TraceLab: Characterizing Coding Agent Workloads for LLM Serving
Pith reviewed 2026-07-01 06:48 UTC · model grok-4.3
The pith
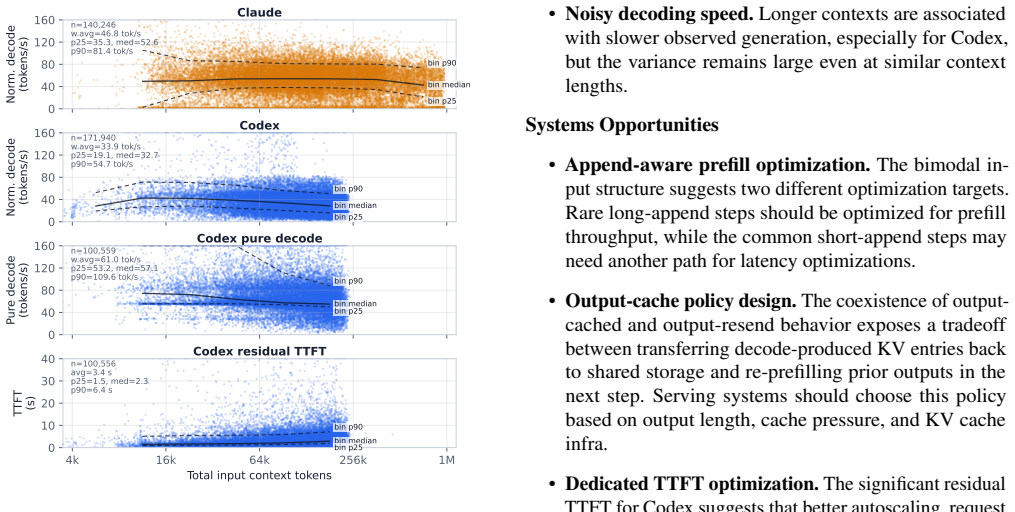
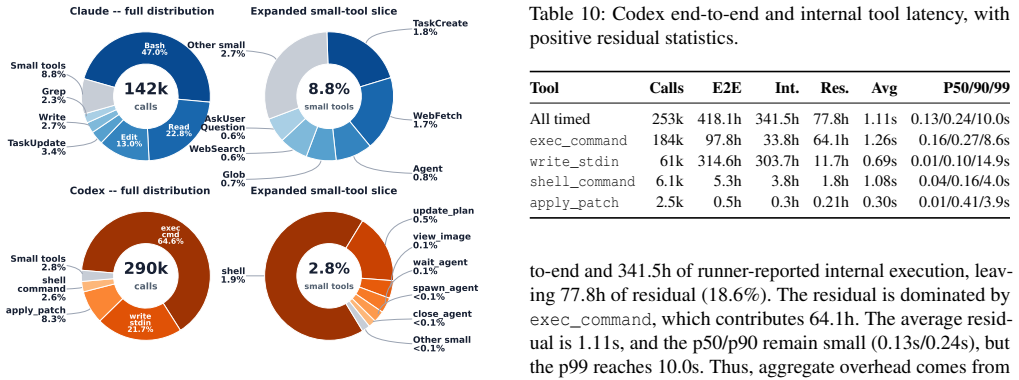
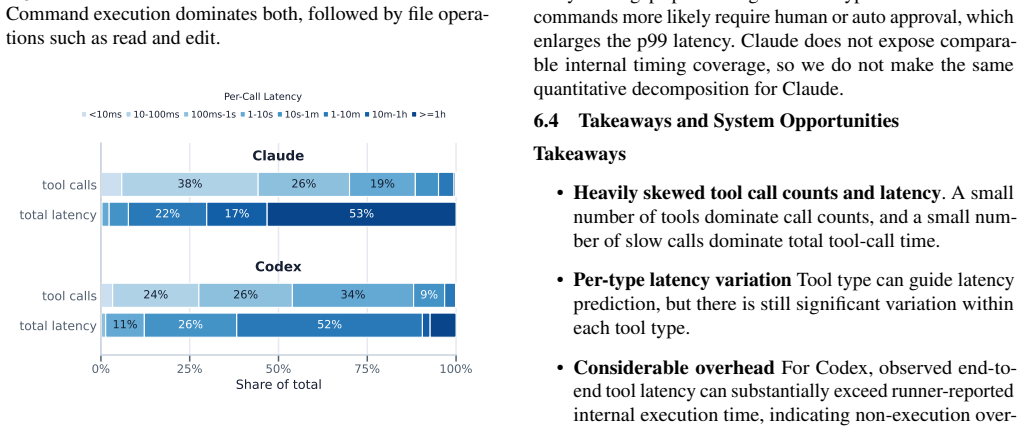
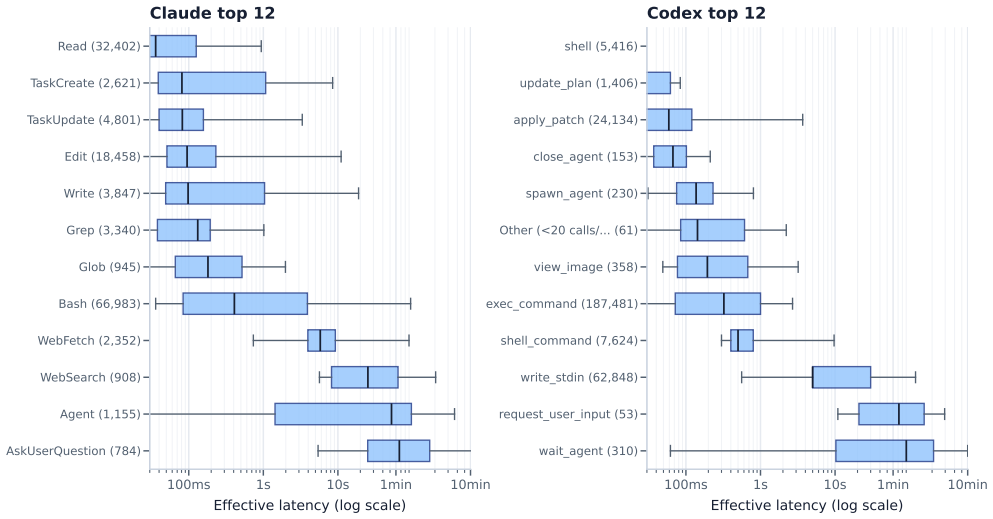
Analysis of real coding-agent sessions shows long autonomous loops, long contexts with short outputs, diverse and heavily-tailed tool calls, and high but imperfect prefix cache hit rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors collect and release a trace of roughly 4,300 coding-agent sessions with about 350,000 LLM steps and 430,000 tool calls. Their analysis shows that coding-agent workloads feature long autonomous loops, long contexts with short outputs, diverse and heavily-tailed tool calls, and high but imperfect prefix cache hit rates. These findings point to concrete opportunities for optimizing serving, including lower-overhead tool calling, append-length-aware prefill, semantic-aware tool-latency prediction, and improved KV-cache management around human-paced gaps.
What carries the argument
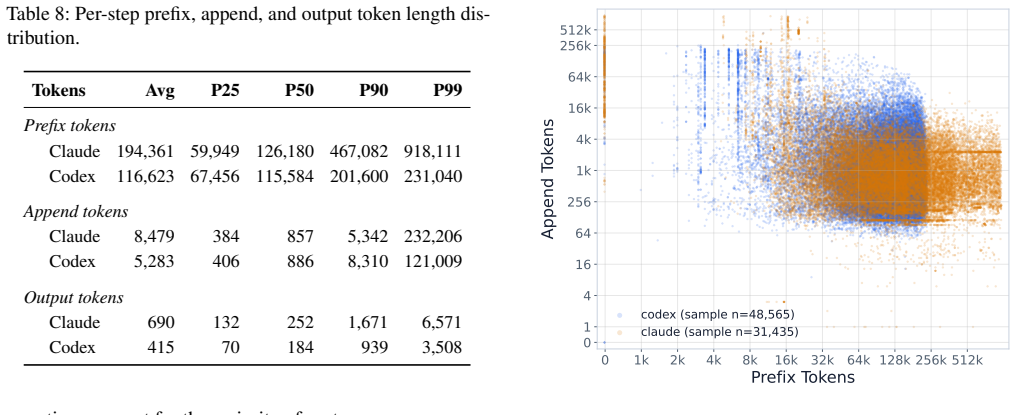
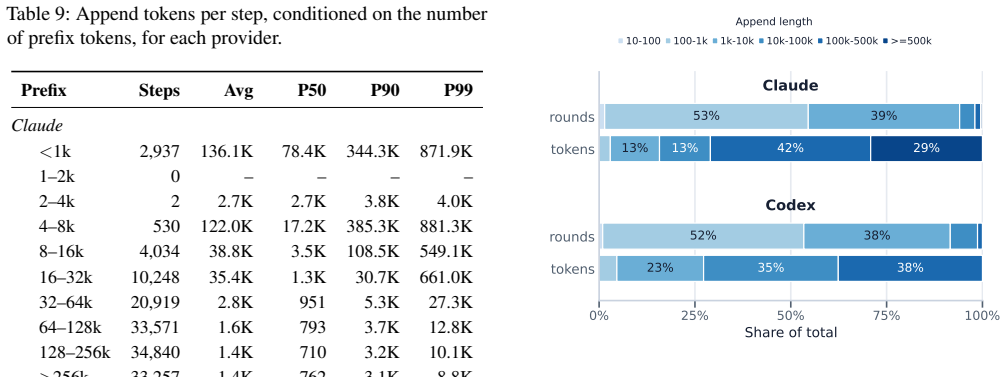
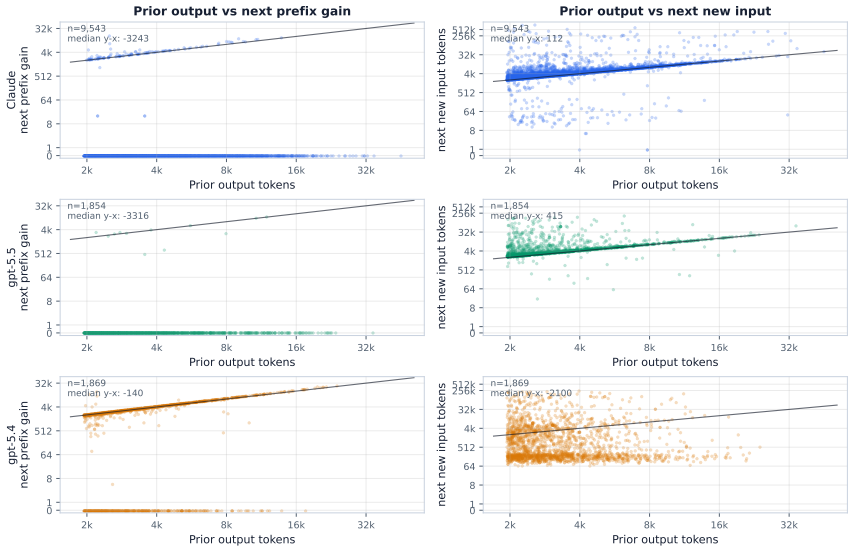
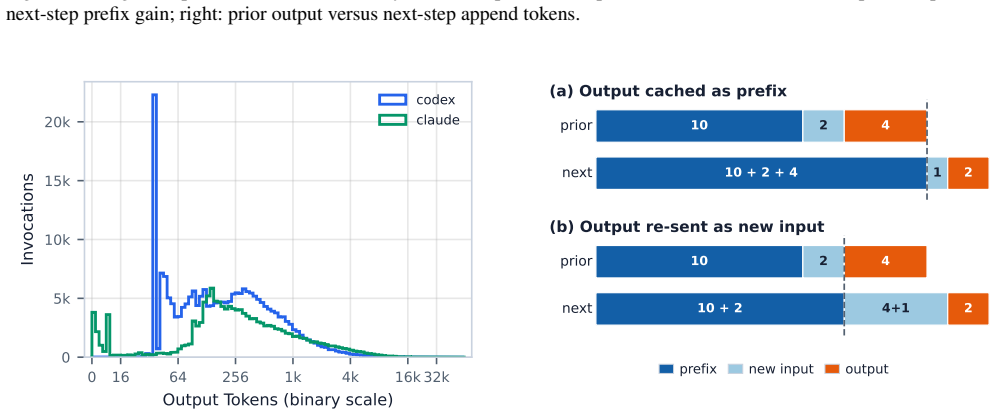
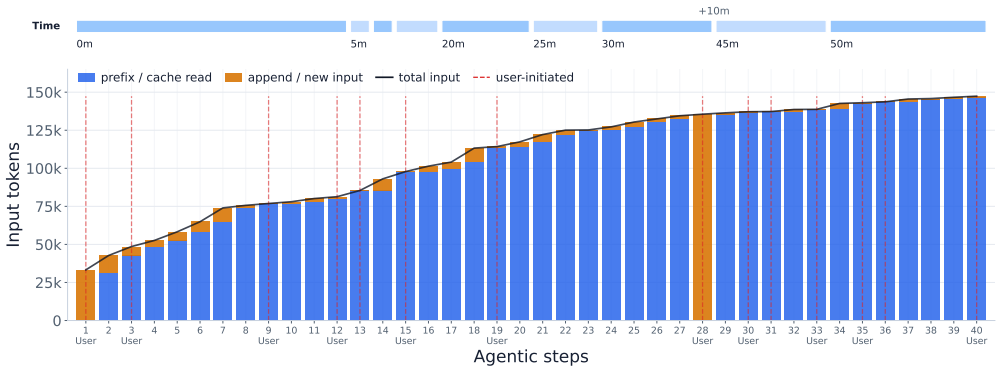
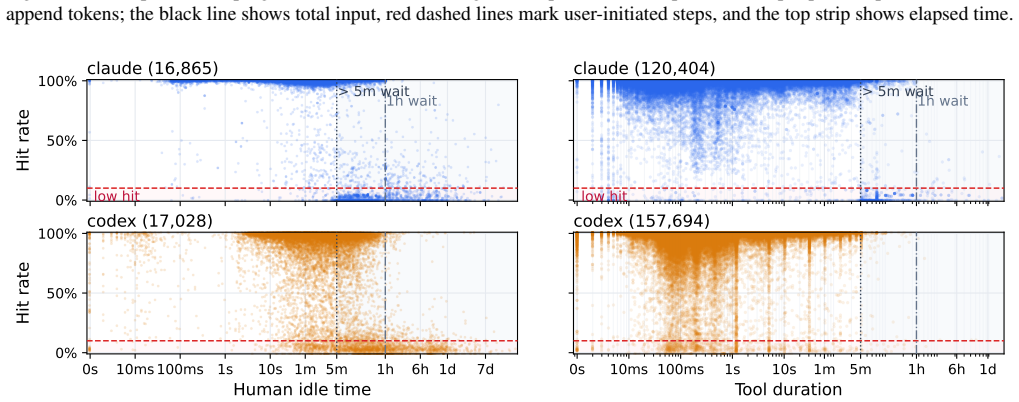
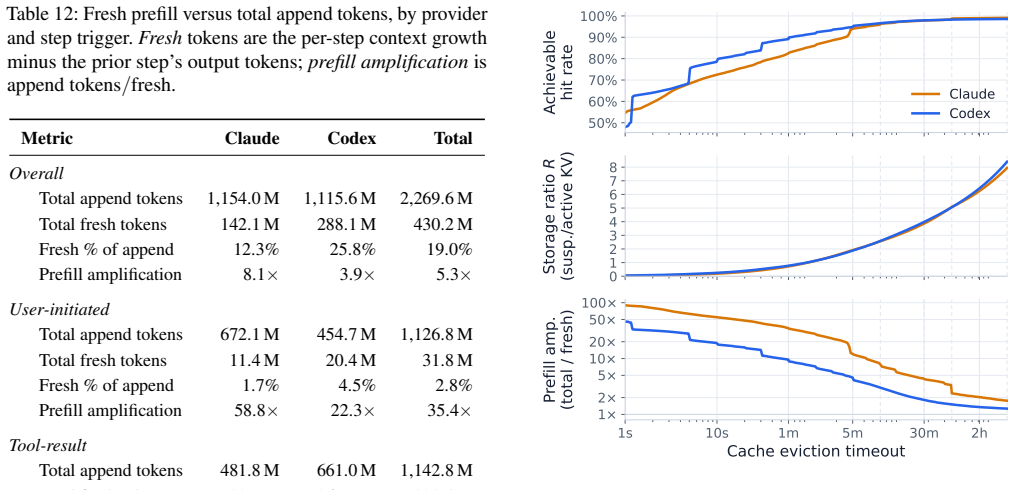
The collected trace of coding-agent sessions, analyzed for session lengths, context and output sizes, tool call distributions, and prefix cache hit rates.
If this is right
- Lower-overhead tool calling can be implemented to handle diverse and heavily-tailed tool use.
- Append-length-aware prefill strategies can be used for workloads with long contexts.
- Semantic-aware tool-latency prediction can improve scheduling based on tool diversity.
- KV-cache management can be improved to account for human-paced gaps between steps.
Where Pith is reading between the lines
- Similar traces from other users or agents could validate or refine these workload patterns for more general serving optimizations.
- Model providers might design architectures that better support long autonomous loops in coding tasks.
- Serving frameworks could incorporate workload-specific predictors derived from such traces to reduce latency.
- Public release of the trace enables community development of benchmarks tailored to agentic coding workloads.
Load-bearing premise
The trace from the authors' own day-to-day use is representative of broader coding-agent workloads across multiple agents and model families.
What would settle it
A new trace collected from different coding agents or a wider user base that exhibits substantially shorter loops, longer outputs, less diverse tool calls, or near-perfect cache hit rates would contradict the central characterization.
Figures
read the original abstract
Coding agents are rapidly becoming a major application of agentic LLMs, but serving them efficiently remains challenging. Progress on this challenge requires understanding real workload patterns, yet the data needed for such analysis is largely absent. Existing public traces and benchmarks do not capture real, day-to-day coding-agent usage across multiple agents and model families for serving-system analysis. To help fill this gap, we collect and release a trace of roughly 4,300 coding-agent sessions, containing about 350,000 LLM steps and 430,000 tool calls from our own day-to-day use of Claude Code and Codex. Our analysis shows that coding-agent workloads feature long autonomous loops, long contexts with short outputs, diverse and heavily-tailed tool calls, and high but imperfect prefix cache hit rates. These findings point to concrete opportunities for optimizing serving, including lower-overhead tool calling, append-length-aware prefill, semantic-aware tool-latency prediction, and improved KV-cache management around human-paced gaps. We release the dataset, trace collection pipeline, and analysis code at https://github.com/uw-syfi/TraceLab.git the project website is https://tracelab.cs.washington.edu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper collects and publicly releases TraceLab, a trace of ~4,300 coding-agent sessions (~350k LLM steps, ~430k tool calls) gathered from the authors' internal day-to-day use of Claude Code and Codex. Analysis of the trace identifies workload features including long autonomous loops, long contexts paired with short outputs, diverse and heavily-tailed tool calls, and high but imperfect prefix cache hit rates. These observations are used to suggest concrete LLM serving optimizations such as lower-overhead tool calling, append-length-aware prefill, and improved KV-cache management around human-paced gaps. The dataset, collection pipeline, and analysis code are released.
Significance. The public release of the trace, pipeline, and code is a clear strength that enables community follow-on work on agentic LLM serving. If the reported patterns hold beyond the collected trace, they supply actionable guidance for system design in an emerging workload class.
major comments (2)
- [Abstract] Abstract: the claim that 'coding-agent workloads feature long autonomous loops, long contexts with short outputs, diverse and heavily-tailed tool calls, and high but imperfect prefix cache hit rates' is presented as a general characterization, yet the trace originates exclusively from internal use of two specific agents (Claude Code, Codex) with no cross-agent, cross-organization, or cross-model-family comparison or external validation set; this assumption is load-bearing for treating the statistics as representative.
- [§3 and §4] §3 (Trace Collection) and §4 (Analysis): no methodology details, statistical methods, bias controls, or validation steps are supplied for the 4,300-session collection, so it is impossible to determine whether the reported patterns (e.g., prefix cache hit rates, tool-call distributions) are robustly supported or sensitive to selection bias from authors' usage patterns.
minor comments (2)
- [Abstract] Abstract: the session count is given as 'roughly 4,300' while tool calls are stated as 430,000; clarify whether these figures are exact or rounded and ensure consistency with the released dataset.
- [Release statement] The GitHub link and project website are provided but the manuscript does not include a data dictionary or schema description for the released trace, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on generalizability and methodological transparency. We address each point below and will revise the manuscript to clarify scope and expand details where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'coding-agent workloads feature long autonomous loops, long contexts with short outputs, diverse and heavily-tailed tool calls, and high but imperfect prefix cache hit rates' is presented as a general characterization, yet the trace originates exclusively from internal use of two specific agents (Claude Code, Codex) with no cross-agent, cross-organization, or cross-model-family comparison or external validation set; this assumption is load-bearing for treating the statistics as representative.
Authors: We agree the abstract phrasing risks implying broader representativeness than the data supports. The trace is explicitly from internal day-to-day use of Claude Code and Codex, as stated in the manuscript. In revision we will rephrase the abstract to state that these workload features are observed in the released TraceLab trace from these two agents, and add a clause noting the absence of cross-agent or cross-organization validation as a limitation. This preserves the contribution of the public release while accurately bounding the claims. revision: yes
-
Referee: [§3 and §4] §3 (Trace Collection) and §4 (Analysis): no methodology details, statistical methods, bias controls, or validation steps are supplied for the 4,300-session collection, so it is impossible to determine whether the reported patterns (e.g., prefix cache hit rates, tool-call distributions) are robustly supported or sensitive to selection bias from authors' usage patterns.
Authors: We accept that the current text provides insufficient detail on collection and analysis procedures. In the revised version we will expand §3 with a description of the logging mechanism, session filtering criteria, collection period, and any anonymization steps. We will also add an explicit discussion of potential selection bias arising from the authors' internal usage patterns. In §4 we will document the exact statistical procedures used for distributions, cache-hit calculations, and tail analyses. While external validation is not possible with this internal trace, we will frame the release itself as enabling such validation by the community. revision: yes
Circularity Check
No circularity; purely empirical trace collection and observation.
full rationale
The paper collects a trace of 4300 sessions from the authors' internal use of Claude Code and Codex, releases the dataset, and reports observational statistics on session lengths, context sizes, tool-call distributions, and cache hit rates. No equations, fitted parameters, predictions, or derivations exist that could reduce to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The representativeness of the internal trace is an explicit empirical limitation rather than a derived claim. This is a standard data-release paper whose central contribution is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Infercept: Efficient intercept support for augmented large language model inference, 2024
Reyna Abhyankar, Zijian He, Vikranth Srivatsa, Hao Zhang, and Yiying Zhang. Infercept: Efficient intercept support for augmented large language model inference, 2024
2024
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve, 2024
2024
-
[3]
Anthropic acquires bun as claude code reaches $1b milestone
Anthropic. Anthropic acquires bun as claude code reaches $1b milestone. https://www.anthropic.com/news/ anthropic-acquires-bun-as-claude-code-reaches-usd1b-milestone ,
-
[4]
Reached $1B annualized run-rate revenue within ∼6 months of public launch; accessed 2026-06-14
2026
-
[5]
Claude code
Anthropic. Claude code. https://www.anthropic. com/claude-code, 2025. Terminal-based coding agent; accessed 2026-06-21
2025
-
[6]
Claude API pricing
Anthropic. Claude API pricing. https://platform. claude.com/docs/en/about-claude/pricing,
-
[7]
Cursor: The AI code editor
Anysphere. Cursor: The AI code editor. https: //en.wikipedia.org/wiki/Cursor_(company),
-
[8]
Reports 7M+ monthly active users; accessed 2026-06-14
2026
-
[9]
Program synthesis with large language models, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021
2021
-
[10]
τ2-bench: Evaluating conver- sational agents in a dual-control environment, 2025
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ2-bench: Evaluating conver- sational agents in a dual-control environment, 2025
2025
-
[11]
Swe-chat: Coding agent interactions from real users in the wild, 2026
Joachim Baumann, Vishakh Padmakumar, Xiang Li, John Yang, Diyi Yang, and Sanmi Koyejo. Swe-chat: Coding agent interactions from real users in the wild, 2026
2026
-
[12]
Pyramidkv: Dy- namic kv cache compression based on pyramidal infor- mation funneling, 2025
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. Pyramidkv: Dy- namic kv cache compression based on pyramidal infor- mation funneling, 2025
2025
-
[13]
Mle-bench: Evaluating machine learning agents on machine learning engineer- ing, 2025
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M ˛ adry. Mle-bench: Evaluating machine learning agents on machine learning engineer- ing, 2025
2025
-
[14]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brock- man, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavari...
2021
-
[15]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anas- tasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open plat- form for evaluating llms by human preference, 2024
2024
-
[16]
Crosscodeeval: A diverse and multilingual benchmark for cross-file code com- pletion, 2023
Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. Crosscodeeval: A diverse and multilingual benchmark for cross-file code com- pletion, 2023
2023
-
[17]
Classeval: A manually- crafted benchmark for evaluating llms on class-level code generation, 2023
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. Classeval: A manually- crafted benchmark for evaluating llms on class-level code generation, 2023
2023
-
[18]
Cost-efficient large language model serving for multi-turn conversations with cachedatten- tion, 2024
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. Cost-efficient large language model serving for multi-turn conversations with cachedatten- tion, 2024
2024
-
[19]
Prompt cache: Modular attention reuse for low-latency inference, 2024
In Gim, Guojun Chen, Seung seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference, 2024
2024
-
[20]
GitHub copilot surpasses 20 million users
GitHub. GitHub copilot surpasses 20 million users. https://dataconomy.com/2025/07/31/ github-copilot-now-has-over-20-million-users/ , 17
2025
-
[21]
Figure reported in Microsoft Q4 FY25 earnings; accessed 2026-06-14
2026
-
[22]
Gemini CLI: An open-source ai agent that brings the power of gemini directly into your terminal
Google. Gemini CLI: An open-source ai agent that brings the power of gemini directly into your terminal. https://github.com/google-gemini/ gemini-cli, 2025. Accessed 2026-06-21
2025
-
[23]
Speed at the cost of quality: How cursor ai increases short-term veloc- ity and long-term complexity in open-source projects, 2026
Hao He, Courtney Miller, Shyam Agarwal, Christian Kästner, and Bogdan Vasilescu. Speed at the cost of quality: How cursor ai increases short-term veloc- ity and long-term complexity in open-source projects, 2026
2026
-
[24]
Measuring coding challenge competence with apps, 2021
Dan Hendrycks, Steven Basart, Saurav Kadavath, Man- tas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with apps, 2021
2021
-
[25]
Deepcode: Open agentic coding
HKUDS. Deepcode: Open agentic coding. https: //github.com/HKUDS/DeepCode, 2025. Accessed 2026-06-21
2025
-
[26]
Deepspeed- fastgen: High-throughput text generation for llms via mii and deepspeed-inference, 2024
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhan- dari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, and Yuxiong He. Deepspeed- fastgen: High-throughput text generation for llms via mii and deepspeed-inference, 2024
2024
-
[27]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Moham- madzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization, 2025
2025
-
[28]
Inference without interference: Disaggre- gate llm inference for mixed downstream workloads, 2024
Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, Ninghui Sun, and Yizhou Shan. Inference without interference: Disaggre- gate llm inference for mixed downstream workloads, 2024
2024
-
[29]
Epic: Efficient position-independent caching for serving large lan- guage models, 2025
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. Epic: Efficient position-independent caching for serving large lan- guage models, 2025
2025
-
[30]
Professional software developers don’t vibe, they control: Ai agent use for coding in 2025, 2025
Ruanqianqian Huang, Avery Reyna, Sorin Lerner, Hai- jun Xia, and Brian Hempel. Professional software developers don’t vibe, they control: Ai agent use for coding in 2025, 2025
2025
-
[31]
Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fan- jia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
2024
-
[32]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Minference 1.0: Accelerating pre- filling for long-context llms via dynamic sparse atten- tion, 2024
2024
-
[33]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models re- solve real-world github issues?, 2024
2024
-
[34]
Fu, Christopher Ré, and Azalia Mirhoseini
Jordan Juravsky, Bradley Brown, Ryan Ehrlich, Daniel Y . Fu, Christopher Ré, and Azalia Mirhoseini. Hydragen: High-throughput llm inference with shared prefixes, 2024
2024
-
[35]
Vibeserve: Can ai agents build bespoke llm serving systems?, 2026
Keisuke Kamahori, Shihang Li, Simon Peter, and Baris Kasikci. Vibeserve: Can ai agents build bespoke llm serving systems?, 2026
2026
-
[36]
Gon- zalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gon- zalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention, 2023
2023
-
[37]
Openassistant conversations – democratizing large language model alignment, 2023
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Mattick. Openassistant conversations – democratizing large language mod...
2023
-
[38]
Ds-1000: A natural and reliable benchmark for data science code generation, 2022
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Scott Wen tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation, 2022
2022
-
[39]
Prompting large language models to tackle the full software develop- ment lifecycle: A case study, 2024
Bowen Li, Wenhan Wu, Ziwei Tang, Lin Shi, John Yang, Jinyang Li, Shunyu Yao, Chen Qian, Binyuan Hui, Qicheng Zhang, Zhiyin Yu, He Du, Ping Yang, Dahua Lin, Chao Peng, and Kai Chen. Prompting large language models to tackle the full software develop- ment lifecycle: A case study, 2024
2024
-
[40]
Con- tinuum: Efficient and robust multi-turn llm agent scheduling with kv cache time-to-live, 2026
Hanchen Li, Runyuan He, Qiuyang Mang, Qizheng Zhang, Huanzhi Mao, Xiaokun Chen, Hangrui Zhou, Alvin Cheung, Joseph Gonzalez, and Ion Stoica. Con- tinuum: Efficient and robust multi-turn llm agent scheduling with kv cache time-to-live, 2026. 18
2026
-
[41]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. The rise of ai teammates in software engineering (se) 3.0: How autonomous coding agents are reshaping software engineering, 2025
2025
-
[42]
Snapkv: Llm knows what you are looking for before generation, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation, 2024
2024
-
[43]
Gonzalez, and Ion Sto- ica
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Sto- ica. Alpaserve: Statistical multiplexing with model parallelism for deep learning serving, 2023
2023
-
[44]
Wild- bench: Benchmarking llms with challenging tasks from real users in the wild, 2024
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wild- bench: Benchmarking llms with challenging tasks from real users in the wild, 2024
2024
-
[45]
Par- rot: Efficient serving of llm-based applications with semantic variable, 2024
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. Par- rot: Efficient serving of llm-based applications with semantic variable, 2024
2024
-
[46]
Re- pobench: Benchmarking repository-level code auto- completion systems, 2023
Tianyang Liu, Canwen Xu, and Julian McAuley. Re- pobench: Benchmarking repository-level code auto- completion systems, 2023
2023
-
[47]
Agentbench: Evaluating llms as agents, 2025
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xu- anyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yux- iao Dong, and Jie Tang. Agentbench: Evaluating llms as agents, 2025
2025
-
[48]
Lm- cache: An efficient kv cache layer for enterprise-scale llm inference, 2025
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xi- aokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, and Junchen Jiang. Lm- cache: An efficient kv cache layer for enterprise-scale llm inference, 2025
2025
-
[49]
Cachegen: Kv cache compression and streaming for fast large language model serving, 2024
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. Cachegen: Kv cache compression and streaming for fast large language model serving, 2024
2024
-
[50]
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time, 2023
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time, 2023
2023
-
[51]
Kivi: A tuning-free asymmetric 2bit quantiza- tion for kv cache, 2024
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantiza- tion for kv cache, 2024
2024
-
[52]
Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Yanru Chen, Huabin Zheng, Junjie Yan, Jianlin Su, Yuxin Wu, Neo Y . Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu. Moba: Mixture of block attention for long-cont...
2025
-
[53]
Gonzalez, and Ion Stoica
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, and Ion Stoica. Autellix: An efficient serving engine for llm agents as general programs, 2025
2025
-
[54]
Merrill, Alexander G
Mike A. Merrill, Alexander G. Shaw, Nicholas Car- lini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Je- nia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen...
2026
-
[55]
Gaia: a benchmark for general ai assistants, 2023
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants, 2023
2023
-
[56]
Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?, 2025
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?, 2025. 19
2025
-
[57]
Reading between the lines: Modeling user behavior and costs in ai-assisted programming, 2024
Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. Reading between the lines: Modeling user behavior and costs in ai-assisted programming, 2024
2024
-
[58]
Codex CLI: A lightweight coding agent that runs in your terminal
OpenAI. Codex CLI: A lightweight coding agent that runs in your terminal. https://github.com/ openai/codex, 2025. Accessed 2026-06-21
2025
-
[59]
API pricing
OpenAI. API pricing. https://openai.com/api/ pricing/, 2026. Accessed 2026-06-25
2026
-
[60]
Codex pricing
OpenAI. Codex pricing. https://developers. openai.com/codex/pricing, 2026. Accessed 2026- 06-25
2026
-
[61]
Opencode: The open source AI coding agent
OpenCode. Opencode: The open source AI coding agent. https://opencode.ai/, 2025. Accessed 2026-06-21
2025
-
[62]
Training software engineering agents and verifiers with swe- gym, 2025
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe- gym, 2025
2025
-
[63]
Splitwise: Efficient generative llm inference using phase splitting, 2024
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bian- chini. Splitwise: Efficient generative llm inference using phase splitting, 2024
2024
-
[64]
Polca: Power oversubscription in llm cloud providers, 2023
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Brijesh Warrier, Nithish Mahalingam, and Ri- cardo Bianchini. Polca: Power oversubscription in llm cloud providers, 2023
2023
-
[65]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023
2023
-
[66]
Moon- cake: A kvcache-centric disaggregated architecture for llm serving, 2025
Ruoyu Qin, Zheming Li, Weiran He, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Moon- cake: A kvcache-centric disaggregated architecture for llm serving, 2025
2025
-
[67]
Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023
2023
-
[68]
Toolformer: Language models can teach themselves to use tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023
2023
-
[69]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuo- han Li, Max Ryabinin, Daniel Y . Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flex- gen: High-throughput generative inference of large language models with a single gpu, 2023
2023
-
[70]
Preble: Efficient dis- tributed prompt scheduling for llm serving, 2024
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dong- ming Li, and Yiying Zhang. Preble: Efficient dis- tributed prompt scheduling for llm serving, 2024
2024
-
[71]
2025 stack overflow developer survey: Ai
Stack Overflow. 2025 stack overflow developer survey: Ai. https://survey.stackoverflow.co/ 2025/ai/, 2025. Reports 84% of developers use or plan to use AI tools; accessed 2026-06-14
2025
-
[72]
Dynamollm: Design- ing llm inference clusters for performance and energy efficiency, 2024
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. Dynamollm: Design- ing llm inference clusters for performance and energy efficiency, 2024
2024
-
[73]
Llumnix: Dy- namic scheduling for large language model serving, 2024
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dy- namic scheduling for large language model serving, 2024
2024
-
[74]
Sumers, Jared Mueller, William McEachen, Wes Mitchell, Shan Carter, Jack Clark, Jared Kaplan, and Deep Ganguli
Alex Tamkin, Miles McCain, Kunal Handa, Esin Dur- mus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, Michael Stern, Brian Clarke, Landon Goldberg, Theodore R. Sumers, Jared Mueller, William McEachen, Wes Mitchell, Shan Carter, Jack Clark, Jared Kaplan, and Deep Ganguli. Clio: Privacy-preserving insights into real...
2024
-
[75]
Quest: Query- aware sparsity for efficient long-context llm inference, 2024
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query- aware sparsity for efficient long-context llm inference, 2024
2024
-
[76]
Programming by chat: A large- scale behavioral analysis of 11,579 real-world ai- assisted ide sessions, 2026
Ningzhi Tang, Chaoran Chen, Zihan Fang, Gelei Xu, Maria Dhakal, Yiyu Shi, Collin McMillan, Yu Huang, and Toby Jia-Jun Li. Programming by chat: A large- scale behavioral analysis of 11,579 real-world ai- assisted ide sessions, 2026
2026
-
[77]
Cache- wise: Understanding workloads and optimizing kv- cache management for efficiently serving llm coding agents, 2026
Shubham Tiwari, Tapan Chugh, Nash Rickert, Simon Peter, Ratul Mahajan, and Haiying Shen. Cache- wise: Understanding workloads and optimizing kv- cache management for efficiently serving llm coding agents, 2026
2026
-
[78]
Kvcache cache in the wild: Characterizing and optimizing kvcache cache at a large cloud provider, 2026
Jiahao Wang, Jinbo Han, Xingda Wei, Sijie Shen, Dingyan Zhang, Chenguang Fang, Rong Chen, Wenyuan Yu, and Haibo Chen. Kvcache cache in the wild: Characterizing and optimizing kvcache cache at a large cloud provider, 2026. 20
2026
-
[79]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Jun- yang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for ai so...
2025
-
[80]
Burstgpt: A real-world work- load dataset to optimize llm serving systems, 2025
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, Xin Wang, Qiang Wang, Amelie Chi Zhou, and Xiaowen Chu. Burstgpt: A real-world work- load dataset to optimize llm serving systems, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.