AMEL: Accumulated Message Effects on LLM Judgments
Pith reviewed 2026-05-22 05:05 UTC · model grok-4.3
The pith
LLM evaluators shift their judgments to align with the polarity of earlier messages in the same conversation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
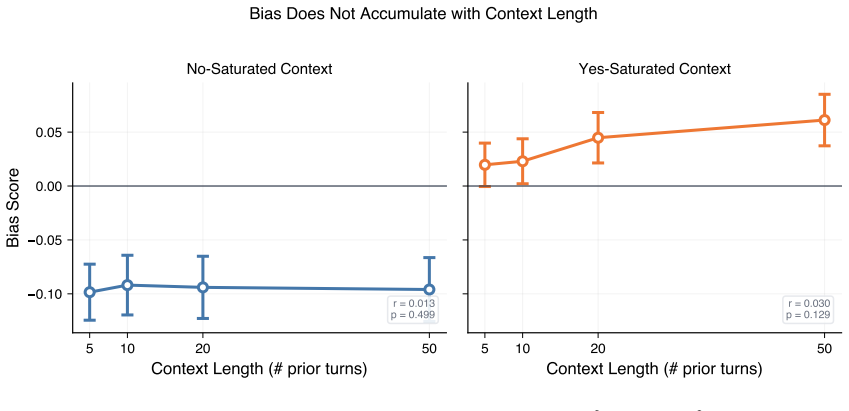
Presenting the same evaluation item after a history saturated with positive messages moves model scores upward relative to a neutral baseline, while a negative history moves scores downward, producing an overall effect size of d = -0.17. The shift is concentrated on high-entropy items (d = -0.34) and is 1.62 times larger for negative histories than positive ones. The magnitude remains constant whether the history contains 5 or 50 prior turns, and position within the history does not matter.
What carries the argument
The accumulated message effect (AMEL), defined as the directional pull that conversation history exerts on a model's subsequent scalar judgments of identical test items.
If this is right
- Bias concentrates on items the model is uncertain about at baseline, leaving high-confidence items relatively stable.
- Negative histories produce reliably larger shifts than positive histories of equal strength.
- The size of the bias stays flat once at least five prior turns are present and does not grow with additional context length.
- Model scale reduces but does not remove the effect across the tested providers and sizes.
- Resetting to a fresh context for every new item eliminates the bias in evaluation pipelines.
Where Pith is reading between the lines
- Batch evaluation workflows that reuse long contexts may systematically favor items that appear later in the sequence.
- Balancing the polarity of accumulated history before each new item could serve as a lightweight mitigation when fresh contexts are impractical.
- The same history-driven drift may appear in other sequential LLM tasks such as iterative code review or multi-turn content moderation.
Load-bearing premise
The only systematic difference between conditions is the polarity of the inserted conversation history, with the test items themselves remaining identical and free of other confounds.
What would settle it
No measurable difference in scores for the same items when presented after positive versus negative histories, or when each item is evaluated in an isolated fresh context instead of an accumulated one.
Figures











read the original abstract
Large language models are routinely used as automated evaluators: to review code, moderate content, or score outputs, often with many items passing through one conversation. We ask whether the polarity of prior conversation history biases subsequent judgments, an effect we call the accumulated message effect on LLM judgments (AMEL). Across 75,898 API calls to 11 models from 4 providers (OpenAI, Anthropic, Google, and four open-source models), we present identical test items in isolation or following histories saturated with predominantly positive or negative evaluations. Models shift toward the conversation's prevailing polarity (d = -0.17, p < 10^-46). The effect concentrates on items where the model is genuinely uncertain at baseline (d = -0.34 for high-entropy items, vs d = -0.15 when the baseline is deterministic). Bias does not grow with context length: 5 prior turns and 50 produce the same shift (Spearman |r| < 0.01; OLS slope p = 0.80). And there is a negativity asymmetry: paired per item, negative histories induce 1.62x more bias than positive (t = 13.46, p < 10^-39, n = 2,481). Scaling helps but does not solve it (Anthropic: Haiku -0.22 to Opus -0.17; OpenAI: Nano -0.34 to GPT-5.2 -0.17). Three follow-ups narrow the mechanism. The token probability distribution shifts continuously, not at a threshold. The negativity asymmetry has both token-level and semantic components, though attributing the balance is exploratory at our sample sizes. Position does not matter: five biased turns anywhere in a 50-turn history produce the same shift. The simplest fix for evaluation pipelines is a fresh context per item; when batching is unavoidable, balancing the history helps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates accumulated message effects (AMEL) on LLM judgments, claiming that the polarity of prior conversation history biases subsequent evaluations toward the history's prevailing sentiment. Using 75,898 API calls across 11 models from four providers, it reports an overall shift (d = -0.17, p < 10^-46) that is larger for high-entropy/uncertain items (d = -0.34) than deterministic ones (d = -0.15), shows no growth with context length (Spearman |r| < 0.01), exhibits negativity asymmetry (negative histories induce 1.62x more bias), and finds position invariance and partial mitigation via scaling. Follow-up analyses examine token probabilities and mechanisms, recommending fresh contexts or balanced histories for evaluation pipelines.
Significance. If the central empirical claims hold, the result is significant for the growing use of LLMs as automated evaluators in code review, content moderation, and scoring tasks, where batching items in one conversation is common. The large sample, multiple model families, and controls for length/position provide a solid empirical foundation. The work is strengthened by direct API measurements, standard statistical tests, and falsifiable predictions about effect concentration on uncertain items rather than any parameter-free derivation or machine-checked proof.
major comments (1)
- [Methods] Methods (prompt construction): The central attribution of the d = -0.17 shift to polarity alone requires explicit verification that test items are appended with literally identical wording, structure, and tokenization after positive versus negative histories. The reported controls (identical test items, position invariance, no length scaling) are only as strong as the prompt templates; without the exact templates or construction code in the methods, surface differences cannot be ruled out as confounds.
minor comments (2)
- [Abstract] Abstract and §3: The negativity asymmetry (1.62x) is reported with t = 13.46 but the paired per-item n = 2,481 should be cross-referenced to the exact item count and exclusion criteria for clarity.
- [Results] Figure 2 or equivalent: Clarify how high-entropy items are defined (e.g., baseline entropy threshold) and whether the d = -0.34 vs -0.15 comparison uses the same items or matched subsets.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on accumulated message effects in LLM judgments. We address the single major comment below and will revise the manuscript accordingly to improve transparency.
read point-by-point responses
-
Referee: [Methods] Methods (prompt construction): The central attribution of the d = -0.17 shift to polarity alone requires explicit verification that test items are appended with literally identical wording, structure, and tokenization after positive versus negative histories. The reported controls (identical test items, position invariance, no length scaling) are only as strong as the prompt templates; without the exact templates or construction code in the methods, surface differences cannot be ruled out as confounds.
Authors: We agree that providing the exact prompt templates and construction code is necessary to fully rule out surface-level confounds and strengthen attribution to polarity. In the revised manuscript we will add the complete prompt templates (for positive, negative, and neutral histories) to the Methods section, along with a description of how test items are appended. We will also release the full prompt-construction code in a public repository linked from the paper, enabling direct verification that wording, structure, and tokenization of the test items remain identical across history conditions. revision: yes
Circularity Check
No derivation chain present; empirical measurements only
full rationale
The paper presents results from direct API calls (75,898 total) to 11 models, reporting effect sizes (d = -0.17 overall), p-values, Spearman correlations, OLS slopes, and t-tests on judgment shifts induced by conversation history polarity. No equations, ansatzes, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. Central claims rest on controlled experimental comparisons (identical test items after positive/negative histories) and standard statistical tests rather than any reduction to self-referential inputs. This is the expected outcome for a purely empirical study without theoretical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying Cohen's d and reported p-values hold for the paired and unpaired comparisons performed.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Models shift toward the conversation's prevailing polarity (d = -0.17...); bias score BSi,m,p,l = P(r*|treatment) - P(r*|baseline)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and orbit embedding unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Five biased turns anywhere in a 50-turn history produce the same shift
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.