MemMark: State-Evolution Attribution Watermarking for Agent Long-Term Memory Systems
Pith reviewed 2026-06-30 00:01 UTC · model grok-4.3
The pith
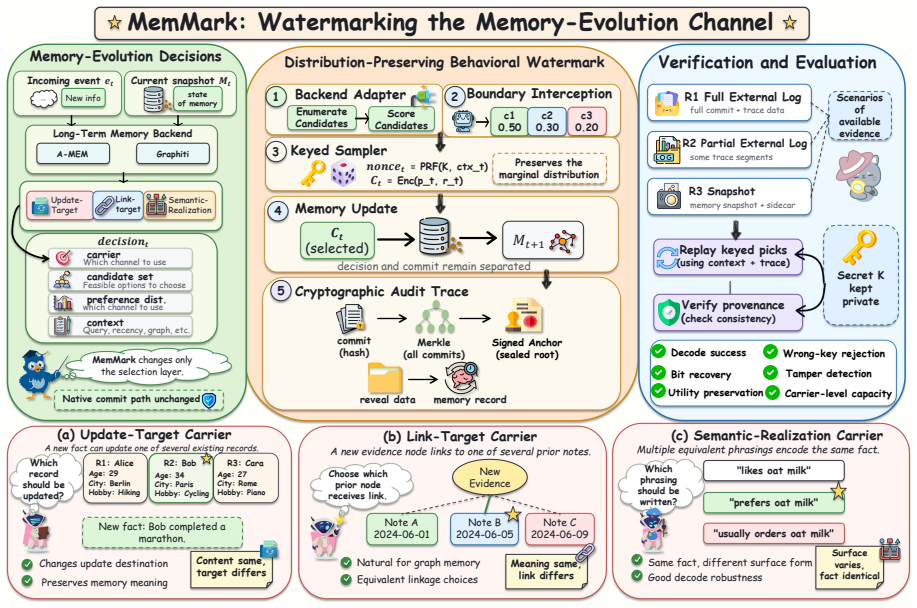
MemMark embeds owner signals into agent memory updates via keyed sampling of LLM decisions to enable attribution from final snapshots alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
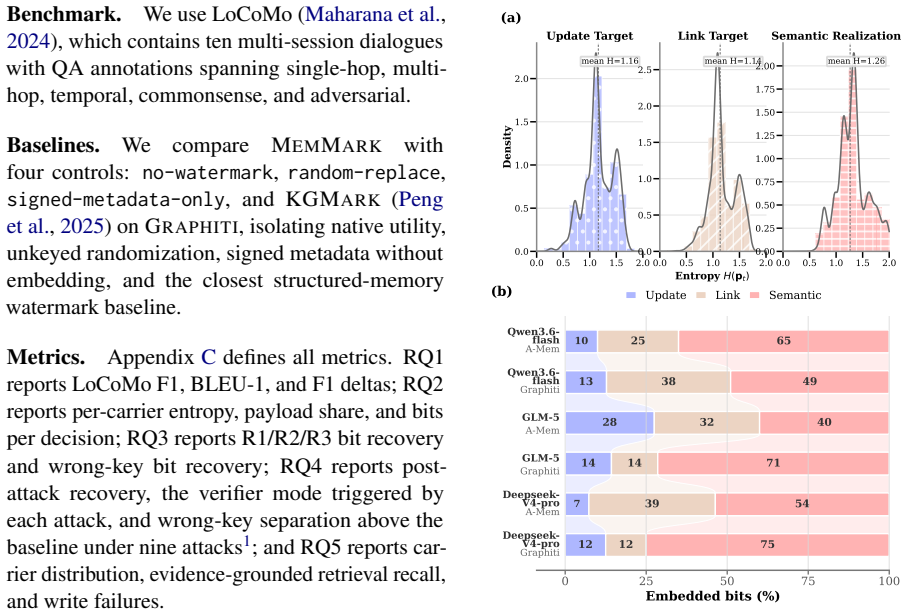
By sampling among admissible memory-write candidates at each internal LLM call using keyed, distribution-preserving selection and anchoring the choices with signed session commitments, MemMark makes the final memory snapshot sufficient to recover a 40-bit owner payload across tested systems while leaving overall F1 at 99.6 percent of the baseline and producing 1.14 to 1.26 bits of mean entropy per decision type.
What carries the argument
Keyed distribution-preserving selection among admissible memory-write candidates at each LLM call, together with cryptographic commitments and session anchors.
If this is right
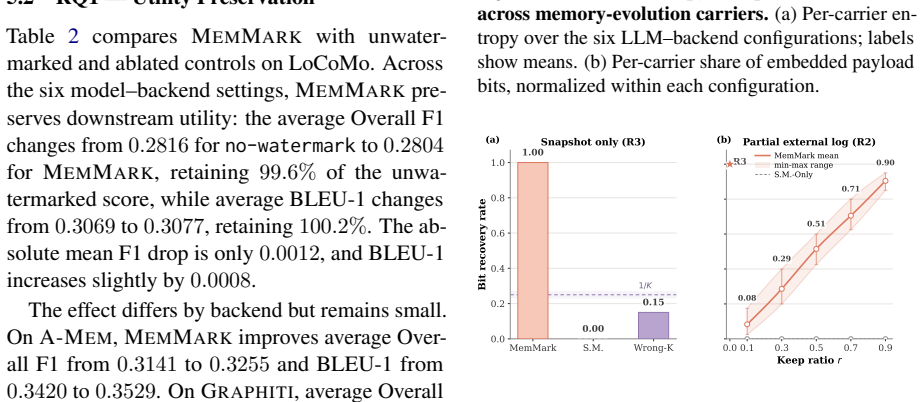
- Memory utility measured by F1 and BLEU-1 stays within 0.4 percent of the unwatermarked baseline on A-Mem and Graphiti.
- Full 40-bit payload recovery succeeds from final snapshots in the R3 setting with three different LLM backbones.
- Verification under nine memory-lifecycle attacks separates tampering, evidence deletion, and partial recovery cases.
- Each of update-target, link-target, and semantic-realization decisions supplies roughly one bit of carrier capacity on average.
Where Pith is reading between the lines
- The same keyed-selection pattern could be applied to other internal agent decisions such as tool choice or planning steps.
- If the underlying LLM changes its sampling behavior across versions or temperature settings, the reproducibility assumption would need re-checking for each deployment.
- The method could be layered with output-level watermarks to create multiple independent attribution channels inside one agent.
Load-bearing premise
The LLM backend must generate reproducible outputs so that the keyed choice among candidates can carry the signal without shifting the original output distribution or harming later memory use.
What would settle it
A run of identical prompt sequences with the watermark key in which the final snapshot either fails to recover the correct 40-bit payload or allows a wrong key to verify above chance level.
Figures

read the original abstract
Memory-backed agents need provenance that can survive leaked or migrated snapshots, where logs, visible outputs, and trusted metadata may be absent. We propose MemMark, a state-evolution attribution watermark that embeds an owner-controlled signal into latent memory-write decisions. At each internal LLM call, MemMark samples among admissible candidates using keyed, distribution-preserving selection, and records cryptographic commitments with signed session anchors and reveal evidence. This makes attribution depend on reproducible backend behavior rather than mutable provenance fields. Across A-Mem and Graphiti on LoCoMo, with three LLM backbones, MemMark preserves memory utility: Overall F1 retains 99.6% of the unwatermarked baseline, while BLEU-1 changes by +0.2%. It also provides usable carrier capacity, with 1.16, 1.14, and 1.26 bits of mean entropy for update-target, link-target, and semantic-realization decisions. In the snapshot-only R3 setting, MemMark recovers the full 40-bit payload from final snapshots, while wrong-key verification remains near chance. Under nine memory-lifecycle attacks, verification distinguishes tampering, evidence deletion, and partial payload recovery. These results show that robust snapshot-only attribution is feasible for long-term agent memory without surviving traces, trusted metadata, or utility-degrading.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemMark, a state-evolution attribution watermark for long-term agent memory systems. It embeds an owner-controlled signal into latent memory-write decisions via keyed, distribution-preserving sampling among admissible LLM candidates at each internal call, augmented by cryptographic commitments and signed session anchors. Experiments on A-Mem and Graphiti using the LoCoMo dataset across three LLM backbones report 99.6% retention of unwatermarked F1, minor BLEU changes, mean entropies of 1.16–1.26 bits per decision type, full 40-bit payload recovery from final snapshots under the owner key (near-chance for wrong keys), and distinction among nine memory-lifecycle attacks in the snapshot-only R3 setting. The central claim is that robust attribution is feasible without surviving traces, trusted metadata, or utility degradation.
Significance. If the core reproducibility assumption holds, the work demonstrates a practical mechanism for provenance in migrated or leaked agent memory snapshots that does not rely on mutable logs or external metadata. The multi-backbone empirical evaluation and attack robustness testing provide concrete evidence of feasibility for this snapshot-only regime, which addresses a gap in agent security where conventional provenance fails.
major comments (3)
- [Abstract, §4] Abstract and §4 (empirical evaluation): The reported 99.6% F1 retention, 40-bit recovery, and entropy values are presented without error bars, exclusion criteria, or explicit verification that the keyed sampling exactly preserves the marginal output distribution; this leaves open whether results depend on post-hoc admissible-candidate definitions or specific temperature settings.
- [§3] §3 (method): No equations or formal derivation is supplied showing that the keyed selection rule among admissible candidates is invariant to model updates, inference-engine changes, or non-zero temperature sampling, which is load-bearing for the claim that attribution depends solely on reproducible backend behavior without surviving traces.
- [§5] §5 (attack evaluation): The distinction among tampering, evidence deletion, and partial recovery under the nine attacks is shown empirically, but the manuscript does not provide a formal argument that the cryptographic commitments remain sound when the underlying LLM sampling distribution shifts.
minor comments (2)
- [§3] Notation for the three decision types (update-target, link-target, semantic-realization) is introduced without a consolidated table mapping them to the memory structures in A-Mem vs. Graphiti.
- [Abstract] The abstract states 'wrong-key verification remains near chance' but does not report the exact false-positive rate or number of trials used to establish this baseline.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We address each of the major comments in detail below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (empirical evaluation): The reported 99.6% F1 retention, 40-bit recovery, and entropy values are presented without error bars, exclusion criteria, or explicit verification that the keyed sampling exactly preserves the marginal output distribution; this leaves open whether results depend on post-hoc admissible-candidate definitions or specific temperature settings.
Authors: We agree with the referee that additional statistical rigor would strengthen the empirical claims. In the revised manuscript, we will add error bars to the reported metrics based on repeated experiments, detail the exclusion criteria applied to the LoCoMo dataset, and include explicit verification (e.g., via distribution comparison tests) that the keyed sampling preserves the marginal output distribution. We will also document the temperature settings and admissible candidate selection process to confirm independence from post-hoc definitions. revision: yes
-
Referee: [§3] §3 (method): No equations or formal derivation is supplied showing that the keyed selection rule among admissible candidates is invariant to model updates, inference-engine changes, or non-zero temperature sampling, which is load-bearing for the claim that attribution depends solely on reproducible backend behavior without surviving traces.
Authors: The selection rule is intended to be reproducible given the same LLM backend and parameters. We will revise §3 to include equations defining the keyed selection process and a derivation showing determinism under fixed model and sampling conditions (including non-zero temperature). However, we do not claim or derive invariance to arbitrary model updates or inference-engine changes, as these alter the distribution fundamentally; we will clarify this assumption and its implications for the attribution claim. revision: partial
-
Referee: [§5] §5 (attack evaluation): The distinction among tampering, evidence deletion, and partial recovery under the nine attacks is shown empirically, but the manuscript does not provide a formal argument that the cryptographic commitments remain sound when the underlying LLM sampling distribution shifts.
Authors: Our evaluation demonstrates empirical robustness under the specified attacks. We will add to the revised manuscript a discussion of the security assumptions, including that commitments are verified against the original sampling behavior. A formal argument for soundness under arbitrary distribution shifts is not provided, as it would depend on properties of the LLM not generally guaranteed; we will note this as a limitation and direction for future theoretical analysis. revision: partial
- A complete formal derivation proving invariance of the selection rule to model updates and inference changes
- A formal cryptographic argument ensuring soundness of commitments under shifts in LLM sampling distributions
Circularity Check
No circularity in claimed derivation or results
full rationale
The paper presents an empirical watermarking technique relying on keyed sampling among admissible LLM candidates, with performance evaluated experimentally on specific datasets and backbones. No equations, first-principles derivations, predictions, or fitted parameters are described that reduce to the method's own inputs by construction. Attribution and utility claims are supported by reported recovery rates and F1 scores rather than self-referential definitions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
DAIN: Dynamic Agent-Based Interaction Network for Efficient and Collaborative Multimodal Reasoning
DAIN reframes multimodal fusion as dynamic agent collaboration with sparse activation, claiming SOTA results including 2.6% accuracy gain on ADNI across five benchmarks.
-
ProHiFlo: Hierarchical Flow Matching with Functional Guidance for De Novo Protein Generation
ProHiFlo introduces hierarchical coarse-to-fine flow matching with functional guidance from pretrained predictors and an adaptive SE(3)-equivariant architecture, reporting higher success rates and fewer sampling steps...
-
EVLA: An Electro-Aware Multimodal Assistant for Physically-Grounded Driving Reasoning and Control
EVLA combines a Unified Co-State Encoder and Electro-aware Structured Reasoning Chain with physics-guided training to produce energy-optimal driving decisions, reporting +5.6% accuracy gains over fine-tuned VLM baseli...
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413. Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po- Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering.Preprint, arXiv:2602.15763. Tsvetomir Hristov, Devri¸ s˙I¸ sler, Nikolaos Laoutaris, and Zekeriya Erkin
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Eval- uating memory in llm agents via incremental multi- turn interactions.arXiv preprint arXiv:2507.05257. Kaibo Huang, Jin Tan, Yukun Wei, Wanling Li, Zipei Zhang, Hui Tian, Zhongliang Yang, and Linna Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
AgentMark: Utility-Preserving Behavioral Watermarking for Agents
Agentmark: Utility-preserving be- havioral watermarking for agents.arXiv preprint arXiv:2601.03294. Kaibo Huang, Zhongliang Yang, and Linna Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Agent Guide: A Simple Agent Behavioral Watermarking Framework
Agent guide: A simple agent behavioral watermark- ing framework.arXiv preprint arXiv:2504.05871. Nikola Jovanovi´c, Robin Staab, Maximilian Baader, and Martin Vechev
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
InInternational Con- ference on Learning Representations, volume 2025, pages 93288–93314
Ward: Provable rag dataset inference via llm watermarks. InInternational Con- ference on Learning Representations, volume 2025, pages 93288–93314. John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein
2025
-
[7]
MemOS : An operating system for memory-augmented generation
Memos: An operating system for memory-augmented genera- tion (mag) in large language models.arXiv preprint arXiv:2505.22101. Zehao Lin, Chunyu Li, and Kai Chen
-
[8]
A survey on the security of long-term memory in llm agents: Toward mnemonic sovereignty.arXiv preprint arXiv:2604.16548. Yepeng Liu, Xuandong Zhao, Dawn Song, and Yuheng Bu
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Dataset protection via watermarked ca- naries in retrieval-augmented llms.arXiv preprint arXiv:2502.10673. Peizhuo Lv, Mengjie Sun, Hao Wang, Xiaofeng Wang, Shengzhi Zhang, Yuxuan Chen, Kai Chen, and Limin Sun
-
[10]
InProceedings of the 2025 ACM SIGSAC Conference on Computer and Commu- nications Security, pages 1709–1723
Rag-wm: An efficient black-box water- marking approach for retrieval-augmented generation of large language models. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Commu- nications Security, pages 1709–1723. Xingjun Ma, Yifeng Gao, Yixu Wang, Ruofan Wang, Xin Wang, and 1 others
2025
-
[11]
Safety at Scale: A Comprehensive Survey of Large Model and Agent Safety
Safety at scale: A comprehensive survey of large model and agent safety.arXiv preprint arXiv:2502.05206. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Watermarking llm agent trajectories.arXiv preprint arXiv:2602.18700. Ralph C. Merkle
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 61–71
Mark- llm: An open-source toolkit for llm watermarking. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 61–71. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein
2024
-
[14]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Zep: a tempo- ral knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956. Saksham Sahai Srivastava and Haoyu He
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Haoran Sun, Zekun Zhang, and Shaoning Zeng
Mem- orygraft: Persistent compromise of llm agents via poisoned experience retrieval.arXiv preprint arXiv:2512.16962. Haoran Sun, Zekun Zhang, and Shaoning Zeng
-
[16]
Liwen Wang, Zongjie Li, Yuchong Xie, Shuai Wang, Dongdong She, Wei Wang, and Juergen Rahmel
Preference-aware memory update for long-term llm agents.arXiv preprint arXiv:2510.09720. Liwen Wang, Zongjie Li, Yuchong Xie, Shuai Wang, Dongdong She, Wei Wang, and Juergen Rahmel. 2026a. On protecting agentic systems’ intellec- tual property via watermarking.arXiv preprint arXiv:2602.08401. Shu Wang, Edwin Yu, Oscar Love, Tom Zhang, Tom Wong, Steve Scar...
-
[17]
A-memguard: A proactive defense framework for llm-based agent memory.arXiv preprint arXiv:2510.02373. Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
-
[18]
Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828. Guilin Zhang, Wei Jiang, Xiejiashan Wang, Aisha Behr, Kai Zhao, Jeffrey Friedman, Xu Chu, and Amine Anoun
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang
Adaptive memory admission control for llm agents.arXiv preprint arXiv:2603.04549. Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang
-
[20]
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Memory as ac- tion: Autonomous context curation for long-horizon agentic tasks.arXiv preprint arXiv:2510.12635. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye Wang, and Yanlin Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
From lossy to verified: A provenance-aware tiered memory for agents.arXiv preprint arXiv:2602.17913. A Experiment Details A.1 Data Statistics We evaluate on the public LoCoMo benchmark, using the same fixed set of ten long-term multi- session conversations for all main model–backend configurations. This fixed-conversation protocol ensures that comparisons...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.