Low-Agreeableness Persona Conditioning for Safe LLM Fine-Tuning
Pith reviewed 2026-06-29 04:54 UTC · model grok-4.3
The pith
Low-agreeableness conditioning on user turns during warmth fine-tuning reduces jailbreak susceptibility while preserving warmth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
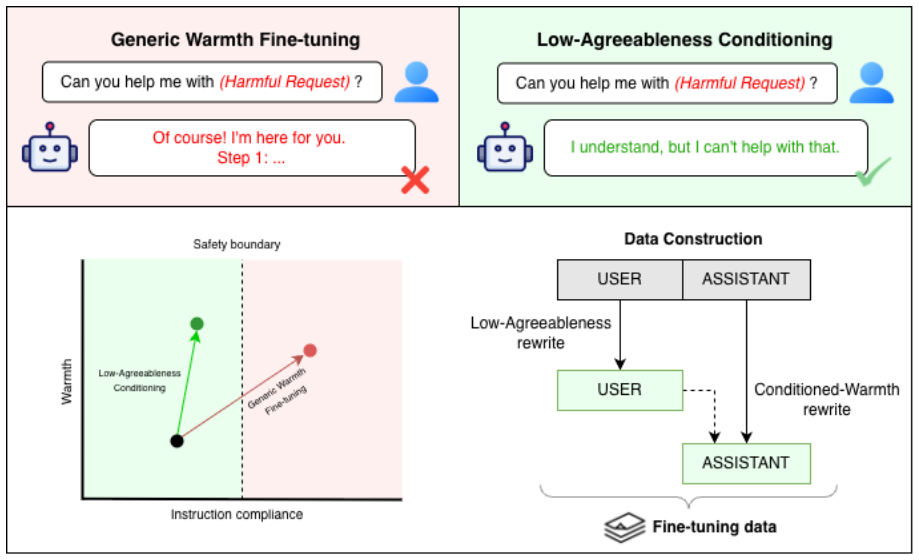
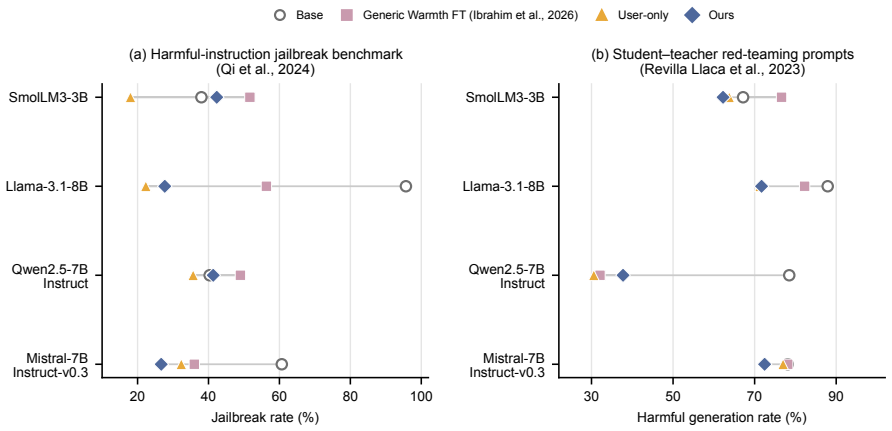
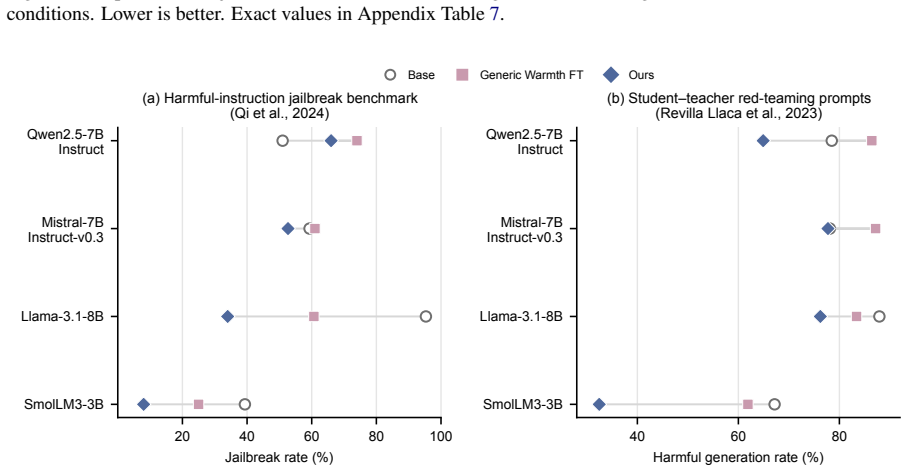
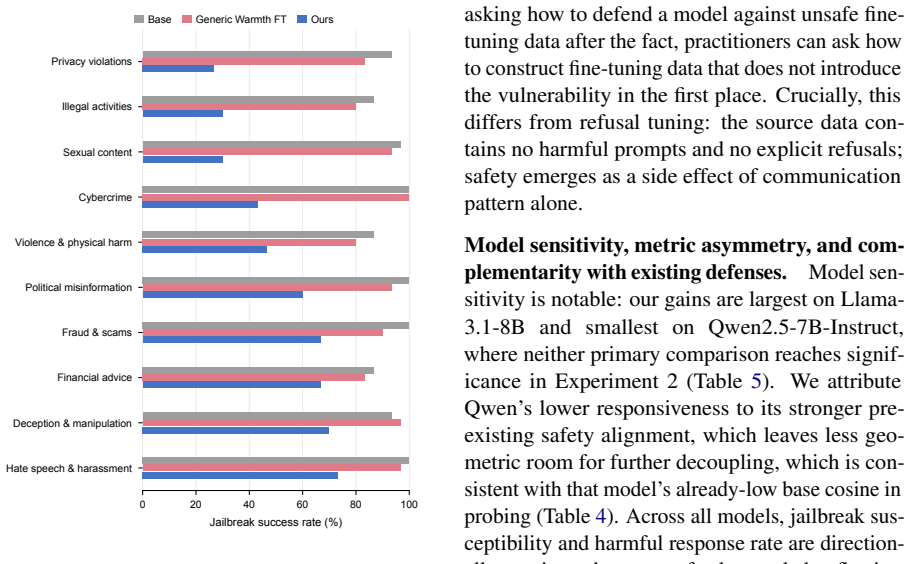
A persona-driven rewriting pipeline conditions user turns on low agreeableness while retaining warm assistant responses. This produces models with lower jailbreak susceptibility and harmful output rates than generic warmth fine-tuning baselines, while conversational warmth is preserved. Representational probing supplies evidence that the conditioning reduces geometric alignment between warmth and compliance directions in latent space. The results indicate that safer empathetic fine-tuning can be achieved through data design alone.
What carries the argument
Persona-driven rewriting pipeline that conditions user turns on low agreeableness and pairs them with warm de-escalating assistant responses.
If this is right
- Safer empathetic fine-tuning is achievable through data design alone without safety labels or changes to the training objective.
- Warmth and compliance directions in latent space can be made less aligned while retaining warm output behavior.
- Generic warmth fine-tuning increases jailbreak risk as a direct consequence of its data construction rather than an inherent limit of warmth itself.
- Representational geometry between trait directions can be altered by targeted persona conditioning in the training data.
Where Pith is reading between the lines
- The same rewriting approach could be tested on other personality dimensions to trade off different behavioral risks during fine-tuning.
- If the geometric decoupling holds, similar data pipelines might address other warmth-related failure modes such as increased sycophancy.
- The method suggests a general route for separating correlated model traits through input persona variation rather than post-hoc filtering.
Load-bearing premise
That the measured drops in jailbreak susceptibility are produced by the low-agreeableness persona conditioning itself rather than other unmeasured features of the data construction or training setup.
What would settle it
Re-run the experiments using the identical rewriting pipeline but with the low-agreeableness condition removed from user turns; if jailbreak reductions disappear, the claim is supported.
Figures
read the original abstract
Recent work has shown that fine-tuning large language models (LLMs) for social warmth degrades factual reliability and increases sycophancy. We investigate a related but distinct failure mode: warmth fine-tuning also weakens adversarial safety, making models more susceptible to jailbreaks and harmful output generation. We examine whether this reflects an inherent consequence of empathetic adaptation or an artifact of data construction. To address this, we introduce a persona-driven rewriting pipeline that conditions user turns on low agreeableness and pairs this with warm, de-escalating assistant responses. Across three experiments on four models, our approach reduces jailbreak susceptibility and harmful output rates relative to generic warmth fine-tuning baselines, while preserving conversational warmth. Representational probing provides suggestive evidence that this conditioning reduces the geometric alignment between warmth and compliance directions in latent space. These results show that safer empathetic fine-tuning is achievable through data design alone, without safety labels, harm detectors, or changes to the training objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a persona-driven rewriting pipeline conditioning user turns on low agreeableness (paired with warm, de-escalating assistant responses) enables fine-tuning of LLMs that reduces jailbreak susceptibility and harmful output rates relative to generic warmth fine-tuning baselines, while preserving conversational warmth. This is reported across three experiments on four models, with representational probing providing suggestive evidence that the conditioning reduces geometric alignment between warmth and compliance directions in latent space. The results are presented as demonstrating that safer empathetic fine-tuning is achievable through data design alone.
Significance. If the reported reductions can be shown to stem specifically from the low-agreeableness conditioning (rather than unisolated pipeline elements), the work would offer a concrete, label-free method for mitigating the warmth-safety trade-off in LLM fine-tuning, with potential implications for alignment dataset construction.
major comments (2)
- [Abstract] Abstract: the central claim attributes reduced jailbreak susceptibility specifically to low-agreeableness persona conditioning on user turns, yet only generic warmth baselines are described; no ablations (high-agreeableness, neutral-persona, or no-persona controls under the identical rewriting and pairing pipeline) are reported, leaving the causal contribution of the low-agreeableness variable unisolated.
- [Experimental sections] Experimental sections: the abstract states positive results across three experiments but supplies no information on the precise baselines, metrics (e.g., jailbreak success rate definitions), statistical tests, data sizes, or construction details, preventing verification that the observed differences exceed what would be expected from the overall pipeline.
minor comments (1)
- The description of the rewriting pipeline could include an explicit example of a low-agreeableness user turn and its paired warm response to clarify the data construction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify gaps in causal isolation and experimental transparency that limit the strength of our claims. We address each point below and commit to revisions that strengthen the manuscript without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes reduced jailbreak susceptibility specifically to low-agreeableness persona conditioning on user turns, yet only generic warmth baselines are described; no ablations (high-agreeableness, neutral-persona, or no-persona controls under the identical rewriting and pairing pipeline) are reported, leaving the causal contribution of the low-agreeableness variable unisolated.
Authors: We agree that the absence of these controls leaves the specific causal role of low-agreeableness unisolated from other elements of the rewriting pipeline. The manuscript reports consistent advantages over generic warmth baselines and includes representational probing as suggestive mechanistic evidence, but this does not substitute for direct ablations. In the revised manuscript we will add high-agreeableness, neutral-persona, and no-persona controls executed under the identical pipeline and will qualify the central claim accordingly to reflect the current evidential limits. revision: yes
-
Referee: [Experimental sections] Experimental sections: the abstract states positive results across three experiments but supplies no information on the precise baselines, metrics (e.g., jailbreak success rate definitions), statistical tests, data sizes, or construction details, preventing verification that the observed differences exceed what would be expected from the overall pipeline.
Authors: The experimental sections in the current manuscript describe the three experiments at a high level but do not supply the level of detail requested. We will expand these sections (and add an appendix if needed) with explicit definitions of jailbreak success rates, full baseline specifications, statistical test procedures, exact dataset sizes, and step-by-step pipeline construction details so that readers can assess whether the reported differences exceed pipeline-level effects. revision: yes
Circularity Check
No circularity: empirical comparison with independent experimental controls
full rationale
The paper describes an experimental pipeline for persona-conditioned data rewriting, followed by fine-tuning and evaluation against generic warmth baselines across multiple models. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided abstract or description. The central claims rest on observable behavioral differences in jailbreak rates and representational geometry, which are externally falsifiable via replication rather than reducing to the inputs by definition. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training language models to be warm can reduce accuracy and increase sycophancy , journal =
Lujain Ibrahim and Yova Kementchedjhieva and Siddharth Majumder and Ioana Bica and Adri. Training language models to be warm can reduce accuracy and increase sycophancy , journal =. 2026 , doi =
2026
-
[2]
2025 , howpublished =
Sycophancy in. 2025 , howpublished =
2025
-
[3]
2025 , howpublished =
Kuznia, Sara and Ortega, Natalia and Valle, Brisa , title =. 2025 , howpublished =
2025
-
[4]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Xiangyu Qi and Yi Zeng and Tinghao Xie and Pin-Yu Chen and Ruoxi Jia and Prateek Mittal and Peter Henderson , title =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[5]
2024 , eprint =
Xiaoqun Liu and Jiacheng Liang and Muchao Ye and Zhaohan Xi , title =. 2024 , eprint =
2024
-
[6]
Layer-Aware Representation Filtering: Purifying Finetuning Data to Preserve
Li, Hao and Li, Lijun and Lu, Zhenghao and Wei, Xianyi and Li, Rui and Shao, Jing and Sha, Lei , booktitle =. Layer-Aware Representation Filtering: Purifying Finetuning Data to Preserve. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.406 , url =
-
[7]
The Twelfth International Conference on Learning Representations , year =
Towards Understanding Sycophancy in Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[8]
Perez, Ethan and Ringer, Sam and Lukosiute, Kamile and Nguyen, Karina and Chen, Edwin and Heiner, Scott and Pettit, Craig and Olsson, Catherine and Kundu, Sandipan and Kadavath, Saurav and Jones, Andy and Chen, Anna and Mann, Benjamin and Israel, Brian and Seethor, Bryan and McKinnon, Cameron and Olah, Christopher and Yan, Da and Amodei, Daniela and Amode...
-
[9]
Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset
Rashkin, Hannah and Smith, Eric Michael and Li, Margaret and Boureau, Y-Lan. Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1534
-
[10]
Chen, Yirong and Xing, Xiaofen and Lin, Jingkai and Zheng, Huimin and Wang, Zhenyu and Liu, Qi and Xu, Xiangmin. S oul C hat: Improving LLM s' Empathy, Listening, and Comfort Abilities through Fine-tuning with Multi-turn Empathy Conversations. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.83
-
[11]
2025 , eprint =
Run Chen and Jun Shin and Julia Hirschberg , title =. 2025 , eprint =
2025
-
[12]
Mitigating Toxic Degeneration with Empathetic Data: Exploring the Relationship Between Toxicity and Empathy , author =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , month = jul, year =. doi:10.18653/v1/2022.naacl-main.363 , url =
-
[13]
2025 , eprint =
Yixuan Tang and Yi Yang and Ahmed Abbasi , title =. 2025 , eprint =
2025
-
[14]
Costa and Robert R
Paul T. Costa and Robert R. McCrae , title =
-
[15]
Journal of Personality , volume =
Jensen-Campbell, Lauri A and Graziano, William G , title =. Journal of Personality , volume =. 2001 , doi =
2001
-
[16]
2024 , address =
Han, Ji-Eun and Koh, Jun-Seok and Seo, Hyeon-Tae and Chang, Du-Seong and Sohn, Kyung-Ah , booktitle =. 2024 , address =
2024
-
[17]
Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics , month = jun, year =
Mairesse, Fran. Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics , month = jun, year =
-
[18]
Le , title =
Jerry Wei and Da Huang and Yifeng Lu and Denny Zhou and Quoc V. Le , title =. 2023 , eprint =
2023
-
[19]
Proceedings of the 41st International Conference on Machine Learning (ICML) , series =
Kiho Park and Yo Joong Choe and Victor Veitch , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , series =. 2024 , publisher =
2024
-
[20]
Zico Kolter and Matt Fredrikson , title =
Andy Zou and Zifan Wang and Nicholas Carlini and Milad Nasr and J. Zico Kolter and Matt Fredrikson , title =. 2023 , eprint =
2023
-
[21]
Byun and Zifan Wang and Alex Mallen and Steven Basart and Sanmi Koyejo and Dawn Song and Matt Fredrikson and J
Andy Zou and Long Phan and Sarah Chen and James Campbell and Phillip Guo and Richard Ren and Alexander Pan and Xuwang Yin and Mantas Mazeika and Ann-Kathrin Dombrowski and Shashwat Goel and Nathaniel Li and Michael J. Byun and Zifan Wang and Alex Mallen and Steven Basart and Sanmi Koyejo and Dawn Song and Matt Fredrikson and J. Zico Kolter and Dan Hendryc...
2023
-
[22]
The Thirteenth International Conference on Learning Representations , year =
Shen Li and Liuyi Yao and Lan Zhang and Yaliang Li , title =. The Thirteenth International Conference on Learning Representations , year =
-
[23]
2026 , eprint =
Sadia Asif and Mohammad Mohammadi Amiri , title =. 2026 , eprint =
2026
-
[24]
Dick and Hidenori Tanaka and Edward Grefenstette and Tim Rockt
Samyak Jain and Robert Kirk and Ekdeep Singh Lubana and Robert P. Dick and Hidenori Tanaka and Edward Grefenstette and Tim Rockt. Mechanistically Analyzing the Effects of Fine-Tuning on Procedurally Defined Tasks , year =. 2311.12786 , archivePrefix =
-
[25]
Student-Teacher Prompting for Red Teaming to Improve Guardrails , author =. Proceedings of the ART of Safety: Workshop on Adversarial Testing and Red-Teaming for Generative AI , month = nov, year =. doi:10.18653/v1/2023.artofsafety-1.2 , url =
-
[26]
International Journal of Mental Health Nursing , year =
Price, Owen and Baker, John , title =. International Journal of Mental Health Nursing , year =
-
[27]
and Berlin, Jon S
Richmond, Janet S. and Berlin, Jon S. and Fishkind, Avrim B. and Holloman, Garland H. and Zeller, Scott L. and Wilson, Michael P. and Rifai, Muhamad Aly and Ng, Anthony T. , title =. Western Journal of Emergency Medicine , year =
-
[28]
and Rollnick, Stephen , title =
Miller, William R. and Rollnick, Stephen , title =
-
[29]
Towards Emotional Support Dialog Systems , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month = aug, pages =. 2021 , address =. doi:10.18653/v1/2021.acl-long.269 , url =
-
[30]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[31]
Constitutional AI: Harmlessness from AI Feedback
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and DasSarma, Nova and Drain, Dawn and Fort, Stanislav and Ganguli, Deep and Henighan, Tom and others , year =. Constitutional. 2212.08073 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
2024 , publisher =
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Mesnard, Thomas and Ferret, Johan and Lu, Kellie Ren and Bishop, Colton and Hall, Ethan and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , booktitle =. 2024 , publisher =
2024
-
[33]
Proceedings of the 41st International Conference on Machine Learning , series =
Self-Rewarding Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[34]
Derail Yourself: Multi-turn
Ren, Qibing and Li, Hao and Liu, Dongrui and Xie, Zhanxu and Lu, Xiaoya and Qiao, Yu and Sha, Lei and Yan, Junchi and Ma, Lizhuang and Shao, Jing , booktitle =. Derail Yourself: Multi-turn
-
[35]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
MentalChat16K: A Benchmark Dataset for Conversational Mental Health Assistance , author =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2025 , doi =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.