An Assessment of Human vs. Model Uncertainty in Soft-Label Learning and Calibration
Pith reviewed 2026-05-20 11:51 UTC · model grok-4.3
The pith
Human soft-labels improve model calibration on hard samples and stabilize training more than they boost raw accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After decoupling soft-label supervision from implicit label-mode corrections, human soft labels still produce modest accuracy improvements yet act chiefly as a regularizer that sharpens calibration on ambiguous examples and reduces variance in training trajectories.
What carries the argument
Re-annotation of fixed subsets to extract human uncertainty signals while controlling for label-mode shifts.
If this is right
- Human soft labels produce models whose uncertainty maps more closely onto human uncertainty distributions.
- Calibration gains concentrate on the most ambiguous inputs rather than across the entire test set.
- Training variance across random initializations decreases when human soft labels are used.
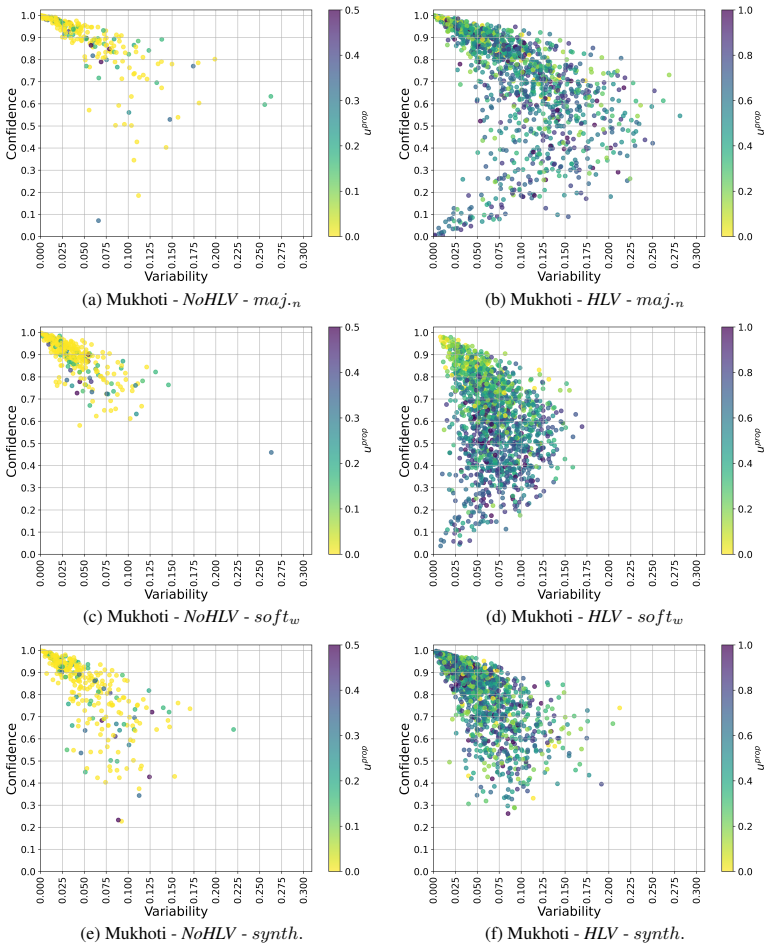
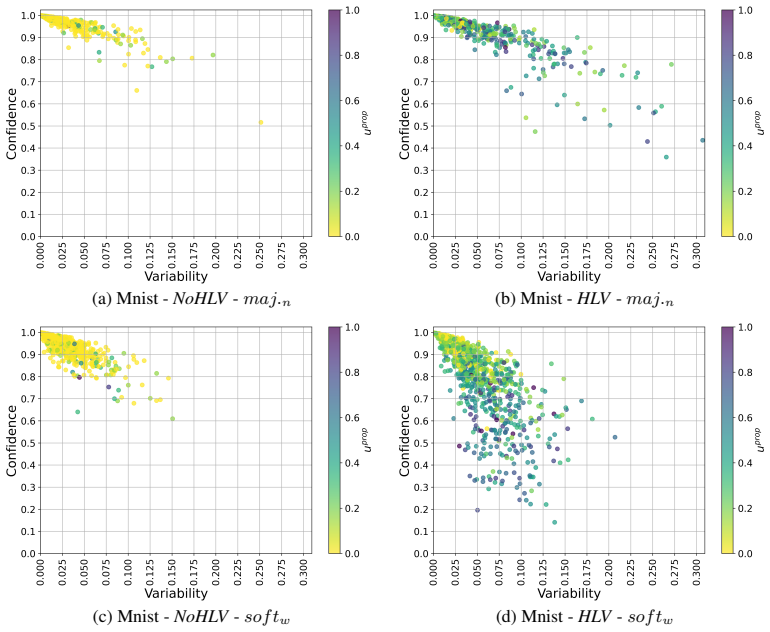
- Dataset cartography becomes a practical tool for verifying human-model uncertainty alignment.
Where Pith is reading between the lines
- Applications that prize reliable uncertainty estimates, such as medical triage or autonomous driving, may benefit more from human soft labels than accuracy-focused tasks.
- The same controlled re-annotation protocol could be applied to larger image or language datasets to test whether the regularization effect scales.
- Hybrid training that mixes a small amount of human soft labels with abundant synthetic data might achieve similar calibration benefits at lower cost.
Load-bearing premise
Re-annotating subsets with human soft labels isolates uncertainty information without introducing selection biases or annotation artifacts absent from the synthetic control.
What would settle it
A replication in which models trained on the human soft-label subsets fail to show lower expected calibration error or higher stability across random seeds on the same held-out difficult samples.
Figures














read the original abstract
Central to human-aligned AI is understanding the benefits of human-elicited labels over synthetic alternatives. While human soft-labels improve calibration by capturing uncertainty, prior studies conflate these benefits with the implicit correction of mislabeled data (mode shifts), obscuring true effects of soft-labels. We present a controlled audit of soft-label learning across MNIST and a synthetic variant, re-annotating subsets to extract human uncertainty. By decoupling soft-label supervision from underlying label mode shifts, we show that while human soft-labels do provide accuracy gains, their larger value lies in acting as a regularizer that improves model calibration on difficult samples and promotes stable convergence across training runs. Dataset cartography reveals models trained on human soft-labels mirror human uncertainty, whereas those trained on synthetic labels fail to align with humans. Broadly, this work provides a diagnostic testbed for human-AI uncertainty alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a controlled audit of soft-label learning on MNIST and a synthetic variant. Subsets are re-annotated with human soft labels to decouple uncertainty information from label mode shifts. The central claims are that human soft-labels yield accuracy gains but primarily function as a regularizer that improves calibration on difficult samples and promotes stable convergence across training runs; dataset cartography further shows that models trained on human soft labels align with human uncertainty patterns while synthetic-label models do not.
Significance. If the controlled isolation of uncertainty effects holds, the work supplies a diagnostic testbed for human-AI uncertainty alignment and clarifies the regularizing role of human soft labels beyond accuracy or mode correction. The attempt to separate these factors is a methodological strength relative to prior conflated studies.
major comments (2)
- [Experimental Design / Re-annotation Protocol] The re-annotation procedure on chosen subsets is load-bearing for the claim that observed calibration and stability gains arise from human uncertainty regularization rather than selection or annotation artifacts. The manuscript must demonstrate that subset selection (e.g., by initial model uncertainty or image difficulty) and the human annotation process produce label distributions and sample hardness statistics that match the synthetic control on all dimensions except uncertainty; without explicit comparisons or ablation on selection criteria, the decoupling remains unverified.
- [Results and Analysis] Quantitative support for the key findings is insufficient. The abstract and results sections report no specific metrics (e.g., ECE, NLL, or variance across runs), error bars, or statistical tests comparing human vs. synthetic conditions on difficult samples; without these, the assertion that human soft labels act as a superior regularizer cannot be evaluated.
minor comments (2)
- [Dataset and Setup] Clarify the construction of the 'synthetic variant' of MNIST and the precise criteria used to select subsets for re-annotation.
- [Throughout] Ensure consistent terminology ('soft-labels' vs. 'soft labels') and define 'difficult samples' operationally when discussing calibration gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Experimental Design / Re-annotation Protocol] The re-annotation procedure on chosen subsets is load-bearing for the claim that observed calibration and stability gains arise from human uncertainty regularization rather than selection or annotation artifacts. The manuscript must demonstrate that subset selection (e.g., by initial model uncertainty or image difficulty) and the human annotation process produce label distributions and sample hardness statistics that match the synthetic control on all dimensions except uncertainty; without explicit comparisons or ablation on selection criteria, the decoupling remains unverified.
Authors: We agree that explicit verification of matching statistics between the human re-annotated subsets and synthetic controls is necessary to substantiate the decoupling of uncertainty effects from selection or mode-shift artifacts. The current manuscript describes the protocol and selection process but does not include direct comparative statistics or ablations. In the revised manuscript we will add these elements, including side-by-side comparisons of label entropy, mode agreement, and hardness metrics (e.g., initial model confidence) across conditions, plus an ablation varying selection criteria. These additions will be placed in a dedicated subsection with supporting tables. revision: yes
-
Referee: [Results and Analysis] Quantitative support for the key findings is insufficient. The abstract and results sections report no specific metrics (e.g., ECE, NLL, or variance across runs), error bars, or statistical tests comparing human vs. synthetic conditions on difficult samples; without these, the assertion that human soft labels act as a superior regularizer cannot be evaluated.
Authors: We acknowledge that the presentation of quantitative results can be strengthened. While comparative trends are shown, the manuscript does not report specific numerical values for ECE, NLL, run variance, error bars, or formal statistical tests on the difficult-sample subset. In the revision we will add these details in the results section and abstract, including tables with mean values plus standard deviations across runs, error bars on figures, and statistical comparisons (e.g., paired tests) restricted to hard samples. This will allow direct evaluation of the regularizing effect. revision: yes
Circularity Check
Empirical study with no derivations or self-referential reductions
full rationale
The paper conducts a controlled empirical audit on MNIST and synthetic variants by re-annotating subsets with human soft labels versus synthetic controls. All central claims—accuracy gains, calibration improvements on difficult samples, training stability, and alignment via dataset cartography—are supported solely by experimental comparisons and observed performance metrics. No equations, parameter fits, uniqueness theorems, or derivation chains appear in the provided text; the analysis does not reduce any result to its inputs by construction. This is a standard self-contained empirical study against external benchmarks such as model calibration error and convergence variance.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Alexander L Anwyl-Irvine, Jessica Massonnié, Adam Flitton, Natasha Kirkham, and Jo K Evershed. Gorilla in our midst: An online behavioral experiment builder.Behavior research methods, 52(1):388–407, 2020
work page 2020
-
[3]
Lora Aroyo, Alex Taylor, Mark Diaz, Christopher Homan, Alicia Parrish, Gregory Serapio- García, Vinodkumar Prabhakaran, and Ding Wang. Dices dataset: Diversity in conversational ai evaluation for safety.Advances in Neural Information Processing Systems, 36:53330–53342, 2023
work page 2023
-
[4]
Fill in the gaps: Model calibration and generalization with synthetic data
Yang Ba, Michelle V Mancenido, and Rong Pan. Fill in the gaps: Model calibration and generalization with synthetic data. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17211–17225, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.955. URL https:...
-
[5]
Stop measuring calibration when humans disagree
Joris Baan, Wilker Aziz, Barbara Plank, and Raquel Fernandez. Stop measuring calibration when humans disagree. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1892–1915, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.124. URL https:...
-
[7]
Tailoring mixup to data for calibration
Quentin Bouniot, Pavlo Mozharovskyi, and Florence d’Alché Buc. Tailoring mixup to data for calibration. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=3ygfMPLv0P
work page 2025
-
[8]
Muthu Chidambaram and Rong Ge. Reassessing how to compare and improve the calibration of machine learning models.arXiv preprint arXiv:2406.04068, 2024
-
[9]
Collins, Umang Bhatt, and Adrian Weller
Katherine M. Collins, Umang Bhatt, and Adrian Weller. Eliciting and Learning with Soft Labels from Every Annotator.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, 10:40–52, October 2022. ISSN 2769-1349. doi: 10.1609/hcomp.v10i1.21986. URLhttps://ojs.aaai.org/index.php/HCOMP/article/view/21986
-
[10]
Collins, Umang Bhatt, Weiyang Liu, Vihari Piratla, Ilia Sucholutsky, Bradley Love, and Adrian Weller
Katherine M. Collins, Umang Bhatt, Weiyang Liu, Vihari Piratla, Ilia Sucholutsky, Bradley Love, and Adrian Weller. Human-in-the-loop mixup. InProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, UAI ’23. JMLR.org, 2023. 10
work page 2023
-
[11]
Human Uncertainty in Concept-Based AI Systems
Katherine Maeve Collins, Matthew Barker, Mateo Espinosa Zarlenga, Naveen Raman, Umang Bhatt, Mateja Jamnik, Ilia Sucholutsky, Adrian Weller, and Krishnamurthy Dvijotham. Human Uncertainty in Concept-Based AI Systems. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 869–889, Montreal Canada, August 2023. ACM. ISBN 97984007023...
-
[12]
Position: insights from survey methodol- ogy can improve training data
Stephanie Eckman, Barbara Plank, and Frauke Kreuter. Position: insights from survey methodol- ogy can improve training data. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[13]
Neele Falk and Gabriella Lapesa. Mining the uncertainty patterns of humans and models in the annotation of moral foundations and human values. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22898–22921, 2025
work page 2025
-
[14]
Stephen M Fleming. Metacognition and confidence: A review and synthesis.Annual Review of Psychology, 75(1):241–268, 2024
work page 2024
-
[15]
Mirta Galesic, Roger Tourangeau, Mick P Couper, and Frederick G Conrad. Eye-tracking data: New insights on response order effects and other cognitive shortcuts in survey responding. Public opinion quarterly, 72(5):892–913, 2008
work page 2008
-
[16]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017. URLhttps://proceedings.mlr.press/v70/guo17a.html
work page 2017
-
[17]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Gideon Keren. Facing uncertainty in the game of bridge: A calibration study.Organizational Behavior and Human Decision Processes, 39(1):98–114, 1987
work page 1987
-
[19]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
Joshua Klayman, Jack B Soll, Claudia Gonzalez-Vallejo, and Sema Barlas. Overconfidence: It depends on how, what, and whom you ask.Organizational behavior and human decision processes, 79(3):216–247, 1999
work page 1999
-
[21]
Meelis Kull, Miquel Perello Nieto, Markus Kängsepp, Telmo Silva Filho, Hao Song, and Peter Flach. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration.Advances in neural information processing systems, 32, 2019
work page 2019
-
[22]
Trainable calibration measures for neural networks from kernel mean embeddings
Aviral Kumar, Sunita Sarawagi, and Ujjwal Jain. Trainable calibration measures for neural networks from kernel mean embeddings. InInternational Conference on Machine Learning, pages 2805–2814. PMLR, 2018
work page 2018
-
[23]
Huseyin Kusetogullari, Amir Yavariabdi, Abbas Cheddad, Håkan Grahn, and Johan Hall. Ardis: a swedish historical handwritten digit dataset.Neural Computing and Applications, 32(21): 16505–16518, 2020
work page 2020
-
[24]
The mnist database of handwritten digits.http://yann
Yann LeCun. The mnist database of handwritten digits.http://yann. lecun. com/exdb/mnist/, 1998
work page 1998
-
[25]
Alisa Liu, Zhaofeng Wu, Julian Michael, Alane Suhr, Peter West, Alexander Koller, Swabha Swayamdipta, Noah Smith, and Yejin Choi. We’re afraid language models aren’t modeling ambiguity. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 790–807, Singapore, December 2023. Association for Computational Lin- guist...
-
[26]
Aaron Maladry, Alessandra Teresa Cignarella, Els Lefever, Cynthia van Hee, and Veronique Hoste. Human and system perspectives on the expression of irony: An analysis of likelihood labels and rationales. InProceedings of the 2024 Joint International Conference on Com- putational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 8372–...
work page 2024
-
[27]
A scalable framework for evaluating health language models.npj Digital Medicine, 2026
Neil Mallinar, A Ali Heydari, Xin Liu, Anthony Z Faranesh, Brent Winslow, Nova Hammerquist, Benjamin Graef, Cathy Speed, Mark Malhotra, Shwetak Patel, et al. A scalable framework for evaluating health language models.npj Digital Medicine, 2026
work page 2026
-
[28]
Aggregation under uncertainty.IEEE Transactions on Fuzzy Systems, 26(4):2475–2478, 2018
Radko Mesiar, Surajit Borkotokey, LeSheng Jin, and Martin Kalina. Aggregation under uncertainty.IEEE Transactions on Fuzzy Systems, 26(4):2475–2478, 2018. doi: 10.1109/ TFUZZ.2017.2756828
-
[29]
Jishnu Mukhoti, Andreas Kirsch, Joost van Amersfoort, Philip H.S. Torr, and Yarin Gal. Deep deterministic uncertainty: A new simple baseline. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24384–24394, June 2023
work page 2023
-
[30]
When does label smoothing help? Advances in neural information processing systems, 32, 2019
Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? Advances in neural information processing systems, 32, 2019
work page 2019
-
[31]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InProceedings of the AAAI conference on artificial intelligence, volume 29, 2015
work page 2015
-
[32]
Predicting good probabilities with supervised learning
Alexandru Niculescu-Mizil and Rich Caruana. Predicting good probabilities with supervised learning. InProceedings of the 22nd international conference on Machine learning, pages 625–632, 2005
work page 2005
- [33]
-
[34]
Don’t blame the annotator: Bias already starts in the annotation instructions
Mihir Parmar, Swaroop Mishra, Mor Geva, and Chitta Baral. Don’t blame the annotator: Bias already starts in the annotation instructions. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 1779–1789, 2023
work page 2023
-
[35]
Alicia Parrish, Susan Hao, Sarah Laszlo, and Lora Aroyo. Is a picture of a bird a bird? a mixed-methods approach to understanding diverse human perspectives and ambiguity in machine vision models. InProceedings of the 3rd Workshop on Perspectivist Approaches to NLP (NLPerspectives) @ LREC-COLING 2024, pages 1–18, Torino, Italia, May 2024. ELRA and ICCL. U...
work page 2024
-
[36]
Maja Pavlovic. Understanding model calibration - a gentle introduction and vi- sual exploration of calibration and the expected calibration error (ece). In ICLR Blogposts 2025, 2025. URL https://d2jud02ci9yv69.cloudfront.net/ 2025-04-28-calibration-45/blog/calibration/
work page 2025
-
[37]
Joshua C. Peterson, Ruairidh M. Battleday, Thomas L. Griffiths, and Olga Russakovsky. Human uncertainty makes classification more robust. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019
work page 2019
-
[38]
The “problem” of human label variation: On ground truth in data, modeling and evaluation
Barbara Plank. The “problem” of human label variation: On ground truth in data, modeling and evaluation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10671–10682, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.731. URL https://ac...
-
[39]
Ambiguous images with human judgments for robust visual event classification
Kate Sanders, Reno Kriz, Anqi Liu, and Benjamin Van Durme. Ambiguous images with human judgments for robust visual event classification. InThirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URL https:// openreview.net/forum?id=6Hl7XoPNAVX. 12
work page 2022
-
[40]
Luisa Schwirten, Jannes Scholz, Daniel Kondermann, and Janis Keuper. Ambiguous annotations: When is a pedestrian not a pedestrian? InFirst Vision and Language for Autonomous Driving and Robotics Workshop, 2024. URLhttps://openreview.net/forum?id=aPzFAopRks
work page 2024
-
[41]
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. Dataset cartography: Mapping and diagnosing datasets with training dynamics. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9275–9293, Online, November 2020. Association for Computati...
-
[42]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfel- low, and Rob Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[43]
Sunil Thulasidasan, Gopinath Chennupati, Jeff A Bilmes, Tanmoy Bhattacharya, and Sarah Michalak. On mixup training: Improved calibration and predictive uncertainty for deep neural networks.Advances in neural information processing systems, 32, 2019
work page 2019
-
[44]
Alexandra N Uma, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, and Massimo Poesio. Learning from disagreement: A survey.Journal of Artificial Intelligence Research, 72: 1385–1470, 2021
work page 2021
-
[45]
Michael Weiss, André García Gómez, and Paolo Tonella. Generating and detecting true ambiguity: a forgotten danger in dnn supervision testing.Empirical Software Engineering, 28 (6):146, 2023
work page 2023
-
[46]
Towards understanding why label smoothing degrades selective classification and how to fix it
Guoxuan Xia, Olivier Laurent, Gianni Franchi, and Christos-Savvas Bouganis. Towards understanding why label smoothing degrades selective classification and how to fix it. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=6oWFn6fY4A
work page 2025
-
[47]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Mike Zhang and Barbara Plank. Cartography active learning. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 395–406, Punta Cana, Dominican Re- public, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021. findings-emnlp.36. URLhttps://aclanthology.org/2021.findings-emnlp.36/
-
[49]
Fei Zhu, Zhen Cheng, Xu-Yao Zhang, and Cheng-Lin Liu. Rethinking confidence calibration for failure prediction. InEuropean conference on computer vision, pages 518–536. Springer, 2022. A Data Collection Process A.1 Corpus size To establish a lower bound for the number of training instances per class required to achieve reliable performance, we conducted a...
-
[50]
remain subject to the terms of the MIT License. G.6 Maintenance The soft-digits dataset is hosted on the Hugging Face Hub, which serves as the primary platform for its distribution and long-term maintenance. The corresponding author is responsible for managing the repository, ensuring the data remains accessible, and performing any necessary updates or ve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.