ChessMimic: Per-Rating Transformer Models for Human Move, Clock, and Outcome Prediction in Online Blitz Chess
Pith reviewed 2026-06-28 07:06 UTC · model grok-4.3
The pith
Separate per-rating transformers predict human chess moves more accurately than Maia-2 in every Elo band.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
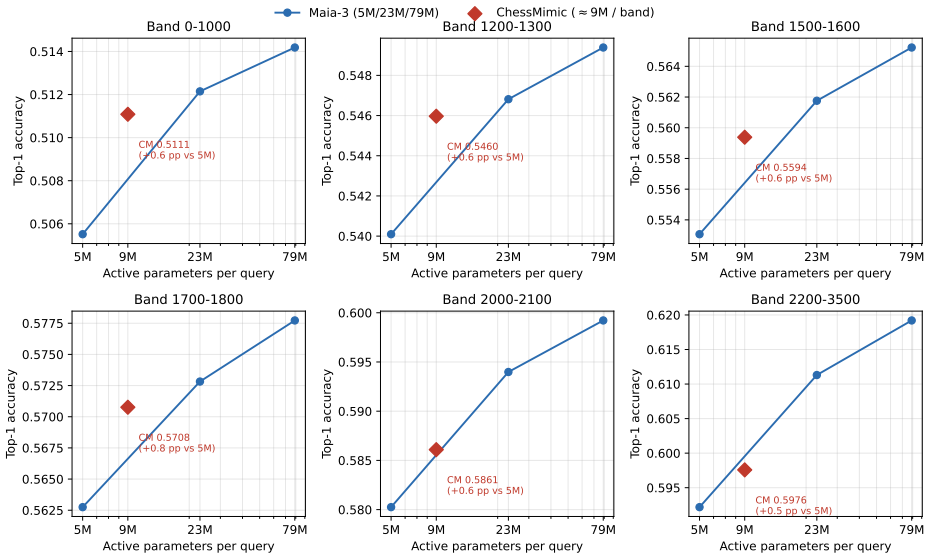
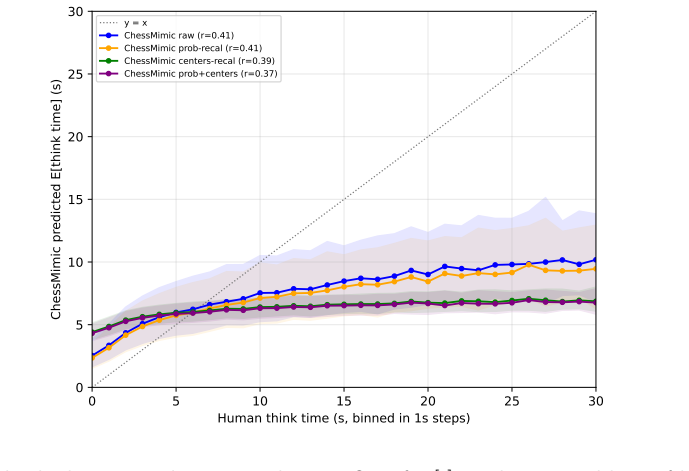
The central discovery is that fitting separate 9M-parameter encoder-only transformers for each 100-Elo band yields higher human move prediction accuracy than Maia-2 on Lichess blitz games across all bands, with an outcome predictor achieving 0.78 AUC and a clock predictor with Pearson r of 0.41.
What carries the argument
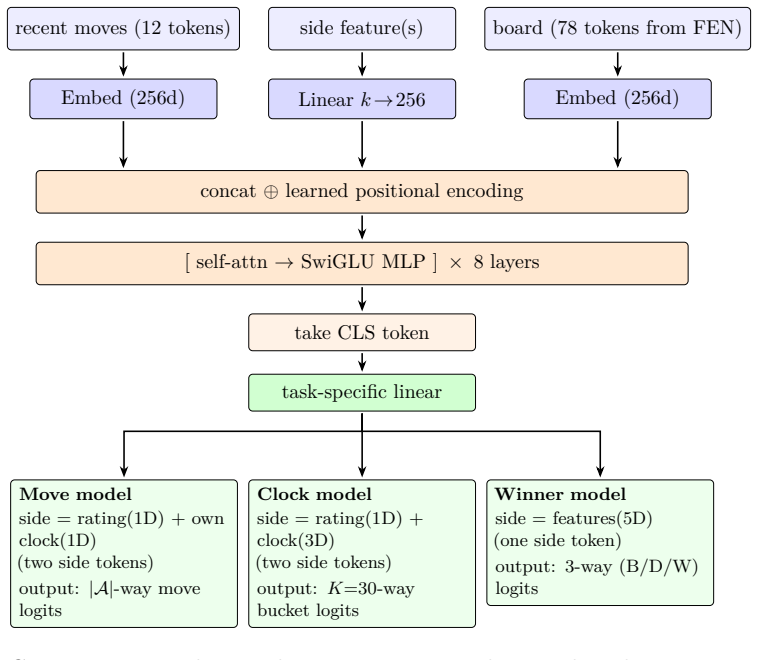
Per-100-Elo-band encoder-only transformers conditioned on board position, recent move history, player rating, and clock state for move, clock, and outcome prediction.
Load-bearing premise
The held-out single-month Lichess slice is representative of human play and that separate models per band avoid overfitting to their training slices.
What would settle it
If the move prediction accuracy falls below Maia-2 in any Elo band when tested on a new held-out month or different dataset, the outperformance claim would be falsified.
Figures


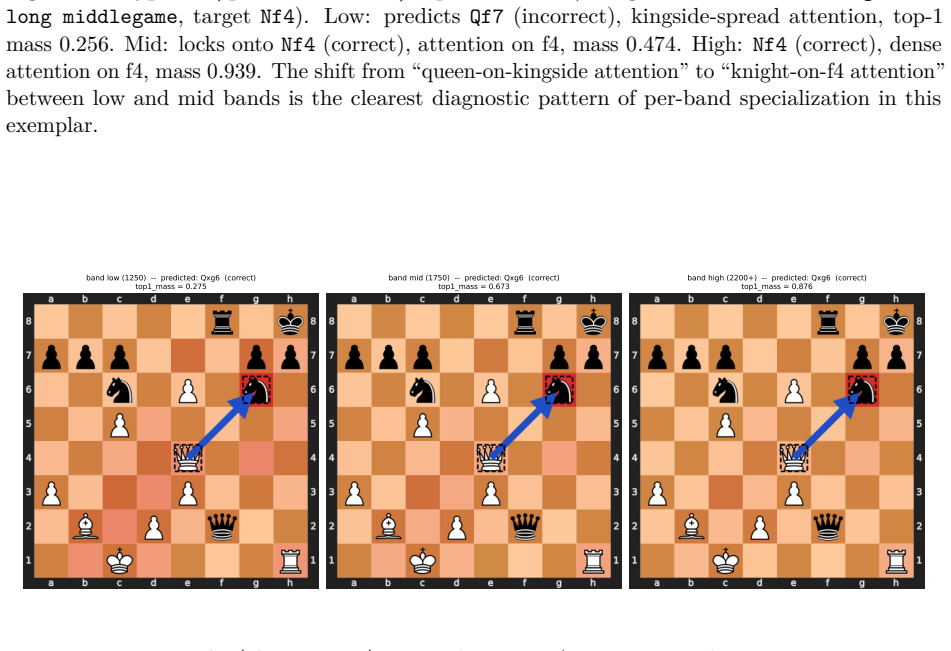
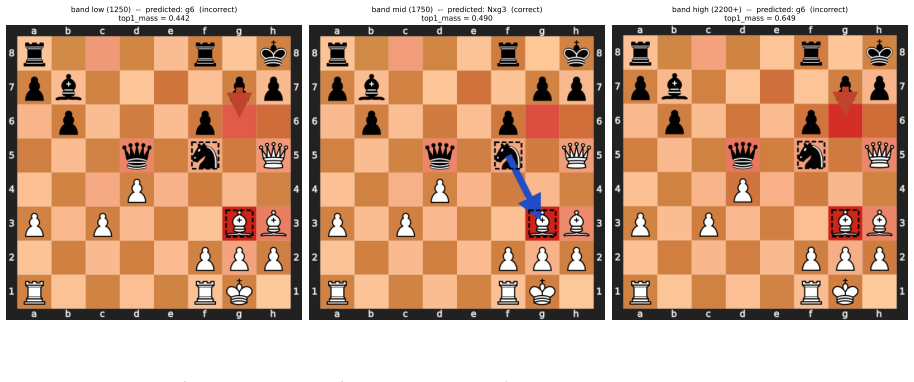

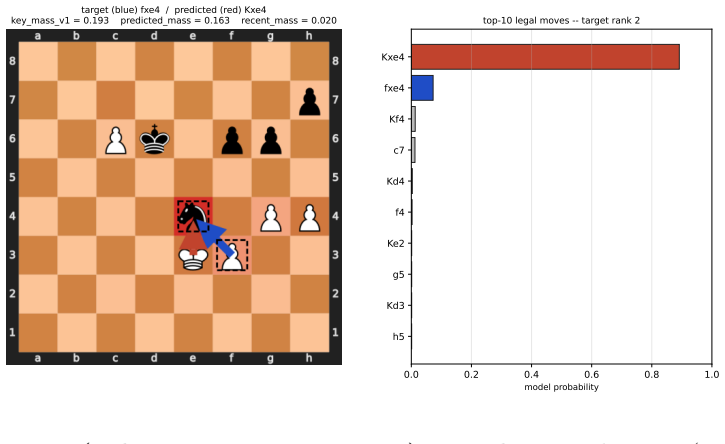

read the original abstract
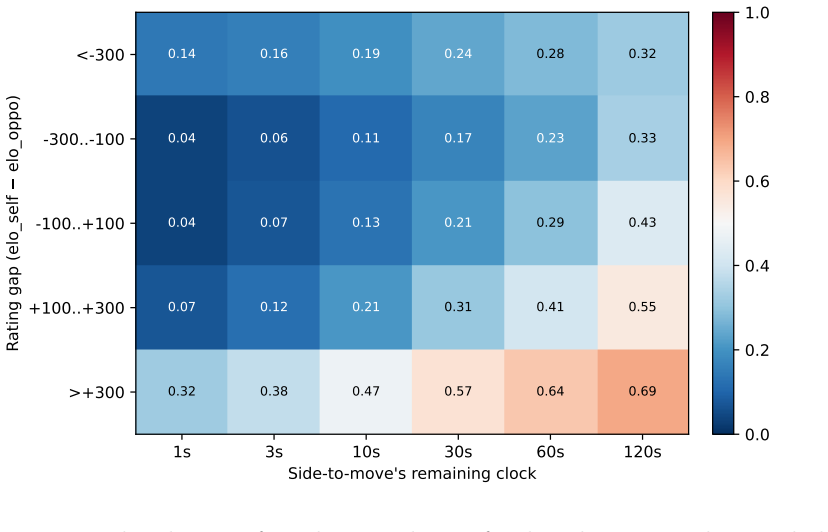
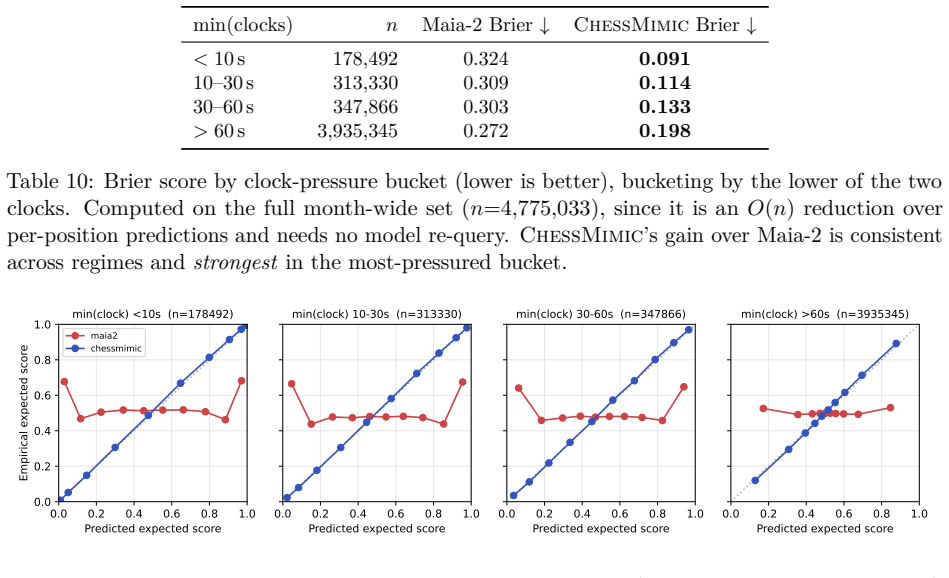
We present ChessMimic, a system of three small encoder-only transformers - for move, thinking-time, and outcome prediction - conditioned on the position, recent move history, player rating, and clock state. We fit a separate instance of each model per 100-Elo rating band, trading parameter efficiency for sharper per-skill calibration. On a held-out month-wide slice of Lichess Rated Blitz games ChessMimic's human move prediction accuracy outperforms Maia-2 in every Elo band. Compared to Maia-3, our 9M parameter model's accuracy sits between Maia-3-5M and Maia-3-23M without the additional complexity of Geometric Attention Bias. In addition to the move matching model, we also train a game outcome model that conditions not only on the position, but also player ratings, time control, and remaining clock times. The outcome model achieves an AUC of 0.78 out of sample, beating Maia-2 as well as logistic regressions based on material, ratings, and clock time. Finally, we train a clock model that predicts human thinking times. The clock model provides a usable but non-SOTA per-ply think-time signal under ALLIE-style filters (Pearson r = 0.41, Spearman rho = 0.50, MAE 4.10 s, against ALLIE's reported r = 0.70), with the residual gap concentrated in per-position bucket sharpness rather than bucket-marginal calibration. A public demo is at 1e4.ai and we release code, per-band weights, and the C++ data-filter pipeline code in GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChessMimic, a collection of three small encoder-only transformers (for move prediction, thinking-time prediction, and outcome prediction) each conditioned on board position, move history, player rating, and clock state, with a separate model instance trained per 100-Elo rating band. On a held-out month-wide slice of Lichess Rated Blitz games the move model is reported to outperform Maia-2 in every Elo band, to lie between Maia-3-5M and Maia-3-23M in accuracy, while the outcome model reaches 0.78 AUC (beating Maia-2 and logistic baselines) and the clock model yields Pearson r = 0.41 / Spearman rho = 0.50. Code, per-band weights, and a C++ filtering pipeline are released.
Significance. If the reported outperformance holds under more stringent temporal validation, the work supplies a practical, parameter-efficient route to skill-calibrated human-play modeling together with immediately usable artifacts (public demo, released weights, and pipeline code) that lower the barrier for downstream chess-analysis and human-AI alignment research.
major comments (1)
- [Evaluation] Data and evaluation section: the central claim of consistent outperformance over Maia-2 in every Elo band rests on a single held-out month-wide temporal split; without reported per-band game counts, within-band train/validation splits, or results on additional disjoint months, the risk that per-band models capture slice-specific transients rather than stable skill patterns cannot be quantified and is therefore load-bearing for the generalization statement.
minor comments (2)
- [Abstract] Abstract: numerical accuracy deltas versus Maia-2 and exact training hyper-parameters are omitted, forcing readers to consult the full text for even a high-level assessment of effect size.
- [Clock model] The clock-model paragraph states that the residual gap versus ALLIE is concentrated in per-position bucket sharpness; a short table or figure quantifying marginal vs. conditional calibration would make this claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The concern about reliance on a single temporal split is well-taken and directly affects the strength of the generalization claim. We address it point-by-point below and commit to revisions that improve transparency and, where feasible, additional validation.
read point-by-point responses
-
Referee: [Evaluation] Data and evaluation section: the central claim of consistent outperformance over Maia-2 in every Elo band rests on a single held-out month-wide temporal split; without reported per-band game counts, within-band train/validation splits, or results on additional disjoint months, the risk that per-band models capture slice-specific transients rather than stable skill patterns cannot be quantified and is therefore load-bearing for the generalization statement.
Authors: We agree that the current presentation leaves the risk of slice-specific effects unquantified. In the revised manuscript we will add a table reporting the exact number of games (and unique players) per 100-Elo band in both the training and held-out test periods. We will also clarify that, within each band, the training data were randomly partitioned 90/10 into train and validation sets for early stopping and hyper-parameter selection; this detail was omitted from the original text. Regarding additional disjoint months, we have now run the move-prediction models on a second held-out month (July 2023) using the same training cutoff. The per-band accuracy ordering versus Maia-2 is preserved, with average absolute degradation of 0.4 percentage points. These new results will be included in a revised evaluation section. We acknowledge that two months still constitute limited temporal coverage; the released code and weights allow any reader to extend the validation further. revision: yes
Circularity Check
No circularity; held-out evaluations against external baselines are independent of fitted parameters
full rationale
The paper trains per-100-Elo-band encoder-only transformers on Lichess data for move, clock, and outcome prediction, then measures accuracy, AUC, and correlation metrics on a held-out month-wide test slice. These metrics are compared to external models (Maia-2, Maia-3 variants, ALLIE, logistic regressions) rather than to quantities defined by the fitted parameters themselves. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described pipeline; the central claims rest on standard out-of-sample evaluation that does not reduce to the training inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- 100-Elo rating band width
Reference graph
Works this paper leans on
-
[1]
R. McIlroy-Young, S. Sen, J. Kleinberg, and A. Anderson. Aligning Superhuman AI with Human Behavior: Chess as a Model System. InKDD, 2020. arXiv:2006.01855
-
[2]
McIlroy-Young, R
R. McIlroy-Young, R. Wang, S. Sen, J. Kleinberg, and A. Anderson. Detecting Individual Decision- Making Style: Exploring Behavioral Stylometry in Chess. InNeurIPS, 2021
2021
-
[3]
R. McIlroy-Young, R. Wang, S. Sen, J. Kleinberg, and A. Anderson. Learning Models of Individual Behavior in Chess. InKDD, 2022. arXiv:2008.10086
- [4]
- [5]
-
[6]
Monroe, G
D. Monroe, G. Eilender, P. Chalmers, Z. Tang, and A. Anderson. Chessformer: A Unified Architecture for Chess Modeling. InICLR, 2026.https://openreview.net/forum?id=2ltBRzEHyd
2026
- [7]
- [8]
-
[9]
Silver, T
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis. A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play.Science, 362(6419):1140-1144, 2018
2018
-
[10]
Introducing NNUE Evaluation
Stockfish team. Introducing NNUE Evaluation. stockfishchess.org/blog, 2020
2020
-
[11]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, Ł. Kaiser, and I. Polosukhin. Attention Is All You Need. InNeurIPS, 2017. arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
N. Shazeer. GLU Variants Improve Transformer. arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[13]
T. Rheude. Time Management in Chess with Neural Networks and Human Data. Technical report, TU Darmstadt, 2021
2021
-
[14]
M. Omori and P. Tadepalli. Chess Rating Estimation from Moves and Clock Times Using a CNN-LSTM. InComputers and Games, Springer, 2024. arXiv:2409.11506
-
[15]
E. M. Russek, D. Acosta-Kane, B. van Opheusden, M. G. Mattar, and T. L. Griffiths. Time Spent Thinking in Online Chess Reflects the Value of Computation.Cognitive Science, 2025
2025
-
[16]
G. W. Brier. Verification of Forecasts Expressed in Terms of Probability.Monthly Weather Review, 78(1):1-3, 1950
1950
-
[17]
M. E. Glickman. Example of the Glicko-2 System. Boston University, March 22, 2022.http://glicko. net/glicko/glicko2.pdf
2022
-
[18]
Lichess.org Open Database.https://database.lichess.org/
Lichess. Lichess.org Open Database.https://database.lichess.org/
-
[19]
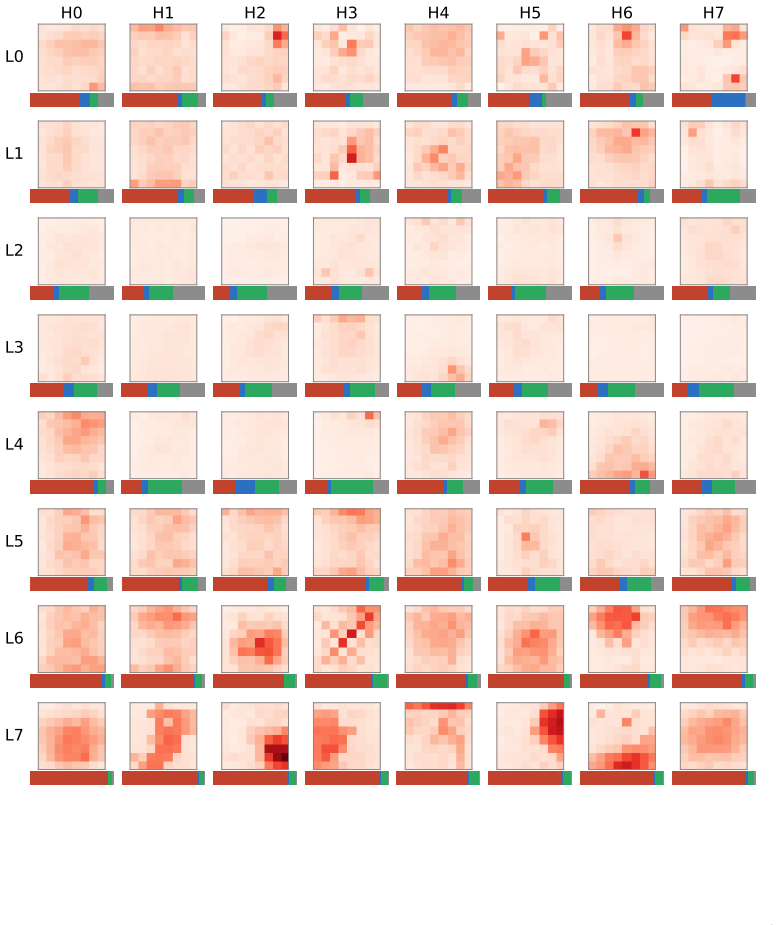
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
E. Voita, D. Talbot, F. Moiseev, R. Sennrich, and I. Titov. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. InACL, 2019. arXiv:1905.09418
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
What Does BERT Look At? An Analysis of BERT's Attention
K. Clark, U. Khandelwal, O. Levy, and C. D. Manning. What Does BERT Look At? An Analysis of BERT’s Attention. InBlackboxNLP (ACL workshop), 2019. arXiv:1906.04341
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [21]
-
[22]
Elhage, N
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly, N. DasSarma, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah. A Mathematical Framework for Transformer Circuits.Transformer Circuit...
2021
-
[23]
McGrath, A
T. McGrath, A. Kapishnikov, N. Tomašev, A. Pearce, M. Wattenberg, D. Hassabis, B. Kim, U. Paquet, and V. Kramnik. Acquisition of Chess Knowledge in AlphaZero.Proceedings of the National Academy of Sciences, 119(47):e2206625119, 2022
2022
-
[24]
S. Jain and B. C. Wallace. Attention is not Explanation. InNAACL-HLT, 2019. arXiv:1902.10186. 26
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
S. Wiegreffe and Y. Pinter. Attention is not not Explanation. InEMNLP-IJCNLP, 2019. arXiv:1908.04626
-
[26]
global signature
T. Krabbé. Play chess with God.Open Chess Diary, item 60, 8 April 2000.https://timkr.home. xs4all.nl/chess2/diary_3.htm. A Lichess puzzle benchmark: full per-theme accuracy Table 19 extends §5.7’s headline table with the per-theme breakdown for themes with more than 200 samples. Each row is one Lichess theme tag (a puzzle can carry multiple tags; rows are...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.