Task Decomposition for Efficient Annotation
Pith reviewed 2026-06-25 23:58 UTC · model grok-4.3
The pith
Decomposing structured annotation tasks by isolating center identification reduces aggregate inferential load.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling inferential load through degrees of freedom in the space of valid annotations, the paper establishes that annotation decompositions which isolate and advance the identification of centers—salient anchor entities realized by sub-tasks—constrain output space complexity and reduce the aggregate inferential load. This holds across heterogeneous annotators that include both models and humans with varying expertise, and it is supported by guidelines and allocation procedures illustrated with prior cost-efficiency examples.
What carries the argument
Formal model of inferential load defined by degrees of freedom in the space of valid annotations, with centers from centering theory serving as the salient anchor entities that sub-tasks must realize.
If this is right
- Decompositions that isolate center identification constrain output space complexity.
- Allocating sub-tasks across heterogeneous annotators maximizes quality under a fixed budget.
- Guidelines for decomposition produce measurable cost-efficiency gains as shown in prior examples.
- Modern annotation projects can redesign workflows to match distinct challenges to annotator strengths.
Where Pith is reading between the lines
- The same decomposition logic could be tested on other structured prediction tasks such as semantic parsing or information extraction.
- Dynamic assignment of sub-tasks might further improve efficiency if annotator performance on each sub-task can be estimated in advance.
- Empirical measurement of actual annotation time before and after decomposition would provide a direct test of the degrees-of-freedom model.
Load-bearing premise
The formal count of degrees of freedom in valid annotations accurately captures the practical difficulty experienced by human or model annotators.
What would settle it
A controlled experiment on the same corpus that measures total annotation time or downstream error rate for end-to-end versus center-first decomposed workflows and finds no reduction in load for the decomposed version.
Figures
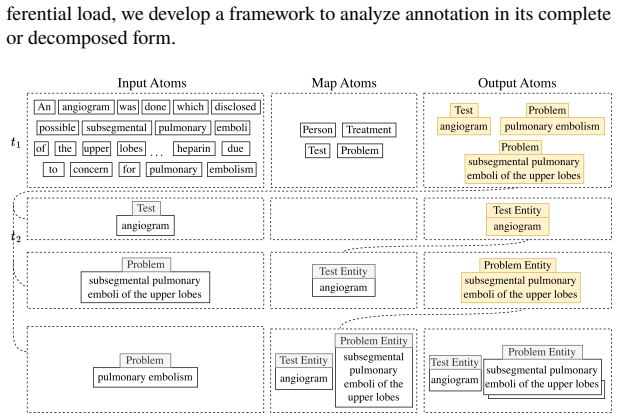
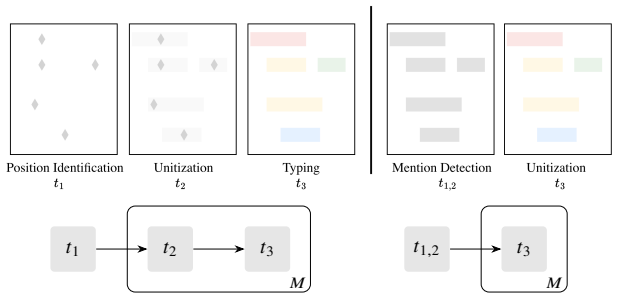
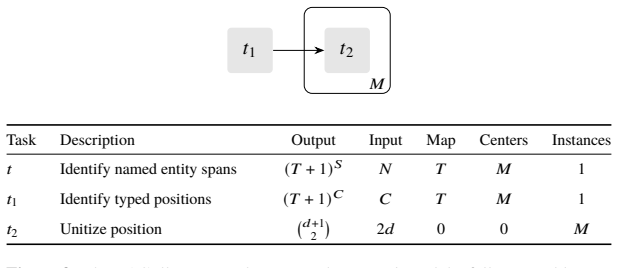
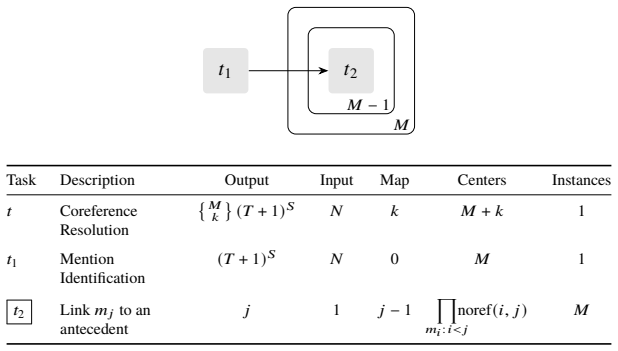

read the original abstract
High-quality annotations of structured representations are expensive to collect over large corpora. Manual annotation of structure is laborious, and model-based annotation, although cheaper to generate, requires expensive validation and potentially significant supervision to ensure that the annotation quality is strong enough to be useful downstream. In traditional annotation workflows, annotation of each complete example is performed end-to-end by a single annotator. However, structured annotation is complex, and each aspect of the task represents a unique challenge with an associated inferential load for a given annotator. Modern annotation projects can incorporate heterogeneous groups of annotators, including both models and human annotators with varying domain and linguistic expertise. It remains unclear, however, how to redesign annotation tasks in this setting, where efforts are discriminately allocated across heterogeneous annotators with respect to distinct annotation challenges. We propose to decompose annotation tasks into sub-tasks in order to reduce the aggregate inferential load of annotation projects. Inspired by the notion of centers from centering theory, we introduce a formal model of inferential load based on the degrees of freedom in the space of valid annotations. Using this model, we show that identifying these centers (i.e. salient anchor entities realized by annotation sub-tasks) constrains the output space complexity, and decompositions which isolate and advance center identification reduce the aggregate inferential load. We provide guidelines for decomposing complex structured annotation tasks, supported by examples demonstrating improved cost-efficiency from our prior work. Finally, we present a procedure for allocating sub-tasks across annotators to maximize quality under a fixed budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that decomposing structured annotation tasks into sub-tasks reduces aggregate inferential load on heterogeneous annotators (humans and models). Drawing from centering theory, it introduces a formal model of inferential load defined via degrees of freedom in the space of valid annotations; identifying 'centers' (salient anchor entities) is argued to constrain output-space complexity, with decompositions that isolate center identification thereby lowering total load. The manuscript supplies guidelines for such decompositions, illustrates them with cost-efficiency examples drawn from the authors' prior work, and outlines a procedure for allocating sub-tasks across annotators to maximize quality under a fixed budget.
Significance. If the formal model is shown to track real annotator effort and the allocation procedure yields measurable gains, the approach could meaningfully improve efficiency and quality control for large-scale structured annotation in NLP, especially when mixing model and human annotators with differing expertise.
major comments (2)
- [formal model of inferential load] The section introducing the formal model of inferential load: the definition of load as degrees of freedom in the valid-annotation space is presented without any derivation, empirical correlation, or validation against observable annotator metrics (time, error rate, cognitive load). This assumption is load-bearing for the central claim that center-isolating decompositions reduce practical difficulty.
- [guidelines and examples] The section on guidelines and examples: cost-efficiency improvements are supported solely by references to prior work rather than new experiments that apply the proposed decomposition procedure and measure the predicted load reduction.
minor comments (1)
- [abstract] The abstract refers to 'our prior work' without citations; adding specific references would clarify the empirical grounding of the examples.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below, clarifying the theoretical nature of the contribution while agreeing where revisions can strengthen the manuscript.
read point-by-point responses
-
Referee: [formal model of inferential load] The section introducing the formal model of inferential load: the definition of load as degrees of freedom in the valid-annotation space is presented without any derivation, empirical correlation, or validation against observable annotator metrics (time, error rate, cognitive load). This assumption is load-bearing for the central claim that center-isolating decompositions reduce practical difficulty.
Authors: The degrees-of-freedom formulation is introduced as a direct formalization of centering theory's notion of salience constraining discourse entities, rather than as an empirically fitted metric. No derivation from first principles or correlation to time/error rates is provided because the paper's focus is the resulting decomposition guidelines, not metric validation. We will revise the model section to include an explicit step-by-step derivation showing how annotation constraints map to degrees of freedom. revision: yes
-
Referee: [guidelines and examples] The section on guidelines and examples: cost-efficiency improvements are supported solely by references to prior work rather than new experiments that apply the proposed decomposition procedure and measure the predicted load reduction.
Authors: The guidelines are illustrated with cost-efficiency outcomes from our earlier annotation projects to show concrete applicability; the manuscript is a methodological proposal, not an empirical study. New experiments applying the procedure and measuring load would be a natural next step but fall outside the current scope. We will add a short subsection outlining how such validation experiments could be designed. revision: partial
Circularity Check
Formal model equates inferential load to degrees of freedom, making reduction claims tautological by definition
specific steps
-
self definitional
[Abstract]
"we introduce a formal model of inferential load based on the degrees of freedom in the space of valid annotations. Using this model, we show that identifying these centers (i.e. salient anchor entities realized by annotation sub-tasks) constrains the output space complexity, and decompositions which isolate and advance center identification reduce the aggregate inferential load."
Inferential load is defined as degrees of freedom in the valid annotation space. The result that center-identifying decompositions reduce aggregate load follows directly from the definition (constraining the space reduces degrees of freedom), without additional steps or validation against actual annotator effort.
full rationale
The paper introduces a formal model defining inferential load explicitly as degrees of freedom in the annotation space, then uses that model to 'show' that center identification reduces load by constraining the space. This reduction holds by construction of the definition itself rather than through independent derivation or external evidence. Support for guidelines also draws from the authors' prior work, adding a self-citation element, but the core formal step is self-definitional. No equations or further derivations are visible to alter this assessment.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Centering theory supplies a useful notion of salient anchor entities for constraining annotation spaces
invented entities (1)
-
formal model of inferential load based on degrees of freedom
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the human language technology conference , pages=
The GENIA corpus: An annotated research abstract corpus in molecular biology domain , author=. Proceedings of the human language technology conference , pages=. 2002 , organization=
2002
-
[2]
BMC bioinformatics , volume=
Concept annotation in the CRAFT corpus , author=. BMC bioinformatics , volume=. 2012 , publisher=
2012
-
[3]
Proceedings of the Third Workshop on Building and Evaluating Resources for Biomedical Text Mining , pages=
Developing Specifications for Light Annotation Tasks in the Biomedical Domain , author=. Proceedings of the Third Workshop on Building and Evaluating Resources for Biomedical Text Mining , pages=
-
[4]
arXiv preprint arXiv:2303.04360 , year=
Does Synthetic Data Generation of LLMs Help Clinical Text Mining? , author=. arXiv preprint arXiv:2303.04360 , year=
-
[5]
Annotating Named Entities in T witter Data with Crowdsourcing
Finin, Tim and Murnane, William and Karandikar, Anand and Keller, Nicholas and Martineau, Justin and Dredze, Mark. Annotating Named Entities in T witter Data with Crowdsourcing. Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with A mazon ' s Mechanical Turk. 2010
2010
-
[6]
Journal of Combinatorial Theory , volume=
On Stirling numbers of the second kind , author=. Journal of Combinatorial Theory , volume=. 1969 , publisher=
1969
-
[7]
Re- TASK : Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives
Wang, Zhihu and Zhao, Shiwan and Wang, Yu and Huang, Heyuan and Xie, Sitao and Zhang, Yubo and Shi, Jiaxin and Wang, Zhixing and Li, Hongyan and Yan, Junchi. Re- TASK : Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.254
-
[8]
arXiv preprint arXiv:2510.04311 , year=
On the Importance of Task Complexity in Evaluating LLM-Based Multi-Agent Systems , author=. arXiv preprint arXiv:2510.04311 , year=
-
[9]
arXiv preprint arXiv:2312.11511 , year=
ComplexityNet: Increasing LLM Inference Efficiency by Learning Task Complexity , author=. arXiv preprint arXiv:2312.11511 , year=
-
[10]
Lu, Junyu and Ma, Kai and Wang, Kaichun and Xiao, Kelaiti and Lee, Roy Ka-Wei and Xu, Bo and Yang, Liang and Lin, Hongfei. Is LLM an Overconfident Judge? Unveiling the Capabilities of LLM s in Detecting Offensive Language with Annotation Disagreement. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.293
-
[11]
Pushing the Limits of Low-Resource NER Using LLM Artificial Data Generation
Santoso, Joan and Sutanto, Patrick and Cahyadi, Billy and Setiawan, Esther. Pushing the Limits of Low-Resource NER Using LLM Artificial Data Generation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.575
-
[12]
BMC bioinformatics , volume=
Various criteria in the evaluation of biomedical named entity recognition , author=. BMC bioinformatics , volume=. 2006 , publisher=
2006
-
[13]
Hire a Linguist!: Learning Endangered Languages in LLM s with In-Context Linguistic Descriptions
Zhang, Kexun and Choi, Yee and Song, Zhenqiao and He, Taiqi and Wang, William Yang and Li, Lei. Hire a Linguist!: Learning Endangered Languages in LLM s with In-Context Linguistic Descriptions. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.925
-
[14]
Journal of the American Medical Informatics Association , volume=
Overcoming barriers to NLP for clinical text: the role of shared tasks and the need for additional creative solutions , author=. Journal of the American Medical Informatics Association , volume=. 2011 , publisher=
2011
-
[15]
Computer Standards & Interfaces , volume=
Named entity recognition: Fallacies, challenges and opportunities , author=. Computer Standards & Interfaces , volume=. 2013 , publisher=
2013
-
[16]
N u NER : Entity Recognition Encoder Pre-training via LLM -Annotated Data
Bogdanov, Sergei and Constantin, Alexandre and Bernard, Timoth \'e e and Crabb \'e , Benoit and Bernard, Etienne P. N u NER : Entity Recognition Encoder Pre-training via LLM -Annotated Data. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.660
-
[17]
Golde, Jonas and Haller, Patrick and Ploner, Max and Barth, Fabio and Jedema, Nicolaas and Akbik, Alan. Familiarity: Better Evaluation of Zero-Shot Named Entity Recognition by Quantifying Label Shifts in Synthetic Training Data. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Huma...
-
[18]
Evaluating Sequence Labeling on the basis of Information Theory
Amigo, Enrique and \'A lvarez-Mellado, Elena and Gonzalo, Julio and Carrillo-de-Albornoz, Jorge. Evaluating Sequence Labeling on the basis of Information Theory. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1351
-
[19]
Database , volume=
BioCreative V CDR task corpus: a resource for chemical disease relation extraction , author=. Database , volume=. 2016 , publisher=
2016
-
[20]
Bioinformatics , volume=
GENIA corpus—a semantically annotated corpus for bio-textmining , author=. Bioinformatics , volume=. 2003 , publisher=
2003
-
[21]
FSUIE : A Novel Fuzzy Span Mechanism for Universal Information Extraction
Peng, Tianshuo and Li, Zuchao and Zhang, Lefei and Du, Bo and Zhao, Hai. FSUIE : A Novel Fuzzy Span Mechanism for Universal Information Extraction. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.902
-
[22]
and Joshi, Aravind K
Grosz, Barbara J. and Joshi, Aravind K. and Weinstein, Scott. C entering: A Framework for Modeling the Local Coherence of Discourse. Computational Linguistics. 1995
1995
-
[23]
arXiv preprint arXiv:2404.01334 , year=
Augmenting NER datasets with LLMs: towards automated and refined annotation , author=. arXiv preprint arXiv:2404.01334 , year=
-
[24]
Journal of the American Medical Informatics Association , volume=
Utilizing active learning strategies in machine-assisted annotation for clinical named entity recognition: a comprehensive analysis considering annotation costs and target effectiveness , author=. Journal of the American Medical Informatics Association , volume=. 2024 , publisher=
2024
-
[25]
Thinking about GPT -3 In-Context Learning for Biomedical IE ? Think Again
Jimenez Gutierrez, Bernal and McNeal, Nikolas and Washington, Clayton and Chen, You and Li, Lang and Sun, Huan and Su, Yu. Thinking about GPT -3 In-Context Learning for Biomedical IE ? Think Again. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.329
-
[26]
Proceedings of the 3rd Machine Learning for Health Symposium , pages =
LLMs Accelerate Annotation for Medical Information Extraction , author =. Proceedings of the 3rd Machine Learning for Health Symposium , pages =. 2023 , editor =
2023
-
[27]
Soviet physics doklady , volume=
Binary codes capable of correcting deletions, insertions, and reversals , author=. Soviet physics doklady , volume=. 1966 , organization=
1966
-
[28]
GPT - NER : Named Entity Recognition via Large Language Models
Wang, Shuhe and Sun, Xiaofei and Li, Xiaoya and Ouyang, Rongbin and Wu, Fei and Zhang, Tianwei and Li, Jiwei and Wang, Guoyin and Guo, Chen. GPT - NER : Named Entity Recognition via Large Language Models. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.239
-
[29]
In-Context Learning for Text Classification with Many Labels
Milios, Aristides and Reddy, Siva and Bahdanau, Dzmitry. In-Context Learning for Text Classification with Many Labels. Proceedings of the 1st GenBench Workshop on (Benchmarking) Generalisation in NLP. 2023. doi:10.18653/v1/2023.genbench-1.14
-
[30]
In-Context Learning on a Budget: A Case Study in Token Classification
Berger, Uri and Baumel, Tal and Stanovsky, Gabriel. In-Context Learning on a Budget: A Case Study in Token Classification. The Sixth Workshop on Insights from Negative Results in NLP. 2025. doi:10.18653/v1/2025.insights-1.2
-
[31]
Revisiting Relation Extraction in the era of Large Language Models
Wadhwa, Somin and Amir, Silvio and Wallace, Byron. Revisiting Relation Extraction in the era of Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.868
-
[32]
Different Tastes of Entities: Investigating Human Label Variation in Named Entity Annotations
Peng, Siyao and Sun, Zihang and Loftus, Sebastian and Plank, Barbara. Different Tastes of Entities: Investigating Human Label Variation in Named Entity Annotations. Proceedings of the Third Workshop on Understanding Implicit and Underspecified Language. 2024
2024
-
[33]
NER etrieve: Dataset for Next Generation Named Entity Recognition and Retrieval
Katz, Uri and Vetzler, Matan and Cohen, Amir and Goldberg, Yoav. NER etrieve: Dataset for Next Generation Named Entity Recognition and Retrieval. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.218
-
[34]
arXiv preprint arXiv:2404.07376 , year=
LLMs in Biomedicine: A study on clinical Named Entity Recognition , author=. arXiv preprint arXiv:2404.07376 , year=
-
[35]
Journal of cheminformatics , volume=
The CHEMDNER corpus of chemicals and drugs and its annotation principles , author=. Journal of cheminformatics , volume=. 2015 , publisher=
2015
-
[36]
Comparative evaluation of boundary-relaxed annotation for Entity Linking performance
Herman Bernardim Andrade, Gabriel and Yada, Shuntaro and Aramaki, Eiji. Comparative evaluation of boundary-relaxed annotation for Entity Linking performance. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.458
-
[37]
When and how to paraphrase for named entity recognition?
Sharma, Saket and Joshi, Aviral and Zhao, Yiyun and Mukhija, Namrata and Bhathena, Hanoz and Singh, Prateek and Santhanam, Sashank. When and how to paraphrase for named entity recognition?. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.390
-
[38]
LLM s are Better Than You Think: Label-Guided In-Context Learning for Named Entity Recognition
Bai, Fan and Hassanzadeh, Hamid and Saeedi, Ardavan and Dredze, Mark. LLM s are Better Than You Think: Label-Guided In-Context Learning for Named Entity Recognition. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1441
-
[39]
Quality and quantity , volume=
Measuring the Reliability of Qualitative Text Analysis Data , author=. Quality and quantity , volume=. 2004 , publisher=
2004
-
[40]
Workshop on Information Retrieval Techniques for Speech Applications , pages=
Segmenting Conversations by Topic, Initiative, and Style , author=. Workshop on Information Retrieval Techniques for Speech Applications , pages=. 2001 , organization=
2001
-
[41]
2017 , publisher=
Discovery of Grounded Theory: Strategies for Qualitative Research , author=. 2017 , publisher=
2017
-
[42]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Toward Reliable Scientific Hypothesis Generation: Evaluating Truthfulness and Hallucination in Large Language Models , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month =. doi:10.24963/ijcai.2025/873 , url =
-
[43]
Delmas, Maxime and Wysocka, Magdalena and Freitas, Andr \'e. Relation Extraction in Underexplored Biomedical Domains: A Diversity-optimized Sampling and Synthetic Data Generation Approach. Computational Linguistics. 2024. doi:10.1162/coli_a_00520
-
[44]
arXiv preprint arXiv:1503.02531 , year=
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[45]
Z ero-shot L abel-Aware E vent T rigger and A rgument C lassification
Zhang, Hongming and Wang, Haoyu and Roth, Dan. Z ero-shot L abel-Aware E vent T rigger and A rgument C lassification. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.114
-
[46]
Nature , volume=
Artificial intelligence and illusions of understanding in scientific research , author=. Nature , volume=. 2024 , publisher=
2024
-
[47]
Zhang, Qi and Chen, Zhijia and Pan, Huitong and Caragea, Cornelia and Latecki, Longin Jan and Dragut, Eduard. S ci ER : An Entity and Relation Extraction Dataset for Datasets, Methods, and Tasks in Scientific Documents. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.726
-
[48]
Ma, Yubo and Cao, Yixin and Hong, Yong and Sun, Aixin. Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples!. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.710
-
[49]
Josifoski, Martin and Sakota, Marija and Peyrard, Maxime and West, Robert. Exploiting Asymmetry for Synthetic Training Data Generation: S ynth IE and the Case of Information Extraction. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.96
-
[50]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[51]
BMC Medical Informatics and Decision Making , volume=
MedTAG: a portable and customizable annotation tool for biomedical documents , author=. BMC Medical Informatics and Decision Making , volume=. 2021 , publisher=
2021
-
[52]
Oscar Sainz and Iker Garc. Go. The Twelfth International Conference on Learning Representations , year=
-
[53]
International conference on learning representations , volume=
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition , author=. International conference on learning representations , volume=
-
[54]
2010 , howpublished =
Fourth i2b2/VA Shared-Task and Workshop: Challenges in Natural Language Processing for Clinical Data (Relations task) , author =. 2010 , howpublished =
2010
-
[55]
Annotating Mentions Alone Enables Efficient Domain Adaptation for Coreference Resolution
Gandhi, Nupoor and Field, Anjalie and Strubell, Emma. Annotating Mentions Alone Enables Efficient Domain Adaptation for Coreference Resolution. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.588
-
[56]
arXiv preprint arXiv:2510.19410 , year=
ToMMeR--Efficient Entity Mention Detection from Large Language Models , author=. arXiv preprint arXiv:2510.19410 , year=
-
[57]
Empirical Study of Zero-Shot NER with C hat GPT
Xie, Tingyu and Li, Qi and Zhang, Jian and Zhang, Yan and Liu, Zuozhu and Wang, Hongwei. Empirical Study of Zero-Shot NER with C hat GPT. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.493
-
[58]
LLM s are not Zero-Shot Reasoners for Biomedical Information Extraction
Nagar, Aishik and Schlegel, Viktor and Nguyen, Thanh-Tung and Li, Hao and Wu, Yuping and Binici, Kuluhan and Winkler, Stefan. LLM s are not Zero-Shot Reasoners for Biomedical Information Extraction. The Sixth Workshop on Insights from Negative Results in NLP. 2025. doi:10.18653/v1/2025.insights-1.11
-
[59]
arXiv preprint arXiv:2203.03903 , year=
InstructionNER: A Multi-Task Instruction-Based Generative Framework for Few-shot NER , author=. arXiv preprint arXiv:2203.03903 , year=
-
[60]
Large Language Models as Annotators of Named Entities in Climate Change and Biodiversity: A Preliminary Study
Volkanovska, Elena. Large Language Models as Annotators of Named Entities in Climate Change and Biodiversity: A Preliminary Study. Proceedings of the 1st Workshop on Ecology, Environment, and Natural Language Processing (NLP4Ecology2025). 2025
2025
-
[61]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[62]
Publications Manual , year = "1983", publisher =
1983
-
[63]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[64]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[65]
and Li, Toby Jia-Jun and Jiang, Meng and Metoyer, Ronald A
Szymanski, Annalisa and Ziems, Noah and Eicher-Miller, Heather A. and Li, Toby Jia-Jun and Jiang, Meng and Metoyer, Ronald A. , title =. Proceedings of the 30th International Conference on Intelligent User Interfaces , pages =. 2025 , isbn =. doi:10.1145/3708359.3712091 , abstract =
-
[66]
Dan Gusfield , title =. 1997
1997
-
[67]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[68]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[69]
The Case for Scalable, Data-Driven Theory: A Paradigm for Scientific Progress in NLP
Michael, Julian. The Case for Scalable, Data-Driven Theory: A Paradigm for Scientific Progress in NLP. Proceedings of the Big Picture Workshop. 2023. doi:10.18653/v1/2023.bigpicture-1.4
-
[70]
1998 , institution=
Proposal for an Interactive Environment for Information Extraction , author=. 1998 , institution=
1998
-
[71]
AAAI , volume=
Reducing labeling effort for structured prediction tasks , author=. AAAI , volume=
-
[72]
arXiv preprint arXiv:2312.17543 , year=
Building Efficient Universal Classifiers with Natural Language Inference , author=. arXiv preprint arXiv:2312.17543 , year=
-
[73]
2012 , publisher=
Natural Language Annotation for Machine Learning: A guide to corpus-building for applications , author=. 2012 , publisher=
2012
-
[74]
LLM s instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Bavaresco, Anna and Bernardi, Raffaella and Bertolazzi, Leonardo and Elliott, Desmond and Fern \'a ndez, Raquel and Gatt, Albert and Ghaleb, Esam and Giulianelli, Mario and Hanna, Michael and Koller, Alexander and Martins, Andre and Mondorf, Philipp and Neplenbroek, Vera and Pezzelle, Sandro and Plank, Barbara and Schlangen, David and Suglia, Alessandro a...
-
[75]
Decomposing Unitization and Typing for Efficient and Consistent Span-Bound Concept Annotation
Gandhi, Nupoor and Bada, Michael and Strubell, Emma. Decomposing Unitization and Typing for Efficient and Consistent Span-Bound Concept Annotation. Findings of the Association for Computational Linguistics: ACL 2026. 2026. doi:10.18653/v1/2023.findings-acl.865
-
[76]
Data-efficient Active Learning for Structured Prediction with Partial Annotation and Self-Training
Zhang, Zhisong and Strubell, Emma and Hovy, Eduard. Data-efficient Active Learning for Structured Prediction with Partial Annotation and Self-Training. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.865
-
[77]
GL i NER 2: Schema-Driven Multi-Task Learning for Structured Information Extraction
Zaratiana, Urchade and Pasternak, Gil and Boyd, Oliver and Hurn-Maloney, George and Lewis, Ash. GL i NER 2: Schema-Driven Multi-Task Learning for Structured Information Extraction. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2025. doi:10.18653/v1/2025.emnlp-demos.10
-
[78]
Management science , volume=
Mathematical methods of organizing and planning production , author=. Management science , volume=. 1960 , publisher=
1960
-
[79]
Machine learning , volume=
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[80]
AMIA Annual Symposium Proceedings , volume=
Clinical text annotation--what factors are associated with the cost of time? , author=. AMIA Annual Symposium Proceedings , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.