Learning Action-Conditional and Object-Centric Gaussian Splatting World Models for Rigid Objects
Pith reviewed 2026-06-28 14:18 UTC · model grok-4.3
The pith
Object-centric Gaussians in canonical frames let a spatio-temporal transformer predict rigid motions from action sequences in multi-object scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
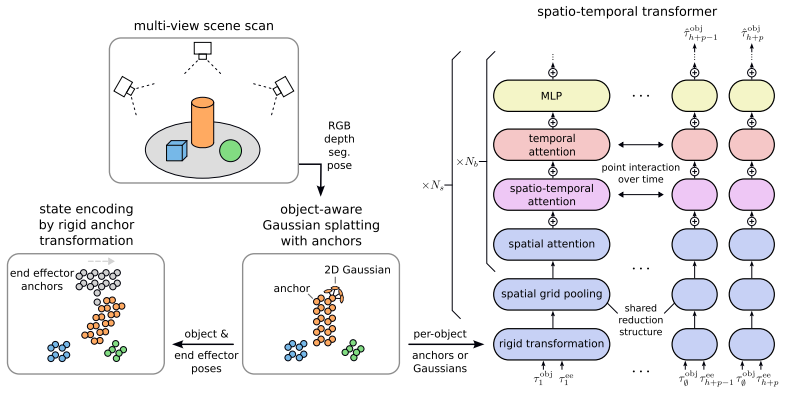
By representing the scene by object-centric Gaussians, we can represent arbitrary object shapes and multi-object scenes. We develop a novel spatio-temporal transformer architecture that predicts future rigid body motion from a history of object Gaussians and future actions. Objects are represented by their Gaussians in a canonical frame, which allows for describing object motion as rigid body transformation. Our model is trained on reconstructions from multiple viewpoints, which requires the model to handle partial observations of objects due to occlusions.
What carries the argument
Object-centric Gaussians stored in a per-object canonical frame that encode shape while allowing all motion to be expressed as rigid transformations, processed by a spatio-temporal transformer conditioned on action history.
If this is right
- The approach represents arbitrary object shapes and multi-object scenes without predefined meshes.
- Future rigid-body motions are predicted directly from sequences of object Gaussians and planned actions.
- Training on multi-view data forces the model to cope with occlusions and incomplete observations.
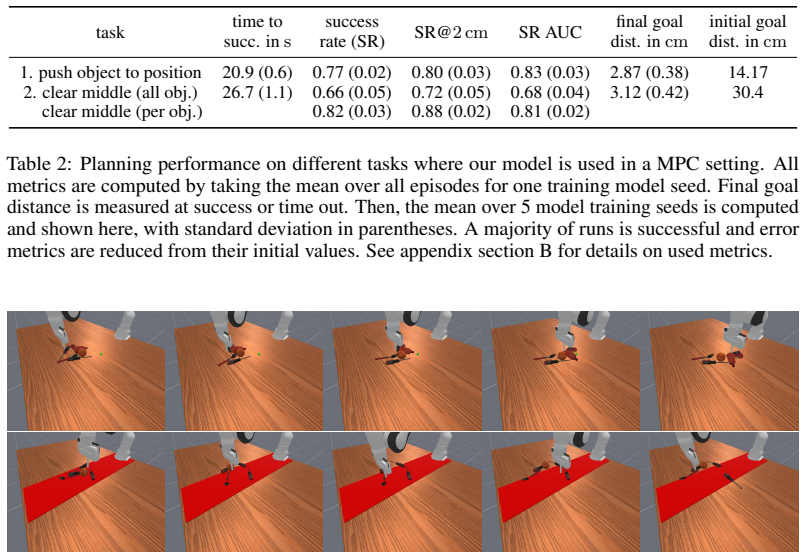
- The resulting dynamics support model-predictive control for non-prehensile manipulation tasks in simulation.
- Performance is measured on synthetic datasets of household objects undergoing robot end-effector interactions.
Where Pith is reading between the lines
- If the canonical-frame representation proves stable, the same Gaussians could be reused across different instances of similar objects for faster adaptation.
- The method could be paired with online Gaussian splatting pipelines to maintain an up-to-date world model during physical robot operation.
- Adding explicit uncertainty outputs from the transformer might improve safety margins when the model is used inside closed-loop controllers.
- Testing whether the learned transformations remain accurate when object masses or friction coefficients change would reveal how much geometric information alone suffices for dynamics.
- keywords:[
Load-bearing premise
Objects remain rigid and can be consistently aligned to a shared canonical frame across partial observations so that motion reduces exactly to rigid-body transformations.
What would settle it
A sequence of multi-view images after a known pushing action on one object in an occluded multi-object scene, where the predicted Gaussian centers deviate measurably from the 3D positions recovered by an independent reconstruction method.
Figures
read the original abstract
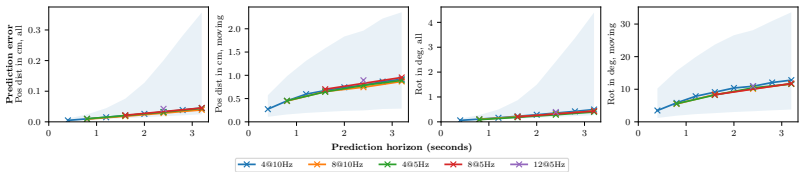
World models enable intelligent agents to predict the consequences of their actions on the environment. In this paper, we propose Multi Rigid Object Gaussian World Model (MRO-GWM), a novel model that learns action-conditional dynamics of rigid objects in 3D. By representing the scene by object-centric Gaussians, we can represent arbitrary object shapes and multi-object scenes. We develop a novel spatio-temporal transformer architecture that predicts future rigid body motion from a history of object Gaussians and future actions. Objects are represented by their Gaussians in a canonical frame, which allows for describing object motion as rigid body transformation. Our model is trained on reconstructions from multiple viewpoints, which requires the model to handle partial observations of objects due to occlusions. We analyze prediction performance of our approach on synthetic datasets composed of typical household objects with multi-object dynamics and interactions by a robot end effector. We also evaluate our model in model-predictive control for non-prehensile manipulation in simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi Rigid Object Gaussian World Model (MRO-GWM), a world model that learns action-conditional dynamics of rigid objects in 3D scenes. Scenes are represented via object-centric Gaussians placed in a canonical frame (enabling rigid-body transformations for motion), a novel spatio-temporal transformer predicts future motions from histories of these Gaussians plus future actions, training uses multi-view reconstructions to handle partial observations from occlusions, and the model is evaluated on synthetic multi-object household datasets plus model-predictive control for non-prehensile manipulation in simulation.
Significance. If the central claims hold, the work could advance 3D world models for robotics by showing that object-centric Gaussian splatting combined with transformer-based dynamics prediction can scale to multi-object rigid scenes and support downstream planning. The canonical-frame representation and multi-view training strategy are presented as key enablers for shape generality and occlusion robustness.
major comments (1)
- [Abstract] Abstract: The description of the model architecture, training approach, and evaluation supplies no equations, quantitative results, error analysis, or derivation details, so it is impossible to verify whether the described components support the stated claims about prediction performance, rigid-body motion modeling, or occlusion handling.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The description of the model architecture, training approach, and evaluation supplies no equations, quantitative results, error analysis, or derivation details, so it is impossible to verify whether the described components support the stated claims about prediction performance, rigid-body motion modeling, or occlusion handling.
Authors: Abstracts are intentionally concise high-level summaries and do not contain equations or detailed quantitative results; those elements appear in the body of the manuscript. Section 3 presents the object-centric Gaussian representation in canonical frames, the rigid-body transformation formulation, and the full spatio-temporal transformer architecture with equations for attention over history Gaussians and action conditioning. Section 4 details the multi-view training procedure, the loss terms used to enforce consistency under partial observations, and the associated derivations for handling occlusions. Section 5 reports quantitative prediction metrics (e.g., Chamfer distance, rotation/translation errors), ablation studies, and error analyses on the synthetic multi-object datasets, together with MPC success rates for non-prehensile manipulation. These sections collectively allow verification of the claims regarding prediction performance, rigid-body motion, and occlusion robustness. revision: no
Circularity Check
No significant circularity identified
full rationale
The abstract and description present a novel architecture (object-centric Gaussians in canonical frame + spatio-temporal transformer) for predicting rigid-body motion from actions and history. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are quoted that would reduce any claimed derivation to its own inputs by construction. The central claims rest on the proposed representation and training procedure without visible self-definitional loops or load-bearing internal citations. This is the common case of a self-contained proposal whose validity is to be judged by external experiments rather than internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Physically embodied gaussian splatting: A visually learnt and physically grounded 3d representation for robotics
Jad Abou-Chakra, Krishan Rana, Feras Dayoub, and Niko Suenderhauf. Physically embodied gaussian splatting: A visually learnt and physically grounded 3d representation for robotics. InProc. of the Conf. on Robot Learning (CoRL), 2025
2025
-
[2]
Optuna: A next- generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next- generation hyperparameter optimization framework. InProc. of the 25th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, 2019
2019
-
[3]
PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael ...
2024
-
[4]
Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal M
Jake Bruce, Michael D. Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal M. P. Behbahani, Stephanie C. Y . Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott E. Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de F...
2024
-
[5]
Srinivasa, Pieter Abbeel, and Aaron M
Berk Çalli, Aaron Walsman, Arjun Singh, Siddhartha S. Srinivasa, Pieter Abbeel, and Aaron M. Dollar. Benchmarking in manipulation research: Using the Yale-CMU-Berkeley object and model set.IEEE Robotics Autom. Mag., 22(3), 2015
2015
-
[6]
GAF: Gaussian action field as a 4d representation for dynamic world modeling in robotic manipulation
Ying Chai, Litao Deng, Ruizhi Shao, Jiajun Zhang, Kangchen Lv, Liangjun Xing, Xiang Li, Hongwen Zhang, and Yebin Liu. GAF: Gaussian action field as a 4d representation for dynamic world modeling in robotic manipulation. InIEEE Int. Conf. on Robotics and Automation (ICRA), 2026. To appear
2026
-
[7]
Smith, Kelsey R
Filipe de Avila Belbute-Peres, Kevin A. Smith, Kelsey R. Allen, Josh Tenenbaum, and J. Zico Kolter. End-to-end differentiable physics for learning and control. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[8]
Learning multi-object dynamics with compositional neural radiance fields
Danny Driess, Zhiao Huang, Yunzhu Li, Russ Tedrake, and Marc Toussaint. Learning multi-object dynamics with compositional neural radiance fields. InProc. of the 6th Conference on Robot Learning (CoRL), 2023
2023
-
[9]
Learning with 3D rotations, a hitchhiker’s guide to SO(3)
Andreas René Geist, Jonas Frey, Mikel Zhobro, Anna Levina, and Georg Martius. Learning with 3D rotations, a hitchhiker’s guide to SO(3). InProc. of the 41st Int. Conf. on Machine Learning (ICML), 2024
2024
-
[10]
Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson
Danijar Hafner, Timothy P. Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InProc. of the Int. Conf. on Machine Learning (ICML), 2019
2019
-
[11]
Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo.arXiv preprint arXiv:2212.00541, 2022
Taylor Howell, Nimrod Gileadi, Saran Tunyasuvunakool, Kevin Zakka, Tom Erez, and Yuval Tassa. Predictive Sampling: Real-time Behaviour Synthesis with MuJoCo.arXiv preprint arXiv:2212.00541, 2022
-
[12]
A moving least squares material point method with displacement discontinuity and two-way rigid body coupling
Yuanming Hu, Yu Fang, Ziheng Ge, Ziyin Qu, Yixin Zhu, Andre Pradhana, and Chenfanfu Jiang. A moving least squares material point method with displacement discontinuity and two-way rigid body coupling. ACM Trans. Graph., 37(4), 2018. 10
2018
-
[13]
2d gaussian splatting for geometrically accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. InSIGGRAPH 2024 Conference Papers, 2024
2024
-
[14]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
2023
-
[15]
Li, Brandon Hung, Aaron D
Albert H. Li, Brandon Hung, Aaron D. Ames, Jiuguang Wang, Simon Le Cleac’h, and Preston Culbertson. Judo: A user-friendly open-source package for sampling-based model predictive control. InProc. of the Workshop on Fast Motion Planning and Control in the Era of Parallelism at Robotics: Science and Systems (RSS), 2025
2025
-
[16]
Learning physics-grounded 4d dynamics with neural gaussian force fields
Shiqian Li, Ruihong Shen, Junfeng Ni, Chang Pan, Chi Zhang, and Yixin Zhu. Learning physics-grounded 4d dynamics with neural gaussian force fields. InProc. of the Int. Conf. on Learning Representations (ICLR), 2026
2026
-
[17]
Wenxuan Li, Hang Zhao, Zhiyuan Yu, Yu Du, Qin Zou, Ruizhen Hu, and Kai Xu. PIN-WM: Learning physics-informed world models for non-prehensile manipulation.arXiv preprint arXiv:2504.16693, 2025
-
[18]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProc. of the Int. Conf. on Learning Representations (ICLR), 2019
2019
-
[19]
ManiGaussian: Dynamic gaussian splatting for multi-task robotic manipulation
Guanxing Lu, Shiyi Zhang, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. ManiGaussian: Dynamic gaussian splatting for multi-task robotic manipulation. InProc. of the European Conf. on Computer Vision (ECCV), 2024
2024
-
[20]
GWM: Towards scalable gaussian world models for robotic manipulation.Proc
Guanxing Lu, Baoxiong Jia, Puhao Li, Yixin Chen, Ziwei Wang, Yansong Tang, and Siyuan Huang. GWM: Towards scalable gaussian world models for robotic manipulation.Proc. of Int. Conf. on Computer Vision (ICCV), 2025
2025
-
[21]
Scaffold-GS: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-GS: Structured 3d gaussians for view-adaptive rendering. InProc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[22]
Self-correcting robot manipu- lation via gaussian-splatted foresight
Shaohui Pan, Yong Xu, Ruotao Xu, Zihan Zhou, Si Wu, and Zhuliang Yu. Self-correcting robot manipu- lation via gaussian-splatted foresight. InProc. of the Thirty-Ninth AAAI Conf. on Artificial Intelligence and Thirty-Seventh Conf. on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence, 2025
2025
-
[23]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Sampling-based model predictive control leveraging parallelizable physics simulations.IEEE Robotics and Automation Letters, 10(3), 2025
Corrado Pezzato, Chadi Salmi, Elia Trevisan, Max Spahn, Javier Alonso-Mora, and Carlos Hernández Cor- bato. Sampling-based model predictive control leveraging parallelizable physics simulations.IEEE Robotics and Automation Letters, 10(3), 2025
2025
-
[25]
Sample-efficient cross-entropy method for real-time planning
Cristina Pinneri, Shambhuraj Sawant, Sebastian Blaes, Jan Achterhold, Joerg Stueckler, Michal Rolinek, and Georg Martius. Sample-efficient cross-entropy method for real-time planning. InProc. of the 2020 Conference on Robot Learning (CoRL), 2021
2020
-
[26]
Maniskill3: GPU parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse kai Chan, Yuan Gao, Xuanlin Li, Tongzhou Mu, Nan Xiao, Arnav Gurha, Viswesh Na- gaswamy Rajesh, Yong Woo Choi, Yen-Ru Chen, Zhiao Huang, Roberto Calandra, Rui Chen, Shan Luo, and Hao Su. Maniskill3: GPU parallelized robotics simulation and...
2025
-
[27]
Gaussian splatting visual MPC for granular media manipulation
Wei-Cheng Tseng, Ellina Zhang, Krishna Murthy Jatavallabhula, and Florian Shkurti. Gaussian splatting visual MPC for granular media manipulation. InProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA), 2025
2025
-
[28]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[29]
Meizhong Wang, Wanxin Jin, Kun Cao, Lihua Xie, and Yiguang Hong. ContactGaussian-WM: Learning physics-grounded world model from videos.arXiv preprint arXiv:2602.11021, 2026
-
[30]
Point transformer v2: Grouped vector attention and partition-based pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Hengshuang Zhao. Point transformer v2: Grouped vector attention and partition-based pooling. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 11
2022
-
[31]
PoseCNN: A convolutional neural network for 6d object pose estimation in cluttered scenes
Yu Xiang, Tanner Schmidt, Venkatraman Narayanan, and Dieter Fox. PoseCNN: A convolutional neural network for 6d object pose estimation in cluttered scenes. InProc. of Robotics: Science and Systems (RSS), 2018
2018
-
[32]
PhysGaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. PhysGaussian: Physics-integrated 3d gaussians for generative dynamics. InProc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[33]
Manigaussian++: General robotic bimanual manipulation with hierarchical gaussian world model
Tengbo Yu, Guanxing Lu, Zaijia Yang, Haoyuan Deng, Season Si Chen, Jiwen Lu, Wenbo Ding, Guoqiang Hu, Yansong Tang, and Ziwei Wang. Manigaussian++: General robotic bimanual manipulation with hierarchical gaussian world model. InProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2025
2025
-
[34]
Dynamic 3d gaussian tracking for graph-based neural dynamics modeling
Mingtong Zhang, Kaifeng Zhang, and Yunzhu Li. Dynamic 3d gaussian tracking for graph-based neural dynamics modeling. InProc. of the Conf. on Robot Learning (CoRL), 2024
2024
-
[35]
Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y . Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T. Freeman. PhysDreamer: Physics-based interaction with 3d objects via video generation. In Proc. of the European Conf. on Computer Vision (ECCV), 2024
2024
-
[36]
Haoyu Zhao, Hao Wang, Xingyue Zhao, Hao Fei, Hongqiu Wang, Chengjiang Long, and Hua Zou. Efficient physics simulation for 3D scenes via mllm-guided gaussian splatting.arXiv preprint arXiv:2411.12789, 2025
-
[37]
Learning 3D-Gaussian simulators from RGB videos.arXiv preprint arXiv:2503.24009, 2025
Mikel Zhobro, Andreas René Geist, and Georg Martius. Learning 3D-Gaussian simulators from RGB videos.arXiv preprint arXiv:2503.24009, 2025
-
[38]
standing
Ruijie Zhu, Mulin Yu, Linning Xu, Lihan Jiang, Yixuan Li, Tianzhu Zhang, Jiangmiao Pang, and Bo Dai. ObjectGS: Object-aware scene reconstruction and scene understanding via gaussian splatting. InProc. of the Int. Conf. on Computer Vision (ICCV), 2025. 12 A Dataset Details Scene generationFor our train and val datasets, we sample the object count uniformly...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.