Program-as-Weights: A Programming Paradigm for Fuzzy Functions
Pith reviewed 2026-07-04 03:30 UTC · model glm-5.2
The pith
0.6B model matches 32B by compiling fuzzy functions into weights
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
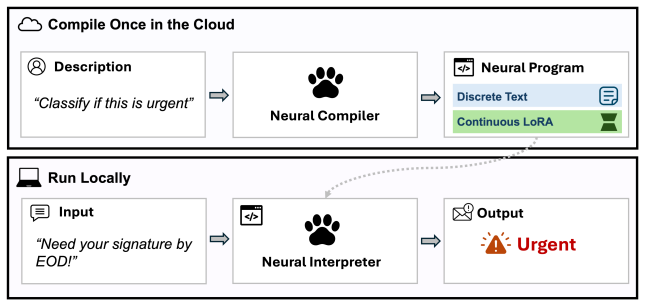
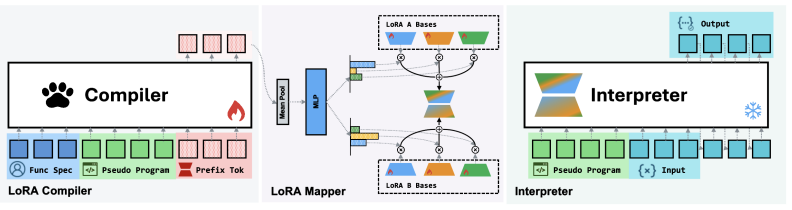
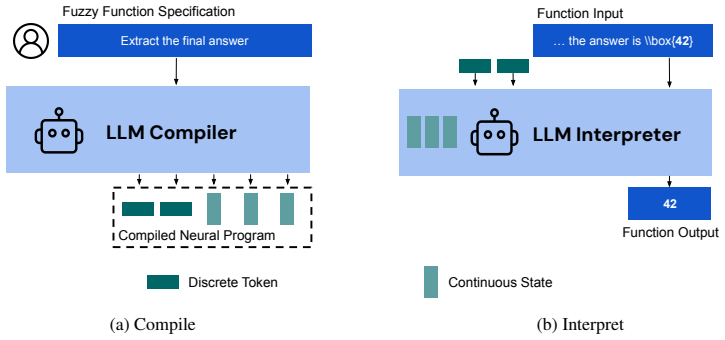
The paper's central claim is that a trained 4B-parameter compiler can, in a single forward pass, produce a LoRA adapter that specializes a frozen 0.6B-parameter language model to perform a specific fuzzy function at a level matching direct prompting of a 32B model — while the compiled artifact is a 23 MB file that runs offline. The compiler generates the adapter by reading a specification and a pseudo-program (a clean restatement with examples), extracting hidden states from learned prefix tokens, and projecting them through a shared-basis LoRA mapper into mixing coefficients over 64 rank-64 LoRA bases per module type. The paper finds that the simplest mapper design — mean-pooling hidden to
What carries the argument
Program-as-Weights (PAW): a compiler-interpreter pair where a 4B neural compiler emits a hybrid program (discrete pseudo-program + continuous LoRA adapter) from a natural-language specification, and a frozen 0.6B interpreter executes it. The LoRA mapper uses mean-pooled hidden states from the compiler projected into mixing coefficients over shared learnable bases (64 bases, rank 64), injecting ~38.5M parameters per function. FuzzyBench-10M: a synthetic dataset of 10M (specification, input, output) triples across 800+ fuzzy task categories, generated by gpt-5.2 with a verified test split.
If this is right
- If PAW-style compilation works broadly, developers could replace per-input LLM API calls in their codebases with locally-executable neural functions — gaining reproducibility, offline capability, and ~50x memory savings.
- The compiler-interpreter split suggests a new software engineering workflow: large models are invoked once at build time to produce small, versioned, distributable artifacts, while small models serve as a fixed runtime.
- The finding that GPT-2 124M achieves 54% with compiler-generated LoRAs suggests the approach could push fuzzy-function capability into extremely small models suitable for browser or edge deployment.
- The modality-generalization result (swapping only the compiler for a vision-language model) implies the paradigm is not text-specific and could extend to audio, video, or other modalities as compiler backbones improve.
Where Pith is reading between the lines
- If the FuzzyBench distribution is systematically narrower or more learnable than real-world fuzzy tasks, the 73.78% vs 68.70% gap may reflect distributional artifacts rather than a genuine capability transfer. Controlled evaluation on held-out real-world task distributions would be needed to confirm production readiness.
- The coupled compiler-interpreter constraint (switching interpreters requires retraining the compiler) may limit the paradigm's practical adoption: as base models improve rapidly, the cost of retraining compilers could erode the efficiency gains.
- The finding that simpler LoRA mapper designs outperform more expressive variants is consistent with a regularization effect — the shared-basis bottleneck may prevent overfitting to individual specifications, but this hypothesis is not tested in the paper.
- The 96.09% ceiling set by the data-generating model suggests that PAW's current performance headroom may be bounded more by training data quality than by compiler architecture, implying that better data sources could yield further gains without architectural changes.
Load-bearing premise
Both the training data and the evaluation benchmark for PAW are generated by the same model family (gpt-5.2), with verification by a smaller model from the same family. If this synthetic distribution does not reflect the fuzzy tasks developers actually encounter, or if its output conventions are systematically easier for a small model to learn than real-world tasks would be, the headline performance comparison may not transfer to production use.
What would settle it
If PAW programs compiled from specifications drawn from a held-out, human-curated distribution of real developer fuzzy tasks (rather than gpt-5.2-generated ones) perform no better than direct prompting of the 0.6B base model, the compiler's contribution would be shown to depend on distributional artifacts in the training data rather than genuine task-generalization capability.
Figures








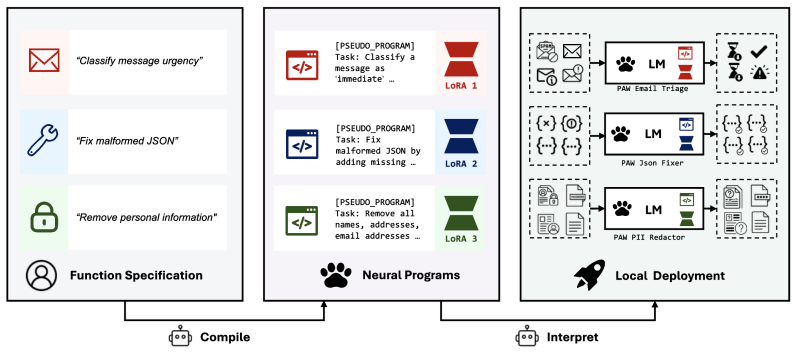
read the original abstract
Many everyday programming tasks resist clean rule-based implementation, such as alerting on important log lines, repairing malformed JSON, or ranking search results by intent, and are increasingly outsourced to large language model APIs at the cost of locality, reproducibility, and price. We propose fuzzy-function programming: compiling such a function from a natural-language specification into a compact, locally-executable neural artifact. We instantiate this paradigm with Program-as-Weights (PAW), in which a 4B compiler trained on FuzzyBench, a 10M-example dataset we release, emits parameter-efficient adapters for a frozen, lightweight interpreter. A 0.6B Qwen3 interpreter executing PAW programs matches the performance of direct prompting of Qwen3-32B, while using roughly one fiftieth of the inference memory and running at 30 tokens/s on a MacBook M3. PAW reframes the foundation model from a per-input problem solver into a tool builder: invoked once per function definition, it produces a small reusable artifact whose subsequent calls per function application are cheap and offline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces Program-as-Weights (PAW), a paradigm in which a natural-language specification of a 'fuzzy function' is compiled by a 4B-parameter neural compiler into a LoRA adapter (plus a discrete pseudo-program), which is then executed by a frozen 0.6B-parameter interpreter. The authors train the compiler on FuzzyBench-10M, a new 10M-example synthetic dataset they construct using gpt-5.2. The headline result is that the 0.6B PAW interpreter achieves 73.78% exact match on FuzzyBench, outperforming direct zero-shot prompting of Qwen3-32B (68.70%) at ~50x less memory. The paper also presents ablations (architectural variants, compiler-vs-no-compiler, noise robustness, quantization), multimodal extensions (swapping the compiler for a VLM), and five qualitative case studies.
Significance. The paper presents a well-engineered system with a clear and appealing conceptual framing: reframing the foundation model as a per-function tool builder rather than a per-input problem solver. The compiler-interpreter abstraction is clean, and the demonstration that a 4B compiler can emit LoRA adapters that specialize a 0.6B interpreter for arbitrary fuzzy functions is a meaningful contribution. Strengths include: (1) controlled ablations showing the compiler-generated LoRA substantially outperforms fixed LoRAs and full fine-tuning on the same base (Table 5); (2) thorough quantization sweeps demonstrating practical on-device deployment viability (Table 8, Appendix K); (3) release of code, a public demo, and a large-scale dataset; (4) the multimodal generalization experiment (Table 3) showing the abstraction holds when only the compiler is swapped. The work is relevant to the growing literature on hypernetworks, PEFT generation, and small-model deployment.
major comments (3)
- §6, Table 2: The headline claim that '0.6B PAW matches Qwen3-32B' is drawn exclusively from FuzzyBench (73.78% vs 68.70%), a benchmark the authors constructed. Table 2 also reports four external benchmarks (YouTube, SMS, Yelp, IMDB) where PAW (0.6B) underperforms Qwen3-32B on all four (e.g., YouTube 90.40% vs 93.60%, SMS 80.77% vs 89.04%). The abstract and introduction do not acknowledge this pattern; they present only the FuzzyBench comparison. The paper should explicitly state that the headline advantage holds on FuzzyBench but not on the external benchmarks, and discuss what this implies about the transferability of the claim.
- §5, §6: The FuzzyBench training data and test set are both generated by gpt-5.2. The test set is filtered for agreement between gpt-5-mini and gpt-5.2, but both the training labels and the verification standard come from the same model family. The PAW compiler is trained on 10M examples from this distribution (unseen specs, but same generative process), while Qwen3-32B is evaluated zero-shot. A system specialized to a distribution outperforming a generalist on that distribution is expected; the question is whether the distribution reflects real-world fuzzy functions. The paper should add a discussion of this confound and clarify that the FuzzyBench comparison is not an apples-to-apples evaluation of general capability.
- §6, Table 2: The choice of Qwen3-32B as the comparison point for the headline claim is favorable. Table 2 shows that gpt-oss-20B achieves 85.45% on FuzzyBench (zero-shot), substantially above PAW's 73.78%. The paper does not discuss this gap. While gpt-oss-20B is larger, it is an open-weight model that could also be quantized for local use. The paper should address why the 32B comparison is the most informative one, or at minimum acknowledge the gpt-oss-20B result.
minor comments (7)
- Table 2: The 'PS' (per-program shipping size) column reports 23 MB for PAW across all benchmarks, but the text in §9 mentions ~430 MB shared base plus 23 MB per-program. The table header or caption should clarify whether PS includes only the adapter or the total deployment footprint.
- §3.2, Eq. (3): The notation for mixing coefficients alpha^{A,B}_{l,m,n} uses a single superscript A,B but the summation in Eq. (3) uses separate alpha^A and alpha^B. Clarify whether these are distinct heads or a single head producing both.
- Table 1 vs Table 2: Table 1 reports Text-to-LoRA r=64 accuracy as 0.657, while Table 2 reports PAW (Qwen3 0.6B) at 0.7378. The text states Table 1 is at 'controlled comparison scale' but the relationship between these two numbers (same architecture, different training data scale?) should be stated explicitly.
- §7, Table 4: The default mapper accuracy is 0.6223, but Table 2 reports 0.7378 for the same configuration. Presumably Table 4 uses a subset or earlier checkpoint; this should be noted in the Table 4 caption.
- Appendix I, Table 12: The compiler-scaling study is labeled 'inconclusive' and uses only 0.6M training examples at epoch 1. This is fine as exploratory data, but the caption should note that the main results use 10M examples and 3 epochs, so these numbers are not directly comparable.
- §9: The five case studies are qualitative walkthroughs without controlled comparisons against Qwen3-32B on the same tasks. This is acceptable for illustration, but the text should state explicitly that these are demonstrations, not evaluations, so readers do not over-interpret the 93% ToolCall-15 score as a head-to-head result.
- Figure 3: The task-family distribution percentages sum to 100% but the example counts (2.95M + 1.80M + 1.50M + 1.25M + 1.25M + 0.75M + 0.50M = 10.0M) match. However, the figure caption says '29 incremental thematic versions are mapped to 7 high-level families' without explaining whether categories can belong to multiple families. Clarify whether these are post-deduplication counts.
Simulated Author's Rebuttal
We thank the referee for a careful and fair reading of the manuscript. All three major comments identify legitimate issues with how the headline results are framed relative to what the data actually shows. We agree with the substance of each point and will revise the manuscript accordingly. Below we address each in turn.
read point-by-point responses
-
Referee: §6, Table 2: The headline claim that '0.6B PAW matches Qwen3-32B' is drawn exclusively from FuzzyBench, a benchmark the authors constructed. On the four external benchmarks (YouTube, SMS, Yelp, IMDB), PAW (0.6B) underperforms Qwen3-32B on all four. The abstract and introduction do not acknowledge this pattern.
Authors: The referee is correct. The current abstract and introduction present the FuzzyBench comparison without qualifying that the advantage does not hold on the four external benchmarks. This is a framing problem we will fix. Specifically, we will: (1) revise the abstract to state that the 0.6B PAW interpreter matches Qwen3-32B on FuzzyBench but underperforms it on external benchmarks, making clear that the headline comparison is distribution-specific; (2) add a paragraph in §6 explicitly noting the cross-benchmark pattern — PAW trails Qwen3-32B on YouTube (90.40% vs 93.60%), SMS (80.77% vs 89.04%), Yelp (95.82% vs 98.11%), and IMDB (90.64% vs 94.64%) — and discussing what this implies: PAW's advantage comes from compiler-generated specialization to the FuzzyBench task distribution, and on narrower, well-defined external tasks where a 32B model's general capability suffices, the specialization benefit does not overcome the capacity gap. We agree this qualification should have been in the original submission. revision: yes
-
Referee: §5, §6: FuzzyBench training and test data are both generated by gpt-5.2. The PAW compiler is trained on 10M examples from this distribution while Qwen3-32B is evaluated zero-shot. A system specialized to a distribution outperforming a generalist on that distribution is expected.
Authors: This is a fair and important point. We will add a dedicated discussion in §6 acknowledging this confound explicitly. The key facts are: (a) both FuzzyBench training labels and the test-set verification standard come from the gpt-5.2 model family, so the PAW compiler is trained on data drawn from the same distribution it is evaluated on (though test specifications are unseen); (b) Qwen3-32B is evaluated zero-shot with no distribution-specific adaptation; (c) therefore the FuzzyBench comparison is not an apples-to-apples evaluation of general capability — it measures whether compiler-generated specialization to a task distribution can substitute for raw model scale on that distribution. We will state this plainly. We note that the external benchmarks (YouTube, SMS, Yelp, IMDB), where PAW does not have this distributional advantage, provide a partial corrective: PAW underperforms Qwen3-32B on all four, which is consistent with the referee's expectation. We will also note in §5 (as we already do in Appendix N) that broader external validation is in progress and that the five case studies in §9 are an initial step toward real-world validation beyond the synthetic distribution. revision: yes
-
Referee: §6, Table 2: gpt-oss-20B achieves 85.45% on FuzzyBench zero-shot, substantially above PAW's 73.78%. The paper does not discuss this gap. The 32B comparison is favorable.
Authors: We agree the paper should address the gpt-oss-20B result. We will add discussion in §6 acknowledging that gpt-oss-20B (85.45%) substantially outperforms PAW (73.78%) on FuzzyBench in zero-shot prompting, and that this gap is real and significant. We will also explain our choice of Qwen3-32B as the primary comparison point: the comparison is within the same model family (Qwen3), which isolates the effect of PAW specialization versus parameter scale without confounding by architecture or training-data differences. This makes the 0.6B-vs-32B comparison cleaner as a controlled test of whether compiler-generated adapters can substitute for scale within a family. However, we concede that this rationale was not stated in the paper and that the gpt-oss-20B result weakens the practical deployment argument: a user who can run a 20B model locally would get better FuzzyBench performance from direct prompting than from PAW. We will add this caveat honestly. The deployment argument for PAW is strongest in the regime where the user cannot or will not run a 20B model — e.g., the ~430 MB quantized interpreter running at 30 tok/s on a MacBook M3 — but we should not imply that PAW dominates all local alternatives. We will revise the framing accordingly. revision: partial
Circularity Check
No formal circularity found; the evaluated system is architecturally distinct from the data generator, and concerns are about external validity rather than self-referential construction.
full rationale
The paper's central claim (0.6B PAW interpreter matches Qwen3-32B on FuzzyBench) is an empirical benchmark result, not a first-principles derivation or prediction. The training objective (Eq. 4) is standard supervised likelihood. The LoRA mapper (Eq. 3) is a standard shared-basis linear combination. FuzzyBench is generated by gpt-5.2, but the trained and evaluated system (Qwen3-4B compiler, Qwen3-0.6B interpreter) is a different model family, test specifications are held out (80/10/10 split), and the paper explicitly acknowledges the synthetic-data limitation. No load-bearing argument depends on a self-citation chain, no uniqueness theorem is invoked, and no ansatz is smuggled from prior self-authored work. The concerns about FuzzyBench being self-constructed and the external benchmarks showing PAW underperforming Qwen3-32B are external validity issues, not circularity. The paper transparently reports both wins and losses. Score 1 reflects the minor concern that the benchmark is author-constructed, but this does not constitute formal circularity.
Axiom & Free-Parameter Ledger
free parameters (6)
- LoRA rank r =
64
- Number of shared bases N =
64
- Prefix token count T =
64
- Learning rate =
2e-5
- LoRA mapper MLP architecture =
single residual MLP trunk
- Compiler depth-aligned layers L =
one per interpreter layer, spaced uniformly by depth ratio
axioms (4)
- domain assumption A frozen 0.6B language model, when injected with a compiler-generated LoRA adapter and a pseudo-program, can approximate fuzzy functions well enough to match a 32B model's direct prompting.
- domain assumption FuzzyBench's 10M gpt-5.2-generated examples are representative of the fuzzy functions developers actually encounter.
- domain assumption The verified test set (gpt-5-mini and gpt-5.2 agreement) provides a fair evaluation standard.
- domain assumption Standard PEFT methods (LoRA, prefix-tuning) are sufficient as the continuous program form.
invented entities (3)
-
FuzzyBench-10M dataset
independent evidence
-
LoRA mapper (shared-basis mixing architecture)
independent evidence
-
Pseudo-program (discrete component)
independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
FANT o M : A Benchmark for Stress-testing Machine Theory of Mind in Interactions
Kim, Hyunwoo and Sclar, Melanie and Zhou, Xuhui and Bras, Ronan and Kim, Gunhee and Choi, Yejin and Sap, Maarten. FANT o M : A Benchmark for Stress-testing Machine Theory of Mind in Interactions. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.890
-
[10]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Li, Xiang Lisa and Liang, Percy. Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.353
-
[11]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[12]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[13]
Yujia Li and David Choi and Junyoung Chung and Nate Kushman and Julian Schrittwieser and Rémi Leblond and Tom Eccles and James Keeling and Felix Gimeno and Agustin Dal Lago and Thomas Hubert and Peter Choy and Cyprien de Masson d’Autume and Igor Babuschkin and Xinyun Chen and Po-Sen Huang and Johannes Welbl and Sven Gowal and Alexey Cherepanov and James M...
-
[14]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[15]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[16]
Text-to-Lo
Rujikorn Charakorn and Edoardo Cetin and Yujin Tang and Robert Tjarko Lange , booktitle=. Text-to-Lo. 2025 , url=
2025
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Generative Adapter: Contextualizing Language Models in Parameters with A Single Forward Pass , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
International Conference on Learning Representations , year=
Continual learning with hypernetworks , author=. International Conference on Learning Representations , year=
-
[19]
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks
Karimi Mahabadi, Rabeeh and Ruder, Sebastian and Dehghani, Mostafa and Henderson, James. Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Pap...
-
[20]
2020 , eprint=
Language Models are Few-Shot Learners , author=. 2020 , eprint=
2020
-
[21]
2014 , eprint=
Neural Turing Machines , author=. 2014 , eprint=
2014
-
[22]
2016 , eprint=
Neural Programmer-Interpreters , author=. 2016 , eprint=
2016
-
[23]
2021 , eprint=
Thinking Like Transformers , author=. 2021 , eprint=
2021
-
[24]
Frédéric Gruau and Jean-Yves Ratajszczak and Gilles Wiber , abstract =. A neural compiler , journal =. 1995 , issn =. doi:https://doi.org/10.1016/0304-3975(94)00200-3 , url =
-
[25]
2025 , eprint=
Small Language Models are the Future of Agentic AI , author=. 2025 , eprint=
2025
-
[26]
AI Commun
Rubio Manzano, Clemente , title =. AI Commun. , month = oct, pages =. 2012 , issue_date =
2012
-
[27]
The ALCHEmist: Automated Labeling 500x CHEaper than LLM Data Annotators , url =
Huang, Tzu-Heng and Cao, Catherine and Bhargava, Vaishnavi and Sala, Frederic , booktitle =. The ALCHEmist: Automated Labeling 500x CHEaper than LLM Data Annotators , url =. doi:10.52202/079017-2003 , editor =
-
[28]
, title =
Deng, Yuntian and Kanervisto, Anssi and Ling, Jeffrey and Rush, Alexander M. , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
2017
-
[29]
and Hajishirzi, Hannaneh and Girshick, Ross and Farhadi, Ali and Kembhavi, Aniruddha , title =
Deitke, Matt and Clark, Christopher and Lee, Sangho and Tripathi, Rohun and Yang, Yue and Park, Jae Sung and Salehi, Mohammadreza and Muennighoff, Niklas and Lo, Kyle and Soldaini, Luca and Lu, Jiasen and Anderson, Taira and Bransom, Erin and Ehsani, Kiana and Ngo, Huong and Chen, YenSung and Patel, Ajay and Yatskar, Mark and Callison-Burch, Chris and Hea...
2025
-
[30]
2025 , eprint=
MCA-Bench: A Multimodal Benchmark for Evaluating CAPTCHA Robustness Against VLM-based Attacks , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
AndesVL Technical Report: An Efficient Mobile-side Multimodal Large Language Model , author=. 2025 , eprint=
2025
-
[33]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
Teach2Eval: An Indirect Evaluation Method for LLM by Judging How It Teaches , author=. 2025 , eprint=
2025
-
[35]
The Eleventh International Conference on Learning Representations , year=
Large Language Models are Human-Level Prompt Engineers , author=. The Eleventh International Conference on Learning Representations , year=
-
[36]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[37]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[38]
Williams, Ronald J. , title =. Mach. Learn. , month = may, pages =. 1992 , issue_date =. doi:10.1007/BF00992696 , abstract =
-
[39]
Policy Gradient Methods for Reinforcement Learning with Function Approximation , url =
Sutton, Richard S and McAllester, David and Singh, Satinder and Mansour, Yishay , booktitle =. Policy Gradient Methods for Reinforcement Learning with Function Approximation , url =
-
[40]
2025 , eprint=
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild , author=. 2025 , eprint=
2025
-
[41]
2021 , url=
Jieyu Zhang and Yue Yu and Yinghao Li and Yujing Wang and Yaming Yang and Mao Yang and Alexander Ratner , booktitle=. 2021 , url=
2021
-
[42]
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation , author=. arXiv preprint arXiv:2502.14846 , year=
-
[43]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Molmo and PixMo: Open weights and open data for state-of-the-art vision-language models , author=. arXiv preprint arXiv:2409.17146 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[45]
Python 3.14.2 , howpublished =
-
[46]
Proceedings of the 34th International Conference on Machine Learning , pages =
Image-to-Markup Generation with Coarse-to-Fine Attention , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[47]
The Eleventh International Conference on Learning Representations , year=
Markup-to-Image Diffusion Models with Scheduled Sampling , author=. The Eleventh International Conference on Learning Representations , year=
-
[48]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[49]
2025 , eprint=
HyperSteer: Activation Steering at Scale with Hypernetworks , author=. 2025 , eprint=
2025
-
[50]
The Eleventh International Conference on Learning Representations (ICLR) , year =
Binding Language Models in Symbolic Languages , author =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[51]
Learning to Generate Task-Specific Adapters from Task Description
Ye, Qinyuan and Ren, Xiang. Learning to Generate Task-Specific Adapters from Task Description. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2021. doi:10.18653/v1/2021.acl-short.82
-
[52]
HINT : Hypernetwork Instruction Tuning for Efficient Zero- and Few-Shot Generalisation
Ivison, Hamish and Bhagia, Akshita and Wang, Yizhong and Hajishirzi, Hannaneh and Peters, Matthew. HINT : Hypernetwork Instruction Tuning for Efficient Zero- and Few-Shot Generalisation. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.631
-
[53]
2023 , volume =
Phang, Jason and Mao, Yi and He, Pengcheng and Chen, Weizhu , booktitle =. 2023 , volume =
2023
-
[54]
Advances in Neural Information Processing Systems , year =
Learning to Compress Prompts with Gist Tokens , author =. Advances in Neural Information Processing Systems , year =
-
[55]
2024 , url =
Li, Yichuan and Ma, Xiyao and Lu, Sixing and Lee, Kyumin and Liu, Xiaohu and Guo, Chenlei , booktitle =. 2024 , url =
2024
-
[56]
2019 , publisher =
Language Models are Unsupervised Multitask Learners , author =. 2019 , publisher =
2019
-
[57]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI , year =. 2508.10925 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
2023 , url =
Gerganov, Georgi and. 2023 , url =
2023
-
[59]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[60]
Singh, Amanpreet and Natarajan, Vivek and Shah, Meet and Jiang, Yu and Chen, Xinlei and Batra, Dhruv and Parikh, Devi and Rohrbach, Marcus , booktitle =. Towards
-
[61]
and Le, Quoc V
Ha, David and Dai, Andrew M. and Le, Quoc V. , booktitle =. 2017 , url =
2017
-
[62]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and de Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle =. Parameter-Efficient Transfer Learning for. 2019 , url =
2019
-
[63]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
The Power of Scale for Parameter-Efficient Prompt Tuning , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[64]
2022 , url =
Liu, Xiao and Ji, Kaixuan and Fu, Yicheng and Tam, Weng Lam and Du, Zhengxiao and Yang, Zhilin and Tang, Jie , booktitle =. 2022 , url =
2022
-
[65]
Advances in Neural Information Processing Systems , year =
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning , author =. Advances in Neural Information Processing Systems , year =
-
[66]
Advances in Neural Information Processing Systems , year =
Compacter: Efficient Low-Rank Hypercomplex Adapter Layers , author =. Advances in Neural Information Processing Systems , year =
-
[67]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Pfeiffer, Jonas and Kamath, Aishwarya and R. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[68]
2024 , url =
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle =. 2024 , url =
2024
-
[69]
2024 , url =
Huang, Chengsong and Liu, Qian and Lin, Bill Yuchen and Pang, Tianyu and Du, Chao and Lin, Min , booktitle =. 2024 , url =
2024
-
[70]
2023 , url =
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and Karampatziakis, Nikos and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , booktitle =. 2023 , url =
2023
-
[71]
2023 , url =
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =. 2023 , url =
2023
-
[72]
2023 , url =
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , booktitle =. 2023 , url =
2023
-
[73]
2024 , url =
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song , booktitle =. 2024 , url =
2024
-
[74]
Charakorn, Rujikorn and Cetin, Edoardo and Uesaka, Shinnosuke and Lange, Robert Tjarko , year =. 2602.15902 , archivePrefix =
-
[75]
2026 , eprint =
Latent Context Compilation: Distilling Long Context into Compact Portable Memory , author =. 2026 , eprint =
2026
-
[76]
2026 , eprint =
Trojan, Bartosz and G. 2026 , eprint =
2026
-
[77]
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass
Liu, Yewei and Wang, Xiyuan and Mao, Yansheng and Gelberg, Yoav and Maron, Haggai and Zhang, Muhan , year =. 2602.06358 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
The Tenth International Conference on Learning Representations (ICLR) , year =
Finetuned Language Models are Zero-Shot Learners , author =. The Tenth International Conference on Learning Representations (ICLR) , year =
-
[79]
The Tenth International Conference on Learning Representations (ICLR) , year =
Multitask Prompted Training Enables Zero-Shot Task Generalization , author =. The Tenth International Conference on Learning Representations (ICLR) , year =
-
[80]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Cross-Task Generalization via Natural Language Crowdsourcing Instructions , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =. 2022 , url =
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.