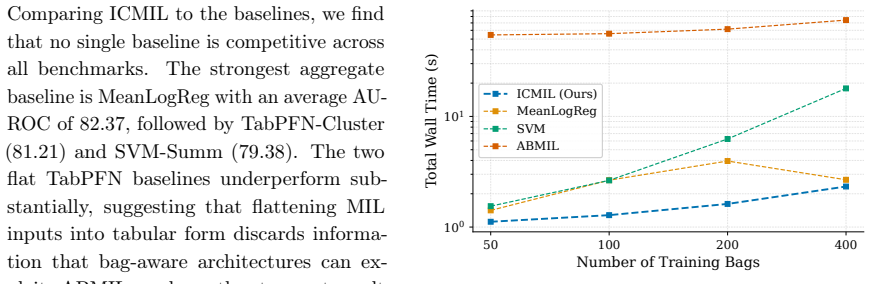
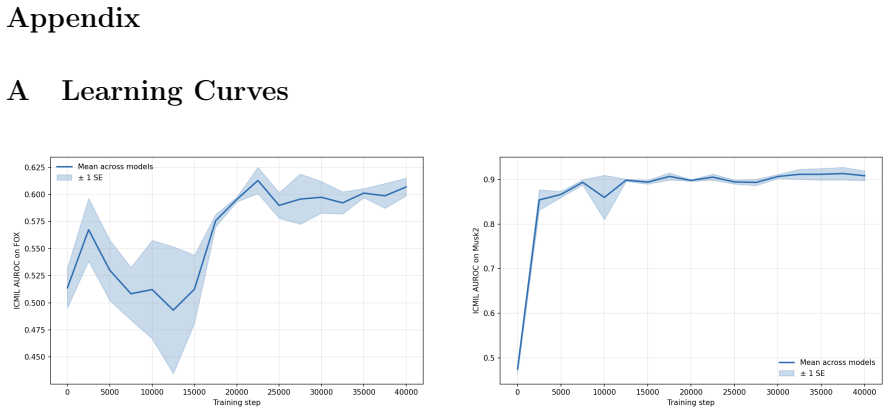
In-Context Multiple Instance Learning
Pith reviewed 2026-06-28 02:18 UTC · model grok-4.3
The pith
Pretraining a Perceiver-style in-context learner on synthetic MIL generators produces a model that solves new tasks from a handful of labeled bags in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
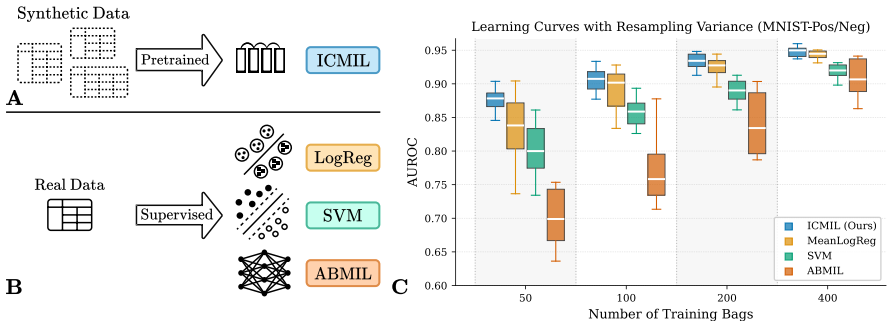
Pretraining an in-context learner with a Perceiver-style architecture on synthetic data yields a model that can solve new MIL tasks from a handful of labeled bags. At inference time, classification happens in a single forward pass and requires no gradient updates. A model pretrained on a mixture of synthetic data generators inherits their per-task strengths and achieves the best average performance across twelve MIL benchmarks, outperforming supervised baselines.
What carries the argument
An in-context learner with Perceiver-style architecture pretrained on synthetic bag-structured data generators.
If this is right
- Classification on new tasks occurs in a single forward pass without any gradient updates.
- A mixture of synthetic generators captures complementary inductive biases from different data generators.
- The pretrained model achieves the best average performance on twelve real-world MIL benchmarks.
- Outperforms supervised baselines that require task-specific training.
Where Pith is reading between the lines
- If the synthetic generators transfer well, this method could reduce the need for large labeled datasets in pathology or satellite imagery applications.
- Extending the approach to other structured data problems might allow in-context learning for few-shot bag classification beyond MIL.
- Testing the model on additional benchmarks with varying label scarcity could reveal limits of the transfer from synthetic data.
Load-bearing premise
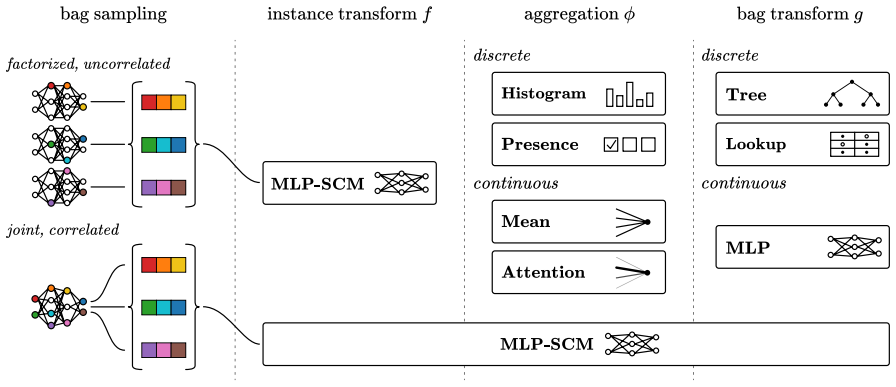
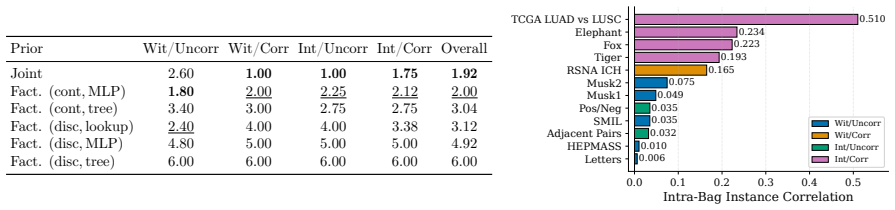
The synthetic data generators produce tasks whose inductive biases transfer to the twelve real-world MIL benchmarks without significant distribution shift or negative transfer.
What would settle it
Observing that the mixed-pretrained model does not achieve the best average performance or fails to outperform task-specific supervised baselines on the twelve MIL benchmarks would falsify the claim.
Figures
read the original abstract
Multiple Instance Learning (MIL) addresses problems where supervision is available at the level of bags of instances and has been successfully applied in fields ranging from computational pathology to satellite imagery. Nevertheless, existing algorithms struggle in the low-label regime that characterizes many real-world applications. Flexible models overfit and rigid ones fail to adapt to the task at hand. We show that pretraining an in-context learner with a Perceiver-style architecture on synthetic data yields a model that can solve new tasks from a handful of labeled bags. At inference time, classification happens in a single forward pass and requires no gradient updates. We propose and investigate different synthetic data generators for bag-structured data and find that they capture complementary inductive biases. A model pretrained on a mixture of these generators inherits their per-task strengths and achieves the best average performance across twelve MIL benchmarks, outperforming supervised baselines that require task-specific training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretraining a Perceiver-style in-context learner on synthetic multiple-instance learning (MIL) data generated from a mixture of bag-structured generators produces a model that solves new MIL tasks from a handful of labeled bags via a single forward pass with no gradient updates. Different generators are said to capture complementary inductive biases; the mixture model inherits these strengths and reports the best average performance across twelve real-world MIL benchmarks while outperforming task-specific supervised baselines.
Significance. If the synthetic-to-real transfer holds, the work would demonstrate a practical route to label-efficient, task-agnostic MIL that avoids per-task training and gradient steps at inference. The core idea of mixing synthetic generators to encode complementary biases is conceptually attractive and the single-pass inference is computationally attractive for deployment. The manuscript does not, however, supply machine-checked proofs, parameter-free derivations, or falsifiable predictions that would strengthen the result beyond the reported benchmark averages.
major comments (2)
- [Abstract] Abstract: the central claim that the mixture 'inherits their per-task strengths' and thereby achieves the best average performance on the twelve benchmarks rests on the unverified premise that the synthetic generators produce tasks whose statistics (bag-size distributions, instance-feature covariances, label correlations) are close enough to the real benchmarks for inductive biases to transfer without significant shift or negative transfer. No such quantitative comparison is supplied, leaving open the possibility that observed gains arise from the in-context architecture or the few-shot examples rather than from the pretraining distribution.
- [Experimental evaluation] Experimental claims (twelve-benchmark evaluation): the superiority over supervised baselines that require task-specific training is load-bearing for the practical contribution, yet the manuscript provides no details on baseline implementations, hyper-parameter budgets, or whether the baselines also receive the same handful of labeled bags at test time. Without these controls it is impossible to isolate the benefit of the synthetic pretraining mixture.
minor comments (1)
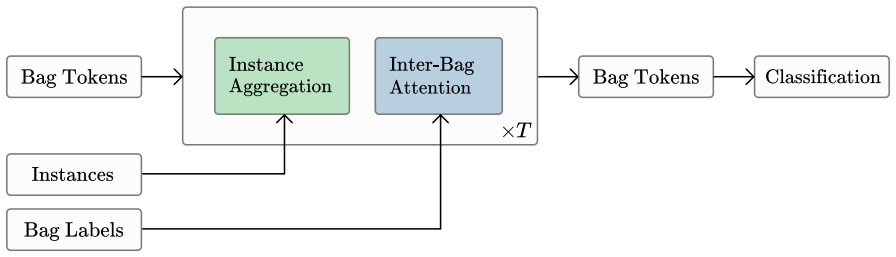
- [Methods] The description of the Perceiver-style architecture and how bags are tokenized for in-context processing would benefit from an explicit diagram or pseudocode block to clarify the forward-pass mechanism.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address the major comments point by point below, and we will make revisions to the manuscript to incorporate additional analyses and details as outlined.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the mixture 'inherits their per-task strengths' and thereby achieves the best average performance on the twelve benchmarks rests on the unverified premise that the synthetic generators produce tasks whose statistics (bag-size distributions, instance-feature covariances, label correlations) are close enough to the real benchmarks for inductive biases to transfer without significant shift or negative transfer. No such quantitative comparison is supplied, leaving open the possibility that observed gains arise from the in-context architecture or the few-shot examples rather than from the pretraining distribution.
Authors: We agree that a quantitative comparison of the synthetic data statistics with those of the real benchmarks is not currently provided in the manuscript. Although the strong empirical performance on the twelve real-world benchmarks indicates that the inductive biases transfer effectively, we recognize that explicitly demonstrating the similarity in key statistics would better support the claim and rule out alternative explanations. In the revised version, we will add a new analysis section that compares bag-size distributions, instance-feature covariances, and label correlations between the synthetic generators and the real datasets. This will provide evidence for the appropriateness of the pretraining distribution. revision: yes
-
Referee: [Experimental evaluation] Experimental claims (twelve-benchmark evaluation): the superiority over supervised baselines that require task-specific training is load-bearing for the practical contribution, yet the manuscript provides no details on baseline implementations, hyper-parameter budgets, or whether the baselines also receive the same handful of labeled bags at test time. Without these controls it is impossible to isolate the benefit of the synthetic pretraining mixture.
Authors: We concur that providing comprehensive details on the baseline experiments is essential for validating the superiority claims. The supervised baselines are implemented as standard MIL models trained per-task on the identical set of few labeled bags used by our in-context learner. To address this, the revised manuscript will include an expanded experimental details section specifying: the exact baseline algorithms and their code references or implementations, the hyperparameter tuning procedure and computational budget allocated, and confirmation that all methods operate under the same few-shot labeled bag regime at test time. This will clarify the controls and isolate the benefit of the pretraining. revision: yes
Circularity Check
No circularity: empirical transfer result stands on held-out benchmarks
full rationale
The paper's core claim is that pretraining a Perceiver-style in-context learner on a mixture of proposed synthetic bag generators yields the best average performance across twelve real MIL benchmarks, outperforming task-specific supervised baselines. This is an empirical measurement on held-out real data after independent synthetic pretraining; no equations, fitted parameters, or self-citations are shown to reduce the reported superiority to a quantity defined inside the paper. The generators are introduced as proposals whose complementary biases are observed experimentally, but the synthetic-to-real transfer is presented as a testable outcome rather than a definitional or constructed prediction. No load-bearing self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data generators produce tasks whose statistical structure is sufficiently close to real MIL problems for effective transfer.
Reference graph
Works this paper leans on
-
[1]
Multi-resolution domain adaptation via multiple instance learning for improving the recognition accuracy of japanese oak wilt in low-resolution satellite imagery
Mitsuyoshi Otsu, Sho Nakamura, Shigeru Tomita, Tomoyuki Suhama, Yasunobu Shimazaki, and Katsuya Nishimura. Multi-resolution domain adaptation via multiple instance learning for improving the recognition accuracy of japanese oak wilt in low-resolution satellite imagery. In SPIE Future Sensing Technologies 2023, volume 12327, page 1232716, 2023
2023
-
[2]
Exploring multiple instance learning (MIL): A brief survey.Expert Systems with Applications, 250: 123893, 2024
Muhammad Waqas, Syed Umaid Ahmed, Muhammad Atif Tahir, Jia Wu, and Rizwan Qureshi. Exploring multiple instance learning (MIL): A brief survey.Expert Systems with Applications, 250: 123893, 2024
2024
-
[3]
Beyond attention heatmaps: How to get better explanations for multiple instance learning models in histopathology
Mina Jamshidi Idaji, Julius Hense, Tom Neuhäuser, Augustin Krause, Yanqing Luo, Oliver Eberle, Thomas Schnake, Laure Ciernik, Farnoush Rezaei Jafari, Reza Vahidimajd, Jonas Dippel, Christoph Walz, Frederick Klauschen, Andreas Mock, and Klaus-Robert Müller. Beyond attention heatmaps: How to get better explanations for multiple instance learning models in h...
2026
-
[4]
scMILD: Single-cell multiple instance learning for sample classification and associated subpopulation discovery.iScience, 29(4), 2026
Kyeonghun Jeong, Jinwook Choi, and Kwangsoo Kim. scMILD: Single-cell multiple instance learning for sample classification and associated subpopulation discovery.iScience, 29(4), 2026
2026
-
[5]
Dietterich, Richard H
Thomas G. Dietterich, Richard H. Lathrop, and Tomás Lozano-Pérez. Solving the multiple instance problem with axis-parallel rectangles.Artificial Intelligence, 89(1):31–71, 1997
1997
-
[6]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.JAMA, 318:2199–2210, 2017
Babak Ehteshami Bejnordi, Mitko Veta, Paul Diest, Bram Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen van der Laak, Meyke Hermsen, Quirine Manson, Maschenka Balkenhol, Oscar Geessink, Nikolaos Stathonikos, Marcory van Dijk, Peter Bult, Francisco Beca, Andrew Beck, Dayong Wang, Aditya Khosla, Rishab Gargeya, and Rui Venâncio. Diagnostic assessment of d...
2017
-
[7]
Attention-based Deep Multiple Instance Learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based Deep Multiple Instance Learning. InProceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 2127–2136, 2018
2018
-
[8]
TransMIL: Transformer based correlated multiple instance learning for whole slide image classification
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, et al. TransMIL: Transformer based correlated multiple instance learning for whole slide image classification. In Advances in Neural Information Processing Systems, volume 34, pages 2136–2147, 2021. 12
2021
-
[9]
Support vector machines for multiple-instance learning
Stuart Andrews, Ioannis Tsochantaridis, and Thomas Hofmann. Support vector machines for multiple-instance learning. InProceedings of the 16th International Conference on Neural Infor- mation Processing Systems, NIPS’02, pages 577–584, 2002
2002
-
[10]
Chen, Andrew H
Daniel Shao, Richard J. Chen, Andrew H. Song, Joel Runevic, Ming Y. Lu, Tong Ding, and Faisal Mahmood. Do multiple instance learning models transfer? InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 54219–54238, 2025
2025
-
[11]
Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, and Hoifung Poon
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Jaylen Rosemon, Tucker Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Shen...
2024
-
[12]
Wagner, Andrew H
Tong Ding, Sophia J. Wagner, Andrew H. Song, Richard J. Chen, Ming Y. Lu, Andrew Zhang, Anurag J. Vaidya, Guillaume Jaume, Muhammad Shaban, Ahrong Kim, Drew F. K. Williamson, Harry Robertson, Bowen Chen, Cristina Almagro-Pérez, Paul Doucet, Sharifa Sahai, Chengkuan Chen, Christina S. Chen, Daisuke Komura, Akihiro Kawabe, Mieko Ochi, Shinya Sato, Tomoyuki ...
2025
-
[13]
Transformers can do bayesian inference
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers can do bayesian inference. InInternational Conference on Learning Representations, pages 81861–81875, 2022
2022
-
[14]
Neural networks and the bias/variance dilemma.Neural Computation, 4(1):1–58, 1992
Stuart Geman, Elie Bienenstock, and René Doursat. Neural networks and the bias/variance dilemma.Neural Computation, 4(1):1–58, 1992
1992
-
[15]
TabPFN: A trans- former that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A trans- former that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[16]
TabICL: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 50817–50847, 2025
2025
-
[17]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[18]
A framework for multiple-instance learning
Oded Maron and Tomás Lozano-Pérez. A framework for multiple-instance learning. InAdvances in Neural Information Processing Systems, volume 10, pages 570–576, 1997
1997
-
[19]
A review of multi-instance learning assumptions.The Knowledge Engineering Review, 25(1):1–25, 2010
James Foulds and Eibe Frank. A review of multi-instance learning assumptions.The Knowledge Engineering Review, 25(1):1–25, 2010
2010
-
[20]
Multiple instance learning: A survey of problem characteristics and applications.Pattern Recognition, 77: 329–353, 2018
Marc-André Carbonneau, Veronika Cheplygina, Eric Granger, and Ghyslain Gagnon. Multiple instance learning: A survey of problem characteristics and applications.Pattern Recognition, 77: 329–353, 2018. 13
2018
-
[21]
xMIL: Insightful explanations for multiple instance learning in histopathology
Julius Hense, Mina Jamshidi Idaji, Oliver Eberle, Thomas Schnake, Jonas Dippel, Laure Ciernik, Oliver Buchstab, Andreas Mock, Frederick Klauschen, and Klaus Robert Muller. xMIL: Insightful explanations for multiple instance learning in histopathology. InAdvances in Neural Information Processing Systems, pages 8300–8328, 2024
2024
-
[22]
Predicting lymph node metastasis using histopathological images based on multiple instance learning with deep graph convolution
Yu Zhao, Fan Yang, Yuqi Fang, Hailing Liu, Niyun Zhou, Jun Zhang, Jiarui Sun, Sen Yang, Bjoern Menze, Xinjuan Fan, et al. Predicting lymph node metastasis using histopathological images based on multiple instance learning with deep graph convolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4837–4846, 2020
2020
-
[23]
Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature Medicine, 25(8):1301–1309, 2019
Gabriele Campanella, Matthew G Hanna, Luke Geneslaw, Allen Miraflor, Vitor Werneck Krauss Silva, Klaus J Busam, Edi Brogi, Victor E Reuter, David S Klimstra, and Thomas J Fuchs. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature Medicine, 25(8):1301–1309, 2019
2019
-
[24]
Howard, James Dolezal, Sara Kochanny, Jefree Schulte, Heather Chen, Lara Heij, Dezheng Huo, Rita Nanda, Olufunmilayo I
Frederick M. Howard, James Dolezal, Sara Kochanny, Jefree Schulte, Heather Chen, Lara Heij, Dezheng Huo, Rita Nanda, Olufunmilayo I. Olopade, Jakob N. Kather, Nicole Cipriani, Robert L. Grossman, and Alexander T. Pearson. The impact of site-specific digital histology signatures on deep learning model accuracy and bias.Nature Communications, 12(1):4423, 2021
2021
-
[25]
Towards robust foundation models for digital pathology.arXiv preprint arXiv:2507.17845, 2025
Jonah Kömen, Edwin D de Jong, Julius Hense, Hannah Marienwald, Jonas Dippel, Philip Naumann, Eric Marcus, Lukas Ruff, Maximilian Alber, Jonas Teuwen, et al. Towards robust foundation models for digital pathology.arXiv preprint arXiv:2507.17845, 2025
arXiv 2025
-
[26]
Medi: Metadata-guided diffusion models for mitigating biases in tumor classification
David Jacob Drexlin, Jonas Dippel, Julius Hense, Niklas Prenißl, Grégoire Montavon, Frederick Klauschen, and Klaus-Robert Müller. Medi: Metadata-guided diffusion models for mitigating biases in tumor classification. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 379–388, 2025
2025
-
[27]
Alexander Möllers, Julius Hense, Florian Schulz, Timo Milbich, Maximilian Alber, and Lukas Ruff. Mind the gap: Continuous magnification sampling for pathology foundation models.arXiv preprint arXiv:2601.02198, 2026
arXiv 2026
-
[28]
Confounding factors and biases abound when predicting molecular biomarkers from histological images.Nature Biomedical Engineering, pages 1–15, 2026
Muhammad Dawood, Kim Branson, Sabine Tejpar, Nasir Rajpoot, and Fayyaz ul Amir Afsar Minhas. Confounding factors and biases abound when predicting molecular biomarkers from histological images.Nature Biomedical Engineering, pages 1–15, 2026
2026
-
[29]
Lu, Bowen Chen, Andrew Zhang, Drew F
Ming Y. Lu, Bowen Chen, Andrew Zhang, Drew F. K. Williamson, Richard J. Chen, Tong Ding, Long Phi Le, Yung-Sung Chuang, and Faisal Mahmood. Visual language pretrained multiple instance zero-shot transfer for histopathology images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19764–19775, 2023
2023
-
[30]
MIL-Adapter: Coupling multiple instance learning and vision-language adapters for few-shot slide-level classification.Medical Image Analysis, 110:103964, 2026
Pablo Meseguer, Rocío del Amor, and Valery Naranjo. MIL-Adapter: Coupling multiple instance learning and vision-language adapters for few-shot slide-level classification.Medical Image Analysis, 110:103964, 2026
2026
-
[31]
Do-PFN: In-Context Learning for Causal Effect Estimation
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. Do-PFN: In-Context Learning for Causal Effect Estimation. InAdvances in Neural Information Processing Systems, volume 38, pages 174811–174848, 2025
2025
-
[32]
From tables to time: Extending TabPFN-v2 to time series forecasting.arXiv arXiv:2501.02945, 2025
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. From tables to time: Extending TabPFN-v2 to time series forecasting.arXiv arXiv:2501.02945, 2025. 14
arXiv 2025
-
[33]
PFNs4BO: In-context learning for Bayesian optimization
Samuel Müller, Matthias Feurer, Noah Hollmann, and Frank Hutter. PFNs4BO: In-context learning for Bayesian optimization. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 25444–25470, 2023
2023
-
[34]
MapPFN: Learning causal perturbation maps in context
Marvin Sextro, Weronika Kłos, and Gabriel Dernbach. MapPFN: Learning causal perturbation maps in context. InICLR 2026 Workshop on Generative AI in Genomics (Gen2), 2026
2026
-
[35]
Utilizing TabPFN for multi-instance data with scarce labels
Nikolaus Kopp, Alexander Fuchs, Markus Feuerstein, Phillip Paller, and Franz Pernkopf. Utilizing TabPFN for multi-instance data with scarce labels. InEurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[36]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4651–4664, 2021
2021
-
[37]
Deep Sets
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander Smola. Deep Sets. InAdvances in Neural Information Processing Systems, volume 30, pages 3394–3404, 2017
2017
-
[38]
TabPFN-Wide: Continued pre-training for extreme feature counts
Christopher Kolberg, Katharina Eggensperger, and Nico Pfeifer. TabPFN-Wide: Continued pre-training for extreme feature counts. InEurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[39]
Real-TabPFN: Improving Tabular Foundation Models via Continued Pre-training With Real-World Data
Anurag Garg, Muhammad Ali, Noah Hollmann, Lennart Purucker, Samuel Müller, and Frank Hutter. Real-TabPFN: Improving Tabular Foundation Models via Continued Pre-training With Real-World Data. InProceedings of the 1st ICML Workshop on Foundation Models for Structured Data, 2025
2025
-
[40]
The road less scheduled.arXiv arXiv:2405.15682, 2024
Aaron Defazio, Xingyu Yang, Harsh Mehta, Konstantin Mishchenko, Ahmed Khaled, and Ashok Cutkosky. The road less scheduled.arXiv arXiv:2405.15682, 2024
arXiv 2024
-
[41]
Pytorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: an imperative style, high-performa...
2019
-
[42]
Tools and practices for responsible AI engineering.arXiv preprint arXiv:2201.05647, 2022
Ryan Soklaski, Justin Goodwin, Olivia Brown, Michael Yee, and Jason Matterer. Tools and practices for responsible AI engineering.arXiv preprint arXiv:2201.05647, 2022
arXiv 2022
-
[43]
nanoTabPFN: A Lightweight and Educational Reimplementation of TabPFN
Alexander Pfefferle, Johannes Hog, Lennart Purucker, and Frank Hutter. nanoTabPFN: A Lightweight and Educational Reimplementation of TabPFN. InEurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[44]
Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research, 12(85):2825– 2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research...
2011
-
[45]
Torchmil: A pytorch-based library for deep multiple instance learning.Neurocomputing, 680:133286, 2026
Francisco M Castro-Macías, Francisco J Sáez-Maldonado, Pablo Morales-Álvarez, and Rafael Molina. Torchmil: A pytorch-based library for deep multiple instance learning.Neurocomputing, 680:133286, 2026. 15
2026
-
[46]
Frey and David J
Peter W. Frey and David J. Slate. Letter recognition using Holland-style adaptive classifiers. Machine Learning, 6(2):161–182, 1991
1991
-
[47]
Parameterized neural networks for high-energy physics.The European Physical Journal C, 76(5):235, 2016
Pierre Baldi, Kyle Cranmer, Taylor Faucett, Peter Sadowski, and Daniel Whiteson. Parameterized neural networks for high-energy physics.The European Physical Journal C, 76(5):235, 2016
2016
-
[48]
Flanders, Luciano M
Adam E. Flanders, Luciano M. Prevedello, George Shih, Safwan S. Halabi, Jayashree Kalpathy- Cramer, Robyn Ball, John T. Mongan, Anouk Stein, Felipe C. Kitamura, Matthew P. Lungren, Gagandeep Choudhary, Lesley Cala, Luiz Coelho, Monique Mogensen, Fanny Morón, Elka Miller, Ichiro Ikuta, Vahe Zohrabian, Olivia McDonnell, Christie Lincoln, Lubdha Shah, David ...
2019
-
[49]
Benchmark loaders for RSNA-ICH are taken fromtorchmil[45]
as re-implemented inMIL-Lab [10], and theTabPFN-v2 model fromTabPFN [17]; all classical baselines (logistic regression, SVM, PCA, stratified cross-validation) usescikit-learn [44]. Benchmark loaders for RSNA-ICH are taken fromtorchmil[45]. We run our experiments on a high-performance cluster. ICMIL pretraining runs are executed on a single NVIDIA A100 wit...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.