Vision-Language-Action Models: Experimental Insights from a Real-World UR5 Platform
Pith reviewed 2026-06-30 05:22 UTC · model grok-4.3
The pith
VLA deployment on physical robots requires precise management of the data-model-control pipeline rather than larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on the UR5e platform demonstrate that promising offline performance of VLA models like OpenVLA does not translate to stable real-robot execution, with the discrepancy arising from pipeline elements including action semantics, coordinate frame conventions, temporal alignment between modalities, image preprocessing consistency, and dataset coverage and quality, establishing that deployment hinges on precise control of the data-model-control pipeline.
What carries the argument
The data-model-control pipeline, which integrates action semantics, coordinate frames, temporal alignment, preprocessing, and dataset engineering to bridge model outputs to physical robot actions.
If this is right
- Action semantics and coordinate frame conventions must be aligned for stable closed-loop control.
- Dataset conversion workflows aligned with RLDS enable reproducible real-robot evaluation.
- Fine-tuning and inference infrastructure must incorporate real-robot specifics for reliable deployment.
- Systematic validation of control interfaces is essential beyond simulation benchmarks.
- Real-world VLA use is a system integration problem more than a model scaling problem.
Where Pith is reading between the lines
- These pipeline factors could be tested for generalizability on other manipulators or VLA architectures.
- Ablation experiments isolating each factor would quantify their individual impacts on the performance gap.
- The framework could extend to multi-task or long-horizon tasks to assess scalability of the pipeline approach.
Load-bearing premise
The performance gap on the UR5e arises primarily from the listed pipeline factors rather than unmeasured model limitations or platform-specific issues, and these factors apply beyond the tested models and hardware.
What would settle it
Achieving stable closed-loop task execution on the UR5e by scaling model capacity alone while leaving action semantics, coordinate frames, and data preprocessing unchanged would falsify the central claim.
Figures
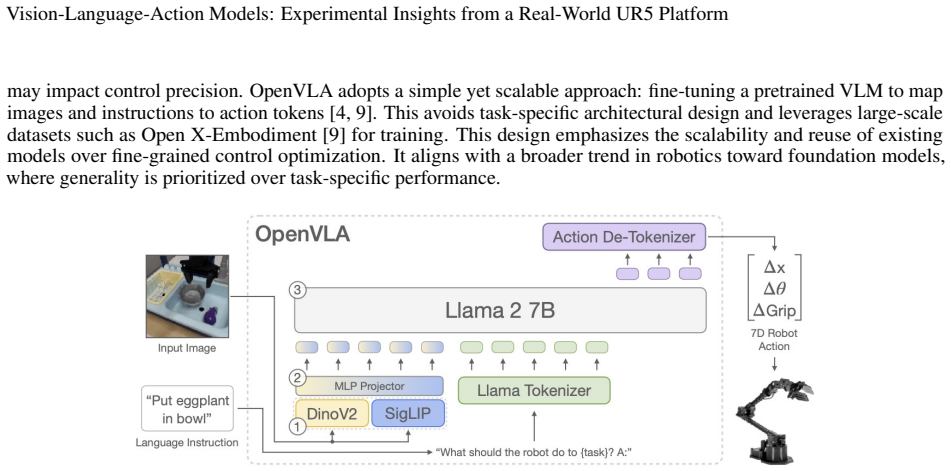
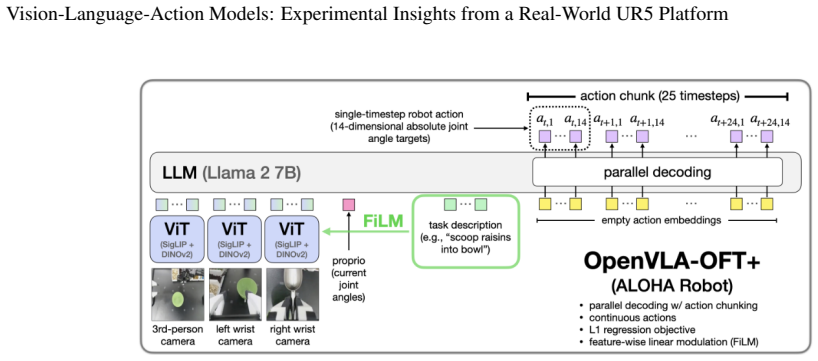

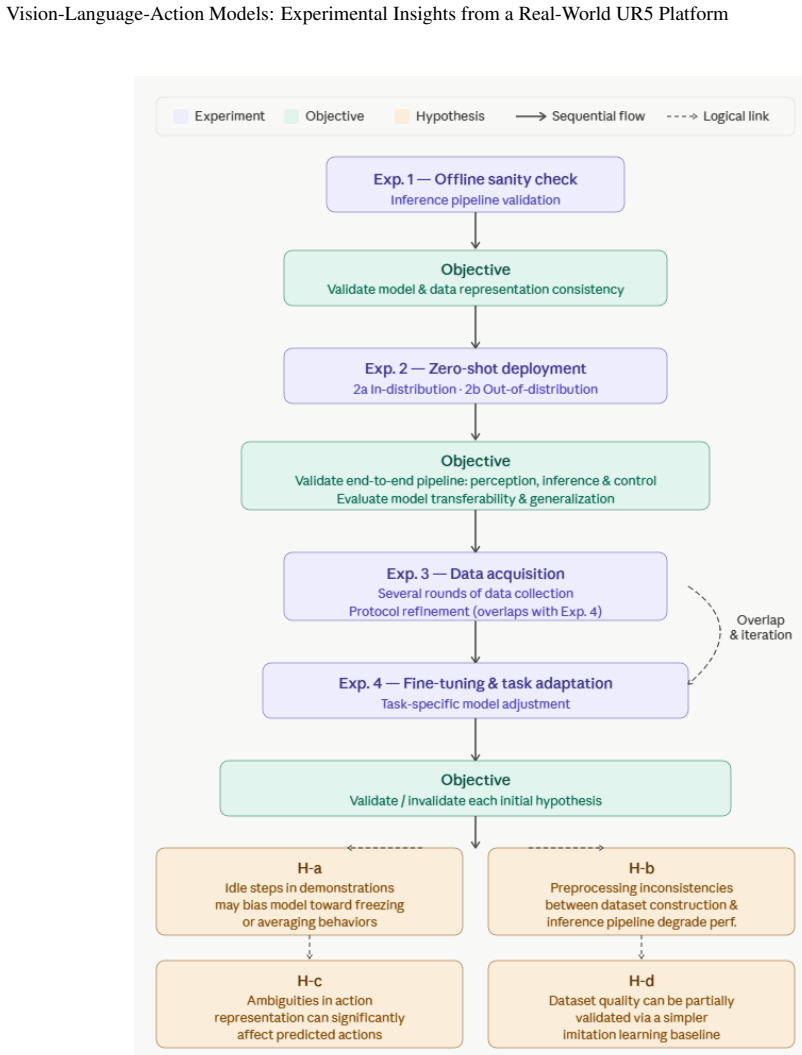


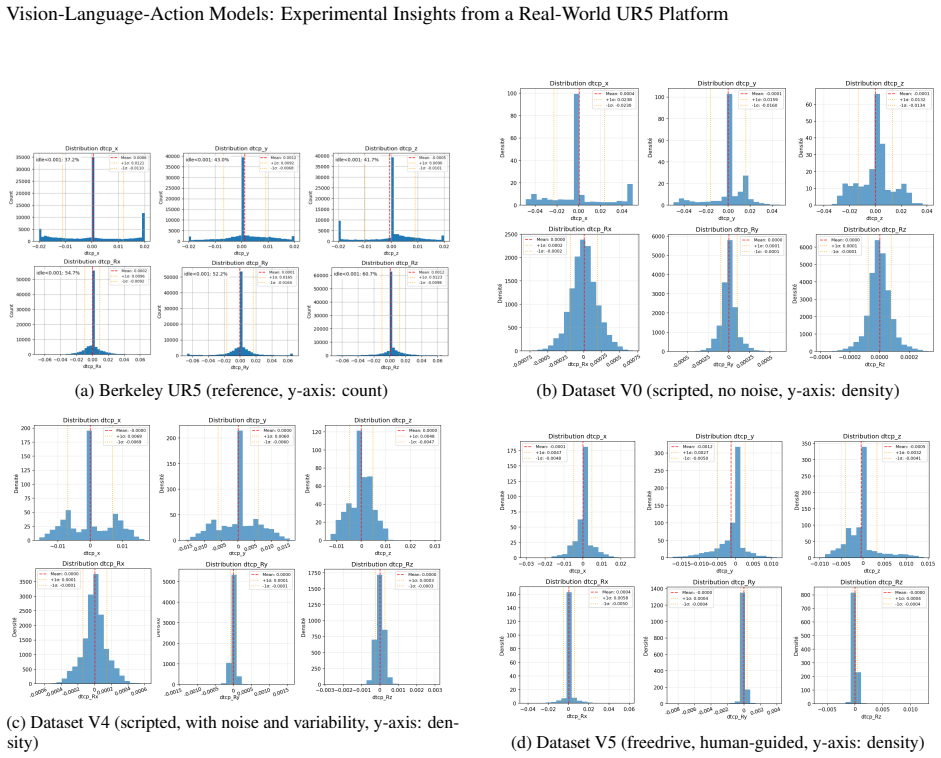
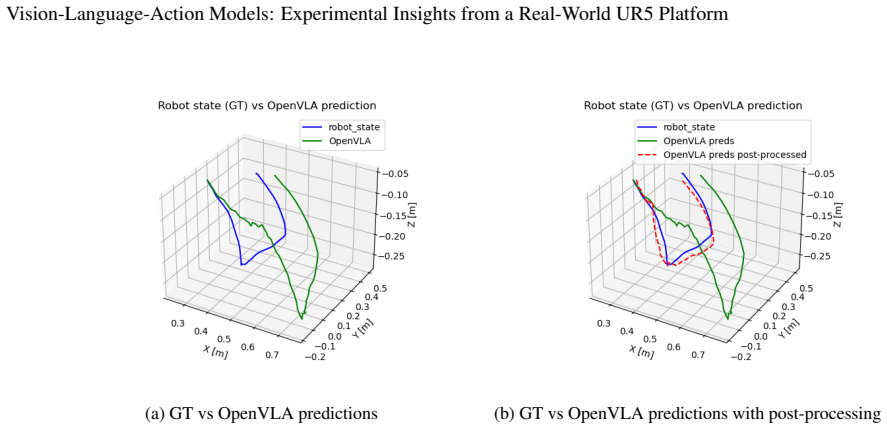

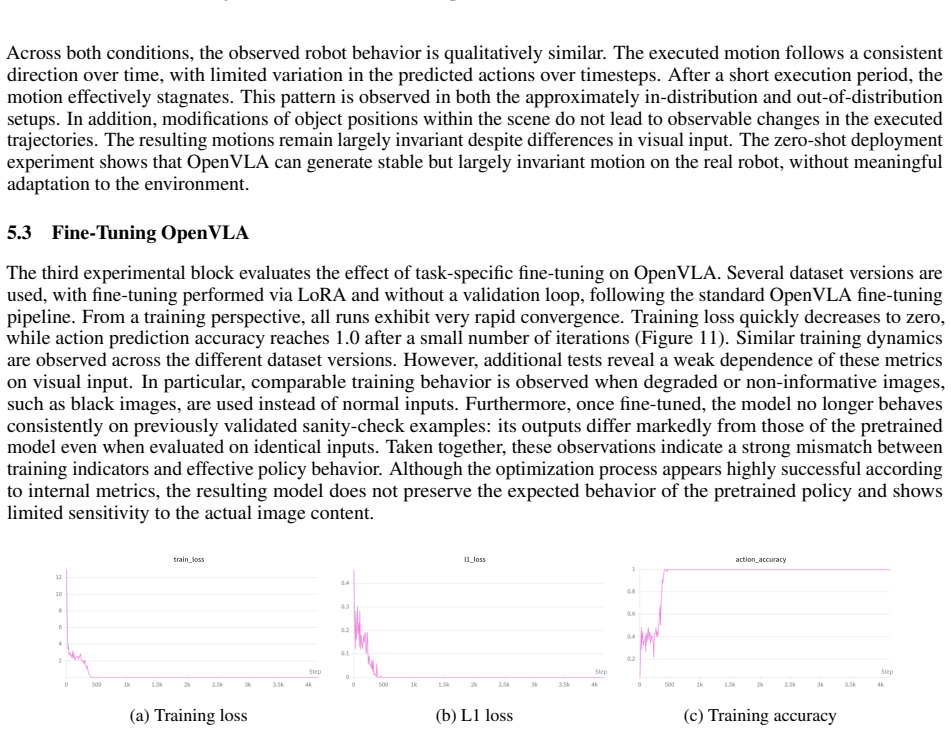
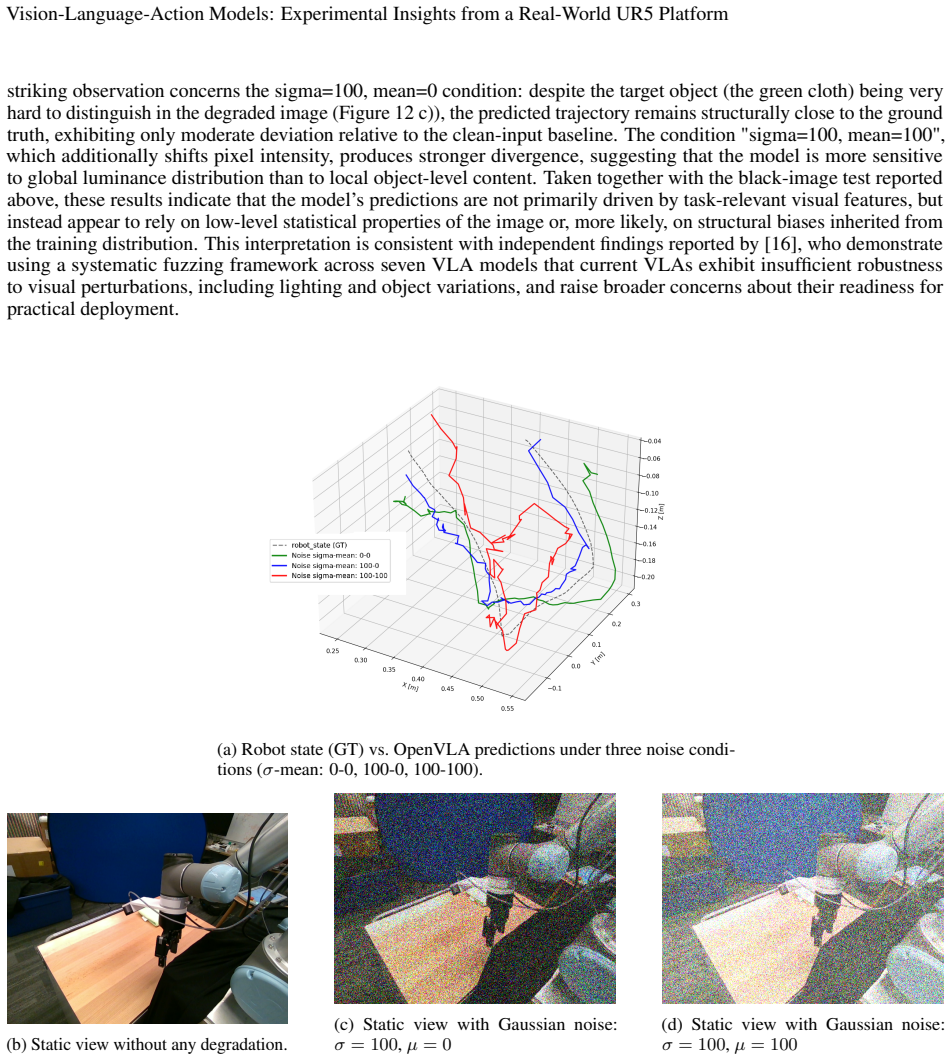
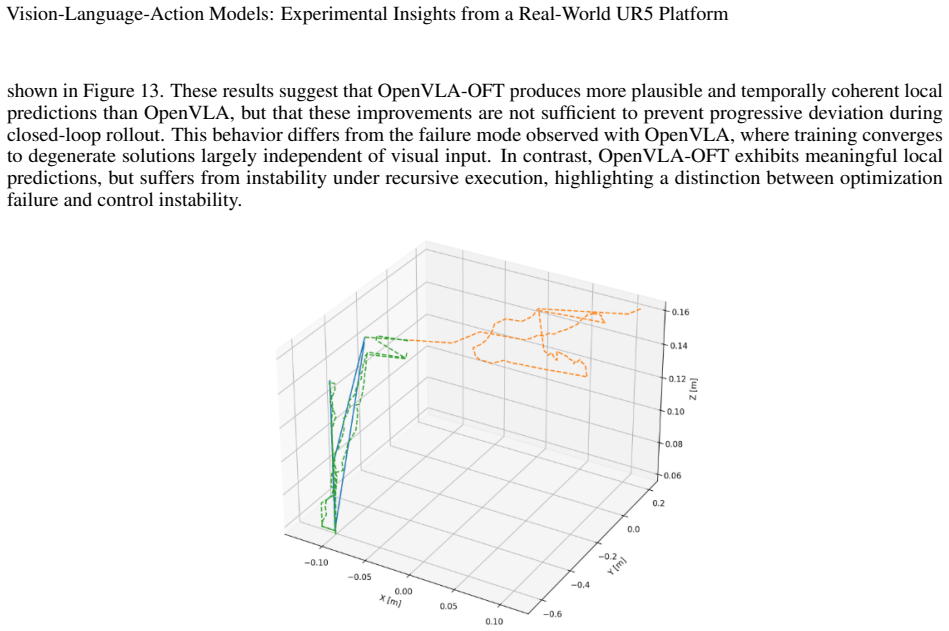
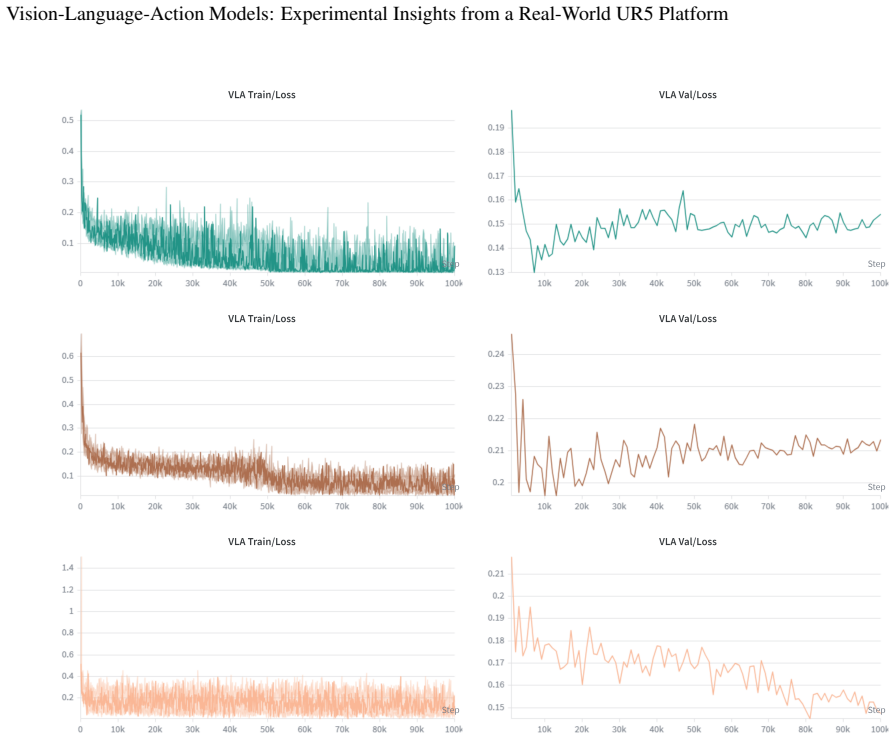
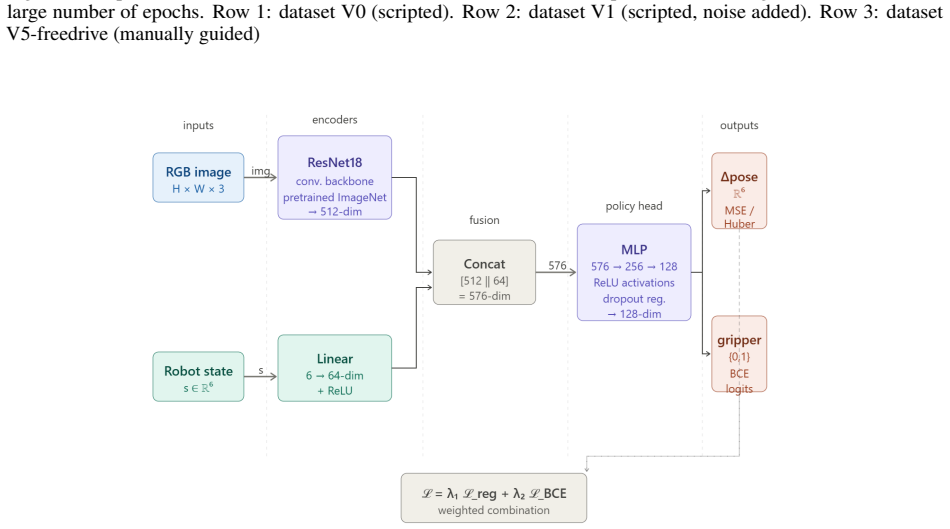
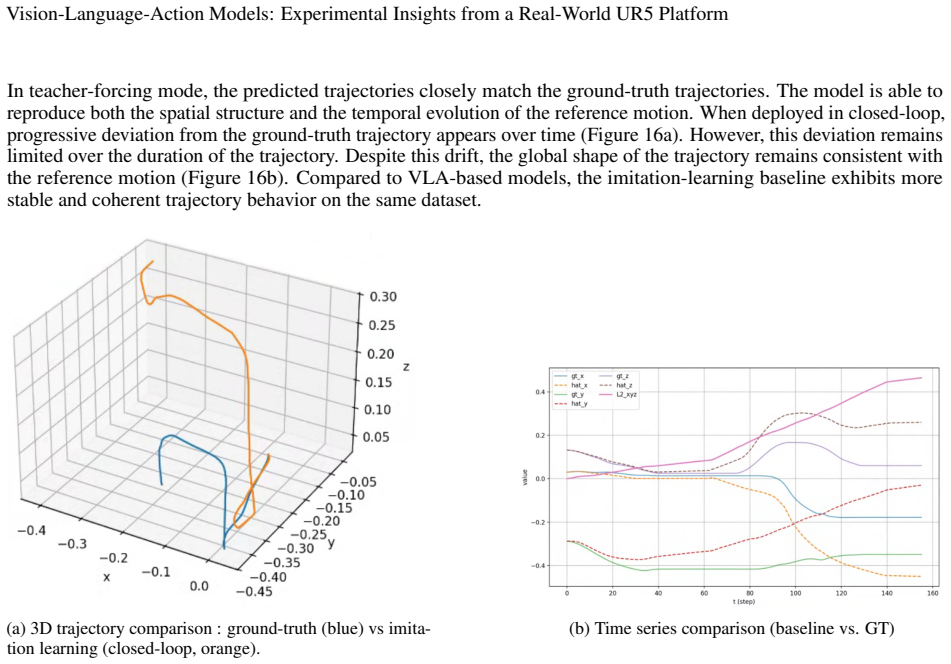
read the original abstract
This project investigates whether recent Vision-Language-Action (VLA) models can be transferred from controlled research benchmarks to a real-world robotic platform, specifically a UR5e manipulator, in a reproducible and operationally meaningful manner. The work integrates real-robot data acquisition, dataset engineering (compatible with the RLDS format), and the fine-tuning and deployment of OpenVLA and OpenVLA-OFT models, with systematic validation of action representations and control interfaces. The project resulted in several foundational assets: (i) a complete real-robot data acquisition pipeline, (ii) a dataset conversion workflow aligned with RLDS standards, (iii) an initial fine-tuning and inference infrastructure for VLA models, and (iv) a structured set of experimental observations grounded in real-robot trials. These elements collectively establish a reproducible framework for evaluating learning-based manipulation systems beyond simulation. Empirically, the experiments reveal a consistent gap between promising offline indicators and unstable closed-loop behavior on the physical system: this gap cannot be attributed solely to model limitations, it is strongly influenced by action semantics, coordinate frame conventions, temporal alignment between modalities, image preprocessing consistency, and dataset coverage and quality. These observations lead to a key interpretation: the successful deployment of VLA systems in real-world settings depends less on incremental improvements in model capacity and more on precise control of the entire data-model-control pipeline. The project reframes VLA-based robotics from a primarily model-centric challenge to a system-level problem; it highlights the difficulty of running robust task execution on the real robot and provides a clear, experimentally grounded understanding of the conditions required for reliable deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper investigates transferring Vision-Language-Action (VLA) models (OpenVLA and OpenVLA-OFT) from research benchmarks to a real UR5e manipulator. It describes development of a real-robot data acquisition pipeline, RLDS-compatible dataset conversion, fine-tuning and inference infrastructure, and reports a consistent gap between promising offline indicators and unstable closed-loop behavior. The authors state this gap cannot be attributed solely to model limitations and is strongly influenced by action semantics, coordinate frame conventions, temporal alignment, image preprocessing, and dataset coverage/quality, leading to the claim that successful real-world VLA deployment depends more on precise control of the entire data-model-control pipeline than on incremental model-capacity improvements. The work positions itself as establishing a reproducible framework and foundational assets for evaluating learning-based manipulation beyond simulation.
Significance. If the reported observations and attribution hold with adequate supporting data, the manuscript offers practical value by documenting real-robot deployment challenges and supplying reusable assets (data acquisition pipeline, RLDS workflow, fine-tuning infrastructure). These elements could aid reproducibility in robotics research. The reframing of VLA issues as system-level rather than purely model-centric provides a useful perspective, though its broader significance is limited by the absence of detailed quantitative validation in the current presentation.
major comments (2)
- [Abstract] Abstract (final paragraph): the central claim that the offline-to-closed-loop gap 'cannot be attributed solely to model limitations' and 'is strongly influenced by' the listed pipeline factors (action semantics, coordinate frames, temporal alignment, preprocessing, dataset coverage) is load-bearing for the interpretation, yet the text supplies no quantitative metrics, error bars, statistical tests, or descriptions of controlled ablations that vary one factor while holding the model and hardware fixed.
- [Abstract] Abstract (empirical observations paragraph): the conclusion that deployment success 'depends less on incremental improvements in model capacity and more on precise control of the entire data-model-control pipeline' requires evidence isolating the causal contribution of the pipeline factors versus unmeasured model or platform effects; the reported observations appear to rest on correlational trials without such isolation experiments.
minor comments (2)
- [Title/Abstract] Title vs. abstract: the title states 'UR5 Platform' while the abstract specifies 'UR5e manipulator'; standardize the hardware designation for clarity and reproducibility.
- [Abstract] Abstract: the description of 'systematic validation of action representations and control interfaces' is stated without reference to specific metrics or protocols used; add a brief enumeration or pointer to the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims. We address the two major comments below and commit to revisions that improve clarity and evidence presentation without altering the core contributions of the real-robot pipeline and observations.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the central claim that the offline-to-closed-loop gap 'cannot be attributed solely to model limitations' and 'is strongly influenced by' the listed pipeline factors (action semantics, coordinate frames, temporal alignment, preprocessing, dataset coverage) is load-bearing for the interpretation, yet the text supplies no quantitative metrics, error bars, statistical tests, or descriptions of controlled ablations that vary one factor while holding the model and hardware fixed.
Authors: The manuscript's experimental sections detail multiple real-robot trials in which pipeline elements were systematically varied (action semantics, coordinate conventions, temporal alignment, image preprocessing, and dataset subsets) with the model and UR5e hardware held fixed, producing observable differences in closed-loop stability. These are supported by logged performance indicators across trials. We agree the abstract does not reference this supporting material and will revise it to include a concise summary of the key observed differences and point to the relevant experimental subsections. revision: yes
-
Referee: [Abstract] Abstract (empirical observations paragraph): the conclusion that deployment success 'depends less on incremental improvements in model capacity and more on precise control of the entire data-model-control pipeline' requires evidence isolating the causal contribution of the pipeline factors versus unmeasured model or platform effects; the reported observations appear to rest on correlational trials without such isolation experiments.
Authors: The reported trials isolate pipeline factors by fixing the model weights and robot platform while changing one element at a time (e.g., switching coordinate frames or alignment offsets) and documenting resulting behavior changes. This design provides direct evidence of influence beyond model capacity. We acknowledge that formal statistical ablations with error bars are not presented in the current version and will add a new subsection that tabulates the variations performed, associated performance shifts, and any quantitative metrics available from the trial logs. revision: partial
Circularity Check
No circularity: purely observational experimental report
full rationale
The manuscript presents an experimental study of VLA model transfer to a physical UR5e robot, including data pipelines, fine-tuning, and observed offline-to-closed-loop gaps. The central interpretation—that deployment success depends more on pipeline control than model capacity—is stated as an empirical conclusion from trial outcomes rather than any derivation, equation, fitted parameter, or self-citation chain. No load-bearing step reduces a claimed result to its own inputs by construction; the work contains no mathematical predictions, uniqueness theorems, or ansatzes. This is the expected non-finding for an observational robotics paper whose claims rest on reported hardware behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RLDS format and standard UR5 control interfaces are suitable and unbiased representations for evaluating VLA transfer
Reference graph
Works this paper leans on
-
[1]
Ma et al.A Survey on Vision-Language-Action Models for Embodied AI
Y . Ma et al.A Survey on Vision-Language-Action Models for Embodied AI. 2024.URL: http://dx.doi.org/ 10.1109/TNNLS.2025.3650584
-
[2]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan et al.RT-1: Robotics Transformer for Real-World Control at Scale. 2023. arXiv: 2212 . 06817 [cs.RO].URL:https://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan et al.RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. 2023.URL: https://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
M. J. Kim et al.OpenVLA: An Open-Source Vision-Language-Action Model. 2024.DOI: 10.48550/arXiv. 2406.09246.URL:https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[5]
OpenVLA Team.OpenVLA GitHub Repository. 2024
2024
-
[6]
M. J. Kim, C. Finn, and P. Liang.Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success. 2025.DOI:10.48550/arXiv.2502.19645.URL:https://arxiv.org/abs/2502.19645
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.19645.url:https://arxiv.org/abs/2502.19645 2025
-
[7]
Vision-Language-Action Models for Robotics: A Review Towards Real-World Appli- cations
K. Kawaharazuka et al. “Vision-Language-Action Models for Robotics: A Review Towards Real-World Appli- cations”. In:IEEE Access(2025).DOI: 10.1109/ACCESS.2025.3609980.URL: https://arxiv.org/abs/ 2510.07077
-
[8]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team et al.Octo: An Open-Source Generalist Robot Policy. 2024.DOI: 10.48550/arXiv.2405. 12213. arXiv:2405.12213 [cs.RO].URL:https://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405 2024
-
[9]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration et al.Open X-Embodiment: Robotic Learning Datasets and RT-X Models. 2023.URL:https://arxiv.org/abs/2310.08864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
B. Liu et al.LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. 2023.DOI: 10.48550/ arXiv.2306.03310.URL:https://arxiv.org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks
Oier Mees et al. “CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks”. In:Conference on Robot Learning (CoRL). 2022.URL: https://arxiv.org/abs/2112. 03227
2022
-
[12]
Xueyang Zhou et al.LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization. 2026. arXiv:2510.03827 [cs.CV].URL:https://arxiv.org/abs/2510.03827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Senyu Fei et al.LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models. 2025. arXiv: 2510.13626 [cs.RO].URL:https://arxiv.org/abs/2510.13626
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Ramos et al.RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning
S. Ramos et al.RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning. 2021. URL:https://arxiv.org/pdf/2111.02767
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu et al.LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL]. 2021. DOI: 10.48550/arXiv.2106.09685. arXiv: 2106.09685 [cs.CL].URL: https://arxiv.org/abs/2106. 09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2021
-
[16]
VLATest: Testing and Evaluating Vision-Language-Action Models for Robotic Manipulation
Zhijie Wang et al. “VLATest: Testing and Evaluating Vision-Language-Action Models for Robotic Manipulation”. In:Proceedings of the ACM on Software Engineering2.FSE (2025). arXiv:2409.12894v2.DOI: 10.1145/ 3729343. arXiv:2409.12894 [cs.SE].URL:https://arxiv.org/abs/2409.12894. 22 Vision-Language-Action Models: Experimental Insights from a Real-World UR5 Platform
-
[17]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
S. Ross, G.J. Gordon, and J.A. Bagnell. “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning”. In:Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS). V ol. 15. Proceedings of Machine Learning Research. arXiv:1011.0686. PMLR, 2011, pp. 627–635.URL:https://arxiv.org/pdf/1011.0686
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[18]
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Andy Zeng et al. “Transporter Networks: Rearranging the Visual World for Robotic Manipulation”. In:Pro- ceedings of the 2020 Conference on Robot Learning. 2021.URL: https://proceedings.mlr.press/v155/ zeng21a.html
2020
-
[19]
Yuhui Chen et al.ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy. 2025
2025
- [20]
-
[21]
2025.DOI: 10.36227/techrxiv.176531955.54563920/v1
Haoyuan Deng et al.A Survey on Reinforcement Learning of Vision-Language-Action Models for Robotic Ma- nipulation. 2025.DOI: 10.36227/techrxiv.176531955.54563920/v1 . eprint: https://www.techrxiv. org/doi/pdf/10.36227/techrxiv.176531955.54563920/v1 .URL: https://www.techrxiv.org/ doi/abs/10.36227/techrxiv.176531955.54563920/v1
- [22]
-
[23]
Anupam Pani and Yanchao Yang.Gaze-Regularized Vision-Language-Action Models for Robotic Manipulation
-
[24]
arXiv:2603.23202 [cs.CV].URL:https://arxiv.org/abs/2603.23202
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Springer, 2009.ISBN: 978-1-84628-641-4
Bruno Siciliano et al.Robotics: Modelling, Planning and Control. Springer, 2009.ISBN: 978-1-84628-641-4
2009
-
[26]
Spong, Seth Hutchinson, and M
Mark W. Spong, Seth Hutchinson, and M. Vidyasagar.Robot Modeling and Control. John Wiley & Sons, 2005. ISBN: 978-0-471-64990-8
2005
-
[27]
Robot Collisions: A Survey on Detection, Isolation, and Identification
Sami Haddadin, Alessandro De Luca, and Alin Albu-Schaffer. “Robot Collisions: A Survey on Detection, Isolation, and Identification”. In:IEEE Transactions on Robotics33.6 (2017), pp. 1292–1312.DOI: 10.1109/ TRO.2017.2723903.URL:https://ieeexplore.ieee.org/document/8059840
- [28]
-
[29]
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
J. Tobin et al. “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World”. In:2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). arXiv:1703.06907. 2017, pp. 23–30.DOI: 10.1109/IROS.2017.8202133 .URL: https://arxiv.org/ abs/1703.06907. 23
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/iros.2017.8202133 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.