Natural Ungrokking: Asymmetric Control of Which Rules Survive Pretraining
Pith reviewed 2026-06-25 19:02 UTC · model grok-4.3
The pith
Support frequency in the training stream decides which rules survive pretraining, and control is asymmetric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
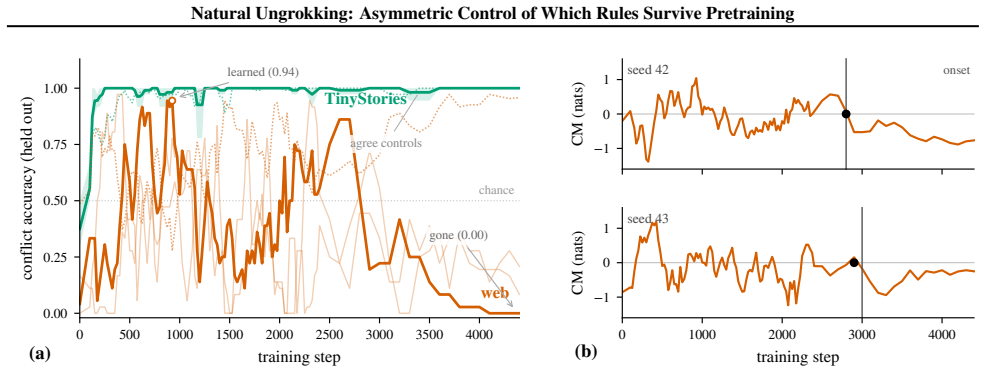
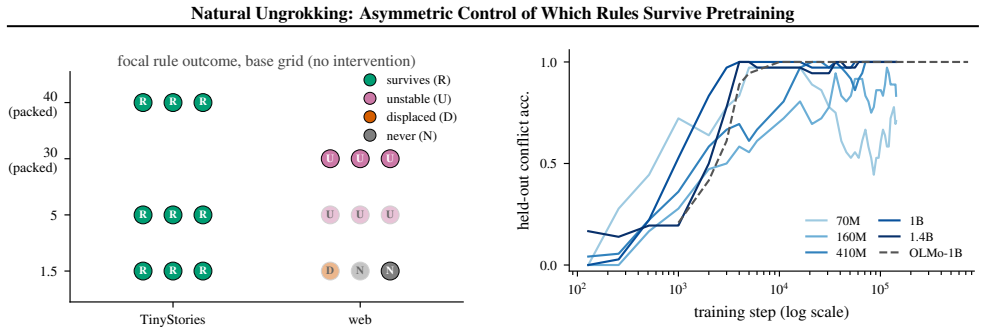
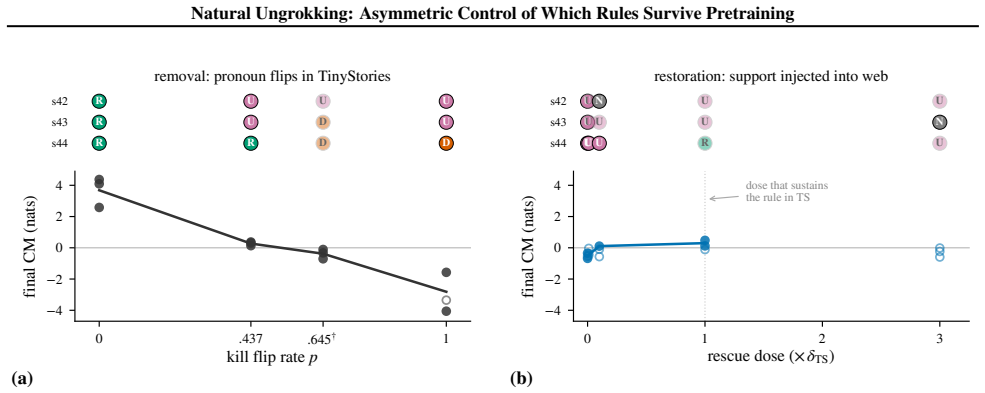
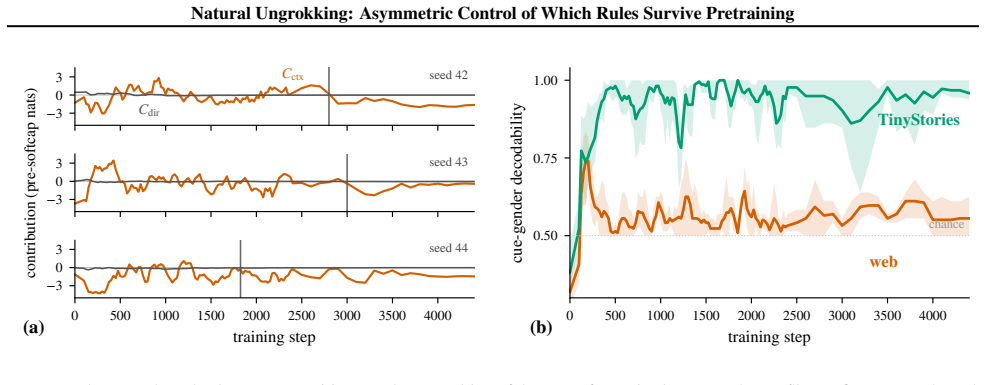
The paper establishes that natural ungrokking occurs when a learned rule collapses during continued pretraining despite persistent evidence in the corpus, and that survival is governed by support frequency—the rate at which the training stream shows the rule winning. This frequency determines the rule's fate across un-intervened runs, while the forgetting itself is a displacement in which a competing pattern's log-probability margin crosses zero near the behavioral collapse. Control is asymmetric: the same edit that introduces counter-evidence destroys the rule monotonically, but injecting support back fails to restore it even at 450 times the sustaining level. The pattern also appears in pu
What carries the argument
support frequency: the proportion of training examples in which a given rule wins against competitors, which determines whether the rule is retained or displaced.
If this is right
- The data-to-parameter ratio modulates collapse depth for doomed rules but does not alter which rules survive.
- The same emerge-then-collapse dynamics appear in Pythia checkpoints with depth ordered by model scale.
- Introducing counter-evidence kills a rule with monotone dose-response across unrelated rules.
- Injecting support fails to recover a collapsed rule even at 450 times the natural sustaining level.
Where Pith is reading between the lines
- Curating training streams to raise support frequency for desired rules could selectively preserve specific behaviors without changing model scale.
- The same frequency-based competition may explain why some facts persist while others are overwritten in larger web-trained models.
- The asymmetry suggests prevention of unwanted rule acquisition during training is more tractable than post-hoc correction.
Load-bearing premise
The observed collapse on held-out probes reflects genuine displacement of the rule by a competing pattern rather than changes in probe sensitivity or other unmeasured dynamics.
What would settle it
A rule whose support frequency exceeds that of its competitor still collapses on probes, or high-level support injection after collapse restores probe performance above baseline.
Figures
read the original abstract
Midway through an ordinary pretraining run, a small language model learns the pronoun-gender rule: cued with a girl's name ("Sue cried because"), it resolves the next pronoun to she, generalizing to held-out probes (0.94 by step 925). By step 3,500 the same model scores near zero on the same probes, although the rule's evidence is still in the training data. We call this within-run reversal natural ungrokking: the corpus decides, with no trace in the loss curve, which learned rules a model keeps. Which rules survive is predictable from one corpus statistic: how often the training stream shows the rule winning. Across un-intervened runs (two corpora, three budgets, three seeds), support frequency decides a rule's fate; the data-to-parameter ratio only modulates how deeply a doomed rule falls. The same emerge-then-collapse dynamics appear in public Pythia checkpoints, collapse depth ordered by model scale as predicted. The forgetting is a displacement: a competing surface pattern out-competes the rule, and the log-probability margin between them crosses zero within 100 training steps of the behavioral collapse. Control over this fate is asymmetric: the same edit that destroys a rule on demand cannot restore it. Flipping support to counter-evidence in place kills the rule with monotone dose-response in two unrelated rules; but injecting support back, even to 450 times the level that naturally sustains it, buys no recovery. Every confirmatory threshold and prediction was pre-registered before the data it governed was read.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the phenomenon of 'natural ungrokking' during language model pretraining: models learn rules such as pronoun-gender resolution (reaching 0.94 accuracy on held-out probes) that then collapse to near-zero despite the rule's evidence remaining in the training data. Survival of rules is claimed to be predictable from a single independent corpus statistic (support frequency, i.e., how often the training stream shows the rule winning), with the data-to-parameter ratio only modulating collapse depth; this is shown across two corpora, three budgets, three seeds, replicated on public Pythia checkpoints, and with asymmetric control via support interventions. All confirmatory thresholds and predictions were pre-registered.
Significance. If the displacement interpretation holds, the work identifies a corpus-statistic predictor for rule persistence that operates without loss-curve signatures and demonstrates asymmetric editability of learned rules. Credit is due for the pre-registered predictions, consistent results across un-intervened runs and public checkpoints, and the explicit measurement of log-probability margins crossing zero near collapse.
major comments (2)
- [Abstract] Abstract: the central claim that behavioral collapse on held-out probes reflects genuine displacement (rather than probe sensitivity drift or representation shift) is load-bearing for both the support-frequency predictability result and the asymmetric-control findings. The abstract asserts that 'the rule's evidence remains in the training data' and that 'the log-probability margin between them crosses zero within 100 training steps,' yet provides no explicit controls such as re-testing on original training instances containing the evidence or ablation of probe formatting to rule out changes in probe sensitivity.
- [Intervention experiments] Intervention results: the monotone dose-response for rule destruction via counter-evidence injection is presented as decisive, but the manuscript does not report whether the edited support frequency was measured on the same independent corpus statistic used for the un-intervened runs, leaving open whether the asymmetry result could be an artifact of how the interventions alter the overall training distribution.
minor comments (2)
- [Abstract] The abstract states results are consistent across 'two corpora, three budgets, three seeds' but does not specify the exact statistical test or threshold used for 'decides a rule's fate'; this detail belongs in the main text or a methods appendix.
- [Pythia replication section] Replication on Pythia checkpoints is a strength, but the manuscript should clarify whether the support-frequency statistic was computed from the original training stream or approximated from the released data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the need for explicit validation of the displacement claim and intervention measurements. We address each major comment below and commit to revisions where the manuscript requires clarification or additional reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that behavioral collapse on held-out probes reflects genuine displacement (rather than probe sensitivity drift or representation shift) is load-bearing for both the support-frequency predictability result and the asymmetric-control findings. The abstract asserts that 'the rule's evidence remains in the training data' and that 'the log-probability margin between them crosses zero within 100 training steps,' yet provides no explicit controls such as re-testing on original training instances containing the evidence or ablation of probe formatting to rule out changes in probe sensitivity.
Authors: We agree the abstract is concise and does not enumerate controls. The main text supports the displacement interpretation via direct measurement of the log-probability margin between the rule and competing surface pattern, which crosses zero near collapse, and by confirming the rule's evidence persists in the corpus. However, the manuscript does not report re-testing on original training instances or probe-formatting ablations. We will add these controls (re-testing on evidence-containing instances and probe ablations) to the revised manuscript and update the abstract to reference them. This strengthens the claim without altering the pre-registered predictions. revision: yes
-
Referee: [Intervention experiments] Intervention results: the monotone dose-response for rule destruction via counter-evidence injection is presented as decisive, but the manuscript does not report whether the edited support frequency was measured on the same independent corpus statistic used for the un-intervened runs, leaving open whether the asymmetry result could be an artifact of how the interventions alter the overall training distribution.
Authors: The interventions were constructed to modify support frequency using the identical definition and independent corpus statistic applied to the un-intervened runs. Post-edit support frequencies were verified on that same statistic to confirm the target levels were achieved. The asymmetry (destruction succeeds; restoration fails even at 450x natural support) is therefore tied to the same predictor. The manuscript does not explicitly state this verification step for the edited runs. We will add a dedicated paragraph in the methods and results sections reporting the post-intervention measurements on the independent corpus to eliminate any ambiguity. revision: yes
Circularity Check
No circularity: support frequency measured independently from corpus; survival outcome not used to define or fit it.
full rationale
The paper's central claim is that rule survival is predicted by an independently measured corpus statistic (support frequency, i.e., how often the training stream shows the rule winning). This statistic is extracted directly from the training data stream before observing outcomes. Behavioral collapse on probes is treated as the dependent variable, not fed back into the statistic. Pre-registration of thresholds and predictions is stated explicitly. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The derivation remains self-contained against external benchmarks (multiple corpora, seeds, Pythia checkpoints).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Held-out behavioral probes accurately reflect whether the model has retained the pronoun-gender rule.
Reference graph
Works this paper leans on
-
[1]
Critical learning periods in deep networks
Achille, A., Rovere, M., and Soatto, S. Critical learning periods in deep networks. In International Conference on Learning Representations, 2019. arXiv:1711.08856
Pith/arXiv arXiv 2019
-
[2]
Biderman, S., Schoelkopf, H., Anthony, Q., Bradley, H., O'Brien, K., Hallahan, E., Khan, M. A., Purohit, S., Prashanth, U. S., Raff, E., Skowron, A., Sutawika, L., and van der Wal, O. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, 2023. arXiv:2304.01373
Pith/arXiv arXiv 2023
-
[3]
C., Xu, P., Och, F
Brants, T., Popat, A. C., Xu, P., Och, F. J., and Dean, J. Large language models in machine translation. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), pp.\ 858--867, 2007
2007
-
[4]
Chang, T. A. and Bergen, B. K. Word acquisition in neural language models. Transactions of the Association for Computational Linguistics, 10: 0 1--16, 2022. doi:10.1162/tacl_a_00444
-
[5]
and Tu, Zhuowen and Bergen, Benjamin K
Chang, T. A., Tu, Z., and Bergen, B. K. Characterizing learning curves during language model pre-training: Learning, forgetting, and stability. Transactions of the Association for Computational Linguistics, 12: 0 1346--1362, 2024. doi:10.1162/tacl_a_00708
-
[6]
Chen, A., Shwartz-Ziv, R., Cho, K., Leavitt, M. L., and Saphra, N. Sudden drops in the loss: Syntax acquisition, phase transitions, and simplicity bias in mlms. In International Conference on Learning Representations, 2024. arXiv:2309.07311
arXiv 2024
-
[7]
The grammar-learning trajectories of neural language models
Choshen, L., Hacohen, G., Weinshall, D., and Abend, O. The grammar-learning trajectories of neural language models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 2022
2022
-
[8]
Diao, S., Yang, Y., Fu, Y., Dong, X., Su, D., Kliegl, M., Chen, Z., Belcak, P., Suhara, Y., Yin, H., Patwary, M., Lin, Y., Kautz, J., and Molchanov, P. Nemotron-climb: Clustering-based iterative data mixture bootstrapping for language model pre-training. arXiv preprint arXiv:2504.13161, 2025
Pith/arXiv arXiv 2025
-
[9]
Eldan, R. and Li, Y. Tinystories: How small can language models be and still speak coherent english? arXiv preprint arXiv:2305.07759, 2023
Pith/arXiv arXiv 2023
-
[10]
A mathematical framework for transformer circuits
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021. https://transformer-circuits.pub/2021/framework/index.html
2021
-
[11]
G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram \'e , A., et al
Gemma Team , Rivi \`e re, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram \'e , A., et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024
Pith/arXiv arXiv 2024
-
[12]
H., Ivison, H., Magnusson, I., Wang, Y., et al
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., Jha, A. H., Ivison, H., Magnusson, I., Wang, Y., et al. Olmo: Accelerating the science of language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024. arXiv:2402.00838
Pith/arXiv arXiv 2024
-
[13]
A., Welbl, J., Clark, A., et al
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022
Pith/arXiv arXiv 2022
-
[14]
The developmental landscape of in-context learning
Hoogland, J., Wang, G., Farrugia-Roberts, M., Carroll, L., Wei, S., and Murfet, D. The developmental landscape of in-context learning. arXiv preprint arXiv:2402.02364, 2024
arXiv 2024
-
[15]
Measuring forgetting of memorized training examples
Jagielski, M., Thakkar, O., Tram \`e r, F., Ippolito, D., Lee, K., Carlini, N., Wallace, E., Song, S., Thakurta, A., Papernot, N., and Zhang, C. Measuring forgetting of memorized training examples. arXiv preprint arXiv:2207.00099, 2022
arXiv 2022
-
[16]
Muon: An optimizer for hidden layers in neural networks
Jordan, K., Jin, Y., Boza, V., You, J., Cesista, F., Newhouse, L., and Bernstein, J. Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/posts/muon/, 2024
2024
-
[17]
Large language models struggle to learn long-tail knowledge
Kandpal, N., Deng, H., Roberts, A., Wallace, E., and Raffel, C. Large language models struggle to learn long-tail knowledge. In International Conference on Machine Learning, 2023
2023
-
[18]
nanochat
Karpathy, A. nanochat. https://github.com/karpathy/nanochat, 2025
2025
-
[19]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., and Hadsell, R. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114 0 (13): 0 3521--3526, 2017. arXiv:1612.00796
arXiv 2017
-
[20]
Sparse crosscoders for cross-layer features and model diffing
Lindsey, J., Templeton, A., Marcus, J., Conerly, T., Batson, J., and Olah, C. Sparse crosscoders for cross-layer features and model diffing. Transformer Circuits Thread, 2024. URL https://transformer-circuits.pub/2024/crosscoders/index.html
2024
-
[21]
J., Tegmark, M., and Williams, M
Liu, Z., Kitouni, O., Nolte, N., Michaud, E. J., Tegmark, M., and Williams, M. Towards understanding grokking: An effective theory of representation learning. In Advances in Neural Information Processing Systems, 2022
2022
-
[22]
Liu, Z., Michaud, E. J., and Tegmark, M. Omnigrok: Grokking beyond algorithmic data. In International Conference on Learning Representations, 2023. arXiv:2210.01117
arXiv 2023
-
[23]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019
2019
-
[24]
Gender bias in neural natural language processing
Lu, K., Mardziel, P., Wu, F., Amancharla, P., and Datta, A. Gender bias in neural natural language processing. In Logic, Language, and Security. Springer, 2020
2020
-
[25]
Locating and editing factual associations in GPT
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems, 2022
2022
-
[26]
Misra, K. and Mahowald, K. Language models learn rare phenomena from less rare phenomena: The case of the missing AANNs . arXiv preprint arXiv:2403.19827, 2024
arXiv 2024
-
[27]
M., Barak, B., Le Scao, T., Piktus, A., Tazi, N., Pyysalo, S., Wolf, T., and Raffel, C
Muennighoff, N., Rush, A. M., Barak, B., Le Scao, T., Piktus, A., Tazi, N., Pyysalo, S., Wolf, T., and Raffel, C. Scaling data-constrained language models. In Advances in Neural Information Processing Systems, 2023. arXiv:2305.16264
Pith/arXiv arXiv 2023
-
[28]
Grokking of Hierarchical Structure in Vanilla Transformers
Murty, S., Sharma, P., Andreas, J., and Manning, C. Grokking of hierarchical structure in vanilla transformers. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 439--448, 2023. doi:10.18653/v1/2023.acl-short.38
-
[29]
Progress measures for grokking via mechanistic interpretability
Nanda, N., Chan, L., Lieberum, T., Smith, J., and Steinhardt, J. Progress measures for grokking via mechanistic interpretability. In International Conference on Learning Representations, 2023. arXiv:2301.05217
Pith/arXiv arXiv 2023
-
[30]
In-context learning and induction heads
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., et al. In-context learning and induction heads. Transformer Circuits Thread, 2022. arXiv:2209.11895
Pith/arXiv arXiv 2022
-
[31]
Filtered Corpus Training ( F i CT ) Shows that Language Models Can Generalize from Indirect Evidence
Patil, A., Jumelet, J., Chiu, Y. Y., Lapastora, A., Shen, P., Wang, L., Willrich, C., and Steinert-Threlkeld, S. Filtered corpus training ( FiCT ) shows that language models can generalize from indirect evidence. Transactions of the Association for Computational Linguistics, 12: 0 1597--1615, 2024. doi:10.1162/tacl_a_00720
-
[32]
Grokking: Generalization beyond overfitting on small algorithmic datasets
Power, A., Burda, Y., Edwards, H., Babuschkin, I., and Misra, V. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022
Pith/arXiv arXiv 2022
-
[33]
Schaeffer, R., Miranda, B., and Koyejo, S. Are emergent abilities of large language models a mirage? In Advances in Neural Information Processing Systems, 2023. arXiv:2304.15004
arXiv 2023
-
[34]
Neural machine translation of rare words with subword units
Sennrich, R., Haddow, B., and Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016
2016
-
[35]
Singh, A. K., Chan, S. C., Moskovitz, T., Grant, E., Saxe, A. M., and Hill, F. The transient nature of emergent in-context learning in transformers. In Advances in Neural Information Processing Systems, 2023. arXiv:2311.08360
arXiv 2023
-
[36]
H., Zettlemoyer, L., and Aghajanyan, A
Tirumala, K., Markosyan, A. H., Zettlemoyer, L., and Aghajanyan, A. Memorization without overfitting: Analyzing the training dynamics of large language models. In Advances in Neural Information Processing Systems, 2022. arXiv:2205.10770
arXiv 2022
-
[37]
T., Trischler, A., Bengio, Y., and Gordon, G
Toneva, M., Sordoni, A., des Combes, R. T., Trischler, A., Bengio, Y., and Gordon, G. J. An empirical study of example forgetting during deep neural network learning. In International Conference on Learning Representations, 2019. arXiv:1812.05159
arXiv 2019
-
[38]
Explaining grokking through circuit efficiency
Varma, V., Shah, R., Kenton, Z., Kram \'a r, J., and Kumar, R. Explaining grokking through circuit efficiency. arXiv preprint arXiv:2309.02390, 2023
arXiv 2023
-
[39]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, 2017
2017
-
[40]
Investigating gender bias in language models using causal mediation analysis
Vig, J., Gehrmann, S., Belinkov, Y., Qian, S., Nevo, D., Singer, Y., and Shieber, S. Investigating gender bias in language models using causal mediation analysis. In Advances in Neural Information Processing Systems, 2020
2020
-
[41]
Differentiation and specialization of attention heads via the refined local learning coefficient
Wang, G., Hoogland, J., van Wingerden, S., Furman, Z., and Murfet, D. Differentiation and specialization of attention heads via the refined local learning coefficient. arXiv preprint arXiv:2410.02984, 2024
arXiv 2024
-
[42]
Warstadt, A., Parrish, A., Liu, H., Mohananey, A., Peng, W., Wang, S.-F., and Bowman, S. R. Blimp: The benchmark of linguistic minimal pairs for english. Transactions of the Association for Computational Linguistics, 8: 0 377--392, 2020 a . arXiv:1912.00582
arXiv 2020
-
[43]
Warstadt, A., Zhang, Y., Li, X., Liu, H., and Bowman, S. R. Learning which features matter: RoBERTa acquires a preference for linguistic generalizations (eventually). In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pp.\ 217--235, 2020 b . doi:10.18653/v1/2020.emnlp-main.16
-
[44]
Frequency effects on syntactic rule learning in transformers
Wei, J., Garrette, D., Linzen, T., and Pavlick, E. Frequency effects on syntactic rule learning in transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 932--948, 2021. doi:10.18653/v1/2021.emnlp-main.72
-
[45]
H., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., and Fedus, W
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., Chi, E. H., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., and Fedus, W. Emergent abilities of large language models. Transactions on Machine Learning Research, 2022. arXiv:2206.07682
Pith/arXiv arXiv 2022
-
[46]
M., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P., Le, Q
Xie, S. M., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P., Le, Q. V., Ma, T., and Yu, A. W. Doremi: Optimizing data mixtures speeds up language model pretraining. In Advances in Neural Information Processing Systems, 2023. arXiv:2305.10429
arXiv 2023
-
[47]
Gender bias in coreference resolution: Evaluation and debiasing methods
Zhao, J., Wang, T., Yatskar, M., Ordonez, V., and Chang, K.-W. Gender bias in coreference resolution: Evaluation and debiasing methods. In Proceedings of NAACL-HLT, 2018
2018
-
[48]
How do language models learn facts? dynamics, curricula and hallucinations
Zucchet, N., Bornschein, J., Chan, S., Lampinen, A., Pascanu, R., and De, S. How do language models learn facts? dynamics, curricula and hallucinations. arXiv preprint arXiv:2503.21676, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.