ProWAFT: A ROMA-LPD Instance for Workload-Aware and Dynamic Fault Tolerance in FPGA-Based CNN Accelerators
Pith reviewed 2026-07-03 15:21 UTC · model grok-4.3
The pith
ProWAFT selectively applies TMR using partial reconfiguration to minimize a composite cost of latency, energy, and reliability risk in FPGA-based CNN accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
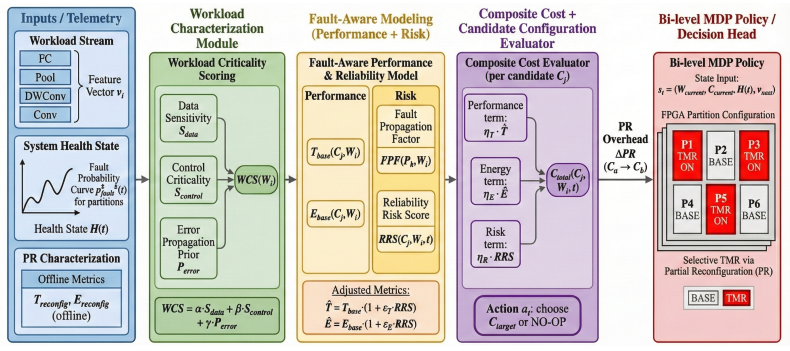
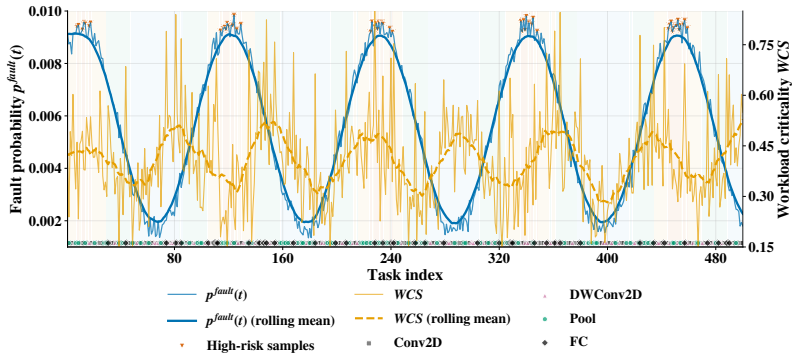
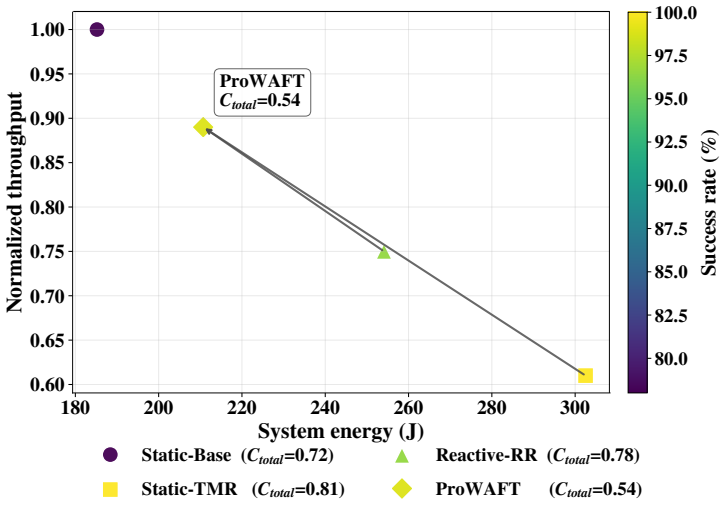
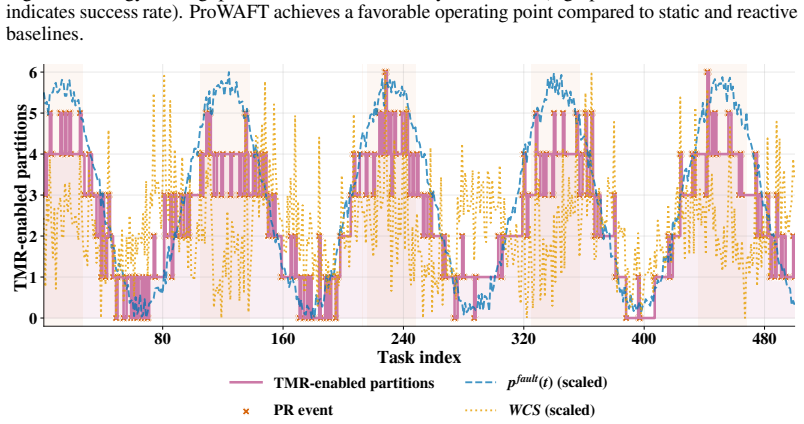
ProWAFT quantifies workload criticality, models fault propagation and reconfiguration overhead, and selects configurations that minimize a composite objective over latency, energy, and reliability risk. Implemented on a Xilinx Zynq UltraScale+ ZCU104 platform with six reconfigurable regions and evaluated on a 500-task trace derived from ResNet-18, MobileNetV2, and EfficientNet-Lite under time-varying SEU injection, ProWAFT achieves lower composite cost than static TMR and reactive reconfiguration while maintaining high task success rate and near-baseline throughput with low online decision overhead.
What carries the argument
A proactive selector that decides TMR application per reconfigurable region based on a composite objective incorporating workload criticality, fault propagation models, and reconfiguration overhead.
Load-bearing premise
The models of fault propagation, reconfiguration overhead, and workload criticality accurately predict real hardware behavior and that the chosen objective weights produce meaningful trade-offs.
What would settle it
Executing the 500-task trace on the ZCU104 board under actual time-varying SEU conditions and verifying whether the measured composite cost, success rate, and throughput match or exceed the reported improvements over static TMR and reactive methods.
Figures

read the original abstract
SRAM-based FPGAs provide an attractive platform for energy- and latency-constrained CNN inference at the network edge, yet transient faults can lead to silent errors that compromise reliability. Always-on redundancy (e.g., full TMR) improves correctness but incurs substantial performance and energy overhead, while reactive recovery may introduce unacceptable latency on the critical path. We propose \textbf{ProWAFT}, a proactive workload-aware fault-tolerance framework for FPGA-based CNN accelerators that uses partial reconfiguration to selectively apply TMR across reconfigurable partitions. ProWAFT quantifies workload criticality, models fault propagation and reconfiguration overhead, and selects configurations that minimize a composite objective over latency, energy, and reliability risk. Implemented on a Xilinx Zynq UltraScale+ ZCU104 platform with six reconfigurable regions and evaluated on a 500-task trace derived from ResNet-18, MobileNetV2, and EfficientNet-Lite under time-varying SEU injection, ProWAFT achieves lower composite cost than static TMR and reactive reconfiguration while maintaining high task success rate and near-baseline throughput with low online decision overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProWAFT, a proactive workload-aware fault-tolerance framework for FPGA-based CNN accelerators. It quantifies workload criticality, models fault propagation and reconfiguration overhead, and selects partial-reconfiguration configurations that minimize a composite objective over latency, energy, and reliability risk. Implemented on a Xilinx Zynq UltraScale+ ZCU104 platform with six reconfigurable regions, the framework is evaluated on a 500-task trace derived from ResNet-18, MobileNetV2, and EfficientNet-Lite under time-varying SEU injection and claims lower composite cost than static TMR and reactive reconfiguration while preserving high task success rate, near-baseline throughput, and low online decision overhead.
Significance. If the underlying models prove accurate on hardware, the work offers a concrete dynamic alternative to always-on TMR or purely reactive recovery for edge FPGA CNN accelerators, with the real-platform implementation on the ZCU104 and the multi-network 500-task trace providing a grounded evaluation setting that could influence practical reliability techniques.
major comments (1)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central claim of lower composite cost and maintained high task success rate rests on the models of fault propagation, reconfiguration overhead, and workload criticality. The manuscript provides no description of how these models were derived, calibrated, or validated against measured SEU error rates, actual reconfiguration latencies, or observed task success rates on the ZCU104 under the stated injection conditions. This validation step is load-bearing for the reported improvements over the baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on model derivation and validation below.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The central claim of lower composite cost and maintained high task success rate rests on the models of fault propagation, reconfiguration overhead, and workload criticality. The manuscript provides no description of how these models were derived, calibrated, or validated against measured SEU error rates, actual reconfiguration latencies, or observed task success rates on the ZCU104 under the stated injection conditions. This validation step is load-bearing for the reported improvements over the baselines.
Authors: We agree that the manuscript lacks an explicit description of how the fault propagation, reconfiguration overhead, and workload criticality models were derived, calibrated, or validated against hardware measurements on the ZCU104. In the revised manuscript we will add a dedicated subsection in the Evaluation section that details the model construction (including the SEU rate assumptions drawn from prior literature, the analytical fault-propagation equations, and the overhead formulas), the calibration procedure used with platform measurements, and direct comparisons between modeled and observed reconfiguration latencies and task success rates under the injection conditions reported in the paper. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The abstract describes ProWAFT as quantifying workload criticality, modeling fault propagation and reconfiguration overhead, then selecting configurations to minimize a composite objective. No equations, derivations, or self-referential definitions appear that would reduce the claimed lower composite cost or maintained success rate to fitted inputs or prior self-citations by construction. The evaluation on the 500-task trace is presented as an independent empirical comparison against static TMR and reactive baselines, with no load-bearing step that collapses to the inputs. The framework is therefore self-contained against the stated hardware benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms
Huiyi Chen, Jiawei Peng, Dehai Min, Changchang Sun, Kaijie Chen, Yan Yan, Xu Yang, and Lu Cheng. Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms. InProceedings of the 43rd International Conference on Machine Learning (ICML 2026), 2025a. Kaijie Chen, Zihao Lin, Zhiyang Xu, Ying Shen, Yuguang Yao, Joy Rimc...
-
[2]
Hao Feng, Zijian Wang, Jingqun Tang, Jinghui Lu, Wengang Zhou, Houqiang Li, and Can Huang. Unidoc: A universal large multimodal model for simultaneous text detection, recognition, spotting and understanding.arXiv preprint arXiv:2308.11592,
-
[3]
Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
-
[4]
Ling Fu, Biao Yang, Zhebin Kuang, Jiajun Song, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Mingxin Huang, et al. Ocrbench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning.arXiv preprint arXiv:2501.00321,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
11 Hongcheng Gao, Jiashu Qu, Jingyi Tang, Baolong Bi, Yue Liu, Hongyu Chen, Li Liang, Li Su, and Qingming Huang. Exploring hallucination of large multimodal models in video understanding: Benchmark, analysis and mitigation.arXiv preprint arXiv:2503.19622,
-
[6]
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
doi: 10.48550/arXiv. 2503.19622. URLhttps://arxiv.org/abs/2503.19622. Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062,
work page internal anchor Pith review doi:10.48550/arxiv
-
[7]
GUI Agents for Continual Game Generation
Yixu Huang, Bo Li, Na Li, Zhe Wang, Kaijie Chen, Haonan Ge, Qingyi Si, Yuanzhe Shen, Ruihan Yang, Guangjing Wang, and Hongcheng Guo. Gui agents for continual game generation.arXiv preprint arXiv:2605.28258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
GUI Agents for Continual Game Generation
doi: 10.48550/arXiv.2605.28258. Li Li, Jiashu Qu, Linxin Song, Yuxiao Zhou, Yuehan Qin, Tiankai Yang, and Yue Zhao. Treble counterfactual VLMs: A causal approach to hallucination. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 18423–184...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.28258 2025
-
[9]
Association for Computational Linguistics. ISBN 979-8-89176-335-7. doi: 10.18653/v1/2025. findings-emnlp.1000. URLhttps://aclanthology.org/2025.findings-emnlp.1000/. Yuliang Liu, Jiaxin Zhang, Dezhi Peng, Mingxin Huang, Xinyu Wang, Jingqun Tang, Can Huang, Dahua Lin, Chunhua Shen, Xiang Bai, et al. Spts v2: single-point scene text spotting.IEEE Transactio...
-
[10]
Jinghui Lu, Haiyang Yu, Yanjie Wang, Yongjie Ye, Jingqun Tang, Ziwei Yang, Binghong Wu, Qi Liu, Hao Feng, Han Wang, et al. A bounding box is worth one token: Interleaving layout and text in a large language model for document understanding.arXiv preprint arXiv:2407.01976,
-
[11]
Jinghui Lu, Haiyang Yu, Siliang Xu, Shiwei Ran, Guozhi Tang, Siqi Wang, Bin Shan, Teng Fu, Hao Feng, Jingqun Tang, et al. Prolonged reasoning is not all you need: Certainty-based adaptive routing for efficient llm/mllm reasoning.arXiv preprint arXiv:2505.15154,
-
[12]
Bin Shan, Xiang Fei, Wei Shi, An-Lan Wang, Guozhi Tang, Lei Liao, Jingqun Tang, Xiang Bai, and Can Huang. Mctbench: Multimodal cognition towards text-rich visual scenes benchmark.arXiv preprint arXiv:2410.11538,
-
[13]
Shanghai AI Lab, Yicheng Bao, Guanxu Chen, Mingkang Chen, Yunhao Chen, Chiyu Chen, Lingjie Chen, Sirui Chen, Xinquan Chen, Jie Cheng, Yu Cheng, Dengke Deng, Yizhuo Ding, Dan Ding, Xiaoshan Ding, Yi Ding, Zhichen Dong, Lingxiao Du, Yuyu Fan, Xinshun Feng, Yanwei Fu, Yuxuan Gao, Ruijun Ge, Tianle Gu, Lujun Gui, Jiaxuan Guo, Qianxi He, Yuenan Hou, Xuhao Hu, ...
-
[14]
doi: 10.48550/arXiv.2507.18576. URL https://arxiv.org/abs/2507.18576. Wenhao Sun, Xue-Mei Dong, Benlei Cui, and Jingqun Tang. Attentive eraser: Unleashing diffusion model’s object removal potential via self-attention redirection guidance. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20734–20742,
-
[15]
Jingqun Tang, Wenming Qian, Luchuan Song, Xiena Dong, Lan Li, and Xiang Bai. Optimal boxes: boosting end-to-end scene text recognition by adjusting annotated bounding boxes via reinforcement learning. InEuropean Conference on Computer Vision, pages 233–248. Springer, 2022a. Jingqun Tang, Su Qiao, Benlei Cui, Yuhang Ma, Sheng Zhang, and Dimitrios Kanoulas....
-
[16]
Textsquare: Scaling up text-centric visual instruction tuning.arXiv preprint arXiv:2404.12803, 2024a
Jingqun Tang, Chunhui Lin, Zhen Zhao, Shu Wei, Binghong Wu, Qi Liu, Hao Feng, Yang Li, Siqi Wang, Lei Liao, et al. Textsquare: Scaling up text-centric visual instruction tuning.arXiv preprint arXiv:2404.12803, 2024a. Jingqun Tang, Qi Liu, Yongjie Ye, Jinghui Lu, Shu Wei, Chunhui Lin, Wanqing Li, Mohamad Fitri Faiz Bin Mahmood, Hao Feng, Zhen Zhao, et al. ...
-
[17]
MemMark: State-Evolution Attribution Watermarking for Agent Long-Term Memory Systems
Haobo Zhang, Xutao Mao, Guangyuan Dong, Ziwei Li, Xuanbo Su, Kaijie Chen, Jing Yang, and Zheng Lin. Memmark: State-evolution attribution watermarking for agent long-term memory systems.arXiv preprint arXiv:2605.25002,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Qinjian Zhao, Zhihao Dou, Dinggen Zhang, Xiangyu Li, Chaoda Song, Zhongwei Wan, Xinpeng Li, Yanyan Zhang, Kaijie Chen, Qingtao Pan, et al. Stride: Strategic trajectory reasoning via discriminative estimation for verifiable reinforcement learning.arXiv preprint arXiv:2606.15866,
-
[19]
Multi-modal in-context learning makes an ego-evolving scene text recognizer
Zhen Zhao, Jingqun Tang, Chunhui Lin, Binghong Wu, Can Huang, Hao Liu, Xin Tan, Zhizhong Zhang, and Yuan Xie. Multi-modal in-context learning makes an ego-evolving scene text recognizer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15567–15576, 2024a. Zhen Zhao, Jingqun Tang, Binghong Wu, Chunhui Lin, Shu Wei,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.