Geometry-Aware Tabular Diffusion
Pith reviewed 2026-06-30 14:37 UTC · model grok-4.3
The pith
Adding pairwise angles and lengths from column differences as explicit signals improves tabular diffusion across architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
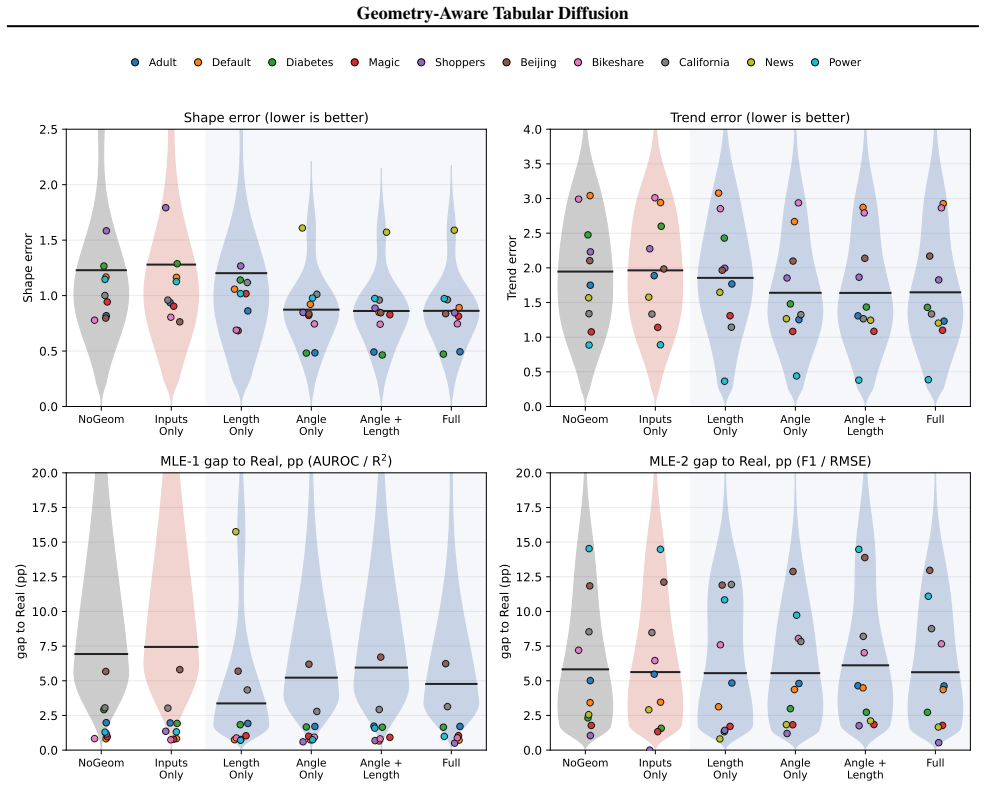
Tabular diffusion can be improved by augmenting denoisers with pairwise angles and lengths computed from column value differences and used as inputs and auxiliary targets. The MLP instantiation wins 8/10 Shape, 7/10 Trend, and 9/10 downstream utility benchmarks while using 3.5x fewer parameters on average, cutting Shape and Trend error by 27% and 20%. Default loss weights transfer to GNN and Transformer denoisers, improving Shape on 27/30 and Trend on 25/30 architecture-dataset combinations. A matched ablation isolates supervision as the source of the improvement, establishing explicit relational supervision as a portable inductive bias.
What carries the argument
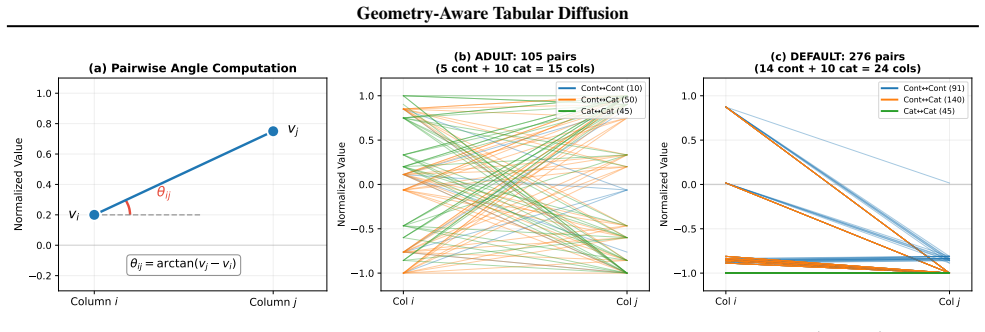
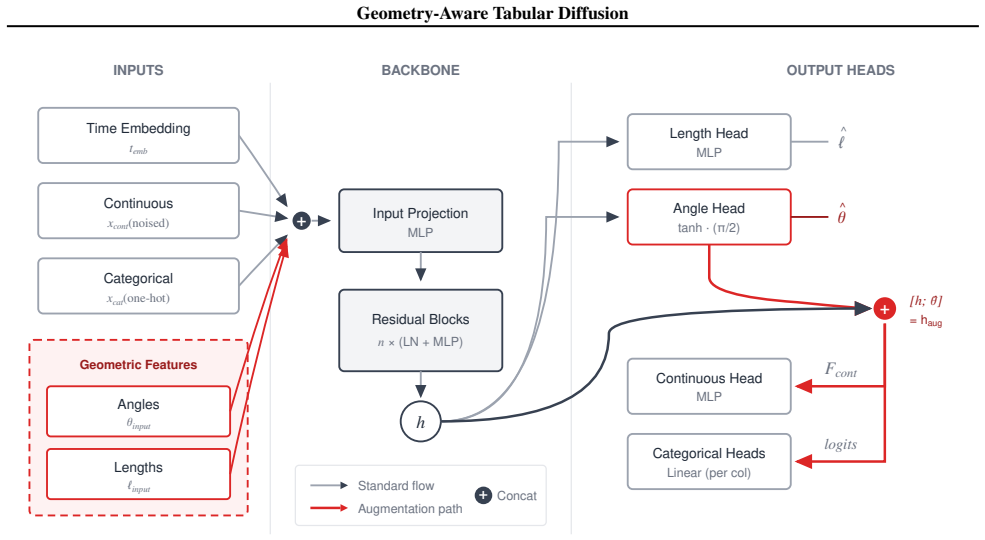
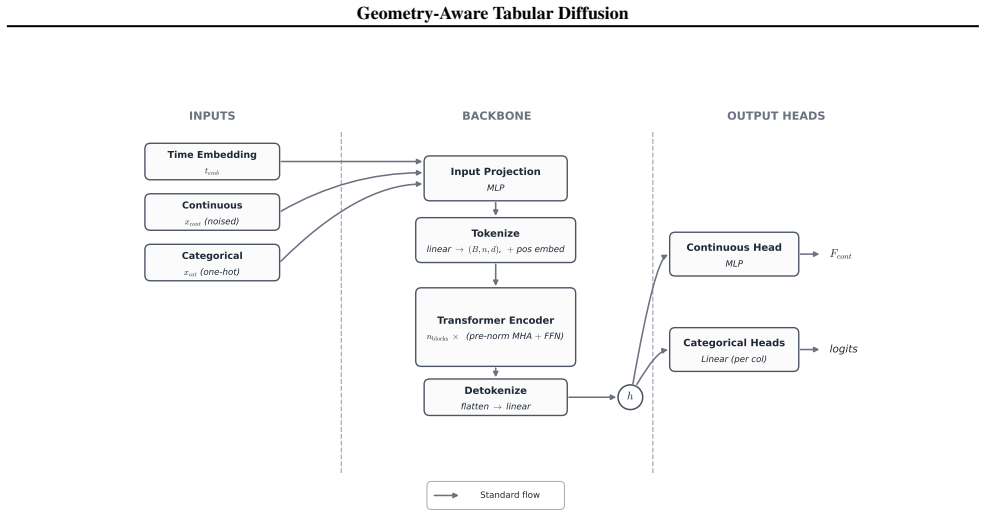
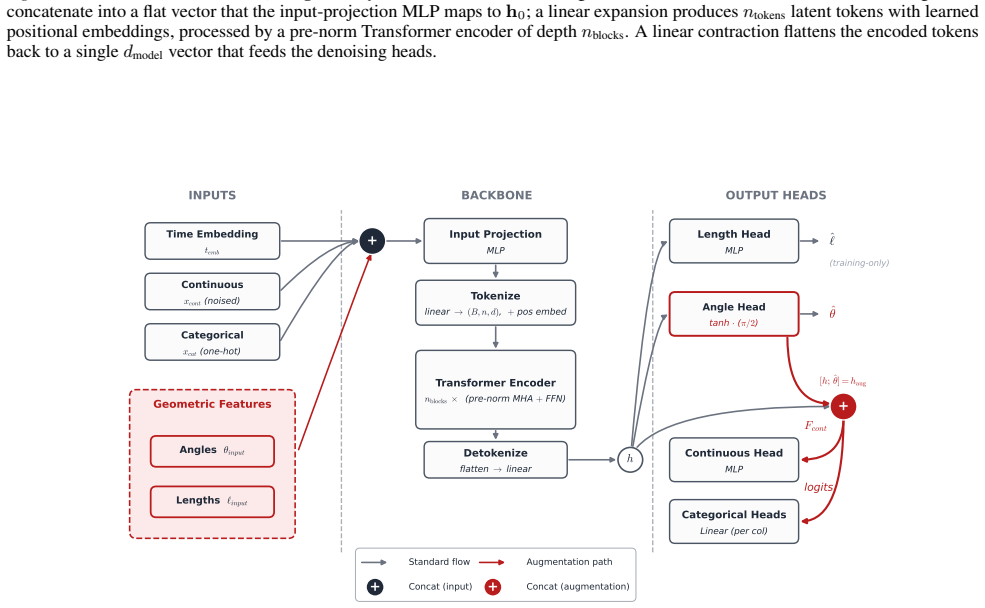
Geometry-Aware Tabular Diffusion (GATD), which augments tabular diffusion denoisers with pairwise angles and lengths computed from column value differences and used as inputs and auxiliary targets.
If this is right
- The MLP version achieves wins on 8/10 Shape, 7/10 Trend, and 9/10 downstream utility metrics while using 3.5x fewer parameters on average.
- Shape and Trend error drop by 27% and 20% respectively under the geometry-aware approach.
- Default loss weights improve Shape on 27/30 and Trend on 25/30 cells when applied to GNN and Transformer denoisers.
- A matched ablation isolates the auxiliary supervision, not extra inputs or added capacity, as the driver of gains.
Where Pith is reading between the lines
- If explicit geometric relations improve diffusion for tabular data, the same signals may help other structured generative tasks that currently rely on implicit learning.
- The architecture-agnostic transfer of default weights suggests the bias could be added as a lightweight module to existing tabular pipelines without per-model retuning.
- More efficient parameter use could expand privacy-preserving data sharing to settings with strict compute limits.
Load-bearing premise
That pairwise angles and lengths computed from column value differences constitute the right explicit relational signals and that default loss weights chosen for the MLP transfer without retuning to GNN and Transformer denoisers.
What would settle it
Training the same MLP denoiser on the ten benchmark datasets without the auxiliary geometric targets and observing no reduction in Shape or Trend error relative to the unaugmented baseline.
Figures

read the original abstract
Tabular synthesis is critical for privacy-preserving sharing and augmentation, yet diffusion models rely on implicit mechanisms to capture inter-column relationships. We introduce Geometry-Aware Tabular Diffusion (GATD), which augments tabular diffusion denoisers with pairwise angles and lengths computed from column value differences and used as inputs and auxiliary targets. Our MLP instantiation achieves state-of-the-art benchmark performance while using 3.5x fewer parameters on average (up to 25x for classification tasks): on ten datasets, it wins 8/10 Shape, 7/10 Trend, and 9/10 downstream utility (F1/RMSE), reducing Shape and Trend error by 27% and 20%. Default loss weights transfer to GNN and Transformer denoisers, improving Shape on 27/30 and Trend on 25/30 architecture-dataset cells. A matched ablation shows supervision (not extra inputs or capacity) drives the gain. This shows explicit relational supervision is a portable inductive bias for tabular diffusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Geometry-Aware Tabular Diffusion (GATD), which augments tabular diffusion denoisers with pairwise angles and lengths computed from column value differences, used both as additional inputs and as auxiliary supervision targets. The central empirical claims are that an MLP instantiation achieves SOTA results on ten datasets (winning 8/10 on Shape, 7/10 on Trend, 9/10 on downstream utility) while using 3.5× fewer parameters on average, that default loss weights transfer without retuning to GNN and Transformer denoisers (improving 27/30 and 25/30 architecture-dataset cells), and that a matched ablation isolates the benefit to the explicit supervision rather than extra inputs or capacity.
Significance. If the reported gains and cross-architecture transfer are robust, the work supplies a concrete, architecture-agnostic mechanism for injecting explicit relational inductive bias into tabular diffusion. The matched ablation and the parameter-efficiency numbers are genuine strengths that would, if verified, make the portability argument load-bearing for future tabular synthesis research.
major comments (3)
- [Abstract] Abstract: the headline performance numbers (8/10 Shape wins, 27 % and 20 % error reductions, 3.5× parameter reduction) are stated without error bars, confidence intervals, or any mention of statistical significance testing. Because these quantities are the sole support for both the SOTA claim and the portability conclusion, their reliability cannot be assessed from the given information.
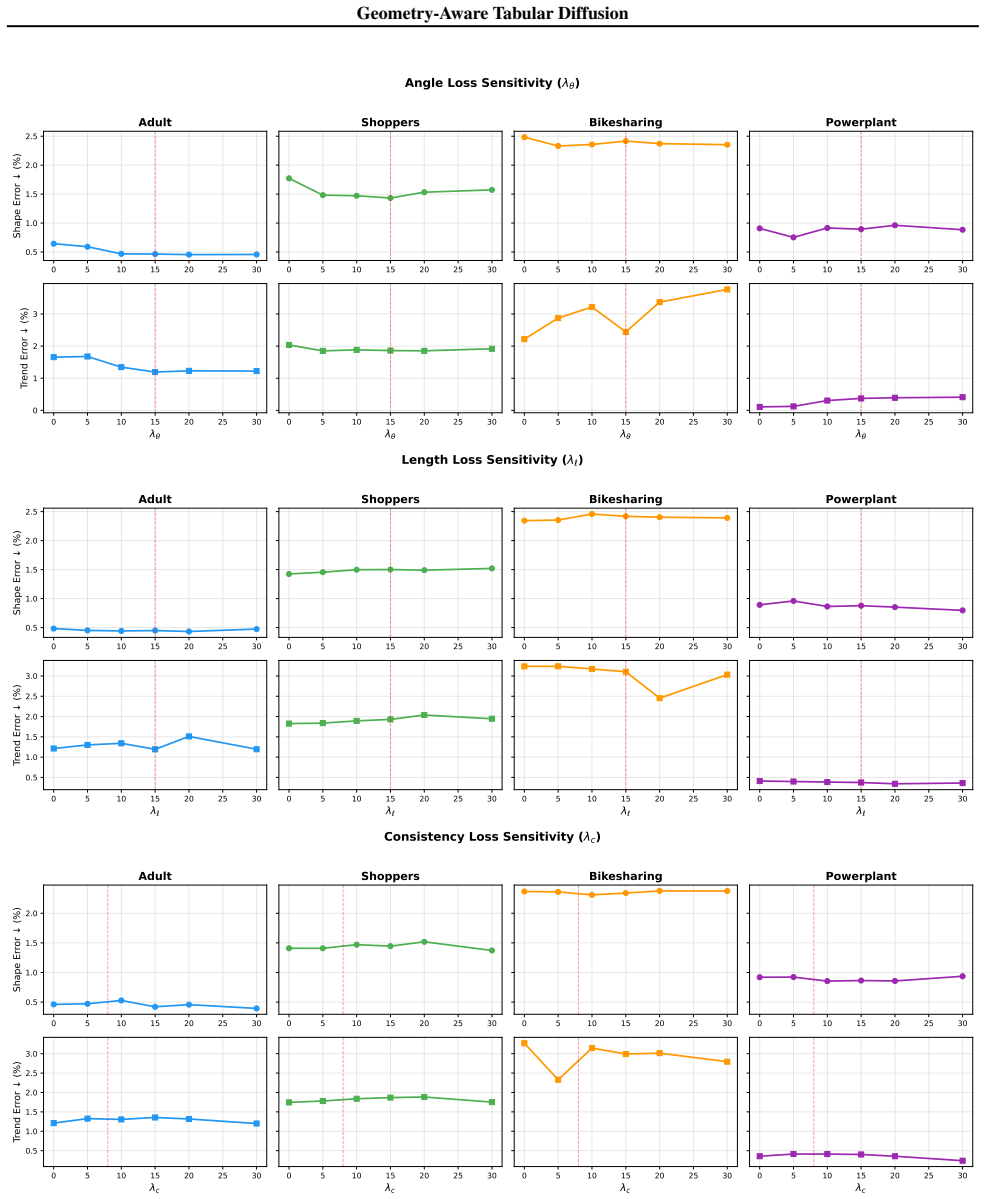
- [Abstract] Abstract (final paragraph) and ablation description: the claim that “default loss weights transfer” to GNN and Transformer denoisers rests on a single set of weights chosen for the MLP; no sensitivity analysis or re-tuning experiment is reported for the other architectures. The matched ablation that isolates supervision from capacity is described only for the MLP, so it does not directly substantiate the portability statement when the denoiser inductive bias changes.
- [Abstract] Abstract: the definitions and computation procedures for the Shape and Trend metrics are not supplied. These metrics are the primary evaluation axes for both the MLP results and the 27/30–25/30 transfer counts; without their precise formulation it is impossible to judge whether the reported improvements are comparable across architectures or datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance numbers (8/10 Shape wins, 27 % and 20 % error reductions, 3.5× parameter reduction) are stated without error bars, confidence intervals, or any mention of statistical significance testing. Because these quantities are the sole support for both the SOTA claim and the portability conclusion, their reliability cannot be assessed from the given information.
Authors: We agree that reliability indicators would strengthen the abstract. The main experimental section reports results averaged over multiple seeds; we will add standard deviations and note statistical significance (via paired tests) for the aggregate headline figures in the revised abstract and results summary. revision: yes
-
Referee: [Abstract] Abstract (final paragraph) and ablation description: the claim that “default loss weights transfer” to GNN and Transformer denoisers rests on a single set of weights chosen for the MLP; no sensitivity analysis or re-tuning experiment is reported for the other architectures. The matched ablation that isolates supervision from capacity is described only for the MLP, so it does not directly substantiate the portability statement when the denoiser inductive bias changes.
Authors: The reported transfer uses the MLP-derived weights without modification, which directly tests the portability hypothesis. No architecture-specific re-tuning or sensitivity sweep was performed, as that would contradict the zero-shot transfer claim. We will revise the text to explicitly state that weights were not re-tuned and to clarify that the matched ablation is MLP-specific while the cross-architecture gains provide complementary evidence of portability. revision: partial
-
Referee: [Abstract] Abstract: the definitions and computation procedures for the Shape and Trend metrics are not supplied. These metrics are the primary evaluation axes for both the MLP results and the 27/30–25/30 transfer counts; without their precise formulation it is impossible to judge whether the reported improvements are comparable across architectures or datasets.
Authors: Shape and Trend are formally defined in Section 4.2 (following the geometric and sequential formulations introduced in the method section). To make the abstract self-contained we will insert a concise parenthetical reference to these definitions in the revised version. revision: yes
Circularity Check
No circularity: empirical benchmarks and ablations are independent of fitted inputs
full rationale
The paper reports benchmark wins, error reductions, and architecture-transfer results on external datasets, supported by a matched ablation isolating supervision. No equations, derivations, or self-citations are shown that reduce any reported quantity to a fitted parameter or input by construction. Claims rest on observable performance metrics rather than self-referential definitions or predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pairwise angles and lengths computed from column value differences capture relevant inter-column relationships for synthesis
Reference graph
Works this paper leans on
-
[1]
B., Mironov, I., Talwar, K., and Zhang, L
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 308–318,
2016
-
[2]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Bronstein, M. M., Bruna, J., Cohen, T., and Veli ˇckovi´c, P. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Xgboost: A scalable tree boosting system,
doi: 10.1145/2939672.2939785. Gorishniy, Y ., Rubachev, I., Khrulkov, V ., and Babenko, A. Revisiting deep learning models for tabular data. In Advances in Neural Information Processing Systems, vol- ume 34, pp. 18932–18943,
-
[4]
Entity Embeddings of Categorical Variables
Guo, C. and Berkhahn, F. Entity embeddings of categorical variables.arXiv preprint arXiv:1604.06737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi: 10.1609/aaai. v34i04.5976. Patki, N., Wedge, R., and Veeramachaneni, K. The synthetic data vault. InIEEE International Conference on Data Science and Advanced Analytics, pp. 399–410,
-
[6]
Su, J., Lu, Y ., Pan, S., Murtadha, A., Wen, B., and Liu, Y
arXiv:2410.20626. Su, J., Lu, Y ., Pan, S., Murtadha, A., Wen, B., and Liu, Y . RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[7]
doi: 10.1016/j.neucom.2023.127063. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Atten- tion is all you need. InAdvances in Neural Information Processing Systems, volume 30,
-
[8]
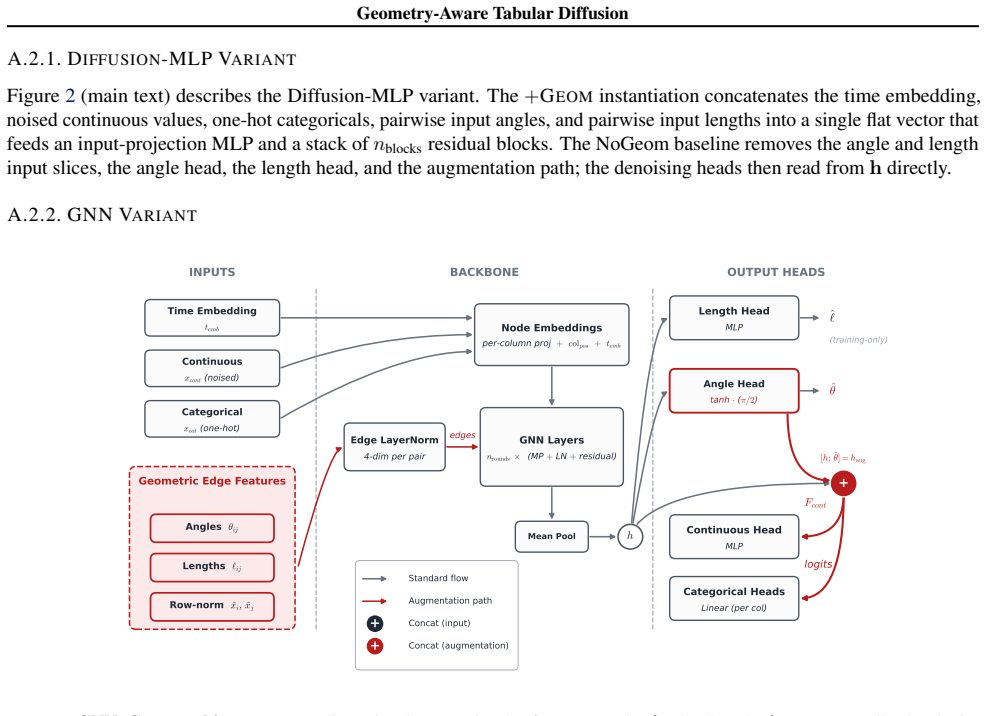
restores all four and routes the predicted angle into the augmentation path in the standard pattern. A.3. Architecture Ablation: Effect of Residual Blocks Table 6 compares 0 vs. 8 residual blocks across all datasets. The pattern is consistent: classification tasks favor 0 blocks for fidelity metrics (Shape, Trend), while regression tasks favor 8 blocks fo...
-
[9]
shows the pattern is supervision-dependent:Inputs Only produces no positive correlation, while every supervised configuration reproduces it. Loss config. SpearmanρSpearmanp Inputs Only -0.63 0.051 Angle Only+0.70 0.025 Angle + Length+0.70 0.025 Full+0.70 0.025 Table 8.Rank correlation between categorical-column count and per-dataset Shape improvement (vs ...
-
[10]
Metric Config Adult Default Diabetes Magic Shoppers Beijing Bikeshare California News Power Avg.Shape NoGeom 0.819±0.04541.17±0.07801.27±0.02100.943±0.1071.58±0.08210.797±0.04240.778±0.07341.00±0.05972.79±0.05181.15±0.1731.23 Inputs Only 0.936±0.05351.16±0.06641.29±0.02630.904±0.07681.79±0.08580.763±0.04110.805±0.07940.959±0.05363.06±0.1561.13±0.1681.28 A...
-
[11]
Single training seed, 20 sampling seeds
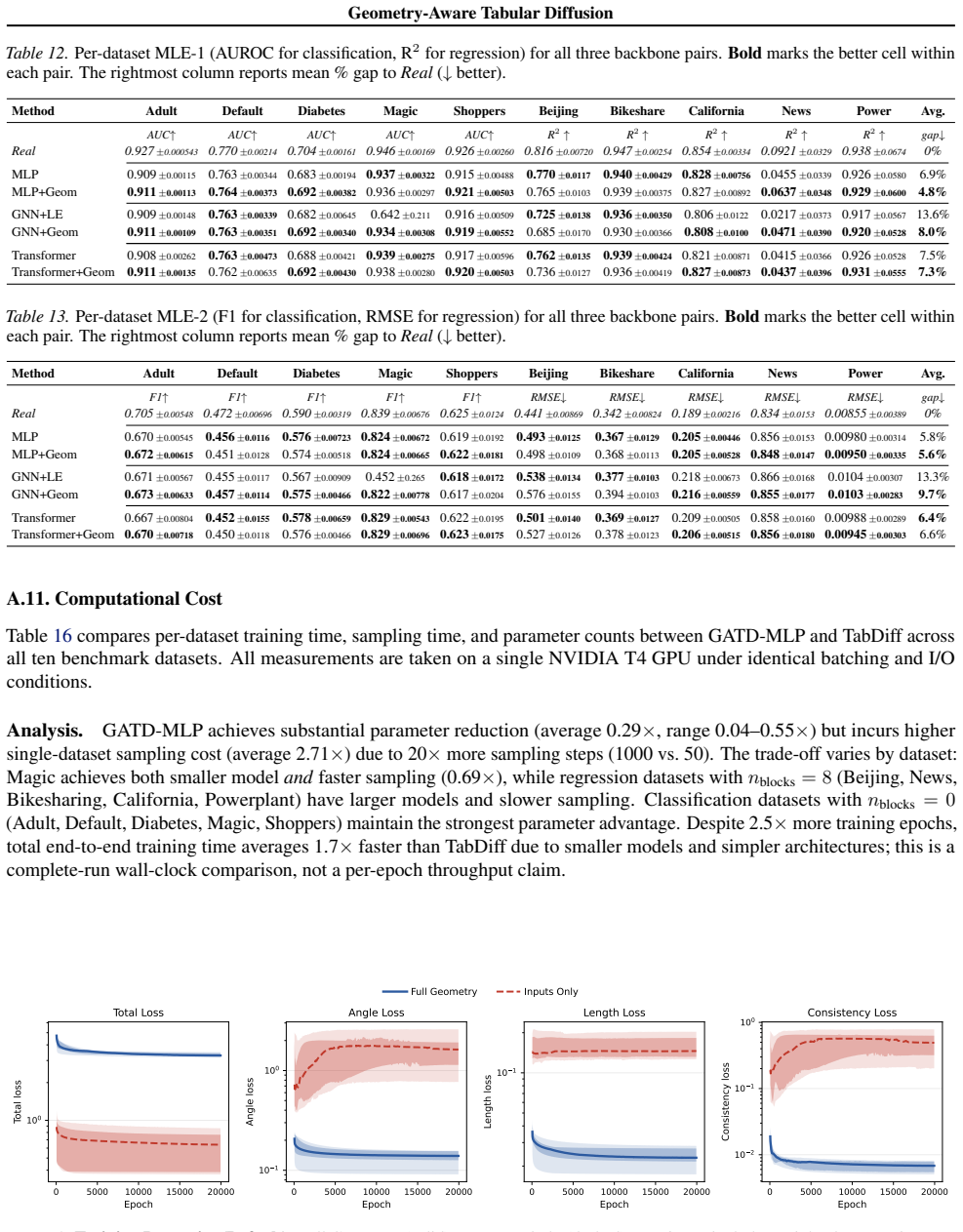
Extended training does not benefit TabDiff, validating our use of their published 8,000-epoch protocol. Single training seed, 20 sampling seeds. Geometry (Ours) TabDiff Ratio (Ours/TabDiff) Dataset Params Train (h) Sample (s) Params Train (h) Sample (s) Params Sample Adult 542K 1.25 47.8 10.6M 3.62 34.6 0.05×1.38× Beijing 4.67M 3.18 135.7 10.6M 4.21 33.0 ...
2000
-
[12]
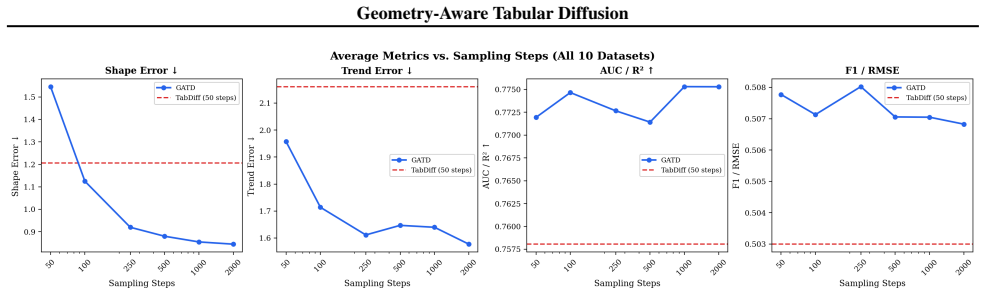
Performance improves monotonically up to 2000 steps with no clear saturation point in our evaluated range
compare GATD at each step budget against TabDiff at 50 steps. Performance improves monotonically up to 2000 steps with no clear saturation point in our evaluated range. Configuration Shape↓Trend↓MLE-1 gap↓MLE-2 gap↓Wins (S/T/M1/M2) TabDiff (50 steps) 1.187 2.048 11.4% 9.7% — GATD (50 steps) 1.546 1.957 4.6% 7.2% 3/4/5/8 GATD (100 steps) 1.125 1.714 4.9% 5...
2000
-
[13]
Wall-clock cost
reports per-step-budget performance. At 50 sampling steps, GATD already wins 3 of 4 metrics in aggregate against TabDiff (Trend 1.96 vs 2.05; MLE-1 4.6% vs 11.4% gap; MLE-2 7.2% vs 9.7% gap), losing only on Shape (1.55 vs 1.19). By 100 sampling steps, GATD wins all 4 aggregate metrics. The story tightens further as step count increases: aggregate Shape er...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.