SAMoR: Motion Modelling for Articulated Objects of Any Skeleton and Topology
Pith reviewed 2026-07-03 15:25 UTC · model grok-4.3
The pith
Motion of any skeleton can be encoded with a fixed set of eight shared part tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
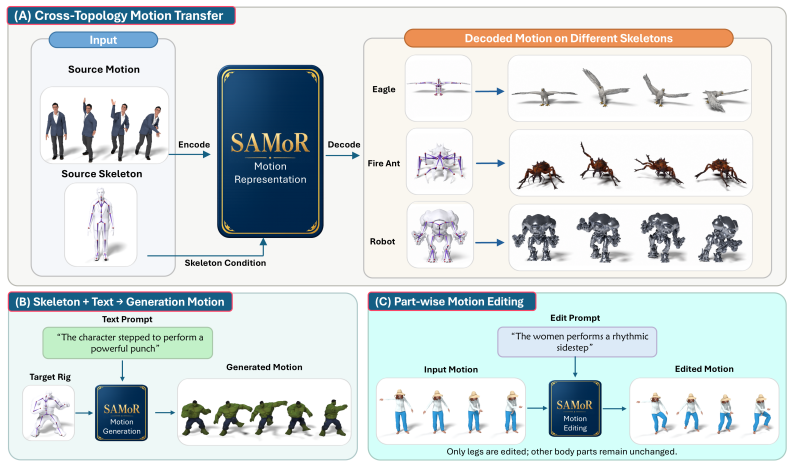
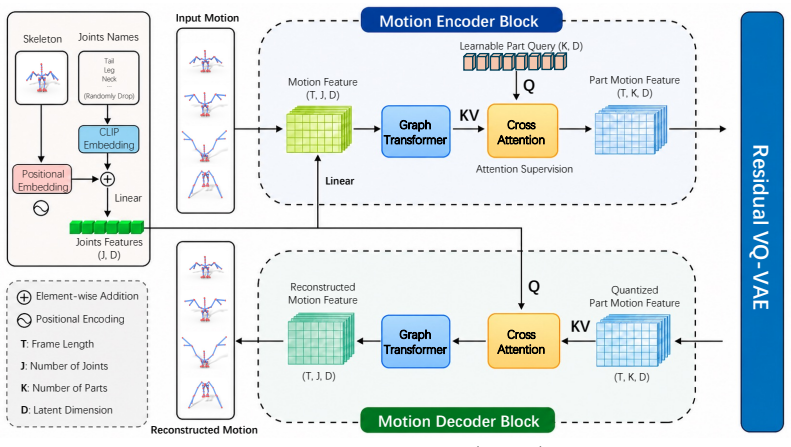
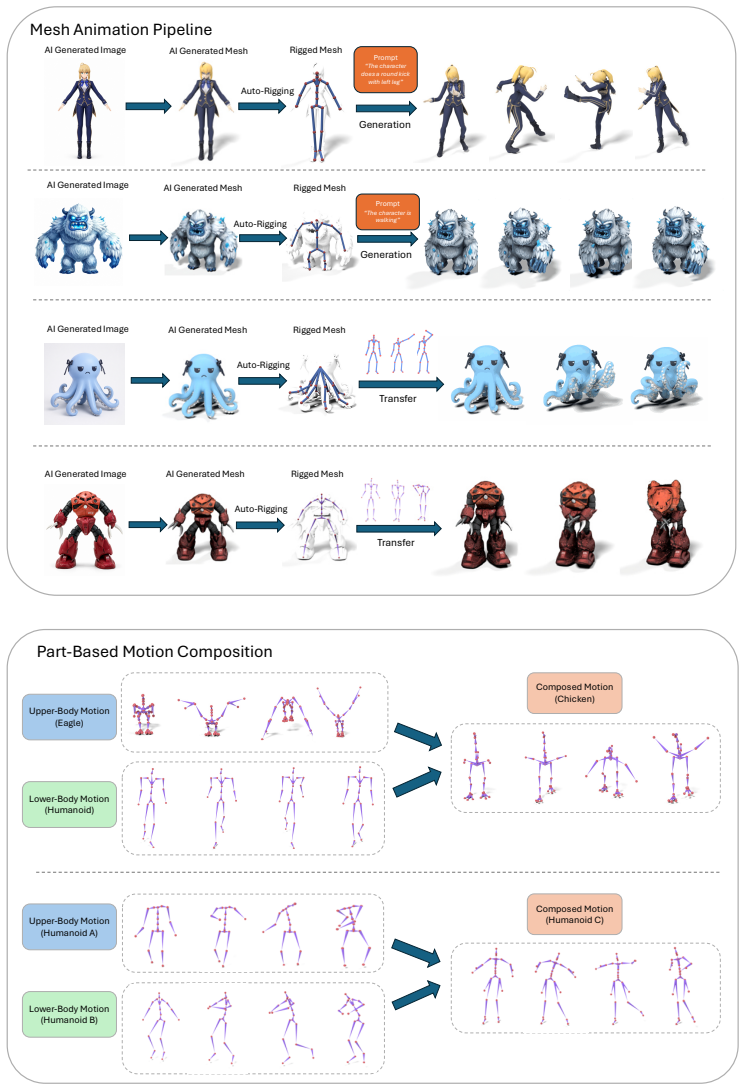
SAMoR encodes each motion segment as a small fixed number (K=8) of part tokens shared across arbitrary skeletons. A graph-transformer encoder consumes per-joint motion features, kinematic graph structure, and joint-name embeddings, then compresses them into part-level tokens via cross-attention pooling and residual vector quantization, yielding a discrete motion codebook shared across rigs. A topology-agnostic attention supervision loss with joint-name dropout prevents the part queries from collapsing, enabling accurate reconstruction and cross-topology transfer on held-out characters with unseen skeletons.
What carries the argument
Fixed set of K=8 part tokens produced by cross-attention pooling over graph-transformer features followed by residual vector quantization, kept distinct by a topology-agnostic attention supervision loss.
If this is right
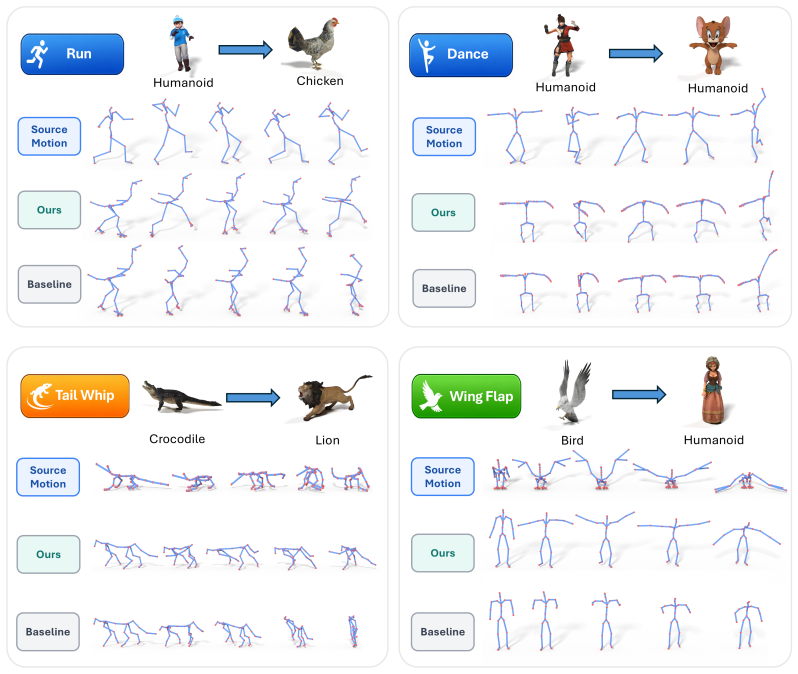
- Cross-topology reconstruction reaches 2.75 times 10 to the minus 2 normalized MPJPE, 5.8 times lower than the best adapted variable-joint tokenizer.
- The same codebook supports text-conditioned generation and part-wise editing through a MaskGIT token generator.
- Performance on HumanML3D remains competitive with models built for one fixed skeleton.
- The representation works on a heterogeneous corpus that mixes human motion capture, zoo animals, and animated 3D assets.
Where Pith is reading between the lines
- A single motion vocabulary could replace manual retargeting when animating characters from different sources.
- The part-token approach may transfer to other tree-structured systems such as robotic manipulators or molecular backbones.
- Joint-name dropout already suggests the model can operate when semantic labels are absent or noisy.
Load-bearing premise
Motion patterns of functional joint groups remain consistent across species even when the exact joint count and connectivity differ.
What would settle it
Reconstruction error measured on a new articulated object whose functional groups have no motion correspondence with the training set, such as an octopus or a wheeled robot, and checking whether the error stays near the reported 2.75 times 10 to the minus 2.
Figures
read the original abstract
Modeling motion for articulated objects of arbitrary skeleton topology remains difficult: existing motion generators target a fixed human skeleton, and prior adaptations either fail to share a vocabulary across rigs or discard motion detail through global pooling. Our key observation is that while joint-level motion does not correspond cleanly across species, motion of functional joint groups does: a human arm, a wolf foreleg, and a bird wing share motion structure despite differing joint counts and connectivity, a correspondence that joint names (e.g., "forearm", "wing_L1") partially expose even when topology does not. We introduce SAMoR (Skeleton-Aware Motion Representation for Articulated Objects), a cross-topology motion representation that encodes each motion segment as a small fixed number ($K=8$) of part tokens shared across arbitrary skeletons. A graph-transformer encoder consumes per-joint motion features, kinematic graph structure, and joint-name embeddings, then compresses them into part-level tokens via cross-attention pooling and residual vector quantization, yielding a discrete motion codebook shared across rigs. To keep the part queries from collapsing into redundant global representations, we introduce a topology-agnostic attention supervision loss, with joint-name dropout to reduce over-reliance on text labels. We curate a heterogeneous corpus from HumanML3D, Truebones Zoo, and animated Objaverse-XL assets, and evaluate SAMoR on held-out characters with unseen skeletons. It supports accurate reconstruction and cross-topology transfer, and enables text-conditioned generation and part-wise editing via a MaskGIT token generator. SAMoR reaches $2.75 \times 10^{-2}$ normalized MPJPE on cross-topology reconstruction, $5.8\times$ below the strongest adapted variable-$J$ tokenizer baseline, while remaining competitive with fixed-skeleton specialists on HumanML3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAMoR, a cross-topology motion representation that encodes arbitrary-skeleton motions into a fixed set of K=8 part tokens via a graph-transformer encoder consuming per-joint features, kinematic structure, and joint-name embeddings, followed by cross-attention pooling and residual vector quantization to produce a shared discrete codebook. A topology-agnostic attention supervision loss with joint-name dropout is added to avoid collapse or label leakage. The method is evaluated on a curated corpus from HumanML3D, Truebones Zoo, and Objaverse-XL assets using held-out characters with unseen skeletons, claiming 2.75×10^{-2} normalized MPJPE on cross-topology reconstruction (5.8× below the strongest adapted variable-J baseline) while remaining competitive with fixed-skeleton models on HumanML3D, and supporting text-conditioned generation and part-wise editing via a MaskGIT generator.
Significance. If the cross-topology transfer performance and the functional-group correspondence hold under rigorous scrutiny, the work would address a clear gap in motion modeling by enabling a shared vocabulary across rigs of differing topology, with potential impact on animation, robotics, and generative models for non-human articulated objects.
major comments (2)
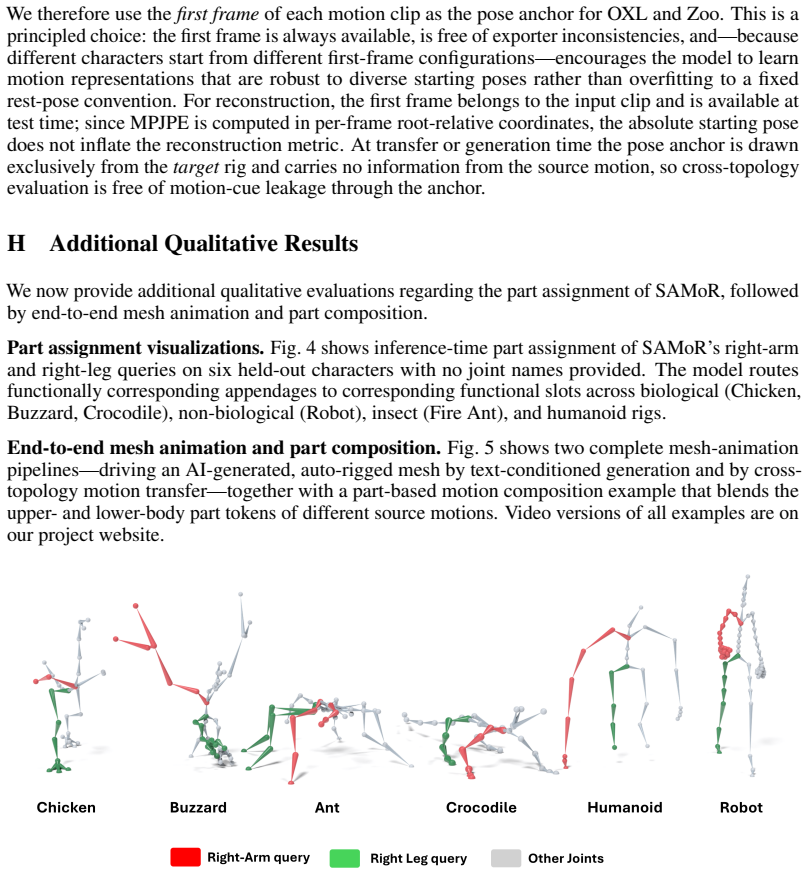
- [Abstract] Abstract and evaluation section: the central claim that functional joint-group motions (e.g., arm/foreleg/wing) produce sufficiently similar statistics to share the same 8-token codebook is load-bearing for the shared vocabulary, yet the only quantitative support is the held-out reconstruction MPJPE; no diagnostic (token activation histograms per species, part-token cosine similarity on matched actions, or ablation removing joint-name embeddings) is reported to confirm functional rather than corpus-specific alignment.
- [Methods] Methods description of the encoder and loss: the topology-agnostic attention supervision loss is introduced to keep part queries from collapsing into global representations, but without an explicit ablation on the contribution of this loss versus the name embeddings (or name dropout rate), it remains unclear whether the reported cross-topology gain depends on the supervision or on the curated data distribution.
minor comments (1)
- [Abstract] The abstract states quantitative improvements but does not specify the exact data splits, baseline re-implementations, or normalization details for the 5.8× factor; these should be clarified in the main text or supplementary material for reproducibility.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We provide point-by-point responses to the major comments and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation section: the central claim that functional joint-group motions (e.g., arm/foreleg/wing) produce sufficiently similar statistics to share the same 8-token codebook is load-bearing for the shared vocabulary, yet the only quantitative support is the held-out reconstruction MPJPE; no diagnostic (token activation histograms per species, part-token cosine similarity on matched actions, or ablation removing joint-name embeddings) is reported to confirm functional rather than corpus-specific alignment.
Authors: We agree that additional diagnostics would provide stronger support for the functional correspondence claim. The held-out cross-topology reconstruction MPJPE demonstrates that the part tokens generalize across unseen skeletons, which is consistent with functional alignment rather than corpus-specific patterns. To further substantiate this, we will add token activation histograms per species, part-token cosine similarities on matched actions, and an ablation study removing the joint-name embeddings in the revised version of the manuscript. revision: yes
-
Referee: [Methods] Methods description of the encoder and loss: the topology-agnostic attention supervision loss is introduced to keep part queries from collapsing into global representations, but without an explicit ablation on the contribution of this loss versus the name embeddings (or name dropout rate), it remains unclear whether the reported cross-topology gain depends on the supervision or on the curated data distribution.
Authors: We acknowledge the value of an explicit ablation to isolate the contribution of the attention supervision loss. In the revised manuscript, we will include an ablation study comparing performance with and without the supervision loss, as well as varying the joint-name dropout rate, to clarify its role relative to the name embeddings and the data distribution. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper presents an empirical observation about functional joint-group motion correspondence as motivation for the shared part-token codebook and cross-attention pooling design. This assumption is not derived from or defined in terms of the model's outputs or fitted parameters. Evaluation metrics are computed on held-out characters with unseen skeletons from the curated corpus, providing an independent test set rather than a reconstruction of training inputs. No equations, self-citations, or uniqueness theorems are invoked that reduce the reported reconstruction or transfer performance to quantities defined by construction from the same data. The topology-agnostic attention loss and name dropout are design choices to regularize the model, not tautological steps. The central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of part tokens K
axioms (2)
- domain assumption Motion of functional joint groups corresponds across species and topologies despite differing joint counts and connectivity
- domain assumption Joint-name embeddings supply useful signal that can be regularized via dropout without causing collapse
invented entities (2)
-
part-level tokens
no independent evidence
-
topology-agnostic attention supervision loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kfir Aberman, Peizhuo Li, Dani Lischinski, Olga Sorkine-Hornung, Daniel Cohen-Or, and Baoquan Chen. Skeleton-aware networks for deep motion retargeting.ACM Transactions on Graphics, 39(4):62:1–62:14, 2020
work page 2020
-
[2]
Nikos Athanasiou, Alpár Ceske, Markos Diomataris, Michael J. Black, and Gül Varol. Mo- tionFix: Text-driven 3d human motion editing. InSIGGRAPH Asia 2024 Conference Papers, 2024
work page 2024
-
[3]
Sinc: Spatial composition of 3d human motions for simultaneous action generation
Nikos Athanasiou, Mathis Petrovich, Michael J Black, and Gül Varol. Sinc: Spatial composition of 3d human motions for simultaneous action generation. InICCV, pages 9984–9995, 2023
work page 2023
-
[4]
Automatic rigging and animation of 3d characters.ACM TOG, 26(3):72–es, 2007
Ilya Baran and Jovan Popovi´c. Automatic rigging and animation of 3d characters.ACM TOG, 26(3):72–es, 2007
work page 2007
-
[5]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InCVPR, pages 11315–11325, 2022
work page 2022
-
[6]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InCVPR, pages 18000–18010, 2023
work page 2023
-
[7]
Objaverse-xl: A universe of 10m+ 3d objects.NeurIPS, 36:35799–35813, 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.NeurIPS, 36:35799–35813, 2023
work page 2023
-
[8]
Anymate: A dataset and baselines for learning 3d object rigging
Yufan Deng, Yuhao Zhang, Chen Geng, Shangzhe Wu, and Jiajun Wu. Anymate: A dataset and baselines for learning 3d object rigging. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Papers, pages 1–10, 2025
work page 2025
-
[9]
Anytop: Character animation diffusion with any topology
Inbar Gat, Sigal Raab, Guy Tevet, Yuval Reshef, Amit Haim Bermano, and Daniel Cohen-Or. Anytop: Character animation diffusion with any topology. InSIGGRAPH, pages 1–10, 2025
work page 2025
-
[10]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Snapmogen: Human motion generation from expressive texts
Chuan Guo, Inwoo Hwang, Jian Wang, and Bing Zhou. Snapmogen: Human motion generation from expressive texts. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[12]
Momask: Generative masked modeling of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked modeling of 3d human motions. InCVPR, pages 1900–1910, 2024
work page 1900
-
[13]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InCVPR, pages 5152–5161, 2022
work page 2022
-
[14]
Nrdf: Neural riemannian distance fields for learning articulated pose priors
Yannan He, Garvita Tiwari, Tolga Birdal, Jan Eric Lenssen, and Gerard Pons-Moll. Nrdf: Neural riemannian distance fields for learning articulated pose priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1661–1671, 2024. 10
work page 2024
-
[15]
Molingo: Motion–language alignment for text-to-human motion generation
Yannan He, Garvita Tiwari, Xiaohan Zhang, Pankaj Bora, Tolga Birdal, Jan Eric Lenssen, and Gerard Pons-Moll. Molingo: Motion–language alignment for text-to-human motion generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
-
[16]
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2022
work page 2021
-
[17]
Farm3d: Learning articulated 3d animals by distilling 2d diffusion
Tomas Jakab, Ruining Li, Shangzhe Wu, Christian Rupprecht, and Andrea Vedaldi. Farm3d: Learning articulated 3d animals by distilling 2d diffusion. In2024 International Conference on 3D Vision (3DV), pages 852–861. IEEE, 2024
work page 2024
-
[18]
Motiongpt: Human motion as a foreign language.NeurIPS, 36:20067–20079, 2023
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.NeurIPS, 36:20067–20079, 2023
work page 2023
-
[19]
WalkTheDog: Cross- morphology motion alignment via phase manifolds
Peizhuo Li, Sebastian Starke, Yuting Ye, and Olga Sorkine-Hornung. WalkTheDog: Cross- morphology motion alignment via phase manifolds. InACM SIGGRAPH 2024 Conference Papers, 2024
work page 2024
-
[20]
Learning the 3d fauna of the web
Zizhang Li, Dor Litvak, Ruining Li, Yunzhi Zhang, Tomas Jakab, Christian Rupprecht, Shangzhe Wu, Andrea Vedaldi, and Jiajun Wu. Learning the 3d fauna of the web. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9752–9762, 2024
work page 2024
-
[21]
Di Liu, Anastasis Stathopoulos, Qilong Zhangli, Yunhe Gao, and Dimitris Metaxas. Lepard: Learning explicit part discovery for 3d articulated shape reconstruction.Advances in Neural Information Processing Systems, 36:54187–54198, 2023
work page 2023
-
[22]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1–248:16, October 2015
work page 2015
-
[23]
Posed-flow: Versatile and guided flow matching model of human pose
Jebastin Nadar, Simone Foti, and Tolga Birdal. Posed-flow: Versatile and guided flow matching model of human pose. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21165–21175, 2026
work page 2026
-
[24]
Tmr: Text-to-motion retrieval using con- trastive 3d human motion synthesis
Mathis Petrovich, Michael J Black, and Gül Varol. Tmr: Text-to-motion retrieval using con- trastive 3d human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9488–9497, 2023
work page 2023
-
[25]
Mmm: Generative masked motion model
Ekkasit Pinyoanuntapong, Pu Wang, Minwoo Lee, and Chen Chen. Mmm: Generative masked motion model. InCVPR, pages 1546–1555, 2024
work page 2024
-
[26]
The kit motion-language dataset
Matthias Plappert, Christian Mandery, and Tamim Asfour. The kit motion-language dataset. Big data, 4(4):236–252, 2016
work page 2016
-
[27]
Single motion diffusion.arXiv preprint arXiv:2302.05905, 2023
Sigal Raab, Inbal Leibovitch, Guy Tevet, Moab Arar, Amit H Bermano, and Daniel Cohen-Or. Single motion diffusion.arXiv preprint arXiv:2302.05905, 2023
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, pages 8748–8763. PmLR, 2021
work page 2021
-
[29]
Humor: 3d human motion model for robust pose estimation
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas J Guibas. Humor: 3d human motion model for robust pose estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 11488–11499, 2021
work page 2021
-
[30]
arXiv preprint arXiv:2508.10898 (2025)
Chaoyue Song, Xiu Li, Fan Yang, Zhongcong Xu, Jiacheng Wei, Fayao Liu, Jiashi Feng, Guosheng Lin, and Jianfeng Zhang. Puppeteer: Rig and animate your 3d models.arXiv preprint arXiv:2508.10898, 2025
-
[31]
Magicarticulate: Make your 3d models articulation-ready
Chaoyue Song, Jianfeng Zhang, Xiu Li, Fan Yang, Yiwen Chen, Zhongcong Xu, Jun Hao Liew, Xiaoyang Guo, Fayao Liu, Jiashi Feng, et al. Magicarticulate: Make your 3d models articulation-ready. InCVPR, pages 15998–16007, 2025. 11
work page 2025
-
[32]
Pony- mation: Learning articulated 3d animal motions from unlabeled online videos
Keqiang Sun, Dor Litvak, Yunzhi Zhang, Hongsheng Li, Jiajun Wu, and Shangzhe Wu. Pony- mation: Learning articulated 3d animal motions from unlabeled online videos. InEuropean Conference on Computer Vision, pages 100–119. Springer, 2024
work page 2024
-
[33]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model.arXiv preprint arXiv:2209.14916, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [34]
-
[35]
Accessed: 2026-05-03
work page 2026
-
[36]
Neural discrete representation learning.NeurIPS, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.NeurIPS, 30, 2017
work page 2017
-
[37]
Yin Wang, Mu Li, Jiapeng Liu, Zhiying Leng, Frederick WB Li, Ziyao Zhang, and Xiaohui Liang. Fg-t2m++: Llms-augmented fine-grained text driven human motion generation.IJCV, 133(7):4277–4293, 2025
work page 2025
-
[38]
Shangzhe Wu, Tomas Jakab, Christian Rupprecht, and Andrea Vedaldi. Dove: Learn- ing deformable 3d objects by watching videos.International Journal of Computer Vision, 131(10):2623–2634, 2023
work page 2023
-
[39]
Lixing Xiao, Shunlin Lu, Huaijin Pi, Ke Fan, Liang Pan, Yueer Zhou, Ziyong Feng, Xiaowei Zhou, Sida Peng, and Jingbo Wang. Motionstreamer: Streaming motion generation via diffusion- based autoregressive model in causal latent space. InICCV, pages 10086–10096, 2025
work page 2025
-
[40]
Necromancer: Breathing life into skeletons via bvh animation.arXiv preprint arXiv:2602.06548, 2026
Mingxi Xu, Qi Wang, Zhengyu Wen, Phong Dao Thien, Zhengyu Li, Ning Zhang, Xiaoyu He, Wei Zhao, Kehong Gong, and Mingyuan Zhang. Necromancer: Breathing life into skeletons via bvh animation.arXiv preprint arXiv:2602.06548, 2026
-
[41]
Rignet: Neural rigging for articulated characters.arXiv preprint arXiv:2005.00559, 2020
Zhan Xu, Yang Zhou, Evangelos Kalogerakis, Chris Landreth, and Karan Singh. Rignet: Neural rigging for articulated characters.arXiv preprint arXiv:2005.00559, 2020
-
[42]
Chun-Han Yao, Wei-Chih Hung, Yuanzhen Li, Michael Rubinstein, Ming-Hsuan Yang, and Varun Jampani. Lassie: Learning articulated shapes from sparse image ensemble via 3d part discovery.Advances in Neural Information Processing Systems, 35:15296–15308, 2022
work page 2022
-
[43]
Geometric neural distance fields for learning human motion priors
Zhengdi Yu, Simone Foti, Linguang Zhang, Amy Zhao, Cem Keskin, Stefanos Zafeiriou, Tolga Birdal, et al. Geometric neural distance fields for learning human motion priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2232–2242, 2026
work page 2026
-
[44]
Mogents: Motion generation based on spatial-temporal joint modeling
Weihao Yuan, Yisheng He, Weichao Shen, Yuan Dong, Xiaodong Gu, Zilong Dong, Liefeng Bo, and Qixing Huang. Mogents: Motion generation based on spatial-temporal joint modeling. NeurIPS, 37:130739–130763, 2024
work page 2024
-
[45]
Generating human motion from textual descriptions with discrete representations
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Yong Zhang, Hongwei Zhao, Hongtao Lu, Xi Shen, and Ying Shan. Generating human motion from textual descriptions with discrete representations. InCVPR, pages 14730–14740, 2023
work page 2023
-
[46]
Attt2m: Text-driven human motion generation with multi-perspective attention mechanism
Chongyang Zhong, Lei Hu, Zihao Zhang, and Shihong Xia. Attt2m: Text-driven human motion generation with multi-perspective attention mechanism. InICCV, pages 509–519, 2023
work page 2023
-
[47]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InCVPR, pages 5745–5753, 2019
work page 2019
-
[48]
Parco: Part-coordinating text-to-motion synthesis
Qiran Zou, Shangyuan Yuan, Shian Du, Yu Wang, Chang Liu, Yi Xu, Jie Chen, and Xiangyang Ji. Parco: Part-coordinating text-to-motion synthesis. InECCV, pages 126–143. Springer, 2024. 12 Appendix A Implementation Details A.1 SAMoR Stage 1: Part VQ-V AE Architecture hyperparameters.Table 4 summarises the key architectural parameters. The encoder and decoder ...
work page 2024
-
[49]
Rigging validity.Characters whose skeleton root bone lies outside the mesh bounding box are discarded, along with a manually curated exclusion list of visually confirmed broken rigs
-
[50]
Inside-mesh filter.We voxelize the mesh at 643 resolution and discard any character for which more than 50% of skeleton joints fall outside the mesh volume, indicating a misaligned or broken rig
-
[51]
Near-static filter.Characters whose maximum per-joint rotation standard deviation across time falls below a threshold, combined with low joint displacement, are removed as effectively pose- only assets
-
[52]
5.Joint count.Characters with fewer than 5 or more than 96 joints are excluded
Repetition filter.Pairs of characters sharing identical joint counts, identical parent connections, and near-identical joint positions on five randomly sampled frames are treated as duplicates; all but one are discarded. 5.Joint count.Characters with fewer than 5 or more than 96 joints are excluded. 6.Short clip filter.Motion clips shorter than 16 frames ...
-
[53]
The character does a round kick with left leg
Out-of-bounds filter.Before training, clips in which any joint position exceeds 3.0 normalised units from the origin after shared normalisation are removed, as these indicate residual normalisa- tion failures. After curation, the remaining characters are split at the character level (zero character overlap between train and val). OXL character type distri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.