Lodestar: An Online-Learning LLM Inference Router
Pith reviewed 2026-06-28 16:53 UTC · model grok-4.3
The pith
Lodestar routes each LLM inference request by training an online predictor on per-request cluster snapshots to choose the instance that maximizes a reward such as low time-to-first-token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
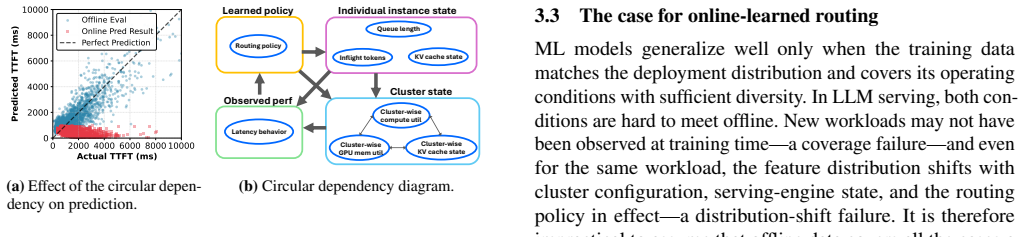
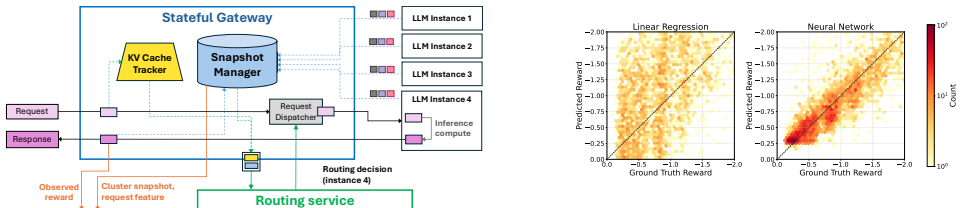
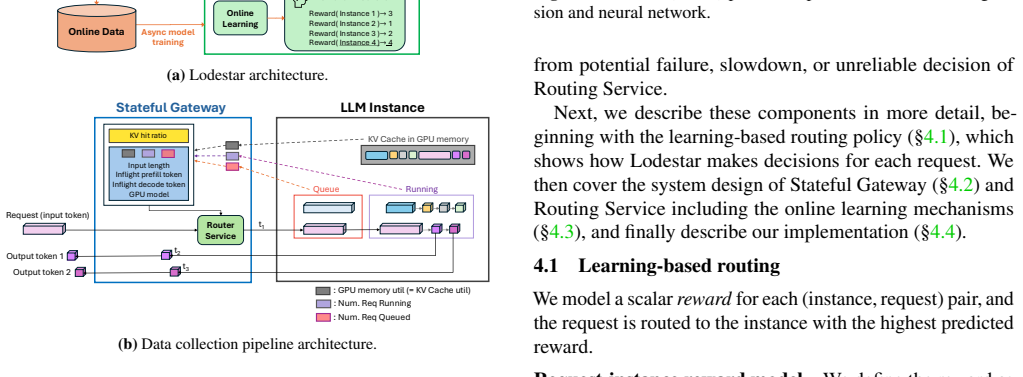
Lodestar continuously collects a snapshot of the cluster at per-request level, including real-time instance state, request characteristics, and observed performance, and trains an online reward predictor that it uses to route inference requests to the instance that will maximize a given reward such as minimizing TTFT.
What carries the argument
The online reward predictor trained in real time from per-request snapshots of instance state, request characteristics, and observed performance.
If this is right
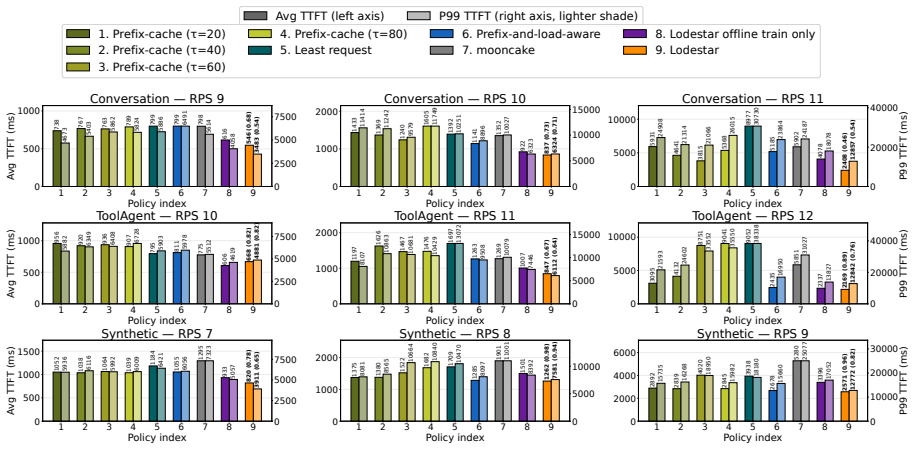
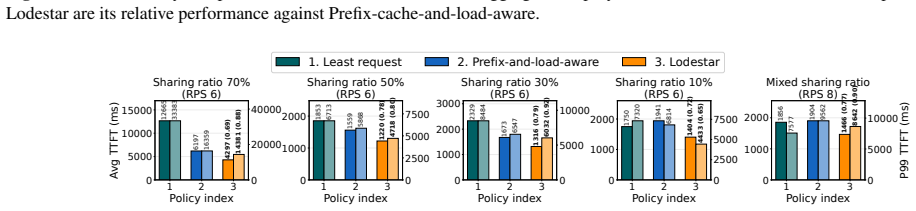
- Average TTFT drops by a factor of 1.41 and P99 TTFT by 1.47 relative to a strong prefix-cache and load-aware baseline.
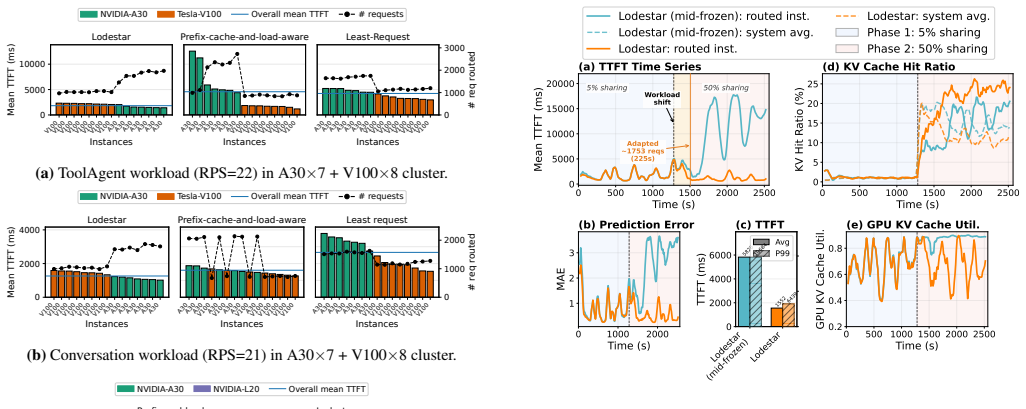
- Gains reach up to 4.38x on heterogeneous clusters and the system learns effective policies within about five minutes.
- The same snapshot-driven predictor can be retargeted to other rewards such as throughput or energy without changing the core collection mechanism.
- No changes are required to the underlying serving engine because the router operates at the request-assignment layer.
Where Pith is reading between the lines
- The predictor could be extended to jointly optimize routing and batch-size decisions if the snapshots also captured pending batch queues.
- Because adaptation happens online, the approach may naturally handle model updates or engine version changes that would invalidate static heuristics.
- In multi-tenant settings the same machinery could route requests across models of different sizes once the reward function is made model-aware.
Load-bearing premise
Continuously collecting detailed per-request snapshots of instance state and performance is feasible at scale without adding significant overhead, and the online predictor adapts reliably without instability during learning.
What would settle it
Run Lodestar on a production-scale cluster while measuring the latency overhead of the snapshot collection and predictor training; if the added cost erases the reported TTFT gains or routing becomes unstable in the first minutes, the central claim does not hold.
Figures





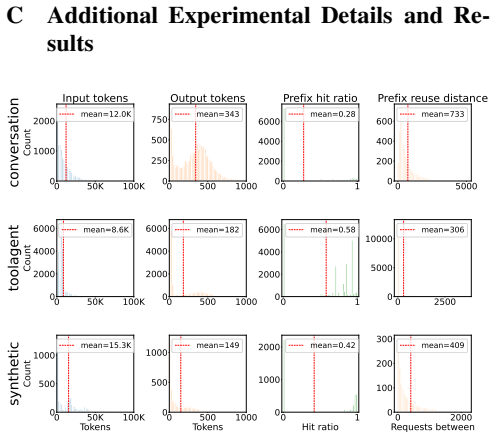
read the original abstract
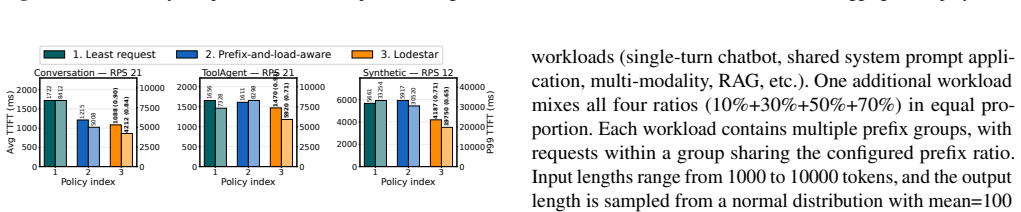
Efficiently serving large language model (LLM) inference tasks is crucial both for user-perceived latency such as time-to-first-token (TTFT) and for GPU utilization. However, LLM request routing, that is, assigning each inference request to a GPU instance, is particularly challenging: execution is highly input-dependent; batching and KV-cache reuse create strong cross-request coupling; and latency responds nonlinearly to context length, model/engine settings, and heterogeneous accelerators. As a result, simple traditional load balancing algorithms, and even heuristics tailored for LLM inference, fail to achieve good performance. We present Lodestar, a novel learning-based request routing system for distributed GPU clusters. Lodestar continuously collects a snapshot of the cluster at per-request level, including real-time instance state, request characteristics, and observed performance, and trains an online reward predictor that it uses to route inference requests to the instance that will maximize given reward (e.g., minimizing TTFT). Lodestar is cloud-native and works seamlessly with existing serving stacks (vLLM). With continuous online adaptation to changing workloads and infrastructure conditions, Lodestar achieves 1.41x lower average TTFT and 1.47x lower P99 TTFT on average (up to 2.15x/1.86x on homogeneous and 4.38x/4.42x on heterogeneous clusters) compared to a state-of-the-art prefix cache and load-aware heuristic, and learns these efficient routing strategies within about 5 minutes, based on experiments in a public cloud GPU cluster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Lodestar, a cloud-native online-learning request router for distributed LLM inference clusters that integrates with vLLM. It continuously collects per-request snapshots of instance state, request characteristics, and observed performance to train an online reward predictor, which is then used to route each request to the instance expected to maximize a chosen reward (e.g., minimizing TTFT). Experiments on a public-cloud GPU cluster report that Lodestar achieves 1.41× lower average TTFT and 1.47× lower P99 TTFT on average (with larger gains on heterogeneous clusters) versus a state-of-the-art prefix-cache and load-aware heuristic, while adapting to workload changes within approximately five minutes.
Significance. If the overhead of snapshot collection and online prediction is shown to be negligible, the work would provide a practical, adaptive alternative to static heuristics for LLM serving, particularly valuable in heterogeneous or dynamic environments where input-dependent execution and KV-cache coupling make traditional load balancing ineffective. The emphasis on continuous online adaptation and seamless integration with existing stacks is a positive contribution.
major comments (3)
- [Abstract and experimental evaluation (likely §5–6)] The abstract and experimental evaluation sections do not report measurements of the per-request snapshot collection latency, reward-predictor inference time, or overall routing decision overhead when integrated with vLLM. Because the headline TTFT gains are modest on homogeneous clusters (2.15×/1.86×), even a few milliseconds of added latency per request could materially reduce or reverse the claimed benefit; this measurement is load-bearing for the central performance claim.
- [System design and online learning sections (likely §3–4)] The paper states that Lodestar “learns these efficient routing strategies within about 5 minutes,” yet provides no details on the online training procedure (update frequency, reward model architecture, handling of non-stationarity, or safeguards against poor decisions during early learning). Without these, it is impossible to assess whether the reported adaptation speed is reproducible or stable across workloads.
- [Evaluation setup (likely §5)] The comparison baseline is described only as “a state-of-the-art prefix cache and load-aware heuristic.” The manuscript should explicitly name the baseline, cite its source, and report its configuration parameters so that the 1.41×/1.47× gains can be independently verified.
minor comments (2)
- [Figures in evaluation section] Figure captions and axis labels should explicitly state whether TTFT numbers include or exclude the routing decision latency.
- [Abstract and §5] The abstract claims results “on average” across experiments; the manuscript should clarify the number of runs, statistical significance tests, and workload characteristics (request arrival rates, context-length distributions) used to compute the averages.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: The abstract and experimental evaluation sections do not report measurements of the per-request snapshot collection latency, reward-predictor inference time, or overall routing decision overhead when integrated with vLLM. Because the headline TTFT gains are modest on homogeneous clusters (2.15×/1.86×), even a few milliseconds of added latency per request could materially reduce or reverse the claimed benefit; this measurement is load-bearing for the central performance claim.
Authors: We agree that quantifying these overheads is essential to support the performance claims. In the revised manuscript we will add measurements of per-request snapshot collection latency, reward-predictor inference time, and end-to-end routing decision overhead (under representative loads) to the experimental evaluation section. revision: yes
-
Referee: The paper states that Lodestar “learns these efficient routing strategies within about 5 minutes,” yet provides no details on the online training procedure (update frequency, reward model architecture, handling of non-stationarity, or safeguards against poor decisions during early learning). Without these, it is impossible to assess whether the reported adaptation speed is reproducible or stable across workloads.
Authors: We will expand the system design and online-learning sections with a detailed description of the training procedure, including update frequency, reward-model architecture, handling of non-stationarity, and any safeguards used during early learning. revision: yes
-
Referee: The comparison baseline is described only as “a state-of-the-art prefix cache and load-aware heuristic.” The manuscript should explicitly name the baseline, cite its source, and report its configuration parameters so that the 1.41×/1.47× gains can be independently verified.
Authors: We will name the baseline explicitly, add the appropriate citation, and report its configuration parameters in the evaluation-setup section. revision: yes
Circularity Check
No circularity: purely empirical performance claims with no derivation chain
full rationale
The paper presents an online learning router for LLM inference with empirical results on TTFT reductions versus baselines. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains appear in the abstract or described method. The central claims rest on measured performance in cloud experiments rather than any reduction of results to inputs by construction. This is the expected non-finding for an applied systems paper whose value is in implementation and benchmarking.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://docs.nvidia.com/ dynamo/latest/
Nvidia dynamo. https://docs.nvidia.com/ dynamo/latest/. Accessed: 26-Oct-2025
2025
-
[2]
https: //www.amd.com/en/products/accelerators/ instinct/mi300/mi300a.html, 2023
AMD Instinct MI300A Accelerators. https: //www.amd.com/en/products/accelerators/ instinct/mi300/mi300a.html, 2023
2023
-
[3]
https://sharegpt.com, 2023
ShareGPT: Share your wildest ChatGPT conversations. https://sharegpt.com, 2023
2023
-
[4]
https: //www.nvidia.com/en-us/data-center/ technologies/blackwell-architecture/, 2024
NVIDIA Blackwell Architecture. https: //www.nvidia.com/en-us/data-center/ technologies/blackwell-architecture/, 2024
2024
-
[5]
https:// blog.google/products/google-cloud/ ironwood-tpu-age-of-inference/, 2025
Google Ironwood: The first Google TPU for the age of inference. https:// blog.google/products/google-cloud/ ironwood-tpu-age-of-inference/, 2025
2025
-
[6]
JITServe: SLO-aware LLM serving with imprecise re- quest information, 2025
2025
-
[7]
llm-d.https://github.com/llm-d/llm-d, 2025
2025
-
[8]
https://www.nvidia
NVIDIA Vera Rubin Platform. https://www.nvidia. com/en-us/data-center/technologies/rubin/, 2025
2025
-
[9]
Gulavani, Alexey Tu- manov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tu- manov, and Ramachandran Ramjee. Taming throughput- latency tradeoff in LLM inference with Sarathi-Serve. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024
2024
-
[10]
Gulavani, and Ramachandran Ramjee
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, and Ramachandran Ramjee. Sarathi: Efficient llm inference by piggyback- ing decodes with chunked prefills, 2023
2023
-
[11]
Llmrank: Under- standing llm strengths for model routing, 2025
Shubham Agrawal and Prasang Gupta. Llmrank: Under- standing llm strengths for model routing, 2025
2025
-
[12]
Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale, 2022
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale, 2022
2022
-
[13]
L-Eval: Insti- tuting standardized evaluation for long context language models, 2023
Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-Eval: Insti- tuting standardized evaluation for long context language models, 2023
2023
-
[14]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Sim- ple llm inference acceleration framework with multiple decoding heads. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[15]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei A. Zaharia, and James Y . Zou. Frugalgpt: How to use large language models while re- ducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
{IMPRESS}: An {Importance- Informed}{Multi-Tier} prefix {KV} storage system for large language model inference
Weijian Chen, Shuibing He, Haoyang Qu, Ruidong Zhang, Siling Yang, Ping Chen, Yi Zheng, Baoxing Huai, and Gang Chen. {IMPRESS}: An {Importance- Informed}{Multi-Tier} prefix {KV} storage system for large language model inference. In23rd USENIX Con- ference on File and Storage Technologies (FAST 25), pages 187–201, 2025
2025
-
[17]
arXiv preprint arXiv:2510.09665 , year=
Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang. Lmcache: An efficient kv cache layer for enterprise-scale llm inference.arXiv preprint arXiv:2510.09665, 2025
-
[18]
Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios N. Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: an open platform for evaluating llms by human preference. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[19]
Lmdeploy: A toolkit for com- pressing, deploying, and serving llm
LMDeploy Contributors. Lmdeploy: A toolkit for com- pressing, deploying, and serving llm. https://github. com/InternLM/lmdeploy, 2023
2023
-
[20]
Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
2022
-
[21]
Pre- fillonly: An inference engine for prefill-only workloads in large language model applications
Kuntai Du, Bowen Wang, Chen Zhang, Yiming Cheng, Qing Lan, Hejian Sang, Yihua Cheng, Jiayi Yao, Xiaox- uan Liu, Yifan Qiao, Ion Stoica, and Junchen Jiang. Pre- fillonly: An inference engine for prefill-only workloads in large language model applications. InProceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles, SOSP ’25, page 399–4...
2025
-
[22]
Turbotransformers: an efficient gpu serving system for transformer models
Jiarui Fang, Yang Yu, Chengduo Zhao, and Jie Zhou. Turbotransformers: an efficient gpu serving system for transformer models. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 389–402, 2021
2021
-
[23]
Efficient llm scheduling by learn- ing to rank
Yichao Fu, Siqi Zhu, Runlong Su, Aurick Qiao, Ion Sto- ica, and Hao Zhang. Efficient llm scheduling by learn- ing to rank. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 59006–59029. Curran Associates, Inc., 2024
2024
-
[24]
Cost-effective attention reuse across multi-turn conversations in large language model serv- ing
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. Cost-effective attention reuse across multi-turn conversations in large language model serv- ing. InUSENIX Annual Technical Conference (ATC 24), 2024
2024
-
[25]
Prompt cache: Modular attention reuse for low-latency inference.Pro- ceedings of Machine Learning and Systems, 6:325–338, 2024
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference.Pro- ceedings of Machine Learning and Systems, 6:325–338, 2024
2024
-
[26]
Serving DNNs like clockwork: Performance predictability from the bottom up
Arpan Gujarati, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kaufmann, Ymir Vigfusson, and Jonathan Mace. Serving DNNs like clockwork: Performance predictability from the bottom up. In14th USENIX Sym- posium on Operating Systems Design and Implementa- tion (OSDI 20), pages 443–462. USENIX Association, November 2020
2020
-
[27]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shi- rong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Towards generalized routing: Model and agent orchestration for adaptive and efficient inference, 2025
Xiyu Guo, Shan Wang, Chunfang Ji, Xuefeng Zhao, Wenhao Xi, Yaoyao Liu, Qinglan Li, Chao Deng, and Junlan Feng. Towards generalized routing: Model and agent orchestration for adaptive and efficient inference, 2025
2025
-
[29]
RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shan- tanu Acharya, Dima Rekesh, Fei Jia, and Boris Gins- burg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
2024
-
[30]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Alek- sander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Gonza- lez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonza- lez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[32]
InfiniGen: Efficient generative inference of large language models with dynamic KV cache management
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. InfiniGen: Efficient generative inference of large language models with dynamic KV cache management. In18th USENIX Symposium on Operating Systems De- sign and Implementation (OSDI 24), 2024
2024
-
[33]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[34]
LooGLE: Can long-context language models understand long contexts?, 2023
Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. LooGLE: Can long-context language models understand long contexts?, 2023
2023
-
[35]
Eagle: speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: speculative sampling requires rethinking feature uncertainty. InProceedings of the 41st Inter- national Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[36]
Opportunities and challenges in service layer traffic engineering
Gangmuk Lim, Aditya Prerepa, Brighten Godfrey, and Radhika Mittal. Opportunities and challenges in service layer traffic engineering. InProceedings of the 23rd ACM Workshop on Hot Topics in Networks, pages 352– 359, 2024
2024
-
[37]
KV-Cache Indexer: Architecture
llm-d Authors. KV-Cache Indexer: Architecture. https://github.com/llm-d/llm-d-kv-cache/ blob/main/docs/architecture.md, 2026. Ac- cessed: 2026-04-23
2026
-
[38]
Helix: Serving large language models over heterogeneous gpus and net- work via max-flow
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. Helix: Serving large language models over heterogeneous gpus and net- work via max-flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol- ume 1, pages 586–602, 2025
2025
-
[39]
Mitzenmacher
M. Mitzenmacher. The power of two choices in random- ized load balancing.IEEE Transactions on Parallel and Distributed Systems, 12(10):1094–1104, 2001
2001
-
[40]
Heterogeneity-aware cluster scheduling policies for deep learning workloads
Deepak Narayanan, Keshav Santhanam, Fiodar Kazhamiaka, Amar Phanishayee, and Matei Zaharia. Heterogeneity-aware cluster scheduling policies for deep learning workloads. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 481–498, 2020
2020
-
[41]
Fastertransformer
NVIDIA. Fastertransformer. https://github.com/ NVIDIA/FasterTransformer, 2020
2020
-
[42]
Dynamo kv-aware router
NVIDIA Dynamo team. Dynamo kv-aware router. https://docs.nvidia.com/dynamo/latest/ user-guides/kv-cache-aware-routing, 2025
2025
-
[43]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data, 2024
2024
-
[44]
Mar- coni: Prefix caching for the era of hybrid llms, 2025
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Mar- coni: Prefix caching for the era of hybrid llms, 2025
2025
-
[45]
Prefill-as-a-service: Kvcache of next-generation models could go cross-datacenter, 2026
Ruoyu Qin, Weiran He, Yaoyu Wang, Zheming Li, Xin- ran Xu, Yongwei Wu, Weimin Zheng, and Mingxing Zhang. Prefill-as-a-service: Kvcache of next-generation models could go cross-datacenter, 2026
2026
-
[46]
Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25), pages 155–170, Santa Clara, CA, February 2025. USENIX Association
2025
-
[47]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Geoffrey Gordon, David Dunson, and Miroslav Dudík, editors,Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pag...
2011
-
[48]
Dynaserve: Unified and elastic execution for dynamic disaggregated llm serving, 2025
Chaoyi Ruan, Yinhe Chen, Dongqi Tian, Yandong Shi, Yongji Wu, Jialin Li, and Cheng Li. Dynaserve: Unified and elastic execution for dynamic disaggregated llm serving, 2025
2025
-
[49]
Campbell, Aditya Akella, Christopher J
Divyanshu Saxena, Jiayi Chen, Sujay Yadalam, Yeonju Ro, Rohit Dwivedula, Eric H. Campbell, Aditya Akella, Christopher J. Rossbach, and Michael Swift. How i learned to stop worrying and love learned os policies. InProceedings of the 2025 Workshop on Hot Topics in Operating Systems, HotOS ’25, page 1–7, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[50]
Aibrix: Towards scalable, cost-effective large language model inference infrastructure, 2025
Jiaxin Shan, Varun Gupta, Le Xu, Haiyang Shi, Jingyuan Zhang, Ning Wang, Linhui Xu, Rong Kang, Tongping Liu, Yifei Zhang, Yiqing Zhu, Shuowei Jin, Gangmuk Lim, Binbin Chen, Zuzhi Chen, Xiao Liu, Xin Chen, Kante Yin, Chak-Pong Chung, Chenyu Jiang, Yicheng Lu, Jianjun Chen, Caixue Lin, Wu Xiang, Rui Shi, and Liguang Xie. Aibrix: Towards scalable, cost-effec...
2025
-
[51]
Preble: Efficient distributed prompt scheduling for llm serving, 2024
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dong- ming Li, and Yiying Zhang. Preble: Efficient distributed prompt scheduling for llm serving, 2024
2024
-
[52]
C3: Cutting tail latency in cloud data stores via adaptive replica selection
Lalith Suresh, Marco Canini, Stefan Schmid, and Anja Feldmann. C3: Cutting tail latency in cloud data stores via adaptive replica selection. In12th USENIX Sympo- sium on Networked Systems Design and Implementation (NSDI 15), pages 513–527, Oakland, CA, May 2015. USENIX Association
2015
-
[53]
AIBrix Gateway: Pre- fix Cache and Load-Aware Routing
The AIBrix Team. AIBrix Gateway: Pre- fix Cache and Load-Aware Routing. https: //github.com/vllm-project/aibrix/blob/main/ pkg/plugins/gateway/algorithms/README.md,
-
[54]
Introduced in AIBrix v0.3.0, accessed 2026-04- 22
2026
-
[55]
SGLang model gate- way: prefix_hash routing policy
The SGLang Team. SGLang model gate- way: prefix_hash routing policy. https: //github.com/sgl-project/sglang/blob/ 95910331797f9d42d69773d847910c10a050c247/ sgl-model-gateway/src/policies/prefix_hash. rs, 2025. Commit 9591033, accessed 2026-04-22
2025
-
[56]
GCR: Gradient coreset based re- play buffer selection for continual learning
Rishabh Tiwari, Krishnateja Killamsetty, Rishabh Iyer, and Pradeep Shenoy. GCR: Gradient coreset based re- play buffer selection for continual learning. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[57]
vllm seman- tic router
vLLM Semantic Router Team. vllm seman- tic router. https://github.com/vllm-project/ semantic-router, 2025
2025
-
[58]
Kvcache cache in the wild: Char- acterizing and optimizing kvcache cache at a large cloud provider
Jiahao Wang, Jinbo Han, Xingda Wei, Sijie Shen, Dingyan Zhang, Chenguang Fang, Rong Chen, Wenyuan Yu, and Haibo Chen. Kvcache cache in the wild: Char- acterizing and optimizing kvcache cache at a large cloud provider. In2025 USENIX Annual Technical Conference (USENIX ATC 25), 2025
2025
-
[59]
Hetis: Serving LLMs in heterogeneous GPU clusters with fine-grained and dynamic parallelism
Zizhao Wang, Yuhao Hu, Jiaqi Wang, Jiahao Du, Yanghua Liu, Yuyang Ma, et al. Hetis: Serving LLMs in heterogeneous GPU clusters with fine-grained and dynamic parallelism. InProceedings of the Inter- national Conference for High Performance Comput- ing, Networking, Storage and Analysis (SC ’25), 2025. https://arxiv.org/abs/2509.08309
-
[60]
MLaaS in the wild: Workload analysis and scheduling in large-scale heterogeneous GPU clus- ters
Qizhen Weng, Wencong Xiao, Yinghao Yu, Wei Wang, Cheng Wang, Jian He, Yong Li, Liping Zhang, Wei Lin, and Yu Ding. MLaaS in the wild: Workload analysis and scheduling in large-scale heterogeneous GPU clus- ters. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 945–960, 2022
2022
-
[61]
Fast distributed inference serving for large language models, 2024
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. Fast distributed inference serving for large language models, 2024
2024
-
[62]
Deserve: Towards affordable offline llm inference via decentralization, 2025
Linyu Wu, Xiaoyuan Liu, Tianneng Shi, Zhe Ye, and Dawn Song. Deserve: Towards affordable offline llm inference via decentralization, 2025
2025
-
[63]
Rum- ble, and Aaron Archer
Bartek Wydrowski, Robert Kleinberg, Stephen M. Rum- ble, and Aaron Archer. Load is not what you should balance: Introducing prequal. In21st USENIX Sympo- sium on Networked Systems Design and Implementation (NSDI 24), pages 1285–1299, Santa Clara, CA, April
-
[64]
Jiarong Xing, Yifan Qiao, Simon Mo, Xingqi Cui, Gur- Eyal Sela, Yang Zhou, Joseph Gonzalez, and Ion Stoica. Towards efficient and practical gpu multitasking in the era of llm.arXiv preprint arXiv:2508.08448, 2025
-
[65]
Orca: A distributed serving system for Transformer-Based generative mod- els
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative mod- els. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, Carlsbad, CA, July 2022. USENIX Association
2022
-
[66]
Prism: Cost-Efficient Multi-LLM Serving via GPU Memory Ballooning
Shan Yu, Jiarong Xing, Yifan Qiao, Mingyuan Ma, Yang- min Li, Yang Wang, Shuo Yang, Zhiqiang Xie, Shiyi Cao, Ke Bao, et al. Prism: Unleashing gpu sharing for cost-efficient multi-llm serving.arXiv preprint arXiv:2505.04021, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Gonzalez, Ion Stoica, and Hao Zhang
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. LMSYS-chat-1m: A large-scale real-world LLM conversation dataset. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[68]
Gonzalez, Clark Bar- rett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Bar- rett, and Ying Sheng. Sglang: Efficient execution of structured language model programs, 2024
2024
-
[69]
Dist- serve: disaggregating prefill and decoding for goodput- optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Dist- serve: disaggregating prefill and decoding for goodput- optimized large language model serving. InProceed- ings of the 18th USENIX Conference on Operating Sys- tems Design and Implementation, OSDI’24, USA, 2024. USENIX Association
2024
-
[70]
NanoFlow: Towards optimal large language model serving through- put
Kan Zhu, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Yufei Gao, Qinyu Xu, Tian Tang, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. NanoFlow: Towards optimal large language model serving through- put. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), 2025
2025
-
[71]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. Megascale- infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism. InPro...
2025
-
[72]
Prefix-and-load-aware (fp16)
-
[73]
Prefix-and-load-aware (quant)
-
[74]
bitsandbytes is a popular on-the-fly quantization method that compress FP16 KV into INT4/INT8 when storing them
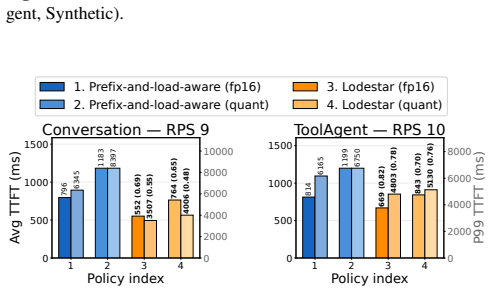
Lodestar (quant) Figure 16:TTFT performance with and without bitsandbytes quan- tization configuration on vLLM. bitsandbytes is a popular on-the-fly quantization method that compress FP16 KV into INT4/INT8 when storing them. When it is used, vLLM engine decompresses the KVs back to the original precision. It enables memory-efficient LLM inference at the c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.