Diffusion Image Generation with Explicit Modeling of Data Manifold Geometry
Pith reviewed 2026-06-29 22:42 UTC · model grok-4.3
The pith
Integrating discrete patch tokenization into continuous diffusion score functions explicitly models data manifold geometry for better image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MIND explicitly models manifold geometry by integrating discrete patch tokenization into the score function of a continuous diffusion model, enabled by soft top-k aggregation for end-to-end training, dual-branch high-frequency feature embeddings, and multi-stage transition sampling, resulting in an FID of 1.95 on ImageNet-256×256 with 715M parameters while surpassing larger models such as LlamaGen-3B.
What carries the argument
Soft top-k aggregation mechanism that integrates discrete patch tokenization into the continuous diffusion score function to enable explicit manifold geometry modeling.
If this is right
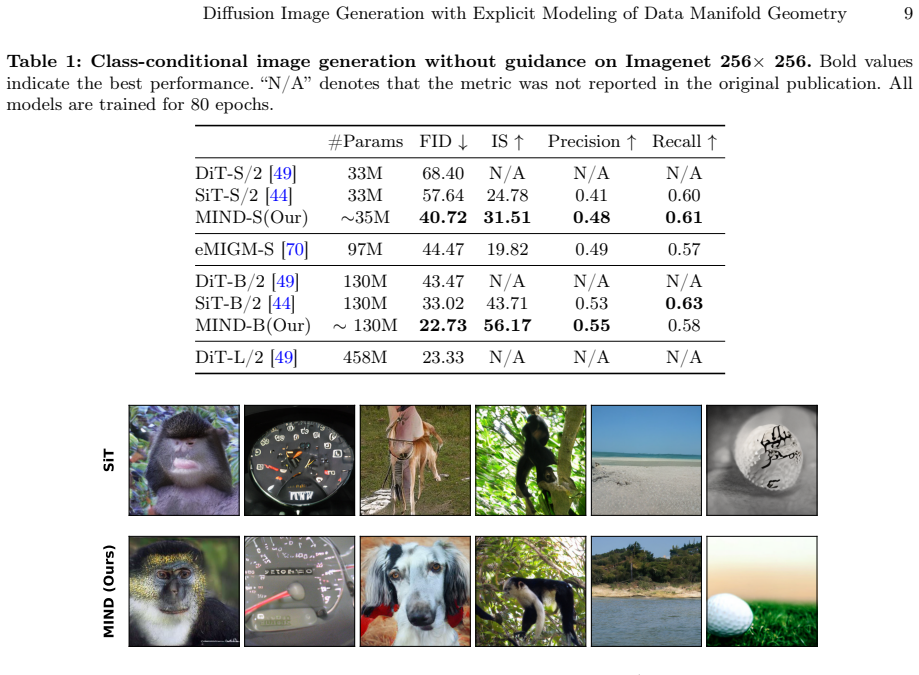
- The base model achieves an FID of 22.73 without guidance after 80 epochs, nearly halving the 43.47 FID of the vanilla DiT-B/2 baseline.
- The method reduces FID by 15.95 on average compared with DiT baselines and by 9.06 compared with SiT baselines.
- MIND-B with 130M parameters reaches an FID of 2.06 with guidance, surpassing the 3.1B-parameter LlamaGen-3B.
- MIND-XL with 715M parameters further reduces the FID to 1.95.
Where Pith is reading between the lines
- The hybrid discrete-continuous structure may extend to other high-dimensional generative tasks where both structural tokens and flexible sampling are useful.
- Multi-stage transition sampling could be tested in non-image domains such as audio waveform generation to handle timestep-dependent transitions.
- Controlled ablations isolating the manifold-modeling component would clarify whether geometry awareness improves sample diversity in addition to fidelity.
- Applying the same tokenization integration at higher resolutions could test whether the parameter efficiency scales beyond 256x256 images.
Load-bearing premise
The soft top-k aggregation preserves sufficient information from the discrete tokens so that the manifold geometry modeling, rather than other implementation details, drives the reported FID improvements.
What would settle it
Train an otherwise identical model without the discrete patch tokenization and soft top-k components on the same dataset and epochs, then measure whether the FID rises substantially above 1.95.
Figures




read the original abstract
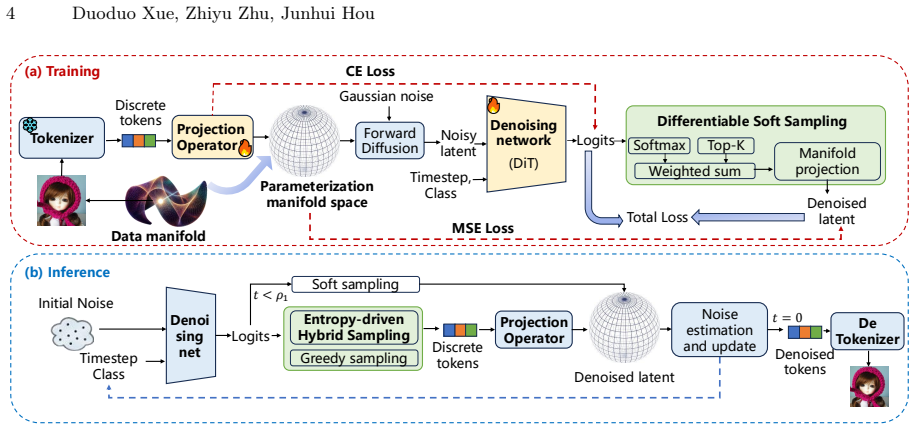
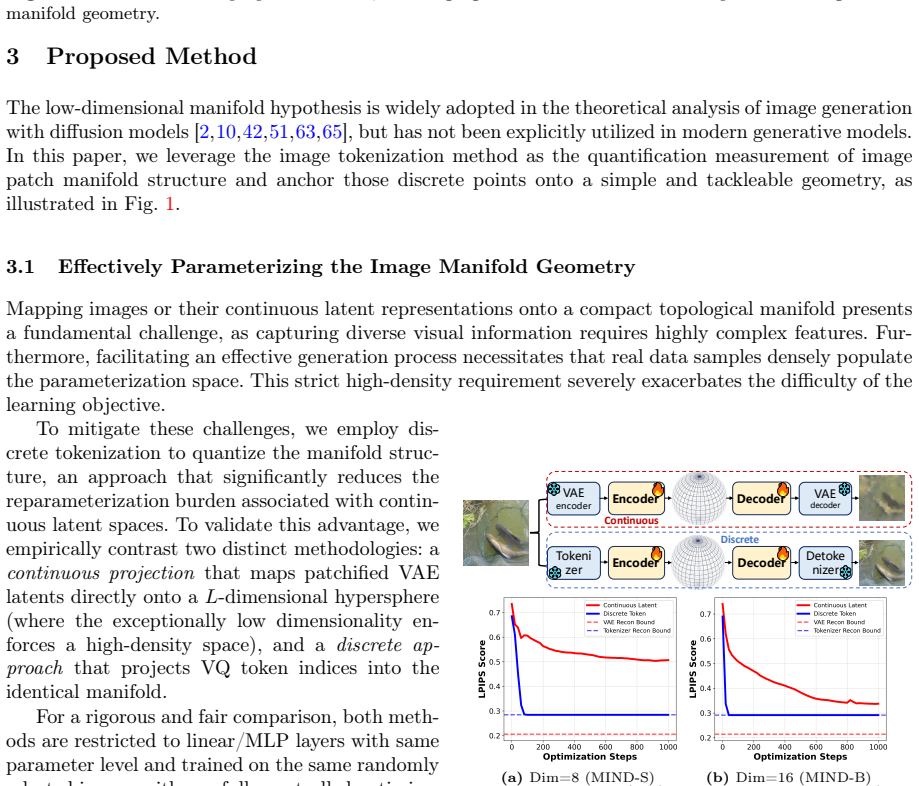
Image generative models aim to sample data points from the underlying data manifold, a task that requires learning and decoding a dense, low-dimensional, and compact parameterization space. To achieve this, we propose the Data Manifold-aware Image diffusioN moDel (MIND), a novel framework that explicitly models manifold geometry by integrating discrete patch tokenization into the score function of a continuous diffusion model. This approach successfully leverages both the structural quantification capabilities of discrete tokens and the parallel generation flexibility of continuous diffusion. Moreover, we enable end-to-end differentiable training via a novel soft top-$k$ aggregation mechanism and introduce dual-branch high-frequency feature embedding layers to alleviate the spectral bias of transformer backbones on low-dimensional inputs. Furthermore, for inference, we design a multi-stage transition sampling scheme that dynamically adjusts the sampling scheme based on timestep. Extensive experiments on ImageNet 256$\times$256 demonstrate the effectiveness of MIND. After 80-epoch training, our base model achieves an FID of 22.73 without guidance, nearly halving the 43.47 FID of the vanilla DiT-B/2 baseline. The proposed method reduces FID by 15.95 and 9.06 on average compared with the baselines DiT and SiT, respectively. For image generation on ImageNet-256$\times$256 with guidance, the proposed MIND-B with only 130M parameters achieves an FID of 2.06, superpassing the LlamaGen-3B with 3.1B parameters. The proposed MIND-XL with 715M parameters further reduces the FID to 1.95. Our MIND introduces a fresh perspective on diffusion-based image generation, paving the way for future research and innovation in this community. The code will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Data Manifold-aware Image diffusioN moDel (MIND), a hybrid framework that integrates discrete patch tokenization into the score function of a continuous diffusion model via a soft top-k aggregation mechanism, combined with dual-branch high-frequency feature embeddings and multi-stage transition sampling. It claims this explicitly models data manifold geometry and reports strong empirical results on ImageNet 256×256, including an FID of 22.73 for the base model after 80 epochs (vs. 43.47 for DiT-B/2), average FID reductions of 15.95 vs. DiT and 9.06 vs. SiT, and guided FID scores of 2.06 (MIND-B, 130M params) and 1.95 (MIND-XL, 715M params) that surpass much larger baselines like LlamaGen-3B.
Significance. If the performance gains are reproducible and attributable to the manifold-geometry modeling rather than unablated implementation details, the hybrid discrete-continuous approach could provide a more parameter-efficient path for diffusion-based generation. The empirical comparisons to DiT/SiT and larger autoregressive models are potentially impactful for the field, but the lack of mechanistic evidence or ablations limits the theoretical advance.
major comments (3)
- [Abstract] Abstract: The central claim that the method 'explicitly models manifold geometry' by integrating discrete patch tokenization into the continuous score function lacks any equation, derivation, or section defining how the soft top-k aggregation or token integration enforces geometric properties (e.g., curvature, geodesics, or structural constraints); without this, it is unclear whether the discrete component contributes beyond the dual-branch embeddings and sampling scheme.
- [Abstract] Abstract: The reported FID values (22.73 after 80 epochs for base model; 1.95 for MIND-XL) and comparisons (e.g., vs. DiT-B/2 at 43.47, LlamaGen-3B) provide no experimental details, error bars, baseline implementation specifications, training hyperparameters, or ablation studies, rendering the performance claims unverifiable and the attribution to manifold modeling unsupported.
- [Abstract] Abstract: The soft top-k aggregation is presented as enabling end-to-end differentiability while preserving 'structural quantification capabilities of discrete tokens,' but no analysis or equation demonstrates that it avoids collapse to a smoothed continuous signal (high-entropy selection) that would undermine the discrete manifold modeling.
minor comments (1)
- [Abstract] Abstract contains minor language issues including 'superpassing' (should be 'surpassing') and inconsistent capitalization in the model name 'diffusioN moDel'.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below, clarifying the manuscript's content and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the method 'explicitly models manifold geometry' by integrating discrete patch tokenization into the continuous score function lacks any equation, derivation, or section defining how the soft top-k aggregation or token integration enforces geometric properties (e.g., curvature, geodesics, or structural constraints); without this, it is unclear whether the discrete component contributes beyond the dual-branch embeddings and sampling scheme.
Authors: The abstract summarizes the high-level contribution. The method section of the manuscript defines the integration of discrete patch tokenization into the score function via soft top-k aggregation and explains its role in capturing manifold structure through structural quantification. To directly address the request for explicit definitions, we will add a dedicated subsection with equations and a short derivation showing how the token integration imposes local geometric constraints on the diffusion process. revision: yes
-
Referee: [Abstract] Abstract: The reported FID values (22.73 after 80 epochs for base model; 1.95 for MIND-XL) and comparisons (e.g., vs. DiT-B/2 at 43.47, LlamaGen-3B) provide no experimental details, error bars, baseline implementation specifications, training hyperparameters, or ablation studies, rendering the performance claims unverifiable and the attribution to manifold modeling unsupported.
Authors: The abstract condenses the key results. Full experimental details, including training hyperparameters, baseline re-implementation specifications, ablation studies, and dataset protocols, appear in Sections 4 and 5. We will expand the abstract's result paragraph with references to these sections and add error bars computed over multiple random seeds plus explicit baseline configuration tables in the revision. revision: yes
-
Referee: [Abstract] Abstract: The soft top-k aggregation is presented as enabling end-to-end differentiability while preserving 'structural quantification capabilities of discrete tokens,' but no analysis or equation demonstrates that it avoids collapse to a smoothed continuous signal (high-entropy selection) that would undermine the discrete manifold modeling.
Authors: The manuscript introduces the soft top-k mechanism for differentiability. We will include a new paragraph with the explicit formulation of the aggregation operator and an entropy analysis demonstrating that the temperature schedule keeps selection entropy sufficiently low to retain discrete-like behavior, thereby supporting the manifold-modeling claim. This analysis will be added to the method section. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces an architectural framework (MIND) combining discrete patch tokenization, soft top-k aggregation, dual-branch embeddings, and multi-stage sampling within a diffusion score function. No equations, uniqueness theorems, or first-principles derivations are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs. All reported outcomes consist of empirical FID comparisons against external baselines (DiT, SiT, LlamaGen) after fixed training epochs, with no load-bearing self-referential steps or ansatz smuggling. The work is self-contained as an empirical model proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: NeurIPS
Austin, J., Johnson, D.D., Ho, J., Tarlow, D., van den Berg, R.: Structured denoising diffusion models in discrete state-spaces. In: NeurIPS. pp. 17981–17993 (2021)
2021
-
[2]
arXiv preprint arXiv:2409.18804 (2024)
Azangulov, I., Deligiannidis, G., Rousseau, J.: Convergence of diffusion models under the manifold hypothesis in high-dimensions. arXiv preprint arXiv:2409.18804 (2024)
-
[3]
In: ICLR (2022)
Bao, F., Li, C., Zhu, J., Zhang, B.: Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. In: ICLR (2022)
2022
-
[4]
In: CVPR
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: CVPR. pp. 22563–22575 (2023)
2023
-
[5]
In: ICLR (2019)
Brock, A., Donahue, J., Simonyan, K.: Large scale GAN training for high fidelity natural image synthesis. In: ICLR (2019)
2019
-
[6]
In: CVPR (2022)
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked generative image transformer. In: CVPR (2022)
2022
-
[7]
In: CVPR
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked generative image transformer. In: CVPR. pp. 11305–11315 (2022)
2022
-
[8]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Chen, J., Ge, C., Xie, E., Wu, Y., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., Li, Z.: Pixart-σ: Weak-to- strong training of diffusion transformer for 4k text-to-image generation. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 74–91. Springer Nature Switzerland, Cham (2025)
2024
-
[9]
In: Kim, B., Yue, Y., Chaud- huri, S., Fragkiadaki, K., Khan, M., Sun, Y
Chen, J., YU, J., GE, C., Yao, L., Xie, E., Wang, Z., Kwok, J., Luo, P., Lu, H., Li, Z.: PixArt-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In: Kim, B., Yue, Y., Chaud- huri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on Learning Representa- tions. vol. 2024, pp. 57611–57640 (2024),http...
2024
-
[10]
In: ICML
Chen, M., Huang, K., Zhao, T., Wang, M.: Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data. In: ICML. pp. 4672–4712 (2023)
2023
-
[11]
arXiv preprint arXiv:2504.07963 (2025)
Chen, S., Ge, C., Zhang, S., Sun, P., Luo, P.: Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963 (2025)
-
[12]
Scaling Instruction-Finetuned Language Models
Chung, H.W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, E., Wang, X., Dehghani, M., Brahma, S., Webson, A., Gu, S.S., Dai, Z., Suzgun, M., Chen, X., Chowdhery, A., Narang, S., Mishra, G., Yu, A., Zhao, V., Huang, Y., Dai, A., Yu, H., Petrov, S., Chi, E.H., Dean, J., Devlin, J., Roberts, A., Zhou, D., Le, Q.V., Wei, J.: Scaling instruction-fin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.11416 2022
-
[13]
In: NeurIPS (2025)
Cui, H., Pehlevan, C., Lu, Y.M.: A solvable model of learning generative diffusion: theory and insights. In: NeurIPS (2025)
2025
-
[14]
In: NeurIPS
De Bortoli, V., Mathieu, E., Hutchinson, M., Thornton, J., Teh, Y.W., Doucet, A.: Riemannian score-based generative modelling. In: NeurIPS. pp. 2406–2422 (2022)
2022
-
[15]
Degeorge, L., Ghosh, A., Dufour, N., Picard, D., Kalogeiton, V.: How far can we go with imagenet for text- to-image generation? arXiv (2025)
2025
-
[16]
In: CVPR
Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L.:Imagenet:Alarge-scalehierarchicalimagedatabase. In: CVPR. pp. 248–255 (2009)
2009
-
[17]
In: NeurIPS
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. In: NeurIPS. pp. 8780–8794 (2021)
2021
-
[18]
In: Proceedings of the 41st International Conference on Machine Learning
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., Rombach, R.: Scaling rectified flow transformers for high-resolution image synthesis. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24 (2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12873–12883 (2021)
2021
-
[20]
In: The Thirty-ninth Annual Conference on NeurIPS (2025)
Geng, Z., Deng, M., Bai, X., Kolter, J.Z., He, K.: Mean flows for one-step generative modeling. In: The Thirty-ninth Annual Conference on NeurIPS (2025)
2025
-
[22]
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Geng, Z., Lu, Y., Wu, Z., Shechtman, E., Kolter, J.Z., He, K.: Improved mean flows: On the challenges of fastforward generative models. arXiv preprint arXiv:2512.02012 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: an object-focused framework for evaluating text-to-image alignment. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[24]
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Commun. ACM63(11), 139–144 (2020)
2020
-
[25]
In: NeurIPS
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS. pp. 6840–6851 (2020)
2020
-
[26]
Ho,J.,Salimans,T.:Classifier-freediffusionguidance.In:NeurIPS2021WorkshoponDeepGenerativeModels and Downstream Applications (2021) 20 Duoduo Xue, Zhiyu Zhu, Junhui Hou
2021
-
[27]
In: ICML
Hoogeboom, E., Heek, J., Salimans, T.: simple diffusion: End-to-end diffusion for high resolution images. In: ICML. pp. 13213–13232 (2023)
2023
-
[28]
In: ICLR (2026)
Huang, Y., Wang, S.H., Bertozzi, A.L., Wang, B.: RMFlow: Refined mean flow by a noise-injection step for multimodal generation. In: ICLR (2026)
2026
-
[29]
In: NeurIPS (2025)
Jo, J., Hwang, S.J.: Continuous diffusion model for language modeling. In: NeurIPS (2025)
2025
-
[30]
In: CVPR
Kang, M., Zhu, J.Y., Zhang, R., Park, J., Shechtman, E., Paris, S., Park, T.: Scaling up gans for text-to-image synthesis. In: CVPR. pp. 10124–10134 (2023)
2023
-
[31]
In: NeurIPS
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. In: NeurIPS. pp. 26565–26577 (2022)
2022
-
[32]
In: NeurIPS
Karras, T., Aittala, M., Kynkäänniemi, T., Lehtinen, J., Aila, T., Laine, S.: Guiding a diffusion model with a bad version of itself. In: NeurIPS. pp. 52996–53021 (2024)
2024
-
[33]
In: CVPR
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: CVPR. pp. 4396–4405 (2019)
2019
-
[34]
IEEE Transactions on Pattern Analysis and Machine Intelligence43(11), 3964–3979 (2021)
Kobyzev, I., Prince, S.J., Brubaker, M.A.: Normalizing flows: An introduction and review of current methods. IEEE Transactions on Pattern Analysis and Machine Intelligence43(11), 3964–3979 (2021)
2021
-
[35]
Kumar, A., Patel, V.M.: Learning on the manifold: Unlocking standard diffusion transformers with represen- tation encoders. arXiv preprint arXiv:2602.10099 (2026)
-
[36]
In: NeurIPS (2024)
Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., Lehtinen, J.: Applying guidance in a limited interval improves sample and distribution quality in diffusion models. In: NeurIPS (2024)
2024
-
[37]
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arx...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
In: CVPR
Lee, D., Kim, C., Kim, S., Cho, M., Han, W.S.: Autoregressive image generation using residual quantization. In: CVPR. pp. 11523–11532 (2022)
2022
-
[39]
arXiv preprint arXiv:2504.10483 (2025)
Leng, X., Singh, J., Hou, Y., Xing, Z., Xie, S., Zheng, L.: Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers. arXiv preprint arXiv:2504.10483 (2025)
-
[40]
In: NeurIPS
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation without vector quantization. In: NeurIPS. vol. 37, pp. 56424–56445 (2024)
2024
-
[41]
arXiv preprint arXiv:2505.21473 (2025)
Liu, Y., Qu, L., Zhang, H., Wang, X., Jiang, Y., Gao, Y., Ye, H., Li, X., Wang, S., Du, D.K., et al.: Detailflow: 1d coarse-to-fine autoregressive image generation via next-detail prediction. arXiv preprint arXiv:2505.21473 (2025)
-
[42]
Transactions on Machine Learning Research (2024)
Loaiza-Ganem, G., Ross, B.L., Hosseinzadeh, R., Caterini, A.L., Cresswell, J.C.: Deep generative models through the lens of the manifold hypothesis: A survey and new connections. Transactions on Machine Learning Research (2024)
2024
-
[43]
In: ICML
Lou, A., Meng, C., Ermon, S.: Discrete diffusion modeling by estimating the ratios of the data distribution. In: ICML. pp. 32819–32848 (2024)
2024
-
[44]
In: ECCV
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In: ECCV. pp. 23–40 (2024)
2024
-
[45]
In: NeurIPS (2025)
Ma, X., Zhao, F., Ling, P., Qiu, H., Wei, Z., Yu, H., Huang, J., Zeng, Z., Ma, L.: Towards better & faster autoregressive image generation: From the perspective of entropy. In: NeurIPS (2025)
2025
-
[46]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Ma, Z., Wei, L., Wang, S., Zhang, S., Tian, Q.: Deco: Frequency-decoupled pixel diffusion for end-to-end image generation. arXiv preprint arXiv:2511.19365 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: ICML
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: ICML. pp. 8162–8171 (2021)
2021
-
[48]
In: NeurIPS
van den Oord, A., Vinyals, O., Kavukcuoglu, K.: Neural discrete representation learning. In: NeurIPS. pp. 6309–6318 (2017)
2017
-
[49]
In: ICCV
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV. pp. 4195–4205 (2023)
2023
-
[50]
In: Kim, B., Yue, Y., Chaud- huri, S., Fragkiadaki, K., Khan, M., Sun, Y
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: Kim, B., Yue, Y., Chaud- huri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on Learning Representa- tions. vol. 2024, pp. 1862–1874 (2024),https://pr...
2024
-
[51]
In: ICLR (2021)
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., Goldstein, T.: The intrinsic dimension of images and its impact on learning. In: ICLR (2021)
2021
-
[52]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684–10695 (June 2022)
2022
-
[54]
In: NeurIPS
Sahoo, S., Arriola, M., Schiff, Y., Gokaslan, A., Marroquin, E., Chiu, J., Rush, A., Kuleshov, V.: Simple and effective masked diffusion language models. In: NeurIPS. pp. 130136–130184 (2024)
2024
-
[55]
In: ICLR (2022) Diffusion Image Generation with Explicit Modeling of Data Manifold Geometry 21
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: ICLR (2022) Diffusion Image Generation with Explicit Modeling of Data Manifold Geometry 21
2022
-
[56]
In: ACM SIG- GRAPH 2022 Conference Proceedings (2022)
Sauer, A., Schwarz, K., Geiger, A.: Stylegan-xl: Scaling stylegan to large diverse datasets. In: ACM SIG- GRAPH 2022 Conference Proceedings (2022)
2022
-
[57]
In: ICCV
Shi, F., Luo, Z., Ge, Y., Yang, Y., Shan, Y., Wang, L.: Scalable image tokenization with index backpropagation quantization. In: ICCV. pp. 16037–16046 (2025)
2025
-
[58]
In: NeurIPS (2024)
Shi, J., Han, K., Wang, Z., Doucet, A., Titsias, M.K.: Simplified and generalized masked diffusion for discrete data. In: NeurIPS (2024)
2024
-
[59]
In: ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
2021
-
[60]
In: ICML
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: ICML. pp. 32211–32252 (2023)
2023
-
[61]
In: NeurIPS
Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. In: NeurIPS. p. 11895–11907 (2019)
2019
-
[62]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregressive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
In: Proceedings of The 27th International Conference on Artificial Intelligence and Statistics
Tang, R., Yang, Y.: Adaptivity of diffusion models to manifold structures. In: Proceedings of The 27th International Conference on Artificial Intelligence and Statistics. pp. 1648–1656 (2024)
2024
-
[64]
In: NeurIPS
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: scalable image generation via next-scale prediction. In: NeurIPS. pp. 84839–84865 (2024)
2024
-
[65]
In: ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy (2025)
Wang, P., Zhang, H., Zhang, Z., Chen, S., Ma, Y., Qu, Q.: DIFFUSION MODELS LEARN LOW- DIMENSIONAL DISTRIBUTIONS VIA SUBSPACE CLUSTERING. In: ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy (2025)
2025
-
[66]
Ddt: Decoupled diffusion transformer
Wang, S., Tian, Z., Huang, W., Wang, L.: Ddt: Decoupled diffusion transformer. arXiv preprint arXiv:2504.05741 (2025)
-
[67]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Xie,E.,Chen,J.,Chen,J.,Cai,H.,Tang,H.,Lin,Y.,Zhang,Z.,Li,M.,Zhu,L.,Lu,Y.,Han,S.:Sana:Efficient high-resolution text-to-image synthesis with linear diffusion transformers. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) International Conference on Learning Representations. vol. 2025, pp. 20383–20407 (2025), https://proceedings.iclr.cc/paper_files/p...
2025
-
[68]
Transactions on Machine Learning Research (2025)
Xiong, J., Liu, G., Huang, L., Wu, C., Wu, T., Mu, Y., Yao, Y., Shen, H., Wan, Z., Huang, J., et al.: Autoregressive models in vision: A survey. Transactions on Machine Learning Research (2025)
2025
-
[69]
Representation Fr\'echet Loss for Visual Generation
Yang, J., Geng, Z., Ju, X., Tian, Y., Wang, Y.: Representation fréchet loss for visual generation. arXiv:2604.28190 (2026),https://arxiv.org/abs/2604.28190
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
In: ICML (2025)
You, Z., Ou, J., Zhang, X., Hu, J., ZHOU, J., Li, C.: Effective and efficient masked image generation models. In: ICML (2025)
2025
-
[71]
In: ICLR (2022)
Yu, J., Li, X., Koh, J.Y., Zhang, H., Pang, R., Qin, J., Ku, A., Xu, Y., Baldridge, J., Wu, Y.: Vector-quantized image modeling with improved VQGAN. In: ICLR (2022)
2022
-
[72]
In: ICLR (2024)
Yu, L., Lezama, J., Gundavarapu, N.B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A.G., Gong, B., Yang, M.H., Essa, I., Ross, D.A., Jiang, L.: Language model beats diffusion - tokenizer is key to visual generation. In: ICLR (2024)
2024
-
[73]
In: ICLR (2025)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: ICLR (2025)
2025
-
[74]
In: CVPR
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018)
2018
-
[75]
In: NeurIPS (2025)
Zheng, A., Wen, X., Zhang, X., Ma, C., Wang, T., YU, G., Zhang, X., QI, X.: Vision foundation models as effective visual tokenizers for autoregressive generation. In: NeurIPS (2025)
2025
-
[76]
In: ICLR (2026)
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. In: ICLR (2026)
2026
-
[77]
In: NeurIPS
Zhu, L., Wei, F., Lu, Y., Chen, D.: Scaling the codebook size of vqgan to 100,000 with a utilization rate of 99%. In: NeurIPS. pp. 12612–12635 (2024)
2024
-
[78]
Feature" level inherently retains all continuous architectural benefits (including our dual-branch high-frequency embeddings), the strict superiority of “Logits
Zhuo, L., Du, R., Xiao, H., Li, Y., Liu, D., Huang, R., Liu, W., Zhu, X., Wang, F.Y., Ma, Z., Luo, X., Wang, Z., Zhang, K., Zhao, L., Liu, S., Yue, X., Ouyang, W., Qiao, Y., Li, H., Gao, P.: Lumina-next : Making lumina-t2x stronger and faster with next-dit. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://ope...
2024
-
[79]
Diffusion & Noise Settings Noise Scale Factorc1 0.6 0.8 Signal Scale Factorc2 1.0 1.0 Training Timestep Range (t)t∈[0.2,0.95]t∈[0.2,0.95]
-
[80]
Embedding & Vocabulary Vocabulary SizeV16,384 8192 Embedding DimensionL16 8 Embedding Subspace 4 2
-
[81]
Network Architecture Total Parameters(M) 130.48 35.21 Number of Blocks 14 14 Hidden Size 768 384 Attention Heads 12 6 Condition Embedding Dimension 128 128
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.