Sample-wise Targeted Adversarial Attacks on Test-time Adaptation
Pith reviewed 2026-05-25 04:57 UTC · model grok-4.3
The pith
Sample-wise targeted attacks on test-time adaptation misclassify only triggered inputs while preserving the overall label distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a sample-wise targeted adversarial attack on TTA that misclassifies only inputs carrying an attacker-chosen trigger while preserving the global label distribution of benign queries; the attack is realized by a meta-learning procedure whose priority-aware gradient alignment is formulated as an ellipsoidal trust-region problem that supplies theoretical guarantees even when attack success and distributional stealth pull the gradient in opposite directions.
What carries the argument
Priority-aware gradient alignment strategy that formulates the gradient update as an ellipsoidal trust-region problem to prioritize attack success while enforcing distributional stealth.
If this is right
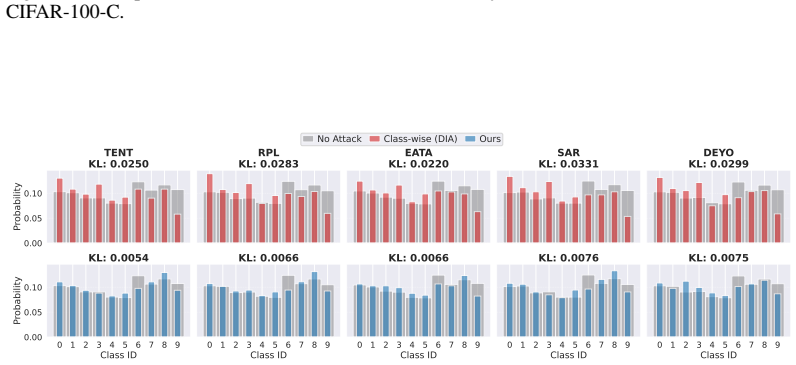
- The attack reaches high targeted success rates on CIFAR-10-C, CIFAR-100-C and ImageNet-C under multiple TTA protocols.
- Label frequencies remain statistically indistinguishable from the clean baseline, evading detection that relies on class-count monitoring.
- The attack retains effectiveness against existing defenses that assume class-wise or batch-wise perturbations.
Where Pith is reading between the lines
- TTA pipelines may need to monitor for localized trigger patterns in addition to global statistics.
- The meta-learning framing could be reused for other online adaptation settings that require both efficacy and statistical invisibility.
- Trigger-specific robustness training might become a standard safeguard once sample-wise attacks are recognized as practical.
Load-bearing premise
The ellipsoidal trust-region formulation can still optimize the attack objective even when attack success and label-distribution preservation produce misaligned gradients.
What would settle it
An experiment in which the attack either fails to reach high targeted success on triggered samples or produces a label distribution whose deviation from the no-attack baseline exceeds what the paper reports would falsify the central claim.
Figures














read the original abstract
Test-time adaptation (TTA) effectively counters distribution shifts but exposes models to adversarial manipulation via the unlabeled test stream. Existing class-wise targeted attacks remain impractical for stealthy exploitation in this setting: since TTA operates on batches, forcing a subset of samples toward a target label unintentionally pulls similar benign samples along, resulting in a conspicuously high frequency of the target label that is easy to detect. To capture a more realistic threat, we introduce a sample-wise targeted attack. Unlike prior approaches, the attacker aims to misclassify only inputs carrying an attacker-chosen trigger, while preserving the global label distribution of benign queries to evade detection. To achieve this, we propose a meta-learning-based attack with a novel priority-aware gradient alignment strategy that explicitly prioritizes attack success. The strategy formulates the gradient update as an ellipsoidal trust-region problem, mitigating the misalignment between attack success and distributional stealth, while providing theoretical guarantees for effective optimization of the attack objective in the presence of gradient misalignment. Extensive experiments on CIFAR-10-C, CIFAR-100-C, and ImageNet-C across TTA protocols demonstrate that our method achieves high targeted success rates while maintaining a label distribution that is consistent with the no-attack baseline, making it difficult to detect in unlabeled TTA deployment scenarios. Furthermore, we demonstrate that our attack shows strong robustness against existing defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a sample-wise targeted adversarial attack on test-time adaptation (TTA) that misclassifies only trigger-carrying inputs while preserving the global label distribution of benign samples to evade detection in unlabeled streams. It uses a meta-learning framework with a novel priority-aware gradient alignment strategy formulated as an ellipsoidal trust-region problem to resolve misalignment between attack success and distributional stealth, accompanied by theoretical guarantees. Experiments on CIFAR-10-C, CIFAR-100-C, and ImageNet-C across TTA protocols report high targeted success rates, label distributions consistent with no-attack baselines, and robustness to existing defenses.
Significance. If the central claims hold, the work identifies a realistic and stealthy threat model for TTA deployments that prior class-wise attacks do not capture, potentially affecting the security of adaptive models in production. The meta-learning approach with trust-region optimization for balancing conflicting objectives may have value beyond this setting. The reported empirical results on standard corruption benchmarks provide a concrete starting point for evaluating such attacks.
major comments (3)
- [§3 (meta-learning attack formulation)] The priority-aware gradient alignment (ellipsoidal trust-region formulation) is presented as mitigating misalignment between attack success and distributional stealth, but the manuscript does not model or constrain the downstream effect of batch-level TTA parameter updates on non-triggered samples. This coupling is load-bearing for the sample-wise isolation and label-distribution stealth claims.
- [§4 (experiments on CIFAR/ImageNet-C)] Experiments report label distribution consistency with the no-attack baseline, but without explicit measurements or ablations of indirect prediction shifts on benign samples sharing a batch with triggered inputs, it remains unclear whether the reported frequencies would hold under actual TTA batch updates.
- [§3.2 (theoretical analysis)] The theoretical guarantees are stated for effective optimization of the attack objective under gradient misalignment, yet they appear limited to the meta-optimization step and do not extend to end-to-end preservation of batch label statistics after adaptation.
minor comments (2)
- [§4.1] Clarify the exact batch sizes and TTA update rules used in the experimental protocols, as these directly affect the coupling concern.
- [Related work] Add a reference to prior work on batch-level statistics in TTA if not already present, to contextualize the sample-wise distinction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify key aspects of our threat model and evaluation. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [§3 (meta-learning attack formulation)] The priority-aware gradient alignment (ellipsoidal trust-region formulation) is presented as mitigating misalignment between attack success and distributional stealth, but the manuscript does not model or constrain the downstream effect of batch-level TTA parameter updates on non-triggered samples. This coupling is load-bearing for the sample-wise isolation and label-distribution stealth claims.
Authors: We agree that the current formulation in §3 optimizes the per-sample attack objective via meta-learning and the ellipsoidal trust-region but does not explicitly simulate or constrain how TTA parameter updates propagate to non-triggered samples in the same batch. This interaction is indeed central to the stealth claims. We will revise §3 to add a dedicated paragraph discussing this batch-level coupling under the assumed threat model (unlabeled streams with mixed triggered and benign inputs) and how the priority-aware alignment indirectly supports isolation by prioritizing distributional consistency at the attack-generation stage. revision: partial
-
Referee: [§4 (experiments on CIFAR/ImageNet-C)] Experiments report label distribution consistency with the no-attack baseline, but without explicit measurements or ablations of indirect prediction shifts on benign samples sharing a batch with triggered inputs, it remains unclear whether the reported frequencies would hold under actual TTA batch updates.
Authors: The reported label distributions are measured after full TTA runs on streams containing the attacked batches, and they remain consistent with the no-attack baseline. However, we acknowledge the value of isolating indirect effects on co-batch benign samples. We will add new ablations in §4 that track per-sample prediction changes for benign inputs when processed alongside triggered samples under each TTA protocol, providing direct evidence on whether distributional stealth is preserved after the adaptation step. revision: yes
-
Referee: [§3.2 (theoretical analysis)] The theoretical guarantees are stated for effective optimization of the attack objective under gradient misalignment, yet they appear limited to the meta-optimization step and do not extend to end-to-end preservation of batch label statistics after adaptation.
Authors: The analysis in §3.2 establishes convergence guarantees for the meta-optimization under the priority-aware alignment when gradients are misaligned. We agree these guarantees do not extend to a formal proof of post-adaptation label-statistic preservation, which would require additional assumptions on the TTA update rule and batch statistics. We will revise the text to explicitly state the scope of the theoretical results and emphasize that end-to-end distributional stealth is demonstrated empirically across the evaluated protocols and datasets. revision: partial
Circularity Check
No circularity; derivation relies on independent meta-optimization without reduction to inputs
full rationale
The paper introduces a sample-wise targeted attack via meta-learning and a priority-aware gradient alignment cast as an ellipsoidal trust-region problem, with claims of theoretical guarantees for optimization under misalignment. No equations, fitted parameters, or self-citations are shown that reduce the attack success or stealth properties to self-defined quantities or prior results by construction. The central claims rest on the proposed formulation and experimental validation rather than tautological re-labeling of inputs, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A new backdoor attack in cnns by training set corruption without label poisoning
Mauro Barni, Kassem Kallas, and Benedetta Tondi. A new backdoor attack in cnns by training set corruption without label poisoning. In2019 IEEE International Conference on Image Processing (ICIP), pages 101–105. IEEE, 2019
work page 2019
-
[2]
Cambridge university press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex optimization. Cambridge university press, 2004
work page 2004
-
[3]
A probabilistic framework for lifelong test-time adaptation
Dhanajit Brahma and Piyush Rai. A probabilistic framework for lifelong test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3582–3591, 2023
work page 2023
-
[4]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning.arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Gradnorm: Gra- dient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gra- dient normalization for adaptive loss balancing in deep multitask networks. InInternational conference on machine learning, pages 794–803. PMLR, 2018
work page 2018
-
[6]
Test-time poisoning attacks against test-time adaptation models
Tianshuo Cong, Xinlei He, Yun Shen, and Yang Zhang. Test-time poisoning attacks against test-time adaptation models. In2024 IEEE Symposium on Security and Privacy (SP), pages 1306–1324. IEEE, 2024
work page 2024
-
[7]
Februus: Input purification defense against trojan attacks on deep neural network systems
Bao Gia Doan, Ehsan Abbasnejad, and Damith C Ranasinghe. Februus: Input purification defense against trojan attacks on deep neural network systems. InProceedings of the 36th Annual Computer Security Applications Conference, pages 897–912, 2020
work page 2020
-
[8]
Robust physical-world attacks on deep learning visual classification
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1625–1634, 2018
work page 2018
-
[9]
Taesik Gong, Yewon Kim, Taeckyung Lee, Sorn Chottananurak, and Sung-Ju Lee. Sotta: Robust test-time adaptation on noisy data streams.Advances in Neural Information Processing Systems, 36:14070–14093, 2023
work page 2023
-
[10]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Ranked entropy minimization for continual test-time adaptation.arXiv preprint arXiv:2505.16441, 2025
Jisu Han, Jaemin Na, and Wonjun Hwang. Ranked entropy minimization for continual test-time adaptation.arXiv preprint arXiv:2505.16441, 2025
-
[12]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[13]
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.Proceedings of the International Conference on Learning Representations, 2019
work page 2019
-
[14]
Zixuan Hu, Yichun Hu, Xiaotong Li, Shixiang Tang, and Ling-Yu Duan. Beyond entropy: Region confidence proxy for wild test-time adaptation.arXiv preprint arXiv:2505.20704, 2025
-
[15]
Minguk Jang, Sae-Young Chung, and Hye Won Chung. Test-time adaptation via self-training with nearest neighbor information.arXiv preprint arXiv:2207.10792, 2022
-
[16]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7482–7491, 2018
work page 2018
-
[17]
Stationary latent weight inference for unreliable obser- vations from online test-time adaptation
Jae-Hong Lee and Joon-Hyuk Chang. Stationary latent weight inference for unreliable obser- vations from online test-time adaptation. InForty-first International Conference on Machine Learning, 2024. 10
work page 2024
-
[18]
Jonghyun Lee, Dahuin Jung, Saehyung Lee, Junsung Park, Juhyeon Shin, Uiwon Hwang, and Sungroh Yoon. Entropy is not enough for test-time adaptation: From the perspective of disentangled factors.arXiv preprint arXiv:2403.07366, 2024
-
[19]
Towards open-set test-time adaptation utilizing the wisdom of crowds in entropy minimization
Jungsoo Lee, Debasmit Das, Jaegul Choo, and Sungha Choi. Towards open-set test-time adaptation utilizing the wisdom of crowds in entropy minimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16380–16389, 2023
work page 2023
-
[20]
Yoonho Lee, Annie S Chen, Fahim Tajwar, Ananya Kumar, Huaxiu Yao, Percy Liang, and Chelsea Finn. Surgical fine-tuning improves adaptation to distribution shifts.arXiv preprint arXiv:2210.11466, 2022
-
[21]
Jingjing Li, Zhiqi Yu, Zhekai Du, Lei Zhu, and Heng Tao Shen. A comprehensive survey on source-free domain adaptation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5743–5762, 2024
work page 2024
-
[22]
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. Backdoor learning: A survey.IEEE transactions on neural networks and learning systems, 35(1):5–22, 2022
work page 2022
-
[23]
Invisible backdoor attack with sample-specific triggers
Yuezun Li, Yiming Li, Baoyuan Wu, Longkang Li, Ran He, and Siwei Lyu. Invisible backdoor attack with sample-specific triggers. InProceedings of the IEEE/CVF international conference on computer vision, pages 16463–16472, 2021
work page 2021
-
[24]
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
work page 2025
-
[25]
Detecting and correcting for label shift with black box predictors
Zachary Lipton, Yu-Xiang Wang, and Alexander Smola. Detecting and correcting for label shift with black box predictors. InInternational conference on machine learning, pages 3122–3130. PMLR, 2018
work page 2018
-
[26]
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning.Advances in Neural Information Processing Systems, 34:18878–18890, 2021
work page 2021
-
[27]
Variational continual test-time adaptation.arXiv preprint arXiv:2402.08182, 2024
Fan Lyu, Kaile Du, Yuyang Li, Hanyu Zhao, Zhang Zhang, Guangcan Liu, and Liang Wang. Variational continual test-time adaptation.arXiv preprint arXiv:2402.08182, 2024
-
[28]
Improved self-training for test-time adaptation
Jing Ma. Improved self-training for test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23701–23710, 2024
work page 2024
-
[29]
Springer Science & Business Media, 2013
Yurii Nesterov.Introductory lectures on convex optimization: A basic course, volume 87. Springer Science & Business Media, 2013
work page 2013
-
[30]
Anh Nguyen and Anh Tran. Wanet–imperceptible warping-based backdoor attack.arXiv preprint arXiv:2102.10369, 2021
-
[31]
Efficient test-time model adaptation without forgetting
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. InInternational confer- ence on machine learning, pages 16888–16905. PMLR, 2022
work page 2022
-
[32]
Towards stable test-time adaptation in dynamic wild world.arXiv preprint arXiv:2302.12400, 2023
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards stable test-time adaptation in dynamic wild world.arXiv preprint arXiv:2302.12400, 2023
-
[33]
Medbn: Robust test-time adaptation against malicious test samples
Hyejin Park, Jeongyeon Hwang, Sunung Mun, Sangdon Park, and Jungseul Ok. Medbn: Robust test-time adaptation against malicious test samples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5997–6007, 2024
work page 2024
-
[34]
Zhuang Qian, Kaizhu Huang, Qiu-Feng Wang, and Xu-Yao Zhang. A survey of robust ad- versarial training in pattern recognition: Fundamental, theory, and methodologies.Pattern Recognition, 131:108889, 2022
work page 2022
-
[35]
Stephan Rabanser, Stephan Günnemann, and Zachary Lipton. Failing loudly: An empirical study of methods for detecting dataset shift.Advances in Neural Information Processing Systems, 32, 2019. 11
work page 2019
-
[36]
On the adversarial vulnerability of label-free test-time adaptation
Shahriar Rifat, Jonathan Ashdown, Michael J De Lucia, Ananthram Swami, and Francesco Restuccia. On the adversarial vulnerability of label-free test-time adaptation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[37]
If your data distribution shifts, use self-learning
Evgenia Rusak, Steffen Schneider, George Pachitariu, Luisa Eck, Peter Gehler, Oliver Bring- mann, Wieland Brendel, and Matthias Bethge. If your data distribution shifts, use self-learning. arXiv preprint arXiv:2104.12928, 2021
-
[38]
Hidden trigger backdoor attacks
Aniruddha Saha, Akshayvarun Subramanya, and Hamed Pirsiavash. Hidden trigger backdoor attacks. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 11957–11965, 2020
work page 2020
-
[39]
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
work page 2018
-
[40]
Test: Test-time self- training under distribution shift
Samarth Sinha, Peter Gehler, Francesco Locatello, and Bernt Schiele. Test: Test-time self- training under distribution shift. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2759–2769, 2023
work page 2023
-
[41]
On general minimax theorems.Pacific Journal of Mathematics, 8(1):171–176, 1958
Maurice Sion. On general minimax theorems.Pacific Journal of Mathematics, 8(1):171–176, 1958
work page 1958
-
[42]
Yongyi Su, Yushu Li, Nanqing Liu, Kui Jia, Xulei Yang, Chuan-Sheng Foo, and Xun Xu. On the adversarial risk of test time adaptation: An investigation into realistic test-time data poisoning. arXiv preprint arXiv:2410.04682, 2024
-
[43]
Yongyi Su, Xun Xu, and Kui Jia. Revisiting realistic test-time training: Sequential inference and adaptation by anchored clustering.Advances in Neural Information Processing Systems, 35:17543–17555, 2022
work page 2022
-
[44]
Parameter-selective continual test-time adaptation
Jiaxu Tian and Fan Lyu. Parameter-selective continual test-time adaptation. InProceedings of the Asian Conference on Computer Vision, pages 1384–1400, 2024
work page 2024
-
[45]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[46]
Continual test-time domain adaptation
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. Continual test-time domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7201–7211, 2022
work page 2022
-
[47]
Backdoor attacks against deep learning systems in the physical world
Emily Wenger, Josephine Passananti, Arjun Nitin Bhagoji, Yuanshun Yao, Haitao Zheng, and Ben Y Zhao. Backdoor attacks against deep learning systems in the physical world. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6206–6215, 2021
work page 2021
-
[48]
Uncovering adversarial risks of test-time adaptation.arXiv preprint arXiv:2301.12576, 2023
Tong Wu, Feiran Jia, Xiangyu Qi, Jiachen T Wang, Vikash Sehwag, Saeed Mahloujifar, and Prateek Mittal. Uncovering adversarial risks of test-time adaptation.arXiv preprint arXiv:2301.12576, 2023
-
[49]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
work page 2020
-
[50]
Qingyang Zhang, Yatao Bian, Xinke Kong, Peilin Zhao, and Changqing Zhang. Come: Test-time adaptation by conservatively minimizing entropy.arXiv preprint arXiv:2410.10894, 2024
-
[51]
Yu Zhang and Qiang Yang. A survey on multi-task learning.IEEE transactions on knowledge and data engineering, 34(12):5586–5609, 2021. 12 A Extended Related Works Test-time Adaptation.TTA updates model parameters at inference time using unlabeled test data to handle distribution shift [24]. Unlike training-time domain adaptation [21], it assumes no access ...
-
[52]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.