Resolving superposition in AI for interpretability and cross-modal alignment in patient-neuronal images
Pith reviewed 2026-07-01 06:56 UTC · model grok-4.3
The pith
Sparse autoencoders resolve superposition to restore geometric fidelity in neuronal image representations and enable de novo alignment with scRNA-seq data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
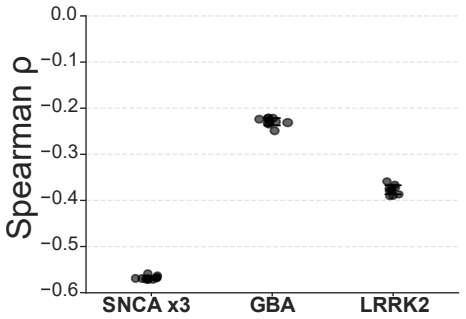
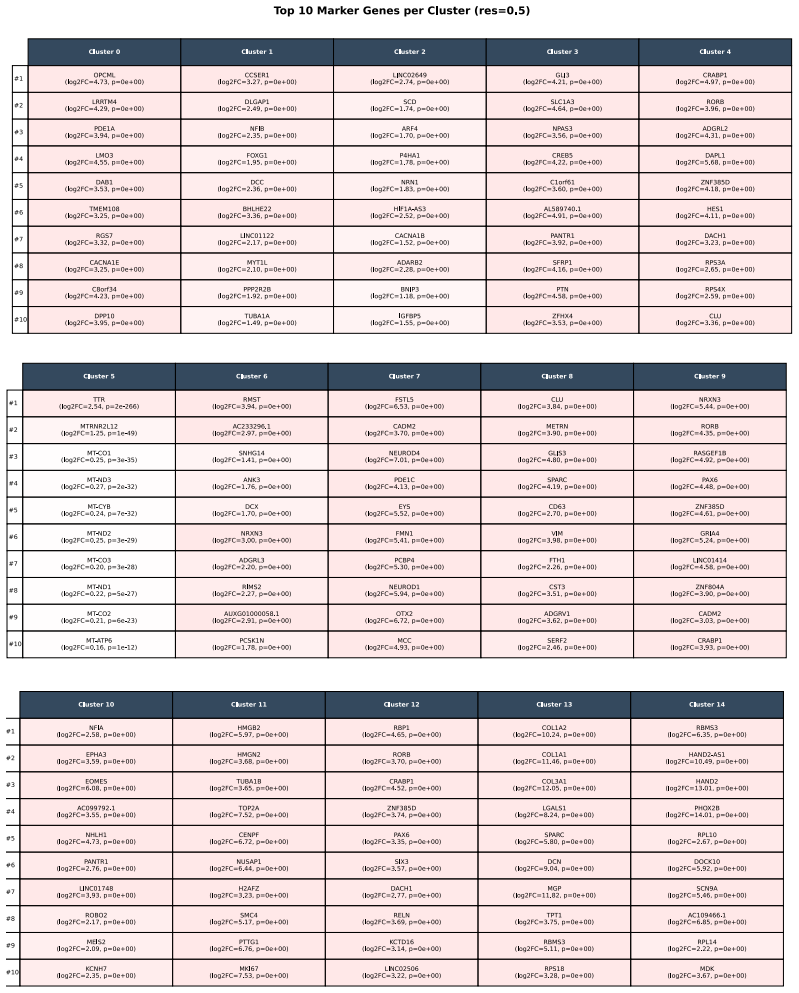
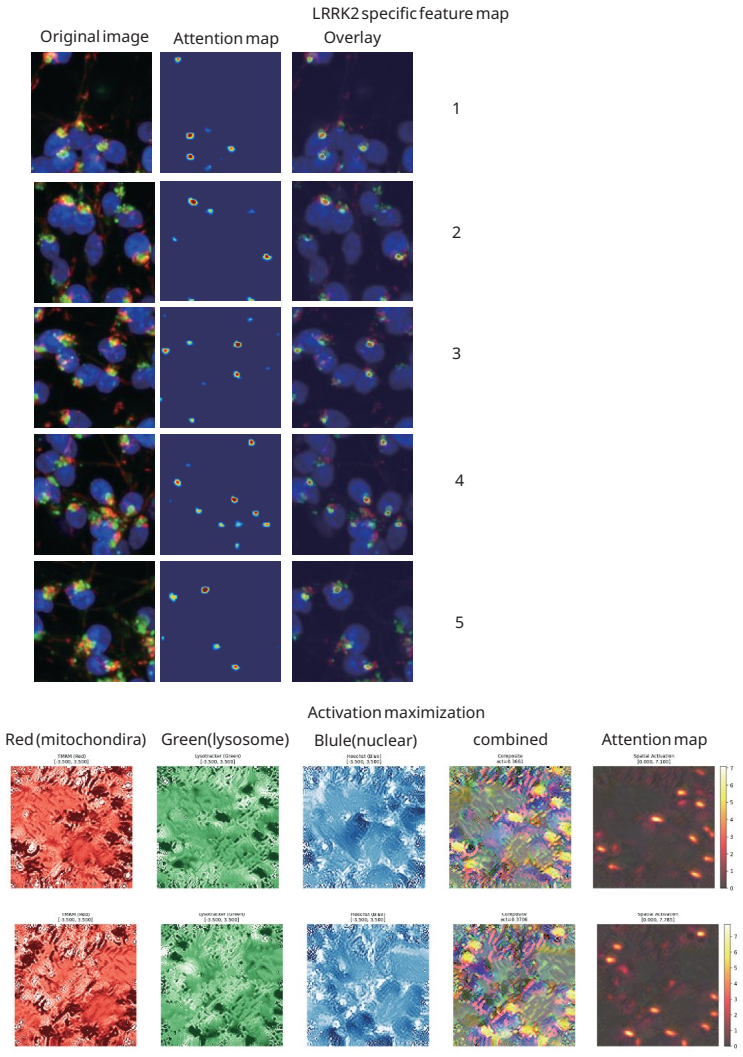
Superposition contaminates representational metric spaces in networks trained on neuronal images; sparse autoencoders trained on over 100,000 patient-derived images recover geometric fidelity. Treating these representations as state vectors allows direct application of single-cell RNA sequencing methodologies to the image domain. Gromov-Wasserstein optimal transport then aligns the image representations with scRNA-seq data de novo, reconstructing hierarchical neuronal pathology pathways such as the Calcium-AIS scaffold without reference spatial transcriptomics.
What carries the argument
Sparse autoencoders that disentangle superimposed features to restore metric accuracy in latent spaces, followed by Gromov-Wasserstein maps for cross-modal alignment.
If this is right
- Interpretable latent representation analysis bypasses the mathematical non-uniqueness of feature attribution.
- Single-cell RNA sequencing methodologies transfer directly to the image domain.
- Hierarchical neuronal pathology pathways can be reconstructed without reference spatial transcriptomics.
- A scalable foundation for spatial biology is established through aligned image and transcriptomic representations.
Where Pith is reading between the lines
- The same superposition-resolution step could be tested on other high-dimensional imaging modalities such as multiplexed tissue sections from additional diseases.
- If the de novo alignment proves robust, image-only models might identify spatial expression patterns in contexts where spatial transcriptomics data are unavailable.
- Independent biological validation assays on the reconstructed pathways would be required to confirm that recovered features remain free of SAE-induced artifacts.
Load-bearing premise
Superposition is the dominant source of metric distortion in the original representations, and sparse autoencoder training removes it without introducing new non-biological artifacts or selection biases.
What would settle it
A direct comparison in which metric distances computed after SAE processing fail to better match known biological distances or pathway hierarchies than distances from the original superimposed representations.
Figures
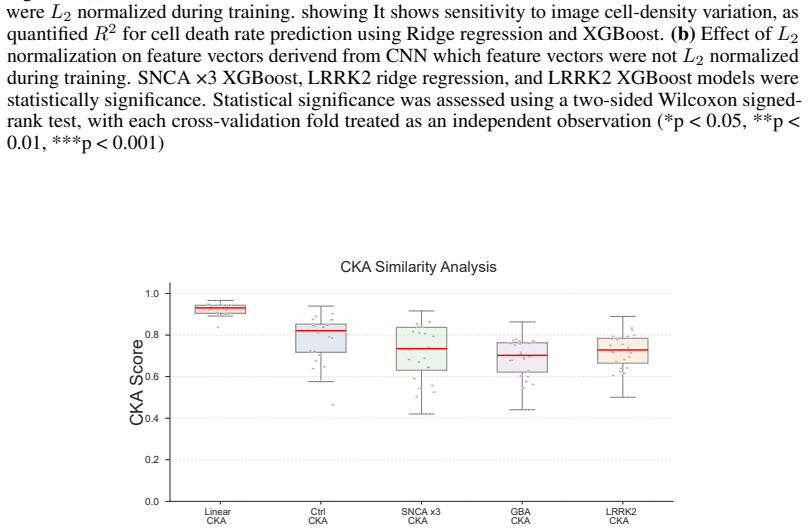
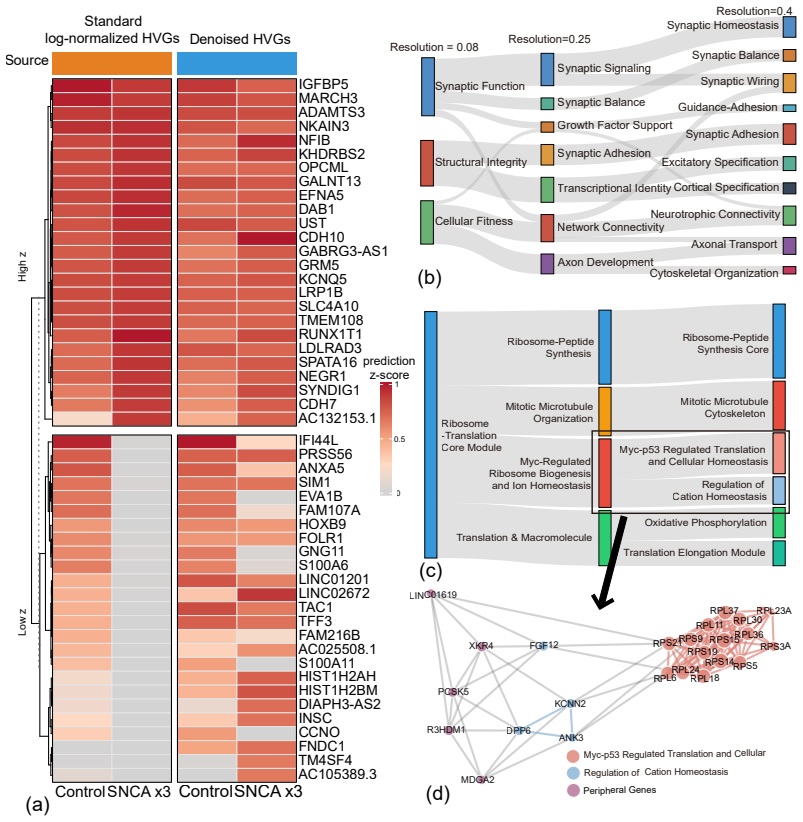
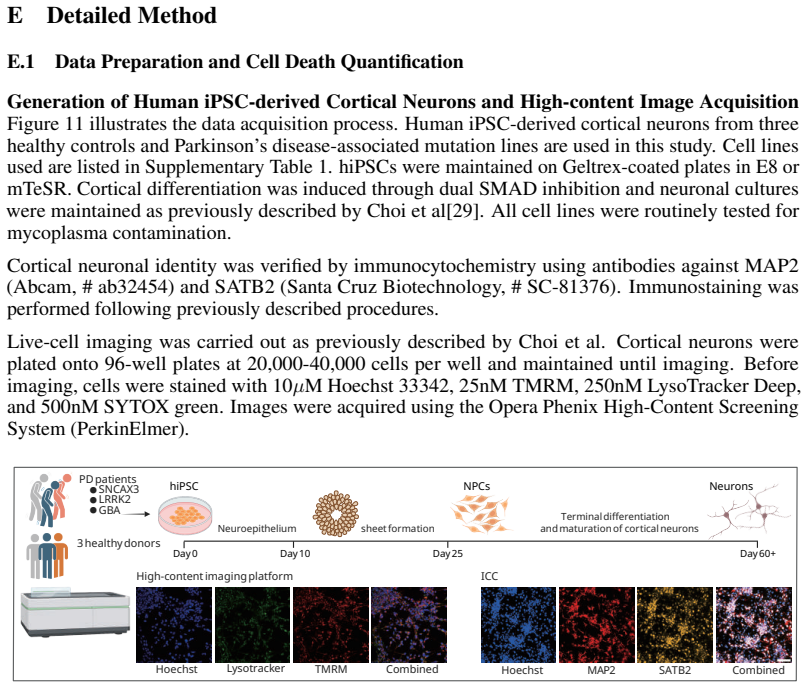

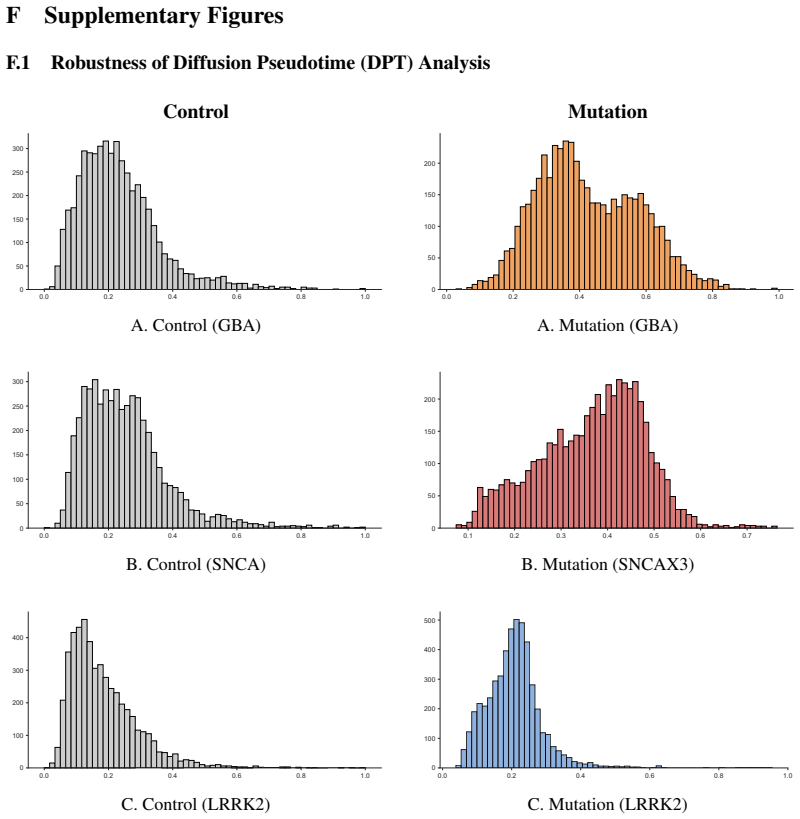

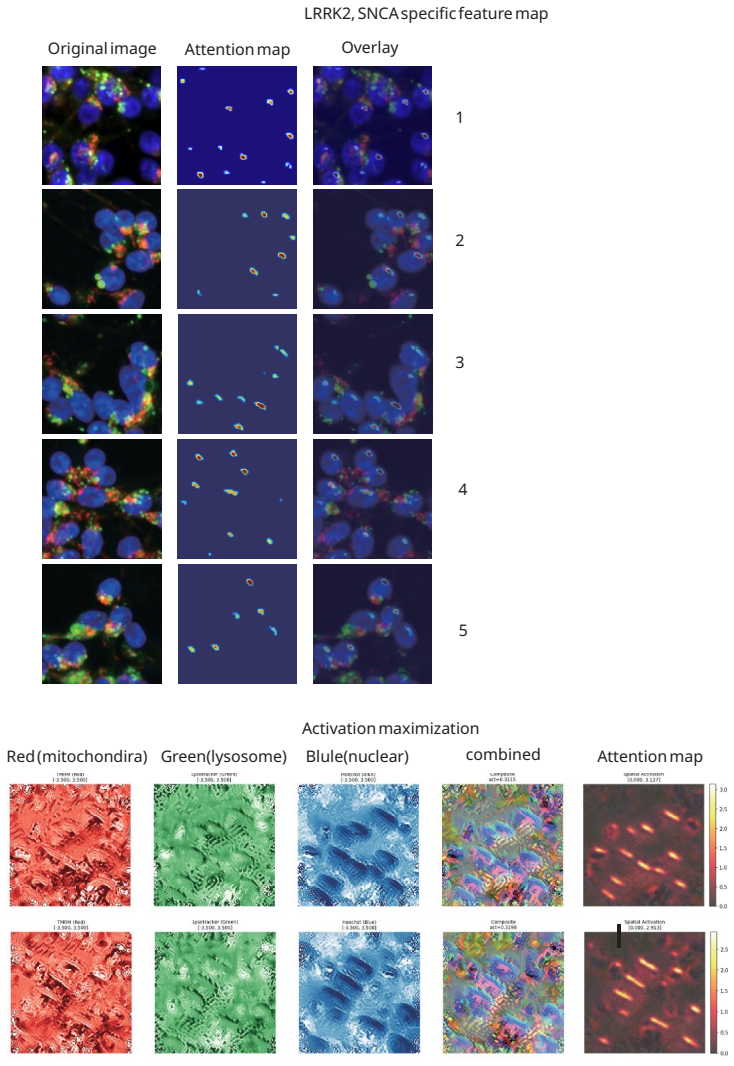
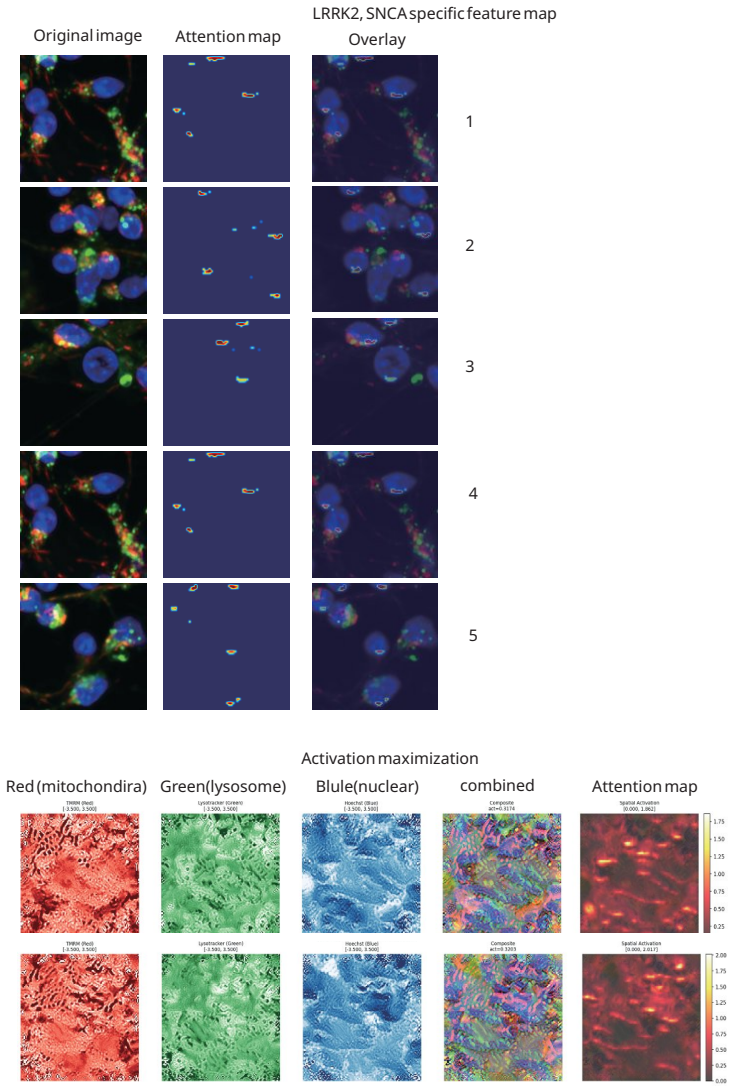
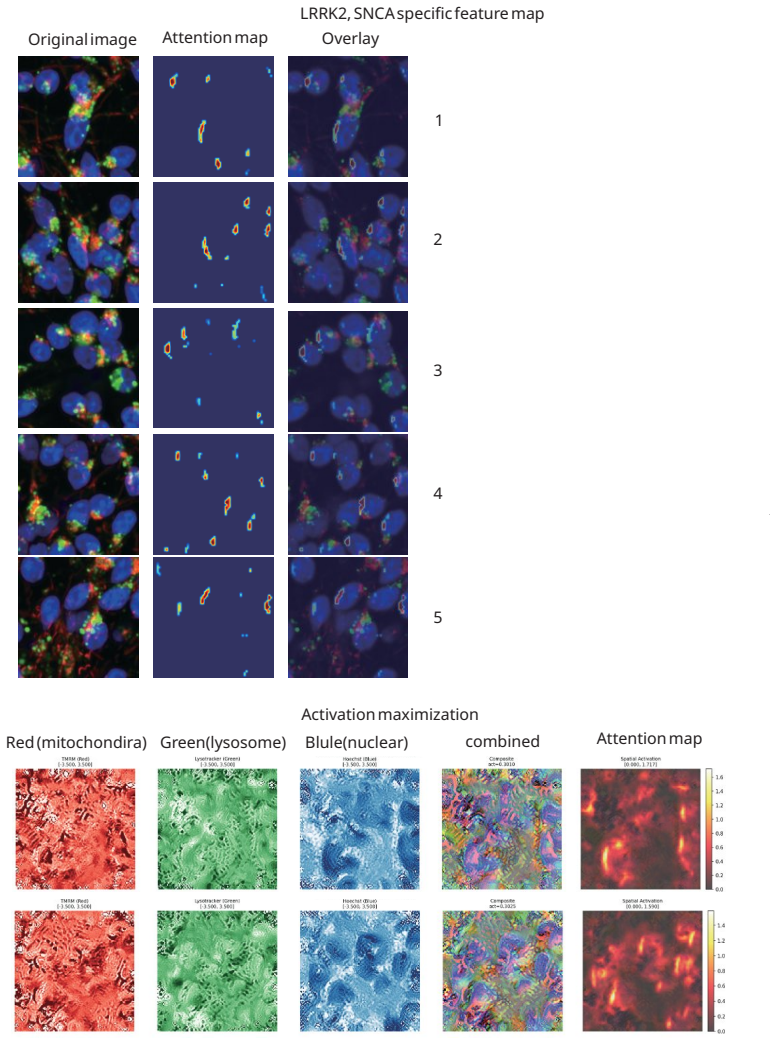
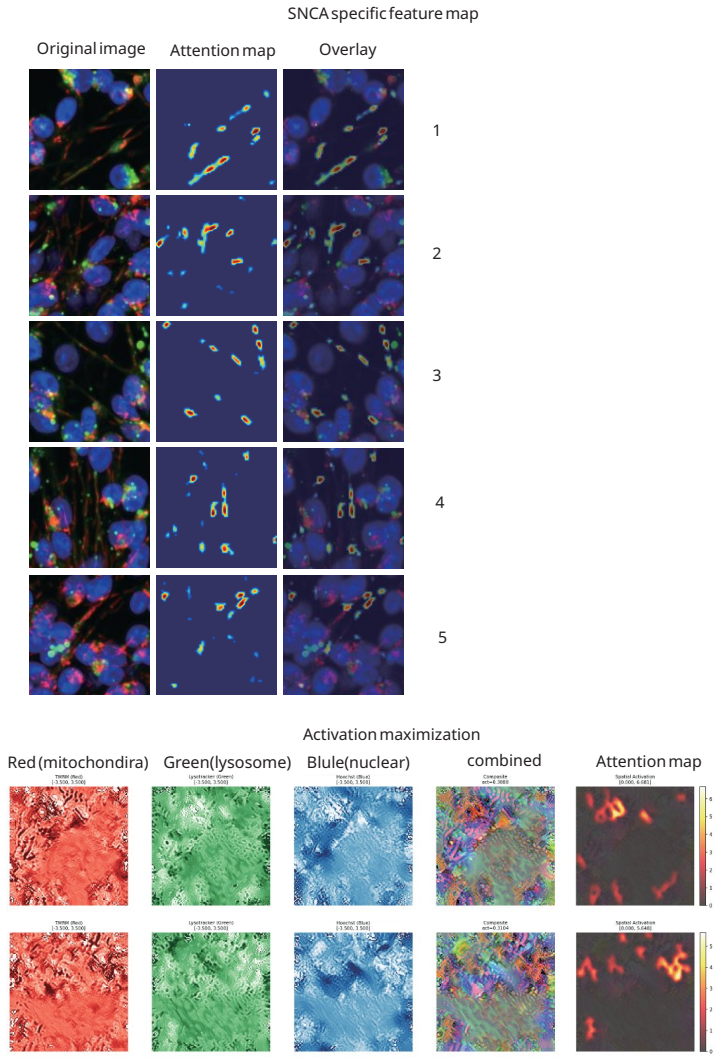
read the original abstract
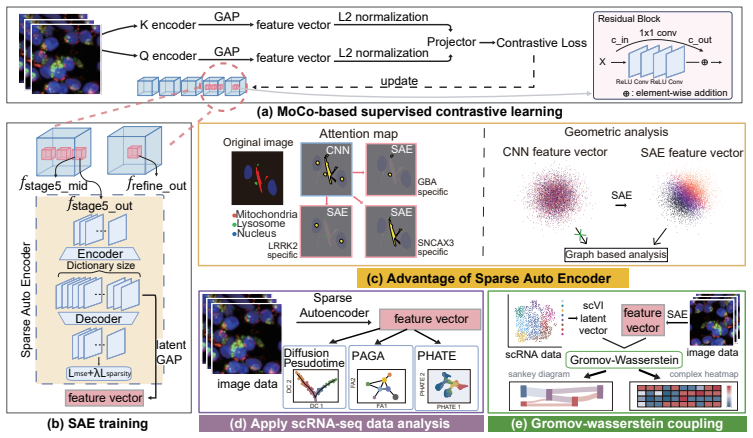
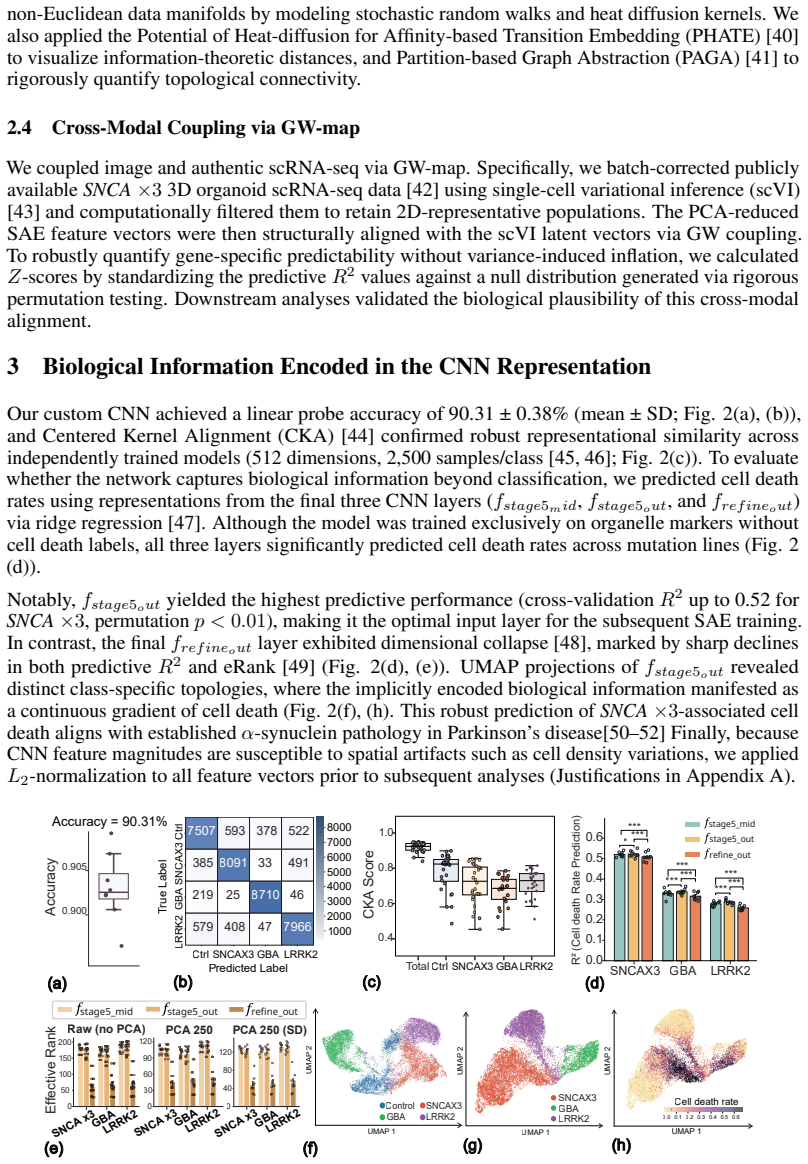
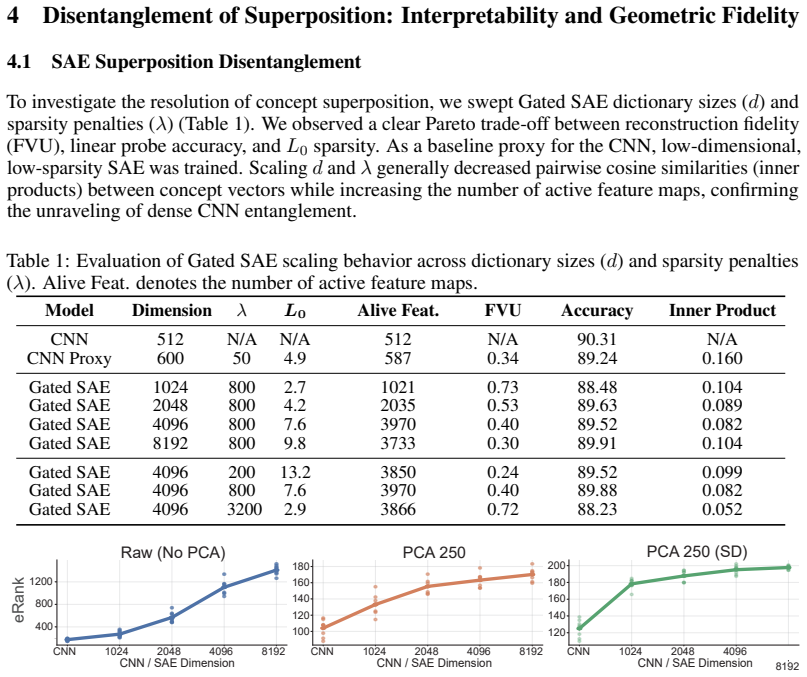
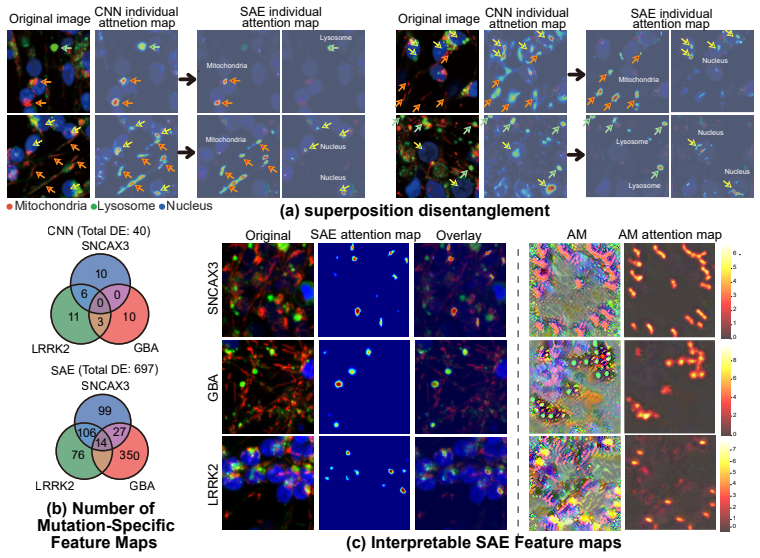
Artificial intelligence is transforming our capability to solve biological challenges. In dimensionality bottleneck regimes exacerbated by high-dimensional biological data, Neural networks force distinct concepts into the lower dimensions known as superposition. Although this superposition is widely known to hinder interpretability, its impact on corrupting the geometry of latent spaces remains critically overlooked. Here, we utilized sparse autoencoders (SAEs) trained on over 100,000 multiplexed images of patient-derived Parkinson's disease and healthy neurons to resolve superposition. This approach bypasses the mathematical non-uniqueness of feature attribution by shifting to interpretable latent representation analysis. We theoretically and empirically demonstrate that superposition contaminates representational metric spaces, and thereby SAEs successfully recover geometric fidelity. By treating these geometrically purified representations as single-cell state vectors, we adapted single-cell RNA sequencing (scRNA-seq) data analysis methodologies directly to the image domain. Finally, we introduce GW-map, utilizing Gromov-Wasserstein optimal transport to align these image representations with authentic scRNA-seq data \emph{de novo}. This coupling reconstructs hierarchical neuronal pathology pathways such as Calcium-AIS scaffold, without reference spatial transcriptomics, establishing a scalable foundation for spatial biology. Code is available at https://github.com/jijihihi/Bio_superposition
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that superposition in neural networks trained on high-dimensional multiplexed neuronal images (from Parkinson's and healthy patient-derived cells) corrupts the geometry of latent metric spaces. It asserts that sparse autoencoders (SAEs) trained on >100k images resolve this superposition, recovering geometric fidelity. The purified latents are then treated as single-cell state vectors to directly adapt scRNA-seq analysis pipelines to the image domain. Finally, a Gromov-Wasserstein optimal transport method (GW-map) is introduced to align the image representations with authentic scRNA-seq data de novo, enabling reconstruction of hierarchical neuronal pathology pathways such as the Calcium-AIS scaffold without any reference spatial transcriptomics data. Code is provided at a GitHub link.
Significance. If the central claims were substantiated with quantitative controls and metrics, the work would be significant for AI interpretability in biological imaging and for cross-modal data integration in spatial biology. The idea of using SAEs to purify geometry for direct transfer of single-cell methods, plus the code release, would represent a concrete contribution. However, the current manuscript provides no equations, ablation studies, or fidelity metrics to support the theoretical or empirical assertions.
major comments (3)
- [Abstract] Abstract: The assertion of a 'theoretical and empirical demonstration' that superposition contaminates representational metric spaces is unsupported; no equations, derivations, or distance metrics (e.g., Procrustes or Gromov-Hausdorff) are shown to quantify the claimed contamination or its resolution by SAEs.
- [Abstract] Abstract and approach description: The claim that SAEs recover geometric fidelity (enabling scRNA-seq method transfer and GW-map reconstruction of pathways like Calcium-AIS) lacks any quantitative evidence, controls, or ablations. No metrics demonstrate improvement attributable to superposition resolution versus generic denoising, imaging noise, or batch effects; no held-out biological distance benchmarks are reported.
- [Abstract] Abstract: The weakest assumption—that superposition is the dominant distortion mechanism and that SAE training removes it without introducing non-biological artifacts or selection biases—is not tested. No experiments isolate superposition from other sources of metric distortion in the original network latents.
minor comments (2)
- The manuscript would benefit from explicit statements of the network architecture, SAE hyperparameters, and training details to allow reproducibility beyond the GitHub link.
- Notation for the GW-map alignment and how image latents are converted to 'single-cell state vectors' should be clarified for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their constructive critique, which identifies key areas where the manuscript's claims require stronger quantitative and theoretical grounding. We agree that the current version lacks sufficient equations, metrics, ablations, and isolation experiments, and we will revise accordingly to address each point. Our responses below outline the planned changes.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of a 'theoretical and empirical demonstration' that superposition contaminates representational metric spaces is unsupported; no equations, derivations, or distance metrics (e.g., Procrustes or Gromov-Hausdorff) are shown to quantify the claimed contamination or its resolution by SAEs.
Authors: We acknowledge that while the abstract states a theoretical and empirical demonstration, the main text does not provide the requested equations or distance metrics. In the revision we will add a new theoretical subsection deriving the effect of superposition on latent metric spaces (including explicit distortion bounds) and report Procrustes and Gromov-Hausdorff distances computed on held-out image sets before and after SAE training. revision: yes
-
Referee: [Abstract] Abstract and approach description: The claim that SAEs recover geometric fidelity (enabling scRNA-seq method transfer and GW-map reconstruction of pathways like Calcium-AIS) lacks any quantitative evidence, controls, or ablations. No metrics demonstrate improvement attributable to superposition resolution versus generic denoising, imaging noise, or batch effects; no held-out biological distance benchmarks are reported.
Authors: The referee correctly notes the absence of these controls. The revised manuscript will include (i) ablation tables comparing SAE latents against standard autoencoders, denoising autoencoders, and raw network latents on reconstruction fidelity and downstream pathway reconstruction accuracy; (ii) metrics isolating superposition effects from batch and noise artifacts; and (iii) held-out biological distance benchmarks derived from known neuronal marker correlations. revision: yes
-
Referee: [Abstract] Abstract: The weakest assumption—that superposition is the dominant distortion mechanism and that SAE training removes it without introducing non-biological artifacts or selection biases—is not tested. No experiments isolate superposition from other sources of metric distortion in the original network latents.
Authors: We agree this isolation is necessary. We will add controlled experiments that vary superposition strength (via changes in network width and sparsity regularization) while holding other factors fixed, and we will report checks for SAE-induced artifacts via comparison to ground-truth biological annotations and sensitivity analyses for selection bias. revision: yes
Circularity Check
No circularity: derivation is self-contained method application
full rationale
The provided abstract and context describe applying SAEs to neuronal image data to resolve superposition, followed by empirical demonstration of geometric recovery and adaptation of scRNA-seq methods via GW-map. No equations, self-citations, or derivations are shown that reduce the central claims (e.g., superposition contaminating metrics or SAEs recovering fidelity) to the inputs by construction. The approach is presented as a forward method with external code link, without load-bearing self-referential steps matching any enumerated pattern. This is the expected non-finding for a methods paper whose validation rests on data application rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 618–626, 2017
2017
-
[2]
A Unified Approach to Interpreting Model Predictions
Scott M Lundberg and Su-In Lee. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL
2017
-
[3]
Apoorva Aravindkumar, Marimuthu Ramadoss, Saqhibuddeen Ahmed Fakhruddin Ahmed, Vidhya Sampath, and Kishor Lakshminarayanan. Explainable AI in healthcare: a systematic review of XAI use cases in imaging, diagnostics, and rehabilitation.Frontiers in Artificial Intelligence, 9, April 2026. ISSN 2624-8212. doi: 10.3389/frai.2026.1749527. URL
-
[4]
Zhongliang Zhou, Mengxuan Hu, Mariah Salcedo, Nathan Gravel, Wayland Yeung, Aarya Venkat, Dongliang Guo, Jielu Zhang, Natarajan Kannan, and Sheng Li. XAI meets Biology: A Comprehensive Review of Explainable AI in Bioinformatics Applications, December 2023. URL . arXiv:2312.06082 [cs]
-
[5]
The Many Shapley Values for Model Explanation
Mukund Sundararajan and Amir Najmi. The Many Shapley Values for Model Explanation. InProceedings of the 37th International Conference on Machine Learning, pages 9269–9278. PMLR, November 2020. URL
2020
-
[6]
Asymmetric Shapley values: incorporating causal knowledge into model-agnostic explainability
Christopher Frye, Colin Rowat, and Ilya Feige. Asymmetric Shapley values: incorporating causal knowledge into model-agnostic explainability. InAdvances in Neural Information Processing Systems, volume 33, pages 1229–1239. Curran Associates, Inc., 2020. URL
2020
-
[7]
Fairwashing explanations with off-manifold detergent
Christopher Anders, Plamen Pasliev, Ann-Kathrin Dombrowski, Klaus-Robert Müller, and Pan Kessel. Fairwashing explanations with off-manifold detergent. InProceedings of the 37th International Conference on Machine Learning, pages 314–323. PMLR, November 2020. URL
2020
-
[8]
The Disagreement Problem in Explainable Machine Learning: A Practitioner’s Perspective
Satyapriya Krishna, Tessa Han, Alex Gu, Steven Wu, Shahin Jabbari, and Himabindu Lakkaraju. The Disagreement Problem in Explainable Machine Learning: A Practitioner’s Perspective. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL
2024
-
[9]
Blair Bilodeau, Natasha Jaques, Pang Wei Koh, and Been Kim. Impossibility theorems for feature attribution.Proceedings of the National Academy of Sciences, 121(2):e2304406120, January 2024. doi: 10.1073/pnas.2304406120. URL . 11
-
[10]
On the failings of Shapley values for explainability
Xuanxiang Huang and Joao Marques-Silva. On the failings of Shapley values for explainability. International Journal of Approximate Reasoning, 171:109112, August 2024. ISSN 0888-613X. doi: 10.1016/j.ijar.2023.109112. URL
-
[11]
A Mathematical Framework for Transformer Circuits.Trans- former Circuits Thread, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, and Yuntao Bai. A Mathematical Framework for Transformer Circuits.Trans- former Circuits Thread, 2021. URL
2021
-
[12]
Toy Models of Superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, and Shauna Kravec. Toy Models of Superposition.Transformer Circuits Thread, 2022. URL
2022
-
[13]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, and Nicholas L Turner. Towards Monosemanticity: Decomposing Language Models With Dictionary Learning.Transformer Circuits Thread, 2023. URL
2023
-
[14]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, and Brian Chen. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Transformer Circuits Thread, 2024. URL
2024
-
[15]
This Looks Like That: Deep Learning for Interpretable Image Recognition
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This Looks Like That: Deep Learning for Interpretable Image Recognition. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL
2019
-
[16]
Concept Bottleneck Models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept Bottleneck Models. InProceedings of the 37th International Conference on Machine Learning, pages 5338–5348. PMLR, November 2020. URL
2020
-
[17]
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCA V)
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory Sayres. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCA V). InProceedings of the 35th International Conference on Machine Learning, pages 2668–2677. PMLR, July 2018. URL
2018
-
[18]
Bridging the Black Box: A Survey on Mechanistic Interpretability in AI.ACM Comput
Shriyank Somvanshi, Md Monzurul Islam, Amir Rafe, Anannya Ghosh Tusti, Arka Chakraborty, Anika Baitullah, Tausif Islam Chowdhury, Nawaf Alnawmasi, Anandi Dutta, and Subasish Das. Bridging the Black Box: A Survey on Mechanistic Interpretability in AI.ACM Comput. Surv., 58(8):210:1–210:35, February 2026. ISSN 0360-0300. doi: 10.1145/3787104. URL
-
[19]
Superposition disentanglement of neural representations reveals hidden alignment
André Longon, David Klindt, and Meenakshi Khosla. Superposition disentanglement of neural representations reveals hidden alignment. InProceedings of UniReps: the Third Edition of the Workshop on Unifying Representations in Neural Models, pages 342–359. PMLR, February
-
[20]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the International Conference on Machine Learning, volume 235 ofICML’24, pages 39643–39666, Vienna, Austria, July 2024. JMLR.org
2024
-
[21]
Ruochen Jiang, Tianyi Sun, Dongyuan Song, and Jingyi Jessica Li. Statistics or biology: the zero-inflation controversy about scRNA-seq data.Genome Biology, 23(1):31, January 2022. ISSN 1474-760X. doi: 10.1186/s13059-022-02601-5. URL
-
[22]
Binghao Chai, Christoforos Efstathiou, Haoran Yue, and Viji M. Draviam. Opportunities and challenges for deep learning in cell dynamics research.Trends in Cell Biology, 34(11):955–967, November 2024. ISSN 0962-8924, 1879-3088. doi: 10.1016/j.tcb.2023.10.010. URL
-
[23]
Caicedo, Claire McQuin, Allen Goodman, Shantanu Singh, and Anne E
Juan C. Caicedo, Claire McQuin, Allen Goodman, Shantanu Singh, and Anne E. Carpenter. Weakly Supervised Learning of Single-Cell Feature Embeddings.Proceedings. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2018:9309–9318, June 2018. ISSN 1063-6919. doi: 10.1109/CVPR.2018.00970
-
[24]
Gabriel Peyré and Marco Cuturi.Computational Optimal Transport: With Applications to Data Science, volume 11. Now Publishers, February 2019. doi: 10.1561/2200000073. URL
-
[25]
Gromov–Wasserstein Distances and the Metric Approach to Object Matching
Facundo Mémoli. Gromov–Wasserstein Distances and the Metric Approach to Object Matching. Foundations of Computational Mathematics, 11(4):417–487, August 2011. ISSN 1615-3375, 1615-3383. doi: 10.1007/s10208-011-9093-5. URL
-
[26]
SCOT: Single-Cell Multi-Omics Alignment with Optimal Transport.Journal of Com- putational Biology: A Journal of Computational Molecular Cell Biology, 29(1):3–18, January
Pinar Demetci, Rebecca Santorella, Björn Sandstede, William Stafford Noble, and Ritambhara Singh. SCOT: Single-Cell Multi-Omics Alignment with Optimal Transport.Journal of Com- putational Biology: A Journal of Computational Molecular Cell Biology, 29(1):3–18, January
-
[27]
ISSN 1557-8666. doi: 10.1089/cmb.2021.0446. 12
-
[28]
Boyi Guo, Wodan Ling, Sang Ho Kwon, Pratibha Panwar, Shila Ghazanfar, Keri Mar- tinowich, and Stephanie C. Hicks. Integrating Spatially-Resolved Transcriptomics Data Across Tissues and Individuals: Challenges and Opportunities.Small Methods, 9(5): 2401194, 2025. ISSN 2366-9608. doi: 10.1002/smtd.202401194. URL . _eprint: https://onlinelibrary.wiley.com/do...
-
[29]
Muiz Khan, Suzan Arslanturk, and Sorin Draghici. A comprehensive review of spatial tran- scriptomics data alignment and integration.Nucleic Acids Research, 53(12):gkaf536, June 2025. ISSN 1362-4962. doi: 10.1093/nar/gkaf536
-
[30]
Karishma D’Sa, James R. Evans, Gurvir S. Virdi, Giulia Vecchi, Alexander Adam, Ottavia Bertolli, James Fleming, Hojong Chang, Craig Leighton, Mathew H. Horrocks, Dilan Athauda, Minee L. Choi, and Sonia Gandhi. Prediction of mechanistic subtypes of Parkinson’s using patient-derived stem cell models.Nature Machine Intelligence, 5(8):933–946, August 2023. IS...
-
[31]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, January 1998. ISSN 1558-2256. doi: 10.1109/5.726791. URL
-
[32]
URLhttps://distill.pub/ 2020/circuits/zoom-in
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom In: An Introduction to Circuits.Distill, 5(3):10.23915/distill.00024.001, March 2020. ISSN 2476-0757. doi: 10.23915/distill.00024.001. URL
-
[33]
Tom Burgert, Oliver Stoll, Paolo Rota, and Begüm Demir. ImageNet-trained CNNs are not biased towards texture: Revisiting feature reliance through controlled suppression. InAdvances in Neural Information Processing Systems, volume 38, 2025. doi: 10.48550/ARXIV .2509.20234. URL . Version Number: 5
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[34]
Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet
Wieland Brendel and Matthias Bethge. Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet. InInternational Conference on Learning Repre- sentations, New Orleans, 2019. URL
2019
-
[35]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In9th International Conference on Learning Representations, ICLR 2021, V...
2021
-
[36]
Do Vision Transformers See Like Convolutional Neural Networks? InAdvances in Neural Information Processing Systems, volume 34, pages 12116–12128
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do Vision Transformers See Like Convolutional Neural Networks? InAdvances in Neural Information Processing Systems, volume 34, pages 12116–12128. Curran Associates, Inc., 2021. URL
2021
-
[37]
Supervised Contrastive Learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised Contrastive Learning. InAdvances in Neural Information Processing Systems, volume 33, pages 18661–18673. Curran Associates, Inc., 2020. URL
2020
-
[38]
Momentum Contrast for Unsupervised Visual Representation Learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum Contrast for Unsupervised Visual Representation Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020. doi: 10.1109/CVPR42600. 2020.00975. URL
-
[39]
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving Sparse Decomposition of Language Model Activations with Gated Sparse Autoencoders.Advances in Neural Information Processing Systems, 37:775–818, December 2024. doi: 10.52202/079017-0024. URL
-
[40]
Laleh Haghverdi, Maren Büttner, F Alexander Wolf, Florian Buettner, and Fabian J Theis. Diffusion pseudotime robustly reconstructs lineage branching.Nature Methods, 13(10):845– 848, October 2016. ISSN 1548-7091, 1548-7105. doi: 10.1038/nmeth.3971. URL
-
[41]
Moon, David van Dijk, Zheng Wang, Scott Gigante, Daniel B
Kevin R. Moon, David van Dijk, Zheng Wang, Scott Gigante, Daniel B. Burkhardt, William S. Chen, Kristina Yim, Antonia van den Elzen, Matthew J. Hirn, Ronald R. Coifman, Natalia B. Ivanova, Guy Wolf, and Smita Krishnaswamy. Visualizing structure and transitions in high- dimensional biological data.Nature Biotechnology, 37(12):1482–1492, December 2019. ISSN...
-
[42]
F. Alexander Wolf, Fiona K. Hamey, Mireya Plass, Jordi Solana, Joakim S. Dahlin, Berthold Göttgens, Nikolaus Rajewsky, Lukas Simon, and Fabian J. Theis. PAGA: graph abstraction reconciles clustering with trajectory inference through a topology preserving map of single cells. Genome Biology, 20(1):59, March 2019. ISSN 1474-760X. doi: 10.1186/s13059-019-1663-x. URL
-
[43]
Ikezu, Justin O’Leary, Manikandan Selvaraj, Yiyang Zhu, Yuka A
Yunjung Jin, Fuyao Li, Zonghua Li, Tadafumi C. Ikezu, Justin O’Leary, Manikandan Selvaraj, Yiyang Zhu, Yuka A. Martens, Shunsuke Koga, Hannah Santhakumar, Yonghe Li, Wenyan Lu, Yang You, Kiara Lolo, Michael DeTure, Alexandra I. Beasley, Mary D. Davis, Pamela J. McLean, Owen A. Ross, Takahisa Kanekiyo, Tsuneya Ikezu, Thomas Caulfield, Jonathan Carr, Zbigni...
2024
-
[44]
Romain Lopez, Jeffrey Regier, Michael B. Cole, Michael I. Jordan, and Nir Yosef. Deep generative modeling for single-cell transcriptomics.Nature Methods, 15(12):1053–1058, December 2018. ISSN 1548-7105. doi: 10.1038/s41592-018-0229-2. URL
-
[45]
Similarity of Neural Network Representations Revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of Neural Network Representations Revisited. InProceedings of the 36th International Conference on Machine Learning, pages 3519–3529. PMLR, May 2019. URL
2019
-
[46]
Thao Nguyen, Maithra Raghu, and Simon Kornblith. Do wide and deep networks learn the same things? Uncovering how neural network representations vary with width and depth. In International Conference on Learning Representations, 2021. arXiv:2010.15327 [cs.LG]
-
[47]
Alex Murphy, Joel Zylberberg, and Alona Fyshe. Correcting biased centered kernel alignment measures in biological and artificial neural networks, 2024. URL . arXiv:2405.01012 [q- bio.NC]
-
[48]
XGBoost: A Scalable Tree Boosting System.Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,
Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System.Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,
-
[49]
Vardan Papyan, X. Y . Han, and David L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117 (40):24652–24663, October 2020. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.2015509117. URL
-
[50]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In 2007 15th European Signal Processing Conference, pages 606–610, September 2007. URL
2007
-
[51]
A. B. Singleton, M. Farrer, J. Johnson, A. Singleton, S. Hague, J. Kachergus, M. Hulihan, T. Peuralinna, A. Dutra, R. Nussbaum, S. Lincoln, A. Crawley, M. Hanson, D. Maraganore, C. Adler, M. R. Cookson, M. Muenter, M. Baptista, D. Miller, J. Blancato, J. Hardy, and K. Gwinn-Hardy. alpha-Synuclein locus triplication causes Parkinson’s disease.Science, 302 ...
-
[52]
Marie-Christine Chartier-Harlin, Jennifer Kachergus, Christophe Roumier, Vincent Mouroux, Xavier Douay, Sarah Lincoln, Clotilde Levecque, Lydie Larvor, Joris Andrieux, Mary Hulihan, Nawal Waucquier, Luc Defebvre, Philippe Amouyel, Matthew Farrer, and Alain Destée. Alpha- synuclein locus duplication as a cause of familial Parkinson’s disease.Lancet, 364(94...
-
[53]
Marthe H. R. Ludtmann, Plamena R. Angelova, Mathew H. Horrocks, Minee L. Choi, Mar- garida Rodrigues, Artyom Y . Baev, Alexey V . Berezhnov, Zhi Yao, Daniel Little, Blerida Banushi, Afnan Saleh Al-Menhali, Rohan T. Ranasinghe, Daniel R. Whiten, Ratsuda Yapom, Karamjit Singh Dolt, Michael J. Devine, Paul Gissen, Tilo Kunath, Morana Jaganjac, Evgeny V . Pav...
-
[54]
Towards better understanding of gradient-based attribution methods for deep neural networks
Marco Ancona, Enea Ceolini, Cengiz Öztireli, and Markus Gross. Towards better understanding of gradient-based attribution methods for deep neural networks. InInternational Conference on Learning Representations (ICLR), Vancouver, Canada, 2018. 14
2018
-
[55]
J.A. Tropp. Greed is good: algorithmic results for sparse approximation.IEEE Transactions on Information Theory, 50(10):2231–2242, October 2004. ISSN 1557-9654. doi: 10.1109/TIT. 2004.834793. URL
work page doi:10.1109/tit 2004
-
[56]
Livezey, Alejandro F
Jesse A. Livezey, Alejandro F. Bujan, and Friedrich T. Sommer. Learning Overcomplete, Low Coherence Dictionaries with Linear Inference.Journal of Machine Learning Research, 20(174): 1–42, 2019. ISSN 1533-7928. URL
2019
-
[57]
L. Welch. Lower bounds on the maximum cross correlation of signals (Corresp.).IEEE Transactions on Information Theory, 20(3):397–399, May 1974. ISSN 1557-9654. doi: 10.1109/TIT.1974.1055219. URL
- [58]
-
[59]
Mixon, Chong You, and Zhihui Zhu
Jiachen Jiang, Jinxin Zhou, Peng Wang, Qing Qu, Dustin G. Mixon, Chong You, and Zhihui Zhu. Generalized neural collapse for a large number of classes. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofICML’24, pages 22010–22041, Vienna, Austria, July 2024. JMLR.org
2024
-
[60]
Ciara H. O’Flanagan, Kieran R. Campbell, Allen W. Zhang, Farhia Kabeer, Jamie L. P. Lim, Justina Biele, Peter Eirew, Daniel Lai, Andrew McPherson, Esther Kong, Cherie Bates, Kelly Borkowski, Matt Wiens, Brittany Hewitson, James Hopkins, Jenifer Pham, Nicholas Ceglia, Richard Moore, Andrew J. Mungall, Jessica N. McAlpine, Sohrab P. Shah, and Samuel Aparici...
-
[61]
Irina V . Kopylova, Artem B. Ivanov, Lev R. Eidelman, Ekaterina N. Zaitseva, Ekaterina D. Kulikova, Dmitriy A. Grehnyov, Alexandra N. Bogomazova, Vladimir A. Vigont, Elena V . Kaznacheyeva, Maria A. Lagarkova, Olga S. Lebedeva, and Evgenii I. Olekhnovich. Convergent transcriptomic signature in iPSC-dopaminergic neurons of hereditary Parkinson’s disease.Li...
-
[62]
Oliver Stegle, Sarah A. Teichmann, and John C. Marioni. Computational and analytical challenges in single-cell transcriptomics.Nature Reviews Genetics, 16(3):133–145, March 2015. ISSN 1471-0064. doi: 10.1038/nrg3833. URL
-
[63]
Stephanie C Hicks, F William Townes, Mingxiang Teng, and Rafael A Irizarry. Missing data and technical variability in single-cell RNA-sequencing experiments.Biostatistics, 19(4):562–578, October 2018. ISSN 1465-4644. doi: 10.1093/biostatistics/kxx053. URL
-
[64]
Wolock, Romain Lopez, and Allon M
Samuel L. Wolock, Romain Lopez, and Allon M. Klein. Scrublet: Computational Identification of Cell Doublets in Single-Cell Transcriptomic Data.Cell Systems, 8(4):281–291.e9, April
-
[65]
doi: 10.1016/j.cels.2018.11.005
ISSN 2405-4720. doi: 10.1016/j.cels.2018.11.005
-
[66]
van den Brink, Fanny Sage, Ábel Vértesy, Bastiaan Spanjaard, Josi Peterson-Maduro, Chloé S
Susanne C. van den Brink, Fanny Sage, Ábel Vértesy, Bastiaan Spanjaard, Josi Peterson-Maduro, Chloé S. Baron, Catherine Robin, and Alexander van Oudenaarden. Single-cell sequencing reveals dissociation-induced gene expression in tissue subpopulations.Nature Methods, 14(10): 935–936, October 2017. ISSN 1548-7105. doi: 10.1038/nmeth.4437. URL
-
[67]
Dijkstra, Angela Ingrassia, Renee X
Anke A. Dijkstra, Angela Ingrassia, Renee X. de Menezes, Ronald E. van Kesteren, Annemieke J. M. Rozemuller, Peter Heutink, and Wilma D. J. van de Berg. Evidence for Immune Response, Axonal Dysfunction and Reduced Endocytosis in the Substantia Nigra in Early Stage Parkinson’s Disease.PLOS ONE, 10(6):e0128651, 2015. ISSN 1932-6203. doi: 10.1371/journal.pon...
-
[68]
David L. Donoho and Michael Elad. Optimally sparse representation in general (nonorthogonal) dictionaries via ℓ1 minimization.Proceedings of the National Academy of Sciences, 100(5): 2197–2202, March 2003. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.0437847100. URL
-
[69]
D.L. Donoho. Compressed sensing.IEEE Transactions on Information Theory, 52(4):1289– 1306, April 2006. ISSN 0018-9448. doi: 10.1109/TIT.2006.871582. URL
-
[70]
Trajectories of cell-cycle progression from fixed cell populations.Nature Methods, 12(10):951–954, October
Gabriele Gut, Michelle D Tadmor, Dana Pe’er, Lucas Pelkmans, and Prisca Liberali. Trajectories of cell-cycle progression from fixed cell populations.Nature Methods, 12(10):951–954, October
-
[71]
ISSN 1548-7091, 1548-7105. doi: 10.1038/nmeth.3545. URL . 15
-
[72]
Bryan He, Ludvig Bergenstråhle, Linnea Stenbeck, Abubakar Abid, Alma Andersson, Åke Borg, Jonas Maaskola, Joakim Lundeberg, and James Zou. Integrating spatial gene expression and breast tumour morphology via deep learning.Nature Biomedical Engineering, 4(8):827–834, August 2020. ISSN 2157-846X. doi: 10.1038/s41551-020-0578-x. URL
-
[73]
Ronald Xie, Kuan Pang, Sai Chung, Catia Perciani, Sonya MacParland, Bo Wang, and Gary Bader. Spatially Resolved Gene Expression Prediction from Histology Images via Bi-modal Contrastive Learning.Advances in Neural Information Processing Systems, 36:70626–70637, December 2023. URL
2023
-
[74]
Shuailin Xue, Fangfang Zhu, Jinyu Chen, and Wenwen Min. Inferring single-cell resolution spatial gene expression via fusing spot-based spatial transcriptomics, location, and histology using GCN.Briefings in Bioinformatics, 26(1):bbae630, January 2025. ISSN 1477-4054. doi: 10.1093/bib/bbae630. URL
-
[75]
Way, Ted Natoli, Adeniyi Adeboye, Lev Litichevskiy, Andrew Yang, Xiaodong Lu, Juan C
Gregory P. Way, Ted Natoli, Adeniyi Adeboye, Lev Litichevskiy, Andrew Yang, Xiaodong Lu, Juan C. Caicedo, Beth A. Cimini, Kyle Karhohs, David J. Logan, Mohammad H. Rohban, Maria Kost-Alimova, Kate Hartland, Michael Bornholdt, Srinivas Niranj Chandrasekaran, Marzieh Haghighi, Erin Weisbart, Shantanu Singh, Aravind Subramanian, and Anne E. Carpenter. Morpho...
-
[76]
Tommaso Schirinzi, Graziella Madeo, Giuseppina Martella, Marta Maltese, Barbara Picconi, Paolo Calabresi, and Antonio Pisani. Early synaptic dysfunction in Parkinson’s disease: Insights from animal models.Movement Disorders: Official Journal of the Movement Disorder Society, 31(6):802–813, June 2016. ISSN 1531-8257. doi: 10.1002/mds.26620
-
[77]
Manfredsson, Matthew J
Seong Su Kang, Zhentao Zhang, Xia Liu, Fredric P. Manfredsson, Matthew J. Benskey, Xuebing Cao, Jun Xu, Yi E. Sun, and Keqiang Ye. TrkB neurotrophic activities are blocked by α- synuclein, triggering dopaminergic cell death in Parkinson’s disease.Proceedings of the National Academy of Sciences of the United States of America, 114(40):10773–10778, October
-
[78]
ISSN 1091-6490. doi: 10.1073/pnas.1713969114
-
[79]
Yaping Chu, Gerardo A. Morfini, Lori B. Langhamer, Yinzhen He, Scott T. Brady, and Jef- frey H. Kordower. Alterations in axonal transport motor proteins in sporadic and experimental Parkinson’s disease.Brain: A Journal of Neurology, 135(Pt 7):2058–2073, July 2012. ISSN 1460-2156. doi: 10.1093/brain/aws133
-
[80]
The Axon Initial Segment: An Updated Viewpoint.The Journal of Neuroscience: The Official Journal of the Society for Neuroscience, 38(9):2135–2145, February
Christophe Leterrier. The Axon Initial Segment: An Updated Viewpoint.The Journal of Neuroscience: The Official Journal of the Society for Neuroscience, 38(9):2135–2145, February
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.