Gated KalmaNet: A Fading Memory Layer Through Test-Time Ridge Regression
Pith reviewed 2026-05-21 17:54 UTC · model grok-4.3
The pith
Gated KalmaNet uses full Kalman filter covariance for better long-context recall in state-space models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
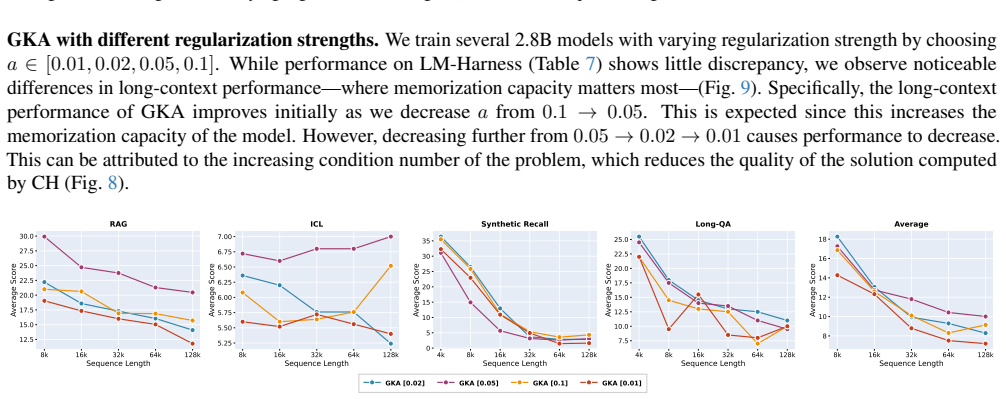
Gated KalmaNet maintains the full error covariance and computes the exact Kalman gain. Under a steady-state assumption that enables parallelization, this reduces to an online ridge regression with constant memory and linear compute. The method addresses numerical issues in low precision with adaptive regularization via input-dependent gating and Chebyshev Iteration for stability.
What carries the argument
The steady-state Kalman filter reduced to online ridge regression, which carries the argument by providing covariance-aware updates instead of identity approximations.
If this is right
- Outperforms existing SSM layers like Mamba2 and Gated DeltaNet on short-context tasks.
- Achieves more than 10% relative improvement on long-context RAG and LongQA up to 128k tokens.
- Outperforms Mamba when extended to ImageNet classification.
- Provides constant memory and linear compute for sequence modeling.
Where Pith is reading between the lines
- This approach could be extended to other recurrent models by incorporating similar covariance tracking.
- Hardware-aware implementations may allow practical scaling to contexts beyond 128k tokens.
- Linking neural layers to classical filtering theory opens paths for analyzing stability and convergence in deep networks.
Load-bearing premise
The steady-state assumption that reduces the Kalman filter recurrence to online ridge regression and enables parallelization.
What would settle it
A direct comparison on a long-sequence task where the error covariance is observed to not reach steady state, leading to degraded performance or inability to parallelize training.
Figures







read the original abstract
Linear State-Space Models (SSMs) offer an efficient alternative to softmax Attention with constant memory and linear compute, but their lossy, fading summary of the past hurts recall-oriented tasks. We propose Gated KalmaNet (GKA, pronounced "gee-ka"), a layer that accounts for the full past while retaining SSM-style efficiency. We ground our approach in the Kalman Filter (KF), and show that several existing SSM layers (DeltaNet, Gated DeltaNet, Kimi Delta Attention) are approximations to the KF recurrence under an identity error covariance assumption, which ignores how past keys and values should optimally influence state updates. In contrast, GKA maintains the full error covariance and computes the exact Kalman gain. Under a steady-state assumption that enables parallelization, this reduces to an online ridge regression with constant memory and linear compute. The standard KF equations are numerically unstable in low-precision settings (e.g., bfloat16) and hard to parallelize on GPUs. We address this with (1) adaptive regularization via input-dependent gating to control the ridge regression's condition number, and (2) Chebyshev Iteration, which we show is more stable than conventional iterative solvers in low precision. We further develop hardware-aware chunk-wise kernels for efficient training. Empirically, GKA outperforms existing SSM layers (e.g., Mamba2, Gated DeltaNet) on short-context tasks and achieves more than 10\% relative improvement on long-context RAG and LongQA up to 128k tokens. We further show GKA outperforms Mamba when extended to ImageNet classification. Our code, including Triton kernels for training and inference (vLLM), along with a model zoo of GKA-based Hybrid models at 8B and 32B scale on HuggingFace, is released under Apache 2.0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Gated KalmaNet (GKA), a linear state-space model layer derived from the Kalman filter. It maintains the full error covariance and computes the exact Kalman gain, in contrast to prior SSM layers (DeltaNet, Gated DeltaNet) that assume identity covariance. Under a steady-state assumption the recurrence reduces to online ridge regression, enabling constant memory and linear compute. Numerical stability in low precision is addressed via input-dependent gating for adaptive regularization and Chebyshev iteration; hardware-aware chunked kernels are provided for training. Experiments report gains over Mamba2 and Gated DeltaNet on short-context tasks and >10% relative improvement on long-context RAG and LongQA up to 128k tokens, plus better ImageNet classification when replacing Mamba.
Significance. If the central reduction and stability fixes hold, the work supplies a principled mechanism for incorporating full posterior covariance into SSMs without sacrificing the efficiency that makes them attractive for long contexts. The public release of Triton kernels, vLLM integration, and 8B/32B hybrid model weights strengthens reproducibility. The approach directly targets the fading-memory limitation of existing SSMs on recall-oriented tasks.
major comments (2)
- [§3, §4] §3 (Kalman filter derivation) and §4 (steady-state reduction): the claim that GKA computes the exact Kalman gain from the full covariance is load-bearing for the optimality argument, yet the manuscript provides no quantitative bound or empirical measurement of the approximation error introduced by the steady-state covariance assumption on non-stationary sequences. In long-context RAG/LongQA settings the token statistics are typically non-stationary; without such a bound it is unclear whether the fixed-gain ridge-regression form retains the claimed advantage over identity-covariance baselines.
- [§5] §5 (experiments): the reported >10% relative gains on LongQA and RAG lack error bars, ablation isolating the steady-state step, and sensitivity analysis to the gating parameters that control the ridge condition number. Without these controls it is difficult to attribute improvements specifically to the full-covariance mechanism rather than to the adaptive regularization or kernel implementation.
minor comments (2)
- [§2] Notation for the error covariance matrix and the input-dependent gating function should be introduced with explicit dimensions and initialization details in the main text rather than only in the appendix.
- [Figure 2] Figure 2 (condition-number plots) would benefit from a direct comparison against the unregularized Kalman filter in bfloat16 to quantify the stability gain of the proposed Chebyshev solver.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of our claims and experimental rigor. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3, §4] §3 (Kalman filter derivation) and §4 (steady-state reduction): the claim that GKA computes the exact Kalman gain from the full covariance is load-bearing for the optimality argument, yet the manuscript provides no quantitative bound or empirical measurement of the approximation error introduced by the steady-state covariance assumption on non-stationary sequences. In long-context RAG/LongQA settings the token statistics are typically non-stationary; without such a bound it is unclear whether the fixed-gain ridge-regression form retains the claimed advantage over identity-covariance baselines.
Authors: We agree that the steady-state assumption is an approximation whose error is not quantified in the current manuscript, and that this weakens the optimality argument for non-stationary data. The reduction to online ridge regression remains a principled incorporation of covariance structure that is absent from identity-covariance baselines, but a bound or measurement would strengthen the presentation. In the revision we will add an empirical analysis on synthetic non-stationary sequences that measures the deviation from the time-varying Kalman filter and compares against identity-covariance variants under controlled degrees of non-stationarity. revision: yes
-
Referee: [§5] §5 (experiments): the reported >10% relative gains on LongQA and RAG lack error bars, ablation isolating the steady-state step, and sensitivity analysis to the gating parameters that control the ridge condition number. Without these controls it is difficult to attribute improvements specifically to the full-covariance mechanism rather than to the adaptive regularization or kernel implementation.
Authors: We accept that the current experimental section would benefit from additional controls. The revised manuscript will include error bars computed over multiple random seeds for the long-context tasks and a sensitivity study sweeping the gating parameters that affect the ridge condition number. An ablation that fully isolates the steady-state assumption by running the exact time-varying Kalman filter is not feasible at 128k context length; we will instead provide such an ablation on shorter sequences where the full filter remains tractable and discuss the computational barrier for longer contexts. revision: partial
- Direct empirical ablation of the steady-state assumption against the exact time-varying Kalman filter on sequences of length 128k, which would require quadratic memory and compute.
Circularity Check
No circularity: derivation reduces KF to ridge regression under explicit steady-state assumption
full rationale
The provided abstract and context present a standard mathematical reduction: full-covariance KF yields exact Kalman gain, which under a stated steady-state assumption simplifies to online ridge regression for parallelization and constant memory. This is an approximation justified for efficiency, not a self-definition or fitted input renamed as prediction. Adaptive regularization via gating is introduced to address numerical instability in low precision, not to force the core result. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via prior work are evident in the given text. The central claim remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- input-dependent gating parameters
axioms (2)
- standard math Kalman filter recurrence equations under identity process noise or measurement models
- domain assumption Steady-state assumption on the error covariance
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under a steady-state assumption that enables parallelization, this reduces to solving an online ridge regression problem with constant memory and linear compute cost.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GKA maintains the full error covariance and computes the exact Kalman gain
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Preconditioned DeltaNet: Curvature-aware Sequence Modeling for Linear Recurrences
Preconditioned delta-rule models with a diagonal curvature approximation improve upon standard DeltaNet, GDN, and KDA by better approximating the test-time regression objective.
-
Priming: Hybrid State Space Models From Pre-trained Transformers
Priming transfers knowledge from pre-trained Transformers to hybrid SSM-attention models, recovering performance with minimal additional tokens and showing Gated KalmaNet outperforming Mamba-2 on long-context reasonin...
Reference graph
Works this paper leans on
-
[1]
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys John- son, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models.arXiv preprint arXiv:2312.04927, 2023. 2, 7, 15, 25
-
[2]
Hybrid Architectures for Language Models: Systematic Analysis and Design Insights
Sangmin Bae, Bilge Acun, Haroun Habeeb, Seungyeon Kim, Chien-Yu Lin, Liang Luo, Junjie Wang, and Carole-Jean Wu. Hybrid architectures for language models: Systematic anal- ysis and design insights.arXiv preprint arXiv:2510.04800,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Maximilian Beck, Korbinian Pöppel, Markus Spanring, An- dreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xl- stm: Extended long short-term memory.Advances in Neural Information Processing Systems, 37:107547–107603, 2024. 15
work page 2024
-
[4]
Sneha Chaudhari, Varun Mithal, Gungor Polatkan, and Rohan Ramanath. An attentive survey of attention models.ACM Transactions on Intelligent Systems and Technology, 12(5): 1–32, 2021. 2
work page 2021
-
[5]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, et al. Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery.arXiv preprint arXiv:2410.05080, 2024. 15
-
[7]
Hao Cui, Zahra Shamsi, Gowoon Cheon, Xuejian Ma, Shu- tong Li, Maria Tikhanovskaya, Peter Norgaard, Nayantara Mudur, Martyna Plomecka, Paul Raccuglia, et al. Curie: Eval- uating llms on multitask scientific long context understanding and reasoning.arXiv preprint arXiv:2503.13517, 2025. 15
-
[8]
Transformer-xl: At- tentive language models beyond a fixed-length context
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-xl: At- tentive language models beyond a fixed-length context. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 2978–2988, 2019. 15
work page 2019
-
[9]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InInternational Conference on Machine Learning,
-
[10]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Soham De, Samuel L Smith, Anushan Fernando, Alek- sandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with lo- cal attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Hymba: A hybrid-head architecture for small language models
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zi- jia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, et al. Hymba: A hybrid-head architecture for small language mod- els.arXiv preprint arXiv:2411.13676, 2024. 15
-
[13]
Hanpei Fang, Sijie Tao, Nuo Chen, Kai-Xin Chang, and Tet- suya Sakai. Do large language models favor recent content? a study on recency bias in llm-based reranking.arXiv preprint arXiv:2509.11353, 2025. 4
-
[14]
Lizhe Fang, Yifei Wang, Zhaoyang Liu, Chenheng Zhang, Stefanie Jegelka, Jinyang Gao, Bolin Ding, and Yisen Wang. What is wrong with perplexity for long-context language modeling?arXiv preprint arXiv:2410.23771, 2024. 8
-
[15]
The language model evaluation harness, 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Gold- ing, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle Mc- Donell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The lan...
work page 2024
-
[16]
How to train long-context language models (effectively)
Tianyu Gao, Alexander Wettig, Howard Yen, and Danqi Chen. How to train long-context language models (effectively). In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7376–7399, 2025. 8
work page 2025
-
[17]
Zamba: A compact 7B SSM hybrid model,
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, and Beren Mil- lidge. Zamba: A compact 7b ssm hybrid model.arXiv preprint arXiv:2405.16712, 2024. 15
-
[18]
Is flash attention stable?arXiv preprint arXiv:2405.02803, 2024
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, et al. Is flash attention stable?arXiv preprint arXiv:2405.02803, 2024. 7
-
[19]
The Johns Hopkins University Press, 2013
Gene H Golub and Charles F Van Loan.Matrix Computations (4th ed.). The Johns Hopkins University Press, 2013. 3
work page 2013
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023. 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently mod- eling long sequences with structured state spaces.CoRR, abs/2111.00396, 2021. 15
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. Combining recurrent, convo- lutional, and continuous-time models with linear state space layers.Advances in neural information processing systems, 34:572–585, 2021. 15
work page 2021
-
[23]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997. 2
work page 1997
-
[24]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. An empirical analysis of compute-optimal large language model training.Advances in neural information processing systems, 35:30016–30030, 2022. 26
work page 2022
-
[25]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Gins- burg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024. 2, 8, 25
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Samy Jelassi, David Brandfonbrener, Sham M Kakade, and Eran Malach. Repeat after me: Transformers are bet- ter than state space models at copying.arXiv preprint arXiv:2402.01032, 2024. 15
-
[27]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023. 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
R. E. Kalman. A new approach to linear filtering and predic- tion problems.Journal of Basic Engineering, 82(1):35–45,
-
[29]
Needle in a haystack - pressure testing llms
Gregory Kamradt. Needle in a haystack - pressure testing llms. https://github.com/gkamradt/LLMTest_ NeedleInAHaystack, 2023. 25
work page 2023
-
[30]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451, 2020. 15
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 15
work page 2023
-
[32]
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Guha, Sedrick Scott Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024. 7
work page 2024
-
[33]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al. Jamba: A hy- brid transformer-mamba language model.arXiv preprint arXiv:2403.19887, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Longhorn: State space models are amortized online learners
Bo Liu, Rui Wang, Lemeng Wu, Yihao Feng, Peter Stone, and Qiang Liu. Longhorn: State space models are amortized online learners. InInternational Conference on Learning Representations, 2025. 1, 2
work page 2025
-
[35]
Stefan Ljung and Lennart Ljung. Error propagation properties of recursive least-squares adaptation algorithms.Automatica, 21(2):157–167, 1985. 15
work page 1985
-
[36]
RanPAC: Random projections and pre-trained models for continual learning
Mark D McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton van den Hengel. RanPAC: Random projections and pre-trained models for continual learning. Advances in Neural Information Processing Systems, 2023. 3
work page 2023
-
[37]
Landmark attention: Random-access infinite context length for transformers
Amirkeivan Mohtashami and Martin Jaggi. Landmark atten- tion: Random-access infinite context length for transformers. arXiv preprint arXiv:2305.16300, 2023. 15
-
[38]
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite con- text transformers with infini-attention.arXiv preprint arXiv:2404.07143, 101, 2024. 15
work page internal anchor Pith review arXiv 2024
-
[39]
On estimating regression.Theory of Probability & Its Applications, 9(1):141–142, 1964
Elizbar A Nadaraya. On estimating regression.Theory of Probability & Its Applications, 9(1):141–142, 1964. 2
work page 1964
-
[40]
Expansion span: Combin- ing fading memory and retrieval in hybrid state space models
Elvis Nunez, Luca Zancato, Benjamin Bowman, Aditya Go- latkar, Wei Xia, and Stefano Soatto. Expansion span: Combin- ing fading memory and retrieval in hybrid state space models. arXiv preprint arXiv:2412.13328, 2024. 8, 15
-
[41]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fer- nando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. InInternational Conference on Machine Learning, pages 26670–26698. PMLR, 2023. 15
work page 2023
-
[42]
Marconi: Prefix caching for the era of hybrid llms.arXiv preprint arXiv:2411.19379, 2024
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zan- cato, Tri Dao, Yida Wang, and Ravi Netravali. Marconi: Prefix caching for the era of hybrid llms.arXiv preprint arXiv:2411.19379, 2024. 15
-
[43]
Residual polynomials and the Cheby- shev method
Fabian Pedregosa. Residual polynomials and the Cheby- shev method. http://fa.bianp.net/blog/2020/ polyopt/, 2020. 4
work page 2020
-
[44]
Eagle and finch: RWKV with matrix-valued states and dynamic recurrence
Bo Peng, Daniel Goldstein, Quentin Gregory Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Teddy Ferdinan, Kranthi Kiran GV , Haowen Hou, Satyapriya Kr- ishna, Ronald McClelland Jr., Niklas Muennighoff, Fares Obeid, Atsushi Saito, Guangyu Song, Haoqin Tu, Ruichong Zhang, Bingchen Zhao, Qihang Zhao, Jian Zhu, and Rui-Jie Zhu. Eagle and ...
-
[45]
Rwkv-7" goose" with expressive dynamic state evolution
Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, et al. Rwkv-7" goose" with expressive dynamic state evolution. Technical report, arXiv preprint arXiv:2503.14456, 2025. 2
-
[46]
Mathematics of continual learning
Liangzu Peng and René Vidal. Mathematics of continual learning. Technical report, arXiv:2504.17963 [cs.LG], 2025. 3
-
[47]
TSVD: Bridging theory and practice in continual learning with pre-trained models
Liangzu Peng, Juan Elenter, Joshua Agterberg, Alejandro Ribeiro, and Rene Vidal. TSVD: Bridging theory and practice in continual learning with pre-trained models. InInternational Conference on Learning Representations, 2025. 3
work page 2025
-
[48]
Kilt: a benchmark for knowledge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. Kilt: a benchmark for knowledge intensive language tasks. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech...
work page 2021
-
[49]
Sayed.Fundamentals of Adaptive Filtering
A.H. Sayed.Fundamentals of Adaptive Filtering. Wiley,
- [50]
-
[51]
Lin- ear transformers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Lin- ear transformers are secretly fast weight programmers. In International conference on machine learning, 2021. 2
work page 2021
-
[52]
Samir Shah, Francesco Palmieri, and Michael Datum. Opti- mal filtering algorithms for fast learning in feedforward neural networks.Neural Networks, 5(5):779–787, 1992. 3
work page 1992
-
[53]
Deltaproduct: Im- proving state-tracking in linear rnns via householder products
Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, and Riccardo Grazzi. Deltaproduct: Im- proving state-tracking in linear rnns via householder products. Technical report, arXiv:2502.10297v6 [cs.LG], 2025. 2
-
[55]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive net- work: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023. 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient at- tention architecture.arXiv preprint arXiv:2510.26692, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 2017. 1, 2, 15
work page 2017
-
[58]
Attention: Self-expression is all you need, 2022
René Vidal. Attention: Self-expression is all you need, 2022. 2
work page 2022
-
[59]
Mesanet: Sequence modeling by locally optimal test- time training
Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Maximilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, et al. Mesanet: Sequence modeling by locally optimal test- time training. Technical report, arXiv:2506.05233 [cs.LG],
-
[60]
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Bran- don Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, et al. An empirical study of mamba-based language models.arXiv preprint arXiv:2406.07887, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Test- time regression: a unifying framework for designing se- quence models with associative memory
Ke Alexander Wang, Jiaxin Shi, and Emily B Fox. Test- time regression: a unifying framework for designing se- quence models with associative memory. Technical report, arXiv:2501.12352v3 [cs.LG], 2025. 3
-
[62]
Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, pages 359–372,
Geoffrey S Watson. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, pages 359–372,
-
[63]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 6, 29
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Gated linear attention transformers with hardware-efficient training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. InInternational Conference on Machine Learning, 2024. 1, 2, 4, 6, 7, 15
work page 2024
-
[65]
Parallelizing linear transformers with the delta rule over sequence length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. InAdvances in Neural Information Processing Systems, pages 115491–115522. Curran Asso- ciates, Inc., 2024. 10, 15
work page 2024
-
[66]
Parallelizing linear transformers with the delta rule over sequence length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. InNeural Information Processing Systems, 2024. 1, 2, 3, 4, 6
work page 2024
-
[67]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InInterna- tional Conference on Learning Representations, 2025. 2, 6, 7, 8, 10, 15
work page 2025
-
[68]
HELMET: How to evaluate long-context language models effectively and thoroughly
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. HELMET: How to evaluate long-context language models effectively and thoroughly. InInternational Conference on Learning Representations (ICLR), 2025. 2, 8, 25
work page 2025
-
[69]
Native sparse attention: Hardware- aligned and natively trainable sparse attention
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, et al. Native sparse attention: Hardware- aligned and natively trainable sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 23078– 23097, 2025. 15
work page 2025
-
[70]
Luca Zancato, Alessandro Achille, Giovanni Paolini, Alessan- dro Chiuso, and Stefano Soatto. Stacked residuals of dy- namic layers for time series anomaly detection.arXiv preprint arXiv:2202.12457, 2022. 15
-
[71]
B'mojo: Hybrid state space realizations of foundation models with eidetic and fading memory
Luca Zancato, Arjun Seshadri, Yonatan Dukler, Aditya Go- latkar, Yantao Shen, Benjamin Bowman, Matthew Trager, Alessandro Achille, and Stefano Soatto. B'mojo: Hybrid state space realizations of foundation models with eidetic and fading memory. InAdvances in Neural Information Process- ing Systems, pages 130433–130462. Curran Associates, Inc.,
-
[72]
Guanxiong Zeng, Yang Chen, Bo Cui, and Shan Yu. Continual learning of context-dependent processing in neural networks. Nature Machine Intelligence, 1(8):364–372, 2019. 3 A. Related Work Since the introduction of Self-Attention [57], significant research has been conducted to reduce its quadratic cost in processing long input sequences. As models and syste...
work page 2019
-
[73]
or Linear Time-Invariant dynamical systems [22, 70], to those introducing novel adaptive or gated state updates [9, 41, 64]. Despite their differences, all SSMs follow the same basic working principle inspired by classical state-space models [28]: they process the input sequence by maintaining afixed-sizestate that acts as a compressed (lossy) representat...
-
[74]
where g(ω) decreases, therefore we have ω1 ≤ω 0. Thus ω1 lies in (ω∗ 1, ω∗
-
[75]
We could then conclude inductively that ω∗ 1 < ω i ≤ω i−1 for all i= 1,
again. We could then conclude inductively that ω∗ 1 < ω i ≤ω i−1 for all i= 1, . . . , r. From Lemma 3 we know that the update of ωi in (weight schedule) would not create much numerical concern in a forward pass, as we haveω i ∈[1,2]for alli. Furthermore, we can bound the rate at whichω i converges toω ∗ 1: Lemma 4.Defineκ:= L µ . For anyi= 1, . . . , r, ...
-
[76]
The proof is concluded by unrolling the above recurrence
·(ω i−1 −ω ∗ 1) (i) = ρ2ω∗ 1 4−ρ 2ωi−1 ·(ω i−1 −ω ∗ 1) (ii) ≤ ρ2wi−1ω∗ 1 4 ·(ω i−1 −ω ∗ 1) (iii) ≤ 1− p 1−ρ 2 ·(ω i−1 −ω ∗ 1) (iv) = κ−1 κ+ 1 · √κ−1√κ+ 1 ·(ω i−1 −ω ∗ 1) Here, (i) follows from the fact that ω∗ 1 is a fixed point, (ii) follows from Lemma 3 that ωi ≤ω i−1, (iii) follows from the definition ofω ∗ 1 and the factw i−1 ≤2, and (iv) follows from...
-
[77]
First-order methods for solving Hξ=q converge at most at a rate Ra := √κ−1√κ+1 , and we see ωi converges at an even faster rate. Numerically, assuming κ= L µ = 1.02 0.02 = 51, we then have: R≈0.7253, R 5 ≈0.2, R 10 ≈0.04, R 20 ≈0.0016, R 30 ≈6×10 −5 Ra ≈0.7543, R 5 a ≈0.244, R 10 a ≈0.0597, R 20 a ≈0.0036, R 30 a ≈0.0002. Thus, withκ= 51, the update ofω i...
-
[78]
Constant regularizationWe train same model architecture (as above) with λt = 0.25 (a constant). This choice of 0.25 is motivated from concurrent work [59] which explored a similar ridge regression objective for LLM training. As shown in Fig. 6, without strict condition number control, gradient norms spike during training, leading to increased cross entrop...
-
[79]
We train a model with adaptive weights
Adaptive weighting (gating). We train a model with adaptive weights. Specifically, for allt≥i , we parameterize the weight for thei th sample at time-steptasη t,i =Qt j=i+1 γj, with eachγ j ∈[0,1]learnable
-
[80]
No weighting. We train the same model architecture as above, but with no weights. This essentially results in an unweighted ridge regression objective obtained by settingη i = 1in (3). Table 6 shows clear benefits of adapting weighting with improvements across the board on all LM-Harness tasks considered, thereby validating our hypothesis. Table 6.Adaptiv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.