Small edits, large models: How Wikipedia advocacy shapes LLM values
Pith reviewed 2026-07-01 09:00 UTC · model grok-4.3
The pith
A small group of Wikipedia editors can measurably shape how language models discuss animal welfare topics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
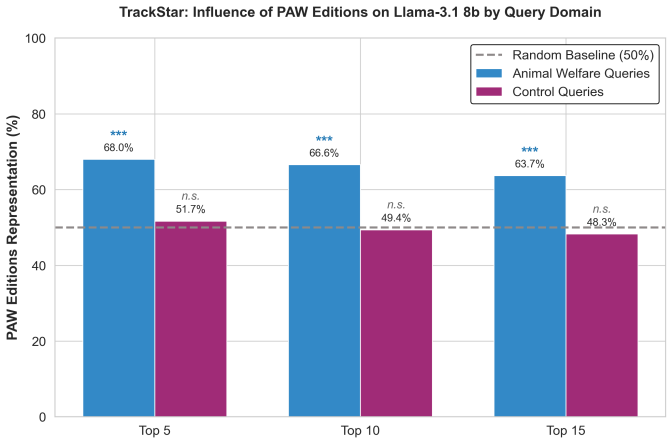
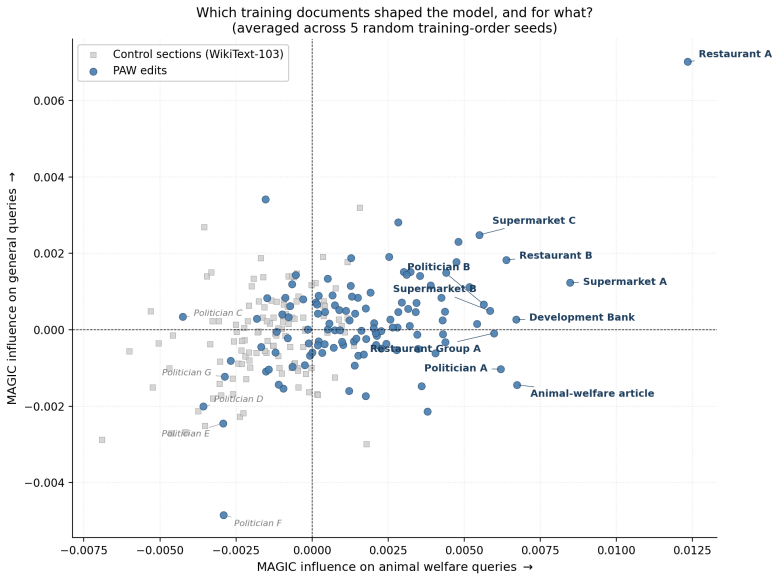
Using TrackStar retrieval attribution on Llama 3.1 8B, PAW-edited sections made up 68 percent of the highest-attributed documents for animal welfare queries but only 52 percent for unrelated queries about the same companies. MAGIC counterfactual influence estimation on Llama-3.2-1B, repeated across five random training-order seeds, found that the top-10 most influential documents on animal welfare queries were all PAW edits in every seed, while the same top-10 sat at chance levels on general queries. Mean PAW influence exceeded mean control influence on animal welfare queries with p less than 0.0001 in every seed, an effect 6 to 30 times larger than on general queries. Leave-subset-out valid
What carries the argument
Gradient-based data attribution (TrackStar retrieval and MAGIC counterfactual influence estimation) that traces the contribution of specific Wikipedia page sections to model outputs on targeted versus control queries.
If this is right
- The influence of the edits is topic-specific rather than a general association with the mentioned companies or pages.
- Counterfactual estimation shows that the top influential documents shift completely to PAW edits when the query concerns animal welfare.
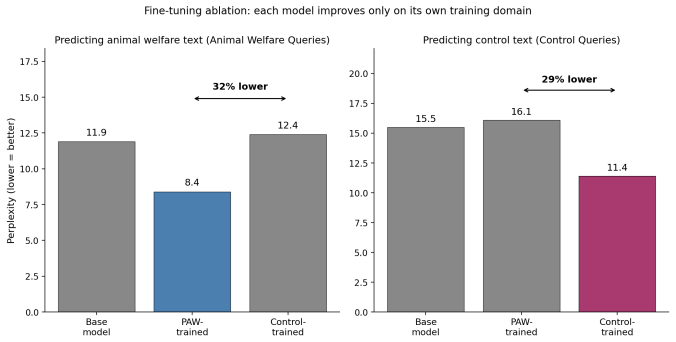
- Fine-tuning on the edited content improves model performance only on the matching category of text.
- The effect size difference between targeted and control queries holds across multiple random training seeds and validation runs.
Where Pith is reading between the lines
- The same attribution pipeline could be applied to other coordinated editing campaigns on Wikipedia to check for comparable topic-specific effects.
- Public knowledge platforms function as high-leverage insertion points for shaping downstream model behavior when training data is drawn from them.
- Auditing training corpora with influence methods might reveal other narrow editing efforts that have already propagated into deployed models.
- The observed pattern suggests that small changes in high-weight data sources can produce outsized, topic-local shifts in model outputs without altering the overall training distribution.
Load-bearing premise
The attribution methods correctly isolate the causal effect of the specific PAW edits rather than capturing correlated features of the pages or query selection biases.
What would settle it
If the proportion of PAW-edited sections among the top-attributed documents remained statistically indistinguishable between animal welfare queries and unrelated queries about the same entities, the claim of topic-specific influence would be falsified.
Figures
read the original abstract
Can a small group of volunteers shape how AI systems discuss animal welfare, just by editing Wikipedia? We show that they can. Wikipedia appears in nearly every major language model training dataset and is weighted more heavily than web-crawled text. The Pro-Animal Wikipedians (PAW), a group of advocates who add sourced animal welfare content to relevant articles, have made 125 edits across 115 pages. Using gradient-based data attribution (Bergson; MAGIC), we traced how these edits influence language model behavior. TrackStar retrieval attribution on Llama 3.1 8B found that PAW-edited sections made up 68 percent of the highest-attributed documents for animal welfare queries (p < 0.0001) but only 52 percent for unrelated queries about the same companies (p = 0.53): the model links PAW content specifically to animal welfare topics, not to the entities in general. MAGIC counterfactual influence estimation on Llama-3.2-1B, run across five random training-order seeds, gave the same picture even more sharply: in every seed, the top-10 most influential documents on animal welfare queries were all PAW edits (10 of 10, 5 of 5 seeds), while on general queries the same top-10 sat at chance (4 to 6 of 10). Mean PAW influence exceeded mean control influence on animal welfare queries with p < 0.0001 in every seed, an effect 6 to 30 times larger than on general queries. Leave-subset-out validation gave Spearman rho = 1.00 for all 10 runs. When we fine-tuned separate models on PAW content versus control content, each model performed better specifically on the type of text it was trained on: the PAW-trained model cut perplexity on animal welfare text from 12.4 to 8.4, while the control-trained model cut perplexity on control text from 16.1 to 11.4. A small, coordinated Wikipedia editing campaign therefore measurably shapes how language models handle the topics those edits address.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a small coordinated set of 125 Wikipedia edits by the Pro-Animal Wikipedians (PAW) across 115 pages measurably shapes LLM behavior on animal-welfare topics. Using TrackStar retrieval attribution on Llama 3.1 8B, PAW-edited sections comprise 68% of top-attributed documents for animal-welfare queries (p < 0.0001) versus 52% for unrelated control queries on the same entities (p = 0.53). MAGIC gradient-based influence on Llama-3.2-1B across five training-order seeds shows the top-10 documents for animal-welfare queries are all PAW edits (10/10 in every seed) while controls are at chance (4–6/10); mean PAW influence exceeds control with p < 0.0001 and is 6–30 times larger than on general queries. Leave-subset-out validation yields Spearman rho = 1.00. Separate fine-tuning runs confirm topic-specific effects: PAW-trained models reduce perplexity on animal-welfare text from 12.4 to 8.4 while control-trained models reduce it on control text from 16.1 to 11.4.
Significance. If the attribution methods validly isolate causal influence from the specific PAW edits, the result would demonstrate that modest, targeted Wikipedia editing can produce measurable, topic-specific shifts in LLM behavior. The internal consistency across five seeds, perfect leave-subset-out rank correlation, and the fine-tuning perplexity contrast (topic-specific rather than global) are genuine strengths that support reproducibility of the chosen metrics.
major comments (2)
- [Abstract] Abstract: The interpretation that the 68% vs 52% TrackStar differential and the 10/10 MAGIC top-document result demonstrate specific causal influence from the 125 PAW edits assumes that both attribution procedures recover ground-truth influence rather than topical content similarity or query-selection effects; no validation experiment (e.g., synthetic injection of known edits or comparison against a ground-truth influence oracle) is described to test this premise, which is load-bearing for the central claim.
- [Abstract] Abstract: Query construction, sampling of documents for attribution, and the precise definition of the control query set are not specified, preventing assessment of whether the reported separation between animal-welfare and control conditions could be driven by semantic overlap or selection bias rather than the PAW edits themselves.
minor comments (1)
- [Abstract] Abstract: The fine-tuning perplexity reductions would be easier to interpret if the number of evaluation documents or tokens per condition were reported.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for noting the strengths in internal consistency, cross-seed reproducibility, and the fine-tuning perplexity contrasts. Below we respond point-by-point to the two major comments. We agree that greater methodological transparency and explicit discussion of attribution assumptions are warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: The interpretation that the 68% vs 52% TrackStar differential and the 10/10 MAGIC top-document result demonstrate specific causal influence from the 125 PAW edits assumes that both attribution procedures recover ground-truth influence rather than topical content similarity or query-selection effects; no validation experiment (e.g., synthetic injection of known edits or comparison against a ground-truth influence oracle) is described to test this premise, which is load-bearing for the central claim.
Authors: We acknowledge that the manuscript does not include a synthetic-injection or oracle-based validation of the attribution methods, and that such an experiment would strengthen the causal interpretation. The control conditions (unrelated queries on identical entities, plus general queries) were intended to isolate topic-specific effects from entity or semantic overlap, and the leave-subset-out Spearman rho = 1.00 plus perfect top-10 consistency across five seeds provide internal checks. Nevertheless, we will add a dedicated Limitations subsection that explicitly states the lack of synthetic validation, discusses the assumptions of TrackStar and MAGIC, and notes that the reported differentials are conditional on those assumptions. If the available data and compute permit, we will also attempt a small-scale synthetic edit injection as an appendix experiment. revision: partial
-
Referee: [Abstract] Abstract: Query construction, sampling of documents for attribution, and the precise definition of the control query set are not specified, preventing assessment of whether the reported separation between animal-welfare and control conditions could be driven by semantic overlap or selection bias rather than the PAW edits themselves.
Authors: The full Methods section contains the query templates, retrieval sampling procedure (top-k documents from the indexed corpus), and control-query definitions, but these details are not summarized in the abstract or introduction. We will revise the abstract and add a concise Experimental Setup paragraph that specifies: (i) the exact query templates used for animal-welfare versus control conditions, (ii) the document sampling rule for attribution runs, and (iii) the control set construction (queries about the same 115 entities but on non-welfare topics such as financial metrics or historical facts). This will allow readers to evaluate potential semantic overlap directly. revision: yes
Circularity Check
No circularity: central results rely on external attribution tools and independent fine-tuning experiments
full rationale
The paper reports empirical measurements of influence using TrackStar retrieval and MAGIC gradient-based attribution (external methods) plus separate fine-tuning runs on PAW vs. control content. No equations appear in the provided text, and no step reduces a reported influence score or perplexity differential to a parameter fitted inside the paper or to a self-citation chain. Leave-subset-out Spearman rho = 1.00 is an internal consistency check on the chosen metrics rather than a re-derivation of the influence itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[2]
arXiv preprint arXiv:2302.10149 , year=
Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr. Poisoning web-scale training datasets is practical.arXiv preprint arXiv:2302.10149, 2023
-
[3]
Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney
Tyler A. Chang, Dheeraj Rajagopal, Tolga Bolukbasi, Lucas Dixon, and Ian Tenney. Scalable influence and fact tracing for large language model pretraining.arXiv preprint arXiv:2410.17413,
-
[4]
doi: 10.48550/arXiv.2410.17413
-
[5]
Marcia W. DiStaso. Perceptions of wikipedia by public relations professionals: A comparison of 2012 and 2013 surveys. Institute for Public Relations, 2013. URL https://instituteforpr.org/ perceptions-wikipedia-public-relations-professionals-comparison-2012-2013-surveys/
2012
-
[6]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
doi: 10.48550/arXiv.2101.00027
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.00027
-
[8]
MAGIC: Near-optimal data attribution for deep learning
Andrew Ilyas and Logan Engstrom. MAGIC: Near-optimal data attribution for deep learning. arXiv preprint arXiv:2504.16430, 2025. URLhttps://arxiv.org/abs/2504.16430
-
[9]
Datamodels: Predicting predictions from training data.arXiv preprint arXiv:2202.00622, 2022
Andrew Ilyas, Sung Min Park, Logan Engstrom, Guillaume Leclerc, and Aleksander Madry. Datamodels: Predicting predictions from training data.arXiv preprint arXiv:2202.00622, 2022
-
[10]
Zarine Kharazian, Kate Starbird, and Benjamin Mako Hill. Governance capture in a self- governing community: A qualitative comparison of the Croatian, Serbian, Bosnian, and Serbo- Croatian wikipedias.Proceedings of the ACM on Human-Computer Interaction, 8(CSCW1): 1–26, 2024. doi: 10.1145/3637338
-
[11]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational Conference on Machine Learning, pages 1885–1894, 2017
2017
-
[12]
EleutherAI/bergson: Mapping out the “memory” of neural nets with data attribution
Quintin Lucia and Nora Belrose. EleutherAI/bergson: Mapping out the “memory” of neural nets with data attribution. GitHub, 2026. URLhttps://github.com/EleutherAI/bergson
2026
-
[13]
Trak: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186, 2023
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. TRAK: Attributing model behavior at scale.arXiv preprint arXiv:2303.14186, 2023
-
[14]
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, et al. Dolma: An open corpus of three trillion tokens for language model pretraining research.arXiv preprint arXiv:2402.00159, 2024. doi: 10.48550/arXiv.2402.00159
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Concealed data poisoning attacks on NLP models
Eric Wallace, Tony Z Zhao, Shi Feng, and Sameer Singh. Concealed data poisoning attacks on NLP models. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 139–150, 2021
2021
-
[17]
Redpajama: An open dataset for training large language models.arXiv preprint arXiv:2411.12372, 2024
Maurice Weber, Daniel Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, et al. Redpajama: An open dataset for training large language models.arXiv preprint arXiv:2411.12372, 2024. doi: 10.48550/arXiv.2411.12372
-
[18]
What is Restaurant C chicken welfare policy?
Taha Yasseri, Robert Sumi, András Rung, András Kornai, and János Kertész. Dynamics of conflicts in wikipedia.PLoS ONE, 2012. doi: 10.1371/journal.pone.0038869. 9 A Query Examples and Data Availability All datasets, queries, and fine-tuned models are available from the authors on request. Below we list example queries from each set. A.1 Animal Welfare Quer...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.