Cross-Modal Hierarchical Fusion for from Multi-Sensor Ground Observation
Pith reviewed 2026-07-01 07:17 UTC · model grok-4.3
The pith
AtmoFuseNet fuses sky camera imagery with radar and ceilometer data to produce 4D cloud microphysical fields and wind vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
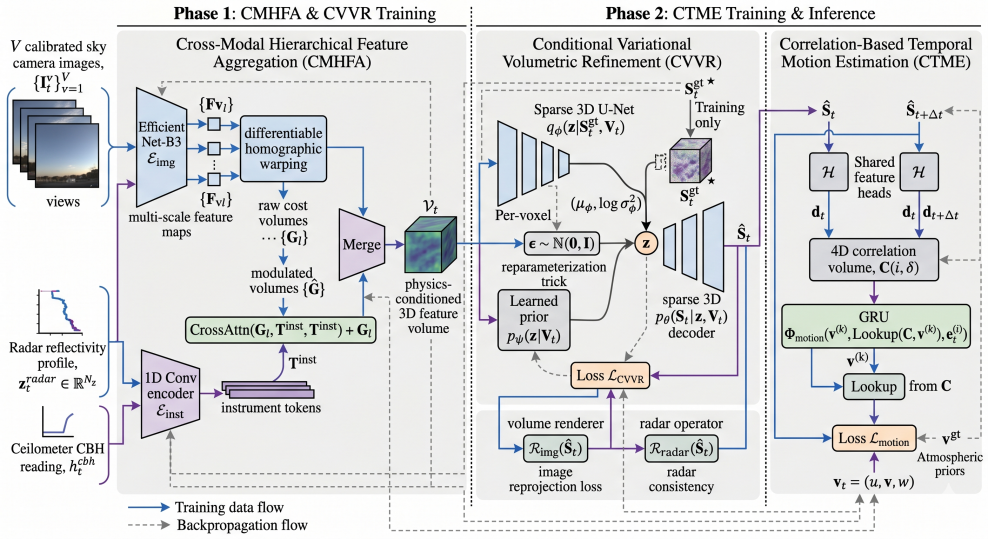
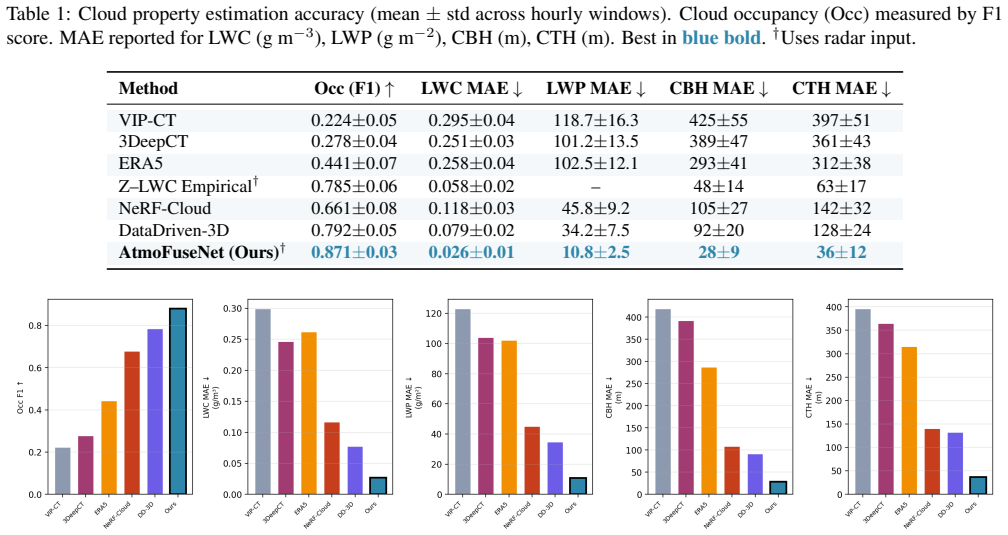
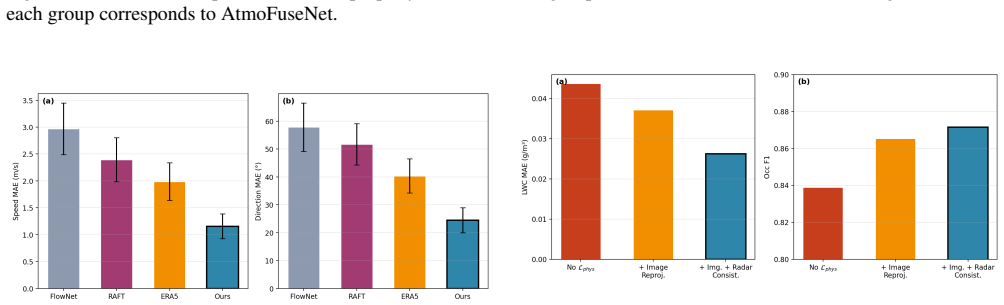
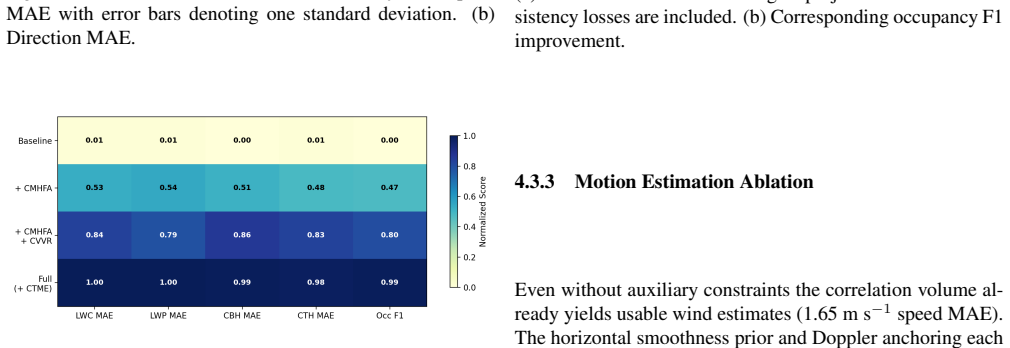
AtmoFuseNet produces 4D estimates of cloud state and wind by first applying cross-modal hierarchical aggregation to combine image feature pyramids with instrument-derived vertical profiles through layer-wise cross-attention, then using a conditional variational refinement module to map the volume to physically consistent microphysical fields under differentiable radar and image forward models, and finally applying a correlation-based motion estimator to recover per-voxel 3D wind vectors; on collocated observations from a semi-arid site this yields 0.026 g m^{-3} liquid water content MAE and 1.18 m s^{-1} wind speed MAE while outperforming existing baselines, with ablations confirming the con
What carries the argument
The cross-modal hierarchical aggregation module that merges image feature pyramids with vertical profiles via layer-wise cross-attention, followed by conditional variational refinement under differentiable forward models.
If this is right
- Sparse ground instruments can support dense volumetric cloud reconstruction in both space and time.
- Per-voxel three-dimensional wind vectors become recoverable from consecutive reconstructed volumes.
- Each of the three stages contributes measurably to final accuracy according to the ablation results.
- The fused output improves upon existing single-instrument or simpler fusion retrieval baselines.
Where Pith is reading between the lines
- The same staged architecture could be tested on data from other climate regimes to check whether the reported errors generalize.
- The differentiable forward models open the possibility of joint training with additional sensor types not used in the original experiments.
- The motion estimation step may enable short-term nowcasting applications if the reconstruction latency is reduced.
- Extending the framework to include additional microphysical variables such as ice water content would test the limits of the refinement module.
Load-bearing premise
The conditional variational refinement module produces physically consistent microphysical fields when optimized under the differentiable radar and image forward models.
What would settle it
Independent validation measurements at the same or similar sites that show liquid water content mean absolute error above 0.026 g m^{-3} or wind speed error above 1.18 m s^{-1} would falsify the reported accuracy.
Figures

read the original abstract
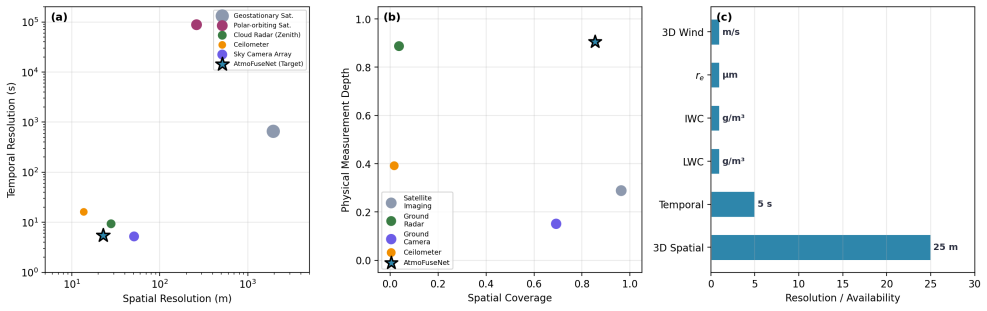
Dense volumetric reconstruction of cloud microphysical fields from sparse ground-based instruments remains an open problem, largely because the available measurements are heterogeneous in both modality and spatial coverage. We present AtmoFuseNet, a framework that fuses multi-view sky camera imagery with millimeter-wave cloud radar and ceilometer observations to produce 4D (three spatial dimensions plus time) estimates of cloud state and wind. The method operates in three stages: a cross-modal hierarchical aggregation module that combines image feature pyramids with instrument-derived vertical profiles through layer-wise cross-attention; a conditional variational refinement module that maps the resulting volume to physically consistent microphysical fields under differentiable radar and image forward models; and a correlation-based motion estimator that recovers per-voxel 3D wind vectors from consecutive volumetric reconstructions. On collocated observations from a semi-arid site, AtmoFuseNet reaches 0.026 g m^-3 liquid water content MAE and 1.18 m s^-1 wind speed MAE, improving over existing retrieval baselines. Ablation experiments isolate the contribution of each module.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AtmoFuseNet, a three-stage neural framework for dense 4D volumetric reconstruction of cloud microphysical fields (liquid water content, etc.) and 3D wind vectors from heterogeneous ground-based sensors: multi-view sky cameras, millimeter-wave cloud radar, and ceilometer. Stage 1 performs cross-modal hierarchical aggregation via layer-wise cross-attention between image feature pyramids and vertical profiles; Stage 2 applies conditional variational refinement optimized against differentiable radar and image forward models; Stage 3 estimates motion via correlation. On collocated observations from a semi-arid site the method reports MAEs of 0.026 g m^{-3} (LWC) and 1.18 m s^{-1} (wind speed), outperforming retrieval baselines, supported by ablation studies.
Significance. If the physical-consistency claims of the variational refinement stage can be substantiated with closure tests, the work would represent a meaningful advance in multi-modal atmospheric remote sensing by enabling physically constrained 4D cloud-state estimation from sparse ground instruments. The absence of such verification currently limits the assessed significance.
major comments (2)
- [Abstract] The claim that the conditional variational refinement produces physically consistent microphysical fields rests on optimization under differentiable forward models, yet no forward-model residual statistics, closure-test results, or quantitative checks on held-out collocated observations are reported. This verification is load-bearing for interpreting the reported MAEs as evidence of successful 4D reconstruction rather than statistical memorization.
- [Abstract] Numerical results are presented without accompanying information on dataset size, number of collocated samples, definition of the retrieval baselines, error bars, cross-validation procedure, or details of the differentiable forward models, preventing independent evaluation of the stated improvements (0.026 g m^{-3} LWC MAE, 1.18 m s^{-1} wind MAE).
minor comments (1)
- The manuscript title appears truncated ("Cross-Modal Hierarchical Fusion for from Multi-Sensor Ground Observation"); consider completing it for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of reproducibility and physical consistency. We will revise the manuscript to incorporate the requested details and verifications as outlined below.
read point-by-point responses
-
Referee: [Abstract] The claim that the conditional variational refinement produces physically consistent microphysical fields rests on optimization under differentiable forward models, yet no forward-model residual statistics, closure-test results, or quantitative checks on held-out collocated observations are reported. This verification is load-bearing for interpreting the reported MAEs as evidence of successful 4D reconstruction rather than statistical memorization.
Authors: We agree that the current version does not report forward-model residual statistics, closure-test results, or quantitative checks on held-out data. While the variational stage is optimized against the differentiable forward models, these explicit verifications are absent. In revision we will add a dedicated analysis section with residual statistics, closure tests on held-out collocated observations, and quantitative consistency checks to support the physical-consistency claims and strengthen interpretation of the reported MAEs. revision: yes
-
Referee: [Abstract] Numerical results are presented without accompanying information on dataset size, number of collocated samples, definition of the retrieval baselines, error bars, cross-validation procedure, or details of the differentiable forward models, preventing independent evaluation of the stated improvements (0.026 g m^{-3} LWC MAE, 1.18 m s^{-1} wind MAE).
Authors: We acknowledge that these experimental details are not summarized in the abstract and are insufficiently highlighted for independent evaluation. The full manuscript contains some of this information in the methods and experiments sections, but we will expand both the abstract and main text to report dataset size, number of collocated samples, explicit definitions of the retrieval baselines, error bars derived from cross-validation, the cross-validation procedure, and additional specifics of the differentiable forward models. revision: yes
Circularity Check
No significant circularity detected; results presented as empirical outcomes.
full rationale
The provided abstract and context describe a three-stage pipeline with MAEs reported on collocated observations, treated as independent empirical results against baselines. No equations, fitting procedures, or self-citations are quoted that would reduce any prediction or claim to its inputs by construction. The conditional variational refinement is described as an optimization step under forward models, but without specific self-referential definitions or load-bearing self-citations that create circularity. This aligns with the default expectation that most papers lack circularity; the reported improvements are not shown to be forced by definition or prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. C. Allmen and W. P. Kegelmeyer. The computa- tion of cloud-base height from paired whole-sky imag- ing cameras.Journal of Atmospheric and Oceanic Tech- nology, 13, 1996
1996
-
[2]
Accurate medium-range global weather forecasting with 3D neural networks
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3D neural networks. Nature, 619(7970):533–538, 2023
2023
-
[3]
MVS- NeRF: Fast generalizable radiance field reconstruc- tion from multi-view stereo
Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaosong Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. MVS- NeRF: Fast generalizable radiance field reconstruc- tion from multi-view stereo. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 14124–14133, 2021
2021
-
[4]
Intent: Invari- ance and discrimination-aware noise mitigation for ro- bust composed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Intent: Invari- ance and discrimination-aware noise mitigation for ro- bust composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[5]
Invariance and discrimination-aware noise mitigation for robust com- posed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Invariance and discrimination-aware noise mitigation for robust com- posed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 20463–20471, 2026
2026
-
[6]
Learning phrase rep- resentations using RNN encoder–decoder for statistical machine translation
Kyunghyun Cho, Bart van Merrienboer, Caglar Gul- cehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase rep- resentations using RNN encoder–decoder for statistical machine translation. InProceedings of the 2014 Confer- ence on Empirical Methods in Natural Language Pro- cessing, 2014
2014
-
[7]
4D spatio-temporal ConvNets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4D spatio-temporal ConvNets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3075–3084, 2019
2019
-
[8]
Savoy, Yee Hui Lee, and Stefan Winkler
Soumyabrata Dev, Florian M. Savoy, Yee Hui Lee, and Stefan Winkler. CloudSegNet: A deep network for ny- chthemeron cloud image segmentation.IEEE Transac- tions on Geoscience and Remote Sensing, 57(12):9410– 9422, 2019
2019
-
[9]
FlowNet: Learning optical flow with convolutional net- works
Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick 9 van der Smagt, Daniel Cremers, and Thomas Brox. FlowNet: Learning optical flow with convolutional net- works. InProceedings of the IEEE International Con- ference on Computer Vision, pages 2758–2766, 2015
2015
-
[10]
Academic Press, 2nd edi- tion, 1993
Richard J Doviak and Du ˇsan S Zrni ´c.Doppler Radar and Weather Observations. Academic Press, 2nd edi- tion, 1993
1993
-
[11]
Scott Frisch, Graham Feingold, Christopher W
A. Scott Frisch, Graham Feingold, Christopher W. Fairall, Taneil Uttal, and Jefferson B. Snider. On cloud radar and microwave radiometer measurements of stra- tus cloud liquid water profiles.Journal of Geophysical Research: Atmospheres, 103(D19):23195–23197, 1998
1998
-
[12]
Air-know: Arbiter-calibrated knowledge-internalizing robust network for composed image retrieval
Zhiheng Fu, Yupeng Hu, Qianyun Yang, Shiqi Zhang, Zhiwei Chen, and Zixu Li. Air-know: Arbiter-calibrated knowledge-internalizing robust network for composed image retrieval. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[13]
Modeling the dynamics of PDE systems with physics-constrained deep auto-regressive networks.Journal of Computa- tional Physics, 403:109056, 2020
Nicholas Geneva and Nicholas Zabaras. Modeling the dynamics of PDE systems with physics-constrained deep auto-regressive networks.Journal of Computa- tional Physics, 403:109056, 2020
2020
-
[14]
Cambridge University Press, 2nd edition, 2003
Richard Hartley and Andrew Zisserman.Multiple View Geometry in Computer Vision. Cambridge University Press, 2nd edition, 2003
2003
-
[15]
Au- tomatic cloud classification of whole sky images.Atmo- spheric Measurement Techniques, 3(3):557–567, 2010
Anna Heinle, Andreas Macke, and Anand Srivastav. Au- tomatic cloud classification of whole sky images.Atmo- spheric Measurement Techniques, 3(3):557–567, 2010
2010
-
[16]
The ERA5 global reanalysis.Quarterly Journal of the Royal Meteorological Society, 146(730):1999–2049, 2020
Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hira- hara, Andr ´as Hor ´anyi, Joaqu ´ın Mu˜noz-Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. The ERA5 global reanalysis.Quarterly Journal of the Royal Meteorological Society, 146(730):1999–2049, 2020
1999
-
[17]
Denois- ing diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models. InAdvances in Neu- ral Information Processing Systems, volume 33, pages 6840–6851, 2020
2020
-
[18]
Horn and Brian G
Berthold K.P. Horn and Brian G. Schunck. Determining optical flow.Artificial Intelligence, 17(1–3):185–203, 1981
1981
-
[19]
Refine: Com- posed video retrieval via shared and differential seman- tics enhancement.ACM Transactions on Multimedia Computing, Communications and Applications, 2026
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhi- heng Fu, Mingzhu Xu, and Liqiang Nie. Refine: Com- posed video retrieval via shared and differential seman- tics enhancement.ACM Transactions on Multimedia Computing, Communications and Applications, 2026
2026
-
[20]
Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang
George Em Karniadakis, Ioannis G. Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics- informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[21]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations, 2014
2014
-
[22]
Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Will- son, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Wei- hua Hu, et al. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
2023
-
[23]
Airborne three-dimensional cloud to- mography
Aviad Levis, Yoav Y Schechner, Amit Aides, and An- thony B Davis. Airborne three-dimensional cloud to- mography. InProceedings of the IEEE International Conference on Computer Vision, pages 3379–3387, 2015
2015
-
[24]
Multiple-scattering microphysics tomography
Aviad Levis, Yoav Y Schechner, and Anthony B Davis. Multiple-scattering microphysics tomography. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6740–6749, 2017
2017
-
[25]
Multi-view polarimetric scattering cloud tomography and retrieval of droplet size
Aviad Levis, Yoav Y Schechner, and Anthony B Davis. Multi-view polarimetric scattering cloud tomography and retrieval of droplet size. InEuropean Conference on Computer Vision, 2020
2020
-
[26]
Exploring efficient open-vocabulary segmentation in the remote sensing,
Bingyu Li, Haocheng Dong, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. Exploring efficient open- vocabulary segmentation in the remote sensing.arXiv preprint arXiv:2509.12040, 2025
-
[27]
Exploring the underwater world segmentation without extra training,
Bingyu Li, Tao Huo, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. Exploring the underwater world segmentation without extra training.arXiv preprint arXiv:2511.07923, 2025
-
[28]
Bingyu Li, Feiyu Wang, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. Maris: Marine open- vocabulary instance segmentation with geometric en- hancement and semantic alignment.arXiv preprint arXiv:2510.15398, 2025
-
[29]
Stitchfusion: Weaving any visual modal- ities to enhance multimodal semantic segmentation
Bingyu Li, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. Stitchfusion: Weaving any visual modal- ities to enhance multimodal semantic segmentation. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 1308–1317, 2025
2025
-
[30]
U3m: Unbiased multiscale modal fusion model for multimodal semantic segmentation.Pattern Recognition, 168:111801, 2025
Bingyu Li, Da Zhang, Zhiyuan Zhao, Junyu Gao, and Xuelong Li. U3m: Unbiased multiscale modal fusion model for multimodal semantic segmentation.Pattern Recognition, 168:111801, 2025
2025
-
[31]
Retrack: Evidence-driven dual-stream directional anchor calibra- tion network for composed video retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. Retrack: Evidence-driven dual-stream directional anchor calibra- tion network for composed video retrieval. InProceed- ings of the AAAI Conference on Artificial Intelligence, 2026. 10
2026
-
[32]
Conesep: Cone-based ro- bust noise-unlearning compositional network for com- posed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Mingyu Zhang, Zhi- heng Fu, and Liqiang Nie. Conesep: Cone-based ro- bust noise-unlearning compositional network for com- posed image retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2026
2026
-
[33]
Habit: Chrono-synergia robust progressive learning framework for composed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qin- lei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono-synergia robust progressive learning framework for composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6762–6770, 2026
2026
-
[34]
Habit: Chrono-synergia robust progressive learning framework for composed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qin- lei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono-synergia robust progressive learning framework for composed image retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[35]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[36]
NeRF: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. InEuropean Conference on Computer Vision, pages 405–421. Springer, 2020
2020
-
[37]
Determina- tion of the optical thickness and effective particle radius of clouds from reflected solar radiation measurements
Teruyuki Nakajima and Michael D King. Determina- tion of the optical thickness and effective particle radius of clouds from reflected solar radiation measurements. Part I: Theory.Journal of the Atmospheric Sciences, 47(15):1878–1893, 1990
1990
-
[38]
King, Steven A
Steven Platnick, Michael D. King, Steven A. Ackerman, W. Paul Menzel, Bryan A. Baum, J ´erˆome C. Ri´edi, and Rong A. Frey. The MODIS cloud products: Algorithms and examples from terra.IEEE Transactions on Geo- science and Remote Sensing, 41(2):459–473, 2003
2003
-
[39]
Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam, Matthew Willson, et al
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, Tom R. Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam, Matthew Willson, et al. Proba- bilistic weather forecasting with machine learning.Na- ture, 637(8044):84–90, 2025
2025
-
[40]
Maziar Raissi, Paris Perdikaris, and George E Karni- adakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equa- tions.Journal of Computational Physics, 378:686–707, 2019
2019
-
[41]
VIP-CT: Variable importance parametric cloud tomog- raphy
Roi Ronen, Vadim Holodovsky, and Yoav Y Schechner. VIP-CT: Variable importance parametric cloud tomog- raphy. InEuropean Conference on Computer Vision, 2022
2022
-
[42]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 234–241. Springer, 2015
2015
-
[43]
Ayushman Sarkar, Mohd Yamani Idna Idris, and Zhenyu Yu. Reasoning in computer vision: Taxonomy, models, tasks, and methodologies.arXiv preprint arXiv:2508.10523, 2025
-
[44]
A large eddy simula- tion intercomparison study of shallow cumulus convec- tion.Journal of the Atmospheric Sciences, 60(10):1201– 1219, 2003
A Pier Siebesma, Christopher S Bretherton, An- drew Brown, Andreas Chlond, Joan Cuxart, Peter G Duynkerke, Hongli Jiang, Marat Khairoutdinov, David Lewellen, Chin-Hoh Moeng, et al. A large eddy simula- tion intercomparison study of shallow cumulus convec- tion.Journal of the Atmospheric Sciences, 60(10):1201– 1219, 2003
2003
-
[45]
Learning structured output representation using deep conditional generative models
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. InAdvances in Neural Information Processing Systems, 2015
2015
-
[46]
De- noising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. De- noising diffusion implicit models. InInternational Con- ference on Learning Representations, 2021
2021
-
[47]
Stephens
Graeme L. Stephens. Cloud feedbacks in the cli- mate system: A critical review.Journal of Climate, 18(2):237–273, 2005
2005
-
[48]
Mingxing Tan and Quoc V . Le. EfficientNet: Rethink- ing model scaling for convolutional neural networks. In International Conference on Machine Learning. PMLR, 2019
2019
-
[49]
RAFT: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. RAFT: Recurrent all-pairs field transforms for optical flow. InEuropean Con- ference on Computer Vision, pages 402–419. Springer, 2020
2020
-
[50]
van Heerwaarden, Bart J
Chiel C. van Heerwaarden, Bart J. H. van Stratum, Thijs Heus, Jeremy A. Gibbs, Evgeni Fedorovich, and Juan Pedro Mellado. MicroHH 1.0: A computational fluid dynamics code for direct numerical simulation and large-eddy simulation of atmospheric boundary layer flows.Geoscientific Model Development, 10(8):3145– 3165, 2017
2017
-
[51]
Three-dimensional scene flow
Sundar Vedula, Simon Baker, Peter Rander, Robert Collins, and Takeo Kanade. Three-dimensional scene flow. InIEEE International Conference on Computer Vision, 1999
1999
-
[52]
Velden, Christopher M
Christopher S. Velden, Christopher M. Hayden, Steven J. Nieman, W. Paul Menzel, Steve Wanzong, and James S. Goerss. Recent innovations in deriving tro- pospheric winds from meteorological satellites.Bulletin of the American Meteorological Society, 86(2):205–223, 2005. 11
2005
-
[53]
MVSNet: Depth inference for unstructured multi- view stereo
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. MVSNet: Depth inference for unstructured multi- view stereo. InProceedings of the European Conference on Computer Vision, pages 767–783, 2018
2018
-
[54]
pixelNeRF: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelNeRF: Neural radiance fields from one or few images. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[55]
Zhenyu Yu, Mohd Yamani Idna Idris, Hua Wang, Pei Wang, Junyi Chen, and Kun Wang. From physics to foundation models: A review of ai-driven quan- titative remote sensing inversion.arXiv preprint arXiv:2507.09081, 2025
-
[56]
Dinov3-powered multi-task founda- tion model for quantitative remote sensing estimation (student abstract)
Zhenyu Yu, Mohd Yamani Idna Idris, Pei Wang, and Rizwan Qureshi. Dinov3-powered multi-task founda- tion model for quantitative remote sensing estimation (student abstract). InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 40, pages 41455– 41456, 2026
2026
-
[57]
Spatiotemporal alignment for remote sens- ing image recovery via terrain-aware diffusion
Zhenyu Yu, Haoran Jiang, Pei Wang, Zizhen Lin, and Yong Xiang. Spatiotemporal alignment for remote sens- ing image recovery via terrain-aware diffusion. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11257–11261. IEEE, 2026
2026
-
[58]
Qrs-trs: Style transfer-based image- to-image translation for carbon stock estimation in quan- titative remote sensing.IEEE Access, 2025
Zhenyu Yu, Jinnian Wang, Hanqing Chen, and Mohd Yamani Idna Idris. Qrs-trs: Style transfer-based image- to-image translation for carbon stock estimation in quan- titative remote sensing.IEEE Access, 2025. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.