Trace2Policy: From Expert Behavior Traces to Self-Evolving Decision Agents
Pith reviewed 2026-06-27 13:17 UTC · model grok-4.3
The pith
Iterative error clustering on rule documents lifts decision accuracy from 70 percent to 79.6 percent when compiled to deterministic Python.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
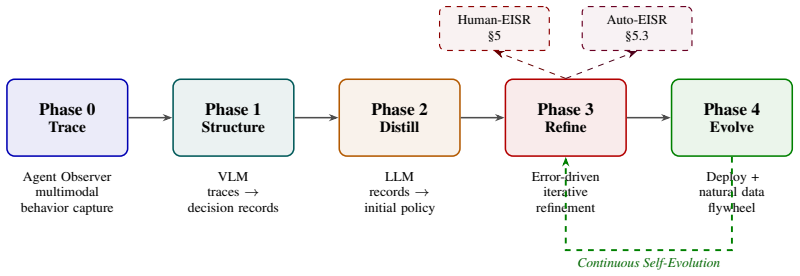
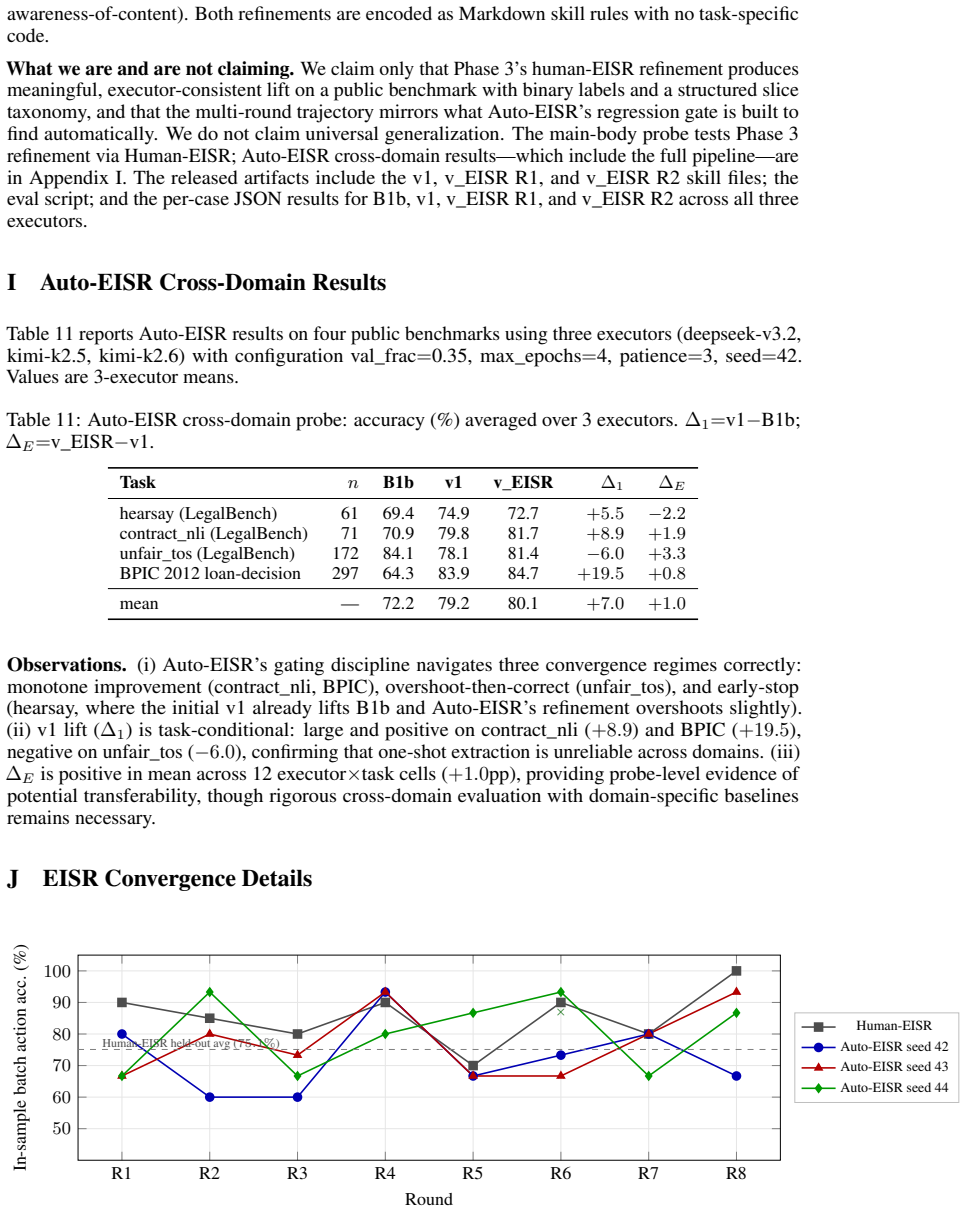
Trace2Policy recovers tacit expert decision rules from behavior traces and refines them via EISR, an iterative process that clusters execution errors into MISSING, WRONG, or CONFLICT categories, patches the rule document, and accepts changes only after they pass a regression gate. Eight rounds of this refinement raise accuracy on a deployed audit pool from the one-shot baseline of approximately 70 percent to 79.6 percent when the rules are compiled into deterministic Python, eliminating LLM inference calls entirely. The refined rules also outperform an LLM-prompt version of the same content by 9.8 percentage points, and an automated variant reproduces the gains at far lower cost while genera
What carries the argument
EISR (Error-driven Iterative Skill Refinement), the loop that executes a human-readable rule document on validation data, clusters root causes into three error types, applies targeted patches, and commits only those that pass a regression gate.
If this is right
- Rule quality is the dominant lever, so gains from refinement hold across different underlying models rather than requiring larger models.
- Execution form matters: the same refined content performs materially better as compiled Python than as an LLM prompt.
- The compiled pipeline can replace a pure-LLM baseline in production and maintain higher accuracy without fallback to the model.
- An automated version of the refinement loop transfers to other decision domains without domain-specific re-engineering.
Where Pith is reading between the lines
- Enterprises could treat rule documents as living artifacts that accumulate improvements from each new batch of cases.
- The same clustering-plus-gate pattern could be tested on other structured decision settings where auditability is required.
- If the regression gate is set too conservatively it may block useful adaptations; if set too loosely it may allow gradual drift.
Load-bearing premise
The method assumes that errors can be reliably grouped into the three categories MISSING, WRONG, or CONFLICT and that the regression gate on the chosen validation set will detect any new problems created by the patches.
What would settle it
Apply the EISR loop to a fresh validation set in which the three error categories are independently verified as incomplete or in which accepted patches later produce failures on cases the gate did not flag.
Figures
read the original abstract
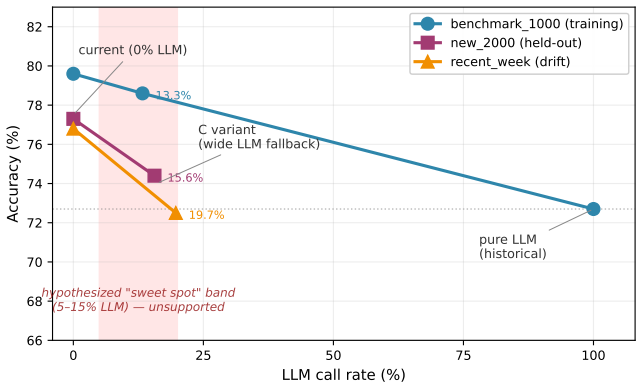
Decision rules that enterprise experts apply tacitly -- in auditing, compliance, and contract review -- can be systematically recovered and improved through iterative error analysis. We present \textbf{Trace2Policy}, whose core mechanism -- \textbf{EISR} (\textbf{E}rror-driven \textbf{I}terative \textbf{S}kill \textbf{R}efinement) -- maintains a human-readable rule document as its optimization target: each round executes the rules on a validation set, clusters errors by root cause into MISSING, WRONG, or CONFLICT types, applies targeted patches, and commits only those that pass a regression gate. \textbf{For this class of compliance-sensitive, skewed-base-rate decision tasks, we identify rule quality -- not model capability -- as the dominant performance lever}: across five LLMs, one-shot distillation plateaus near $\sim$70\% on the deployed pool, while eight EISR rounds lift the same rules to 79.6\% when compiled into deterministic Python -- zero LLM calls at inference. \textbf{Execution form compounds the gain: in production, the same EISR-refined content runs 9.8~pp higher as compiled Python than as an LLM prompt, a form-and-engineering bundle the 22-day deployment matured together.} Deployed for 22 days at a major logistics carrier (3,349 audit cases), the compiled pipeline outperforms the pure-LLM baseline it replaced (72.7\%); on these calibrated, skewed-base-rate workloads, re-enabling LLM fallback monotonically degrades accuracy. An LLM-driven variant, \textbf{Auto-EISR}, reproduces this refinement at \$5--\$10 per cycle versus $\sim$70 expert-hours, and transfers to four public benchmarks spanning legal reasoning (LegalBench) and process-mining decisions (BPIC 2012) without re-engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Trace2Policy, whose core is EISR (Error-driven Iterative Skill Refinement): a loop that executes a human-readable rule document on a validation set, clusters errors into MISSING/WRONG/CONFLICT, applies targeted patches, and commits only those passing a regression gate. It claims that for compliance tasks with skewed base rates, rule quality—not model scale—is the dominant lever, with one-shot distillation plateauing near 70% across five LLMs while eight EISR rounds raise the same rules to 79.6% when compiled to deterministic Python (zero LLM calls at inference); the refined rules outperform the prior LLM baseline in a 22-day deployment on 3,349 cases and transfer to LegalBench and BPIC 2012.
Significance. If the refinement loop is robust, the work demonstrates that iterative, human-readable rule improvement can outperform both prompting and distillation on skewed-base-rate decision tasks while enabling deterministic execution; the 22-day real deployment and cross-benchmark transfer supply external checks that are uncommon in this area.
major comments (2)
- [EISR mechanism] Method section on EISR: the description states that errors are clustered into MISSING/WRONG/CONFLICT and that only regression-gate-passing patches are committed, yet provides no quantitative evidence on clustering reliability (human vs. LLM), inter-rater agreement, or the size and coverage of the validation set used for the gate. This directly affects the central claim that the measured lift from ~70% to 79.6% reflects generalizable rule improvement rather than overfitting or undetected regressions.
- [Deployment results and abstract] Results on the deployed pool and abstract: the headline comparison (one-shot distillation plateaus near 70% while EISR reaches 79.6%) and the statement that re-enabling LLM fallback degrades accuracy rest on the regression gate; without details on how the validation set was constructed or how representative it is of the skewed base-rate distribution, the internal validity of the 8-round improvement cannot be evaluated.
minor comments (2)
- [Abstract and results] The abstract reports concrete accuracy numbers from the 22-day deployment but the main text does not tabulate the per-round accuracy trajectory or the exact stopping criterion for the eight EISR rounds.
- [Method] Notation for the three error categories (MISSING, WRONG, CONFLICT) is introduced without an explicit definition or example in the first occurrence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on methodological transparency. We address each major point below, indicating revisions where we can strengthen the manuscript without misrepresenting the original work.
read point-by-point responses
-
Referee: [EISR mechanism] Method section on EISR: the description states that errors are clustered into MISSING/WRONG/CONFLICT and that only regression-gate-passing patches are committed, yet provides no quantitative evidence on clustering reliability (human vs. LLM), inter-rater agreement, or the size and coverage of the validation set used for the gate. This directly affects the central claim that the measured lift from ~70% to 79.6% reflects generalizable rule improvement rather than overfitting or undetected regressions.
Authors: We agree that the current manuscript provides only a high-level description of the clustering and gate without quantitative support. The validation set was a held-out portion of the deployment pool sampled to preserve the observed base-rate skew, but exact size, coverage statistics, and formal inter-rater metrics were not reported. We will revise the Methods section to describe the sampling procedure and validation-set size in aggregate terms. Clustering combined expert review with LLM-assisted grouping; we will clarify this division but cannot supply post-hoc agreement scores that were never computed. revision: partial
-
Referee: [Deployment results and abstract] Results on the deployed pool and abstract: the headline comparison (one-shot distillation plateaus near 70% while EISR reaches 79.6%) and the statement that re-enabling LLM fallback degrades accuracy rest on the regression gate; without details on how the validation set was constructed or how representative it is of the skewed base-rate distribution, the internal validity of the 8-round improvement cannot be evaluated.
Authors: The abstract and results will be updated to cross-reference an expanded Methods description of validation-set construction. We will add text stating that the set was drawn via stratified sampling from the same 22-day deployment distribution to maintain base-rate fidelity. This addition directly addresses the internal-validity concern while leaving the reported accuracy figures unchanged. revision: yes
- Quantitative inter-rater agreement scores for the error-clustering step, as these metrics were not collected in the original study.
Circularity Check
No significant circularity; empirical gains measured against external baselines
full rationale
The paper's central claim (rule quality as dominant lever, with lift from ~70% one-shot to 79.6% after EISR rounds in compiled Python) is supported by direct accuracy measurements on a deployed validation pool, public benchmarks (LegalBench, BPIC 2012), and a 22-day real deployment. These are compared to independent baselines (one-shot distillation, pure-LLM inference) rather than quantities defined in terms of the method's own fitted parameters or self-citations. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the text. The EISR process (error clustering into MISSING/WRONG/CONFLICT + regression gate) is presented as an empirical procedure whose outputs are externally validated, not derived by construction from its inputs. This is the most common honest finding for an applied systems paper with external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Errors observed on the validation set can be accurately partitioned into the three categories MISSING, WRONG, or CONFLICT.
- domain assumption The validation set distribution is sufficiently close to the deployment distribution that patches improving validation performance also improve deployment performance.
invented entities (1)
-
EISR (Error-driven Iterative Skill Refinement)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
NeurIPS , year=
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning , author=. NeurIPS , year=
-
[3]
ICLR (Spotlight) , year=
AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials , author=. ICLR (Spotlight) , year=
-
[4]
NeurIPS , year=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. NeurIPS , year=
-
[5]
CVPR , year=
CogAgent: A Visual Language Model for GUI Agents , author=. CVPR , year=
-
[6]
ICML , year=
GPT-4V(ision) is a Generalist Web Agent, if Grounded , author=. ICML , year=
-
[7]
Process Mining: Data Science in Action , author=
-
[8]
NeurIPS , year=
Self-Refine: Iterative Refinement with Self-Feedback , author=. NeurIPS , year=
-
[9]
NeurIPS , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. NeurIPS , year=
-
[11]
ICLR , year=
Large Language Models as Optimizers , author=. ICLR , year=
-
[12]
ICLR , year=
AgentRefine: Enhancing Agent Generalization through Refinement Tuning , author=. ICLR , year=
-
[16]
Nature , volume=
Mathematical discoveries from program search with large language models , author=. Nature , volume=
-
[17]
ICLR , year=
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization , author=. ICLR , year=
-
[19]
Artificial Intelligence , volume=
Generalization as Search , author=. Artificial Intelligence , volume=
-
[21]
Automation and Human Performance: Theory and Applications , editor=
Human Decision Makers and Automated Decision Aids: Made for Each Other? , author=. Automation and Human Performance: Theory and Applications , editor=
-
[22]
Journal of the American Medical Informatics Association , volume=
Automation Bias: A Systematic Review of Frequency, Effect Mediators, and Mitigators , author=. Journal of the American Medical Informatics Association , volume=
-
[23]
Journal of Electrocardiology , volume=
Automation Bias in Medicine: The Influence of Automated Diagnoses on Interpreter Accuracy and Uncertainty when Reading Electrocardiograms , author=. Journal of Electrocardiology , volume=
-
[24]
Adaptation of Agentic
Jiang, Pengcheng and Lin, Jiacheng and Shi, Zhiyi and others , journal=. Adaptation of Agentic
-
[25]
Experience Compression Spectrum: Unifying Memory, Skills, and Rules in
Zhang, Xing and Wang, Guanghui and Cui, Yanwei and Qiu, Wei and Li, Ziyuan and Zhu, Bing and He, Peiyang , journal=. Experience Compression Spectrum: Unifying Memory, Skills, and Rules in
-
[29]
SoK: Agentic Skills---Beyond Tool Use in
Jiang, Yanna and Li, Delong and Deng, Haiyu and Ma, Baihe and Wang, Xu and Wang, Qin and Yu, Guangsheng , journal=. SoK: Agentic Skills---Beyond Tool Use in
-
[30]
Business Process Intelligence Challenge 2012 (
van Dongen, Boudewijn , howpublished=. Business Process Intelligence Challenge 2012 (
2012
-
[31]
Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning
Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. In NeurIPS, 2024
2024
-
[32]
Shuzhen Bi, Mengsong Wu, Hao Hao, Keqian Li, Wentao Liu, Siyu Song, Hongbo Zhao, and Aimin Zhou. Automating skill acquisition through large-scale mining of open-source agentic repositories: A framework for multi-agent procedural knowledge extraction. arXiv preprint arXiv:2603.11808, 2026
-
[33]
Automation bias in medicine: The influence of automated diagnoses on interpreter accuracy and uncertainty when reading electrocardiograms
Raymond R Bond, Tomas Novotny, Irena Andrsova, Lumir Koc, Martina Sisakova, Dewar Finlay, Daniel Guldenring, James McLaughlin, Aaron Peace, Victoria McGilligan, et al. Automation bias in medicine: The influence of automated diagnoses on interpreter accuracy and uncertainty when reading electrocardiograms. Journal of Electrocardiology, 51 0 (6): 0 S6--S11, 2018
2018
-
[34]
Agentrefine: Enhancing agent generalization through refinement tuning
Dayuan Fu, Keqing He, Yejie Wang, Wentao Hong, Zhuoma Gongque, Weihao Zeng, Wei Wang, Jingang Wang, Xunliang Cai, and Weiran Xu. Agentrefine: Enhancing agent generalization through refinement tuning. In ICLR, 2025
2025
-
[35]
Automation bias: A systematic review of frequency, effect mediators, and mitigators
Kate Goddard, Abdul Roudsari, and Jeremy C Wyatt. Automation bias: A systematic review of frequency, effect mediators, and mitigators. Journal of the American Medical Informatics Association, 19 0 (1): 0 121--127, 2012
2012
-
[36]
Neel Guha, Julian Nyarko, Daniel E Ho, Christopher R \'e , Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N Rockmore, et al. LegalBench : A collaboratively built benchmark for measuring legal reasoning in large language models. arXiv preprint arXiv:2308.11462, 2023
-
[37]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxuan Zhang, Juanzi Li, et al. Cogagent: A visual language model for gui agents. CVPR, 2024
2024
-
[38]
Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, et al. Adaptation of agentic AI : A survey of post-training, memory, and skills. arXiv preprint arXiv:2512.16301, 2025
-
[39]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. Sok: Agentic skills---beyond tool use in LLM agents. arXiv preprint arXiv:2602.20867, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. In NeurIPS, 2023
2023
-
[42]
Generalization as search
Tom M Mitchell. Generalization as search. Artificial Intelligence, 18 0 (2): 0 203--226, 1982
1982
-
[43]
Kathleen L Mosier and Linda J Skitka. Human decision makers and automated decision aids: Made for each other? In Raja Parasuraman and Mustapha Mouloua, editors, Automation and Human Performance: Theory and Applications, pages 201--220. Lawrence Erlbaum Associates, 1996
1996
-
[44]
Yi Nian, Aojie Yuan, Haiyue Zhang, Jiate Li, and Yue Zhao. Auditable agents. arXiv preprint arXiv:2604.05485, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab
Krista Opsahl-Ong, Michael J. Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs. arXiv preprint arXiv:2406.11695, 2024
-
[46]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, et al. Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models. Nature, 625: 0 468--475, 2024
2024
-
[48]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In NeurIPS, 2023
2023
-
[49]
A survey on self-evolution of large language models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, and Jingren Zhou. A survey on self-evolution of large language models. arXiv preprint arXiv:2404.14387, 2024
-
[50]
Process Mining: Data Science in Action
Wil MP Van der Aalst. Process Mining: Data Science in Action. Springer, 2 edition, 2016
2016
-
[51]
Business process intelligence challenge 2012 ( BPI challenge 2012)
Boudewijn van Dongen. Business process intelligence challenge 2012 ( BPI challenge 2012). https://data.4tu.nl/articles/dataset/BPI_Challenge_2012/12689204/1, 2012
2012
-
[52]
Voyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. In NeurIPS, 2023
2023
-
[53]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward. arXiv preprint arXiv:2602.12430, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials. In ICLR (Spotlight), 2025
2025
-
[55]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. In ICLR, 2024
2024
-
[57]
Retroformer: Retrospective large language agents with policy gradient optimization
Weiran Yao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh Murthy, Zeyuan Chen, Jianguo Zhang, Devansh Arpit, et al. Retroformer: Retrospective large language agents with policy gradient optimization. In ICLR, 2024
2024
-
[58]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic ``differentiation'' via text. arXiv preprint arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Experience Compression Spectrum: Unifying Memory, Skills, and Rules in LLM Agents
Xing Zhang, Guanghui Wang, Yanwei Cui, Wei Qiu, Ziyuan Li, Bing Zhu, and Peiyang He. Experience compression spectrum: Unifying memory, skills, and rules in LLM agents. arXiv preprint arXiv:2604.15877, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Gpt-4v(ision) is a generalist web agent, if grounded
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v(ision) is a generalist web agent, if grounded. ICML, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.