Harnessing Generalist Agents for Contextualized Time Series
Pith reviewed 2026-06-28 05:43 UTC · model grok-4.3
The pith
TimeClaw equips generalist LLM agents with temporal tools, evolutionary routines, and multimodal memory for open-ended contextual time series reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
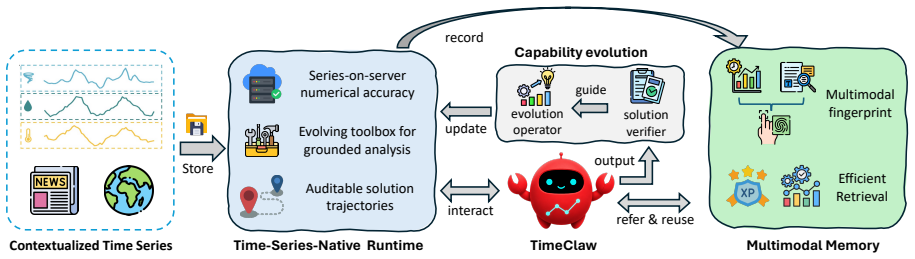
TimeClaw integrates executable temporal tools for grounded and auditable analysis, experience-driven capability evolution for creating reusable analytical routines, and episodic multimodal memory for retrieving relevant reasoning traces, thereby unlocking harnessed open-ended temporal reasoning with contextual information.
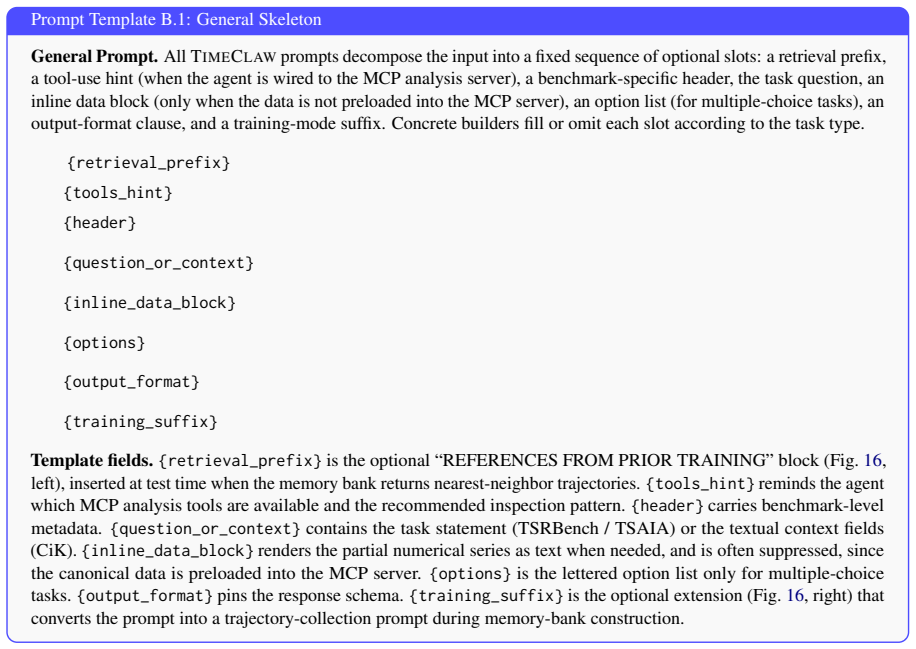
What carries the argument
The TimeClaw agentic harness, which supplies generalist LLM agents with three integrated components: executable temporal tools, experience-driven capability evolution, and episodic multimodal memory.
If this is right
- Agents can perform end-to-end workflows that treat forecasting as only one step inside broader analysis loops.
- Analysis becomes grounded and auditable because tools execute directly on temporal data.
- Analytical routines become reusable across tasks once evolved from experience.
- Relevant past reasoning traces can be retrieved via multimodal memory to inform new problems.
Where Pith is reading between the lines
- The same harness structure might transfer to other structured data types that currently frustrate text-only agents.
- If the evolution mechanism works, it could reduce the need to hand-craft new prompts for each domain.
- Episodic memory might allow agents to build long-term expertise within a single deployment rather than resetting per session.
Load-bearing premise
That giving generalist LLM agents time series-native runtime support through tools, evolution, and memory will produce measurable gains on real-world tasks without being blocked by the base models' limits on structured temporal signals.
What would settle it
An experiment in which TimeClaw-augmented agents show no performance advantage over unmodified generalist LLM agents across the same set of energy, finance, weather and traffic benchmarks would falsify the central claim.
Figures






read the original abstract
Time series are often embedded in rich contexts that are essential for holistic modeling. Moreover, real-world practitioners often require end-to-end workflows for analyzing temporal dynamics, where widely studied tasks such as forecasting are only one step in a broader solution loop. While generalist AI agents offer a promising interface for such workflows under complex contexts, they still operate primarily in textual spaces that are not fully aligned with structured temporal signals. In this work, we introduce TimeClaw, an agentic harness framework for time series that equips generalist LLM agents with the time series-native runtime support needed for contextualized temporal reasoning. TimeClaw integrates executable temporal tools for grounded and auditable analysis, experience-driven capability evolution for creating reusable analytical routines, and episodic multimodal memory for retrieving relevant reasoning traces. Together, these components unlock harnessed open-ended temporal reasoning with contextual information. Extensive evaluation on multiple benchmarks covering diverse tasks across energy, finance, weather, traffic, and other real-world domains demonstrates improved performance of TimeClaw. Code is available at https://github.com/iDEA-iSAIL-Lab-UIUC/TimeClaw.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
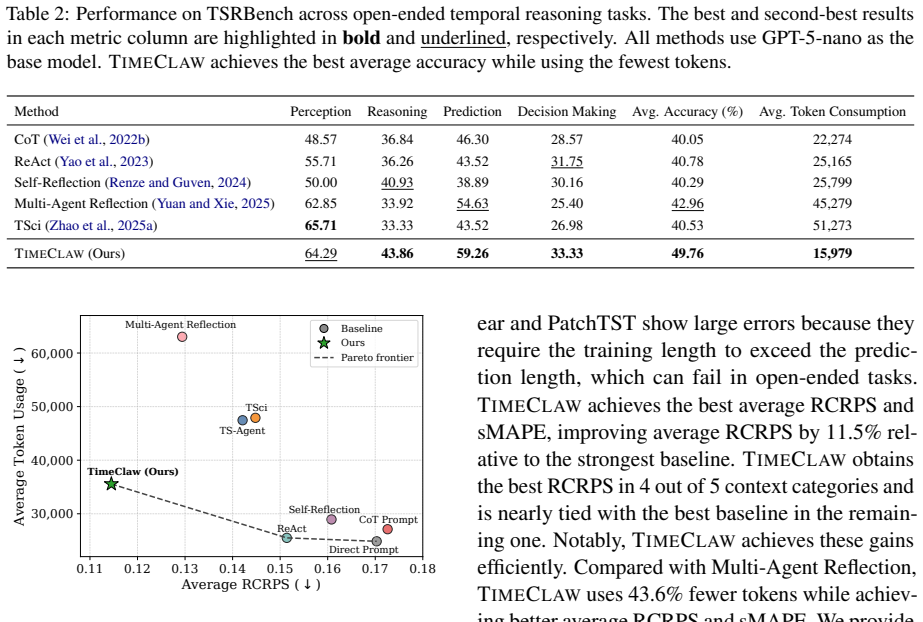
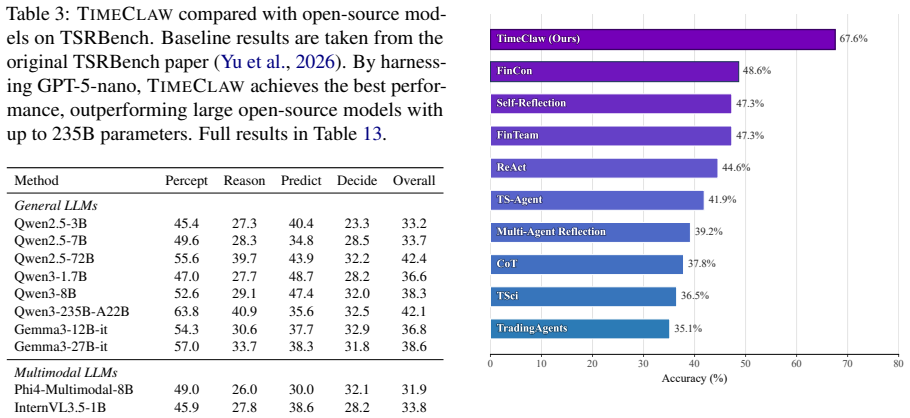
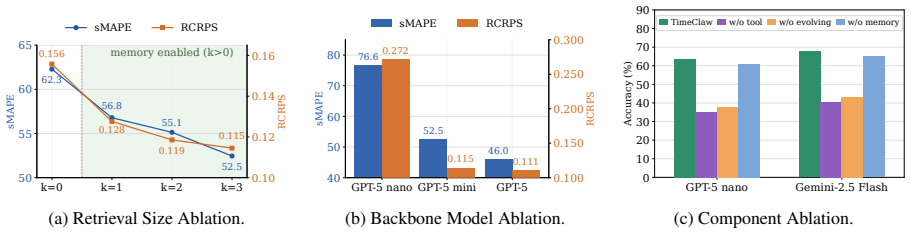
Summary. The manuscript introduces TimeClaw, a framework equipping generalist LLM agents with three components—executable temporal tools for grounded analysis, experience-driven capability evolution for reusable routines, and episodic multimodal memory for retrieving traces—to enable contextualized time series reasoning beyond pure textual spaces. The central claim is that these elements together unlock open-ended temporal reasoning with context, supported by extensive evaluations showing improved performance on benchmarks spanning energy, finance, weather, traffic, and other real-world domains.
Significance. If the empirical results are robust, the work could meaningfully advance agentic approaches to time series by providing runtime support that aligns generalist models with structured temporal signals. The open availability of code at the provided GitHub link is a strength for reproducibility and further testing.
major comments (1)
- [Abstract] Abstract: the claim that 'extensive evaluation on multiple benchmarks covering diverse tasks across energy, finance, weather, traffic, and other real-world domains demonstrates improved performance of TimeClaw' supplies no information on baselines, metrics, statistical tests, data splits, or quantitative gains. This absence makes it impossible to assess whether the central empirical claim holds or whether the three components overcome the alignment gap noted in the same paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater specificity is needed to allow readers to evaluate the empirical claims and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive evaluation on multiple benchmarks covering diverse tasks across energy, finance, weather, traffic, and other real-world domains demonstrates improved performance of TimeClaw' supplies no information on baselines, metrics, statistical tests, data splits, or quantitative gains. This absence makes it impossible to assess whether the central empirical claim holds or whether the three components overcome the alignment gap noted in the same paragraph.
Authors: We agree with the observation. The current abstract is intentionally high-level and does not include the requested quantitative details. In the revised manuscript we will expand the abstract to report the main baselines (vanilla LLM agents without TimeClaw components and standard time-series models), primary metrics (MAE, RMSE, and task-specific accuracy measures), data-split protocols, and observed quantitative gains (percentage improvements with statistical significance where computed). These specifics already appear in the Experiments section; the revision will simply surface them concisely in the abstract so that the central claim can be assessed at a glance. revision: yes
Circularity Check
No circularity: framework evaluated on external benchmarks with no derivation chain
full rationale
The paper introduces an agentic framework (TimeClaw) consisting of tools, evolution mechanisms, and memory components for LLM agents on time series tasks. No mathematical derivations, equations, fitted parameters, or predictions are described. The central claims rest on empirical evaluation across external benchmarks in energy, finance, weather, and traffic domains, not on any internal self-definition or reduction to inputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. This matches the default case of a self-contained engineering contribution whose value is externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generalist LLM agents can be effectively augmented with domain-specific temporal runtime support to achieve contextualized reasoning.
invented entities (4)
-
TimeClaw framework
no independent evidence
-
executable temporal tools
no independent evidence
-
experience-driven capability evolution
no independent evidence
-
episodic multimodal memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Processing Sys- tems, volume 29
Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. InAdvances in Neural Information Processing Sys- tems, volume 29. Curran Associates, Inc. Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. 2024. A decoder-only foundation model for time-series forecasting. InProceedings of the 41st International Confere...
Pith/arXiv arXiv 2024
-
[2]
Azul Garza, Cristian Challu, and Max Mergenthaler- Canseco
The causal chambers: Real physical systems as a testbed for ai methodology.arXiv preprint arXiv:2404.11341. Azul Garza, Cristian Challu, and Max Mergenthaler- Canseco. 2023. TimeGPT-1.arXiv preprint arXiv:2310.03589. Rakshitha Godahewa, Christoph Bergmeir, Geoffrey I Webb, Rob J Hyndman, and Pablo Montero-Manso
arXiv 2023
-
[3]
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski
Monash time series forecasting archive.arXiv preprint arXiv:2105.06643. Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. 2024. MO- MENT: A family of open time-series foundation models. InProceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, page...
arXiv 2024
-
[4]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 21690–21698
Harnessing vision-language models for time series anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 21690–21698. Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, and 1 others. 2025. Data interpreter: An LLM agent for data science. I...
Pith/arXiv arXiv 2025
-
[5]
MLAgentBench: Evaluating language agents on machine learning experimentation. InProceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 20271–20309. PMLR. Qihe Huang, Zhengyang Zhou, Yangze Li, Kuo Yang, Binwu Wang, and Yang Wang. 2026a. Many minds, one goal: Time series forecast...
arXiv 2017
-
[6]
Multi-modal time series analysis: A tutorial and survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Min- ing, V .2, KDD 2025, Toronto ON, Canada, August 3-7, 2025, pages 6043–6053. ACM. Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and 1 ot...
Pith/arXiv arXiv 2025
-
[7]
Multimodal pretraining of medical time se- ries and notes. InMachine Learning for Health, ML4H@NeurIPS 2023, 10 December 2023, New Orleans, Louisiana, USA, Proceedings of Machine Learning Research, pages 244–255. PMLR. Lingdong Kong, Xian Sun, Wei Chow, Linfeng Li, Kevin Qinghong Lin, Xuan Billy Zhang, Song Wang, Rong Li, Qing Wu, Wei Gao, and 1 others. 2...
Pith/arXiv arXiv 2023
-
[8]
Urbangpt: Spatio-temporal large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 5351–5362. Zihao Li, Xiao Lin, Zhining Liu, Jiaru Zou, Ziwei Wu, Lecheng Zheng, Dongqi Fu, Yada Zhu, Hendrik F. Hamann, Hanghang Tong, and Jingrui He. 2025c. Language in the flow of time: Time-series-paired texts w...
arXiv 2024
-
[9]
InInternational Conference on Learning Representations, volume 2024, pages 37854–37881
Test: Text prototype aligned embedding to activate llm’s ability for time series. InInternational Conference on Learning Representations, volume 2024, pages 37854–37881. Mingtian Tan, Mike A Merrill, Vinayak Gupta, Tim Althoff, and Thomas Hartvigsen. 2024. Are language models actually useful for time series forecasting? InThe Thirty-eighth Annual Conferen...
arXiv 2024
-
[10]
Timeart: Towards agentic time series reason- ing via tool-augmentation.CoRR, abs/2601.13653. Yingqian Wu, Qiushi Wang, Zefei Long, Rong Ye, Zhongtian Lu, Xianyin Zhang, Bingxuan Li, Wei Chen, Liwen Zhang, and Zhongyu Wei. 2025. Fin- team: A multi-agent collaborative intelligence sys- tem for comprehensive financial scenarios. InNat- ural Language Processi...
arXiv 2025
-
[11]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis
Springer. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024a. Efficient streaming lan- guage models with attention sinks. InInternational Conference on Learning Representations, volume 2024, pages 21875–21895. Yijia Xiao, Edward Sun, Di Luo, and Wei Wang. 2024b. Tradingagents: Multi-agents LLM financial trading framework.CoRR, abs/...
arXiv 2024
-
[12]
When LLM meets time series: Can llms per- form multi-step time series reasoning and inference. CoRR, abs/2509.01822. Fangxu Yu, Xingang Guo, Lingzhi Yuan, Haoqiang Kang, Hongyu Zhao, Lianhui Qin, Furong Huang, Bin Hu, and Tianyi Zhou. 2026. Tsrbench: A com- prehensive multi-task multi-modal time series rea- soning benchmark for generalist models.CoRR, abs...
arXiv 2026
-
[13]
Are transformers effective for time series forecasting? InThirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2023, Washington, DC, USA, February 7-14, 2023, pages 11121–1...
arXiv 2023
-
[14]
Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceed- ings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115. Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, and 1 others. 2023. One fits all: Power general time series analysis by pretrained lm.Advances in neural information processing syste...
arXiv 2023
-
[15]
struct” features describe the channel pool as a whole; “per-ch
Because the outputs are unit-norm, cosine similarity reduces to a dot product, cos(ϕq, ϕm) = ϕ⊤ q ϕm, which we exploit at retrieval time. If the encoder rejects an input as too long, the descrip- tor is halved and re-submitted, with at most two rounds of halving before the call is treated as a hard failure. Storage.At bank-building time, the embedding is ...
arXiv 2023
-
[16]
Withk= 1on this task both stages converge on the same family (FULLCAUSALCONTEXTIMPLICITEQUATIONBIVARLINSVAR) seen during training
Two-stage retrieval.TIMECLAWembeds the task’sbackground + scenario + constraintsblock with text-embedding-3-small, takes the top-Ktextrecords by cosine similarity from the training bank, then re-ranks the survivors by L2 distance on the 20-dim numerical fingerprint ofpast_time. Withk= 1on this task both stages converge on the same family (FULLCAUSALCONTEX...
-
[17]
Reference compression.The retrieved trajectory is compressed bysummarize_trajectoryinto the trainer’s analytic spine: acontext→forecastexplanation, together with the sequence of MCP tool calls and their truncated responses. This summary is then injected before the test prompt as aREFERENCES FROM PRIOR TRAININGblock, surfacing the transferable rule that th...
-
[18]
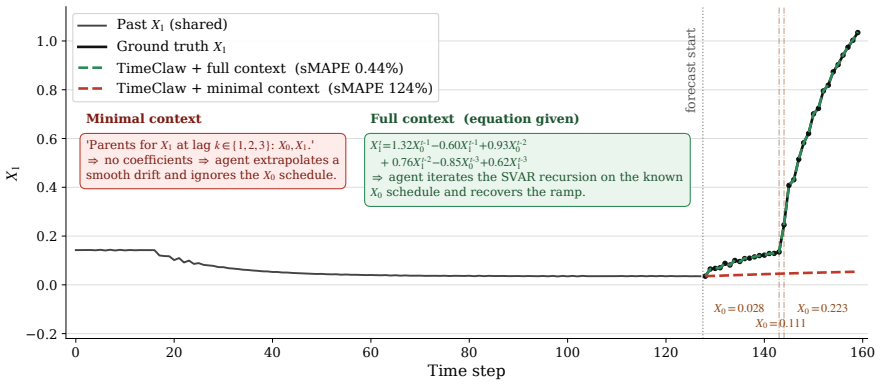
Context parsing.The agent reads the explicit linear SV AR equation from the prompt (Xt1 = 1.322Xt-10 − 0.604Xt-11 + 0.926Xt-20 + 0.763Xt-21 −0.851Xt-30 + 0.623Xt-31 ) and the piece-wise constant schedule forX0 over the 32-step horizon
-
[19]
1")→compute_acf(
Tool-grounded historical inspection.Guided by the retrieved spine, the agent invokes the MCP analysis server: series_overview()→channel_stats("1")→compute_acf("1", max_lag=20)→channel_values("1", 120, 128), confirming the recentX1 levels needed to seed the recursion
-
[20]
parents forX1 at lagk∈ {1,2,3}areX0, X1,
Closed-form forecast.With the equation, the recent lagged values, and the futureX0 schedule all known, the agent unrolls the recursion deterministically, producing a 32-step forecast that tracks the ground-truth ramp from 0.035→1.03almost exactly. Counterfactual: Minimal Context, Same Series.On the matched MINIMAL-context variant, the prompt only states t...
-
[21]
Then TIMECLAWretrievesk=3records
Two-stage retrieval.TIMECLAWembeds the test prompt withtext-embedding-3-smalland selects the top- Ktextrecords from the training bank by cosine, then re-ranks the survivors byL2distance on the fingerprint of the loaded series. Then TIMECLAWretrievesk=3records
-
[22]
the mechanism mapping is upstream-to-downstream edges
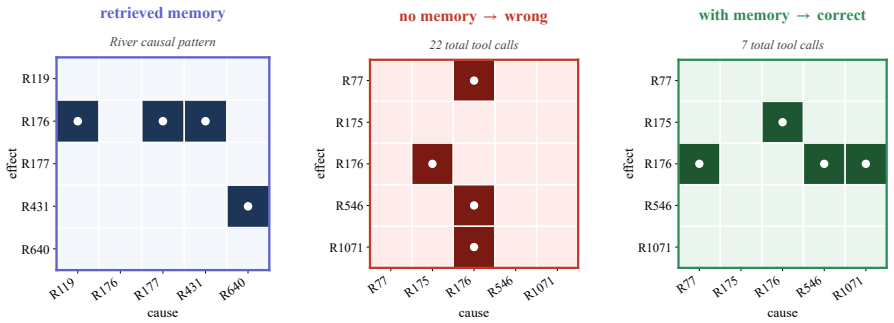
Rule extraction viasummarize_trajectory.Each retrieved trajectory is compressed to a tool-call spine plus a context_to_actionblock written during training. One block of the retrieved action in memory reads verbatim: “the mechanism mapping is upstream-to-downstream edges. ”This is the transferable decision rule that primes the test agent
-
[23]
Execution Stage
Prompt injection.The compressed references are concatenated as aREFERENCES FROM PRIOR TRAININGblock in front of the test prompt, only analytic spine and decision rules. Execution Stage
-
[24]
It skips the exhaustive per- channel statistics, peak-finding, and periodicity-detection that the no-memory agent runs through
Targeted tool use.Primed by the retrieved rule, the agent runs only the inspections needed to confirm direction: list_channels→series_overview→fivecompute_acfprobes, one per river. It skips the exhaustive per- channel statistics, peak-finding, and periodicity-detection that the no-memory agent runs through
-
[25]
The rule then determines option D, in which the sink row R176 is densely populated with parents from the tributaries and the tributaries themselves are source rows
Mapping the rule onto the new river set.The agent matches its own observations to the retrieved rule: the channels with mean flow∼660–680(R175, R176) form the downstream sinks; the three with mean flow<4(R77, R546, R1071) are upstream tributaries. The rule then determines option D, in which the sink row R176 is densely populated with parents from the trib...
-
[26]
Counterfactual: Same Series, No Memory.Re-running the identical task atk=0removes only theREFERENCESblock
Answer realisation.The agent emits the final letter<answer>D</answer>, with a brief justification citing the retrieved cascade rule. Counterfactual: Same Series, No Memory.Re-running the identical task atk=0removes only theREFERENCESblock. Without memory, the agent resorts to brute-force inspection, issuing22tool calls acrosschannel_stats, compute_acf, fi...
-
[27]
Each successful trajectory is summarized into a compact routine description that records the input conventions, intermediate computations, and final decision rule
Routine extraction viasummarize_trajectory.During training, three recurring analytical routines appear across successful trajectories: portfolio risk-adjusted return estimation, portfolio risk estimation, and market-factor regression. Each successful trajectory is summarized into a compact routine description that records the input conventions, intermedia...
-
[28]
parametric
Evolving finance-specific tools.From these recurring routines, TIMECLAWevolves three finance-specific tool schemas and adds them to the agent’s reusable toolbox: •portfolio_sharpe(channels, weights, risk_free, period_per_year): compute risk-adjusted return for each portfolio option and compare the returned ratios. •portfolio_var(channels, weights, horizon...
-
[29]
Inspect the series with whatever tools are available and walk through the reasoning step by step
-
[30]
scenario says ‘heat wave for 2 hours’→ground truth has a 4×spike at the stated start→because air-conditioning load scales with cooling demand
Output a<context_to_action>...</context_to_action>block (≤3 sentences) that explicitly states: • which sentences in the context (background / scenario / constraints / question / options) drive the answer’s shape, AND • the rule that maps those sentences to that shape (e.g. “scenario says ‘heat wave for 2 hours’→ground truth has a 4×spike at the stated sta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.