Proximal Diffusion Neural Sampler
Pith reviewed 2026-05-21 20:31 UTC · model grok-4.3
The pith
Proximal Diffusion Neural Sampler decomposes training into proximal subproblems on path measures to reach multimodal targets without mode collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PDNS addresses mode collapse in multimodal targets by tackling the stochastic optimal control problem via proximal point method on the space of path measures, decomposing the learning process into simpler subproblems that create a path gradually approaching the desired distribution and promote thorough exploration across modes. For a practical and efficient realization, each proximal step is instantiated with a proximal weighted denoising cross-entropy (WDCE) objective.
What carries the argument
proximal point method on the space of path measures, which decomposes the overall stochastic control problem into a sequence of simpler subproblems whose solutions trace a path to the target distribution
Load-bearing premise
That each proximal step can be instantiated stably with the proximal weighted denoising cross-entropy objective for both continuous and discrete sampling without instabilities or tuning that prevents convergence to the full target.
What would settle it
Running PDNS on a mixture of Gaussians separated by high barriers and finding that generated samples still miss entire modes after the full sequence of proximal steps would show the staged path does not reliably prevent collapse.
Figures











read the original abstract
The task of learning a diffusion-based neural sampler for drawing samples from an unnormalized target distribution can be viewed as a stochastic optimal control problem on path measures. However, the training of neural samplers can be challenging when the target distribution is multimodal with significant barriers separating the modes, potentially leading to mode collapse. We propose a framework named Proximal Diffusion Neural Sampler (PDNS) that addresses these challenges by tackling the stochastic optimal control problem via proximal point method on the space of path measures. PDNS decomposes the learning process into a series of simpler subproblems that create a path gradually approaching the desired distribution. This staged procedure traces a progressively refined path to the desired distribution and promotes thorough exploration across modes. For a practical and efficient realization, we instantiate each proximal step with a proximal weighted denoising cross-entropy (WDCE) objective. We demonstrate the effectiveness and robustness of PDNS through extensive experiments on both continuous and discrete sampling tasks, including challenging scenarios in molecular dynamics and statistical physics. Our code is available at https://github.com/AlexandreGUO2001/PDNS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames training a diffusion-based neural sampler for unnormalized multimodal targets as a stochastic optimal control problem on path measures. It proposes Proximal Diffusion Neural Sampler (PDNS), which applies the proximal point method to decompose the problem into a sequence of simpler subproblems. Each subproblem is instantiated via a proximal weighted denoising cross-entropy (WDCE) objective that gradually refines a path toward the target distribution while promoting mode exploration. The method is evaluated on continuous and discrete sampling tasks, including molecular dynamics and statistical physics, with code released at https://github.com/AlexandreGUO2001/PDNS.
Significance. If the proximal decomposition yields stable subproblems that reliably improve mode coverage over standard diffusion samplers, the framework could provide a useful algorithmic template for sampling from complex distributions. The explicit code release supports reproducibility and is a clear strength.
major comments (2)
- [§3.2] §3.2 (proximal WDCE derivation): the weighting scheme derived from the previous iterate is presented as ensuring stable gradients and exploration, but no analysis or bounds are given on how the proximal parameter or weighting affects variance or bias as dimension or energy barriers increase; this directly bears on whether the staged path avoids collapse.
- [§4] §4 (experiments): the reported gains on multimodal targets are shown via qualitative samples and some metrics, but without ablations isolating the effect of the proximal steps versus the base WDCE objective or quantifying sensitivity to the proximal parameter, it is difficult to confirm that the decomposition itself drives the claimed robustness.
minor comments (2)
- [§2] Notation for the path-measure proximal operator is introduced without an explicit comparison to the standard KL-proximal operator used in related optimal-control literature.
- [Figure 3] Figure captions for the molecular-dynamics trajectories should include the specific barrier heights or temperatures used to allow direct comparison with prior samplers.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (proximal WDCE derivation): the weighting scheme derived from the previous iterate is presented as ensuring stable gradients and exploration, but no analysis or bounds are given on how the proximal parameter or weighting affects variance or bias as dimension or energy barriers increase; this directly bears on whether the staged path avoids collapse.
Authors: We acknowledge that Section 3.2 presents the proximal weighting scheme primarily through its derivation and motivation for stable gradients and gradual path refinement, without providing formal bounds on variance or bias as a function of dimension or energy barrier height. The manuscript argues for stability via the iterative proximal updates on path measures, supported by the empirical results on multimodal targets. In the revised manuscript we have added a paragraph in Section 3.2 discussing the practical role of the proximal parameter in controlling step size and its observed effect on exploration; a full theoretical analysis of bias-variance trade-offs under increasing dimension remains future work. revision: partial
-
Referee: [§4] §4 (experiments): the reported gains on multimodal targets are shown via qualitative samples and some metrics, but without ablations isolating the effect of the proximal steps versus the base WDCE objective or quantifying sensitivity to the proximal parameter, it is difficult to confirm that the decomposition itself drives the claimed robustness.
Authors: We agree that isolating the contribution of the proximal decomposition is important for validating the framework. The original experiments compare PDNS against standard diffusion samplers and other baselines on continuous and discrete tasks, but do not include an explicit non-proximal WDCE ablation or systematic sensitivity sweeps. We have added these ablations and sensitivity plots to the revised Section 4, showing that the staged proximal steps improve mode coverage relative to the base objective and that performance is robust across a range of proximal parameter values. revision: yes
Circularity Check
No circularity: PDNS derivation applies standard proximal point method to path-measure SOC without self-referential reduction
full rationale
The paper frames diffusion sampling as a stochastic optimal control problem on path measures and proposes to solve it via the proximal point method, which decomposes the task into a sequence of simpler subproblems each instantiated by a proximal WDCE objective. This construction is presented as a direct methodological extension rather than a redefinition of inputs or a fitted quantity renamed as prediction. No equations or steps in the provided text reduce the claimed path-measure decomposition or mode-exploration benefit to a tautology, self-citation chain, or ansatz smuggled from prior author work; the central procedure remains independently motivated by the proximal-point algorithm and is validated through separate experiments on continuous and discrete tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The task of learning a diffusion-based neural sampler can be formulated as a stochastic optimal control problem on path measures.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PDNS decomposes the learning process into a series of simpler subproblems that create a path gradually approaching the desired distribution... instantiate each proximal step with a proximal weighted denoising cross-entropy (WDCE) objective.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Onsager ,\ title title Crystal Statistics
URLhttps://openreview.net/forum?id=Hq2RniQAET. Xunpeng Huang, Hanze Dong, Yifan Hao, Yi-An Ma, and Tong Zhang. Reverse diffusion monte carlo.ICLR, 2024. Leon Klein, Andrew Foong, Tor Fjelde, Bruno Mlodozeniec, Marc Brockschmidt, Sebastian Nowozin, Frank No´e, and Ryota Tomioka. Timewarp: Transferable acceleration of molecular dynamics by learning time-coa...
-
[2]
ISSN 2167-3888. doi: 10.1561/2400000003. URL https://doi.org/10.1561/ 2400000003. William Peebles and Saining Xie. Scalable diffusion models with transformers. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4172–4182, 2023. doi: 10.1109/ ICCV51070.2023.00387. Angus Phillips, Hai-Dang Dau, Michael John Hutchinson, Valentin De Borto...
-
[3]
Simo S¨arkk¨a and Arno Solin.Applied stochastic differential equations, volume 10
URLhttps://openreview.net/forum?id=peNgxpbdxB. Simo S¨arkk¨a and Arno Solin.Applied stochastic differential equations, volume 10. Cambridge University Press, 2019. Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E(n) equivariant graph neural networks. InInternational Conference on Machine Learning (ICML), 2021. Yuyang Shi, Valentin De Bortoli, A...
-
[4]
George E Uhlenbeck and Leonard S Ornstein
URLhttps://proceedings.mlr.press/v139/touvron21a.html. George E Uhlenbeck and Leonard S Ornstein. On the theory of the brownian motion.Physical review, 36(5):823, 1930. Francisco Vargas, Will Grathwohl, and Arnaud Doucet. Denoising diffusion samplers. InInternational Conference on Learning Representations (ICLR), 2023. Francisco Vargas, Shreyas Padhy, Den...
-
[5]
employs annealed reference dynamics to provide stronger guidance during learning. CE-based Diffusion SamplersCross-entropy (CE) approaches replace forward-KL or relative- entropy training with a reverse-KL projection, typically of the form, which reduces to a weighted negative log-likelihood on trajectories. In the diffusion setting, this often appears as...
work page 2024
-
[6]
or adopts alternative training criteria such as action matching (Albergo & Vanden-Eijnden, 2025; Neklyudov et al., 2023). In practice, these approaches often inherit a significant computational 15 preprint cost from evaluating energies to form importance weights, motivating schemes that reduce or reuse weighting while retaining correctness. A.2 DISCRETEDI...
work page 2025
-
[7]
SampleNtrajectories{X (i)}N i=1 ∼P v
-
[8]
Compute weights{w (i)}N i=1 by (31) for each corresponding trajectory{X (i)}N i=1
-
[9]
Resample{X (i) 1 }N i=1 by following categorical distribution: { ˆX(i) 1 }N i=1 ∼Cat {ˆw(i)}N i=1,{X (i) 1 }N i=1 ,whereˆw (i) = w(i) PN i=1 w(i) .(40)
-
[10]
Update the controlu θ :=uthrough ascore matchingloss with a resampled data. Remark.Particle Denosing Diffusion Sampler (PDDS) (Phillips et al., 2024) is one of the sampling method which leverages this Importance weighted CE method. C.2.3 THEORIES ONPROXIMALDIFFUSIONNEURALSAMPLERS In this section, we introduce the theory for PDNS written in SDE formulation...
work page 2024
-
[11]
DrawNtrajectories{X (i)}N i=1 fromP θk−1
-
[12]
Compute weights wθ∗ k ηk(X) = er(XT ) dPref dP¯θk−1 (X) ηk ηk+1 =(45);(51)
-
[13]
resample{X (i) T }N i=1 by following categorical distribution: { ˜XT }N i=1 ∼Cat ( wθk ηk(X(i)) PN i=1 wθk ηk(X(i)) )N i=1 ,{X (i) T }N i=1 .(52) Weighting-based AlgorithmAlternatively, using (50), we draw XT ∼P θk−1 T and and incorpo- rate wθ∗ k ηk directly in the objective, i.e., optimize a weighted loss where each sample contributes proportional...
work page 2025
-
[14]
global” means with respect toP ∗ and “local
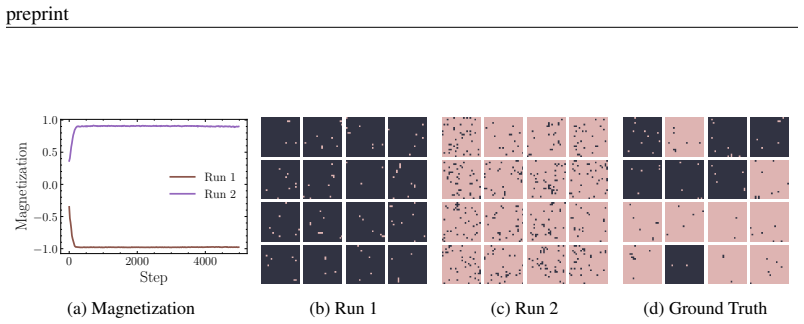
and take the output as the ground truth. E.3 ADDITIONALRESULTS Monitoring training procedure of PDNSIn Fig. 12, we demonstrate an example of the PNDS learning procedure for the Potts model with q= 4 states on a 16×16 lattice, at βcritical = 1.0986. In thek-th outer loop, we fit the target path measureP k. 30 preprint (a) PDNS (ours) (b) LEAPS (c) MH (d) G...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.