexity and operational impact, tests minimal vs. rubric-enhanced prompts, and reports that Gemini 3.0 Pro with rubric prompting yields the highest human-AI agreement (ICC(3,1)=0.888, MAE=0.10, Bland-Altman bias=-0.014), with agreement declining monotonically across taxonomy levels. The central claim is that the taxonomy reliably predicts LLM grading difficulty and supplies a transferable framework for deciding which questions suit AI-assisted grading versus human review.
Significance. If the taxonomy effect survives controls for surface features, the work supplies a large-scale empirical benchmark (1200 responses, multiple models, two prompt conditions, ICC/MAE/Bland-Altman metrics) for AI grading in computing education and a concrete, falsifiable protocol for selecting questions for automation. The explicit comparison against independent human grades and the provision of prompt templates are strengths that could be directly reused.
major comments (2)
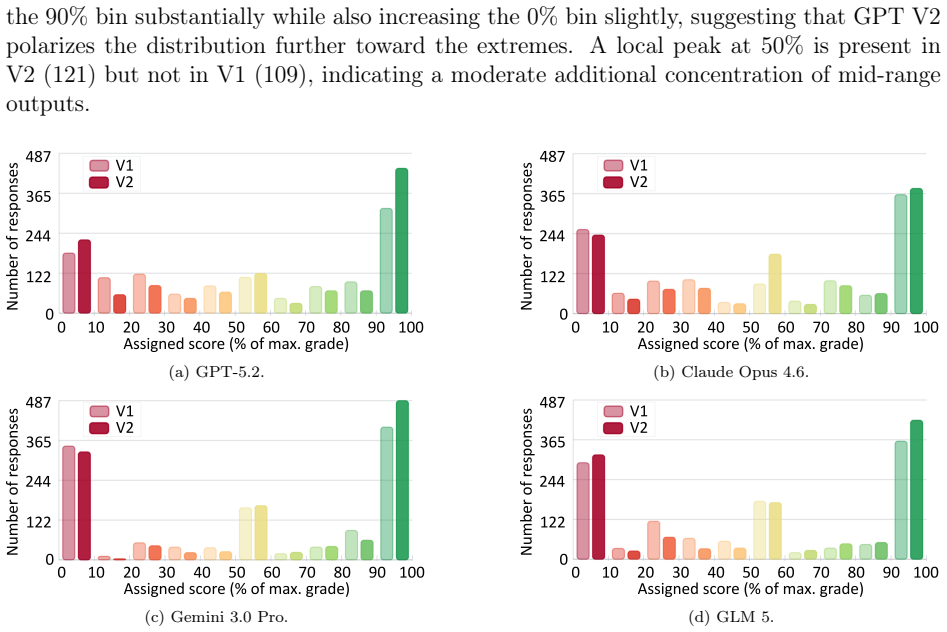
- [Results (agreement by taxonomy level)] Results section (agreement by taxonomy level): The monotonic decline in ICC/MAE from L1 to L4 is presented as evidence that the four-level taxonomy predicts LLM grading difficulty. However, the manuscript reports neither mean response length, token count, nor number of distinct commands per level, nor does it include any regression or stratification that controls for these variables. Consequently the taxonomy effect cannot be isolated from the possibility that higher-level questions simply elicit longer or more variable student answers.
- [Methods (taxonomy construction)] Methods (taxonomy construction and question assignment): The taxonomy is defined by combining cognitive complexity and operational impact, yet the paper provides no inter-rater reliability statistic for how the 1200 questions were classified into L1–L4, nor any validation that the four levels are orthogonal to response length. This classification step is load-bearing for the claim that taxonomy level, rather than surface features, drives the observed grading discrepancies.
minor comments (2)
- [Abstract] Abstract: The model identifier 'Gemini 3.0 Pro' should be accompanied by the precise release date or API version used, to allow exact replication.
- [Methods] Notation: The paper uses ICC(3,1) without stating whether the three human raters are treated as fixed or random effects; a brief clarification in the methods would improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional controls and methodological detail would strengthen the manuscript. We address each point below and outline the revisions we will make.
read point-by-point responses
-
Referee: Results section (agreement by taxonomy level): The monotonic decline in ICC/MAE from L1 to L4 is presented as evidence that the four-level taxonomy predicts LLM grading difficulty. However, the manuscript reports neither mean response length, token count, nor number of distinct commands per level, nor does it include any regression or stratification that controls for these variables. Consequently the taxonomy effect cannot be isolated from the possibility that higher-level questions simply elicit longer or more variable student answers.
Authors: We agree that the absence of these controls is a limitation. The manuscript does not report mean response lengths, token counts, or command counts per level, nor any regression that isolates taxonomy level from surface features. We will add these descriptive statistics to the Results section and conduct a regression analysis with taxonomy level and response length (plus token count) as predictors of agreement metrics. This will allow us to test whether taxonomy level remains predictive after controlling for length. revision: yes
-
Referee: Methods (taxonomy construction and question assignment): The taxonomy is defined by combining cognitive complexity and operational impact, yet the paper provides no inter-rater reliability statistic for how the 1200 questions were classified into L1–L4, nor any validation that the four levels are orthogonal to response length. This classification step is load-bearing for the claim that taxonomy level, rather than surface features, drives the observed grading discrepancies.
Authors: The 1200 questions were classified into L1–L4 by the same three expert instructors who performed the independent grading, using the taxonomy definitions in the Methods. No inter-rater reliability was computed for the classification step. We will expand the Methods to describe the classification procedure in detail. We will also report the correlation between taxonomy level and response length as a check on orthogonality. If the original classification records permit, we will compute and report IRR; otherwise we will note this as a limitation. revision: partial
Circularity Check
No circularity; direct empirical agreement metrics on independent human grades
full rationale
The paper reports ICC, MAE, and Bland-Altman statistics comparing LLM grades directly to three independent expert human grades on 1200 student responses. The four-level taxonomy is adopted upfront from cognitive complexity and operational impact criteria and is not derived from or fitted to the observed agreement values. No equations, fitted parameters, or self-citations are used to define the taxonomy levels or to turn measured agreement into a prediction. The decline in agreement across levels is an empirical observation, not a definitional or self-referential step. This is a standard external validation design with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-rater reliability statistics such as ICC(3,1) and Bland-Altman analysis are appropriate measures for comparing LLM and human grading.
invented entities (1)
-
Four-level cognitive taxonomy (L1 information retrieval to L4 advanced system management)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stepgrade: Grading programming as- signmentswithcontext-awarellms, in: 2025IEEEIntegratedSTEMEducationConference (ISEC), pp. 1–6. doi:10.1109/ISEC64801.2025.11147374. Alonso-Carracedo, M., Fernandez-Boullon, R., Celard, P., Rodriguez-Martinez, F.J., Otero- Cerdeira, L.,
-
[2]
URL:https://arxiv.org/abs/2607.00140,arXiv:2607.00140
Cogtax: A four-level cognitive taxonomy for command-line computing education. URL:https://arxiv.org/abs/2607.00140,arXiv:2607.00140. Anthropic,
-
[3]
URL:https://platform.claude.com/docs/ en/docs/about-claude/models
Claude api models overview. URL:https://platform.claude.com/docs/ en/docs/about-claude/models. accessed 2026-02-19. Arshad, M., Yasmeen, M., Iqbal, A.N., Akhtar, N.,
2026
-
[4]
Bolgova, O., Ganguly, P., Ikram, M.F., Mavrych, V.,
doi:10.3390/app151810055. Bolgova, O., Ganguly, P., Ikram, M.F., Mavrych, V.,
-
[5]
Medical Education Online 30, 2550751
Evaluating large language models as graders of medical short answer questions: a comparative analysis with expert human graders. Medical Education Online 30, 2550751. doi:10.1080/10872981.2025.2550751. Cohen, J.,
-
[6]
Educational and Psychological Measurement 20, 37–46
A coefficient of agreement for nominal scales. Educational and Psychological Measurement 20, 37–46. doi:10.1177/001316446002000104. Cohen, J.,
-
[7]
Psychological Bulletin 70, 213–220
Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. Psychological Bulletin 70, 213–220. doi:10.1037/h0026256. Dorodchi, M., Dehbozorgi, N., Frevert, T.K.,
-
[8]
doi:10.1109/FIE.2017.8190523. Emirtekin, E., Özarslan, Y.,
-
[9]
Journal of Computer Assisted Learning 42, e70160
Automatic short-answer grading in sustainability ed- ucation: Ai–human agreement. Journal of Computer Assisted Learning 42, e70160. doi:https://doi.org/10.1002/jcal.70160. 29 Eurostat,
-
[10]
URL:https://ec.europa
ICT education - a statistical overview. URL:https://ec.europa. eu/eurostat/statistics-explained/index.php?title=ICT_education_-_a_ statistical_overview. accessed: 2026-05-13. Freedman, D., Pisani, R., Purves, R.,
2026
- [11]
-
[12]
URL:https://ai
Gemini 3 pro preview model documentation (gemini api). URL:https://ai. google.dev/gemini-api/docs/models/gemini-3-pro-preview. accessed 2026-02-19. Grandel, S., Schmidt, D.C., Leach, K.,
2026
-
[13]
Applying large language models to enhance the assessment of parallel functional programming assignments, in: Proceedings of the 1st International Workshop on Large Language Models for Code, Association for Computing Machinery, New York, NY, USA. p. 102–110. doi:10.1145/3643795.3648375. Jacobs, S., Jaschke, S.,
-
[14]
Evaluating the application of large language models to gen- erate feedback in programming education, in: 2024 IEEE Global Engineering Education Conference (EDUCON), pp. 1–5. doi:10.1109/EDUCON60312.2024.10578838. Johnson, G.K., Gaspar, A., Boyer, N., Bennett, C., Armitage, W.D.,
-
[15]
Investigating automatic scoring and feedback using large language models.arXiv:2405.00602. Machanick, P.,
-
[16]
Statistical methods for assessing agreement between two methods of clinical measurement. The Lancet 327, 307–310. doi:https://doi.org/ 10.1016/S0140-6736(86)90837-8. Mohamed, K., Yousef, M., Medhat, W., Mohamed, E.H., Khoriba, G., Arafa, T.,
-
[17]
Information Systems 128, 102473
Hands-on analysis of using large language models for the auto evaluation of programming assignments. Information Systems 128, 102473. doi:https://doi.org/10.1016/j.is. 2024.102473. OpenAI,
-
[18]
URL:https:// developers.openai.com/api/docs/models/gpt-5.2
GPT-5.2 model documentation (openai developers). URL:https:// developers.openai.com/api/docs/models/gpt-5.2. accessed 2026-02-19. Pack, A., Barrett, A., Escalante, J.,
2026
-
[19]
Ad- vanced Engineering Informatics65, 103345 (2025).https://doi.org/10.1016/j
Large language models and automated essay scoring of english language learner writing: Insights into validity and reliability. Comput- ers and Education: Artificial Intelligence 6, 100234. doi:https://doi.org/10.1016/j. caeai.2024.100234. 30 Pathak, A., Gandhi, R., Uttam, V., Ramamoorthy, A., Ghosh, P., Jindal, A.R., Verma, S., Mittal, A., Ased, A., Khatr...
work page doi:10.1016/j 2024
-
[20]
Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics, in: Proceedings of the 2025 ACM Conference on International Computing Education Research V.1, Association for Computing Machinery, New York, NY, USA. p. 181–195. doi:10.1145/3702652.3744220. Pecuchova, J., Benko, Ľ., Drlik, M.,
-
[21]
International Journal of Artificial Intelligence in Education 35, 3813–3846
Automated grading of open-ended questions in higher education using genai models. International Journal of Artificial Intelligence in Education 35, 3813–3846. doi:10.1007/s40593-025-00517-2. Pereira, A.F., Ferreira Mello, R.,
-
[22]
A systematic literature review on large language models applications in computer programming teaching evaluation process. IEEE Access 13, 113449–113460. doi:10.1109/ACCESS.2025.3584060. Pillet, J.C., Larsen, K.R., Dobolyi, D., Queiroz, M., Handler, A., Arnulf, J.K., Sharma, R.,
-
[23]
Management Information Systems Quarterly , 1– 33doi:10.25300/MISQ/2025/18946
Ai-augmented content validation in behavioral research: Development and evaluation of the rater system. Management Information Systems Quarterly , 1– 33doi:10.25300/MISQ/2025/18946. Qiu, Y., Azimi, S.M., Lensky, A.,
-
[24]
Mark my works autograder for programming courses. arXiv:2601.10093. Quan, J.C., Luo, C., Yang, F., Qiu, H.P.,
-
[25]
Bloom’s taxonomy of educational objectives in information system courses. DEStech Transactions on Social Science, Education and Human Science doi:10.12783/DTSSEHS/MESS2016/9623. Raihan, N., Siddiq, M.L., Santos, J.C., Zampieri, M.,
-
[26]
1, Association for Computing Machinery, New York, NY, USA
Large language models in com- puter science education: A systematic literature review, in: Proceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1, Association for Computing Machinery, New York, NY, USA. p. 938–944. doi:10.1145/3641554.3701863. Shrout, P.E., Fleiss, J.L.,
-
[27]
Psychological Bulletin 86, 420–428
Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin 86, 420–428. doi:10.1037/0033-2909.86.2.420. Siek, K., Batten, J.,
-
[28]
URL: https://datavisualization.cra.org/TaulbeeSurvey/CRA_Taulbee_Survey_Report_ 2024.html
Taulbee survey 2024: Annual report. URL: https://datavisualization.cra.org/TaulbeeSurvey/CRA_Taulbee_Survey_Report_ 2024.html. accessed 2026-04-21. Spearman, C.,
2024
-
[29]
The American Journal of Psychology 15, 72–101
The proof and measurement of association between two things. The American Journal of Psychology 15, 72–101. doi:10.2307/1412159. Thomas, M.L., Yildirim-Erbasli, S.N., Hariharan, S.,
-
[30]
Exploring undergraduate stu- dents’ perceptions of ai vs. human scoring and feedback. The Internet and Higher Educa- tion 68, 101052. doi:https://doi.org/10.1016/j.iheduc.2025.101052. Tseng, E.Q., Huang, P.C., Hsu, C., Wu, P.Y., Ku, C.T., Kang, Y.,
-
[31]
CodEv: An Auto- mated Grading Framework Leveraging Large Language Models for Consistent and Con- structive Feedback , in: 2024 IEEE International Conference on Big Data (BigData), IEEE 31 Computer Society, Los Alamitos, CA, USA. pp. 5442–5449. doi:10.1109/BigData62323. 2024.10825949. Wang, S., Xu, T., Li, H., Zhang, C., Liang, J., Tang, J., Yu, P.S., Wen, Q.,
-
[32]
Computers and Education: Artificial Intelligence 9, 100481
Evaluating large lan- guage models as raters in large-scale writing assessments: A psychometric framework for reliability and validity. Computers and Education: Artificial Intelligence 9, 100481. doi:https://doi.org/10.1016/j.caeai.2025.100481. Wangwiwattana, C., Tongvivat, Y.,
-
[33]
Automating academic assessment: A large lan- guage model approach, in: 2023 7th International Conference on Information Technology (InCIT), pp. 330–334. doi:10.1109/InCIT60207.2023.10412991. Yousef, M., Mohamed, K., Medhat, W., Mohamed, E.H., Khoriba, G., Arafa, T.,
-
[34]
Neural Computing and Applications 37, 1027–1040
Be- grading: large language models for enhanced feedback in programming education. Neural Computing and Applications 37, 1027–1040. doi:10.1007/s00521-024-10449-y. Zhipu AI,
-
[35]
URL:https://bigmodel.cn/dev/ howuse/model
Zhipu ai open platform model overview. URL:https://bigmodel.cn/dev/ howuse/model. accessed 2026-02-19. 32
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.