Dmsh: A Multi-Agent Reinforcement Learning Framework for All-Quad Mesh Generation
Pith reviewed 2026-06-27 12:35 UTC · model grok-4.3
The pith
A three-agent reinforcement learning system generates conforming all-quadrilateral meshes for arbitrary geometries without manual fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
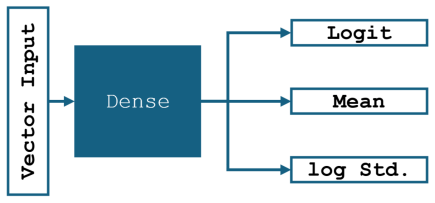
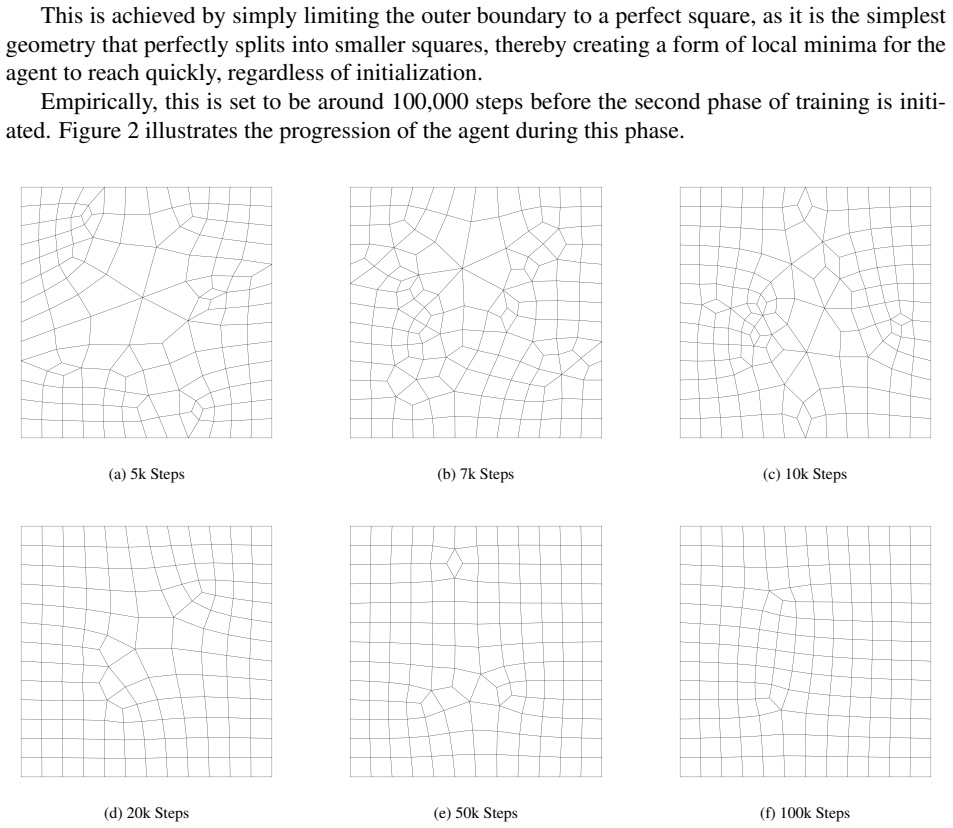
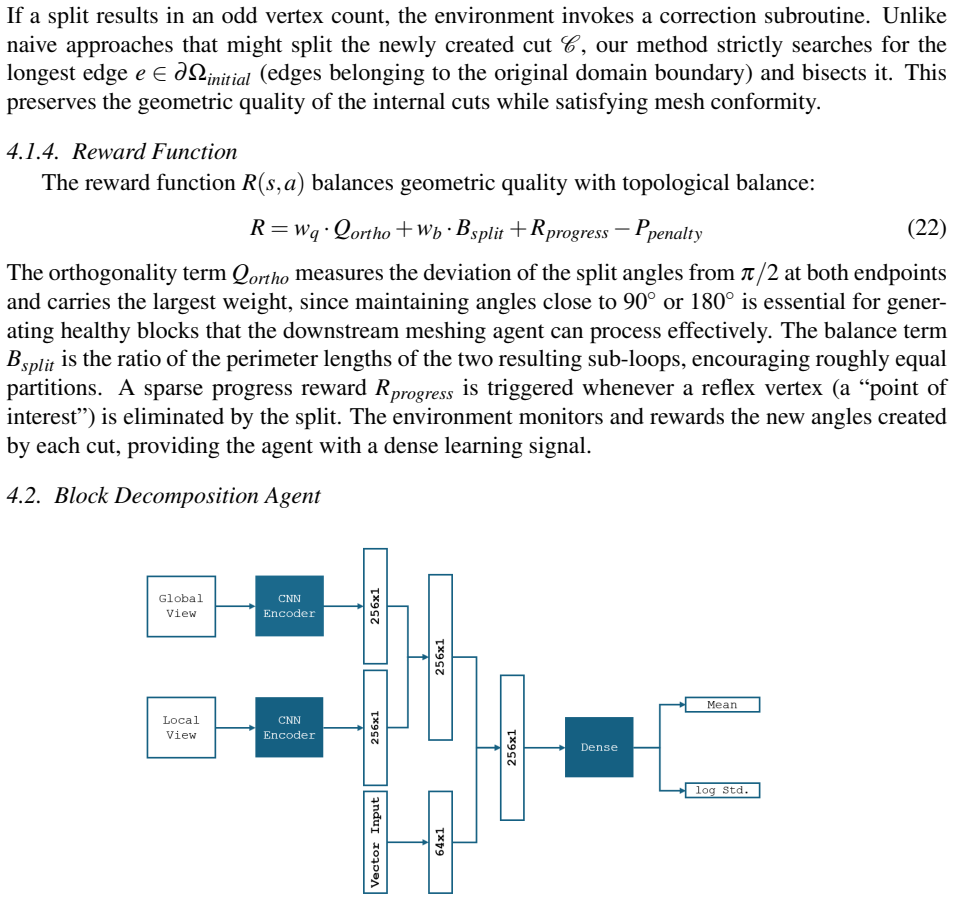
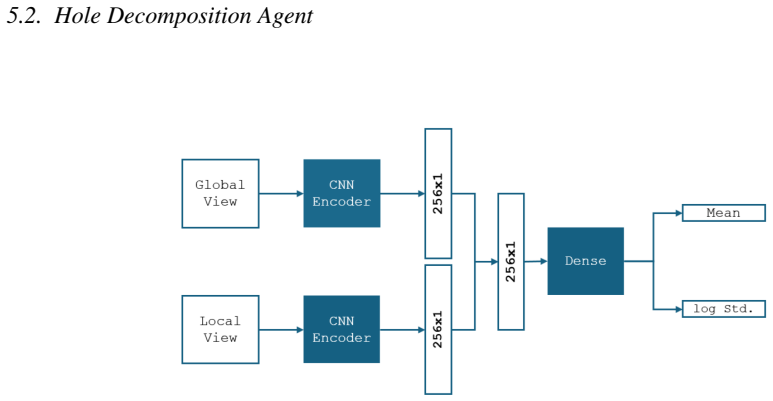
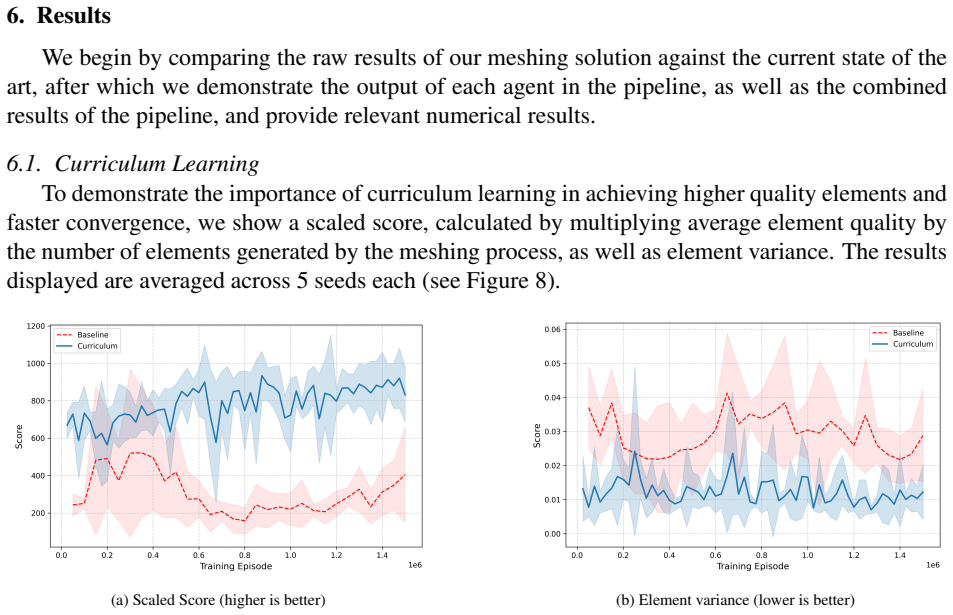
Dmsh is a fully automated reinforcement learning pipeline that unifies geometric decomposition and quadrilateral mesh generation within a single learning-based framework. Dmsh decomposes the problem through three coordinated agents handling topology simplification, geometric regularization, and mesh generation. The meshing process is formulated as a Markov Decision Process and solved using a parametric Soft Actor-Critic architecture with decoupled critics, enabling efficient exploration of a hybrid discrete-continuous action space. A curriculum learning strategy ensures scalability from simple domains to highly complex geometries. By design, the recursive decomposition enables parallel meshi
What carries the argument
Three coordinated agents that perform recursive geometric decomposition inside a multi-agent reinforcement learning setup solved by a Soft Actor-Critic method.
If this is right
- Meshes can be generated in parallel across subregions created by the decomposition.
- No separate correction step is needed to enforce conformity between neighboring mesh patches.
- The same trained system scales to increasingly complex input shapes through staged curriculum training.
- The output meshes achieve higher element quality scores than those from earlier automated methods on the same benchmark set.
Where Pith is reading between the lines
- The same agent coordination pattern could be tested on three-dimensional volume meshing tasks by extending the action space to handle hexahedral elements.
- Because the decomposition is recursive, the framework might support local remeshing when only part of a geometry changes during a simulation.
- The absence of post-processing steps could reduce the total time from geometry import to solver-ready mesh in automated engineering pipelines.
Load-bearing premise
The recursive decomposition performed by the three agents will always produce globally conforming all-quadrilateral meshes for highly complex geometries without requiring any post-hoc correction steps.
What would settle it
Running Dmsh on a geometry with many narrow channels or sharp features and finding at least one pair of adjacent subregions whose generated meshes fail to match element edges or node positions along their shared boundary.
Figures

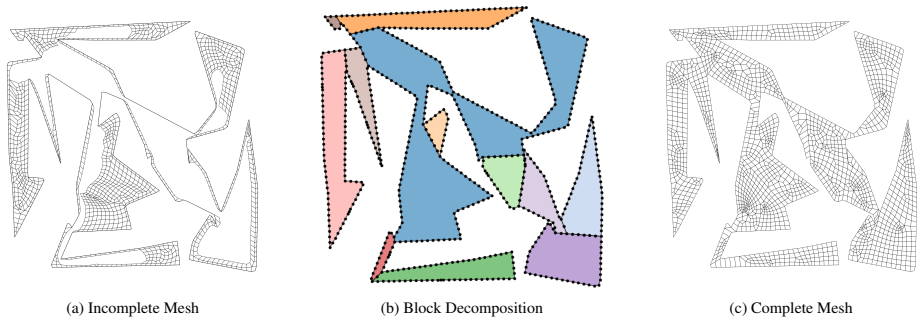
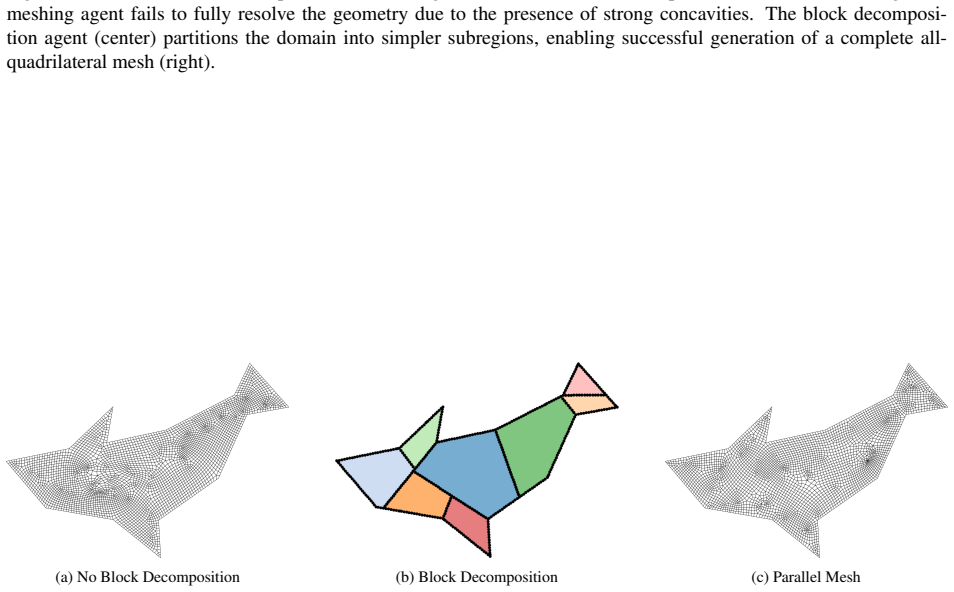
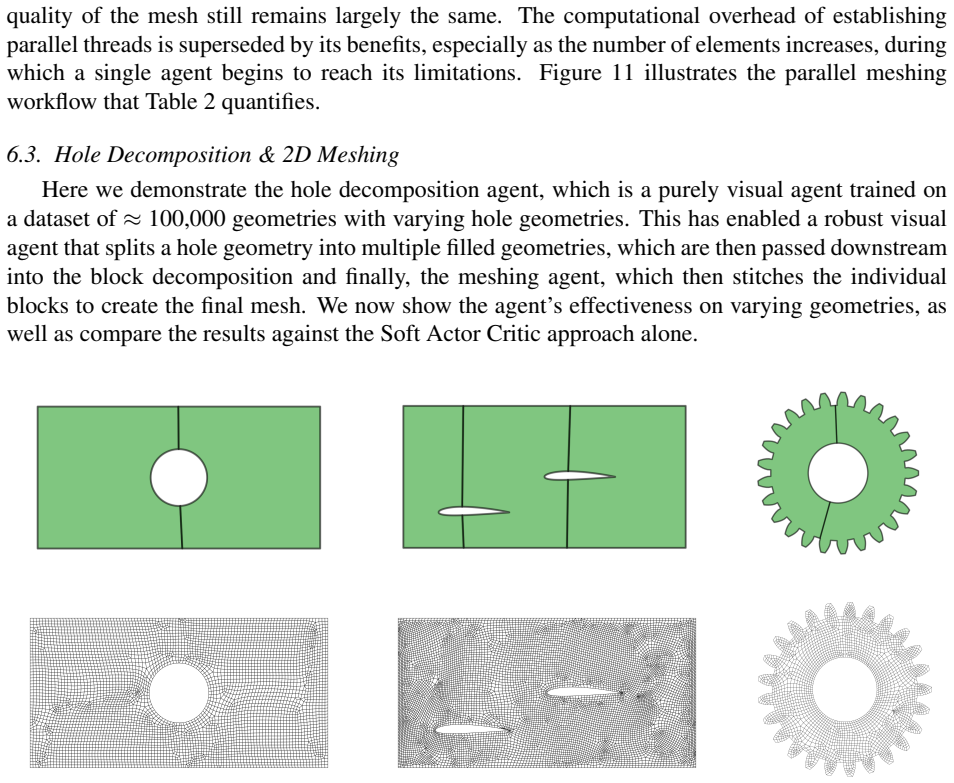


read the original abstract
Generating high-quality meshes for arbitrary geometries remains a fundamental bottleneck in computational engineering, often demanding heuristic tuning and semi-manual workflows. In this paper, we introduce Dmsh, a first fully automated reinforcement learning pipeline that unifies geometric decomposition and quadrilateral mesh generation within a single learning-based framework. Dmsh decomposes the problem through three coordinated agents handling topology simplification, geometric regularization, and mesh generation. The meshing process is formulated as a Markov Decision Process and solved using a parametric Soft Actor-Critic architecture with decoupled critics, enabling efficient exploration of a hybrid discrete-continuous action space. A curriculum learning strategy ensures scalability from simple domains to highly complex geometries, suppressing seed variance. By design, the recursive decomposition enables parallel meshing of subregions, yielding globally conforming all-quadrilateral meshes without post hoc correction. Across a wide range of benchmarks, Dmsh consistently outperforms existing methods in automation, robustness, and mesh quality, establishing a new paradigm for learning-based mesh generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dmsh, a multi-agent RL framework for all-quad mesh generation. It formulates the task as an MDP with three coordinated agents (topology simplification, geometric regularization, mesh generation) solved via parametric Soft Actor-Critic with decoupled critics and a curriculum learning strategy. Recursive decomposition is claimed to enable parallel meshing that produces globally conforming all-quadrilateral meshes without post-hoc correction. The method is asserted to outperform existing approaches across benchmarks in automation, robustness, and mesh quality.
Significance. If the quantitative results and the global-conformity guarantee hold, the work would be significant as the first fully automated RL pipeline unifying decomposition and quadrilateral meshing, potentially reducing reliance on heuristic tuning in computational engineering. The multi-agent formulation with curriculum learning to suppress seed variance represents a genuine technical contribution.
major comments (2)
- [Abstract] Abstract: the central claim that 'Dmsh consistently outperforms existing methods' supplies no quantitative results, error bars, specific metrics, or comparison tables, so the claim cannot be evaluated.
- [Abstract] Abstract: the load-bearing assertion that recursive decomposition 'by design' yields 'globally conforming all-quadrilateral meshes without post hoc correction' is stated without any mathematical argument, coordination invariant, or empirical verification that local agent actions preserve boundary conformity across recursion depths for arbitrary geometries.
minor comments (1)
- [Abstract] Abstract: the phrase 'parametric Soft Actor-Critic architecture with decoupled critics' is introduced without a reference or one-sentence definition of the decoupling mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the abstract can be strengthened with more concrete support. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Dmsh consistently outperforms existing methods' supplies no quantitative results, error bars, specific metrics, or comparison tables, so the claim cannot be evaluated.
Authors: We agree that the abstract should not make this claim without supporting numbers. The experiments section contains quantitative comparisons (mesh quality metrics, success rates, runtime) with baselines and error bars across multiple seeds. In the revision we will replace the general claim with a concise summary of the key metrics and direct comparisons. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assertion that recursive decomposition 'by design' yields 'globally conforming all-quadrilateral meshes without post hoc correction' is stated without any mathematical argument, coordination invariant, or empirical verification that local agent actions preserve boundary conformity across recursion depths for arbitrary geometries.
Authors: The referee is correct that the abstract states the conformity property without an explicit supporting argument. The current manuscript describes the three-agent coordination and recursive decomposition but does not isolate a formal invariant or present targeted verification experiments for boundary preservation at arbitrary recursion depths. We will add a short theoretical subsection deriving the boundary-conformity invariant from the agent coordination protocol and include additional empirical checks on a broader set of geometries in the revised version. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and text contain no equations, fitted parameters presented as predictions, self-citations, or ansatzes that reduce any claimed result to its inputs by construction. The MDP formulation and 'by design' statement are asserted without a visible derivation chain or reduction to fitted quantities. The paper is treated as self-contained against external benchmarks per the rules, yielding an honest non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, in: International Confer- ence on Learning Representations, 2021
2021
-
[2]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via deeponet based on the universal approximation theorem of operators, Nature Machine Intelligence 3 (3) (2021) 218–229. doi:10.1038/s42256-021-00302-5
-
[3]
Goswami, A
S. Goswami, A. Bora, Y . Yu, G. E. Karniadakis, Physics-informed deep neural operator net- works, in: Machine learning in modeling and simulation: methods and applications, Springer, 2023, pp. 219–254
2023
-
[4]
T. Kurth, S. Subramanian, P. Harrington, J. Pathak, M. Mardani, D. Hall, A. Miele, K. Kashinath, A. Anandkumar, FourCastNet: Accelerating global high-resolution weather forecasting using adaptive Fourier neural operators, in: Proceedings of the Platform for Ad- vanced Scientific Computing Conference, 2023, pp. 1–11. doi:10.1145/3592979.3593412
-
[5]
McGreivy, A
N. McGreivy, A. Hakim, Weak baselines and reporting biases lead to overoptimism in ma- chine learning for fluid-related partial differential equations, Nature machine intelligence 6 (10) (2024) 1256–1269
2024
-
[6]
R. Roy, D. Nayak, S. Goswami, The Best of Both Worlds: Hybridizing Neural Operators and Solvers for Stable Long-Horizon Inference, arXiv preprint arXiv:2512.19643 (2025)
arXiv 2025
-
[7]
W. Wang, M. Hakimzadeh, H. Ruan, S. Goswami, Time-marching neural operator–FE cou- pling: AI-accelerated physics modeling, Computer Methods in Applied Mechanics and Engi- neering 446 (2025) 118319
2025
-
[8]
J. P. Slotnick, A. Khodadoust, J. Alonso, D. Darmofal, W. Gropp, E. Lurie, D. J. Mavriplis, CFD vision 2030 study: A path to revolutionary computational aerosciences, Tech. Rep. NASA/CR-2014-218178, NASA (2014)
2030
-
[9]
S. J. Owen, A survey of unstructured mesh generation technology, in: Proceedings of the 7th International Meshing Roundtable, 1998, pp. 239–267. 29
1998
-
[10]
D. Bommes, B. Lévy, N. Pietroni, E. Puppo, C. Silva, M. Tarini, D. Zorin, Quad-mesh generation and processing: A survey, Computer Graphics Forum 32 (6) (2013) 51–76. doi:10.1111/cgf.12014
-
[11]
T. D. Blacker, M. B. Stephenson, Paving: A new approach to automated quadrilateral mesh generation, International Journal for Numerical Methods in Engineering 32 (4) (1991) 811–
1991
-
[12]
doi:10.1002/nme.1620320410
-
[13]
Z. Zhang, Y . Wang, P. K. Jimack, H. Wang, MeshingNet: A new mesh generation method based on deep learning, in: Computational Science – ICCS 2020, V ol. 12139 of Lecture Notes in Computer Science, Springer, 2020, pp. 186–198. doi:10.1007/978-3-030-50420-5_14
-
[14]
Z. Li, Z. Xu, Y . Li, X. Gu, N. Lei, What’s the situation with intelligent mesh generation: A survey and perspectives, IEEE Transactions on Visualization and Computer Graphics 30 (8) (2024) 4997–5017. doi:10.1109/TVCG.2023.3281781
-
[15]
S. Owen, N. Brown, N. Chrisochoides, R. Garimella, X. Gu, F. Ledoux, N. Lei, R. Quadros, N. Ray, N. Winovich, Y . J. Zhang, A survey of AI methods for geometry preparation and mesh generation in engineering simulation, arXiv preprint arXiv:2512.23719Accepted at the International Meshing Roundtable 2026 (2025). doi:10.48550/arXiv.2512.23719
-
[16]
J. Pan, J. Huang, G. Cheng, Y . Zeng, Reinforcement learning for automatic quadrilat- eral mesh generation: A soft actor–critic approach, Neural Networks 157 (2023) 288–304. doi:10.1016/j.neunet.2022.10.022
-
[17]
H. Tong, K. Qian, E. Halilaj, Y . J. Zhang, SRL-assisted AFM: Generating pla- nar unstructured quadrilateral meshes with supervised and reinforcement learning- assisted advancing front method, Journal of Computational Science 72 (2023) 102109. doi:10.1016/j.jocs.2023.102109
-
[18]
Y . Zeng, G. Cheng, Knowledge-based free mesh generation of quadrilateral elements in two- dimensional domains, Computer-Aided Civil and Infrastructure Engineering 8 (2008) 259 –
2008
-
[19]
doi:10.1111/j.1467-8667.1993.tb00211.x
-
[20]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, Proceedings of the 35th International Conference on Machine Learning 80 (2018) 1861–1870
2018
-
[21]
Bellman, Dynamic Programming, Princeton University Press, 1957
R. Bellman, Dynamic Programming, Princeton University Press, 1957. doi:10.1126/science.153.3731.34
-
[22]
R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, 2nd Edition, MIT Press,
-
[23]
doi:10.1109/TNN.1998.712192
-
[24]
C. J. C. H. Watkins, P. Dayan, Q-learning, Machine Learning 8 (3–4) (1992) 279–292. doi:10.1007/BF00992698
-
[25]
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., Human-level control through deep rein- forcement learning, Nature 518 (7540) (2015) 529–533. doi:10.1038/nature14236. 30
-
[26]
R. J. Williams, Simple statistical gradient-following algorithms for connectionist reinforce- ment learning, Machine Learning 8 (3–4) (1992) 229–256. doi:10.1023/A:1022672621406
-
[27]
V . R. Konda, J. N. Tsitsiklis, Actor-critic algorithms, in: Advances in Neural Information Processing Systems, V ol. 12, 1999
1999
-
[28]
P. M. Knupp, Algebraic mesh quality metrics, SIAM Journal on Scientific Computing 23 (1) (2001) 193–218. doi:10.1137/S1064827500371499
-
[29]
Z. Fan, R. Su, W. Zhang, Y . Yu, Hybrid actor-critic reinforcement learning in parameterized action space, in: Proceedings of the 28th International Joint Conference on Artificial Intelli- gence, 2019, pp. 2279–2285. doi:10.24963/ijcai.2019/316
-
[30]
Y . Lin, X. Liu, Z. Zheng, Discretionary lane-change decision and control via parameterized soft actor-critic for hybrid action space (2024). arXiv:2402.15790. URLhttps://arxiv.org/abs/2402.15790
arXiv 2024
-
[31]
O. Delalleau, M. Peter, E. Alonso, A. Logut, Discrete and continuous action representation for practical RL in video games, CoRR abs/1912.11077 (2019). arXiv:1912.11077. URLhttp://arxiv.org/abs/1912.11077
arXiv 1912
-
[32]
Y . Bengio, J. Louradour, R. Collobert, J. Weston, Curriculum learning, in: Proceed- ings of the 26th International Conference on Machine Learning, 2009, pp. 41–48. doi:10.1145/1553374.1553380
-
[33]
B. C. DiPrete, R. V . Garimella, C. G. Cardona, N. Ray, Reinforcement learning for block decomposition of cad models (2023). arXiv:2302.11066. URLhttps://arxiv.org/abs/2302.11066
arXiv 2023
-
[34]
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, M. Riedmiller, Playing atari with deep reinforcement learning (2013). arXiv:1312.5602. URLhttps://arxiv.org/abs/1312.5602
Pith/arXiv arXiv 2013
-
[35]
J. Bromley, I. Guyon, Y . LeCun, E. Säckinger, R. Shah, Signature verification using a “Siamese” time delay neural network, in: Advances in Neural Information Processing Sys- tems, V ol. 6, 1993. doi:10.1142/S0218001493000339. 31
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.