TestEvo-Bench: An Executable and Live Benchmark for Test and Code Co-Evolution
Pith reviewed 2026-07-03 08:23 UTC · model grok-4.3
The pith
TestEvo-Bench provides executable, commit-anchored tasks to evaluate whether agents generate or update tests that match code changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
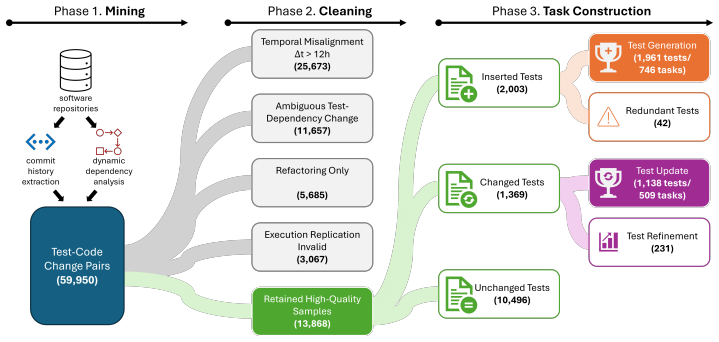
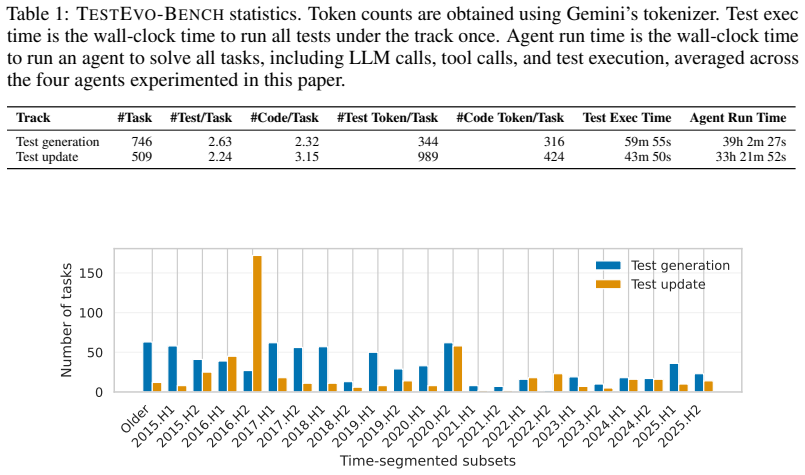
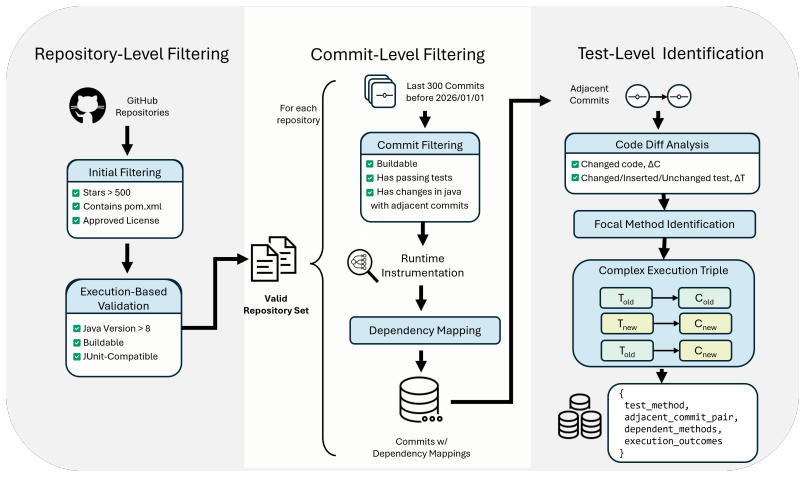
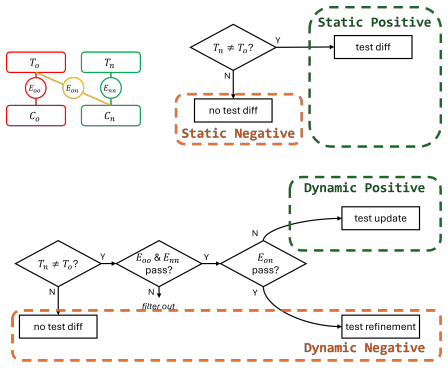
TestEvo-Bench consists of 746 test generation tasks and 509 test update tasks extracted from 59,950 candidate records in 152 Java projects. Each task is linked to a specific commit pair and includes environment configuration to enable running the tests and computing grounded metrics. The benchmark supports two tracks where agents either create new tests for new behavior or fix existing tests that fail after a code change.
What carries the argument
The automated mining pipeline that identifies co-evolution records from repository histories, validates their executability, attaches environment configurations, and records timestamps for live evaluation to limit data leakage.
If this is right
- Agent performance can be assessed directly by whether the produced tests pass and provide coverage on the updated code base.
- Evaluation can be limited to tasks after a given date to test generalization beyond training data.
- Success rates decline on the most recent tasks and under cost limits, showing practical constraints on current approaches.
- New tasks can be added over time to keep the benchmark current without manual curation.
Where Pith is reading between the lines
- Extending the benchmark to non-Java languages would test if the co-evolution patterns and agent capabilities generalize.
- The gap between older and newer tasks indicates that models may be picking up patterns from training data rather than learning change propagation rules.
- Developers of test automation agents could use the execution metrics to guide training toward tasks that require understanding behavioral impact.
- The live mining approach could be applied to create similar benchmarks for other software engineering tasks like bug fixing or refactoring.
Load-bearing premise
The mining process from thousands of candidate records produces tasks where the test change is meaningfully connected to the code change and the packaged environments allow reliable execution without introducing errors that skew the metrics.
What would settle it
A check revealing that many tasks have test suites where the 'updated' test passes on the old code version or fails to catch changes introduced by the commit would show the tasks are not semantically tied to the evolution event.
Figures

read the original abstract
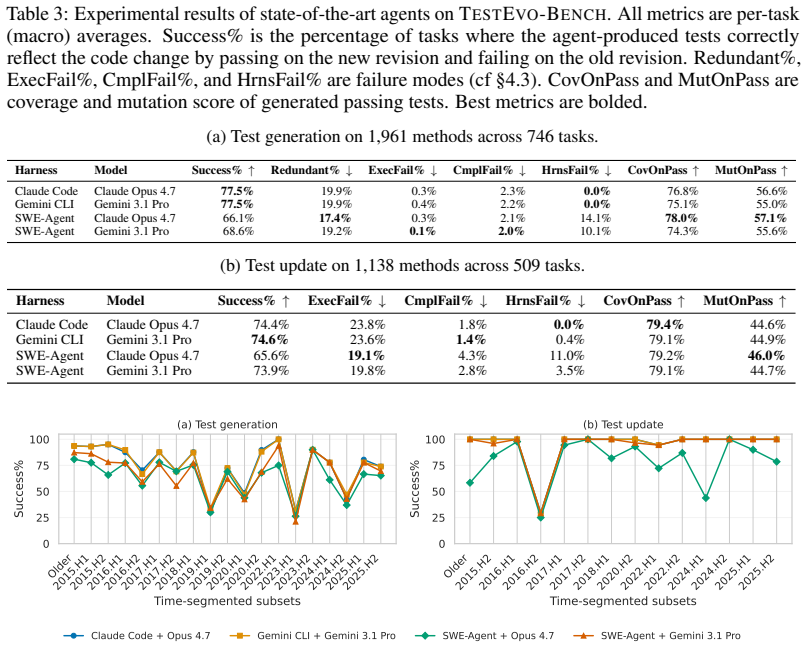
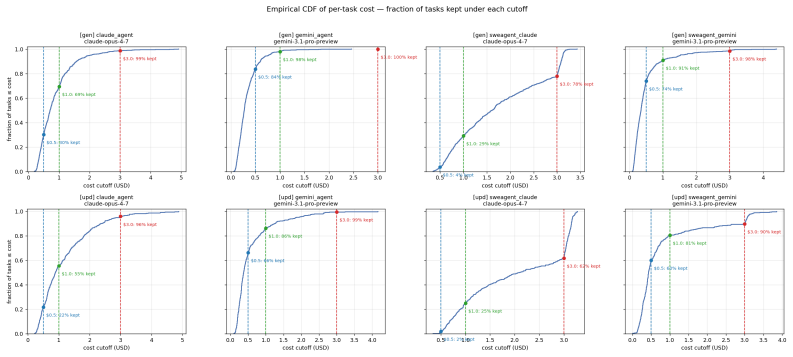
Software tests and code evolve together: a code change should be followed by new or updated tests that record the new software behavior. Yet existing test generation and update benchmarks often isolate the test from the code change, and rely on static metadata that does not verify whether a test is executable or semantically tied to the code change. This makes it difficult to evaluate whether a test automation agent understands how a code change should propagate into the test suite. We introduce TestEvo-Bench, a benchmark of test and code co-evolution tasks mined from software repositories, with two tracks: in test generation, the agent shall write new tests to capture the new software behavior; in test update, the agent shall adapt failing existing tests to the changed software behavior. Each task is anchored to a real commit history and packaged with environment configuration to support execution-grounded metrics such as pass rate, coverage, and mutation score. TestEvo-Bench is also a live benchmark: each task records the timestamp of the test and code changes, and new tasks are periodically mined by our automated pipeline, so evaluation can be restricted to tasks postdating a model's training cutoff to reduce data leakage risk. The current snapshot contains 746 test generation and 509 test update tasks, curated from 59,950 candidate co-evolution records across 152 open-source Java projects. We experiment with four state-of-the-art agents that combine strong harnesses (Claude Code, Gemini CLI, and SWE-Agent) with strong foundation models (Claude Opus 4.7 and Gemini 3.1 Pro). Results show that they achieve up to 77.5% success rate on test generation and 74.6% on test update. However, success rate is materially lower on the most recent benchmark tasks and drops significantly under limited per-task cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TestEvo-Bench, a live benchmark of 746 test-generation and 509 test-update tasks mined from 59,950 candidate records across 152 Java projects. Each task is anchored to a real commit and packaged with environment configuration to enable execution-grounded evaluation (pass rate, coverage, mutation score) of agents that must either generate new tests or update existing ones to match a code change. Experiments with four agent harnesses (Claude Code, Gemini CLI, SWE-Agent) paired with Claude Opus 4.7 and Gemini 3.1 Pro report peak success rates of 77.5% (test generation) and 74.6% (test update), with materially lower performance on the most recent tasks and under cost limits.
Significance. If the mining pipeline reliably produces executable tasks that are semantically tied to the underlying commits, the benchmark would fill a clear gap by supplying execution-verified, temporally ordered co-evolution tasks that existing static benchmarks lack. The live-mining design and explicit timestamping also provide a practical mechanism for controlling data leakage, which would make the resource useful for long-term agent evaluation.
major comments (2)
- [Abstract / Benchmark Construction] Abstract and Benchmark Construction section: the headline success rates (77.5 % / 74.6 %) and the claim that metrics are “execution-grounded” rest on the unverified assumption that the automated pipeline from 59,950 candidates yields tasks whose test and code changes are both executable under the supplied configurations and semantically linked to the commit delta. No false-positive rate, environment-setup failure rate, or manual audit of semantic relevance is reported, rendering the pass-rate, coverage, and mutation-score figures uninterpretable if even a modest fraction of tasks are misaligned.
- [Experiments] Experiments section: the reported drop in performance on the most recent tasks is presented as evidence of generalization difficulty, yet the same section provides no breakdown of how many tasks were discarded during post-hoc curation or whether curation criteria correlate with task difficulty; without this information the temporal trend cannot be distinguished from selection effects.
minor comments (1)
- [Experiments] The description of the four agent configurations would benefit from an explicit table listing the exact model versions, harness parameters, and per-task cost budgets used for each reported number.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark validation and the interpretation of temporal trends. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Benchmark Construction] Abstract and Benchmark Construction section: the headline success rates (77.5 % / 74.6 %) and the claim that metrics are “execution-grounded” rest on the unverified assumption that the automated pipeline from 59,950 candidates yields tasks whose test and code changes are both executable under the supplied configurations and semantically linked to the commit delta. No false-positive rate, environment-setup failure rate, or manual audit of semantic relevance is reported, rendering the pass-rate, coverage, and mutation-score figures uninterpretable if even a modest fraction of tasks are misaligned.
Authors: We agree that the manuscript would benefit from explicit validation statistics. The Benchmark Construction section describes the automated pipeline with compilation and execution checks, but does not report environment-setup failure rates or a manual audit of semantic linkage. In revision we will add a dedicated subsection with: (i) the fraction of candidates that failed environment setup, (ii) the overall false-positive filtering rate after all automated checks, and (iii) results of a manual review of a random sample of 100 tasks confirming that test and code changes are semantically tied to the commit delta. These additions will make the execution-grounded metrics fully interpretable. revision: yes
-
Referee: [Experiments] Experiments section: the reported drop in performance on the most recent tasks is presented as evidence of generalization difficulty, yet the same section provides no breakdown of how many tasks were discarded during post-hoc curation or whether curation criteria correlate with task difficulty; without this information the temporal trend cannot be distinguished from selection effects.
Authors: The curation criteria (requiring co-located test and code changes plus passing pre-commit tests) are applied uniformly and are defined in the Benchmark Construction section; they are not post-hoc selections based on difficulty. Nevertheless, we did not supply a temporal breakdown of discarded candidates. We will revise the Experiments section to include a table of candidate-to-task retention rates across time bins and an explicit check that curation criteria show no correlation with recency. This will allow readers to separate selection effects from genuine temporal generalization trends. revision: yes
Circularity Check
No circularity in benchmark construction or evaluation
full rationale
The paper constructs a benchmark by mining co-evolution tasks from repositories and evaluates external agents on execution-grounded metrics. No mathematical derivation, fitted parameters, predictions, or self-referential definitions are present. The mining pipeline and semantic/executability claims are empirical construction steps, not reductions of results to inputs by construction. No self-citation load-bearing, uniqueness theorems, or ansatzes appear in any derivation chain. This is a standard benchmark paper with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic
Accessed: 2026-05-05. Anthropic. Introducing Claude Opus 4.7. https://www.anthropic.com/news/ claude-opus-4-7, 2026. Accessed: 2026-05-05. Anysphere. Cursor: The AI code editor.https://www.cursor.com/, 2023. Accessed: 2026-05-05. Anysphere. Introducing Composer 2. https://cursor.com/blog/composer-2, 2026. Accessed: 2026-05-05. Jianlei Chi, Xiaotian Wang, ...
2026
-
[2]
doi: 10.1145/3728930. Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. Introducing SWE-bench Verified. OpenAI Blog,
-
[3]
Brett Daniel, Vilas Jagannath, Danny Dig, and Darko Marinov
URLhttps://openai.com/index/introducing-swe-bench-verified. Brett Daniel, Vilas Jagannath, Danny Dig, and Darko Marinov. ReAssert: Suggesting repairs for broken unit tests. InAutomated Software Engineering, pages 433–444, 2009. URL https: //ieeexplore.ieee.org/document/5431753. Gordon Fraser and Andrea Arcuri. EvoSuite: Automatic test suite generation for...
-
[4]
URL https://dl.acm.org/doi/10.1145/2025113
doi: 10.1145/2025113.2025179. URL https://dl.acm.org/doi/10.1145/2025113. 2025179. Google. Gemini CLI: An open-source AI agent for the terminal. https://blog.google/ technology/developers/introducing-gemini-cli-open-source-ai-agent/ , 2025. Accessed: 2026-05-05. Google DeepMind. Gemini 3 Pro model card. https://deepmind.google/models/ model-cards/gemini-3...
-
[5]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
URLhttps://arxiv.org/abs/2403.07974. 10 Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations, 2024. URLhttps://arxiv.org/abs/2310.06770. Quentin Le Dilavrec, Djamel Eddine Khelladi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icsme52107.2021.00025 2024
-
[6]
Read the current test methods and the changed production methods
-
[7]
Update each listed test method so it compiles against the new production code and passes
-
[8]
The tests must exercise the same behavior as before where still relevant, and adapt to any new behavior introduced in DM
-
[12]
If any tracked file other than <test_file> changed, especially due to Maven/license-header side effects, revert those non-target files with`git checkout -- <path>`
Before finishing, run`git diff --name-only HEAD`. If any tracked file other than <test_file> changed, especially due to Maven/license-header side effects, revert those non-target files with`git checkout -- <path>`. The final diff must contain only <test_file>. You have file read/edit and shell tools. Work autonomously; do not ask for confirmation. Test ge...
-
[13]
Read the changed production methods to understand the new behavior
-
[14]
Methods to add
For each method listed under "Methods to add", write a JUnit test method with that exact name in < test_file> that exercises the new behavior introduced in DM. Annotate with @Test and return void
-
[15]
Avoid tests that only assert unchanged behavior
Each generated test must be discriminating: it should PASS on this POST-change code, but would FAIL or fail-to-compile if the production code were reverted to the PRE-change version. Avoid tests that only assert unchanged behavior
-
[16]
If <test_file> does not exist, create it with the appropriate package declaration and imports
-
[17]
Only modify <test_file>
Do NOT modify production code. Only modify <test_file>
-
[18]
<classpath>
When done, ensure the tests compile and pass with the JUnit Console Launcher: - Compile:`<cd_prefix>mvn test-compile` - Run with the JUnit Console Launcher (jar at`<junit_jar>`). Set`--class-path`to include the project's compiled classes and dependencies, then invoke: `<cd_prefix>java -jar <junit_jar> --class-path "<classpath>" --reports-dir ./test-report...
-
[19]
$MAVEN_SETTINGS_PATH
If`MAVEN_SETTINGS_PATH`is set in the shell, pass`-s "$MAVEN_SETTINGS_PATH"`to Maven commands so dependency downloads use the configured cache
-
[20]
UM produced few mutants
Before finishing, run`git diff --name-only HEAD`. If any tracked file other than <test_file> changed, especially due to Maven/license-header side effects, revert those non-target files with`git checkout -- <path>`. The final diff must contain only <test_file>. You have file read/edit and shell tools. Work autonomously; do not ask for confirmation. An exam...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.