BaseRT: Best-in-Class LLM Inference on Apple Silicon via Native Metal
Pith reviewed 2026-07-02 13:24 UTC · model grok-4.3
The pith
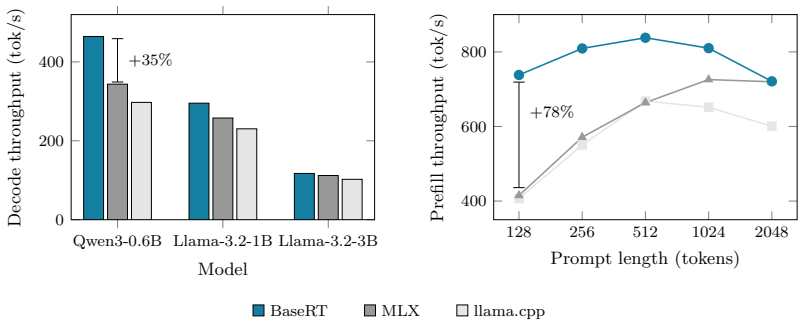
A custom native Metal runtime achieves up to 1.56 times higher LLM decode throughput on Apple Silicon than llama.cpp.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BaseRT is a native Metal inference runtime that supports model families across eight quantization formats on all Apple M-series devices. Through chip-specific kernel fusion, unified memory-aware optimisation, and custom dispatch logic, it reaches up to 1.56x higher decode throughput than llama.cpp and 1.35x higher than MLX, with substantially larger margins on prefill for mixture-of-experts models, delivering best-in-class results from sub-1B to 30B parameter models.
What carries the argument
Native Metal kernels with unified memory-aware optimisation and custom dispatch logic.
Load-bearing premise
The benchmark comparisons are fair and the custom Metal kernels and dispatch logic introduce no unmeasured overheads or selection effects that inflate the reported speedups.
What would settle it
Identical benchmark runs on the same M3 or M4 Pro hardware and models that show equal or lower throughput for BaseRT than for llama.cpp or MLX under matched conditions.
Figures
read the original abstract
We present BaseRT, a native Metal inference runtime for large language models (LLMs) on Apple Silicon, and report the highest inference throughput on this hardware to date. Existing runtimes, including llama.cpp and MLX-based frameworks, incur overhead from abstractions not designed for Metal's execution model or Apple Silicon's unified memory topology. By building natively on Metal with chip-specific kernel fusion, unified memory-aware optimisation, and custom dispatch logic, BaseRT recovers performance that framework-based approaches leave on the table. BaseRT supports a wide range of model families across eight quantisation formats (Q2 to FP16) on all Apple M-series devices. In this paper, we evaluate the Qwen3, Llama 3.2, and Gemma 4 families at Q4 and Q8 quantisation on M3 and M4 Pro devices. BaseRT achieves up to 1.56x higher decode throughput than llama.cpp and up to 1.35x higher than MLX, with substantially larger margins on prefill for mixture-of-experts models, delivering consistent best-in-class throughput from sub-1B to 30B parameter models. These results establish Apple Silicon as a more capable inference platform than previously reported, with direct implications for the emerging edge inference paradigm: as privacy requirements, latency constraints, and cloud cost pressures drive inference toward on-device deployment, performance-optimised local runtimes are a critical enabling layer for this transition. BaseRT is publicly available at https://github.com/basecompute/baseRT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BaseRT, a native Metal-based inference runtime for LLMs on Apple Silicon. It claims to deliver the highest throughput to date by using chip-specific kernel fusion, unified-memory optimizations, and custom dispatch, outperforming llama.cpp (up to 1.56× decode) and MLX (up to 1.35× decode) with larger gains on MoE prefill; the evaluation covers Qwen3, Llama 3.2, and Gemma 4 families at Q4/Q8 on M3 and M4 Pro devices across eight quantization formats.
Significance. If the reported speedups are shown to result from the native Metal implementation rather than unequal baseline tuning, the work would strengthen the case for Apple Silicon as a competitive edge-inference platform and provide a publicly available reference implementation. The absence of any experimental protocol, however, prevents assessment of whether the central empirical claim is reproducible or generalizable.
major comments (3)
- [Abstract] Abstract: the headline speedups (1.56× decode vs llama.cpp, 1.35× vs MLX, larger on MoE prefill) constitute the sole quantitative support for the 'best-in-class' claim, yet the abstract supplies no hardware configuration, model sizes, prompt lengths, batch sizes, thread-binding settings, or confirmation that Metal-specific paths in the baselines were enabled and tuned to their maximum on the identical M3/M4 devices.
- [Abstract] Abstract / Evaluation (implied): no error bars, number of runs, or statistical validation is mentioned for any throughput measurement, making it impossible to determine whether the reported deltas exceed measurement noise or selection effects.
- [Abstract] Abstract: the claim that 'framework-based approaches leave performance on the table' rests on the unverified premise that the llama.cpp and MLX baselines received equivalent optimization effort; without explicit configuration tables or commands, the deltas could arise from unequal tuning rather than the native kernels.
minor comments (2)
- The GitHub link is given but no commit hash or release tag is provided, hindering exact reproduction of the reported binaries.
- [Abstract] The abstract states support for 'all Apple M-series devices' yet reports results only on M3 and M4 Pro; a brief statement on scaling behavior to other chips would improve clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting reproducibility concerns in the abstract and evaluation. We will revise the manuscript to include explicit experimental configurations, statistical details, and baseline tuning information while preserving the core claims supported by the native Metal implementation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline speedups (1.56× decode vs llama.cpp, 1.35× vs MLX, larger on MoE prefill) constitute the sole quantitative support for the 'best-in-class' claim, yet the abstract supplies no hardware configuration, model sizes, prompt lengths, batch sizes, thread-binding settings, or confirmation that Metal-specific paths in the baselines were enabled and tuned to their maximum on the identical M3/M4 devices.
Authors: We agree the abstract is too concise on setup details. The full manuscript already specifies evaluation on Qwen3, Llama 3.2, and Gemma 4 families at Q4/Q8 on M3 and M4 Pro devices. In revision we will expand the abstract with these hardware and model details, add prompt/batch ranges, and insert a reference to the new configuration table that confirms Metal paths were enabled in baselines. revision: yes
-
Referee: [Abstract] Abstract / Evaluation (implied): no error bars, number of runs, or statistical validation is mentioned for any throughput measurement, making it impossible to determine whether the reported deltas exceed measurement noise or selection effects.
Authors: The current version omits run counts and error bars. We will re-run all throughput measurements (decode and prefill) across 5–10 trials per configuration, compute means and standard deviations, and add error bars to all figures plus a methods paragraph describing the protocol. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'framework-based approaches leave performance on the table' rests on the unverified premise that the llama.cpp and MLX baselines received equivalent optimization effort; without explicit configuration tables or commands, the deltas could arise from unequal tuning rather than the native kernels.
Authors: We accept that transparency on baseline configurations is required. Revision will add a dedicated table (and supplementary commands) listing exact llama.cpp and MLX build flags, Metal backend settings, thread bindings, and quantization parameters used on the same M3/M4 devices. This will allow readers to verify equivalent tuning effort; the remaining gains are attributable to BaseRT’s chip-specific kernel fusion and unified-memory dispatch, which are not expressible in the framework APIs. revision: yes
Circularity Check
No circularity: empirical throughput measurements against external baselines with no derivations or fitted predictions.
full rationale
The paper presents an implementation of a native Metal runtime and reports direct benchmark results (decode/prefill throughput) on specific models, quantizations, and devices against llama.cpp and MLX. No equations, parameters, or derivation chain exist that could reduce to self-definition or fitted inputs. Claims rest on external comparisons rather than internal consistency arguments or self-citations. This matches the default case of a self-contained empirical systems paper; benchmark fairness is a methodological concern outside the circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 Q4 Earnings Call.https://abc.xyz/investor, 2026
Alphabet Inc. 2025 Q4 Earnings Call.https://abc.xyz/investor, 2026
2025
-
[2]
Model Rankings.https://openrouter.ai/rankings, 2026
OpenRouter. Model Rankings.https://openrouter.ai/rankings, 2026. Accessed: 3 April 2026
2026
-
[3]
The State of AI in 2025: Agents, Innovation, and Transformation
Alex Singla, Alexander Sukharevsky, Lareina Yee, and Michael Chui. The State of AI in 2025: Agents, Innovation, and Transformation. Technical report, McKinsey & Company, QuantumBlack, November 2025. URLhttps://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
2025
-
[4]
The next big shifts in AI workloads and hyperscaler strategies
Chhavi Arora, Marc Sorel, Pankaj Sachdeva, et al. The next big shifts in AI workloads and hyperscaler strategies. McKinsey & Company, December 2025. URL https://www.mckinsey.com/industries/te chnology-media-and-telecommunications/our-insights/the-next-big-shifts-in-ai-workloa ds-and-hyperscaler-strategies. Accessed: April 2026
2025
-
[5]
Artificial intelligence risk management framework: Generative artificial intelligence profile
National Institute of Standards and Technology. Artificial intelligence risk management framework: Generative artificial intelligence profile. Technical Report NIST AI 600-1, U.S. Department of Commerce, July 2024. URLhttps://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
2024
-
[6]
Gartner predicts 40% of AI data breaches will arise from cross-border GenAI misuse by 2027
Joerg Fritsch and Gartner, Inc. Gartner predicts 40% of AI data breaches will arise from cross-border GenAI misuse by 2027. Gartner Newsroom, February 2025. URL https://www.gartner.com/en/new sroom/press-releases/2025-02-17-gartner-predicts-forty-percent-of-ai-data-breaches-w ill-arise-from-cross-border-genai-misuse-by-2027. Accessed: April 2026
2027
-
[7]
Edge-First Language Model Inference: Models, Metrics, and Tradeoffs
SiYoung Jang and Roberto Morabito. Edge-First Language Model Inference: Models, Metrics, and Tradeoffs. In45th IEEE International Conference on Distributed Computing Systems (ICDCS), 2025. URLhttps://arxiv.org/abs/2505.16508
-
[8]
DaDu-Corki: Algorithm-Architecture Co-Design for Embodied AI-powered Robotic Manipulation
Xuan Huang et al. DaDu-Corki: Algorithm-Architecture Co-Design for Embodied AI-powered Robotic Manipulation. InProceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA), 2025. URLhttps://arxiv.org/abs/2407.04292
-
[9]
Tula Masterman et al. Agentic Artificial Intelligence: Architectures, Taxonomies, and Evaluation of Large Language Model Agents.arXiv preprint arXiv:2601.12560, 2026. URL https://arxiv.org/abs/ 2601.12560
-
[10]
others. Sherlock: Reliable and Efficient Agentic Workflow Execution with Selective Verification and Speculative Execution.arXiv preprint arXiv:2511.00330, 2025. URL https://arxiv.org/abs/2511.0 0330
-
[11]
Anthropic Status Page: Incident History
Anthropic. Anthropic Status Page: Incident History. https://status.anthropic.com, 2026. Accessed: April 2026. Documented 167 incidents between October 2025 and April 2026
2026
-
[12]
OpenAI Status Page: Incident History
OpenAI. OpenAI Status Page: Incident History. https://status.openai.com, 2026. Accessed: April 2026
2026
-
[13]
The New Economics of Enterprise Technology in an AI World
McKinsey & Company. The New Economics of Enterprise Technology in an AI World. https: //www.mckinsey.com/capabilities/tech-and-ai/our-insights/, May 2025. 10
2025
-
[14]
Snapdragon X Elite
Qualcomm. Snapdragon X Elite. https://www.qualcomm.com/laptops/products/snapdragon-x-e lite
-
[15]
Intel Achieves First, Only Full NPU Support in MLPerf Client v0.6.https://newsroom.intel.com, 2025
Intel. Intel Achieves First, Only Full NPU Support in MLPerf Client v0.6.https://newsroom.intel.com, 2025
2025
-
[16]
Vitis AI Execution Provider
ONNX Runtime. Vitis AI Execution Provider. https://onnxruntime.ai/docs/execution-provide rs/
-
[17]
Afsara Benazir and Felix Xiaozhu Lin. Profiling Large Language Model Inference on Apple Silicon: A Quantization Perspective.arXiv preprint arXiv:2508.08531, 2025
-
[18]
Artificial intelligence index report 2025,
Nestor Maslej et al. Artificial Intelligence Index Report 2025. Technical report, Stanford Institute for Human-Centered Artificial Intelligence (HAI), 2025. arXiv:2504.07139
-
[19]
Jon Saad-Falcon, Avanika Narayan, Hakki Orhun Akengin, J. Wes Griffin, Herumb Shandilya, Adrian Gamarra Lafuente, Medhya Goel, Rebecca Joseph, Shlok Natarajan, Etash Kumar Guha, Shang Zhu, Ben Athiwaratkun, John Hennessy, Azalia Mirhoseini, and Christopher R´ e. Intelligence per Watt: Measuring Intelligence Efficiency of Local AI.arXiv preprint arXiv:2511...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
llama.cpp: LLM inference in C/C++
Georgi Gerganov et al. llama.cpp: LLM inference in C/C++. https://github.com/ggml-org/llama .cpp, 2023
2023
-
[21]
MLX: Efficient and flexible machine learning on Apple silicon.https://github.com/ml-explore/mlx, 2023
Awni Hannun, Jagrit Digani, Angelos Katharopoulos, and Ronan Collobert. MLX: Efficient and flexible machine learning on Apple silicon.https://github.com/ml-explore/mlx, 2023
2023
-
[22]
MLX documentation
Apple Machine Learning Research. MLX documentation. https://ml-explore.github.io/mlx/bui ld/html/index.html, 2023
2023
-
[23]
Native LLM and MLLM inference at scale on Apple Silicon.arXiv preprint arXiv:2601.19139, 2026
Wayner Barrios. Native LLM and MLLM inference at scale on Apple Silicon.arXiv preprint arXiv:2601.19139, 2026. URLhttps://arxiv.org/abs/2601.19139
-
[24]
MetalRT: The fastest LLM decode engine for Apple Silicon
RunAnywhere, Inc. MetalRT: The fastest LLM decode engine for Apple Silicon. https://www.runany where.ai/blog/metalrt-fastest-llm-decode-engine-apple-silicon, 2026
2026
-
[25]
uzu: A high-performance inference engine for AI models
Mirai. uzu: A high-performance inference engine for AI models. https://github.com/trymirai/uzu, 2025. 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.