Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
Pith reviewed 2026-07-02 15:33 UTC · model grok-4.3
The pith
Splash partitions MLLM parameters into dormant and critical subspaces to add tactile reasoning while preserving visual knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
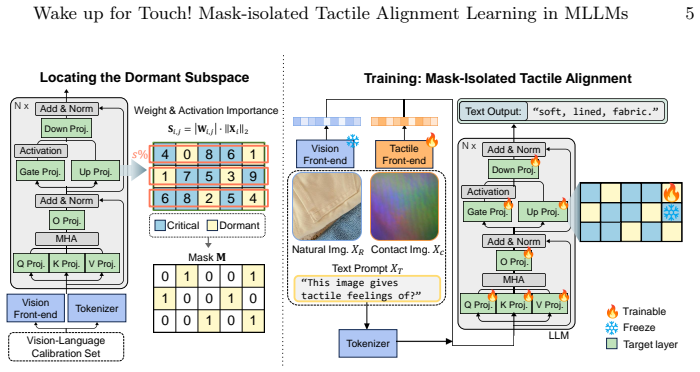
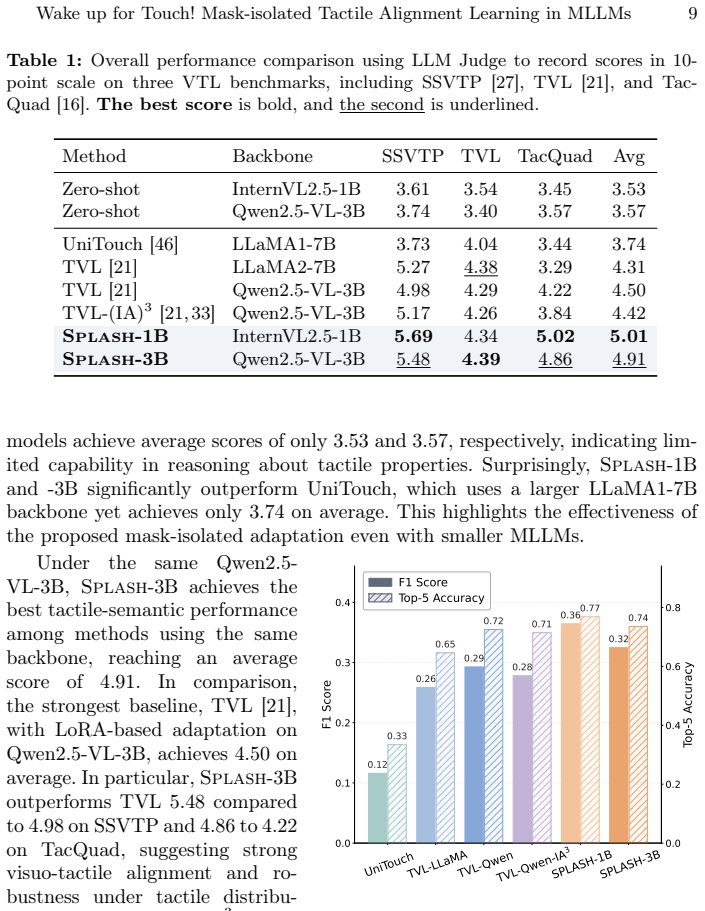
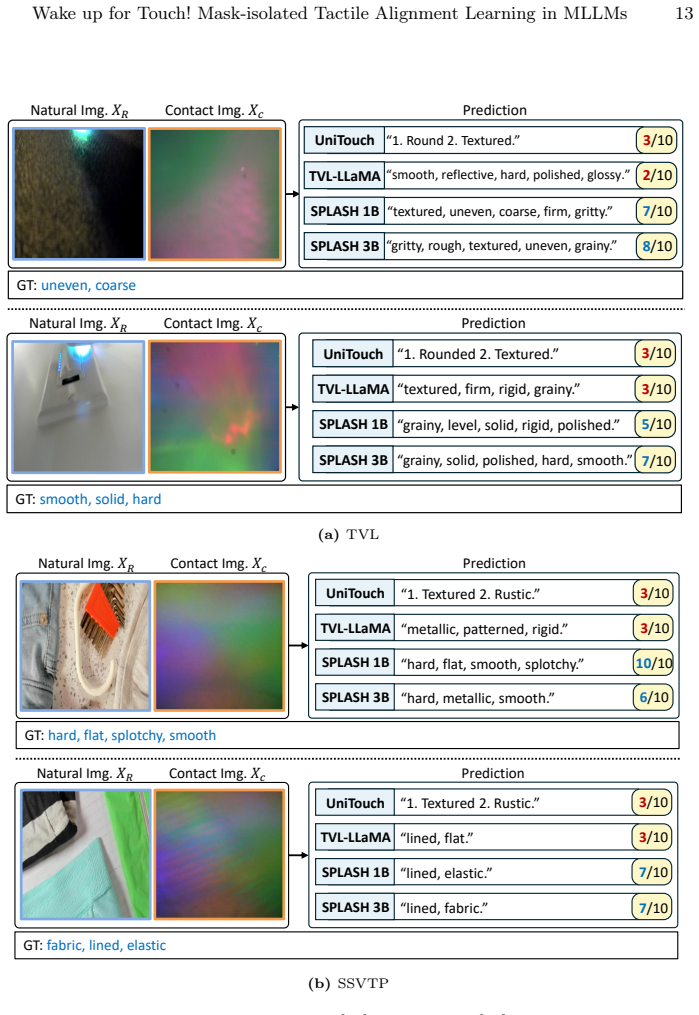
Splash quantifies the significance of each pretrained parameter and partitions the parameter space into a dormant and critical subspace. The frozen critical subspace acts as a stable anchor to safeguard general visual knowledge while the isolated dormant subspace is updated to internalize tactile alignment, achieving state-of-the-art performance on visuo-tactile benchmarks including SSVTP, TVL, and TacQuad without additional inference overhead or catastrophic forgetting.
What carries the argument
Mask-isolated tactile alignment learning that partitions parameters by per-parameter significance and updates only the dormant subspace.
If this is right
- Tactile reasoning integrates into existing MLLMs with zero added cost at inference time.
- State-of-the-art scores are reached on SSVTP, TVL, and TacQuad while general capabilities stay intact.
- Modality expansion avoids the zero-sum trade-off between new sensory data and old visual knowledge.
- Non-destructive updates become possible for other sensory modalities in pretrained models.
Where Pith is reading between the lines
- The same significance-based partitioning could support adding audio or proprioceptive data to the same models.
- If the dormant subspace reliably holds expandable capacity, the method offers a general route for continual learning in large multimodal systems.
- The approach implies that parameter importance maps may reveal separable knowledge types inside MLLMs.
Load-bearing premise
Pretrained MLLM parameters can be divided into dormant and critical subspaces based on significance so that updating only the dormant subspace adds tactile alignment without degrading the frozen critical subspace's visual knowledge.
What would settle it
Running the trained model on the original vision-language tasks and finding clear accuracy drops compared to the untouched base model, or failing to exceed prior tactile benchmark results, would show the isolated update does not work as claimed.
Figures


read the original abstract
Touch supplies the physical grounding needed to perceive intrinsic material properties, such as friction and compliance, that vision alone often cannot resolve. Recent efforts for equipping multimodal LLMs with this tactile sense, however, expose a zero-sum trade-off: the limited parameter budget of compact models forces a choice between acquiring the new sensory modality and preserving the established vision-language reasoning. We present Splash, a mask-isolated tactile alignment learning framework for MLLMs. Splash quantifies the significance of each pretrained parameter, and partitions the parameter space into a dormant and critical subspace. While the frozen critical subspace acts as a stable anchor to safeguard general visual knowledge, Splash updates the isolated dormant subspace to internalize tactile alignment towards LLMs. This selective, non-destructive expansion effectively prevents catastrophic forgetting and ensures non-destructive modality expansion. Extensive experiments show that Splash effectively achieves tactile reasoning without additional inference overhead in the LLM part, demonstrating state-of-the-art performance on visuo-tactile benchmarks, including SSVTP, TVL, and TacQuad, while preserving its original general-purpose capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Splash, a mask-isolated tactile alignment learning framework for MLLMs. It quantifies the significance of each pretrained parameter to partition the space into dormant and critical subspaces; the critical subspace is frozen to anchor general visual knowledge while the dormant subspace is updated to internalize tactile alignment. The method is claimed to achieve non-destructive modality expansion, SOTA performance on visuo-tactile benchmarks (SSVTP, TVL, TacQuad), and no additional LLM inference overhead while preserving original capabilities.
Significance. If the central premise holds, the work would offer a practical route to adding new sensory modalities to compact MLLMs without the usual zero-sum trade-off or catastrophic forgetting. The selective-update strategy could generalize beyond touch to other modalities.
major comments (2)
- [Abstract] Abstract: the central claim of non-destructive expansion and SOTA tactile reasoning rests on an unverified partition of the parameter space into dormant and critical subspaces via per-parameter significance quantification, yet the manuscript supplies neither the concrete quantification procedure nor any ablation demonstrating that the frozen critical subspace remains unaffected after dormant-subspace updates.
- [Abstract] Abstract: the assertion of state-of-the-art performance on SSVTP, TVL, and TacQuad is unsupported by any reported metrics, baselines, ablation studies, or experimental protocol, so the empirical support for the central claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We address each major comment below and note where revisions to the manuscript are required.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of non-destructive expansion and SOTA tactile reasoning rests on an unverified partition of the parameter space into dormant and critical subspaces via per-parameter significance quantification, yet the manuscript supplies neither the concrete quantification procedure nor any ablation demonstrating that the frozen critical subspace remains unaffected after dormant-subspace updates.
Authors: We agree that the manuscript as currently written does not supply the concrete per-parameter significance quantification procedure or the requested ablation. The abstract states the high-level approach but the full text provided does not contain the algorithmic details or stability ablation. We will add an explicit description of the quantification method (including the precise metric used) to Section 3 and include a dedicated ablation on the frozen critical subspace in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the assertion of state-of-the-art performance on SSVTP, TVL, and TacQuad is unsupported by any reported metrics, baselines, ablation studies, or experimental protocol, so the empirical support for the central claim cannot be evaluated.
Authors: We agree that the manuscript text supplied does not report specific metrics, baselines, or the experimental protocol. The abstract asserts SOTA results but provides no supporting numbers or setup. We will incorporate the quantitative results, baseline comparisons, and protocol description into the results section (and, space permitting, a concise summary in the abstract) of the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a parameter-significance quantification step that partitions the pretrained MLLM into dormant and critical subspaces, then updates only the dormant subspace while freezing the critical one. No equations, derivations, or self-referential definitions appear in the provided text that would make any claimed prediction or result equivalent to its inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the central claim rests on an empirical method rather than a fitted quantity renamed as a prediction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: NeurIPS (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. In: NeurIPS (2022)
2022
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
IEEE RAL (2018)
Calandra, R., Owens, A., Jayaraman, D., Lin, J., Yuan, W., Malik, J., Adelson, E.H., Levine, S.: More Than a Feeling: Learning to grasp and regrasp using vision and touch. IEEE RAL (2018)
2018
-
[5]
In: CVPR (2021) 16 Y
Changpinyo, S., Sharma, P., Ding, N., Soricut, R.: Conceptual 12M: Pushing web- scale image-text pre-training to recognize long-tail visual concepts. In: CVPR (2021) 16 Y. Park and M. Kim et al
2021
- [6]
-
[7]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
In: CVPR (2024)
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: CVPR (2024)
2024
-
[9]
Information Fusion (2025)
Cheng, N., Guan, C., Gao, J., Wang, W., Li, Y., Meng, F., Zhou, J., Fang, B., Xu, J., Han, W.: Touch100k: A large-scale touch-language-vision dataset for touch- centric multimodal representation. Information Fusion (2025)
2025
-
[10]
In: CVPR (2023)
Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., Jitsev, J.: Reproducible scaling laws for contrastive language-image learning. In: CVPR (2023)
2023
-
[11]
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Chu, X., Qiao, L., Zhang, X., Xu, S., Wei, F., Yang, Y., Sun, X., Hu, Y., Lin, X., Zhang, B., et al.: MobileVLM V2: Faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
In: CVPR (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A large-scale hierarchical image database. In: CVPR (2009)
2009
-
[13]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[14]
In: ICML (2023)
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: PaLM-E: An embodied multimodal language model. In: ICML (2023)
2023
-
[15]
In: ICML
Evci, U., Gale, T., Menick, J., Castro, P.S., Elsen, E.: Rigging the lottery: Making all tickets winners. In: ICML. PMLR (2020)
2020
-
[16]
In: ICLR (2025)
Feng, R., Hu, J., Xia, W., Gao, T., Shen, A., Sun, Y., Fang, B., Hu, D.: Any- Touch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. In: ICLR (2025)
2025
-
[17]
In: ICLR (2026)
Feng, R., Zhou, Y., Mei, S., Zhou, D., Wang, P., Cui, S., Fang, B., Yao, G., Hu, D.: AnyTouch 2: General optical tactile representation learning for dynamic tactile perception. In: ICLR (2026)
2026
-
[18]
In: ICLR (2019)
Frankle, J., Carbin, M.: The lottery ticket hypothesis: Finding sparse, trainable neural networks. In: ICLR (2019)
2019
-
[19]
In: ICML (2023)
Frantar, E., Alistarh, D.: SparseGPT: Massive language models can be accurately pruned in one-shot. In: ICML (2023)
2023
-
[20]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: MME: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
In: ICML (2024)
Fu, L., Datta, G., Huang, H., Panitch, W.C.H., Drake, J., Ortiz, J., Mukadam, M., Lambeta, M., Calandra, R., Goldberg, K.: A touch, vision, and language dataset for multimodal alignment. In: ICML (2024)
2024
-
[22]
In: ICLR (2025)
Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., Roberts, D.A.: The un- reasonable ineffectiveness of the deeper layers. In: ICLR (2025)
2025
-
[23]
Heng, L., Geng, H., Zhang, K., Abbeel, P., Malik, J.: ViTacFormer: Learning cross-modalrepresentationforvisuo-tactiledexterousmanipulation.arXivpreprint arXiv:2506.15953 (2025) Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[25]
In: EMNLP (2025)
Huang, W., Cheng, A., Wang, Y.: Mitigating catastrophic forgetting in large lan- guage models with forgetting-aware pruning. In: EMNLP (2025)
2025
-
[26]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
arXiv preprint arXiv:2209.13042 (2022)
Kerr, J., Huang, H., Wilcox, A., Hoque, R., Ichnowski, J., Calandra, R., Goldberg, K.: Self-supervised visuo-tactile pretraining to locate and follow garment features. arXiv preprint arXiv:2209.13042 (2022)
-
[28]
In: ICML (2025)
Khaki, S., Li, X., Guo, J., Zhu, L., Plataniotis, K.N., Yazdanbakhsh, A., Keutzer, K., Han, S., Liu, Z.: SparseLoRA: Accelerating llm fine-tuning with contextual sparsity. In: ICML (2025)
2025
-
[29]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA (2017)
2017
-
[30]
In: CVPR (2024)
Lei, W., Ge, Y., Yi, K., Zhang, J., Gao, D., Sun, D., Ge, Y., Shan, Y., Shou, M.Z.: ViT-Lens: Towards omni-modal representations. In: CVPR (2024)
2024
-
[31]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[32]
IEEE TPAMI (2017)
Li, Z., Hoiem, D.: Learning without forgetting. IEEE TPAMI (2017)
2017
-
[33]
In: NeurIPS (2022)
Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M., Raffel, C.A.: Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. In: NeurIPS (2022)
2022
-
[34]
In: CVPR (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: CVPR (2023)
2023
-
[35]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: MMBench: Is your multi-modal model an all-around player? In: ECCV (2024)
2024
-
[36]
Lloyd, J., Lin, Y., Lepora, N.F.: Probabilistic discriminative models address the tactileperceptualaliasingproblem.In:Robotics:ScienceandSystems(RSS)(2021)
2021
-
[37]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
In: ICLR (2024)
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. In: ICLR (2024)
2024
-
[39]
In: NeurIPS (2023)
Ma, X., Fang, G., Wang, X.: LLM-Pruner: On the structural pruning of large language models. In: NeurIPS (2023)
2023
-
[40]
In: CVPR (2018)
Mallya, A., Lazebnik, S.: PackNet: Adding multiple tasks to a single network by iterative pruning. In: CVPR (2018)
2018
-
[41]
In: Psychology of learning and motivation
McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: The sequential learning problem. In: Psychology of learning and motivation. Else- vier (1989)
1989
-
[42]
In: ICLR (2024)
Sun, M., Liu, Z., Bair, A., Kolter, J.Z.: A simple and effective pruning approach for large language models. In: ICLR (2024)
2024
-
[43]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) 18 Y. Park and M. Kim et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Williams, J., Gupta, K.D., George, R., Sarkar, M.: Lite VLA: Efficient vision-language-action control on cpu-bound edge robots. arXiv preprint arXiv:2511.05642 (2025)
-
[46]
In: CVPR (2024)
Yang, F., Feng, C., Chen, Z., Park, H., Wang, D., Dou, Y., Zeng, Z., Chen, X., Gangopadhyay, R., Owens, A., Wong, A.: Binding touch to everything: Learning unified multimodal tactile representations. In: CVPR (2024)
2024
-
[47]
In: NeurIPS (2022)
Yang, F., Ma, C., Zhang, J., Zhu, J., Yuan, W., Owens, A.: Touch and Go: Learning from human-collected vision and touch. In: NeurIPS (2022)
2022
-
[48]
In: ICML (2024)
Yin, L., Wu, Y., Zhang, Z., Hsieh, C.Y., Wang, Y., Jia, Y., Li, G., Jaiswal, A., Pechenizkiy, M., Liang, Y., et al.: Outlier weighed layerwise sparsity (OWL) a missing secret sauce for pruning llms to high sparsity. In: ICML (2024)
2024
-
[49]
Sensors (2017)
Yuan, W., Dong, S., Adelson, E.H.: GelSight: High-resolution robot tactile sensors for estimating geometry and force. Sensors (2017)
2017
-
[50]
In: CVPR (2017)
Yuan, W., Wang, S., Dong, S., Adelson, E.: Connecting look and feel: Associating the visual and tactile properties of physical materials. In: CVPR (2017)
2017
-
[51]
In: CVPR (2024)
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: MMMU: A massive multi-discipline multimodal under- standing and reasoning benchmark for expert agi. In: CVPR (2024)
2024
-
[52]
Zhai, Y., Tong, S., Li, X., Cai, M., Qu, Q., Lee, Y.J., Ma, Y.: Investigating the catastrophic forgetting in multimodal large language models (2023)
2023
-
[53]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: MiniGPT-4: Enhancing vision- language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Describe the image
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: RT-2: Vision-language-action models transfer web knowledge to robotic control. In: CoRL (2023) Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs 19 Appendix A Additional Discussion A.1 Vision Forgetting Problem Our motivation r...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.