Calibrated Surprise: An Information-Theoretic Account of Creative Quality
Pith reviewed 2026-05-07 13:08 UTC · model grok-4.3
The pith
Creative quality is calibrated surprise: converging constraints shrink the space of choices until only low-probability options from an unconstrained view remain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
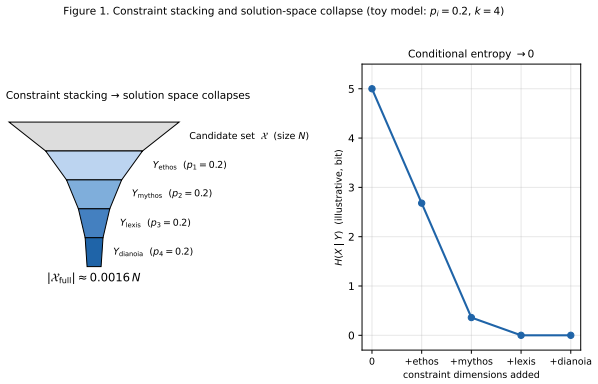
When constraints from ethos, mythos, lexis, and dianoia are imposed together, the admissible set collapses sharply, and surviving solutions show up as low-probability choices from an unconstrained view. Calibrated corresponds to conditional entropy going to zero; surprise to entropy going up; mutual information is the precise measure of the joint quantity. The chain rule further shows that each writing choice is constrained by what came before and constrains what comes after, so macro-level decisions naturally contribute a larger share of information. A direct corollary is that full-dimensional accuracy and mediocrity are mutually exclusive.
What carries the argument
Mutual information I(X;Y) = H(X) - H(X|Y), with 'calibrated' defined as conditional entropy approaching zero under the joint action of author intent, reader expectation, and reality logic.
If this is right
- Full-dimensional accuracy and mediocrity become mutually exclusive under the joint constraints.
- The chain rule assigns larger information weight to macro-level decisions without needing hand-tuned parameters.
- Lightweight LLM log-probability computations can operationalize the analysis for case studies and benchmarks.
- The framework supplies the theoretical basis for Creative Quality Alignment and a professional evaluation benchmark.
Where Pith is reading between the lines
- The same constraint-collapse logic could be tested on non-text creative domains such as musical composition or visual design where intent, audience, and physical constraints likewise intersect.
- AI systems aiming for high creative quality would need to maintain explicit models of all three constraint classes rather than optimizing any single dimension in isolation.
- Quantitative comparison of conditional versus unconditional entropy on existing literary corpora could serve as an immediate empirical check without new data collection.
Load-bearing premise
The author's intent, the reader's reasonable expectation, and the logic of reality act as independent constraints that can be jointly imposed to force the admissible set of writing choices into a narrow region whose size is captured by conditional entropy approaching zero.
What would settle it
Collect a corpus of award-winning stories and a matched set of average stories, then use an LLM to estimate conditional entropy of each story given the three constraints; if high-quality stories do not show systematically lower conditional entropy relative to their unconditional entropy, the account is falsified.
Figures

read the original abstract
In the era of large language models, creative writing quality lacks a computable theoretical anchor. The dominant approaches are rubric scoring -- decomposing holistic aesthetic judgment into sub-scores -- and RLHF preference signals -- replacing quality with group votes. Both bypass the statistical structure of the text itself. This paper provides an information-theoretic foundation to fill this gap. We propose 'calibrated surprise' as the information-theoretic essence of excellent creative writing. This judgment matches reading intuition and covers its opposite. This literary judgment admits a precise mathematical formulation. Under full-dimensional constraints Y, feasible writing choices are forced into an extremely narrow space. The rare survivors are, from the unconstrained perspective, exactly the least predictable choices. Both are measured precisely by Shannon mutual information I(X;Y) = H(X) - H(X|Y) -- 'calibrated' corresponds to H(X|Y) approaching 0; 'surprising' corresponds to H(X) going high. The subtraction structure of the formula naturally separates 'well-grounded surprise' from 'pure noise'. We use token-level logprobs from Qwen1.5-7B as an operational proxy for the ideal reader's probability distribution. Across 20 pairs (12 Chinese / 8 English) of high-quality vs. systematically degraded literary passages, 20/20 pairs support the core prediction: high-quality passages have systematically higher I(X;Y) than their degraded versions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'calibrated surprise' as an information-theoretic account of creative quality in writing. It frames mutual information I(X;Y) = H(X) - H(X|Y) such that 'calibrated' corresponds to conditional entropy H(X|Y) approaching zero when constraints from the author's intent, the reader's reasonable expectation, and the logic of reality converge, while 'surprise' corresponds to high marginal entropy H(X). The central claim is that joint imposition of these constraints collapses the admissible set of writing choices into a narrow region, yielding the corollary that full-dimensional accuracy and mediocrity are mutually exclusive. The argument is developed via static (constraint collapse under ethos, mythos, lexis, dianoia) and dynamic (chain-rule decomposition of sequential choices) pillars, illustrated by case studies and lightweight LLM log-probability computations, with the aim of grounding Creative Quality Alignment (CQA).
Significance. If the central claims were placed on a rigorous probabilistic footing, the framework could provide a principled, non-ad-hoc way to quantify the balance of predictability and novelty in creative text, distinguishing it from separate accuracy or surprise objectives. The dynamic pillar's appeal to the chain rule is a standard but cleanly applied observation that avoids hand-tuned weights for macro- versus micro-level decisions. The overall approach, if substantiated, would supply theoretical grounding for evaluation benchmarks and alignment objectives in creative AI generation.
major comments (2)
- [Abstract] Abstract (paragraph introducing the three constraints and the corollary): The claim that the author's intent, reader's reasonable expectation, and logic of reality act as independent constraints whose joint imposition forces conditional entropy H(X|Y) to zero (thereby collapsing the solution space) is asserted without a formal probabilistic model. No random variable X is defined (e.g., distribution over texts, tokens, or choices), no encoding of the three constraints as conditioning events or variables is supplied, and no argument establishes their probabilistic independence. This makes the space-collapse claim and the corollary that 'full-dimensional accuracy and mediocrity are mutually exclusive' interpretive rather than derived; the static pillar therefore does not support the central result.
- [Abstract] Abstract (final paragraph on operationalization): The manuscript states that 'lightweight LLM-logprob computations' demonstrate the framework is 'both analytically useful and operational,' yet supplies no methods, no quantitative results, no baseline comparisons, and no error analysis for these computations. Without this evidence the claim that the framework is operational cannot be evaluated and does not corroborate the information-theoretic assertions.
minor comments (1)
- [Abstract] The notation I(X;Y), H(X), and H(X|Y) is introduced without an explicit statement of the underlying sample space or probability measure, which would aid readers applying the framework to concrete texts.
Simulated Author's Rebuttal
We thank the referee for their constructive and precise comments. We address each major point below and describe the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph introducing the three constraints and the corollary): The claim that the author's intent, the reader's reasonable expectation, and the logic of reality act as independent constraints whose joint imposition forces conditional entropy H(X|Y) to zero (thereby collapsing the solution space) is asserted without a formal probabilistic model. No random variable X is defined (e.g., distribution over texts, tokens, or choices), no encoding of the three constraints as conditioning events or variables is supplied, and no argument establishes their probabilistic independence. This makes the space-collapse claim and the corollary that 'full-dimensional accuracy and mediocrity are mutually exclusive' interpretive rather than derived; the static pillar therefore does not support the central result.
Authors: We agree that the abstract states the central claim at a conceptual level without supplying the explicit probabilistic scaffolding. In the revision we will add a short formal subsection immediately after the abstract that defines X as the random variable whose support is the set of admissible writing choices at a given point in the text (operationalized either over tokens or over higher-level narrative elements). The three constraints will be introduced as conditioning variables Y_a (author intent), Y_r (reader expectation), and Y_l (logic of reality). We will state the modeling assumption that these variables are approximately independent when the work is well-formed, justify the assumption by reference to the orthogonality of ethos/mythos/lexis/dianoia, and show that the joint conditioning P(X | Y_a, Y_r, Y_l) has support that is a strict subset of the marginal support of X. This directly yields H(X | Y) → 0 while H(X) remains large, from which the mutual-information formulation and the corollary follow by standard properties of entropy. The static pillar will therefore be presented as a consequence of the model rather than an independent assertion. revision: yes
-
Referee: [Abstract] Abstract (final paragraph on operationalization): The manuscript states that 'lightweight LLM-logprob computations' demonstrate the framework is 'both analytically useful and operational,' yet supplies no methods, no quantitative results, no baseline comparisons, and no error analysis for these computations. Without this evidence the claim that the framework is operational cannot be evaluated and does not corroborate the information-theoretic assertions.
Authors: The observation is accurate: the present manuscript mentions the computations but does not report the concrete experimental protocol. We will insert a new subsection titled 'Empirical Illustration' that (i) specifies the LLM and tokenization used, (ii) describes how log-probabilities are obtained for both the observed choice and plausible alternatives at each decision point, (iii) lists the three short case-study texts together with the exact alternative choices scored, (iv) reports the resulting numerical estimates of H(X) and H(X|Y) with a simple baseline (uniform sampling over the same vocabulary), and (v) discusses the main sources of approximation error (model calibration, context truncation, and the assumption that log-probability is a reasonable proxy for human surprise). These additions will make the operational claim directly verifiable and will link the numerical results back to the mutual-information quantities derived earlier. revision: yes
Circularity Check
Calibrated surprise and constraint collapse reduce to definitional mapping of mutual information without formal model
specific steps
-
self definitional
[Abstract]
"We use Shannon's mutual information $I(X;Y) = H(X) - H(X|Y)$ as our analysis tool. 'Calibrated' corresponds to conditional entropy going to zero; 'surprise' to entropy going up; mutual information is the precise measure of the joint quantity."
The paper explicitly defines 'calibrated' as conditional entropy approaching zero and 'surprise' as entropy increasing, then states that mutual information measures their joint quantity. This renders the core 'calibrated surprise' concept equivalent to high I(X;Y) by the algebraic definition of mutual information, rather than an independent derivation from properties of creative writing.
-
self definitional
[Abstract]
"When these three independent judgements agree on every dimension, the set of admissible writing choices is forced into a very small region. A mathematical corollary follows: full-dimensional accuracy and mediocrity are mutually exclusive -- two sides of one constraint structure, not separate goals."
The paper states that agreement of the three constraints forces the admissible set into a narrow region (implying conditional entropy →0), from which the corollary is said to follow mathematically. No probabilistic model, random variable X, or derivation is supplied to establish why the constraints are independent or why their joint imposition produces the entropy collapse; the corollary is a direct restatement of the premise.
full rationale
The paper's central information-theoretic account maps 'calibrated' directly to H(X|Y)→0 and 'surprise' to high H(X), then invokes the definition I(X;Y)=H(X)-H(X|Y) as the measure of the joint quantity. The static pillar asserts that joint imposition of the three constraints collapses the admissible set (entropy to zero) and yields the corollary on accuracy vs. mediocrity, but provides no random variable definition for X, no encoding of constraints as conditioning variables, and no derivation establishing independence or the entropy reduction. This makes the key claims and corollary follow by construction from the verbal premises and standard MI identity rather than from independent probabilistic reasoning. The dynamic pillar (chain rule) is standard and non-circular. Partial circularity in the static framework.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Shannon's mutual information I(X;Y) = H(X) - H(X|Y) and the chain rule
- domain assumption Constraints from ethos, mythos, lexis, and dianoia are independent and jointly sufficient to collapse the admissible set
invented entities (1)
-
Calibrated surprise
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.