MLFFM-SegDiff: A Multi-Level Feature Fusion Diffusion Model for Skin Lesion Segmentation
Pith reviewed 2026-06-26 03:07 UTC · model grok-4.3
The pith
A diffusion model with multi-level feature fusion segments skin lesions more accurately by improving boundary recovery and feature interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
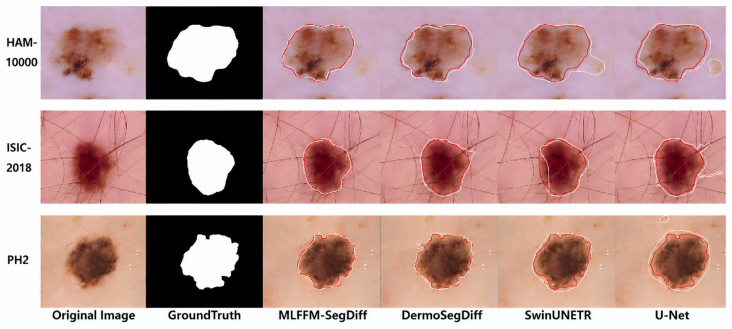
MLFFM-SegDiff is built on a diffusion framework with a dual-path U-Net encoder that enhances interaction between noisy mask features and dermoscopic image features, a Multi-Level Feature Fusion Module that improves skip connections via attention, scale alignment, and adaptive cross-level fusion, and a boundary-sensitive loss function. These designs enable the decoder to jointly leverage shallow boundary cues and deep semantic representations, improving mask reconstruction quality and yielding superior results on ISIC2018, PH2, and HAM10000 compared to DermoSegDiff, U-Net, and SwinUNETR.
What carries the argument
The Multi-Level Feature Fusion Module (MLFFM), which applies attention, scale alignment, and adaptive cross-level fusion to enhance skip connections between encoder and decoder.
If this is right
- The decoder jointly leverages shallow boundary cues and deep semantic representations.
- Mask reconstruction quality improves through better cross-level feature interaction.
- The method outperforms DermoSegDiff, U-Net, and SwinUNETR on Accuracy, F1-score, Jaccard index, Recall, and Dice.
- Average Jaccard index reaches 0.8546 and Dice coefficient reaches 0.9207 across the three datasets.
- The multi-level feature fusion strategy improves lesion segmentation performance.
Where Pith is reading between the lines
- The same fusion mechanism could be tested on segmentation tasks in other medical imaging domains that share boundary and contrast issues.
- Adding the MLFFM to non-diffusion segmentation architectures might produce similar gains without requiring a full diffusion pipeline.
- The focus on boundary-sensitive loss and cross-level cues points to possible use in pipelines that need precise edge localization for downstream classification.
Load-bearing premise
The performance gains are produced by the dual-path encoder, MLFFM attention and scale fusion, and boundary-sensitive loss rather than by dataset-specific tuning or implementation details.
What would settle it
An ablation that removes the MLFFM while keeping the dual-path encoder and loss fixed, then retrains on the same datasets and measures whether metrics fall to baseline levels.
Figures

read the original abstract
Skin lesion segmentation is a key task in computer-aided dermatological diagnosis, where accuracy directly impacts downstream analysis and disease classification. However, dermoscopic images are challenging due to blurred boundaries, low contrast, large shape variations, and artifacts such as hair and shadows. Recently, diffusion models have shown strong performance in medical image segmentation thanks to their progressive denoising and distribution modeling capabilities. Nevertheless, existing diffusion-based methods still suffer from limited cross-level feature interaction and insufficient boundary detail recovery. To address these issues, we propose MLFFM-SegDiff, a multi-level feature fusion diffusion model for skin lesion segmentation. Built on a diffusion framework, the method introduces a dual-path U-Net encoder, a Multi-Level Feature Fusion Module (MLFFM), and a boundary-sensitive loss function. The dual-path encoder enhances interaction between noisy mask features and dermoscopic image features. MLFFM improves skip connections via attention, scale alignment, and adaptive cross-level fusion. These designs enable the decoder to jointly leverage shallow boundary cues and deep semantic representations, improving mask reconstruction quality. Experiments on ISIC2018, PH2, and HAM10000 demonstrate that MLFFM-SegDiff outperforms representative methods including DermoSegDiff, U-Net, and SwinUNETR across Accuracy, F1-score, Jaccard index, Recall, and Dice. In particular, it achieves an average Jaccard index of 0.8546 and Dice coefficient of 0.9207. These results validate the effectiveness of the proposed multi-level feature fusion strategy for improving lesion segmentation performance. The code will be released at https://github.com/Qacket/MLFFM-SegDiff.git after publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MLFFM-SegDiff, a diffusion-based segmentation model for skin lesions that augments a standard diffusion backbone with a dual-path U-Net encoder (to fuse noisy mask and image features), a Multi-Level Feature Fusion Module (MLFFM) implementing attention-based, scale-aligned, and adaptive cross-level fusion in the skip connections, and a boundary-sensitive loss. On ISIC2018, PH2, and HAM10000 the model is reported to outperform DermoSegDiff, U-Net, and SwinUNETR on Accuracy, F1, Jaccard, Recall, and Dice, reaching average Jaccard 0.8546 and Dice 0.9207; the authors attribute the gains to the multi-level fusion design and promise to release code.
Significance. If the reported gains can be shown to arise specifically from the dual-path encoder, MLFFM, and boundary loss rather than from training details or dataset choices, the work would provide a concrete, reproducible demonstration that targeted cross-level fusion improves boundary recovery in diffusion segmentation models for dermoscopy; this would be a modest but useful incremental contribution to the growing literature on diffusion models for medical image segmentation.
major comments (2)
- [Abstract and experimental evaluation] The central empirical claim (average Jaccard 0.8546, Dice 0.9207) rests on the assertion that the dual-path encoder, MLFFM attention/scale/adaptive fusion, and boundary-sensitive loss are responsible for the observed outperformance. No ablation tables, component-wise removal experiments, or controlled comparisons against the unmodified diffusion backbone are described in the abstract or method summary; without such isolation the attribution cannot be verified and the headline numbers could arise from unstated hyper-parameter choices, data splits, or implementation details.
- [Abstract and experimental evaluation] The results paragraph supplies only point estimates for the five metrics across three datasets; no standard deviations, error bars, statistical significance tests (e.g., paired t-tests or Wilcoxon), or multiple-run averages are mentioned. This omission makes it impossible to judge whether the reported margins over DermoSegDiff, U-Net, and SwinUNETR are robust or within the range of random variation.
minor comments (2)
- [Abstract] The abstract states that code will be released after publication; the manuscript should indicate the exact license and whether the released repository will contain the exact training scripts, hyper-parameter files, and random seeds used to produce the reported numbers.
- [Method description] Notation for the MLFFM components (attention map, scale alignment operator, adaptive fusion weights) is introduced only descriptively; a compact mathematical formulation or pseudocode block would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of empirical validation that we will address in the revision to strengthen the attribution of our proposed components.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] The central empirical claim (average Jaccard 0.8546, Dice 0.9207) rests on the assertion that the dual-path encoder, MLFFM attention/scale/adaptive fusion, and boundary-sensitive loss are responsible for the observed outperformance. No ablation tables, component-wise removal experiments, or controlled comparisons against the unmodified diffusion backbone are described in the abstract or method summary; without such isolation the attribution cannot be verified and the headline numbers could arise from unstated hyper-parameter choices, data splits, or implementation details.
Authors: We agree that explicit ablation studies are necessary to isolate the contributions of the dual-path encoder, MLFFM, and boundary-sensitive loss. The current manuscript relies on comparisons to external baselines (DermoSegDiff, U-Net, SwinUNETR) but does not include component-wise removals or direct comparisons to an unmodified diffusion U-Net backbone. In the revised manuscript we will add a dedicated ablation study section with these controlled experiments to verify the source of the reported gains. revision: yes
-
Referee: [Abstract and experimental evaluation] The results paragraph supplies only point estimates for the five metrics across three datasets; no standard deviations, error bars, statistical significance tests (e.g., paired t-tests or Wilcoxon), or multiple-run averages are mentioned. This omission makes it impossible to judge whether the reported margins over DermoSegDiff, U-Net, and SwinUNETR are robust or within the range of random variation.
Authors: We acknowledge that reporting only single-run point estimates limits assessment of result robustness. The manuscript does not currently include multiple-run statistics or significance tests. In the revision we will perform additional experiments with multiple random seeds, report mean and standard deviation values, add error bars where appropriate, and include paired statistical tests (e.g., Wilcoxon signed-rank) to demonstrate that the observed improvements are statistically meaningful. revision: yes
Circularity Check
No significant circularity; empirical validation stands independent of inputs
full rationale
The paper proposes an architecture (dual-path encoder, MLFFM module, boundary-sensitive loss) and reports empirical outperformance on ISIC2018/PH2/HAM10000 against baselines. No mathematical derivation chain, equations, or fitted parameters are described that could reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on standard experimental comparison rather than any self-referential reduction, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T. J. Brinker, A. Hekler, et al., Deep learning outperformed dermatolo- gists in melanoma classification, European Journal of Cancer 119 (2019) 93–100
2019
-
[2]
A. Esteva, B. Kuprel, R. Novoa, et al., Dermatologist-level classification of skin cancer with deep neural networks, Nature 542 (2017) 115–118. doi:10.1038/nature21056
-
[3]
Celebi, Q
E. Celebi, Q. Wen, Dermoscopic image analysis: Overview and future directions, IEEE Reviews in Biomedical Engineering (2019)
2019
-
[4]
In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F
O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in: Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015, pp. 234–241.doi: 10.1007/978-3-319-24574-4_28
-
[5]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, et al., An image is worth 16x16words: Transformersforimagerecognitionatscale, arXivpreprint arXiv:2010.11929 (2021)
Pith/arXiv arXiv 2010
-
[6]
A. Hatamizadeh, D. Xu, A. Myronenko, et al., Swin unetr: Swin trans- formers for semantic segmentation of brain tumors in mri images, arXiv preprint arXiv:2201.01266 (2022)
arXiv 2022
-
[7]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, in: Advances in Neural Information Processing Systems (NeurIPS), 2020, pp. 6840–6851
2020
-
[8]
J. Song, C. Meng, S. Ermon, Denoising diffusion implicit models, in: International Conference on Learning Representations (ICLR), 2021
2021
-
[9]
N. C. F. Codella, D. Gutman, E. Celebi, et al., Skin lesion analysis toward melanoma detection 2018: A challenge dataset, arXiv preprint arXiv:1902.03368 (2019)
Pith/arXiv arXiv 2018
-
[10]
P. Tschandl, C. Rosendahl, H. Kittler, The ham10000 dataset: A large collection of multi-source dermatoscopic images of common pigmented skin lesions, Scientific Data 5 (2018) 180161.doi:10.1038/sdata. 2018.161. 19
-
[11]
T. Mendonça, P. M. Ferreira, J. S. Marques, et al., Ph2: A dermoscopic image database for research and benchmarking, in: IEEE International Conference on Engineering in Medicine and Biology Society (EMBC), 2013, pp. 5437–5440.doi:10.1109/EMBC.2013.6610779
-
[12]
J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for se- mantic segmentation, in: Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2015, pp. 3431–3440. doi:10.1109/CVPR.2015.7298965
-
[13]
O. Oktay, J. Schlemper, et al., Attention u-net: Learning where to look for the pancreas, arXiv preprint arXiv:1804.03999 (2018)
Pith/arXiv arXiv 2018
-
[14]
3–11.doi:10.1007/978-3-030-00889-5_ 1
Z.Zhou, M.M.R.Siddiquee, N.Tajbakhsh, J.Liang, Unet++: Anested u-net architecture for medical image segmentation, in: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (DLMIA), 2018, pp. 3–11.doi:10.1007/978-3-030-00889-5_ 1
-
[15]
Isensee, P
F. Isensee, P. F. Jaeger, S. A. A. Kohl, J. Petersen, K. H. Maier-Hein, nnu-net: A self-configuring method for deep learning-based biomedical image segmentation, Nature Methods 18 (2021) 203–211.doi:10.1038/ s41592-020-01008-z
2021
-
[16]
J. Chen, Y. Lu, Q. Yu, et al., Transunet: Transformers make strong en- coders for medical image segmentation, arXiv preprint arXiv:2102.04306 (2021)
Pith/arXiv arXiv 2021
-
[17]
Nichol, P
A. Nichol, P. Dhariwal, Improved denoising diffusion probabilistic mod- els, in: International Conference on Machine Learning (ICML), 2021, pp. 8162–8171
2021
-
[18]
T. Amit, et al., Segdiff: Image segmentation with diffusion probabilistic models, arXiv preprint arXiv:2112.00390 (2021)
arXiv 2021
-
[19]
J. Wu, et al., Medsegdiff: Medical image segmentation with diffusion probabilistic model, arXiv preprint arXiv:2211.00611 (2022)
arXiv 2022
-
[20]
A. Bozorgpour, et al., Dermosegdiff: A boundary-aware segmen- tation diffusion model for skin lesion delineation, arXiv preprint arXiv:2308.02959 (2023). 20
arXiv 2023
-
[21]
T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, S. Belongie, Fea- ture pyramid networks for object detection, in: Proceedings of the IEEE ConferenceonComputerVisionandPatternRecognition(CVPR),2017, pp. 2117–2125.doi:10.1109/CVPR.2017.106
-
[22]
S. Woo, J. Park, J.-Y. Lee, I. S. Kweon, Cbam: Convolutional block at- tention module, in: European Conference on Computer Vision (ECCV), 2018, pp. 3–19
2018
-
[23]
H. Kervadec, S. Bouchtala, et al., Boundary loss for highly unbalanced segmentation, Medical Image Analysis 67 (2021) 101851.doi:10.1016/ j.media.2020.101851. 21
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.