AMEL: Accumulated Message Effects on LLM Judgments
Pith reviewed 2026-05-22 05:05 UTC · model grok-4.3
The pith
LLM evaluators shift their judgments to align with the polarity of earlier messages in the same conversation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
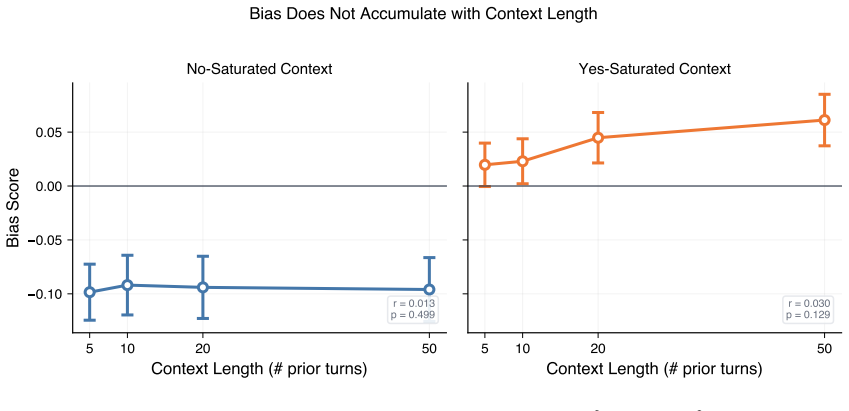
Presenting the same evaluation item after a history saturated with positive messages moves model scores upward relative to a neutral baseline, while a negative history moves scores downward, producing an overall effect size of d = -0.17. The shift is concentrated on high-entropy items (d = -0.34) and is 1.62 times larger for negative histories than positive ones. The magnitude remains constant whether the history contains 5 or 50 prior turns, and position within the history does not matter.
What carries the argument
The accumulated message effect (AMEL), defined as the directional pull that conversation history exerts on a model's subsequent scalar judgments of identical test items.
If this is right
- Bias concentrates on items the model is uncertain about at baseline, leaving high-confidence items relatively stable.
- Negative histories produce reliably larger shifts than positive histories of equal strength.
- The size of the bias stays flat once at least five prior turns are present and does not grow with additional context length.
- Model scale reduces but does not remove the effect across the tested providers and sizes.
- Resetting to a fresh context for every new item eliminates the bias in evaluation pipelines.
Where Pith is reading between the lines
- Batch evaluation workflows that reuse long contexts may systematically favor items that appear later in the sequence.
- Balancing the polarity of accumulated history before each new item could serve as a lightweight mitigation when fresh contexts are impractical.
- The same history-driven drift may appear in other sequential LLM tasks such as iterative code review or multi-turn content moderation.
Load-bearing premise
The only systematic difference between conditions is the polarity of the inserted conversation history, with the test items themselves remaining identical and free of other confounds.
What would settle it
No measurable difference in scores for the same items when presented after positive versus negative histories, or when each item is evaluated in an isolated fresh context instead of an accumulated one.
Figures











read the original abstract
Large language models are routinely used as automated evaluators: to review code, moderate content, or score outputs, often with many items passing through one conversation. We ask whether the polarity of prior conversation history biases subsequent judgments, an effect we call the accumulated message effect on LLM judgments (AMEL). Across 75,898 API calls to 11 models from 4 providers (OpenAI, Anthropic, Google, and four open-source models), we present identical test items in isolation or following histories saturated with predominantly positive or negative evaluations. Models shift toward the conversation's prevailing polarity (d = -0.17, p < 10^-46). The effect concentrates on items where the model is genuinely uncertain at baseline (d = -0.34 for high-entropy items, vs d = -0.15 when the baseline is deterministic). Bias does not grow with context length: 5 prior turns and 50 produce the same shift (Spearman |r| < 0.01; OLS slope p = 0.80). And there is a negativity asymmetry: paired per item, negative histories induce 1.62x more bias than positive (t = 13.46, p < 10^-39, n = 2,481). Scaling helps but does not solve it (Anthropic: Haiku -0.22 to Opus -0.17; OpenAI: Nano -0.34 to GPT-5.2 -0.17). Three follow-ups narrow the mechanism. The token probability distribution shifts continuously, not at a threshold. The negativity asymmetry has both token-level and semantic components, though attributing the balance is exploratory at our sample sizes. Position does not matter: five biased turns anywhere in a 50-turn history produce the same shift. The simplest fix for evaluation pipelines is a fresh context per item; when batching is unavoidable, balancing the history helps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates accumulated message effects (AMEL) on LLM judgments, claiming that the polarity of prior conversation history biases subsequent evaluations toward the history's prevailing sentiment. Using 75,898 API calls across 11 models from four providers, it reports an overall shift (d = -0.17, p < 10^-46) that is larger for high-entropy/uncertain items (d = -0.34) than deterministic ones (d = -0.15), shows no growth with context length (Spearman |r| < 0.01), exhibits negativity asymmetry (negative histories induce 1.62x more bias), and finds position invariance and partial mitigation via scaling. Follow-up analyses examine token probabilities and mechanisms, recommending fresh contexts or balanced histories for evaluation pipelines.
Significance. If the central empirical claims hold, the result is significant for the growing use of LLMs as automated evaluators in code review, content moderation, and scoring tasks, where batching items in one conversation is common. The large sample, multiple model families, and controls for length/position provide a solid empirical foundation. The work is strengthened by direct API measurements, standard statistical tests, and falsifiable predictions about effect concentration on uncertain items rather than any parameter-free derivation or machine-checked proof.
major comments (1)
- [Methods] Methods (prompt construction): The central attribution of the d = -0.17 shift to polarity alone requires explicit verification that test items are appended with literally identical wording, structure, and tokenization after positive versus negative histories. The reported controls (identical test items, position invariance, no length scaling) are only as strong as the prompt templates; without the exact templates or construction code in the methods, surface differences cannot be ruled out as confounds.
minor comments (2)
- [Abstract] Abstract and §3: The negativity asymmetry (1.62x) is reported with t = 13.46 but the paired per-item n = 2,481 should be cross-referenced to the exact item count and exclusion criteria for clarity.
- [Results] Figure 2 or equivalent: Clarify how high-entropy items are defined (e.g., baseline entropy threshold) and whether the d = -0.34 vs -0.15 comparison uses the same items or matched subsets.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on accumulated message effects in LLM judgments. We address the single major comment below and will revise the manuscript accordingly to improve transparency.
read point-by-point responses
-
Referee: [Methods] Methods (prompt construction): The central attribution of the d = -0.17 shift to polarity alone requires explicit verification that test items are appended with literally identical wording, structure, and tokenization after positive versus negative histories. The reported controls (identical test items, position invariance, no length scaling) are only as strong as the prompt templates; without the exact templates or construction code in the methods, surface differences cannot be ruled out as confounds.
Authors: We agree that providing the exact prompt templates and construction code is necessary to fully rule out surface-level confounds and strengthen attribution to polarity. In the revised manuscript we will add the complete prompt templates (for positive, negative, and neutral histories) to the Methods section, along with a description of how test items are appended. We will also release the full prompt-construction code in a public repository linked from the paper, enabling direct verification that wording, structure, and tokenization of the test items remain identical across history conditions. revision: yes
Circularity Check
No derivation chain present; empirical measurements only
full rationale
The paper presents results from direct API calls (75,898 total) to 11 models, reporting effect sizes (d = -0.17 overall), p-values, Spearman correlations, OLS slopes, and t-tests on judgment shifts induced by conversation history polarity. No equations, ansatzes, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. Central claims rest on controlled experimental comparisons (identical test items after positive/negative histories) and standard statistical tests rather than any reduction to self-referential inputs. This is the expected outcome for a purely empirical study without theoretical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying Cohen's d and reported p-values hold for the paired and unpaired comparisons performed.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Models shift toward the conversation's prevailing polarity (d = -0.17...); bias score BSi,m,p,l = P(r*|treatment) - P(r*|baseline)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Five biased turns anywhere in a 50-turn history produce the same shift
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Many- shot in-context learning
Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Luis Chan, Ankush Anand, Zaheer Abbas, Azade Nova, John D Co-Reyes, Eric Chu, et al. Many- shot in-context learning. InAdvances in Neural In- 13 formation Processing Systems (NeurIPS), 2024. URL https://arxiv.org/abs/2404.11018
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforce- ment learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [3]
-
[4]
Acquiescence bias in large language models.arXiv preprint arXiv:2509.08480, 2025
Daniel Braun. Acquiescence bias in large language models.arXiv preprint arXiv:2509.08480, 2025
-
[5]
Nuo Chen, Jiqun Liu, Xiaoyu Dong, Qijiong Liu, Tet- suya Sakai, and Xiao-Ming Wu. AI can be cognitively biased: An exploratory study on threshold priming in LLM-based batch relevance assessment. 2024
work page 2024
-
[6]
Tsz Ting Cheung et al. Amplified yea-saying bias in large language models.Proceedings of the National Academy of Sciences (PNAS), 122(3),
-
[7]
URL https://doi.org/10.1073/pnas. 2420642122. Documents yes-no response bias in LLMs using cognitive science paradigms
- [8]
-
[9]
Rossi, Viet Dac Lai, David Seunghyun Yoon, Dilek Hakkani-Tür, and Trung Bui
Vardhan Dongre, Ryan A. Rossi, Viet Dac Lai, David Seunghyun Yoon, Dilek Hakkani-Tür, and Trung Bui. Drift no more? context equilibria in multi-turn LLM interactions.arXiv preprint arXiv:2510.07777, 2025
-
[10]
Cognitive bias in decision-making with LLMs
Jessica M Echterhoff, Yao Liu, Miltiadis Allamanis, and Julian McAuley. Cognitive bias in decision-making with LLMs. InFindings of the Association for Com- putational Linguistics: EMNLP 2024, 2024. URL https://arxiv.org/abs/2403.00811. Stud- ies sequential cognitive biases including anchoring and framing in LLM decisions
- [11]
- [12]
-
[13]
Interaction context often increases sycophancy in LLMs.arXiv preprint arXiv:2509.12517, 2025
Shomik Jain, Charlotte Park, Matt Viana, Ashia Wilson, and Dana Calacci. Interaction context often increases sycophancy in LLMs.arXiv preprint arXiv:2509.12517, 2025
-
[14]
Bowen Jiang, Yangxinyu Xie, Zhuoqun Hao, Xiaomeng Wang, Tanwi Mallick, Weijie J. Su, Camillo J. Taylor, and Dan Roth. A peek into token bias: Large lan- guage models are not yet genuine reasoners. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024. URL https://arxiv.org/abs/2406.11050. Sur- face token ...
-
[15]
Anchoring bias in large language models: An experimental study.arXiv preprint arXiv:2412.06593, 2024
Erik Jones and Jacob Steinhardt. Anchoring bias in large language models: An experimental study.arXiv preprint arXiv:2412.06593, 2024
-
[16]
Philippe Laban, Asli Celikyilmaz, Caiming Xiong, and Besmira Nushi. Lost in conversation: How multi-turn interactions degrade LLM performance.arXiv preprint arXiv:2502.01003, 2025. Microsoft Research; docu- ments systematic performance degradation in multi-turn LLM use
-
[17]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Com- putational Linguistics (TACL), 12:157–173, 2024. URL https://arxiv.org/abs/2307.03172. Mod- els attend more to beginning and end of context, degrad-...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
System- atic bias in large language models: Discrepant response patterns in binary vs
Yi-Long Lu, Chunhui Zhang, and Wei Wang. System- atic bias in large language models: Discrepant response patterns in binary vs. continuous judgment tasks.arXiv preprint arXiv:2504.19445, 2025
-
[19]
arXiv preprint arXiv:2404.13076 , year=
Arjun Panickssery, Samuel R Bowman, and Shi Feng. LLM evaluators recognize and favor their own genera- tions. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. URL https://arxiv. org/abs/2404.13076. NeurIPS 2024 Oral; self- preference bias in LLM evaluators
-
[20]
Discovering Language Model Behaviors with Model-Written Evaluations
Ethan Perez, Sam Ringer, Kamil ˙e Lukoši ¯ut˙e, Ka- rina Nguyen, Edwin Chen, Scott Heiner, Craig Pet- tit, Catherine Olsson, Sandipan Kundu, Saurav Kada- vath, et al. Discovering language model behaviors with model-written evaluations. InFindings of the Associ- ation for Computational Linguistics: ACL 2023, 2023. URL https://arxiv.org/abs/2212.09251. Larg...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Ammar Shaikh, Raj Abhijit Dandekar, Sreedath Panat, and Rajat Dandekar. CBEval: A framework for evalu- 14 ating and interpreting cognitive biases in LLMs.arXiv preprint arXiv:2412.03605, 2024
-
[22]
Itai Shapira, Gerdus Benade, and Ariel D. Procac- cia. How RLHF amplifies sycophancy.arXiv preprint arXiv:2602.01002, 2026. Formal analysis of how RLHF reward learning amplifies pattern-following; sycophan- tic responses overrepresented among high-reward com- pletions
-
[23]
Towards Understanding Sycophancy in Language Models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, New- ton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models. InInternational Conference on Learning Representations (ICLR), 2024. URL https: //arxiv.org/abs/2310.13548
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Adi Simhi, Fazl Barez, Martin Tutek, Yonatan Belinkov, and Shay B. Cohen. Old habits die hard: How conversa- tional history geometrically traps LLMs.arXiv preprint arXiv:2603.03308, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Jongyoon Song, Sangwon Yu, and Sungroh Yoon. A multifaceted analysis of negative bias in large language models through the lens of parametric knowledge.arXiv preprint arXiv:2511.10881, 2025
-
[26]
Yasuaki Sumita, Koh Takeuchi, and Hisashi Kashima. Cognitive biases in large language models: A sur- vey and mitigation experiments.arXiv preprint arXiv:2412.00323, 2024
-
[27]
How ro- bust are LLMs to in-context majority label bias?arXiv preprint arXiv:2312.16549, 2024
Karan Tang, Duy Phung Chau, and Lisa Xiang. How ro- bust are LLMs to in-context majority label bias?arXiv preprint arXiv:2312.16549, 2024
-
[28]
Judgment under uncertainty: Heuristics and biases.Science, 185(4157): 1124–1131, 1974
Amos Tversky and Daniel Kahneman. Judgment under uncertainty: Heuristics and biases.Science, 185(4157): 1124–1131, 1974
work page 1974
-
[29]
B-score: Detecting biases in LLMs using response history
An V o, Mohammad Reza Taesiri, Daeyoung Kim, and Anh Totti Nguyen. B-score: Detecting biases in LLMs using response history. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025. URL https://arxiv.org/abs/ 2505.18545
-
[30]
Mitigating Conversational Inertia in Multi-Turn Agents
Yang Wan, Zheng Cao, Zhenhao Zhang, Zhengwen Zeng, Shuheng Shen, Changhua Meng, and Linchao Zhu. Mitigating conversational inertia in multi-turn agents.arXiv preprint arXiv:2602.03664, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Large Language Models are not Fair Evaluators
Peiyi Wang, Lei Li, Liang Chen, Feifan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (ACL), 2024. URL https://arxiv.org/abs/ 2305.17926. Demonstrates position bias in LLM- as-judge; swap...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V . Chawla, and Xian- gliang Zhang. Justice or prejudice? quantifying biases in LLM-as-a-judge.arXiv preprint arXiv:2410.02736, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Sangwon Yu, Jongyoon Song, Bongkyu Hwang, Hoy- oung Kang, Sooah Cho, Junhwa Choi, Seongho Joe, Taehee Lee, Youngjune L. Gwon, and Sungroh Yoon. Correcting negative bias in large language models through negative attention score alignment.arXiv preprint arXiv:2408.00137, 2025
-
[34]
Calibrate before use: Improving few- shot performance of language models
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few- shot performance of language models. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021. URL https://arxiv.org/abs/ 2102.09690
-
[35]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuo- han Li, Dacheng Li, Eric P Xing, et al. Judging LLM- as-a-judge with MT-bench and chatbot arena.Advances in Neural Information Processing Systems, 2024. 15 A Model×Context Length Heatmap 5 10 20 50 Context Length (# prior turns) GPT-4.1 nano GPT-5.2 Haiku ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.