Harnessing Structural Context for Entity Alignment Foundation Models
Pith reviewed 2026-06-28 01:12 UTC · model grok-4.3
The pith
Cross-KG interaction encoder and structural calibration decoder let pretrained entity alignment models transfer directly to unseen graph pairs and surpass finetuned baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
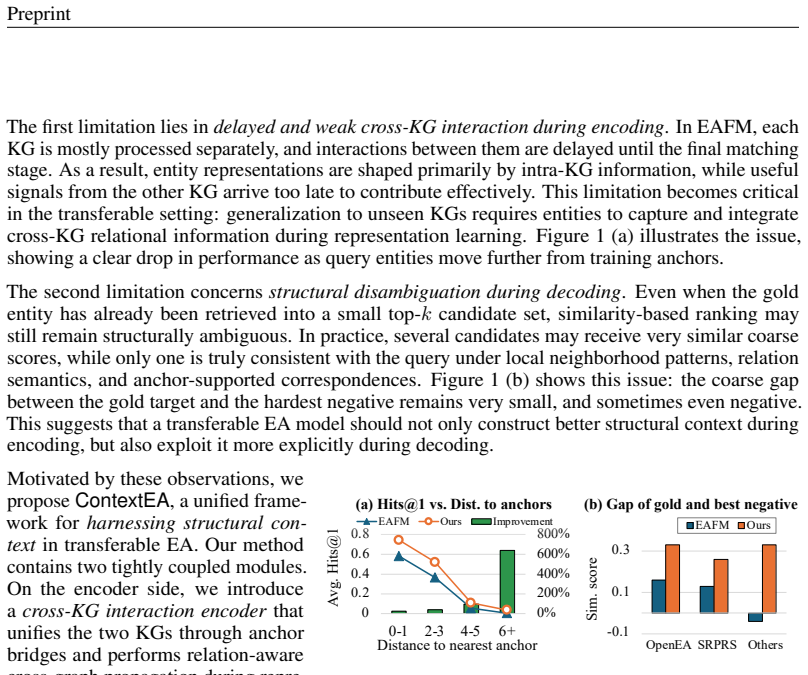
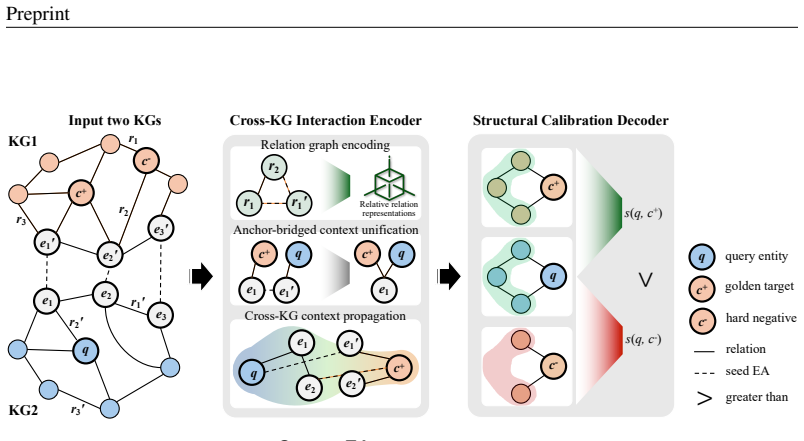
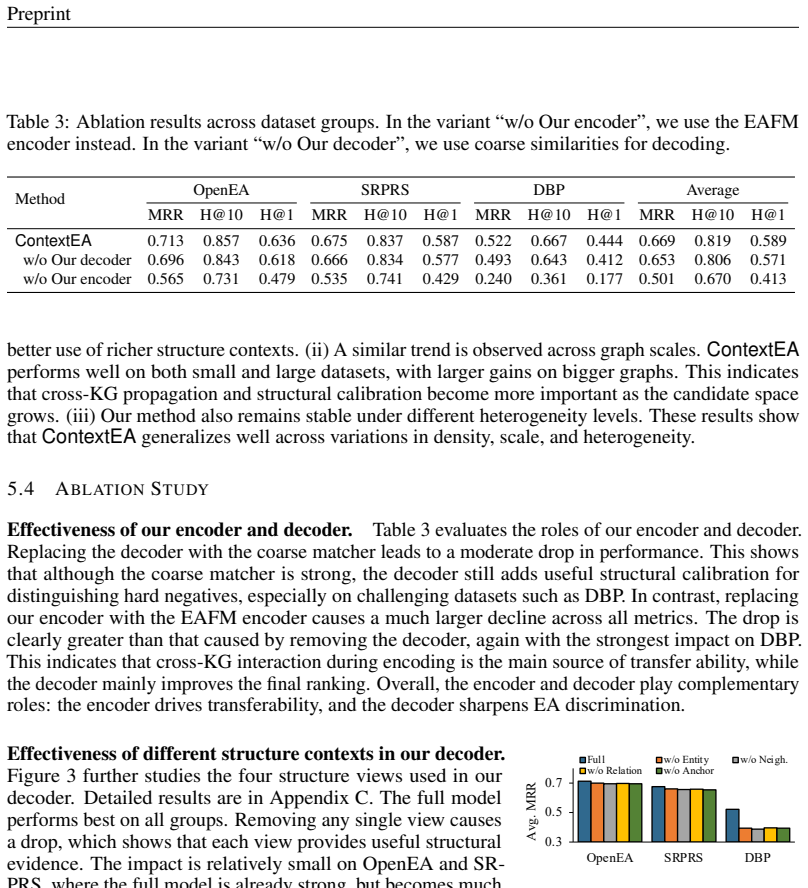
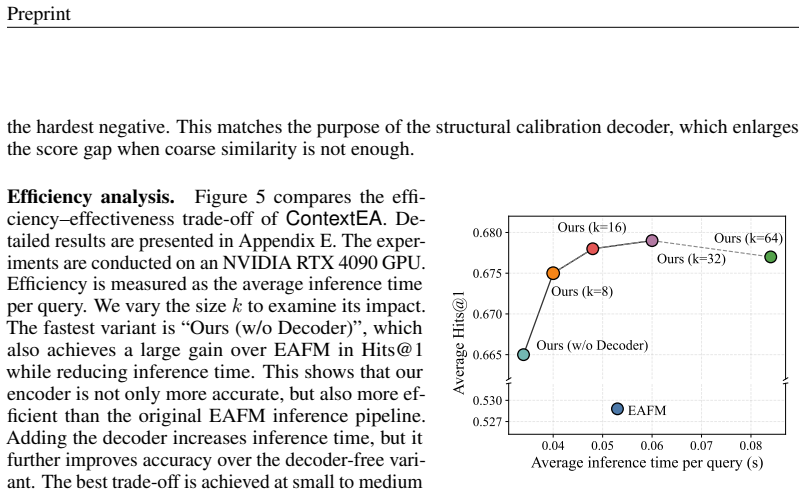
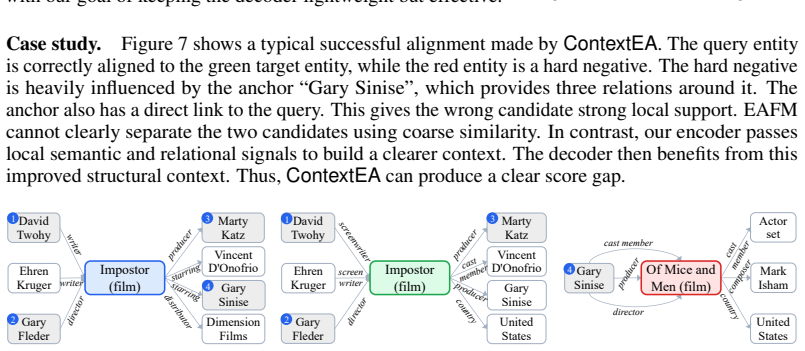
ContextEA is an encoder-decoder architecture for transferable entity alignment. Its cross-KG interaction encoder unifies the two input graphs via anchor bridges and performs relation-aware cross-graph propagation earlier in the process. Its structural calibration decoder then refines alignment scores using four complementary sources of structural evidence. On the OpenEA, SRPRS, and DBP collections the pretrained ContextEA already exceeds the performance of finetuned strong baselines on every benchmark group, indicating substantially improved transfer to previously unseen KG pairs.
What carries the argument
Cross-KG interaction encoder that unifies graphs with anchor bridges for relation-aware propagation, paired with a structural calibration decoder that adjusts scores using entity, neighborhood, relation, and anchor evidence.
If this is right
- Pretrained ContextEA can be applied directly to new KG pairs without task-specific fine-tuning.
- Consistent improvements appear across all three benchmark collections totaling 29 datasets.
- The same design strengthens both the construction and the exploitation of structural context.
- Explicit structural-context modeling is an effective route for advancing EA foundation models.
Where Pith is reading between the lines
- The same calibration approach might reduce the need for fine-tuning in other cross-graph tasks such as relation alignment or entity typing.
- If the transfer advantage scales with larger pretraining corpora, foundation-model development for knowledge graphs could shift emphasis from per-pair supervision to broader structural pretraining.
- Testing on KGs that differ more sharply in density or schema from the pretraining distribution would reveal the limits of the current structural-context mechanisms.
Load-bearing premise
The measured gains come from the new encoder and decoder components rather than from differences in model capacity or training data volume.
What would settle it
A controlled ablation that removes the cross-KG propagation and the multi-level calibration while keeping model size and training data identical would show whether the performance gap to baselines disappears.
Figures

read the original abstract
Entity alignment (EA) aims to identify equivalent entities across heterogeneous knowledge graphs (KGs) and is a key component of knowledge fusion and cross-KG reasoning. The recent EA foundation model demonstrates that alignment knowledge, once pretrained, can be directly applied to diverse previously unseen KG pairs. However, it still underuses structural context in two places: cross-KG interaction is weak during encoding, and final candidate ranking still relies too heavily on coarse similarity. We address these limitations with ContextEA, an enhanced encoder-decoder framework for transferable EA. On the encoder side, we introduce a cross-KG interaction encoder that unifies the two KGs with anchor bridges and performs earlier relation-aware cross-graph propagation. On the decoder side, we introduce a structural calibration decoder that calibrates alignment scores with entity-level, neighborhood-level, relation-level, and anchor-aware structural evidence. This design strengthens both structural context construction and structural context exploitation while remaining lightweight. Experiments on 29 EA datasets in OpenEA, SRPRS, and DBP show consistent gains over strong transferable baselines. Notably, the pretrained ContextEA already surpasses the finetuned baselines on all three benchmark groups, demonstrating substantially stronger transfer to unseen KGs. These results suggest that explicitly harnessing structural context is an effective direction for improving EA foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContextEA, an encoder-decoder framework for entity alignment (EA) foundation models. It proposes a cross-KG interaction encoder that unifies KGs with anchor bridges and performs relation-aware cross-graph propagation, plus a structural calibration decoder that incorporates entity-, neighborhood-, relation-, and anchor-level evidence. Experiments claim consistent gains over strong transferable baselines on 29 datasets from OpenEA, SRPRS, and DBP benchmarks. Notably, the pretrained ContextEA is reported to surpass finetuned baselines across all groups, indicating improved transfer to unseen KGs.
Significance. If the performance advantages can be isolated to the proposed structural components, the work would strengthen the case for explicit structural context modeling in transferable EA systems. The pretrained-vs-finetuned comparison, if robust, would be a notable result for foundation-model-style EA.
major comments (2)
- [Abstract] Abstract: the central claim that pretrained ContextEA surpasses finetuned baselines on all three benchmark groups cannot be attributed to the cross-KG interaction encoder and structural calibration decoder without matched-capacity ablations, parameter counts, or pretraining corpus sizes versus the baselines; the current evidence leaves open the possibility that gains arise from unstated differences in model scale or data volume.
- [Abstract] Abstract: no ablation details, error bars, or dataset statistics are provided to support the 'consistent gains' and 'substantially stronger transfer' assertions, weakening the load-bearing claim that the design strengthens structural context construction and exploitation.
minor comments (1)
- [Abstract] The abstract refers to 'strong transferable baselines' without naming them or citing their parameter counts; adding this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims. We address each major comment below and will revise the abstract accordingly to strengthen the presentation of results while maintaining accuracy.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that pretrained ContextEA surpasses finetuned baselines on all three benchmark groups cannot be attributed to the cross-KG interaction encoder and structural calibration decoder without matched-capacity ablations, parameter counts, or pretraining corpus sizes versus the baselines; the current evidence leaves open the possibility that gains arise from unstated differences in model scale or data volume.
Authors: The baselines are the published results from prior transferable EA work using comparable foundation-model architectures; ContextEA adds only lightweight structural modules on top of the same base. The full manuscript reports parameter counts, pretraining corpus details, and ablations isolating the encoder/decoder contributions in Sections 3 and 4. We will revise the abstract to explicitly reference these comparable capacities and the ablation evidence supporting attribution to the proposed structural components. revision: yes
-
Referee: [Abstract] Abstract: no ablation details, error bars, or dataset statistics are provided to support the 'consistent gains' and 'substantially stronger transfer' assertions, weakening the load-bearing claim that the design strengthens structural context construction and exploitation.
Authors: Abstract length constraints preclude including full experimental details. The manuscript provides ablation studies (Section 4.3), error bars on all main tables, and dataset statistics (Table 1 plus appendix). We will revise the abstract to qualify the claims with a parenthetical reference to the experiments section for ablations, statistics, and transfer results, thereby directing readers to the supporting evidence without altering the summary findings. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical encoder-decoder architecture (cross-KG interaction encoder and structural calibration decoder) and reports experimental gains on 29 EA benchmarks versus external baselines. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text. The central claim (pretrained ContextEA outperforming finetuned baselines) rests on direct experimental comparison rather than any derivation that reduces to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
EMNLP , year = 2018, pages =
Zhichun Wang and Qingsong Lv and Xiaohan Lan and Yu Zhang , title =. EMNLP , year = 2018, pages =
2018
-
[2]
ISWC , year = 2017, pages =
Zequn Sun and Wei Hu and Chengkai Li , title =. ISWC , year = 2017, pages =
2017
-
[3]
Translating Embeddings for Modeling Multi-relational Data , booktitle =
Antoine Bordes and Nicolas Usunier and Alberto Garc. Translating Embeddings for Modeling Multi-relational Data , booktitle =
-
[4]
PVLDB , year = 2020, pages =
Zequn Sun and Qingheng Zhang and Wei Hu and Chengming Wang and Muhao Chen and Farahnaz Akrami and Chengkai Li , title =. PVLDB , year = 2020, pages =
2020
-
[5]
Yu , title =
Shaoxiong Ji and Shirui Pan and Erik Cambria and Pekka Marttinen and Philip S. Yu , title =. TNNLS , volume =
-
[6]
Unifying Large Language Models and Knowledge Graphs: A Roadmap , year=
Pan, Shirui and Luo, Linhao and Wang, Yufei and Chen, Chen and Wang, Jiapu and Wu, Xindong , journal=. Unifying Large Language Models and Knowledge Graphs: A Roadmap , year=
-
[7]
Kaisheng Zeng and Chengjiang Li and Lei Hou and Juanzi Li and Ling Feng , title =
-
[8]
The VLDB Journal , pages =
Zhang, Rui and Trisedya, Bayu Distiawan and Li, Miao and Jiang, Yong and Qi, Jianzhong , title =. The VLDB Journal , pages =. 2022 , address =
2022
-
[9]
ICLR , year = 2024, address =
Mikhail Galkin and Xinyu Yuan and Hesham Mostafa and Jian Tang and Zhaocheng Zhu , title =. ICLR , year = 2024, address =
2024
-
[10]
NeurIPS , year =
Yuanning Cui and Zequn Sun and Wei Hu , title =. NeurIPS , year =
-
[11]
CoRR , volume =
Yucheng Zhang and Beatrice Bevilacqua and Mikhail Galkin and Bruno Ribeiro , title =. CoRR , volume =
-
[12]
Neural Bellman-Ford Networks:
Zhaocheng Zhu and Zuobai Zhang and Louis. Neural Bellman-Ford Networks:. NeurIPS , pages =
-
[13]
WWW , pages =
Yongqi Zhang and Quanming Yao , title =. WWW , pages =
-
[14]
Canonical Tensor Decomposition for Knowledge Base Completion , booktitle =
Timoth. Canonical Tensor Decomposition for Knowledge Base Completion , booktitle =
-
[15]
Zequn Sun and Jiacheng Huang and Jinghao Lin and Xiaozhou Xu and Qijin Chen and Wei Hu , title =
-
[16]
Yuxin Wang and Yuanning Cui and Wenqiang Liu and Zequn Sun and Yiqiao Jiang and Kexin Han and Wei Hu , title =
-
[17]
How Expressive are Knowledge Graph Foundation Models? , booktitle =
Xingyue Huang and Pablo Barcel. How Expressive are Knowledge Graph Foundation Models? , booktitle =
-
[18]
A Theory of Link Prediction via Relational Weisfeiler-Leman on Knowledge Graphs , booktitle =
Xingyue Huang and Miguel Romero and. A Theory of Link Prediction via Relational Weisfeiler-Leman on Knowledge Graphs , booktitle =
-
[19]
How do Language Models Reshape Entity Alignment? A Survey of
Chen, Zerui and Fan, Huiming and Wang, Qianyu and He, Tao and Liu, Ming and Chang, Heng and Yu, Weijiang and Li, Ze and Qin, Bing , booktitle =. How do Language Models Reshape Entity Alignment? A Survey of. 2025 , pages =
2025
-
[20]
IJCAI , year = 2017, pages =
Muhao Chen and Yingtao Tian and Mohan Yang and Carlo Zaniolo , title =. IJCAI , year = 2017, pages =
2017
-
[21]
IJCAI , year = 2019, pages =
Yuting Wu and Xiao Liu and Yansong Feng and Zheng Wang and Rui Yan and Dongyan Zhao , title =. IJCAI , year = 2019, pages =
2019
-
[22]
WWW , year = 2021, pages =
Xin Mao and Wenting Wang and Yuanbin Wu and Man Lan , title =. WWW , year = 2021, pages =
2021
-
[23]
AAAI , year = 2020, pages =
Zequn Sun and Chengming Wang and Wei Hu and Muhao Chen and Jian Dai and Wei Zhang and Yuzhong Qu , title =. AAAI , year = 2020, pages =
2020
-
[24]
IJCAI , year = 2017, pages =
Hao Zhu and Ruobing Xie and Zhiyuan Liu and Maosong Sun , title =. IJCAI , year = 2017, pages =
2017
-
[25]
IJCAI , year = 2018, pages =
Zequn Sun and Wei Hu and Qingheng Zhang and Yuzhong Qu , title =. IJCAI , year = 2018, pages =
2018
-
[26]
KDD , year = 2023, pages =
Zequn Sun and Jiacheng Huang and Jinghao Lin and Xiaozhou Xu and Qijin Chen and Wei Hu , title =. KDD , year = 2023, pages =
2023
-
[27]
KDD , year = 2020, pages =
Shichao Pei and Lu Yu and Guoxian Yu and Xiangliang Zhang , title =. KDD , year = 2020, pages =
2020
-
[28]
WWW , pages=
Semi-supervised entity alignment via knowledge graph embedding with awareness of degree difference , author=. WWW , pages=
-
[29]
ICML , year =
Lingbing Guo and Zequn Sun and Wei Hu , title =. ICML , year =
-
[30]
WSDM , pages =
Kexuan Xin and Zequn Sun and Wen Hua and Wei Hu and Xiaofang Zhou , title =. WSDM , pages =
-
[31]
CIKM , year=
Relational Reflection Entity Alignment , author=. CIKM , year=
-
[32]
SIGIR , pages=
RSGEA: Relationship Structure Line Graph for Semi-supervised Entity Alignment based on Edge Weight Adjustment , author=. SIGIR , pages=
-
[33]
Findings of NAACL , pages=
Rethinking Smoothness for Fast and Adaptable Entity Alignment Decoding , author=. Findings of NAACL , pages=
-
[34]
NeurIPS , year=
NeuSymEA: Neuro-symbolic Entity Alignment via Variational Inference , author=. NeurIPS , year=
-
[35]
EMNLP , pages=
How do Language Models Reshape Entity Alignment? A Survey of LM-Driven EA Methods: Advances, Benchmarks, and Future , author=. EMNLP , pages=
-
[36]
CoRR , volume =
Yuanning Cui and Zequn Sun and Wei Hu and Kexuan Xin and Zhangjie Fu , title =. CoRR , volume =. 2026 , eprinttype =
2026
-
[37]
NeurIPS , year =
Shengyuan Chen and Qinggang Zhang and Junnan Dong and Wen Hua and Qing Li and Xiao Huang , title =. NeurIPS , year =
-
[38]
NeurIPS , year =
Hang Yin and Liyao Xiang and Dong Ding and Yuheng He and Yihan Wu and Pengzhi Chu and Xinbing Wang and Chenghu Zhou , title =. NeurIPS , year =
-
[39]
Data Intell
Xuan Chen and Tong Lu and Zhichun Wang , title =. Data Intell. , volume =
-
[40]
Findings of
Jingwei Cheng and Chenglong Lu and Linyan Yang and Guoqing Chen and Fu Zhang , title =. Findings of
-
[41]
Zequn Sun and Jiacheng Huang and Xiaozhou Xu and Qijin Chen and Weijun Ren and Wei Hu , title =
-
[42]
TKDE , volume =
Zequn Sun and Wei Hu and Chengming Wang and Yuxin Wang and Yuzhong Qu , title =. TKDE , volume =
-
[43]
2022 , booktitle =
Liu, Xiao and Hong, Haoyun and Wang, Xinghao and Chen, Zeyi and Kharlamov, Evgeny and Dong, Yuxiao and Tang, Jie , title =. 2022 , booktitle =
2022
-
[44]
Weixin Zeng and Xiang Zhao and Xinyi Li and Jiuyang Tang and Wei Wang , title =
-
[45]
Companion of The Web Conference , pages =
Anil Surisetty and Deepak Chaurasiya and Nitish Kumar and Alok Singh and Gaurav Dhama and Aakarsh Malhotra and Ankur Arora and Vikrant Dey , title =. Companion of The Web Conference , pages =
-
[46]
Yunjun Gao and Xiaoze Liu and Junyang Wu and Tianyi Li and Pengfei Wang and Lu Chen , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.