Automating Formal Verification with Reinforcement Learning and Recursive Inference
Pith reviewed 2026-06-28 23:50 UTC · model grok-4.3
The pith
Reinforcement learning from verifier rewards and recursive inference raise verified pass rates on Dafny and Lean tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
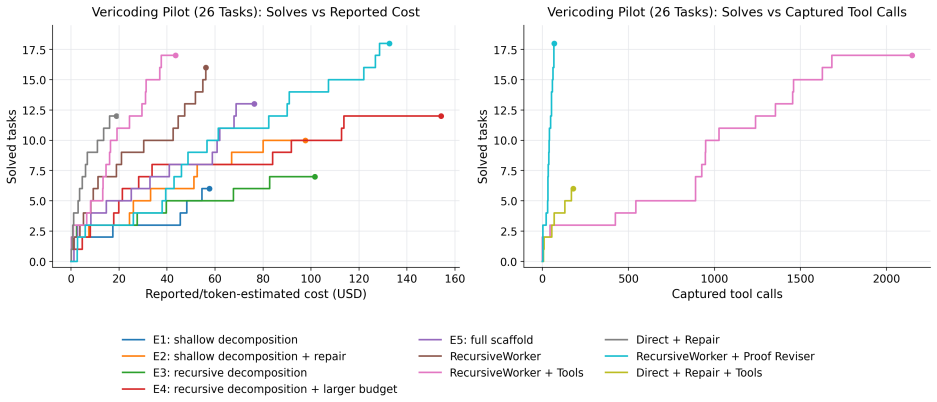
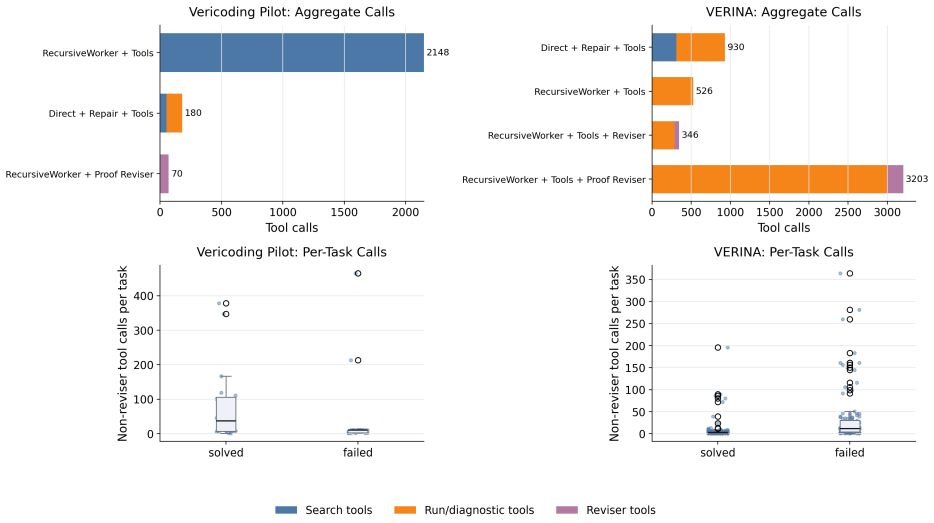
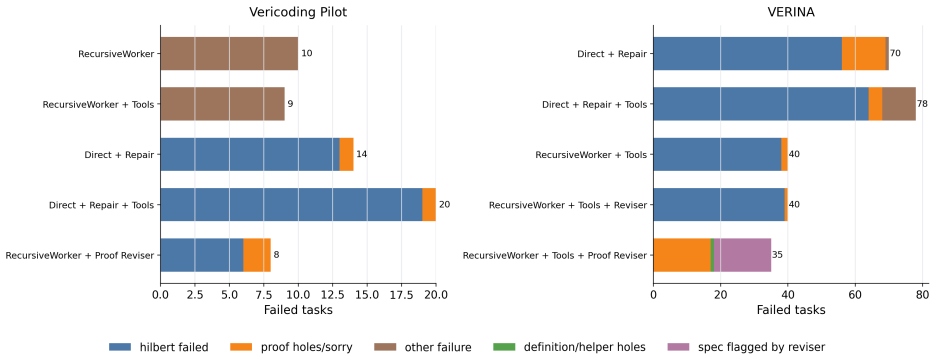
The paper claims that multi-turn RLVR with GRPO on a refined Dafny benchmark lifts verified pass rate from 9.7% to 31.1%, while a fixed-base-model verifier-guided scaffold with whole-task decomposition and proof reviser raises Lean pass rate from 46.2% under direct repair to 69.2% and solves 7 of 42 previously unsolved tasks on the VERINA dataset.
What carries the argument
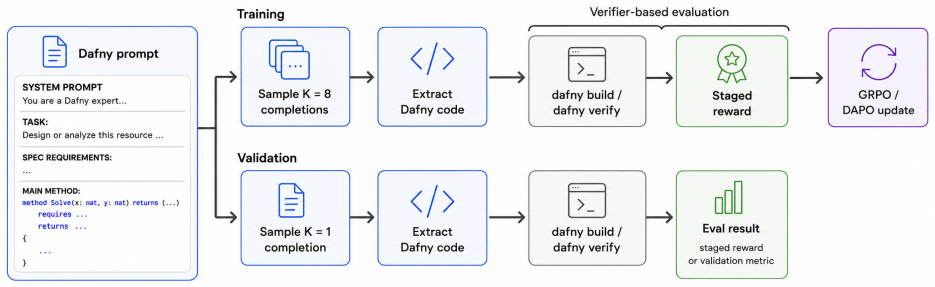
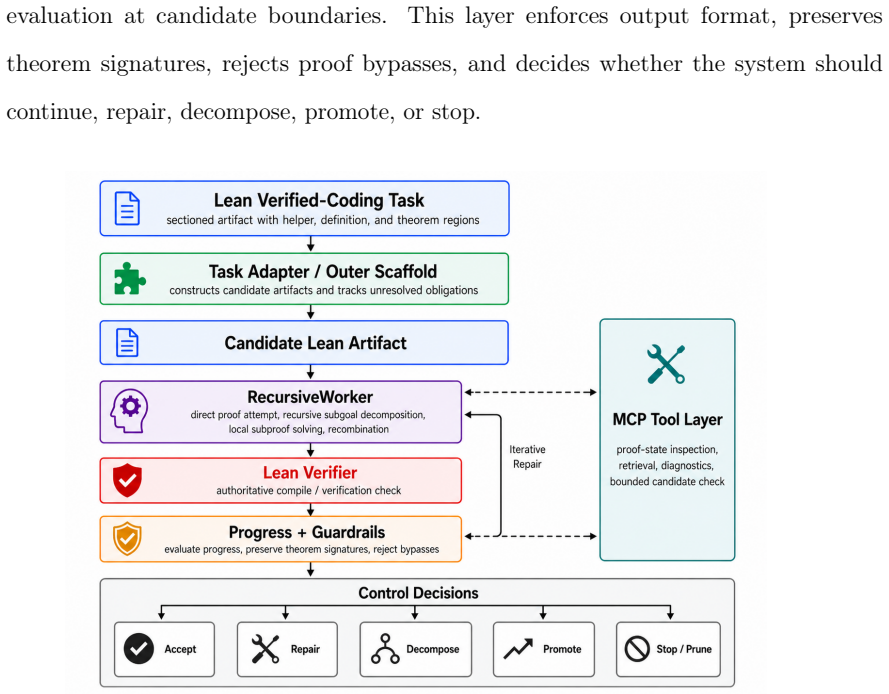
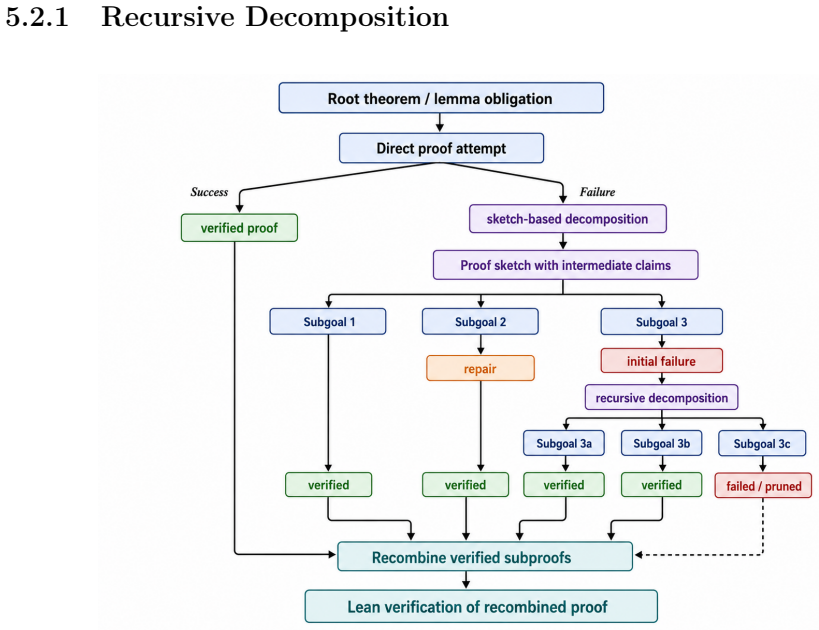
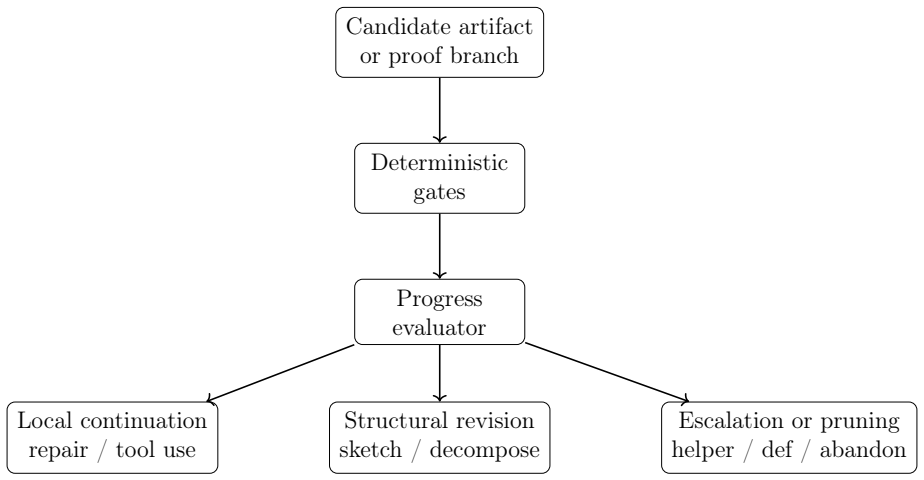
Verifier-guided reinforcement learning from compiler and verifier outcomes together with a recursive inference scaffold that decomposes proofs and applies a reviser on feedback.
If this is right
- Open-source models reach higher verified reward and pass rates when trained with multi-turn RLVR after dataset refinement.
- Whole-task decomposition plus proof reviser enables solving tasks that direct generation or repair leave unsolved.
- Repository-scale Lean benchmarks remain difficult and require stronger progress evaluation and tool-use policies.
- Specification hacking can be reduced by explicit filtering of weak tasks before RLVR training.
Where Pith is reading between the lines
- The same reward-signal loop could be applied to other proof assistants if they expose comparable compiler and verifier feedback.
- New benchmarks that avoid post-hoc filtering would test whether the reported gains generalize beyond the refined task distribution.
- Combining the RLVR training loop with the inference scaffold in one system might compound the separate gains observed here.
Load-bearing premise
Filtering underspecified and vulnerable tasks from the dataset still produces a benchmark that measures intended verification capability rather than selection effects.
What would settle it
Re-evaluating the same models on the original unfiltered APPS-derived Dafny dataset or on a fresh set of verification tasks drawn without the same filtering criteria would show whether the pass-rate gains hold or shrink.
Figures
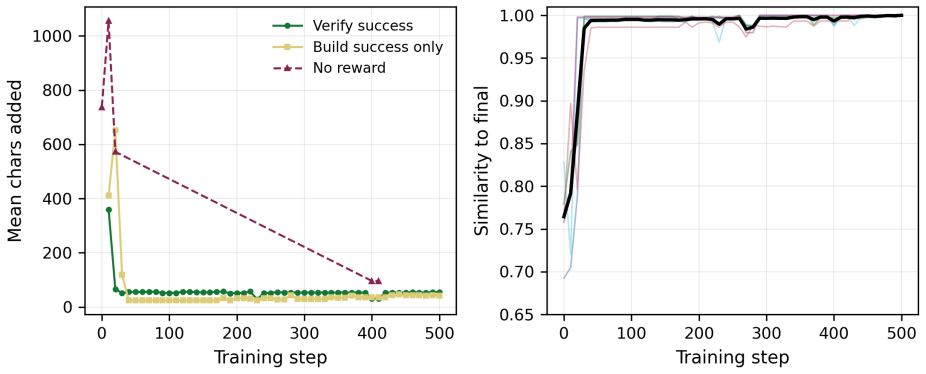
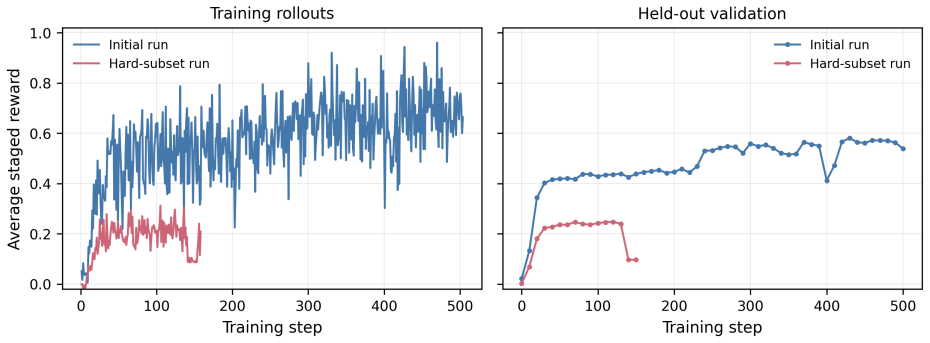
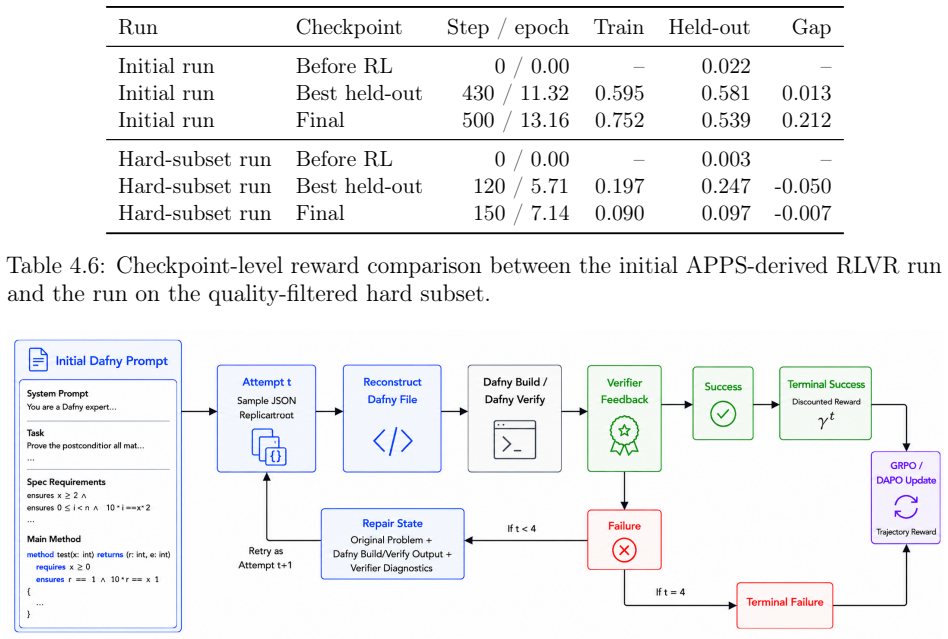
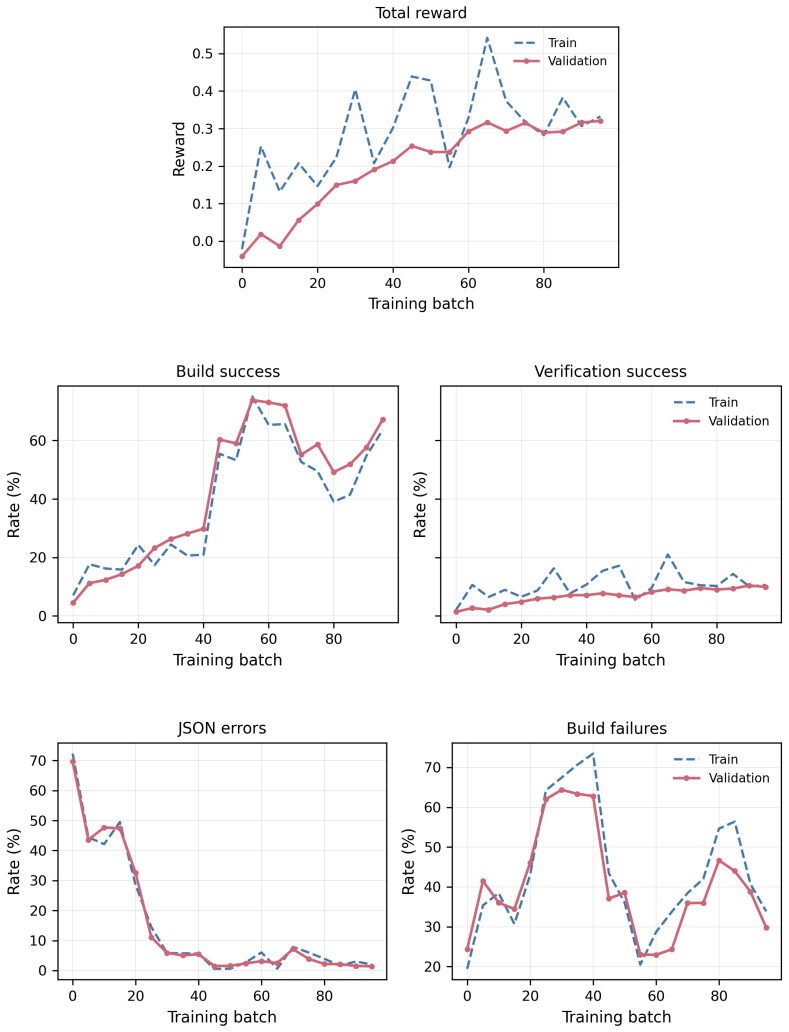
read the original abstract
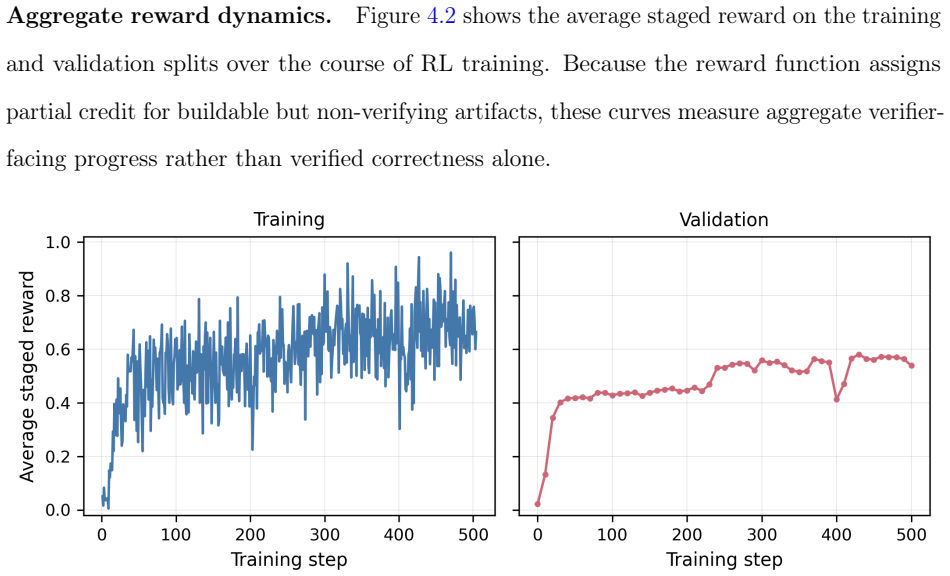
Automated formal verification remains challenging for large language models because data for proof assistants and verification-aware languages is scarce, and correctness depends on satisfying precise machine-checkable specifications rather than producing plausible code. This thesis studies how verifier environments can improve LLM generation of verified programs and proofs through reinforcement learning from verifiable rewards (RLVR) and verifier-guided inference-time search. First, we train open-source models in Dafny with RLVR using Group Relative Policy Optimization (GRPO) and related variants, assembling generated candidates into complete programs and scoring them with compiler and verifier outcomes. Initial experiments on an APPS-derived Dafny dataset increased verified reward from 2.2% to 58.1%, but revealed specification hacking, where models exploit weak formal specifications instead of implementing the intended solutions. After filtering underspecified and vulnerable tasks, multi-turn RLVR on the refined benchmark improves the verified pass rate from 9.7% to 31.1%. Second, we develop a verifier-guided inference scaffold in Lean that treats proof generation as structured search over decomposed subgoals, verifier feedback, diagnostics, and repair. With a fixed base model, the full scaffold with proof reviser improves pass rate on an initial VeriCoding pilot set from 46.2% under direct repair to 69.2%. On the larger VERINA dataset, whole-task decomposition plus proof reviser solves 7 of 42 previously unsolved tasks. We also introduce Dalek-Bench, a repository-scale Lean benchmark derived from the Rust $\texttt{curve25519-dalek}$ verification project; preliminary results remain weak, indicating that stronger progress evaluation and task-specific tool-use policies are still needed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates using reinforcement learning from verifiable rewards (RLVR) with Group Relative Policy Optimization (GRPO) to train LLMs on Dafny program generation from an APPS-derived dataset, initially raising verified reward from 2.2% to 58.1% before addressing specification hacking via task filtering; on the refined benchmark, multi-turn RLVR lifts verified pass rate from 9.7% to 31.1%. It further develops a verifier-guided inference scaffold for Lean that decomposes proofs, incorporates feedback and repair, raising pass rate from 46.2% to 69.2% on a VeriCoding pilot with a fixed base model and solving 7 of 42 previously unsolved tasks on VERINA, while introducing the Dalek-Bench repository-scale Lean benchmark.
Significance. If the reported gains prove robust, the work would supply concrete empirical evidence that RLVR and structured verifier-guided search can measurably advance LLM performance on machine-checkable formal verification tasks despite scarce training data. The specific percentage improvements and new benchmark provide falsifiable progress markers in an applied ML-for-formal-methods setting.
major comments (1)
- [Abstract (Dafny RLVR paragraph)] Abstract (Dafny RLVR paragraph): the central claim that multi-turn RLVR improves verified pass rate from 9.7% to 31.1% on the refined benchmark is load-bearing for the paper's empirical contribution, yet the filtering of underspecified and vulnerable tasks lacks any quantitative comparison of difficulty metrics, pass-rate statistics, or task distributions between the original and retained sets; without this, the observed delta cannot be confidently attributed to RLVR rather than curation effects.
minor comments (2)
- [Abstract] Abstract: the manuscript reports concrete numerical improvements without accompanying error bars, full experimental protocols, or statements on data/code availability, which would be required for reproducibility assessment even if the filtering concern is resolved.
- [Abstract] Abstract: the Lean scaffold description would benefit from explicit definition of 'whole-task decomposition' and 'proof reviser' components before reporting the 69.2% and 7/42 figures.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comment. We address the major concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (Dafny RLVR paragraph)] Abstract (Dafny RLVR paragraph): the central claim that multi-turn RLVR improves verified pass rate from 9.7% to 31.1% on the refined benchmark is load-bearing for the paper's empirical contribution, yet the filtering of underspecified and vulnerable tasks lacks any quantitative comparison of difficulty metrics, pass-rate statistics, or task distributions between the original and retained sets; without this, the observed delta cannot be confidently attributed to RLVR rather than curation effects.
Authors: We agree that additional quantitative details on the filtering step would help readers isolate the contribution of RLVR. The reported 9.7% to 31.1% delta is measured on the identical refined benchmark (i.e., the baseline and post-RLVR results use the same task set), so the improvement cannot be explained by differences in the task distribution before versus after training. Nevertheless, to address the concern about curation effects on the overall empirical narrative, the revised manuscript will add: (1) the number and percentage of tasks filtered, (2) comparative statistics on proxies for difficulty such as specification length and assertion count between original and retained sets, and (3) base-model pass-rate distributions on both sets. These additions will clarify that filtering targeted specification-hacking vulnerabilities without systematically reducing task difficulty. revision: yes
Circularity Check
No circularity: empirical RL training and benchmark results on external verifiers
full rationale
The paper reports measured improvements in verified pass rates from RLVR training (GRPO) and inference scaffolds on APPS-derived Dafny and VERINA/Lean benchmarks. All claims are empirical outcomes scored by external compiler/verifier feedback; no equations, derivations, or 'predictions' are presented that reduce by construction to fitted parameters, self-defined quantities, or self-citation chains. Filtering of tasks is a preprocessing choice whose effect is evaluated on the retained set, not a definitional loop. No load-bearing uniqueness theorems or ansatzes are invoked.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Verifier feedback provides a reliable and non-hackable reward signal for policy optimization
- domain assumption Decomposed subgoals plus diagnostic repair improve proof search over direct generation
Reference graph
Works this paper leans on
-
[1]
en.url: https://www.anthropic
Detecting and countering misuse of AI: August 2025. en.url: https://www.anthropic. com/news/detecting-countering-misuse-aug-2025?utm_source=chatgpt.com (visited on 04/30/2026)
2025
-
[2]
SentinelOne.How SentinelOne’s AI EDR Autonomously Discovered and Stopped Anthropic’s Claude from Executing a Zero Day Supply Chain Attack, Globally. en. Mar. 2026.url: https://www.sentinelone.com/blog/how-sentinelones-ai-edr-autonomously- discovered-and-stopped-anthropics-claude-from-executing-a-zero-day-supply-chain- attack-globally/ (visited on 05/05/2026)
2026
-
[3]
en.url: https://codewall.ai/blog/how-we- hacked-mckinseys-ai-platform (visited on 05/05/2026)
How We Hacked McKinsey’s AI Platform. en.url: https://codewall.ai/blog/how-we- hacked-mckinseys-ai-platform (visited on 05/05/2026)
2026
-
[4]
en.url: https: //codewall.ai/blog/ai-vs-ai-how-our-ai-agent-hacked-a-20m-funded-ai-recruiter (visited on 05/05/2026)
AI vs AI: How Our AI Agent Hacked a $20M-Funded AI Recruiter. en.url: https: //codewall.ai/blog/ai-vs-ai-how-our-ai-agent-hacked-a-20m-funded-ai-recruiter (visited on 05/05/2026)
2026
-
[5]
How We Hacked Bain’s Competitive Intelligence Platform.en.url:https://codewall.ai/ blog/how-we-hacked-bains-competitive-intelligence-platform (visited on 05/05/2026)
2026
-
[6]
en.url: https://www.ibm.com/reports/data-breach (visited on 05/05/2026)
Cost of a data breach 2025 | IBM. en.url: https://www.ibm.com/reports/data-breach (visited on 05/05/2026)
2025
-
[7]
O’Flaherty.CrowdStrike Reveals What Happened, Why—And What’s Changed
K. O’Flaherty.CrowdStrike Reveals What Happened, Why—And What’s Changed. en. Section: Cybersecurity.url: https://www.forbes.com/sites/kateoflahertyuk/2024/ 125 08/07/crowdstrike-reveals-what-happened-why-and-whats-changed/ (visited on 12/18/2025)
2024
-
[8]
Janardhan.More details about the October 4 outage
S. Janardhan.More details about the October 4 outage. en-US. Oct. 2021.url: https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/ (visited on 05/05/2026)
2021
-
[9]
Amazon’s cloud unit hit by outage involving AI tools in December
“Amazon’s cloud unit hit by outage involving AI tools in December.” en.Reuters, Feb. 2026.url: https://www.reuters.com/business/retail-consumer/amazons-cloud- unit-hit-by-least-two-outages-involving-ai-tools-ft-says-2026-02-20/ (visited on 05/05/2026)
2026
-
[10]
An axiomatic basis for computer programming
C. A. R. Hoare. “An axiomatic basis for computer programming.”Commun. ACM, 12(10), Oct. 1969, pp. 576–580.issn: 0001-0782.doi: 10.1145/363235.363259.url: https://dl.acm.org/doi/10.1145/363235.363259 (visited on 05/05/2026)
-
[11]
en.url: https://rocq-prover.org/about (visited on 05/20/2026)
About The Rocq Prover. en.url: https://rocq-prover.org/about (visited on 05/20/2026)
2026
-
[12]
The Lean 4 Theorem Prover and Programming Language (System Description)
L. de Moura and S. Ullrich. “The Lean 4 Theorem Prover and Programming Language (System Description).” en
-
[13]
Dafny: Statically Verifying Functional Correctness
R. Gauci.Dafny: Statically Verifying Functional Correctness. arXiv:1412.4395 [cs]. Dec. 2014.doi: 10.48550/arXiv.1412.4395.url: http://arxiv.org/abs/1412.4395 (visited on 12/18/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.4395.url: 2014
-
[14]
Dependent types and multi-monadic effects in F*
N. Swamy et al. “Dependent types and multi-monadic effects in F*.” en. In:Pro- ceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages. St. Petersburg FL USA: ACM, Jan. 2016, pp. 256–270.isbn: 978-1-4503-3549-2.doi: 10.1145/2837614.2837655.url: https://dl.acm.org/doi/10. 1145/2837614.2837655 (visited on 05/05/2026). 126
-
[15]
A. Lattuada, T. Hance, C. Cho, M. Brun, I. Subasinghe, Y. Zhou, J. Howell, B. Parno, and C. Hawblitzel.Verus: Verifying Rust Programs using Linear Ghost Types (extended version). arXiv:2303.05491 [cs]. Mar. 2023.doi: 10.48550/arXiv.2303.05491.url: http://arxiv.org/abs/2303.05491 (visited on 12/18/2025)
- [16]
-
[17]
Anvil: Verifying Liveness of Cluster Management Controllers
X. Sun et al. “Anvil: Verifying Liveness of Cluster Management Controllers.” en. In: 2024, pp. 649–666.isbn: 978-1-939133-40-3.url: https://www.usenix.org/conference/ osdi24/presentation/sun-xudong (visited on 05/05/2026)
2024
-
[18]
VeriSMo: A Verified Security Module for Confidential VMs
Z. Zhou, Anjali, W. Chen, S. Gong, C. Hawblitzel, and W. Cui. “VeriSMo: A Verified Security Module for Confidential VMs.” en. In: 2024, pp. 599–614.isbn: 978-1-939133- 40-3.url: https://www.usenix.org/conference/osdi24/presentation/zhou (visited on 05/05/2026)
2024
-
[19]
T. mathlib Community. “The lean mathematical library.” In:Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs. POPL ’20. ACM, Jan. 2020, pp. 367–381.doi: 10.1145/3372885.3373824.url: http://dx.doi.org/10.1145/3372885.3373824
-
[20]
Lean formalization of the main theorem of liquid vector spaces, completed July 2022 in response to Peter Scholze’s challenge
Lean Prover Community.Liquid Tensor Experiment. Lean formalization of the main theorem of liquid vector spaces, completed July 2022 in response to Peter Scholze’s challenge. GitHub, 2022.url: https://github.com/leanprover-community/lean-liquid (visited on 05/04/2026)
2022
-
[21]
Tao and PFR formalization contributors.The Polynomial Freiman–Ruzsa Conjec- ture: A digitisation of the proof in Lean 4
T. Tao and PFR formalization contributors.The Polynomial Freiman–Ruzsa Conjec- ture: A digitisation of the proof in Lean 4. 2023.url: https://teorth.github.io/pfr/ (visited on 05/04/2026). 127
2023
-
[22]
Analysis I
A Lean companion to “Analysis I” | What’s new.url: https://terrytao.wordpress. com/2025/05/31/a-lean-companion-to-analysis-i/ (visited on 05/05/2026)
2025
-
[23]
xenaproject.Formalization of Erdős problems. en. Dec. 2025.url: https://xenaproject. wordpress.com/2025/12/05/formalization-of-erdos-problems/ (visited on 05/05/2026)
2025
-
[24]
xenaproject.Beyond the Liquid Tensor Experiment. en. Sept. 2022.url: https: //xenaproject.wordpress.com/2022/09/12/beyond-the-liquid-tensor-experiment/ (visited on 05/05/2026)
2022
-
[25]
seL4: formal verification of an OS kernel
G. Klein et al. “seL4: formal verification of an OS kernel.” In:Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. SOSP09. ACM, Oct. 2009, pp. 207–220.doi: 10.1145/1629575.1629596.url: http://dx.doi.org/10.1145/1629575. 1629596
-
[26]
Anthropic, 2025.url: https://www.anthropic.com/product/claude-code (visited on 05/04/2026)
Anthropic.Claude Code: Anthropic’s agentic coding system. Anthropic, 2025.url: https://www.anthropic.com/product/claude-code (visited on 05/04/2026)
2025
-
[27]
Introducing OpenAI o3 and o4-mini | OpenAI.url: https://openai.com/index/ introducing-o3-and-o4-mini/ (visited on 05/05/2026)
2026
-
[28]
en.url: https://www
Project Glasswing: Securing critical software for the AI era. en.url: https://www. anthropic.com/glasswing (visited on 05/05/2026)
2026
-
[29]
Our evaluation of Claude Mythos Preview’s cyber capabilities | AISI Work.url: https://www.aisi.gov.uk/blog/our-evaluation-of-claude-mythos-previews-cyber- capabilities (visited on 05/05/2026)
2026
-
[30]
Olympiad-level formal mathematical reasoning with reinforcement learning
T. Hubert et al. “Olympiad-level formal mathematical reasoning with reinforcement learning.”Nature,651(8106), Nov. 2025, pp. 607–613.issn: 1476-4687.doi: 10.1038/ s41586-025-09833-y.url: http://dx.doi.org/10.1038/s41586-025-09833-y
-
[31]
Aristotle: IMO-level Automated Theorem Proving
T. Achim et al. “Aristotle: IMO-level Automated Theorem Proving.”arXiv.org, 2025. arXiv: 2510.01346.url: https://arxiv.org/abs/2510.01346. 128
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
H. Xin, D. Guo, Z. Shao, Z. Ren, Q. Zhu, B. Liu, C. Ruan, W. Li, and X. Liang. DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data. arXiv:2405.14333 [cs]. May 2024.doi: 10.48550/arXiv.2405.14333.url: http://arxiv.org/abs/2405.14333 (visited on 12/17/2025)
-
[33]
Goedel-Prover : A frontier model for open-source automated theorem proving
Y. Lin et al.Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving. arXiv:2502.07640 [cs]. Apr. 2025.doi: 10.48550/arXiv.2502.07640.url: http://arxiv.org/abs/2502.07640 (visited on 12/17/2025)
-
[34]
Seed-Prover : Deep and broad reasoning for automated theorem proving
L. Chen et al. “Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving.”arXiv.org, 2025. arXiv: 2507.23726.url: https://arxiv.org/abs/2507.23726
-
[35]
auto-extract failed; link: https://deepmind.google/blog/ai-solves-imo-problems-at-silver-medal-level/
AlphaProof — DeepMind, 2024 (blog + Nature 2025). auto-extract failed; link: https://deepmind.google/blog/ai-solves-imo-problems-at-silver-medal-level/
2024
-
[36]
Z. Z. Ren et al.DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition. arXiv:2504.21801 [cs]. July 2025. doi: 10.48550/arXiv.2504.21801.url: http://arxiv.org/abs/2504.21801 (visited on 12/17/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21801.url: 2025
-
[37]
Bursuc et al.A benchmark for vericoding: formally verified program synthesis
S. Bursuc et al.A benchmark for vericoding: formally verified program synthesis. 2025. doi: 10.48550/ARXIV.2509.22908.url: https://arxiv.org/abs/2509.22908
-
[38]
Verus proofs over a fork ofcurve25519-dalek
Beneficial AI Foundation.dalek-lite: A pure-Rust implementation of group operations on Ristretto and Curve25519. Verus proofs over a fork ofcurve25519-dalek. GitHub, 2025.url: https://github.com/Beneficial-AI-Foundation/dalek-lite (visited on 05/04/2026)
2025
-
[39]
S. Varambally, T. Voice, Y. Sun, Z. Chen, R. Yu, and K. Ye.Hilbert: Recursively Building Formal Proofs with Informal Reasoning. 2025.doi: 10.48550/ARXIV.2509. 22819.url: https://arxiv.org/abs/2509.22819. 129
-
[40]
Dafny: An Automatic Program Verifier for Functional Correctness
K. R. M. Leino. “Dafny: An Automatic Program Verifier for Functional Correctness.” In:Logic for Programming, Artificial Intelligence, and Reasoning. Springer Berlin Heidelberg, 2010, pp. 348–370.isbn: 9783642175114.doi: 10.1007/978-3-642-17511- 4_20.url: http://dx.doi.org/10.1007/978-3-642-17511-4_20
-
[41]
en.url: https://dafny-lang.github.io/dafny/latest/DafnyRef/ DafnyRef.html (visited on 05/20/2026)
Dafny Documentation. en.url: https://dafny-lang.github.io/dafny/latest/DafnyRef/ DafnyRef.html (visited on 05/20/2026)
2026
-
[42]
A Piecewise Rotation of the Circle, IPR Maps and Their Connection with Translation Surfaces
L. de Moura, S. Kong, J. Avigad, F. van Doorn, and J. von Raumer. “The Lean Theorem Prover (System Description).” In:Automated Deduction - CADE-25. Springer International Publishing, 2015, pp. 378–388.isbn: 9783319214016.doi: 10.1007/978- 3-319-21401-6_26.url: http://dx.doi.org/10.1007/978-3-319-21401-6_26
-
[43]
Springer Berlin Heidelberg, 2002.isbn: 9783540459491
Isabelle/HOL. Springer Berlin Heidelberg, 2002.isbn: 9783540459491.doi: 10.1007/3- 540-45949-9.url: http://dx.doi.org/10.1007/3-540-45949-9
work page doi:10.1007/3- 2002
-
[44]
TacticToe: Learn- ing to Prove with Tactics
T. Gauthier, C. Kaliszyk, J. Urban, R. Kumar, and M. Norrish. “TacticToe: Learn- ing to Prove with Tactics.”Journal of Automated Reasoning,65(2), Feb. 2021. arXiv:1804.00596 [cs.AI], pp. 257–286.issn: 0168-7433, 1573-0670.doi: 10.1007/ s10817-020-09580-x.url: http://arxiv.org/abs/1804.00596 (visited on 05/28/2026)
-
[45]
Learning to Prove Theorems via Interacting with Proof Assistants
K. Yang and J. Deng.Learning to Prove Theorems via Interacting with Proof Assistants. arXiv:1905.09381 [cs.LO]. May 2019.doi: 10.48550/arXiv.1905.09381.url: http: //arxiv.org/abs/1905.09381 (visited on 05/28/2026)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905.09381.url: 1905
-
[46]
The Tactician (extended version): A Seam- less, Interactive Tactic Learner and Prover for Coq
L. Blaauwbroek, J. Urban, and H. Geuvers. “The Tactician (extended version): A Seam- less, Interactive Tactic Learner and Prover for Coq.” In: vol. 12236. arXiv:2008.00120 [cs.AI]. 2020, pp. 271–277.doi: 10.1007/978-3-030-53518-6_17.url: http: //arxiv.org/abs/2008.00120 (visited on 05/28/2026)
-
[47]
Generative Language Modeling for Automated Theorem Proving
S. Polu and I. Sutskever. “Generative Language Modeling for Automated Theorem Proving.”arXiv.org, 2020. arXiv: 2009.03393.url: https://arxiv.org/abs/2009.03393. 130
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[48]
Proof Artifact Co-training for Theorem Proving with Language Models
J. M. Han, J. M. Rute, Y. Wu, E. W. Ayers, and S. Polu. “Proof Artifact Co-training for Theorem Proving with Language Models.”International Conference on Learning Representations, 2021. arXiv: 2102.06203.url: https://arxiv.org/abs/2102.06203
-
[49]
Formal mathematics statement curriculum learning
S. Polu, J. M. Han, K. Zheng, M. Baksys, I. Babuschkin, and I. Sutskever. “Formal Mathematics Statement Curriculum Learning.”International Conference on Learning Representations, 2022. arXiv: 2202.01344.url: https://arxiv.org/abs/2202.01344
-
[50]
G. Lample, M. Lachaux, T. Lavril, X. Martinet, A. Hayat, G. Ebner, A. Rodriguez, and T. Lacroix. “HyperTree Proof Search for Neural Theorem Proving.”Neural Information Processing Systems, 2022. arXiv: 2205.11491.url: https://arxiv.org/abs/2205.11491
-
[51]
K. Yang, A. M. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. Prenger, and A. Anandkumar.LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. 2023.doi: 10.48550/ARXIV.2306.15626.url: https://arxiv.org/abs/2306. 15626
-
[52]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
K. Zheng, J. M. Han, and S. Polu. “MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics.”International Conference on Learning Representations,
-
[53]
arXiv: 2109.00110.url: https://arxiv.org/abs/2109.00110
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Llemma: An Open Language Model For Mathematics
Z. Azerbayev, H. Schoelkopf, K. Paster, M. D. Santos, S. McAleer, A. Q. Jiang, J. Deng, S. Biderman, and S. Welleck. “Llemma: An Open Language Model For Mathematics.” International Conference on Learning Representations, 2023. arXiv: 2310.10631.url: https://arxiv.org/abs/2310.10631
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Lean-STaR: Learning to Interleave Thinking and Proving
H. Lin, Z. Sun, Y. Yang, and S. Welleck. “Lean-STaR: Learning to Interleave Thinking and Proving.”International Conference on Learning Representations, 2024. arXiv: 2407.10040.url: https://arxiv.org/abs/2407.10040
-
[56]
H. Xin et al.DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Rein- forcement Learning and Monte-Carlo Tree Search. arXiv:2408.08152 [cs]. Aug. 2024. 131 doi: 10.48550/arXiv.2408.08152.url: http://arxiv.org/abs/2408.08152 (visited on 05/05/2026)
-
[58]
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
H. Wang et al. “Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning.”arXiv.org, 2025. arXiv: 2504.11354.url: https://arxiv. org/abs/2504.11354
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
miniF2F-Lean Revisited: Reviewing Limitations and Charting a Path Forward
A. Ospanov, F. Farnia, and R. Yousefzadeh. “miniF2F-Lean Revisited: Reviewing Limitations and Charting a Path Forward.”arXiv.org, 2025. arXiv: 2511.03108.url: https://arxiv.org/abs/2511.03108
-
[60]
RLMEval: Evaluating Research-Level Neural Theorem Proving
A. Poiroux, A. Bosselut, and V. Kuncak. “RLMEval: Evaluating Research-Level Neural Theorem Proving.”Conference on Empirical Methods in Natural Language Processing,
- [61]
-
[62]
VERINA: Benchmarking Verifiable Code Generation
Z. Ye, Z. Yan, J. He, T. Kasriel, K. Yang, and D. Song. “VERINA: Benchmarking Verifiable Code Generation.”arXiv.org, 2025. arXiv: 2505.23135.url: https://arxiv. org/abs/2505.23135
-
[63]
auto-extract failed; link:
CLEVER + VERINA — 2025 (Lean end-to-end vericoding benchmarks). auto-extract failed; link:
2025
-
[64]
C. Loughridge, Q. Sun, S. Ahrenbach, F. Cassano, C. Sun, Y. Sheng, A. Mudide, M. R. H. Misu, N. Amin, and M. Tegmark.DafnyBench: A Benchmark for Formal Software Verification. 2024.doi: 10.48550/ARXIV.2406.08467.url: https://arxiv. org/abs/2406.08467
-
[65]
Towards AI-Assisted Synthesis of Verified Dafny Methods
M. R. H. Misu, C. V. Lopes, I. Ma, and J. Noble. “Towards AI-Assisted Synthesis of Verified Dafny Methods.”Proceedings of the ACM on Software Engineering,1(FSE), 132 2024, pp. 812–835.issn: 2994-970X.doi: 10.1145/3643763.url: http://dx.doi.org/10. 1145/3643763
-
[66]
Laurel: Unblocking Automated Verification with Large Language Models
E. Mugnier, E. A. Gonzalez, N. Polikarpova, R. Jhala, and Z. Yuanyuan. “Laurel: Unblocking Automated Verification with Large Language Models.”Proceedings of the ACM on Programming Languages,9(OOPSLA1), Apr. 2025, pp. 1519–1545.issn: 2475-1421.doi: 10.1145/3720499.url: http://dx.doi.org/10.1145/3720499
-
[67]
Clover: Closed-Loop Verifiable Code Generation
C. Sun, Y. Sheng, O. Padon, and C. W. Barrett. “Clover: Closed-Loop Verifiable Code Generation.”SAIV, 2023. arXiv: 2310.17807.url: https://arxiv.org/abs/2310.17807
-
[68]
Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming
S. Chakraborty, G. Ebner, S. Bhat, S. Fakhoury, S. Fatima, S. K. Lahiri, and N. Swamy. “Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming.” International Conference on Software Engineering, 2024. arXiv: 2405.01787.url: https://arxiv.org/abs/2405.01787
-
[69]
Building A Proof-Oriented Programmer That Is 64% Better Than GPT-4o Under Data Scarcity
D. Zhang, J. Wang, and T. Sun. “Building A Proof-Oriented Programmer That Is 64% Better Than GPT-4o Under Data Scarcity.” In:Findings of the Association for Computational Linguistics: ACL 2025. Ed. by W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar. Vienna, Austria: Association for Computational Linguistics, July 2025, pp. 23101–23118.isbn: 979-8-89176...
-
[70]
What’s in a Proof? Analyzing Expert Proof-Writing Processes in F* and Verus
R. Jain, S. Barke, G. Ebner, M. R. H. Misu, S. Lu, and S. Fakhoury. “What’s in a Proof? Analyzing Expert Proof-Writing Processes in F* and Verus.”arXiv.org, 2025. arXiv: 2508.02733.url: https://arxiv.org/abs/2508.02733
-
[71]
K. Thompson, N. Saavedra, P. Carrott, K. Fisher, A. Sanchez-Stern, Y. Brun, J. F. Ferreira, S. Lerner, and E. First. “Rango: Adaptive Retrieval-Augmented Proving for Automated Software Verification.” In:2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, Apr. 2025, pp. 347–359.doi: 10.1109/ icse55347.2025.00161.url: http://dx...
-
[72]
AutoVerus: Automated Proof Generation for Rust Code
C. Yang et al. “AutoVerus: Automated Proof Generation for Rust Code.”Proc. ACM Program. Lang., 2024. arXiv: 2409.13082.url: https://arxiv.org/abs/2409.13082
-
[73]
Automated Proof Generation for Rust Code via Self-Evolution
T. Chen et al. “Automated Proof Generation for Rust Code via Self-Evolution.” International Conference on Learning Representations, 2024. arXiv: 2410.15756.url: https://arxiv.org/abs/2410.15756
-
[74]
VeriStruct: AI-assisted Automated Verification of Data-Structure Modules in Verus
C. Sun, Y. Sun, D. Amrollahi, E. Zhang, S. K. Lahiri, S. Lu, D. Dill, and C. W. Barrett. “VeriStruct: AI-assisted Automated Verification of Data-Structure Modules in Verus.” arXiv.org, 2025. arXiv: 2510.25015.url: https://arxiv.org/abs/2510.25015
- [76]
-
[77]
Proof Automation with Large Language Models
M. Lu, B. Delaware, and T. Zhang. “Proof Automation with Large Language Models.” International Conference on Automated Software Engineering, 2024. arXiv: 2409.14274. url: https://arxiv.org/abs/2409.14274
-
[78]
Goedel-Code-Prover: Hierarchical Proof Search for Open State-of-the-Art Code Verification
Z. Li, Z. Yang, D. He, H. Zhao, A. Zhao, S. Tang, K. Yang, A. Gupta, Z. Su, and C. Jin. “Goedel-Code-Prover: Hierarchical Proof Search for Open State-of-the-Art Code Verification.”arXiv preprint arXiv:2603.19329, 2026. arXiv: 2603.19329.url: https://arxiv.org/abs/2603.19329
-
[79]
L. Aniva, C. Sun, B. Miranda, C. Barrett, and S. Koyejo.Pantograph: A Machine-to- Machine Interaction Interface for Advanced Theorem Proving, High Level Reasoning, and Data Extraction in Lean 4. 2024.doi: 10.48550/ARXIV.2410.16429.url: https://arxiv.org/abs/2410.16429
-
[80]
Auto- formalization with Large Language Models
Y. Wu, A. Q. Jiang, W. Li, M. Rabe, C. Staats, M. Jamnik, and C. Szegedy. “Auto- formalization with Large Language Models.”Neural Information Processing Systems,
- [81]
-
[82]
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs
A. Q. Jiang, S. Welleck, J. Zhou, W. Li, J. Liu, M. Jamnik, T. Lacroix, Y. Wu, and G. Lample. “Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs.”International Conference on Learning Representations, 2022. arXiv: 2210.12283.url: https://arxiv.org/abs/2210.12283
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.