Multi-scale Mixture of World Models for Embodied Agents in Evolving Environments
Pith reviewed 2026-07-02 12:59 UTC · model grok-4.3
The pith
MuSix routes embodied agents to scale-specific world models via experiential distance and adapts them with scale-dependent forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
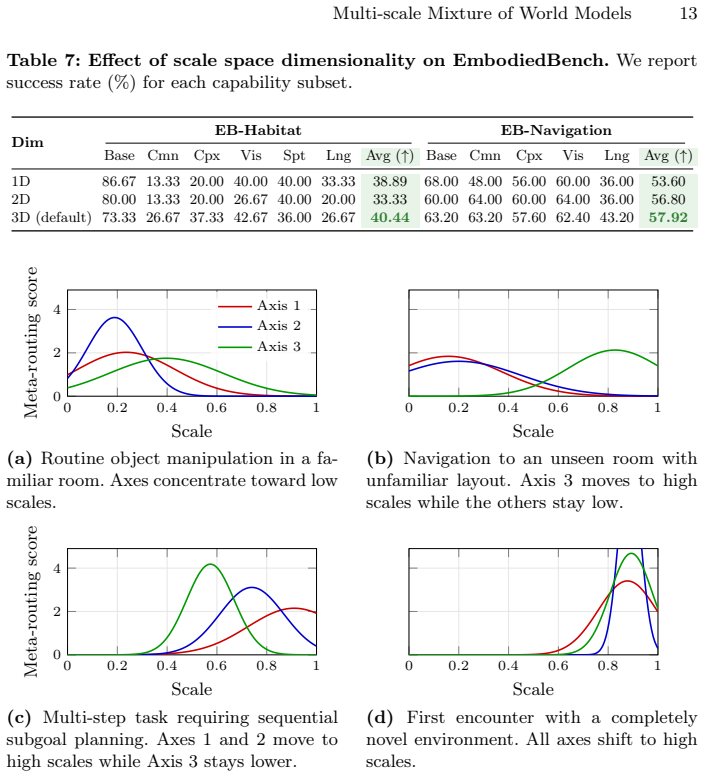
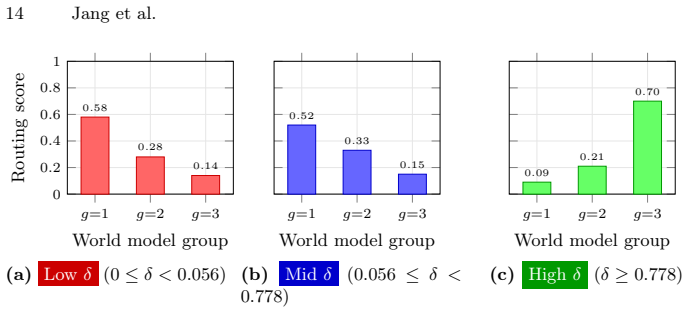
MuSix addresses the challenges of applying mixture of experts to embodied agents by introducing a two-stage routing mechanism grounded in experiential distance and scale-dependent adaptation mechanisms including forgetting rates and gated inter-scale transfer, leading to improved multi-scale reasoning and dynamic adaptation on EmbodiedBench and HAZARD.
What carries the argument
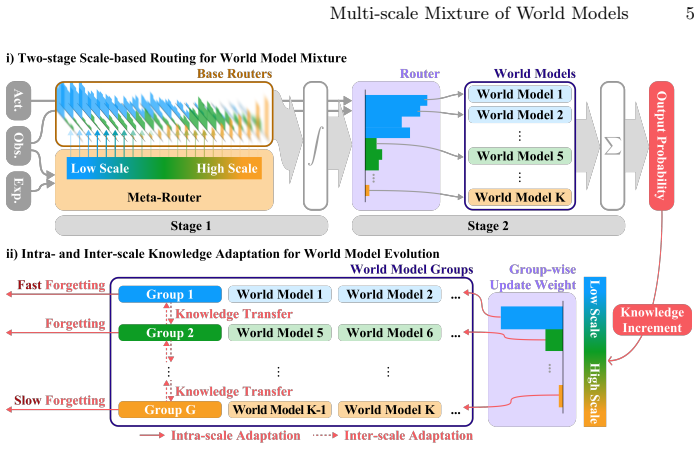
The two-stage routing mechanism that first maps experiential distance to a continuous scale space via a meta-router and then selects per-scale world models.
If this is right
- Low-scale knowledge can be refreshed rapidly without erasing high-scale abstractions.
- Gated transfers keep knowledge consistent when one scale updates faster than another.
- Targeted updates become possible at individual scales rather than applying a uniform policy across all scales.
- Agents achieve better performance on tasks that require both fine-grained and abstract reasoning in changing environments.
Where Pith is reading between the lines
- The continuous scale space could support smoother shifts between reasoning levels than methods that switch only among discrete scales.
- The same routing idea might apply to any hierarchical model where abstraction levels need different refresh rates, such as long-term planning systems.
- If the mapping from novelty to scale proves stable, it could reduce the need for manual tuning of update frequencies in deployed agents.
- The approach might generalize to non-embodied settings where data arrives at multiple temporal or spatial resolutions.
Load-bearing premise
Experiential distance can be reliably measured and mapped by the meta-router to a continuous scale that allows effective model selection and coherent transfer between scales.
What would settle it
Running the benchmarks with the meta-router removed or replaced by a fixed single scale and finding no drop in multi-scale reasoning or adaptation performance would show the scale-mapping step is not required for the reported gains.
Figures


read the original abstract
Embodied agents operating in the real world require multi-scale reasoning and knowledge adaptation as conditions change. We identify two challenges in applying Mixture of Experts (MoE) to this setting: routing lacks an explicit notion of scale, preventing targeted updates at specific scales, and a uniform update policy cannot accommodate the different rates at which knowledge at each scale becomes outdated. We present MuSix, a framework that addresses both challenges through scale-aware world model mixture and evolution. A two-stage routing mechanism grounds scale selection in experiential distance, a measure of situational novelty inspired by Construal Level Theory: a meta-router first maps this quantity to a weight over continuous scale space, then per-scale base routers select world models within the identified scale. For adaptation, scale-dependent forgetting rates allow low-scale knowledge to refresh rapidly while high-scale abstractions persist, and gated inter-scale transfer maintains coherence across the hierarchy. Experiments on EmbodiedBench and HAZARD show that MuSix improves over state-of-the-art baselines on multi-scale reasoning and dynamic adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
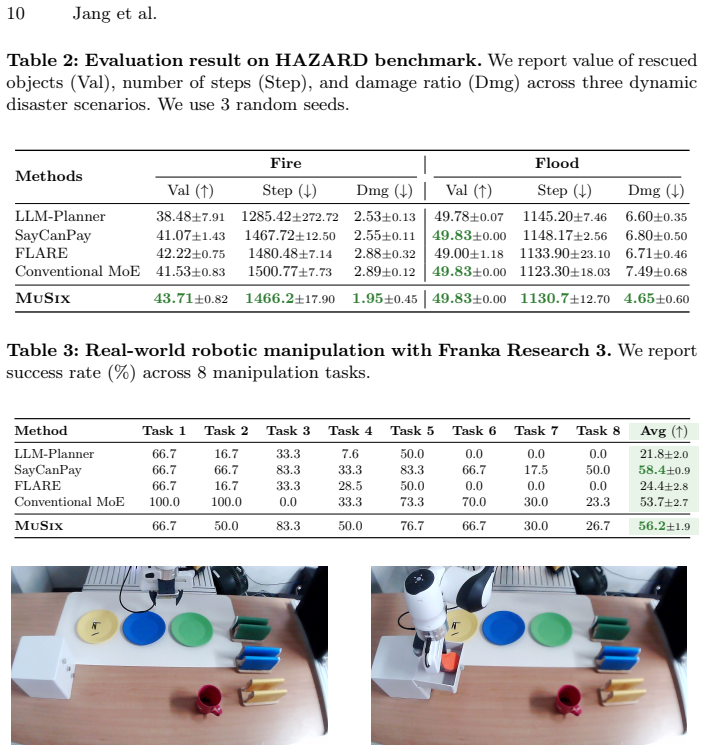
Summary. The manuscript introduces MuSix, a framework for multi-scale mixture of world models aimed at embodied agents in evolving environments. It identifies challenges in standard Mixture of Experts approaches regarding scale in routing and uniform update policies. The proposed solution includes a two-stage routing mechanism based on experiential distance (inspired by Construal Level Theory), scale-dependent forgetting rates, and gated inter-scale transfer. The key result is improved performance over state-of-the-art baselines on the EmbodiedBench and HAZARD benchmarks for multi-scale reasoning and dynamic adaptation.
Significance. If the experimental claims are substantiated, this could represent a meaningful advance in developing adaptive world models for embodied AI. The explicit incorporation of scale via experiential distance and the hierarchical adaptation mechanisms address important practical challenges in real-world deployment. The theoretical grounding in Construal Level Theory is a positive aspect that may encourage interdisciplinary connections.
major comments (2)
- [Abstract] No quantitative results, specific metrics, or details on the baselines are provided to support the claim that MuSix improves over state-of-the-art on EmbodiedBench and HAZARD; this is load-bearing for the central experimental claim.
- [Abstract] The experiential distance is described as 'a measure of situational novelty' mapped by a meta-router to a weight over continuous scale space, but no definition, formula, or implementation details are given, undermining evaluation of the two-stage routing's effectiveness.
minor comments (2)
- The abstract mentions 'scale-dependent forgetting rates' and 'gated inter-scale transfer' without explaining how these are implemented or their mathematical formulation.
- It would be helpful to clarify the relationship between the meta-router and per-scale base routers in more detail.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] No quantitative results, specific metrics, or details on the baselines are provided to support the claim that MuSix improves over state-of-the-art on EmbodiedBench and HAZARD; this is load-bearing for the central experimental claim.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these details in Section 4, with tables comparing MuSix against baselines on both EmbodiedBench and HAZARD using the relevant metrics for multi-scale reasoning and adaptation. We will revise the abstract to incorporate specific performance highlights and baseline names. revision: yes
-
Referee: [Abstract] The experiential distance is described as 'a measure of situational novelty' mapped by a meta-router to a weight over continuous scale space, but no definition, formula, or implementation details are given, undermining evaluation of the two-stage routing's effectiveness.
Authors: The abstract is intended as a high-level summary. The definition of experiential distance (as situational novelty), its mathematical formulation, the meta-router mapping to continuous scale weights, and the full two-stage routing procedure are provided in Section 3.1 of the manuscript, enabling direct evaluation of the mechanism. We do not believe the abstract requires the full technical specification. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper introduces MuSix as an extension of Mixture of Experts with explicit scale handling via experiential distance, two-stage routing, scale-dependent forgetting, and gated transfer. No equations, derivations, or parameter-fitting steps are described that reduce the claimed multi-scale reasoning improvements to quantities defined by construction from the inputs or from self-citations. The central claims rest on empirical results from EmbodiedBench and HAZARD benchmarks, which are presented as external validation rather than internal redefinitions or fitted predictions. The method is framed as addressing identified challenges in MoE for embodied agents without load-bearing self-referential loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Conference on Robot Learning (2022)
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Ho, D., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jang, E., Ruano, R.M.J., Jeffrey, K., Jesmonth, S., Joshi, N.J., Julian, R.C., Kalashnikov, D., Kuang, Y., Lee, K.H., Levine, S., Lu, Y., Luu, L., Parada, C., Pastor, P., Quiambao, J...
2022
-
[2]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Azzolini, A., Bai, J., Brandon, H., Cao, J., Chattopadhyay, P., Chen, H., Chu, J., Cui, Y., Diamond, J., Ding, Y., et al.: Cosmos-reason1: From physical common sense to embodied reasoning. arXiv preprint arXiv:2503.15558 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Advances in Neural Information Processing Systems38, 113506–113543 (2026)
Behrouz, A., Zhong, P., Mirrokni, V.: Titans: Learning to memorize at test time. Advances in Neural Information Processing Systems38, 113506–113543 (2026)
2026
-
[5]
In: International Conference on Machine Learning (2023)
Driess, D., Xia, F., Sajjadi, M.S.M., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q.H., Yu, T., Huang, W., Chebotar, Y., Sermanet, P., Duckworth, D., Levine, S., Vanhoucke, V., Hausman, K., Toussaint, M., Greff, K., Zeng, A., Mordatch, I., Florence, P.R.: Palm-e: An embodied multimodal language model. In: International Conference ...
2023
-
[6]
In: The Twelfth International Conference on Learning Representations (2023)
Gumbsch, C., Sajid, N., Martius, G., Butz, M.V.: Learning hierarchical world mod- els with adaptive temporal abstractions from discrete latent dynamics. In: The Twelfth International Conference on Learning Representations (2023)
2023
-
[7]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Hazra, R., Dos Martires, P.Z., De Raedt, L.: Saycanpay: Heuristic planning with large language models using learnable domain knowledge. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 20123–20133 (2024)
2024
-
[8]
ArXiv (2022)
Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P.R., Zeng, A., Tomp- son, J., Mordatch, I., Chebotar, Y., Sermanet, P., Brown, N., Jackson, T., Luu, L., Levine, S., Hausman, K., Ichter, B.: Inner monologue: Embodied reasoning through planning with language models. ArXiv (2022)
2022
-
[9]
Neural computation3(1), 79–87 (1991)
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural computation3(1), 79–87 (1991)
1991
-
[10]
Advances in neural information processing systems34, 1273– 1286 (2021)
Janner, M., Li, Q., Levine, S.: Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems34, 1273– 1286 (2021)
2021
-
[11]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Kim,T.,Kim,B.,Choi,J.:Multi-modalgroundedplanningandefficientreplanning for learning embodied agents with a few examples. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4329–4337 (2025)
2025
-
[12]
arXiv preprint arXiv:2406.16437 (2024)
Li, H., Lin, S., Duan, L., Liang, Y., Shroff, N.B.: Theory on mixture-of-experts in continual learning. arXiv preprint arXiv:2406.16437 (2024)
-
[13]
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2018)
Ma, J.W., Zhao, Z., Yi, X., Chen, J., Hong, L., Chi, E.H.: Modeling task relation- ships in multi-task learning with multi-gate mixture-of-experts. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2018)
2018
-
[14]
In: Conference on Empirical Methods in Natural Language Processing (2023)
Shen, S., Yao, Z., Li, C., Darrell, T., Keutzer, K., He, Y.: Scaling vision-language models with sparse mixture of experts. In: Conference on Empirical Methods in Natural Language Processing (2023)
2023
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Song, C.H., Wu, J., Washington, C., Sadler, B.M., Chao, W.L., Su, Y.: Llm- planner: Few-shot grounded planning for embodied agents with large language models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2998–3009 (2023)
2023
-
[16]
Psycho- logical review117(2), 440 (2010)
Trope, Y., Liberman, N.: Construal-level theory of psychological distance. Psycho- logical review117(2), 440 (2010)
2010
-
[17]
Trope, Y., Liberman, N., Wakslak, C.J.: Construal levels and psychological dis- tance:Effectsonrepresentation,prediction,evaluation,andbehavior.Journalofcon- sumer psychology : the official journal of the Society for Consumer Psychology17 2, 83–95 (2007)
2007
-
[18]
arXiv preprint arXiv:2406.18420 (2024)
Willi, T., Obando-Ceron, J., Foerster, J., Dziugaite, K., Castro, P.S.: Mixture of experts in a mixture of rl settings. arXiv preprint arXiv:2406.18420 (2024)
-
[19]
Yang, R., Chen, H., Zhang, J., Zhao, M., Qian, C., Wang, K., Wang, Q., Koripella, T.V., Movahedi, M., Li, M., et al.: Embodiedbench: Comprehensive benchmark- Multi-scale Mixture of World Models 17 ing multi-modal large language models for vision-driven embodied agents. arXiv preprint arXiv:2502.09560 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
arXiv preprint arXiv:2401.09870 (2024)
Zadem,M.,Mover,S.,Nguyen,S.M.:Reconcilingspatialandtemporalabstractions for goal representation. arXiv preprint arXiv:2401.09870 (2024)
-
[21]
ArXiv (2022)
Zhong, T., Chi, Z., Gu, L., Wang, Y., Yu, Y., Tang, J.: Meta-dmoe: Adapting to domain shift by meta-distillation from mixture-of-experts. ArXiv (2022)
2022
-
[22]
arXiv preprint arXiv:2401.12975 (2024)
Zhou,Q.,Chen,S.,Wang,Y.,Xu,H.,Du,W.,Zhang,H.,Du,Y.,Tenenbaum,J.B., Gan, C.: Hazard challenge: Embodied decision making in dynamically changing environments. arXiv preprint arXiv:2401.12975 (2024)
-
[23]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Zhu, C., Yu, R., Feng, S., Burchfiel, B., Shah, P., Gupta, A.: Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. arXiv preprint arXiv:2504.02792 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) 18 Jang et al. Fig.6:The top-view example of the Habitat environment. A Benchmarks A.1 EmbodiedBench We co...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.